RAG with Hybrid Search
VeloDB のハイブリッド検索を使用して RAG (検索-Augmented Generation) アプリケーションを構築します - 転置インデックスと BM25 スコアリングによる全文検索と、ベクトルインデックスによる類似度検索を単一の SQL クエリで組み合わせます。
ベクトルインデックスによるハイブリッド検索は VeloDB 26.x で利用可能です。
構築するもの
このチュートリアルの最後には、インタラクティブな Agno UI を持つ動作する RAG チャットボットが完成します:
ハイブリッド検索の仕組み:
- 全文検索 は完全一致するキーワードを含む文書を見つけます ("Kafka", "streaming")
- 類似度検索 は意味的に類似した文書を見つけます (messaging, events, pipelines)
- RRF fusion は両方のランキングを組み合わせます → 両方のリストに現れる文書が最も高くランクされます
RAG における検索品質の重要性
RAG アプリケーションは関連する文書を取得して LLM の応答にコンテキストを提供します。検索品質が低いと以下につながります:
- 幻覚 - LLM がもっともらしいが不正確な回答を生成する
- 不完全な回答 - 関連するコンテキストの欠如
- 無関係な応答 - 間違った文書が取得される
VeloDB は 3 つの検索方法を単一の SQL クエリで組み合わせることでこの問題を解決します。
3 つの検索方法
1. 全文検索(BM25 スコアリング付き)
最適な用途: 完全一致検索、技術的なクエリ、製品名、コード
-- Create table with inverted index for full-text search
CREATE TABLE documents (
id BIGINT NOT NULL AUTO_INCREMENT,
content TEXT,
INDEX idx_content(content) USING INVERTED PROPERTIES("parser"="english")
) DUPLICATE KEY(id)
DISTRIBUTED BY HASH(id) BUCKETS 1;
-- Insert sample documents
INSERT INTO documents (content) VALUES
('Apache Kafka was first released in 2011 as an open-source distributed event streaming platform.'),
('Michael Faraday discovered electromagnetic induction in 1831.'),
('The International Space Station orbits Earth at 400km altitude.');
-- Full-text search using MATCH
SELECT id, content
FROM documents
WHERE content MATCH 'electromagnetic induction'
LIMIT 5;
Result: 完全に一致するキーワードが含まれているため、Faradayドキュメントを返します。
Limitation: 意味的に関連するコンテンツを見逃します。「electricity discoveries」のクエリは「electromagnetic induction」にマッチしません。
2. Similarity Search (Vector)
最適な用途: 自然言語クエリ、概念マッチング、類似した意味の検索
-- Create table with vector index for similarity search
CREATE TABLE documents_with_vectors (
id BIGINT NOT NULL AUTO_INCREMENT,
content TEXT,
embedding ARRAY<FLOAT>,
INDEX idx_embedding(embedding) USING INVERTED
) DUPLICATE KEY(id)
DISTRIBUTED BY HASH(id) BUCKETS 1;
-- Insert documents with embeddings (simplified 5-dim vectors for demo)
INSERT INTO documents_with_vectors (content, embedding) VALUES
('Apache Kafka was first released in 2011 as an open-source distributed event streaming platform.', [0.8, 0.2, 0.1, 0.5, 0.3]),
('Michael Faraday discovered electromagnetic induction in 1831.', [0.1, 0.9, 0.7, 0.2, 0.4]),
('The International Space Station orbits Earth at 400km altitude.', [0.3, 0.1, 0.2, 0.9, 0.8]);
