パフォーマンスの背後にある最適化
Apache Dorisの初期バージョンはオンライン分析処理(OLAP)に焦点を当て、主にレポートと集約ワークロード、つまり複数TableのJOINやGROUP BYといった典型的なクエリに対応していました。2.xでは、Dorisは転置インデックスによるテキスト検索を追加し、効率的なJSON処理のためのVariant型を導入しました。3.xでは、ストレージとコンピュートの分離により、オブジェクトストレージを活用してストレージコストを大幅に削減できるようになりました。4.xでは、Dorisはベクトルインデックスとハイブリッド検索(ベクトル + テキスト)を導入することでAI時代に踏み出し、Dorisをエンタープライズ AI アナリティクスプラットフォームとして位置付けています。本ドキュメントでは、Doris 4.xにおけるベクトルインデックスの実装と、最先端のパフォーマンスを達成するための技術的取り組みについて説明します。
ベクトルインデックスを2つの段階に分けて説明します:インデックス作成とクエリです。インデックス作成段階では、1) データシャーディング、2) 高品質インデックスの効率的な構築、3) インデックス管理に焦点を当てます。クエリ段階には単一の目標があります:冗長な計算と不要なIOを排除し、並行性を最適化してクエリパフォーマンスを向上させることです。
インデックス作成段階
インデックス作成のパフォーマンスは、インデックスのハイパーパラメータと強く関連しています:通常、インデックス品質が高いほど構築時間が長くなります。取り込みパスの最適化により、DorisはインデックスのHigh品質を維持しながら取り込みスループットを向上させることができます。
768D 10Mデータセットにおいて、Apache Dorisは業界最先端の取り込みパフォーマンスを実現しています。
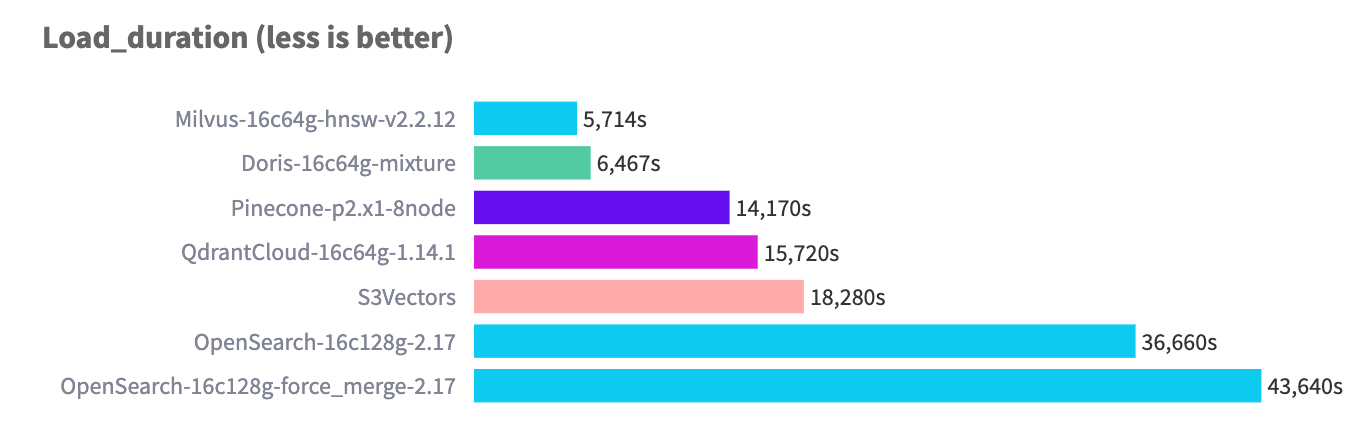
多階層シャーディング
Apache Dorisの内部Tableは本質的に分散されています。クエリと取り込み時に、ユーザーは単一の論理Tableとやり取りし、DorisカーネルがTable定義に基づいて必要な数の物理タブレットを作成します。取り込み時には、データはパーティションキーとバケットキーによって適切なBEタブレットにルーティングされます。複数のタブレットが一緒になって、ユーザーに見える論理Tableを形成します。各取り込みリクエストはトランザクションを形成し、対応するタブレット上にrowset(バージョニング単位)を作成します。各rowsetはいくつかのセグメントを含み、セグメントが実際のデータキャリアです;ANNインデックスはセグメントの粒度で動作します。
ベクトルインデックス(例:HNSW)は、インデックス品質とクエリパフォーマンスを直接決定する主要なハイパーパラメータに依存しており、通常は特定のデータスケールに対してチューニングされます。Apache Dorisの多階層シャーディングは「インデックスパラメータ」を「全Tableデータスケール」から分離します:ユーザーは総データが増加してもインデックスを再構築する必要がなく、バッチあたりの取り込みサイズに基づいてパラメータをチューニングするだけです。テストの結果、異なるバッチサイズでのHNSW推奨パラメータは以下の通りです:
| batch_size | max_degree | ef_construction | ef_search | recall@100 |
