HNSW
HNSW (Malkov & Yashunin, 2016) は、比較的控えめなリソース消費で高いリコールと低いレイテンシを実現する能力により、高性能オンラインベクトル検索の事実上の標準となっています。Apache Doris 4.x以降、HNSWベースのANNインデックスがサポートされています。本文書では、HNSWアルゴリズム、主要なパラメータ、エンジニアリング手法について説明し、本番環境のDorisクラスターでHNSWベースのANNインデックスを構築・調整する方法を解説します。
HNSWの前に
HNSW(Hierarchical Navigable Small World)アルゴリズムは、論文Efficient and robust approximate nearest neighbor search using Hierarchical Navigable Small World graphsで提案されました。HNSW以前にも、近似k-NN検索のための多くのアルゴリズムが既に提案されていましたが、それぞれに固有の制限がありました。
近接グラフ
このアルゴリズム群の基本的なアイデアは、グラフ内のエントリポイント(ランダムな頂点または何らかのヒューリスティックで選択された頂点)から開始し、グラフを反復的にトラバースすることです。各反復において、アルゴリズムはクエリベクトルと現在のノードのすべての隣接ノード間の距離を計算し、最も近い隣接ノードを次の反復の新しいベースノードとして選択し、現在の最良候補セットを継続的に維持します。特定の停止条件(前回の反復でより近いノードが見つからなかった場合など)が満たされると、アルゴリズムは終了し、候補セット内の上位K個の最近傍ノードが最終結果として返されます。
これらの近接グラフアルゴリズムは、Delaunayグラフの近似と見なすことができます。なぜなら、Delaunayグラフには重要な性質があるからです:貪欲検索は常に最近傍を見つけます。
しかし、このアルゴリズム群には2つの主な問題があります:
- データセットが大きくなるにつれ、ルーティングフェーズの反復数はおよそべき法則に従って増加します。
- 高品質な近接グラフの構築が困難で、局所クラスタとグローバル接続性の低さが非常に一般的です。
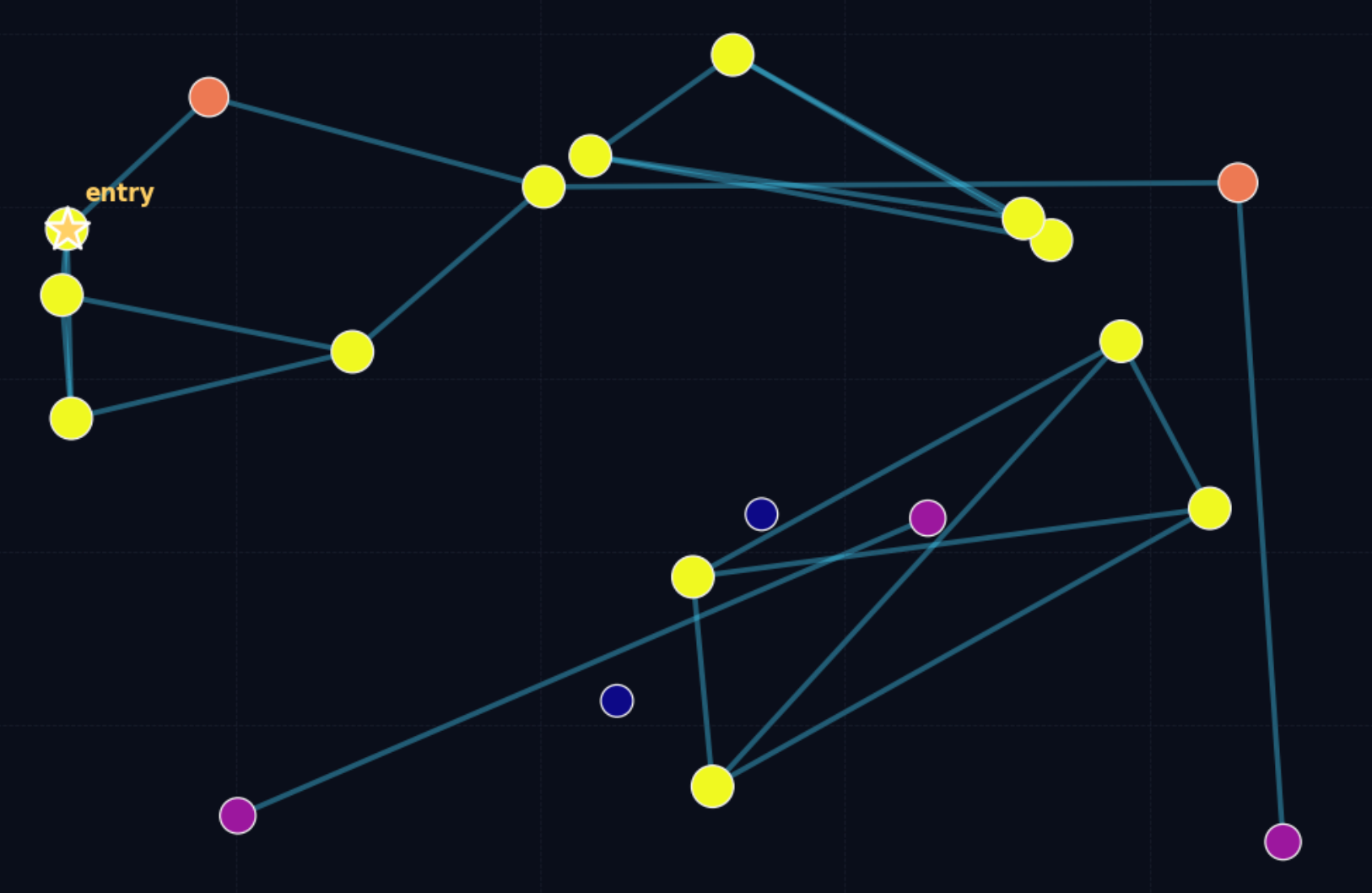
上図は、問題のある近接グラフの形状を直感的に示しています。暗い点は接続性の低いノードを表しており、一部のノードは隣接ノードをほとんど持たないため、検索中に到達することが非常に困難です。
Navigable Small World
上記の問題に対処するため、主に2つのアイデアがあります:
- ハイブリッドアプローチ:まず粗粒度検索を実行してより良いエントリポイントを見つけ、その後近接グラフで貪欲検索を実行します。
- 検索複雑性を制御するために各ノードの最大次数を制限しながら、良好な接続性を維持するnavigable small-world構造を使用します。
NSW(Navigable Small World)は2番目のアイデアを採用しています。
NSWモデルは、社会において人々がどのように繋がっているかを研究する社会実験の一部として、最初にJ. Kleinbergによって提案されました。small-world experiment / six degrees of separationについて聞いたことがあるかもしれません。
k-NNグラフアルゴリズムにおいて、対数または準対数検索複雑性を達成するスモールワールドネットワークは、しばしばNavigable Small World Networkと呼ばれます。多くの具体的な実装がありますが、ここでは詳細は説明しません。
一部のデータセットにおいて、NSWは当時の最先端の検索性能を示しました。しかし、NSWは厳密に対数複雑性を持たないため、特に低次元ベクトル空間において、特定のベンチマークではその性能が最適でない場合があります。
Hierarchical Navigable Small World
NSW検索プロセスは、zoom-outとzoom-inの2つのフェーズで構成されていると見なすことができます。
