RAG with Hybrid Search
Build RAG (Retrieval-Augmented Generation) applications using VeloDB's hybrid search - combining full-text search with inverted index and BM25 scoring, and similarity search with vector index, in a single SQL query.
Hybrid search with vector indexes is available in VeloDB 5.x-preview.
What You'll Build
By the end of this tutorial, you'll have a working RAG chatbot with an interactive Agno UI:
How hybrid search works:
- Full-text search finds documents containing exact keywords ("Kafka", "streaming")
- Similarity search finds semantically similar documents (messaging, events, pipelines)
- RRF fusion combines both rankings → documents appearing in both lists rank highest
Why Search Quality Matters for RAG
RAG applications retrieve relevant documents to provide context for LLM responses. Poor retrieval leads to:
- Hallucinations - LLM generates plausible but incorrect answers
- Incomplete answers - Missing relevant context
- Irrelevant responses - Wrong documents retrieved
VeloDB solves this by combining three search methods in a single SQL query.
Three Search Methods
1. Full-text Search (with BM25 scoring)
Best for: Exact term matching, technical queries, product names, codes
-- Create table with inverted index for full-text search
CREATE TABLE documents (
id BIGINT NOT NULL AUTO_INCREMENT,
content TEXT,
INDEX idx_content(content) USING INVERTED PROPERTIES("parser"="english")
) DUPLICATE KEY(id)
DISTRIBUTED BY HASH(id) BUCKETS 1;
-- Insert sample documents
INSERT INTO documents (content) VALUES
('Apache Kafka was first released in 2011 as an open-source distributed event streaming platform.'),
('Michael Faraday discovered electromagnetic induction in 1831.'),
('The International Space Station orbits Earth at 400km altitude.');
-- Full-text search using MATCH
SELECT id, content
FROM documents
WHERE content MATCH 'electromagnetic induction'
LIMIT 5;
Result: Returns the Faraday document because it contains the exact keywords.
Limitation: Misses semantically related content. A query for "electricity discoveries" won't match "electromagnetic induction".
2. Similarity Search (Vector)
Best for: Natural language queries, concept matching, finding similar meaning
-- Create table with vector index for similarity search
CREATE TABLE documents_with_vectors (
id BIGINT NOT NULL AUTO_INCREMENT,
content TEXT,
embedding ARRAY<FLOAT>,
INDEX idx_embedding(embedding) USING INVERTED
) DUPLICATE KEY(id)
DISTRIBUTED BY HASH(id) BUCKETS 1;
-- Insert documents with embeddings (simplified 5-dim vectors for demo)
INSERT INTO documents_with_vectors (content, embedding) VALUES
('Apache Kafka was first released in 2011 as an open-source distributed event streaming platform.', [0.8, 0.2, 0.1, 0.5, 0.3]),
('Michael Faraday discovered electromagnetic induction in 1831.', [0.1, 0.9, 0.7, 0.2, 0.4]),
('The International Space Station orbits Earth at 400km altitude.', [0.3, 0.1, 0.2, 0.9, 0.8]);
-- Similarity search: find documents similar to "streaming data" [0.7, 0.3, 0.2, 0.4, 0.2]
SELECT id, content,
1 - cosine_distance(embedding, [0.7, 0.3, 0.2, 0.4, 0.2]) AS similarity
FROM documents_with_vectors
ORDER BY cosine_distance(embedding, [0.7, 0.3, 0.2, 0.4, 0.2]) ASC
LIMIT 5;
Result: Finds conceptually similar documents even without keyword overlap.
Limitation: May miss documents with exact keyword matches that users expect.
3. Hybrid Search (Full-text + Vector + Filter + RRF)
Best for: RAG applications requiring both precision and recall
Hybrid search combines full-text and similarity search using Reciprocal Rank Fusion (RRF):
-- Create table with BOTH indexes
CREATE TABLE rag_documents (
id BIGINT NOT NULL AUTO_INCREMENT,
content TEXT,
embedding ARRAY<FLOAT>,
-- Vector index for similarity search
INDEX idx_embedding(embedding) USING INVERTED,
-- Inverted index for full-text search
INDEX idx_content(content) USING INVERTED PROPERTIES("parser"="english")
) DUPLICATE KEY(id)
DISTRIBUTED BY HASH(id) BUCKETS 1
PROPERTIES ("replication_num" = "1");
-- Insert sample documents with embeddings (simplified 5-dim vectors for demo)
INSERT INTO rag_documents (content, embedding) VALUES
('Apache Kafka was first released in 2011 as an open-source distributed event streaming platform.', [0.8, 0.2, 0.1, 0.5, 0.3]),
('Michael Faraday discovered electromagnetic induction in 1831.', [0.1, 0.9, 0.7, 0.2, 0.4]),
('The International Space Station orbits Earth at 400km altitude.', [0.3, 0.1, 0.2, 0.9, 0.8]);
Real embeddings typically have 1536 dimensions. The Docker demo uses OpenAI's text-embedding-3-small for production-quality vectors.