|---|---|---|---|---|
| 250000 | 100 | 200 | 50 | 89% |
| 250000 | 100 | 200 | 100 | 93% |
| 250000 | 100 | 200 | 150 | 95% |
| 250000 | 100 | 200 | 200 | 98% |
| 500000 | 120 | 240 | 50 | 91% |
| 500000 | 120 | 240 | 100 | 94% |
| 500000 | 120 | 240 | 150 | 96% |
| 500000 | 120 | 240 | 200 | 99% |
| 1000000 | 150 | 300 | 50 | 90% |
| 1000000 | 150 | 300 | 100 | 93% |
| 1000000 | 150 | 300 | 150 | 96% |
| 1000000 | 150 | 300 | 200 | 98% |
つまり、「バッチあたりの取り込みサイズ」に焦点を当て、適切なインデックスパラメータを選択して品質と安定したクエリ動作を維持することです。
高性能インデックス構築
並列・高品質インデックス構築
Dorisは2つのレベルの並列性でインデックス構築を高速化します:BEノード間のクラスターレベル並列性と、グループ化されたバッチデータでのノード内マルチスレッド距離計算です。速度だけでなく、Dorisはインメモリバッチングによりインデックス品質を向上させます:総ベクトル数が固定されているがバッチングが細かすぎる場合(頻繁な増分構築)、グラフ構造がよりスパースになり再現率が低下します。例えば、768D10Mにおいて、10バッチで構築すると約99%の再現率に達する可能性がありますが、100バッチでは約95%に低下する可能性があります。インメモリバッチングは、同じハイパーパラメータの下でメモリ使用量とグラフ品質のバランスを取り、過度のバッチングによる品質劣化を回避します。
SIMD
ANN インデックス構築における中核的なコストは大規模な距離計算であり、これはCPUバウンドなワークロードです。Dorisはこの作業をBEノードに集約し、C++で実装し、Faissの自動および手動ベクトル化最適化を活用します。L2距離では、FaissはコンパイラプラグマでAuto Vector化を引き起こします:
FAISS_PRAGMA_IMPRECISE_FUNCTION_BEGIN
float fvec_L2sqr(const float* x, const float* y, size_t d) {
size_t i; float res = 0;
FAISS_PRAGMA_IMPRECISE_LOOP
for (i = 0; i < d; i++) {
const float tmp = x[i] - y[i];
res += tmp * tmp;
}
return res;
}
FAISS_PRAGMA_IMPRECISE_FUNCTION_END
FAISS_PRAGMA_IMPRECISE_* を使用すると、コンパイラが自動ベクトル化を行います:
#define FAISS_PRAGMA_IMPRECISE_LOOP \
_Pragma("clang loop vectorize(enable) interleave(enable)")
