A Practical Guide to Migrating Apache Doris to VeloDB Cloud BYOC
1.Guide Overview
1.1 Purpose of This Guide
This document provides a comprehensive and practical guide for migrating from Apache Doris to VeloDB Cloud BYOC (Bring Your Own Cloud). The goal is to help users complete the migration independently, with low risk, and high efficiency.
1. 2 Scope
This guide covers the following topics:
- Creating a VeloDB Cloud BYOC data warehouse
- Metadata migration
- Data migration
- Job migration
1. 3 Prerequisites
To begin the migration, the following prerequisites must be met:
- Access credentials and permissions for the Apache Doris cluster
- Access credentials and permissions for the VeloDB Cloud platform
- Access credentials and permissions for the public cloud platform
- Network connectivity between the public cloud environment and VeloDB Cloud BYOC
2. Creating a VeloDB Cloud BYOC Data Warehouse
2.1 Prerequisites
- Prepare a public cloud administrator account, which is required for configuring the underlying cloud resources used by VeloDB Cloud.
- Ensure network connectivity between the VeloDB BYOC warehouse and your business environment.
- If the warehouse and the application are deployed in different VPCs, you may establish connectivity via VPC Peering.
- If VPC Peering is not acceptable, it is recommended to deploy the VeloDB BYOC warehouse in the same VPC as the business applications.
2.2 Creation Steps
- Prepare a VeloDB Cloud platform administrator account and log in. Reference link: https://www.velodb.cloud/passport/login
- Complete billing setup in the VeloDB Cloud platform.
- If your VeloDB Cloud BYOC account is still within the free trial period, you may skip this step.
- If the free trial has ended, billing setup is required. Reference link: https://docs.velodb.io/cloud/management-guide/usage-and-billing
- Create a VeloDB Cloud BYOC data warehouse.
- Template Mode is the recommended approach for creating a data warehouse. Template Mode is available for AWS, Azure, and GCP (see reference table below).
- Wizard Mode is also available but currently supported only on AWS (see reference table below).
3. Migration
The document mainly covers the following sections:
- Metadata Migration for Tables, Views, and Materialized Views(both synchronous and asynchronous)
- Metadata Migration for Roles, Users, and Privileges
- Data Migration
- Load Job Migration
- ETL Job Migration
3.1 Prerequisites
- Access credentials and read permissions for the Apache Doris cluster and its data warehouse.
- An S3 bucket in the same region as the VeloDB Cloud BYOC deployment, used as an intermediate storage location during data migration. The required credentials include S3 Access Key / Secret Key (AK/SK) or an applicable IAM Role.
- A VeloDB Cloud platform account with read/write permissions for the target data warehouse. You may create a dedicated user and assign read/write privileges for data import operations. Reference link:
3.2 Migration Process
A typical complete migration process is as follows:
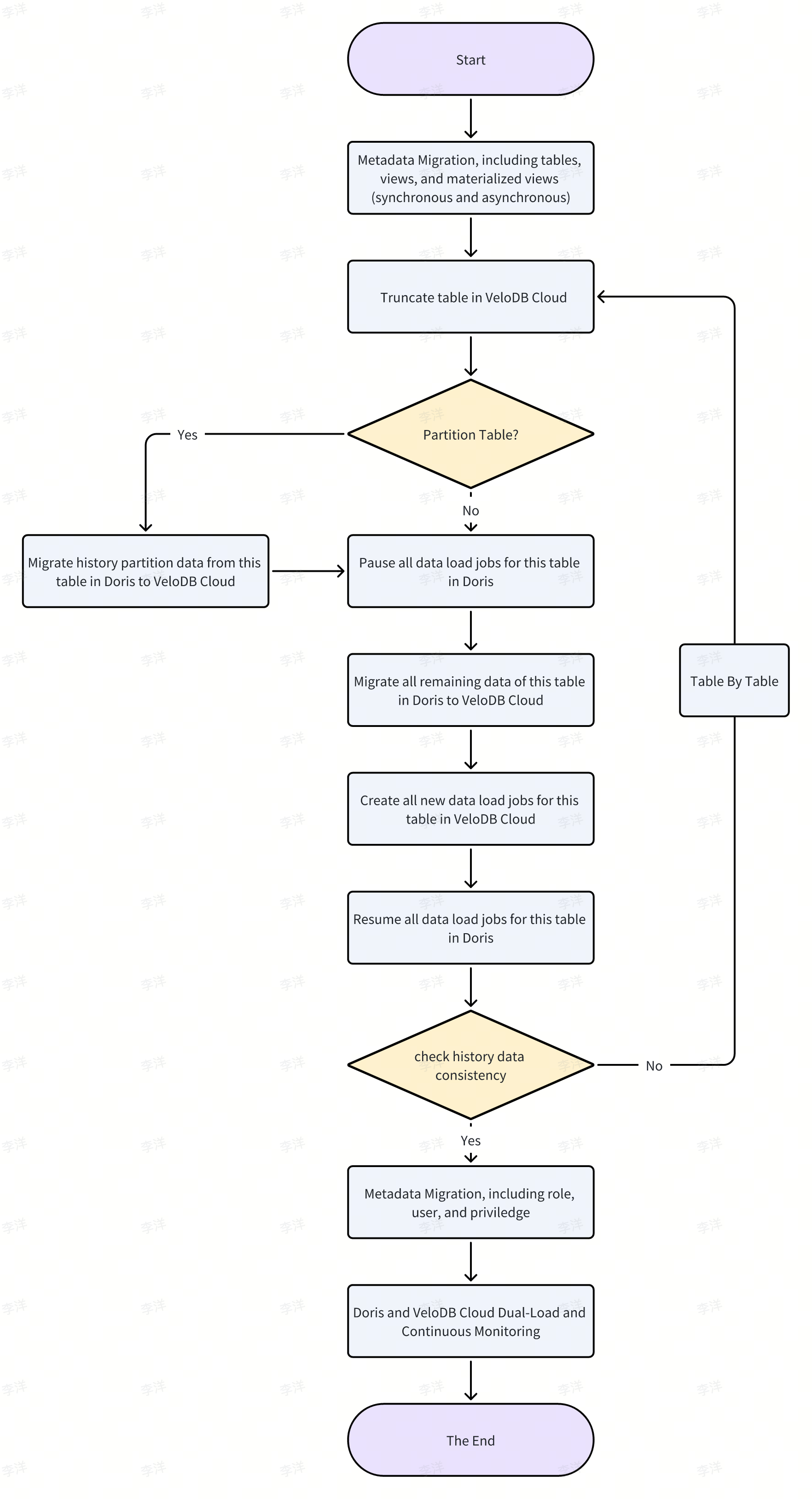
3.3 Metadata Migration
- The current scope of metadata migration includes two major categories:
- Tables, views, and materialized views (synchronous and asynchronous)
- Users and permissions
- Two migration approaches are available, You may choose either option based on your requirements.
- Manual migration guidelines
- Migration script tools
3.3.1 Migration Items
3.3.1.1 Tables, Views, and Materialized Views (Synchronous & Asynchronous)
3.3.1.1.1 Manual Migration
- Table Migration. Use the
SHOW CREATE TABLEcommand on the source Doris cluster to obtain the table DDL. After making necessary adjustments, create the corresponding table in the target VeloDB Cloud environment. Reference: https://doris.apache.org/docs/dev/sql-manual/sql-statements/table-and-view/table/SHOW-CREATE-TABLE - View Migration. Use the
SHOW CREATE VIEWcommand in the source Doris cluster to get the view DDL. Adjust the DDL as needed, then create the view in VeloDB Cloud. Reference: https://doris.apache.org/docs/dev/sql-manual/sql-statements/table-and-view/view/SHOW-CREATE-VIEW - Synchronous Materialized View Migration. Use the command
SHOW CREATE MATERIALIZED VIEW mv_name ON table_nameon the source Doris cluster to obtain the DDL for the synchronous materialized view. After manual adjustment, create the synchronous materialized view in VeloDB Cloud. Reference: https://doris.apache.org/docs/dev/sql-manual/sql-statements/table-and-view/sync-materialized-view/SHOW-CREATE-MATERIALIZED-VIEW - Asynchronous Materialized View Migration. Use the
SHOW CREATE MATERIALIZED VIEW mv_namecommand on the source Doris cluster to view the DDL of the asynchronous materialized view. Adjust the DDL accordingly and recreate the asynchronous materialized view in VeloDB Cloud. Reference: https://doris.apache.org/docs/dev/query-acceleration/materialized-view/async-materialized-view/functions-and-demands#viewing-materialized-view-creation-statement
3.3.1.1.2 Script Migration
table_metadata.py, refer to the final section for the script.