Hybrid search query with RRF fusion:
-- Search for "Kafka streaming" with embedding [0.7, 0.3, 0.2, 0.4, 0.2]
WITH vector_results AS (
-- Similarity search: find conceptually similar documents
SELECT
id, content,
1 - cosine_distance(embedding, [0.7, 0.3, 0.2, 0.4, 0.2]) AS vector_score,
ROW_NUMBER() OVER (ORDER BY cosine_distance(embedding, [0.7, 0.3, 0.2, 0.4, 0.2]) ASC) AS vector_rank
FROM rag_documents
ORDER BY cosine_distance(embedding, [0.7, 0.3, 0.2, 0.4, 0.2]) ASC
LIMIT 10
),
text_results AS (
-- Full-text search: find exact term matches
SELECT
id, content,
1.0 AS text_score,
ROW_NUMBER() OVER (ORDER BY id) AS text_rank
FROM rag_documents
WHERE content MATCH 'Kafka streaming'
LIMIT 10
),
combined AS (
-- Combine results from both methods
SELECT
COALESCE(v.id, t.id) AS id,
COALESCE(v.content, t.content) AS content,
COALESCE(v.vector_score, 0) AS vector_score,
COALESCE(t.text_score, 0) AS text_score,
COALESCE(v.vector_rank, 999) AS vector_rank,
COALESCE(t.text_rank, 999) AS text_rank
FROM vector_results v
FULL OUTER JOIN text_results t ON v.id = t.id
)
-- RRF fusion: combine rankings with 1/(k + rank) formula
SELECT
id, content, vector_score, text_score,
(0.5 / (60 + vector_rank) + 0.5 / (60 + text_rank)) AS hybrid_score
FROM combined
ORDER BY hybrid_score DESC
LIMIT 5;
How RRF works:
- Each search method produces a ranked list
- RRF formula:
score = Σ (weight / (k + rank))where k=60 is standard - Documents appearing in both lists get boosted
- Documents appearing in only one list still contribute
Search Method Comparison
| Query Type | Full-text | Similarity | Hybrid |
|---|---|---|---|
| "electromagnetic induction" | ✅ Exact match | ✅ Concept match | ✅ Best of both |
| "electricity discoveries" | ❌ No keyword match | ✅ Finds Faraday | ✅ Finds Faraday |
| "Kafka 2011" | ✅ Exact match | ⚠️ May rank lower | ✅ Top result |
| "event streaming platforms" | ⚠️ Partial match | ✅ Semantic match | ✅ Best of both |
Key insight: Hybrid search catches cases where either method alone would fail.
Complete RAG Application
Below is a complete RAG application with an interactive chat UI powered by Agno.
Quick Start with Docker
Run the complete demo with a single command:
docker run -p 3001:3001 -p 7777:7777 \
-e VELODB_HOST=your-cluster.velodb.io \
-e VELODB_USER=admin \
-e VELODB_PASSWORD=your-password \
-e VELODB_DATABASE=rag_demo \
-e OPENROUTER_API_KEY=sk-or-v1-your-key \
velodb/rag-tutorial:1.0
Open http://localhost:3001 to start chatting.