Faissは#ifdef SSE3/AVX2/AVX512Fブロック内で_mm*/_mm256*/_mm512*を使用した明示的なSIMDも適用し、ElementOpL2/ElementOpIPと次元特化されたfvec_op_ny_D{1,2,4,8,12}と組み合わせて以下を実現します:
- 1回の反復で複数のサンプルを処理し(例:8/16)、レジスタレベルの転置を行ってメモリアクセスの局所性を向上させる
- FMA(例:
_mm512_fmadd_ps)を使用して乗算加算を融合し、命令数を削減する - 水平和を実行してスカラを効率的に生成する
- 非整列サイズに対してマスク読み取りによりテール要素を処理する これらの最適化により命令とメモリのコストが削減され、インデックス作成のスループットが大幅に向上します。
クエリ段階
検索は遅延に敏感です。数千万のレコードと高い同時実行性において、P99遅延は通常500ms未満である必要があり、これによりオプティマイザ、実行エンジン、インデックス実装の基準が高くなります。標準設定でのテストでは、Dorisは主流の専用ベクトルデータベースに匹敵するパフォーマンスに到達します。以下のグラフはPerformance768D10MにおいてDorisを他のシステムと比較したものです。同等データはZillizのオープンソースVectorDBBenchから取得されています。
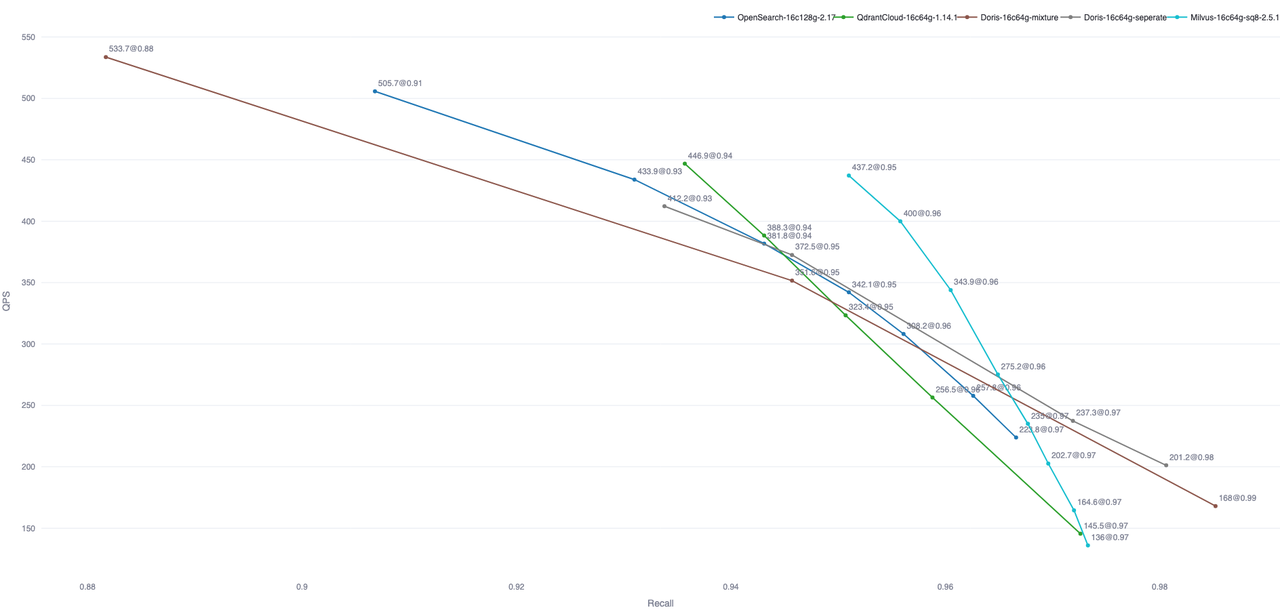
注意:このグラフには標準設定結果の一部が含まれています。OpenSearchとElastic Cloudはインデックスファイル数を最適化することでクエリパフォーマンスを向上させることができます。
Prepare Statement
従来の手法では、DorisはすべてのSQLに対して完全な最適化(構文解析、意味解析、RBO、CBO)を実行します。これは一般的なOLAPには不可欠ですが、シンプルで高度に反復的な検索クエリにとってはオーバーヘッドとなります。Doris 4.0はPrepare Statementをポイント検索を超えてベクトル検索を含むすべてのSQLタイプに拡張します:
- コンパイルと実行の分離
- Prepareは構文解析、意味解析、最適化を1回実行し、再利用可能なLogical Planを生成します。
- Executeは実行時にパラメータをバインドし、事前構築されたプランを実行し、オプティマイザを完全にスキップします。
- プランキャッシュ
- 再利用はSQLフィンガープリント(正規化されたSQL +スキーマバージョン)により決定されます。
- 同じ構造で異なるパラメータ値を持つものはキャッシュされたプランを再利用し、再最適化を回避します。
- スキーマバージョンチェック
- 実行時にスキーマバージョンを検証して正確性を保証します。
- 変更なし→再利用、変更あり→無効化して再準備。
- オプティマイザのスキップによる高速化
- ExecuteはもはやRBO/CBOを実行せず、オプティマイザ時間はほぼ削除されます。
- テンプレート中心のベクトルクエリは大幅に低いエンドツーエンド遅延の恩恵を受けます。
Index Only Scan