# usage
python table_metadata.py pipeline -h
# an example of how to use table_metadata.py
python table_metadata.py pipeline \
--host source-ip --port 9030 --user root --password root \
--target-host target-ip --target-port 9030 --target-user root --target-password root \
--include-dbs test \
--skip-existing \
--dry-run
3.3.1.2 Roles, Users, and Privileges
3.3.1.2.1 Manual Migration
3.3.1.2.1.1 Role and User Migration
- All roles in the Doris system, the users associated with each role, and the privileges granted to each role can be viewed using
SHOW ROLES. Reference: https://doris.apache.org/docs/dev/sql-manual/sql-statements/account-management/SHOW-ROLES - All required roles can be created in the VeloDB system using
CREATE ROLE. Reference: https://doris.apache.org/docs/dev/sql-manual/sql-statements/account-management/CREATE-ROLE/ - All required users can be created in the VeloDB system using
CREATE USER. Reference: https://doris.apache.org/docs/dev/sql-manual/sql-statements/account-management/CREATE-USER/ - Corresponding roles can be assigned to users using
GRANT TO. Reference: https://doris.apache.org/docs/dev/sql-manual/sql-statements/account-management/GRANT-TO
3.3.1.2.1.2 Privilege Migration
- User privileges in the Doris cluster can be viewed using
SHOW GRANTS. Reference: https://doris.apache.org/docs/dev/sql-manual/sql-statements/account-management/SHOW-GRANTS/ - Corresponding privileges can be granted to users and roles in the VeloDB system using
GRANT TO. Reference: https://doris.apache.org/docs/dev/sql-manual/sql-statements/account-management/GRANT-TO
3.3.1.2.2 Script-Based Migration
python privilege_metadata.py pipeline \
--host source-ip --port 9030 --user admin --password '***' \
--target-host target-ip --target-port 9030 --target-user root --target-password '***' \
--create-missing-users --default-password 'Temp@123' \
--output privileges_src.json
3.4 Data and Load Job Migration
3.4.1 Load Job Migration
3.4.1.1 Migration of Internally Managed Load Jobs in Doris
The load jobs internally managed by Doris mainly include four types: Routine Load, Broker Load, MySQL Load, and data lake INSERT INTO SELECT. VeloDB Cloud provides corresponding support for all four approaches and keeps the syntax consistent. Refer to the following links for details:
https://docs.velodb.io/cloud/user-guide/data-ingestion/import-way/routine-load-manual https://docs.velodb.io/cloud/user-guide/data-ingestion/import-way/broker-load-manual https://docs.velodb.io/cloud/user-guide/data-ingestion/import-way/mysql-load-manual https://docs.velodb.io/cloud/user-guide/data-ingestion/import-way/insert-into-manual
3.4.1.1.1 Routine Load Job Migration
- collect Routineload in Doris
collect the list of Routineload names, PAUSE and RESUME statements corresponding to each table. Execute the script
python routine_load_info.py
The returned result is as shown in the screenshot below.
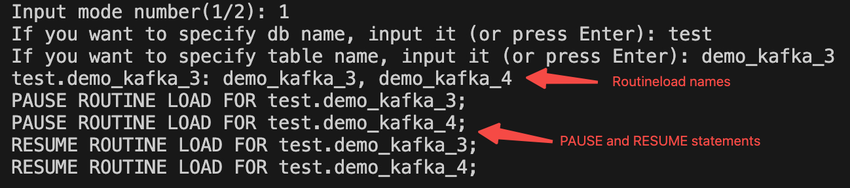
- Pause Routineload in Doris
Pause Routineload tasks at the table level
PAUSE ROUTINE LOAD FOR testdb.example_routine_load_csv;
- Generate Routineload creation statements from Doris
Generate corresponding Routineload statements based on Doris's offset for each table. Execute the script
python routine_load_info.py
The returned result is as shown in the screenshot below.
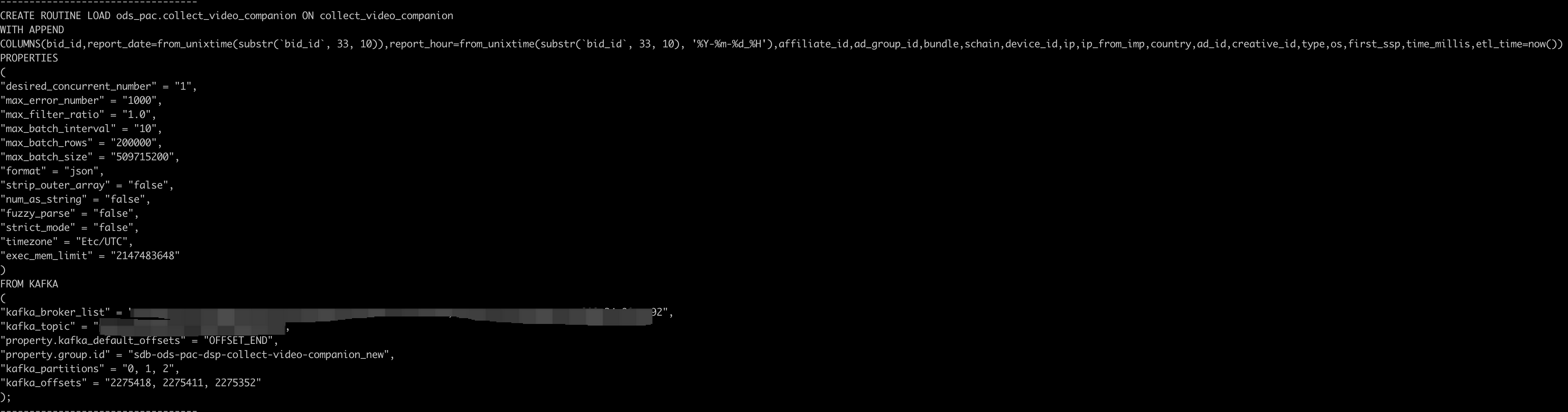
- Create Routineload in VeloDB Cloud
Below is a demo, using Routineload CREATE statements generated for each table
CREATE ROUTINE LOAD ods_ssp.xxx ON ssp_sdk_crash_report
WITH APPEND
PROPERTIES
(
"desired_concurrent_number" = "3",
"max_error_number" = "10000",
"max_filter_ratio" = "1.0",
"max_batch_interval" = "20",
"max_batch_rows" = "1000000",
"max_batch_size" = "509715200",
"format" = "json",
"strip_outer_array" = "false",
"num_as_string" = "false",
"fuzzy_parse" = "false",
"strict_mode" = "false",
"timezone" = "Etc/UTC",
"exec_mem_limit" = "2147483648"
)
FROM KAFKA
(
"kafka_broker_list" = "",
"kafka_topic" = "ssp-sdk-crash-report",
"property.kafka_default_offsets" = "OFFSET_END",
"property.group.id" = "ssp_sdk_crash_report_doris_load_new",
"kafka_partitions" = "0, 1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11, 12, 13, 14, 15, 16, 17, 18, 19, 20, 21, 22, 23, 24, 25, 26, 27, 28, 29, 30, 31, 32, 33, 34, 35, 36, 37, 38, 39, 40, 41, 42, 43, 44, 45, 46, 47, 48, 49, 50, 51, 52, 53, 54, 55, 56, 57, 58, 59, 60, 61, 62, 63",
"kafka_offsets" = "186878, 179431, 179444, 179447, 179449, 179441, 179440, 179451, 179441, 179454, 179449, 179440, 179437, 186873, 179414, 186876, 179442, 179442, 179450, 186871, 179447, 179447, 179449, 179451, 186879, 179455, 179453, 186857, 179447, 179443, 179447, 179454, 186875, 179440, 179439, 179441, 179447, 179447, 186867, 186882, 179448, 179449, 179446, 179448, 179450, 186884, 179450, 179435, 179440, 179441, 179450, 186879, 179461, 179449, 186854, 179447, 186881, 186870, 179458, 179455, 179450, 186871, 186877, 179437"
);
- Resume Routineload in Doris
Restore the Routineload tasks in Doris that have just stopped
RESUME ROUTINE LOAD FOR testdb.example_routine_load_csv;
3.4.1.2 Migration of Load Jobs Managed Outside Doris
Load jobs managed outside Doris are diverse, including native Stream Load, native JDBC INSERT INTO, Flink, Spark, Kafka Connect, dbt, SeaTunnel, Kettle, DataX, and other approaches. VeloDB Cloud provides corresponding support for all of these methods and keeps the syntax consistent. For migration, it is only required to copy or recreate the existing load jobs and their scheduling configurations, update the endpoint addresses, and then run them on VeloDB Cloud. Refer to the following links for details:
https://docs.velodb.io/cloud/user-guide/data-ingestion/import-way/stream-load-manual
https://docs.velodb.io/cloud/user-guide/data-ingestion/import-way/insert-into-values-manual
https://docs.velodb.io/cloud/integration/data-processing/flink-doris-connector
https://docs.velodb.io/cloud/integration/data-processing/spark-doris-connector
https://docs.velodb.io/cloud/integration/data-source/doris-kafka-connector
https://docs.velodb.io/cloud/integration/data-processing/dbt-doris-adapter
https://docs.velodb.io/cloud/integration/data-ingestion/seatunnel
https://docs.velodb.io/cloud/integration/more/kettle
https://docs.velodb.io/cloud/integration/more/datax
3.4.2 Data Migration
3.4.2.1 File-Based Import/Export
- It is recommended to use
SELECT INTO OUTFILEwith Parquet file format to export data from Doris to object storage such as S3, either by table or by partition. - It is recommended to use TVF with Parquet file format to import data from object storage such as S3 into VeloDB Cloud, either by table or by partition.