-- Similarity search: find documents similar to "streaming data" [0.7, 0.3, 0.2, 0.4, 0.2]
SELECT id, content,
1 - cosine_distance(embedding, [0.7, 0.3, 0.2, 0.4, 0.2]) AS similarity
FROM documents_with_vectors
ORDER BY cosine_distance(embedding, [0.7, 0.3, 0.2, 0.4, 0.2]) ASC
LIMIT 5;
結果: キーワードの重複がなくても概念的に類似した文書を見つけることができます。
制限: ユーザーが期待する正確なキーワードマッチを持つ文書を見逃す可能性があります。
3. Hybrid Search (Full-text + Vector + Filter + RRF)
最適用途: 精度と再現率の両方を必要とするRAGアプリケーション
Hybrid searchは**Reciprocal Rank Fusion (RRF)**を使用して全文検索と類似検索を組み合わせます:
-- Create table with BOTH indexes
CREATE TABLE rag_documents (
id BIGINT NOT NULL AUTO_INCREMENT,
content TEXT,
embedding ARRAY<FLOAT>,
-- Vector index for similarity search
INDEX idx_embedding(embedding) USING INVERTED,
-- Inverted index for full-text search
INDEX idx_content(content) USING INVERTED PROPERTIES("parser"="english")
) DUPLICATE KEY(id)
DISTRIBUTED BY HASH(id) BUCKETS 1
PROPERTIES ("replication_num" = "1");
-- Insert sample documents with embeddings (simplified 5-dim vectors for demo)
INSERT INTO rag_documents (content, embedding) VALUES
('Apache Kafka was first released in 2011 as an open-source distributed event streaming platform.', [0.8, 0.2, 0.1, 0.5, 0.3]),
('Michael Faraday discovered electromagnetic induction in 1831.', [0.1, 0.9, 0.7, 0.2, 0.4]),
('The International Space Station orbits Earth at 400km altitude.', [0.3, 0.1, 0.2, 0.9, 0.8]);
実際の埋め込みベクトルは通常1536次元を持ちます。DockerデモではOpenAIのtext-embedding-3-smallを使用してプロダクション品質のベクトルを生成します。
RRF融合を使用したハイブリッド検索クエリ:
-- Search for "Kafka streaming" with embedding [0.7, 0.3, 0.2, 0.4, 0.2]
WITH vector_results AS (
-- Similarity search: find conceptually similar documents
SELECT
id, content,
1 - cosine_distance(embedding, [0.7, 0.3, 0.2, 0.4, 0.2]) AS vector_score,
ROW_NUMBER() OVER (ORDER BY cosine_distance(embedding, [0.7, 0.3, 0.2, 0.4, 0.2]) ASC) AS vector_rank
FROM rag_documents
ORDER BY cosine_distance(embedding, [0.7, 0.3, 0.2, 0.4, 0.2]) ASC
LIMIT 10
),
text_results AS (
-- Full-text search: find exact term matches
SELECT
id, content,
1.0 AS text_score,
ROW_NUMBER() OVER (ORDER BY id) AS text_rank
FROM rag_documents
WHERE content MATCH 'Kafka streaming'
LIMIT 10
),
combined AS (
-- Combine results from both methods
SELECT
COALESCE(v.id, t.id) AS id,
COALESCE(v.content, t.content) AS content,