zoom-out:ランダムに選択された低次数頂点から開始し、より高い次数のノードを優先して検索し、隣接ノードへの平均距離が現在のノードからクエリへの距離を超えるまで続けます。zoom-in:それらの条件下で十分に「高い」ノードが見つかったら、貪欲検索を実行して最終的なTop-N隣接ノードを取得します。
NSWが準対数複雑性を達成する理由は、距離評価の総数が検索中に行われるジャンプ数と訪問されたノードの平均次数の積にほぼ比例するためです。ジャンプ数と平均次数の両方がデータサイズに対してほぼ対数的に増加するため、全体的な準対数複雑性につながります。
HNSWは、zoom-outフェーズを高速化することにより、クエリ時間複雑性を対数に削減します。
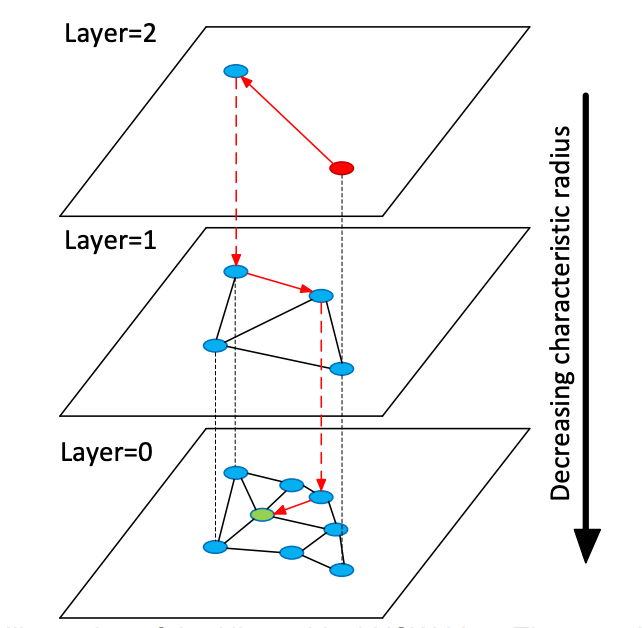
より具体的には、HNSWの「階層」構造は、ノードの特性半径(典型的なエッジ長)に基づいてNSWグラフを複数の層に分割することで得られます。
検索中、HNSWは最上位層のノードをエントリポイントとして選択し、層ごとに貪欲検索を実行します。現在の層で最近傍ノードが見つかると、検索は次の層に降下し、最下位層に到達するまでプロセスを繰り返します。各層のノードの最大次数は制限されており、これにより全体的な時間複雑性を対数に保つのに役立ちます。
この階層構造を構築するため、HNSWは幾何分布に従って各ノードにレベルlを割り当て、構造が高くなりすぎないことを保証します。HNSWは、インデックス作成前のデータシャッフルを必要としません(NSWは必要で、そうでなければグラフ品質が低下する)。これは、ランダムレベル割り当て自体が十分なランダム性を提供するためです。この設計により、HNSWでの効率的な増分更新が可能になります。
Apache DorisにおけるHNSW
Apache Dorisは、バージョン4.0からHNSWベースのANNインデックスの構築をサポートしています。
インデックス構築
ここで使用されるインデックスタイプはANNです。ANNインデックスを作成する方法は2つあります:Table作成時に定義するか、CREATE/BUILD INDEX構文を使用することができます。2つのアプローチは、インデックスがどのように、いつ構築されるかが異なるため、異なるシナリオに適合します。
アプローチ1:Table作成時にベクトル列にANNインデックスを定義します。データがロードされると、セグメントが作成される際に各セグメントに対してANNインデックスが構築されます。利点は、データロードが完了すると、インデックスが既に構築されているため、クエリが即座にそれを使用して高速化できることです。欠点は、同期的なインデックス構築がデータ取り込みを遅くし、コンパクション中に追加のインデックス再構築を引き起こし、リソースの無駄につながる可能性があることです。
CREATE TABLE sift_1M (
id int NOT NULL,
embedding array<float> NOT NULL COMMENT "",
INDEX ann_index (embedding) USING ANN PROPERTIES(
"index_type"="hnsw",
"metric_type"="l2_distance",
"dim"="128"
)
) ENGINE=OLAP
DUPLICATE KEY(id) COMMENT "OLAP"
DISTRIBUTED BY HASH(id) BUCKETS 1
PROPERTIES (
"replication_num" = "1"
);
INSERT INTO sift_1M
SELECT *
FROM S3(
"uri" = "https://selectdb-customers-tools-bj.oss-cn-beijing.aliyuncs.com/sift_database.tsv",
"format" = "csv");
CREATE/BUILD INDEX
アプローチ2: CREATE/BUILD INDEX。
CREATE TABLE sift_1M (
id int NOT NULL,
embedding array<float> NOT NULL COMMENT ""
) ENGINE=OLAP
DUPLICATE KEY(id) COMMENT "OLAP"
DISTRIBUTED BY HASH(id) BUCKETS 1