3.4.2.1.1 Export from Doris
It is recommended to use SELECT INTO OUTFILE with Parquet file format to export data from Doris to object storage such as S3, either by table or by partition. For more details, refer to: https://doris.apache.org/docs/dev/data-operate/export/outfile#export-to-object-storage
- By table
SET query_timeout = 14400;
SELECT *
FROM sales
INTO OUTFILE "s3://my-bucket/export/sales_"
FORMAT AS PARQUET
PROPERTIES (
"s3.endpoint" = "https://s3.us-east-1.amazonaws.com",
"s3.access_key" = "<YourAccessKey>",
"s3.secret_key" = "<YourSecretKey>",
"max_file_size" = "1073741824" -- set each file max size to 1 GB
);
- By partition
SET query_timeout = 14400;
SELECT *
FROM events PARTITION (p20251101)
INTO OUTFILE "s3://my-bucket/export/events/date=2025-11-01_"
FORMAT AS PARQUET
PROPERTIES (
"s3.endpoint" = "https://s3.us-east-1.amazonaws.com",
"s3.access_key" = "<YourAccessKey>",
"s3.secret_key" = "<YourSecretKey>",
"max_file_size" = "1073741824" -- set each file max size to 1 GB
);
3.4.2.1.2 Import into VeloDB Cloud
It is recommended to use TVF with Parquet file format to import data from object storage such as S3 into VeloDB Cloud, either by table or by partition. For more details, refer to: https://docs.velodb.io/cloud/user-guide/data-ingestion/file-format/parquet#tvf-load
- By table
SET insert_timeout = 14400;
INSERT INTO sales
SELECT *
FROM S3(
's3://my-bucket/sales/',
'format' = 'parquet',
'aws.s3.access_key' = '<YourAccessKey>',
'aws.s3.secret_key' = '<YourSecretKey>',
'aws.s3.endpoint' = 'https://s3.us-east-1.amazonaws.com'
);
- By partition
SET insert_timeout = 14400;
INSERT INTO events
SELECT *
FROM S3(
's3://my-bucket/events/date=2025-11-01/',
'format' = 'parquet',
'aws.s3.access_key' = '<YourAccessKey>',
'aws.s3.secret_key' = '<YourSecretKey>',
'aws.s3.endpoint' = 'https://s3.us-east-1.amazonaws.com'
);
3.4.2.1.3 Notes
- The
query_timeoutparameter can be set to control the export timeout, preventing failures when exporting large amounts of data. The unit ofquery_timeoutis seconds. Reference: https://doris.apache.org/docs/dev/data-operate/export/outfile#notice - A separate Workload Group can be created for data export to control the impact of
SELECT INTO OUTFILEtasks on online Doris workloads. Reference: https://doris.apache.org/docs/dev/admin-manual/workload-management/workload-group - The
insert_timeoutparameter can be set to control the timeout of TVF import tasks. In most cases, it is not necessary to set it, as the default value is 14400 seconds (4 hours), which is generally sufficient. Reference: https://doris.apache.org/docs/dev/data-operate/import/import-way/insert-into-manual#data-size - Besides AK/SK authentication, VeloDB Cloud supports S3 authentication for TVF imports via IAM Role. Reference: https://docs.velodb.io/cloud/security/integrations/aws-authentication-and-authorization
- Besides AK/SK authentication, Doris
SELECT INTO OUTFILEexport supports S3 authentication via IAM Role. Reference: https://doris.apache.org/docs/dev/admin-manual/auth/integrations/aws-authentication-and-authorization#assumed-role-authentication
3.4.2.2 Visual Migration
VeloDB Cloud also provides a visual data migration feature that can be operated directly within the management platform. For specific details, please refer to Migration.
3.5 ETL Jobs
- SQL compatibility in ETL jobs can be verified using a replay tool. The principle is to run the ETL job SQL from the Doris cluster in the VeloDB Cloud warehouse.
- If the ETL job SQL is compatible, simply copy and recreate the ETL jobs and their schedules, update the endpoint addresses, and run them on VeloDB Cloud.
- If there are incompatibilities, contact the VeloDB official technical team.
3.5.1Replay Tool
Currently, two versions of the replay tool are provided: x86 and ARM. The archive package includes the tool itself and the user manual.
3.5.1.1 X86
3.5.1.2 ARM
3.6 System Parameter Migration
For system parameters, there is currently no reliable tool. It is recommended to adjust and align them on a case-by-case basis during the validation phase after migration.
4. Post-Migration Validation
4.1 Data Consistency Validation
- Use
SELECT COUNT(*) FROM tableto verify whether the record counts in the Doris source tables and VeloDB Cloud target tables are consistent after data migration. - Use
SELECT SUM(calculable_column) FROM tableto verify whether the detailed data in the Doris source tables and VeloDB Cloud target tables are completely consistent after data migration.
4.2 Import Performance Validation
The Load job import latency and throughput after migration can be verified using the following metrics on the VeloDB Cloud monitoring page: Load Rows Per Second, Load Bytes Per Second, and Transaction Latency.
- Load Rows Per Second https://docs.velodb.io/cloud/management-guide/monitoring-overview#load-rows-per-second
- Load Bytes Per Second https://docs.velodb.io/cloud/management-guide/monitoring-overview#load-bytes-per-second
- Transaction Latency https://docs.velodb.io/cloud/management-guide/monitoring-overview#transaction-latency
4.3 Query Performance Validation
4.3.1 Typical Large Query Performance Validation
Collect typical large query cases and performance metrics, such as ETL jobs or OLAP large query cases, to verify whether the large query performance in the target system VeloDB Cloud is consistent with that of the source Doris system.
If the large query performance in VeloDB Cloud is worse, differences in system parameters between VeloDB Cloud and Doris, hot/cold query patterns, CPU and memory resources, and other factors should be ruled out. For any issues, contact the VeloDB official technical team.
4.3.2 Query Concurrency Stress Test Validation
Collect query concurrency cases and performance metrics from the Doris cluster, such as SQL statements, QPS, and 90/95/99 percentile latency, to verify whether the query concurrency performance in VeloDB Cloud is consistent with that in the source Doris system.
It is recommended to use JMeter for query concurrency stress testing.
If the query concurrency performance in VeloDB Cloud is worse, differences in system parameters between VeloDB Cloud and Doris, hot/cold query patterns, CPU and memory resources, and other factors should be ruled out. For any issues, contact the VeloDB official technical team.