Dorisはベクトルインデックスを外部(プラガブル)インデックスとして実装し、これによりマネジメントが簡素化され非同期構築をサポートしますが、冗長な計算とIOの回避などのパフォーマンス課題も導入します。ANNインデックスは行IDに加えて距離を返すことができます。Dorisは「仮想列」を介してScanオペレータ内の距離式をショートサーキットすることでこれを活用し、Ann Index Only Scanは距離関連の読み取りIOを完全に排除します。 単純なフローでは、Scanがインデックスに述語をプッシュし、インデックスが行IDを返し、その後Scanがデータページを読み取り、式を計算してからN行を上流に返します。
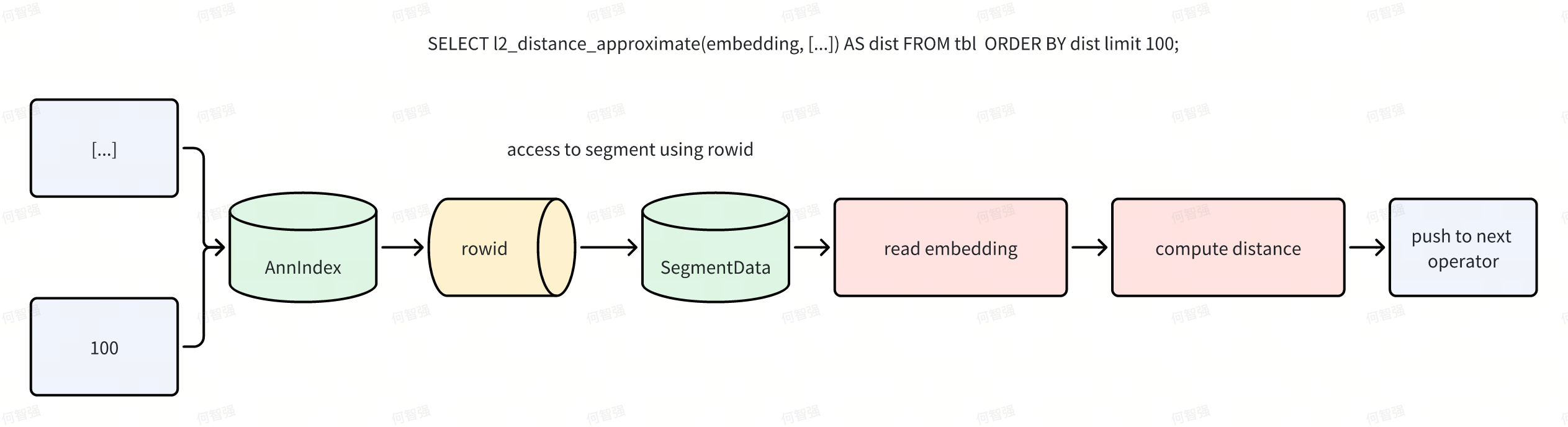
Index Only Scanが適用されると、フローは以下のようになります:
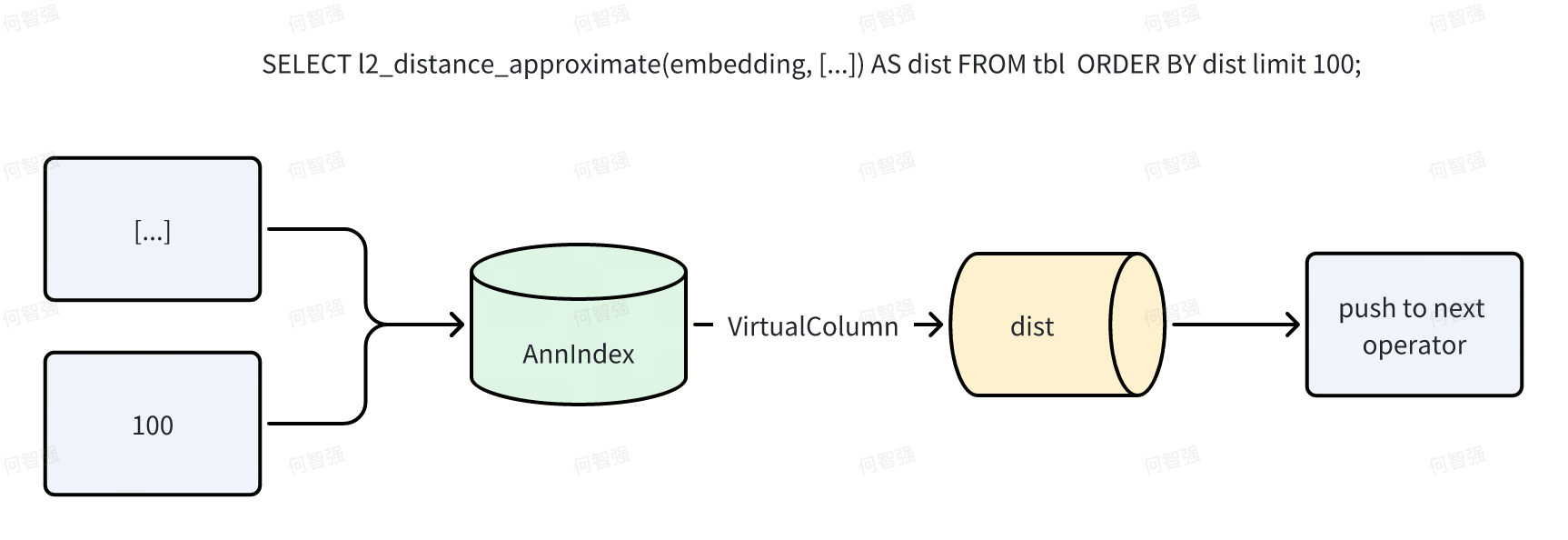
例えば、SELECT l2_distance_approximate(embedding, [...]) AS dist FROM tbl ORDER BY dist LIMIT 100;はデータファイルに触れることなく実行されます。
Ann TopN Search以外にも、Range SearchとCompound Searchは同様の最適化を採用します。Range Searchはより微妙です:インデックスがdistを返すかどうかはコンパレータに依存します。以下はAnn Index Only Scanに関連するクエリタイプとIndex Scanが適用されるかどうかを一覧表示します:
-- Sql1: Range + proj
-- Index returns dist; no need to recompute dist
-- Virtual column for CSE avoids dist recomputation in proj
-- IndexScan: True
select id, dist(embedding, [...]) from tbl where dist <= 10;
-- Sql2: Range + no-proj
-- Index returns dist; no need to recompute
-- IndexScan: True
select id from tbl where dist <= 10 order by id limit N;
-- Sql3: Range + proj + no-dist-from index
-- Index cannot return dist (only updates rowid map)
-- proj requires dist → embedding must be reread
-- IndexScan: False
select id, dist(embedding, [...]) from tbl where dist > 10;
-- Sql4: Range + proj + no-dist-from index
-- Index cannot return dist, but proj does not need dist → embedding not reread
-- IndexScan: True
select id from tbl where dist > 10;
-- Sql5: TopN
-- Index returns dist; virtual slot for CSE uploads dist to proj
-- embedding column not read
-- IndexScan: True