PROPERTIES (
"replication_num" = "1"
);
INSERT INTO sift_1M
SELECT *
FROM S3(
"uri" = "https://selectdb-customers-tools-bj.oss-cn-beijing.aliyuncs.com/sift_database.tsv",
"format" = "csv");
データがロードされた後、CREATE INDEXを実行できます。この時点でインデックスはTable上で定義されますが、既存のデータに対してはまだインデックスが構築されていません。
CREATE INDEX idx_test_ann ON sift_1M (`embedding`) USING ANN PROPERTIES (
"index_type"="hnsw",
"metric_type"="l2_distance",
"dim"="128"
);
SHOW DATA ALL FROM sift_1M
+-----------+-----------+--------------+----------+----------------+---------------+----------------+-----------------+----------------+-----------------+
| TableName | IndexName | ReplicaCount | RowCount | LocalTotalSize | LocalDataSize | LocalIndexSize | RemoteTotalSize | RemoteDataSize | RemoteIndexSize |
+-----------+-----------+--------------+----------+----------------+---------------+----------------+-----------------+----------------+-----------------+
| sift_1M | sift_1M | 1 | 1000000 | 170.001 MB | 170.001 MB | 0.000 | 0.000 | 0.000 | 0.000 |
| | Total | 1 | | 170.001 MB | 170.001 MB | 0.000 | 0.000 | 0.000 | 0.000 |
+-----------+-----------+--------------+----------+----------------+---------------+----------------+-----------------+----------------+-----------------+
2 rows in set (0.01 sec)
その後、BUILD INDEX文を使用してインデックスを構築できます:
BUILD INDEX idx_test_ann ON sift_1M;
BUILD INDEXは非同期で実行されます。SHOW BUILD INDEX(一部のバージョンではSHOW ALTER)を使用してジョブのステータスを確認できます。
SHOW BUILD INDEX WHERE TableName = "sift_1M";
+---------------+-----------+---------------+------------------------------------------------------------------------------------------------------------------------------------+-------------------------+-------------------------+---------------+----------+------+----------+
| JobId | TableName | PartitionName | AlterInvertedIndexes | CreateTime | FinishTime | TransactionId | State | Msg | Progress |