5. Additional Resources
5.1 routine_load_info.py
5.1.1 Prerequisites for Script Execution
pip3 install pymysql
5.1.2Script Content
import pymysql
import re
import json
def get_mysql_connection(host, user, password, port=3306, db=None):
"""
Establish MySQL connection
"""
conn = None
try:
conn = pymysql.connect(
host=host,
user=user,
password=password,
port=port,
db=db,
charset='utf8mb4'
)
except Exception as e:
print(f"Failed to connect to MySQL: {e}")
return conn
def fetch_table_schemas(host, user, password, port=3306):
"""
Execute SQL and return result list
"""
sql = """
select table_schema
from information_schema.tables
where table_schema not in ('mysql','information_schema','__internal_schema')
group by table_schema ;
"""
result_list = []
conn = get_mysql_connection(host, user, password, port)
if conn:
try:
with conn.cursor() as cursor:
cursor.execute(sql)
rows = cursor.fetchall()
result_list = [row[0] for row in rows]
except Exception as e:
print(f"Failed to execute SQL: {e}")
finally:
conn.close()
return result_list
def clean_dbname(dbname):
"""
Remove 'default_cluster:' prefix if exists
"""
if dbname and isinstance(dbname, str):
if dbname.startswith("default_cluster:"):
return dbname.split(":", 1)[1]
return dbname
def fetch_routine_load_info(host, user, password, db_list, port=3306, filter_db=None, filter_table=None):
"""
Traverse db_list, use each db, execute show routine load; get Name,DbName,TableName,Progress fields
Support filter_db, filter_table, only get routine load for specified db/table
Return format: {db1: [dict1, dict2, ...], db2: [...], ...}
"""
result = {}
for db in db_list:
if filter_db and db != filter_db:
continue
conn = get_mysql_connection(host, user, password, port, db=db)
db_result = []
if conn:
try:
with conn.cursor() as cursor:
cursor.execute("show routine load;")
columns = [desc[0] for desc in cursor.description]
rows = cursor.fetchall()
for row in rows:
row_dict = dict(zip(columns, row))
filtered = {k: row_dict.get(k) for k in ['Name', 'DbName', 'TableName', 'Progress']}
filtered['DbName'] = clean_dbname(filtered.get('DbName'))
if filter_table and filtered.get('TableName') != filter_table:
continue
db_result.append(filtered)
except Exception as e:
print(f"Failed to execute show routine load in db {db}: {e}")
finally:
conn.close()
if db_result:
result[db] = db_result
return result
def get_dbtable_to_names(routine_load_infos):
"""
Count all Names for each DbName.TableName
routine_load_infos: {db1: [dict1, dict2, ...], db2: [...], ...}
Return: { "DbName.TableName": set([Name1, Name2, ...]), ... }
"""
dbtable_to_names = {}
for db, info_list in routine_load_infos.items():
for item in info_list:
dbname = clean_dbname(item.get('DbName'))
tablename = item.get('TableName')
name = item.get('Name')
if dbname and tablename and name:
key = f"{dbname}.{tablename}"
if key not in dbtable_to_names:
dbtable_to_names[key] = set()
dbtable_to_names[key].add(name)
return dbtable_to_names
def fetch_create_routine_load(host, user, password, port, db, routine_load_name):
"""
Get create statement for specified routine load
show create routine load for db.routineloadName
Note: The third column is the create statement
"""
db_clean = clean_dbname(db)
conn = get_mysql_connection(host, user, password, port, db=db_clean)
create_sql = ""
if conn:
try:
with conn.cursor() as cursor:
sql = f"show create routine load for {db_clean}.{routine_load_name}"
cursor.execute(sql)
row = cursor.fetchone()
if row:
create_sql = row[2] if len(row) > 2 else (row[1] if len(row) > 1 else row[0])
except Exception as e:
print(f"Failed to get create statement for {db_clean}.{routine_load_name}: {e}")
finally:
conn.close()
return create_sql
def replace_kafka_offsets(create_sql, progress_json):
"""
Replace kafka_offsets in create_sql with offsets from progress_json, add 1 to each
"""
try:
progress = json.loads(progress_json)
offsets = []
for k in sorted(progress.keys(), key=lambda x: int(x)):
v = int(progress[k]) + 1
offsets.append(str(v))
new_offsets = ", ".join(offsets)
def repl(m):
return f'kafka_offsets" = "{new_offsets}"'
create_sql_new = re.sub(r'kafka_offsets"\s*=\s*"[0-9,\s]*"', repl, create_sql)
return create_sql_new
except Exception as e:
print(f"Failed to replace kafka_offsets: {e}")
return create_sql
def patch_create_sql_dbname(create_sql, dbname, routinename):
"""
Replace CREATE ROUTINE LOAD routinename ON with CREATE ROUTINE LOAD dbname.routinename ON
"""
pattern = r'(CREATE\s+ROUTINE\s+LOAD\s+)(\w+)(\s+ON\s+)'
replacement = r'\1' + f'{dbname}.{routinename}' + r'\3'
create_sql = re.sub(pattern, replacement, create_sql, count=1)
return create_sql
def patch_group_id(create_sql):
"""
Replace "property.group.id" = "xxx" with "property.group.id" = "xxx_new"
"""
def repl(m):
old_value = m.group(1)
if old_value.endswith("_new"):
return m.group(0)
return f'"property.group.id" = "{old_value}_new"'
create_sql = re.sub(r'"property\.group.id"\s*=\s*"([^"]+)"', repl, create_sql)
return create_sql
def split_sql_with_separator(sql):
"""
Add separator after each );
"""
return re.sub(r'\);\s*', ');\n----------------------------------\n', sql)
def get_routine_load_create_sqls_with_offsets(host, user, password, port, routine_load_infos):
"""
Get create statement for each routine load, replace kafka_offsets, patch dbname, patch group id
Return: {db: {routine_load_name: create_sql}}
"""
result = {}
for db, info_list in routine_load_infos.items():
db_result = {}
for item in info_list:
name = item.get('Name')
dbname = clean_dbname(item.get('DbName'))
progress = item.get('Progress')
if not (name and dbname and progress):
continue
create_sql = fetch_create_routine_load(host, user, password, port, dbname, name)
if not create_sql:
continue
create_sql_new = replace_kafka_offsets(create_sql, progress)
create_sql_new = patch_create_sql_dbname(create_sql_new, dbname, name)
create_sql_new = patch_group_id(create_sql_new)
db_result[name] = create_sql_new
if db_result:
result[db] = db_result
return result
def generate_pause_resume_sql(dbtable_to_names, filter_db=None, filter_table=None):
"""
Generate PAUSE/RESUME ROUTINE LOAD statements
dbtable_to_names: { "DbName.TableName": set([Name1, Name2, ...]), ... }
filter_db, filter_table: only generate statements for specified db/table
Return: list of (dbtable, [names], [pause_sqls], [resume_sqls])
"""
result = []
for dbtable, names in dbtable_to_names.items():
db, table = dbtable.split('.', 1)
if filter_db and db != filter_db:
continue
if filter_table and table != filter_table:
continue
names_sorted = sorted(list(names))
pause_sqls = []
resume_sqls = []
for name in names_sorted:
pause_sqls.append(f"PAUSE ROUTINE LOAD FOR {db}.{name};")
resume_sqls.append(f"RESUME ROUTINE LOAD FOR {db}.{name};")
result.append((dbtable, names_sorted, pause_sqls, resume_sqls))
return result
def main():
print("Please input MySQL connection info:")
host = input("host: ")
user = input("user: ")
password = input("password: ")
port = input("port(default 3306): ")
port = int(port) if port else 3306
print("Please select mode:")
print("1. Show routine load names for each table and their PAUSE/RESUME statements")
print("2. Show modified routine load create statements")
mode = input("Input mode number(1/2): ").strip()
filter_db = input("If you want to specify db name, input it (or press Enter): ").strip()
filter_table = input("If you want to specify table name, input it (or press Enter): ").strip()
filter_db = filter_db if filter_db else None
filter_table = filter_table if filter_table else None
db_list = fetch_table_schemas(host, user, password, port)
routine_load_infos = fetch_routine_load_info(host, user, password, db_list, port, filter_db, filter_table)
dbtable_to_names = get_dbtable_to_names(routine_load_infos)
if mode == "1":
result = generate_pause_resume_sql(dbtable_to_names, filter_db=filter_db, filter_table=filter_table)
for dbtable, names, pause_sqls, resume_sqls in result:
# 展示表名: routine load名字(逗号分隔)
print(f"{dbtable}: {', '.join(names)}")
# 如果只有一个routine load
if len(names) == 1:
print(pause_sqls[0])
print(resume_sqls[0])
else:
for sql in pause_sqls:
print(sql)
for sql in resume_sqls:
print(sql)
print("") # 空行分隔
elif mode == "2":
print("Getting routine load create statements...")