select id[, dist(embedding, [...])] from tbl order by dist(embedding, [...]) asc limit N;
-- Sql6: TopN + IndexFilter
-- 1) comment not read (inverted index already optimizes this)
-- 2) embedding not read (same reason as Sql5)
-- IndexScan: True
select id[, dist(embedding, [...])] from tbl where comment match_any 'olap' ORDER BY dist(embedding, [...]) LIMIT N;
-- Sql7: TopN + Range
-- IndexScan: True (combination of Sql1 and Sql5)
select id[, dist(embedding, [...])] from tbl where dist(embedding, [...]) > 10 order by dist(embedding, [...]) limit N;
-- Sql8: TopN + Range + IndexFilter
-- IndexScan: True (combination of Sql7 and Sql6)
select id[, dist(embedding, [...])] from tbl where comment match_any 'olap' and dist(embedding, [...]) > 10 ORDER BY dist(embedding, [...]) LIMIT N;
-- Sql9: TopN + Range + CommonFilter
-- Key points: 1) dist < 10 (not > 10); 2) common filter reads dist, not embedding
-- Index returns dist; virtual slot for CSE ensures all reads refer to the same column
-- In theory embedding need not materialize; in practice it still does due to residual predicates on the column
-- IndexScan: False
select id[, dist(embedding, [...])] from tbl where comment match_any 'olap' and dist(embedding, [...]) < 10 AND abs(dist(embedding) + 10) > 10 ORDER BY dist(embedding, [...]) LIMIT N;
-- Sql10: Variant of Sql9, dist < 10 → dist > 10
-- Index cannot return embedding; to compute abs(dist(embedding,...)) embedding must materialize
-- IndexScan: False