COALESCE(v.vector_score, 0) AS vector_score,
COALESCE(t.text_score, 0) AS text_score,
COALESCE(v.vector_rank, 999) AS vector_rank,
COALESCE(t.text_rank, 999) AS text_rank
FROM vector_results v
FULL OUTER JOIN text_results t ON v.id = t.id
)
-- RRF fusion: combine rankings with 1/(k + rank) formula
SELECT
id, content, vector_score, text_score,
(0.5 / (60 + vector_rank) + 0.5 / (60 + text_rank)) AS hybrid_score
FROM combined
ORDER BY hybrid_score DESC
LIMIT 5;
RRFの動作方法:
- 各検索手法はランク付きリストを生成します
- RRF公式:
score = Σ (weight / (k + rank))ここで k=60 が標準です - 両方のリストに現れる文書はブーストされます
- 一つのリストにのみ現れる文書も寄与します
検索手法の比較
| クエリタイプ | 全文検索 | 類似度検索 | ハイブリッド検索 |
|---|---|---|---|
| "electromagnetic induction" | ✅ 完全一致 | ✅ 概念マッチ | ✅ 両方の利点 |
| "electricity discoveries" | ❌ キーワード一致なし | ✅ Faradayを発見 | ✅ Faradayを発見 |
| "Kafka 2011" | ✅ 完全一致 | ⚠️ ランクが低い可能性 | ✅ トップ結果 |
| "event streaming platforms" | ⚠️ 部分一致 | ✅ 意味的マッチ | ✅ 両方の利点 |
重要な洞察: ハイブリッド検索は、いずれかの手法単独では失敗するケースをカバーします。
完全なRAGアプリケーション
以下はAgnoを使用したインタラクティブなチャットUIを持つ完全なRAGアプリケーションです。
Dockerでのクイックスタート
単一のコマンドで完全なデモを実行します:
docker run -p 3001:3001 -p 7777:7777 \
-e VELODB_HOST=your-cluster.velodb.io \
-e VELODB_USER=admin \
-e VELODB_PASSWORD=your-password \
-e VELODB_DATABASE=rag_demo \
-e OPENROUTER_API_KEY=sk-or-v1-your-key \
velodb/rag-tutorial:1.0
http://localhost:3001 を開いてチャットを開始してください。
これらのクエリを試してください
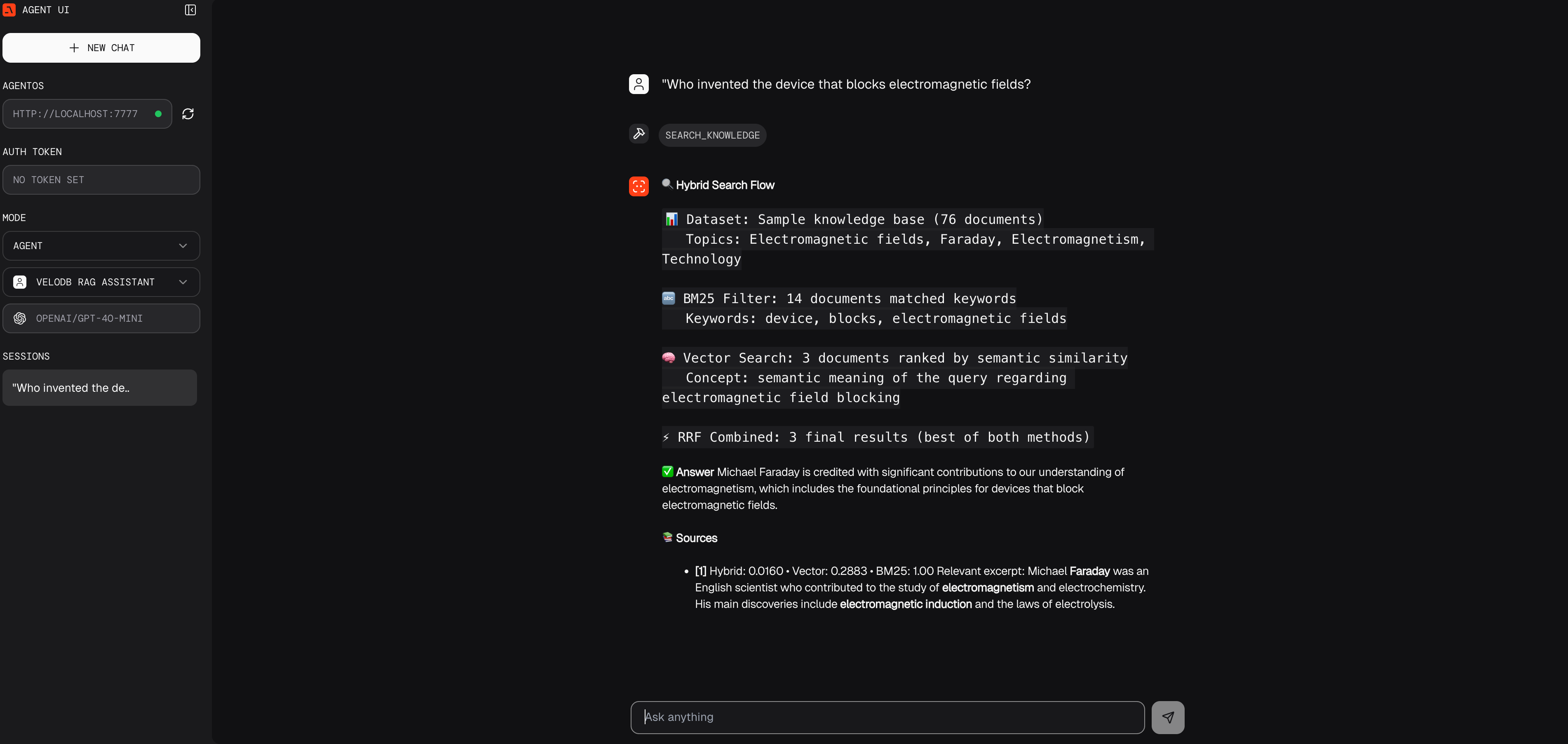
1. ハイブリッド検索をテストする(キーワード + セマンティック)
Who invented the device that blocks electromagnetic fields?
BM25キーワードマッチング("electromagnetic"、"fields")とベクトルセマンティック理解("invented"、"device"、"blocks")を組み合わせてFaradayケージドキュメントを見つける、ハイブリッド検索の動作を確認してください。
2. セマンティック理解をテストする
What streaming platform was created by a social media company?
vector searchがLinkedInをソーシャルメディア会社として理解し、Kafkaドキュメントを見つけていることに注目してください。
3. キーワード精度のテスト
electromagnetic induction
BM25は高い信頼性で正確なキーワードマッチングを提供します。
4. 独自のドキュメントを追加する
Add this to the knowledge base: Apache Kafka is a distributed event streaming platform used for high-performance data pipelines and streaming analytics.
そして次の質問をします:What is Kafka used for?
トラブルシューティング
| 問題 | 解決方法 |
|---|---|
| Connection timeout | VeloDBのホストとポート9030にアクセス可能であることを確認してください |
| Empty search results | 最初にドキュメントが取り込まれていることを確認してください |
| Embedding errors | OpenRouter API keyにクレジットがあることを確認してください |
| MATCH query fails | contentカラムに転置インデックスが存在することを確認してください |