create_sqls_dict = get_routine_load_create_sqls_with_offsets(host, user, password, port, routine_load_infos)
all_sqls = []
for db, name_sqls in create_sqls_dict.items():
for name, sql in name_sqls.items():
all_sqls.append(sql.strip())
print("Modified routine load create statements:")
print("\n----------------------------------\n".join(all_sqls))
else:
print("Invalid mode number.")
if __name__ == "__main__":
main()
5.2 table_metadata.py
5.2.1 Prerequisites for Script Execution
pip3 install mysql-connector-python
5.2.2 Script Content
#!/usr/bin/env python3
import argparse
import datetime as dt
import json
import pathlib
import sys
from typing import Dict, Iterable, List, Optional, Set, Tuple
import mysql.connector
from mysql.connector.connection import MySQLConnection
from mysql.connector.cursor import MySQLCursor
def parse_args() -> argparse.Namespace:
parser = argparse.ArgumentParser()
subparsers = parser.add_subparsers(dest="command", required=True)
export_parser = _add_export_parser(subparsers)
apply_parser = _add_apply_parser(subparsers)
pipeline_parser = _add_pipeline_parser(subparsers)
# shared arguments
for sub in (export_parser, pipeline_parser):
sub.add_argument(
"--include-dbs",
help="Comma-separated list of databases to include. Default: all non-system databases.",
)
sub.add_argument(
"--exclude-dbs",
default="_statistics_,information_schema,mysql,__internal_schema",
help="Comma-separated list of databases to exclude.",
)
sub.add_argument(
"--snapshot-id",
help="Snapshot identifier. Default: current UTC timestamp.",
)
sub.add_argument(
"--output-dir",
default="metadata",
help="Directory where snapshot folders will be created.",
)
for sub in (apply_parser, pipeline_parser):
sub.add_argument(
"--target-host",
required=True,
help="Target FE host for apply.",
)
sub.add_argument(
"--target-port",
type=int,
default=9030,
help="Target FE port for apply.",
)
sub.add_argument(
"--target-user",
required=True,
help="Target MySQL user for apply.",
)
sub.add_argument(
"--target-password",
required=True,
help="Target MySQL password for apply.",
)
sub.add_argument(
"--skip-existing",
action="store_true",
help="When applying, skip tables that already exist on target.",
)
sub.add_argument(
"--dry-run",
action="store_true",
help="When applying, print DDL instead of executing.",
)
sub.add_argument(
"--no-create-databases",
action="store_true",
help="When applying, do not auto-create databases (requires target to exist).",
)
return parser.parse_args()
def _add_export_parser(subparsers):
parser = subparsers.add_parser(
"export", help="Export metadata from source cluster."
)
parser.add_argument("--host", required=True, help="Source FE MySQL host")
parser.add_argument("--port", type=int, default=9030, help="Source FE MySQL port")
parser.add_argument("--user", required=True, help="Source MySQL user")
parser.add_argument("--password", required=True, help="Source MySQL password")
return parser
def _add_apply_parser(subparsers):
parser = subparsers.add_parser("apply", help="Apply metadata to target cluster.")
parser.add_argument(
"--apply-from",
required=True,
help="Directory or JSON file exported by this script.",
)
parser.add_argument("--host", help="Fallback target host if --target-host omitted")
parser.add_argument("--port", type=int, default=9030)
parser.add_argument("--user")
parser.add_argument("--password")
return parser
def _add_pipeline_parser(subparsers):
parser = subparsers.add_parser(
"pipeline", help="Export from source and immediately apply to target."
)
parser.add_argument("--host", required=True, help="Source FE MySQL host")
parser.add_argument("--port", type=int, default=9030, help="Source FE MySQL port")
parser.add_argument("--user", required=True, help="Source MySQL user")
parser.add_argument("--password", required=True, help="Source MySQL password")
return parser
def inline_apply_requested(args: argparse.Namespace) -> bool:
if args.apply_from:
return False
target_flags = ("target_host", "target_port", "target_user", "target_password")
return any(getattr(args, flag) is not None for flag in target_flags)
def resolve_target_connection(
args: argparse.Namespace,
) -> Tuple[Optional[str], Optional[int], Optional[str], Optional[str]]:
return (
args.target_host or args.host,
args.target_port or args.port,
args.target_user or args.user,
args.target_password or args.password,
)
def missing_target_options(args: argparse.Namespace) -> List[str]:
host, _, user, password = resolve_target_connection(args)
return [
name
for name, value in (
("target-host", host),
("target-user", user),
("target-password", password),
)
if not value
]
def create_connection(
host: str, port: int, user: str, password: str
) -> MySQLConnection:
return mysql.connector.connect(
host=host,
port=port,
user=user,
password=password,
autocommit=True,
)
def list_databases(
conn: MySQLConnection, include: Optional[List[str]], exclude: List[str]
) -> List[str]:
cursor = conn.cursor()
sql = "SELECT schema_name FROM information_schema.schemata"
filters = []
params: List[str] = []
if include:
placeholders = ",".join(["%s"] * len(include))
filters.append(f"schema_name IN ({placeholders})")
params.extend(include)
if exclude:
placeholders = ",".join(["%s"] * len(exclude))
filters.append(f"schema_name NOT IN ({placeholders})")
params.extend(exclude)
if filters:
sql += " WHERE " + " AND ".join(filters)
sql += " ORDER BY schema_name"
cursor.execute(sql, params)
rows = [row[0] for row in cursor.fetchall()]
cursor.close()
return rows
def fetch_tables(conn: MySQLConnection, databases: List[str]) -> List[Dict]:
if not databases:
return []
cursor = conn.cursor(dictionary=True)
placeholders = ",".join(["%s"] * len(databases))
sql = f"""
SELECT table_schema, table_name, table_type, engine, create_time,
update_time, table_rows, data_length, index_length, table_comment
FROM information_schema.tables
WHERE table_schema IN ({placeholders})
ORDER BY table_schema, table_name
"""
cursor.execute(sql, databases)
tables = cursor.fetchall()
cursor.close()
return tables
def fetch_columns(conn: MySQLConnection, databases: List[str]) -> Dict[str, List[Dict]]:
if not databases:
return {}
cursor = conn.cursor(dictionary=True)
placeholders = ",".join(["%s"] * len(databases))
sql = f"""
SELECT table_schema, table_name, column_name, ordinal_position,
column_type, data_type, character_set_name, collation_name,
is_nullable, column_default, column_key, extra, column_comment
FROM information_schema.columns
WHERE table_schema IN ({placeholders})
ORDER BY table_schema, table_name, ordinal_position
"""
cursor.execute(sql, databases)
columns: Dict[str, List[Dict]] = {}
for row in cursor.fetchall():
key = f"{row['table_schema']}.{row['table_name']}"
columns.setdefault(key, []).append(row)
cursor.close()
return columns
def quote_identifier(identifier: str) -> str:
return f"`{identifier.replace('`', '``')}`"
def _escape_single_quotes(value: str) -> str:
return value.replace("'", "''")
def fetch_show_create(
conn: MySQLConnection, table_schema: str, table_name: str
) -> Optional[str]:
cursor = conn.cursor()
stmt = f"SHOW CREATE TABLE {quote_identifier(table_schema)}.{quote_identifier(table_name)}"
try:
cursor.execute(stmt)
except mysql.connector.Error:
cursor.close()
return None
row = cursor.fetchone()
cursor.close()
if not row:
return None
return row[1] if len(row) > 1 else row[0]
def fetch_show_create_materialized_view(
conn: MySQLConnection, table_schema: str, table_name: str, view_name: str
) -> Optional[str]:
cursor = conn.cursor()
previous_db: Optional[str] = None
try:
cursor.execute("SELECT DATABASE()")
row = cursor.fetchone()
previous_db = row[0] if row and row[0] else None
except mysql.connector.Error:
previous_db = None
stmt = (
f"SHOW CREATE MATERIALIZED VIEW {quote_identifier(view_name)} "
f"ON {quote_identifier(table_name)}"
)
try:
cursor.execute(f"USE {quote_identifier(table_schema)}")
cursor.execute(stmt)
except mysql.connector.Error:
cursor.close()
return None
row = cursor.fetchone()
if previous_db and previous_db != table_schema:
try:
cursor.execute(f"USE {quote_identifier(previous_db)}")
except mysql.connector.Error:
pass
elif previous_db is None:
try:
cursor.execute("USE information_schema")
except mysql.connector.Error:
pass
cursor.close()
if not row:
return None
# SHOW CREATE MV returns columns (TableName, ViewName, CreateStmt)
return row[-1]
def fetch_materialized_views(
conn: MySQLConnection, tables: List[Dict]
) -> Tuple[Dict[str, List[Dict]], Set[str]]:
tables_by_schema: Dict[str, List[str]] = {}
for tbl in tables:
tables_by_schema.setdefault(tbl["table_schema"], []).append(tbl["table_name"])
async_info_by_schema: Dict[str, Dict[str, Dict[str, str]]] = {}
skip_tables: Set[str] = set()
for schema in tables_by_schema:
info = _fetch_async_mv_info(conn, schema)
if info is None:
info = {}
async_info_by_schema[schema] = info
for name in info:
skip_tables.add(f"{schema}.{name}")
rollups_by_schema: Dict[str, Dict[str, List[str]]] = {}
for schema in tables_by_schema:
rollups_by_schema[schema] = _fetch_rollups_for_schema(conn, schema)
materialized: Dict[str, List[Dict]] = {}
for tbl in tables:
schema = tbl["table_schema"]
table = tbl["table_name"]
key = f"{schema}.{table}"
async_info = async_info_by_schema.get(schema, {})
rollups = set(rollups_by_schema.get(schema, {}).get(table, []))
index_columns = _get_table_indexes(conn, schema, table)
names: Set[str] = set(index_columns.keys())
names.update(_show_materialized_view_names(conn, schema, table))
if table in names:
names.remove(table)
names.update(rollups)
names.update(async_info.keys())
if not names:
continue
entries: List[Dict] = []
for name in sorted(names):
metadata = async_info.get(name)
if metadata:
skip_tables.add(f"{schema}.{name}")
entry = _build_materialized_view_entry(
conn,
schema,
table,
name,
metadata,
index_columns.get(name),
)
if entry:
entries.append(entry)
if entries:
materialized[key] = entries
return materialized, skip_tables
def _build_materialized_view_entry(
conn: MySQLConnection,
schema: str,
table: str,
name: str,
async_metadata: Optional[Dict[str, str]],
columns: Optional[List[str]],
) -> Optional[Dict[str, str]]:
definition = _resolve_materialized_view_definition(
conn, schema, table, name, async_metadata, columns
)
if not definition:
return None
entry: Dict[str, str] = {"name": name, "definition": definition}
if async_metadata:
if async_metadata.get("State"):
entry["state"] = async_metadata["State"]
if async_metadata.get("RefreshState"):
entry["refresh_state"] = async_metadata["RefreshState"]
if async_metadata.get("RefreshInfo"):
entry["refresh_info"] = async_metadata["RefreshInfo"]
return entry
def _resolve_materialized_view_definition(
conn: MySQLConnection,
schema: str,
table: str,
name: str,
async_metadata: Optional[Dict[str, str]],
columns: Optional[List[str]],
) -> Optional[str]:
ddl = fetch_show_create_materialized_view(conn, schema, table, name)
if ddl:
return ddl
if columns:
table_ref = f"{quote_identifier(schema)}.{quote_identifier(table)}"
columns_sql = ", ".join(quote_identifier(col) for col in columns)
return (
f"ALTER TABLE {table_ref} ADD ROLLUP {quote_identifier(name)} "
f"({columns_sql})"
)
if async_metadata:
query_sql = async_metadata.get("QuerySql")
if query_sql:
refresh_info = async_metadata.get("RefreshInfo")
build_clause = f"{refresh_info}\n" if refresh_info else ""
return (
f"CREATE MATERIALIZED VIEW {quote_identifier(name)} "
f"{build_clause}AS \n{query_sql}"
)
return None
def _fetch_async_mv_info(
conn: MySQLConnection, schema: str
) -> Optional[Dict[str, Dict[str, str]]]:
stmt = f"SELECT * FROM mv_infos('database'='{_escape_single_quotes(schema)}')"
cursor = conn.cursor(dictionary=True)
try:
cursor.execute(stmt)
except mysql.connector.Error:
cursor.close()
return None
info: Dict[str, Dict[str, str]] = {}
for row in cursor.fetchall():
name = row.get("Name")
if not name:
continue
info[name] = {
"State": row.get("State", ""),
"RefreshState": row.get("RefreshState", ""),
"RefreshInfo": row.get("RefreshInfo", ""),
"QuerySql": row.get("QuerySql", ""),
}
cursor.close()
return info
def _fetch_rollups_for_schema(
conn: MySQLConnection, schema: str
) -> Dict[str, List[str]]:
cursor = conn.cursor(dictionary=True)
try:
cursor.execute(
f"SHOW ALTER TABLE MATERIALIZED VIEW FROM {quote_identifier(schema)}"
)
except mysql.connector.Error:
cursor.close()
return {}
mapping: Dict[str, Set[str]] = {}
for row in cursor.fetchall():
table = row.get("TableName")
rollup = row.get("RollupIndexName")
if table and rollup:
mapping.setdefault(table, set()).add(rollup)
cursor.close()
return {table: sorted(names) for table, names in mapping.items()}
def _show_materialized_view_names(
conn: MySQLConnection, database: str, table: str
) -> Set[str]:
names: Set[str] = set()
cursor = conn.cursor()
try:
for keyword in ("MATERIALIZED VIEWS", "MATERIALIZED VIEW"):
stmt = (
f"SHOW {keyword} FROM {quote_identifier(database)}."
f"{quote_identifier(table)}"
)
try:
cursor.execute(stmt)
except mysql.connector.Error:
continue
rows = cursor.fetchall()
for row in rows or []:
view_name = None
if isinstance(row, dict):
view_name = (
row.get("ViewName")
or row.get("MVName")
or row.get("MaterializedViewName")
)
elif row:
view_name = row[0]
if view_name:
names.add(view_name)
if names:
break
except mysql.connector.Error:
pass
finally:
cursor.close()
return names
def _get_table_indexes(
conn: MySQLConnection, schema: str, table: str
) -> Dict[str, List[str]]:
cursor = conn.cursor(dictionary=True)
cursor.execute(f"DESC {quote_identifier(schema)}.{quote_identifier(table)} ALL")
indexes: Dict[str, List[str]] = {}
for row in cursor.fetchall():
index_name = row.get("IndexName") or row.get("INDEX_NAME")
column = row.get("Field") or row.get("COLUMN_NAME")
if not index_name or not column:
continue
indexes.setdefault(index_name, []).append(column)
cursor.close()
return indexes
def build_table_metadata(
tables: List[Dict],
columns_map: Dict[str, List[Dict]],
materialized_views_map: Dict[str, List[Dict]],
skip_tables: Set[str],
conn: MySQLConnection,
) -> List[Dict]:
results: List[Dict] = []
for tbl in tables:
key = f"{tbl['table_schema']}.{tbl['table_name']}"
if key in skip_tables:
continue
metadata = {
"database": tbl["table_schema"],
"table": tbl["table_name"],
"table_type": tbl["table_type"],
"engine": tbl["engine"],
"create_time": _format_datetime(tbl["create_time"]),
"update_time": _format_datetime(tbl["update_time"]),
"table_rows": tbl["table_rows"],
"data_length": tbl["data_length"],
"index_length": tbl["index_length"],
"table_comment": tbl["table_comment"],
"columns": columns_map.get(key, []),
}
show_create = fetch_show_create(conn, tbl["table_schema"], tbl["table_name"])
if show_create:
metadata["show_create"] = show_create
mviews = materialized_views_map.get(key)
if mviews:
metadata["materialized_views"] = mviews
results.append(metadata)
return results
def _format_datetime(value):
if value is None:
return None
if isinstance(value, dt.datetime):
return value.isoformat()
return str(value)
def write_output(
metadata: List[Dict],
output_dir: pathlib.Path,
) -> None:
output_dir.mkdir(parents=True, exist_ok=True)
path = output_dir / "tables_metadata.json"
path.write_text(json.dumps(metadata, indent=2, ensure_ascii=False))
def main() -> int:
args = parse_args()
if args.command == "export":
return export_only(args)
if args.command == "apply":
return apply_only(args)
if args.command == "pipeline":
return export_and_apply(args)
print(f"Unknown command: {args.command}", file=sys.stderr)
return 1
def export_only(args: argparse.Namespace) -> int:
exit_code, _ = export_metadata(args)
return exit_code
def apply_only(args: argparse.Namespace) -> int:
namespace = argparse.Namespace(
apply_from=args.apply_from,