+---------------+-----------+---------------+------------------------------------------------------------------------------------------------------------------------------------+-------------------------+-------------------------+---------------+----------+------+----------+
| 1763603913428 | sift_1M | sift_1M | [ADD INDEX idx_test_ann (`embedding`) USING ANN PROPERTIES("dim" = "128", "index_type" = "hnsw", "metric_type" = "l2_distance")], | 2025-11-20 11:14:55.253 | 2025-11-20 11:15:10.622 | 126128 | FINISHED | | NULL |
+---------------+-----------+---------------+------------------------------------------------------------------------------------------------------------------------------------+-------------------------+-------------------------+---------------+----------+------+----------+
DROP INDEX
不適切なANNインデックスはALTER TABLE sift_1M DROP INDEX idx_test_annでドロップできます。インデックスのドロップと再作成は、ハイパーパラメータチューニングの際に、望ましいrecallを達成するために異なるパラメータの組み合わせをテストする必要がある場合によく行われます。
クエリ実行
ANNインデックスはTop‑N検索と範囲検索の両方をサポートしています。
ベクトル列が高次元の場合、クエリベクトル自体のリテラル表現が追加の解析オーバーヘッドを発生させる可能性があります。そのため、本番環境、特に高い同時実行性の下では、完全なクエリベクトルを生のSQLに直接埋め込むことは推奨されません。より良い方法は、繰り返しのSQL解析を回避するprepared statementsを使用することです。
prepared statementsに基づいてDorisでのベクトル検索に必要な操作をラップし、Dorisのクエリ結果をPandas DataFrameにマップするデータ変換ユーティリティを含むdoris-vector-searchの使用を推奨します。これにより、下流のAIアプリケーション開発が便利になります。
from doris_vector_search import DorisVectorClient, AuthOptions
auth = AuthOptions(
host="localhost",
query_port=9030,
user="root",
password="",
)
client = DorisVectorClient(database="demo", auth_options=auth)
tbl = client.open_table("sift_1M")
query = [0.1] * 128 # Example 128-dimensional vector
# SELECT id FROM sift_1M ORDER BY l2_distance_approximate(embedding, query) LIMIT 10;
result = tbl.search(query, metric_type="l2_distance").limit(10).select(["id"]).to_pandas()
print(result)
サンプル出力:
id
0 123911