Try These Queries
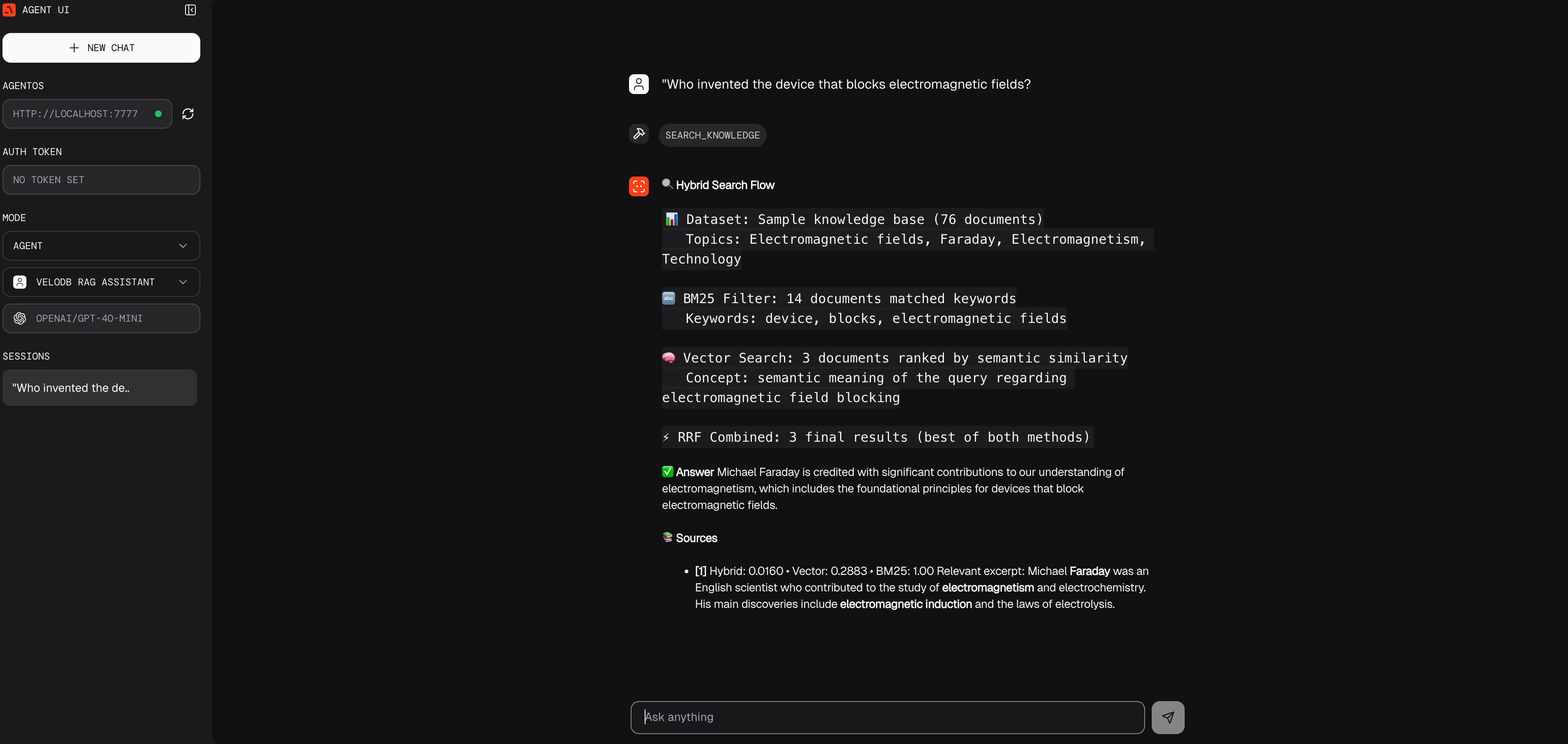
1. Test Hybrid Search (Keywords + Semantic)
Who invented the device that blocks electromagnetic fields?
Watch how hybrid search combines BM25 keyword matching ("electromagnetic", "fields") with vector semantic understanding ("invented", "device", "blocks") to find the Faraday cage document.
2. Test Semantic Understanding
What streaming platform was created by a social media company?
Notice how vector search understands that LinkedIn is a social media company, finding the Kafka document.
3. Test Keyword Precision
electromagnetic induction
BM25 provides exact keyword matching with high confidence.
4. Add Your Own Document
Add this to the knowledge base: Apache Kafka is a distributed event streaming platform used for high-performance data pipelines and streaming analytics.
Then ask: What is Kafka used for?
Troubleshooting
| Issue | Solution |
|---|---|
| Connection timeout | Check VeloDB host and port 9030 are accessible |
| Empty search results | Ensure documents are ingested first |
| Embedding errors | Verify OpenRouter API key has credits |
| MATCH query fails | Check inverted index exists on content column |