target_host=args.target_host or args.host,
target_port=args.target_port,
target_user=args.target_user or args.user,
target_password=args.target_password or args.password,
skip_existing=args.skip_existing,
dry_run=args.dry_run,
no_create_databases=args.no_create_databases,
)
return apply_metadata(namespace)
def export_and_apply(args: argparse.Namespace) -> int:
exit_code, snapshot_dir = export_metadata(args)
if exit_code != 0:
return exit_code
if snapshot_dir is None:
print(
"Inline apply requested but snapshot directory is unavailable.",
file=sys.stderr,
)
return 1
namespace = argparse.Namespace(
apply_from=str(snapshot_dir),
target_host=args.target_host,
target_port=args.target_port,
target_user=args.target_user,
target_password=args.target_password,
skip_existing=args.skip_existing,
dry_run=args.dry_run,
no_create_databases=args.no_create_databases,
)
return apply_metadata(namespace)
def export_metadata(args: argparse.Namespace) -> Tuple[int, Optional[pathlib.Path]]:
missing = [opt for opt in ("host", "user", "password") if not getattr(args, opt)]
if missing:
print(
f"Missing required source connection options for export: {', '.join('--' + m for m in missing)}",
file=sys.stderr,
)
return 1, None
snapshot_id = args.snapshot_id or dt.datetime.utcnow().strftime("%Y%m%dT%H%M%SZ")
output_dir = pathlib.Path(args.output_dir) / snapshot_id
include = (
[db.strip() for db in args.include_dbs.split(",") if db.strip()]
if args.include_dbs
else None
)
exclude = [db.strip() for db in args.exclude_dbs.split(",") if db.strip()]
conn = create_connection(args.host, args.port, args.user, args.password)
try:
dbs = list_databases(conn, include, exclude)
if not dbs:
print("No databases matched filters.", file=sys.stderr)
return 1, None
tables = fetch_tables(conn, dbs)
columns_map = fetch_columns(conn, dbs)
materialized_views_map, skip_tables = fetch_materialized_views(conn, tables)
metadata = build_table_metadata(
tables, columns_map, materialized_views_map, skip_tables, conn
)
write_output(metadata, output_dir)
print(
f"Exported {len(metadata)} tables from {len(set(t['database'] for t in metadata))} databases "
f"to {output_dir}"
)
finally:
conn.close()
return 0, output_dir
def apply_metadata(
args: argparse.Namespace, metadata_path: Optional[pathlib.Path] = None
) -> int:
if metadata_path is None:
if not args.apply_from:
print("Missing --apply-from path for apply mode.", file=sys.stderr)
return 1
metadata_path = pathlib.Path(args.apply_from)
else:
metadata_path = pathlib.Path(metadata_path)
if not metadata_path.exists():
print(f"Metadata path not found: {metadata_path}", file=sys.stderr)
return 1
metadata = load_metadata(metadata_path)
if not metadata:
print("No table metadata found to apply.", file=sys.stderr)
return 1
target_host, target_port, target_user, target_password = resolve_target_connection(
args
)
missing = missing_target_options(args)
if missing:
print(
"Missing target connection options: "
+ ", ".join(f"--{name}" for name in missing),
file=sys.stderr,
)
return 1
conn = create_connection(target_host, target_port, target_user, target_password)
try:
applied, skipped, failed = replay_tables(
conn,
metadata,
create_databases=not args.no_create_databases,
skip_existing=args.skip_existing,
dry_run=args.dry_run,
)
finally:
conn.close()
print(
f"Apply summary: created {applied} tables, skipped {skipped}, failed {failed} "
f"(source objects: {len(metadata)})"
)
return 0 if failed == 0 else 2
def load_metadata(path: pathlib.Path) -> List[Dict]:
if path.is_file():
return normalize_payload(json.loads(path.read_text()))
tables_metadata = path / "tables_metadata.json"
if tables_metadata.exists():
return normalize_payload(json.loads(tables_metadata.read_text()))
print(
f"Unable to locate metadata files under {path}. Expecting tables_metadata.json",
file=sys.stderr,
)
return []
def normalize_payload(payload) -> List[Dict]:
if isinstance(payload, dict):
return [payload]
if isinstance(payload, list):
# ensure dictionaries and sort by database/table for deterministic order
rows = [row for row in payload if isinstance(row, dict)]
return sorted(rows, key=lambda r: (r.get("database", ""), r.get("table", "")))
print("Unsupported metadata payload structure.", file=sys.stderr)
return []
def replay_tables(
conn: MySQLConnection,
metadata: Iterable[Dict],
create_databases: bool,
skip_existing: bool,
dry_run: bool,
) -> Tuple[int, int, int]:
applied = skipped = failed = 0
current_db: Optional[str] = None
cursor = conn.cursor()
pending_mvs: List[Tuple[str, str, Dict]] = []
seen_mv_keys: Set[Tuple[str, str]] = set()
for item in metadata:
database = item.get("database")
table = item.get("table")
ddl = item.get("show_create")
if not database or not table or not ddl:
print(
f"Skipping invalid entry (database/table/DDL missing): {item}",
file=sys.stderr,
)
skipped += 1
continue
if create_databases and not dry_run:
ensure_database(conn, database)
if skip_existing and table_exists(conn, database, table):
print(f"Skip existing table {database}.{table}")
skipped += 1
continue
try:
if dry_run:
print(f"-- DRY RUN create {database}.{table} --\n{ddl}\n")
else:
current_db = ensure_use_database(cursor, database, current_db)
cursor.execute(ddl)
applied += 1
except mysql.connector.Error as exc:
failed += 1
print(
f"Failed to create {database}.{table}: {exc}",
file=sys.stderr,
)
continue
for mv in item.get("materialized_views", []) or []:
key = (database, mv.get("name"))
if not key[1] or key in seen_mv_keys:
continue
seen_mv_keys.add(key)
pending_mvs.append((database, table, mv))
mv_failed = replay_pending_materialized_views(cursor, pending_mvs, dry_run)
failed += mv_failed
cursor.close()
return applied, skipped, failed
def ensure_database(conn: MySQLConnection, database: str) -> None:
cursor = conn.cursor()
cursor.execute(f"CREATE DATABASE IF NOT EXISTS {quote_identifier(database)}")
cursor.close()
def ensure_use_database(
cursor: MySQLCursor, database: str, current_db: Optional[str]
) -> Optional[str]:
if current_db != database:
cursor.execute(f"USE {quote_identifier(database)}")
return database
return current_db
def table_exists(conn: MySQLConnection, database: str, table: str) -> bool:
cursor = conn.cursor()
cursor.execute(
"""
SELECT 1 FROM information_schema.tables
WHERE table_schema=%s AND table_name=%s
LIMIT 1
""",
(database, table),
)
exists = cursor.fetchone() is not None
cursor.close()
return exists
def replay_pending_materialized_views(
cursor: MySQLCursor,
pending: List[Tuple[str, str, Dict]],
dry_run: bool,
) -> int:
if not pending:
return 0
failures = 0
current_db: Optional[str] = None
for database, table, mv in pending:
name = mv.get("name")
ddl = mv.get("definition")
label = f"{database}.{table}.{name or '<unknown>'}"
if not ddl:
print(
f"Skipping materialized view {label}: missing definition",
file=sys.stderr,
)
failures += 1
continue
try:
if dry_run:
print(f"-- DRY RUN create materialized view {label} --\n{ddl}\n")
else:
current_db = ensure_use_database(cursor, database, current_db)
cursor.execute(ddl)
print(f"Created materialized view {label}")
except mysql.connector.Error as exc:
print(f"Failed to create materialized view {label}: {exc}", file=sys.stderr)
failures += 1
return failures
if __name__ == "__main__":
sys.exit(main())
5.3 privilege_metadata.py
5.3.1 Prerequisites for Script Execution
pip3 install mysql-connector-python
5.3.2 Script Content
#!/usr/bin/env python3
"""
Export and apply Doris privilege metadata (users/roles/grants).
"""
import argparse
import json
import pathlib
import sys
from typing import Dict, List, Optional, Tuple
import mysql.connector
from mysql.connector.connection import MySQLConnection
RESERVED_ROLES = {"admin", "operator"}
def parse_args() -> argparse.Namespace:
parser = argparse.ArgumentParser(
description="Export/apply Doris privilege metadata (roles, users, grants)."