select id[, dist(embedding, [...])] from tbl where comment match_any 'olap' and dist(embedding, [...]) > 10 AND abs(dist(embedding) + 10) > 10 ORDER BY dist(embedding, [...]) LIMIT N;
-- Sql11: Variant of Sql9, abs(dist(...)+10) > 10 → array_size(embedding) > 10
-- array_size requires embedding materialization
-- IndexScan: False
select id[, dist(embedding, [...])] from tbl where comment match_any 'olap' and dist(embedding, [...]) < 10 AND array_size(embedding) > 10 ORDER BY dist(embedding, [...]) LIMIT N;
CSE用の仮想カラム
Index Only Scanは主にIO(embeddingのランダム読み取り)を排除します。冗長な計算をさらに削除するため、Dorisはインデックスが返すdistを式エンジンにカラムとして渡す仮想カラムを導入しています。
設計のハイライト:
- 式ノード
VirtualSlotRef - カラムイテレータ
VirtualColumnIterator
VirtualSlotRefは計算時生成カラムです:1つの式によってマテリアライズされ、多くの場所で再利用可能で、初回使用時に1度だけ計算され、ProjectionとpredicatesにわたってCSEを排除します。VirtualColumnIteratorはインデックスが返す距離を式にマテリアライズし、繰り返しの距離計算を回避します。当初はANNクエリのCSE排除のために構築されましたが、メカニズムはProjection + Scan + Filterに一般化されました。
ClickBenchデータセットを使用して、以下のクエリはGoogleクリック数による上位20のWebサイトをカウントします:
set experimental_enable_virtual_slot_for_cse=true;
SELECT counterid,
COUNT(*) AS hit_count,
COUNT(DISTINCT userid) AS unique_users
FROM hits
WHERE ( UPPER(regexp_extract(referer, '^https?://([^/]+)', 1)) = 'GOOGLE.COM'
OR UPPER(regexp_extract(referer, '^https?://([^/]+)', 1)) = 'GOOGLE.RU'
OR UPPER(regexp_extract(referer, '^https?://([^/]+)', 1)) LIKE '%GOOGLE%' )
AND ( LENGTH(regexp_extract(referer, '^https?://([^/]+)', 1)) > 3
OR regexp_extract(referer, '^https?://([^/]+)', 1) != ''
OR regexp_extract(referer, '^https?://([^/]+)', 1) IS NOT NULL )
AND eventdate = '2013-07-15'
GROUP BY counterid
HAVING hit_count > 100
ORDER BY hit_count DESC
LIMIT 20;
コア式 regexp_extract(referer, '^https?://([^/]+)', 1) はCPU集約的で、述語間で再利用されます。仮想列を有効にした場合(set experimental_enable_virtual_slot_for_cse=true;):
- 有効: 0.57秒
- 無効: 1.50秒
エンドツーエンドのパフォーマンスは約3倍向上します。
Scan並列性最適化
DorisはAnn TopN検索のScan並列性を刷新しました。元のポリシーでは行数で並列性を設定していました(デフォルト: Scanタスクあたり2,097,152行)。セグメントはサイズベースであるため、高次元ベクトル列はセグメントあたりの行数がはるかに少なくなり、複数のセグメントが1つのScanタスク内で順次スキャンされることになります。Dorisは「セグメントあたり1つのScanタスク」に切り替え、インデックススキャンの並列性を向上させました。Ann TopNは高いフィルタ率(N行のみ返される)を持つため、back-to-tableフェーズはパフォーマンスを損なうことなくシングルスレッドのままにできます。SIFT 1Mにおいて:
set optimize_index_scan_parallelism=true;
TopNシングルスレッドクエリのレイテンシは230msから50msに低下します。
さらに、4.0では動的並列性を導入:各スケジューリングラウンドの前に、Dorisはスレッドプールの負荷に基づいて投入するScanタスク数を調整します—高負荷時にはタスクを削減し、アイドル時には増加—逐次および並行ワークロード間でリソース使用とスケジューリングオーバーヘッドのバランスを取ります。
Global TopN遅延マテリアライゼーション
典型的なAnn TopNクエリは2つのステージで実行されます:
- Scanがインデックスを介してセグメントあたりのTopN距離を取得
- Global sortがセグメントあたりのTopNをマージして最終的なTopNを生成
プロジェクションが多くの列や大きな型(例:String)を返す場合、ステージ1で各セグメントからN行を読み取ると重いIOが発生する可能性があり、多くの行はステージ2のglobal sort中に破棄されます。DorisはglobalTopN遅延マテリアライゼーションによってステージ1のIOを最小化します。
SELECT id, l2_distance_approximate(embedding, [...]) AS dist FROM tbl ORDER BY dist LIMIT 100;の場合:ステージ1はAnn Index Only Scan + 仮想列を介してセグメントあたり100個の dist 値とrowidのみを出力します。Mセグメントがある場合、ステージ2は 100 * M の dist 値をグローバルにソートして最終的なTopNとrowidを取得し、その後Materialize演算子が対応するtablet/rowset/segmentからrowidによって必要な列を取得します。