)
subparsers = parser.add_subparsers(dest="command", required=True)
export_parser = subparsers.add_parser("export", help="Export privilege metadata.")
_add_source_args(export_parser)
export_parser.add_argument(
"--output",
default="privileges_metadata.json",
help="Path to write JSON output (default: privileges_metadata.json).",
)
apply_parser = subparsers.add_parser("apply", help="Apply privilege metadata.")
apply_parser.add_argument(
"--input",
required=True,
help="JSON file generated by the export command.",
)
_add_target_args(apply_parser)
apply_parser.add_argument(
"--create-missing-users",
action="store_true",
help="Create users automatically if they do not exist on target.",
)
apply_parser.add_argument(
"--default-password",
help="Password to use when creating missing users (if not provided, creation is skipped).",
)
pipeline_parser = subparsers.add_parser(
"pipeline", help="Export from source and immediately apply to target."
)
_add_source_args(pipeline_parser)
_add_target_args(pipeline_parser)
pipeline_parser.add_argument(
"--output",
help="Optional path to also write exported JSON.",
)
pipeline_parser.add_argument(
"--create-missing-users",
action="store_true",
help="Create users automatically if they do not exist on target.",
)
pipeline_parser.add_argument(
"--default-password",
help="Password to use when creating missing users (if not provided, creation is skipped).",
)
return parser.parse_args()
def _add_source_args(parser: argparse.ArgumentParser) -> None:
parser.add_argument("--host", required=True, help="Source FE MySQL host")
parser.add_argument("--port", type=int, default=9030, help="Source FE MySQL port")
parser.add_argument("--user", required=True, help="Source MySQL user")
parser.add_argument("--password", required=True, help="Source MySQL password")
def _add_target_args(parser: argparse.ArgumentParser) -> None:
parser.add_argument("--target-host", required=True, help="Target FE MySQL host")
parser.add_argument(
"--target-port", type=int, default=9030, help="Target FE MySQL port"
)
parser.add_argument("--target-user", required=True, help="Target MySQL user")
parser.add_argument(
"--target-password", required=True, help="Target MySQL password"
)
def main() -> int:
args = parse_args()
if args.command == "export":
return export_command(args)
if args.command == "apply":
return apply_command(args)
if args.command == "pipeline":
return pipeline_command(args)
print(f"Unknown command: {args.command}", file=sys.stderr)
return 1
def export_command(args: argparse.Namespace) -> int:
conn = create_connection(args.host, args.port, args.user, args.password)
try:
metadata = collect_privilege_metadata(conn)
finally:
conn.close()
output_path = pathlib.Path(args.output)
output_path.write_text(json.dumps(metadata, indent=2, ensure_ascii=False))
print(f"Exported privilege metadata to {output_path}")
return 0
def apply_command(args: argparse.Namespace) -> int:
metadata = json.loads(pathlib.Path(args.input).read_text())
return apply_privilege_metadata(
metadata,
args.target_host,
args.target_port,
args.target_user,
args.target_password,
args.create_missing_users,
args.default_password,
)
def pipeline_command(args: argparse.Namespace) -> int:
source_conn = create_connection(args.host, args.port, args.user, args.password)
try:
metadata = collect_privilege_metadata(source_conn)
finally:
source_conn.close()
if args.output:
pathlib.Path(args.output).write_text(json.dumps(metadata, indent=2, ensure_ascii=False))
print(f"Exported privilege metadata to {args.output}")
return apply_privilege_metadata(
metadata,
args.target_host,
args.target_port,
args.target_user,
args.target_password,
args.create_missing_users,
args.default_password,
)
def create_connection(host: str, port: int, user: str, password: str) -> MySQLConnection:
return mysql.connector.connect(
host=host,
port=port,
user=user,
password=password,
autocommit=True,
)
def collect_privilege_metadata(conn: MySQLConnection) -> Dict:
cursor = conn.cursor(dictionary=True)
cursor.execute("SHOW ALL GRANTS")
rows = cursor.fetchall()
cursor.close()
users: Dict[str, Dict] = {}
roles: Dict[str, Dict] = {}
for row in rows:
identity = row["UserIdentity"]
role_list = _parse_roles(row.get("Roles"))
user_entry = users.setdefault(
identity,
{
"identity": identity,
"comment": row.get("Comment"),
"global_privs": row.get("GlobalPrivs"),
"catalog_privs": row.get("CatalogPrivs"),
"database_privs": row.get("DatabasePrivs"),
"table_privs": row.get("TablePrivs"),
"resource_privs": row.get("ResourcePrivs"),
"role_list": [],
},
)
user_entry["role_list"] = role_list
for role in role_list:
role_entry = roles.setdefault(role, {"name": role, "members": []})
role_entry["members"].append(identity)
return {
"users": list(users.values()),
"roles": list(roles.values()),
}
def _parse_roles(value: Optional[str]) -> List[str]:
if not value:
return []
return [role.strip() for role in value.split(",") if role.strip()]
def apply_privilege_metadata(
metadata: Dict,
host: str,
port: int,
user: str,
password: str,
create_missing_users: bool,
default_password: Optional[str],
) -> int:
conn = create_connection(host, port, user, password)
cursor = conn.cursor()
failures = 0
# Ensure roles exist
for role in metadata.get("roles", []):
name = role.get("name")
if not name:
continue
lower_name = name.lower()
if lower_name in RESERVED_ROLES:
print(f"[role] skip reserved role {name}")
continue
role_identifier = quote_identifier(name)
try:
cursor.execute(f"CREATE ROLE IF NOT EXISTS {role_identifier}")
print(f"[role] ensured {name}")
except mysql.connector.Error as exc:
print(f"[ERROR] Failed to create role {name}: {exc}", file=sys.stderr)
failures += 1
# Apply privileges via SHOW ALL GRANTS data
for user_entry in metadata.get("users", []):
identity = user_entry.get("identity")
if not identity:
continue
username, hostpart = _parse_identity(identity)
if not _user_exists(cursor, username, hostpart):
if create_missing_users and default_password:
try:
cursor.execute(
f"CREATE USER {quote_user(username, hostpart)} IDENTIFIED BY %s",
(default_password,),
)
print(f"[user] created '{username}'@'{hostpart}'")
except mysql.connector.Error as exc:
print(f"[ERROR] Failed to create user {identity}: {exc}", file=sys.stderr)
failures += 1
continue
else:
if create_missing_users and not default_password:
print(
"[WARN] --create-missing-users provided but --default-password missing; "
f"user {identity} skipped.",
file=sys.stderr,
)
else:
print(
f"[WARN] User {identity} missing on target. "
"Use --create-missing-users with --default-password to auto-create.",
file=sys.stderr,
)
print(
f"[INFO] Skipping grants for {identity} until user exists.",
)
continue
for role_name in user_entry.get("role_list", []):
if role_name.lower() in RESERVED_ROLES:
print(f"[grant] skip reserved role {role_name} for {identity}")
continue
role_literal = quote_role(role_name)
try:
cursor.execute(f"GRANT {role_literal} TO {quote_user(username, hostpart)}")
print(f"[grant] {role_name} -> {identity}")
except mysql.connector.Error as exc:
print(
f"[ERROR] Failed to grant role {role_name} to {identity}: {exc}",
file=sys.stderr,
)
failures += 1
cursor.close()
conn.close()
return 0 if failures == 0 else 2
def _parse_identity(identity: str) -> Tuple[str, str]:
if "@" not in identity:
return identity.strip("'"), "%"
user_part, host_part = identity.split("@", 1)
return user_part.strip("'"), host_part.strip("'")
def _user_exists(cursor, username: str, host: str) -> bool:
cursor.execute(
"SELECT 1 FROM mysql.user WHERE User=%s AND Host=%s LIMIT 1",
(username, host),
)
return cursor.fetchone() is not None
def quote_user(user: str, host: str) -> str:
escaped_user = user.replace("'", "''")
escaped_host = host.replace("'", "''")
return f"'{escaped_user}'@'{escaped_host}'"
def quote_identifier(identifier: str) -> str:
return f"`{identifier.replace('`', '``')}`"
def quote_role(role_name: str) -> str:
return "'" + role_name.replace("'", "''") + "'"
if __name__ == "__main__":
sys.exit(main())