1 11743
2 108584
3 123739
4 73311
5 124746
6 620941
7 124493
8 177392
9 153178
Recall最適化
ベクトル検索において、recallは最も重要な指標です。パフォーマンス数値は、特定のrecallレベルの下でのみ意味を持ちます。recallに影響する主要な要因は以下の通りです:
- HNSWのインデックス時パラメータ(
max_degree、ef_construction)とクエリ時パラメータ(ef_search)。 - ベクトル量子化。
- セグメントサイズとセグメント数。
この記事では、(1)と(3)がrecallに与える影響に焦点を当てます。ベクトル量子化については別の文書で説明します。
インデックスハイパーパラメータ
HNSWインデックスは、ベクトルを多層グラフに編成します。インデックス構築中、ベクトルは一つずつ挿入され、各層の近傍と接続されます。このプロセスは大まかに以下の通りです:
- 層の割り当て:各ベクトルは幾何分布に従ってランダムにレベルが割り当てられます。上位レベルのノードはより疎であり、ナビゲーションのショートカットとして機能します。
ef_constructionを使用した候補近傍の検索: 各レベルで、HNSWは最大サイズef_constructionの候補キューを使用してローカル検索を実行します。ef_constructionの値が大きいほど、一般的により良い近傍とより高品質なグラフ(したがってより高いrecall)が得られますが、インデックス構築時間が長くなります。max_degreeを使用した接続の制限: 各ノードの近傍数はmax_degreeによって制限され、グラフが過度に密になることを防ぎます。
クエリ時:
- 上位層での貪欲検索(粗検索): 最上位層のエントリーノードから開始し、HNSWは上位層で貪欲検索を実行してクエリの近傍に素早く移動します。
ef_searchを使用した最下層での幅優先的検索(精密検索): レイヤー0では、HNSWは最大サイズef_searchの候補キューを使用してより徹底的に近傍を展開します。
まとめ:
max_degreeはノードあたりの(双方向)エッジの最大数を定義します。これはrecall、メモリ使用量、クエリパフォーマンスに影響します。max_degreeが大きいほど通常より高いrecallが得られますが、クエリが遅くなります。ef_constructionはインデックス構築中の候補キューの最大長を定義します。値が大きいほどグラフ品質とrecallが向上しますが、インデックス構築時間が増加します。ef_searchはクエリ中の候補キューの最大長を定義します。値が大きいほどrecallが向上しますが、距離計算の回数が増加し、クエリレイテンシとCPU使用量が増加します。
デフォルトで、Dorisはmax_degree = 32、ef_construction = 40、ef_search = 32を使用します。
上記はこれら3つのハイパーパラメータの定性的分析です。以下の表は、SIFT_1Mデータセットでの実証結果を示しています:
| max_degree | ef_construction | ef_search | recall_at_1 | recall_at_100 |
|---|---|---|---|---|
| 32 | 80 | 32 | 0.955 | 0.75335 |
| 32 | 80 | 64 | 0.98 | 0.88015 |
| 32 | 80 | 96 | 0.995 | 0.9328 |
| 32 | 120 | 32 | 0.96 | 0.7736 |
| 32 | 120 | 64 | 0.975 | 0.89865 |
| 32 | 120 | 96 | 0.99 | 0.94575 |
| 32 | 160 | 32 | 0.955 | 0.78745 |
| 32 | 160 | 64 | 0.98 | 0.9097 |
| 32 | 160 | 96 | 0.995 | 0.95485 |
| 48 | 80 | 32 | 0.985 | 0.85895 |
| 48 | 80 | 64 | 0.99 | 0.9453 |
| 48 | 80 | 96 | 1 | 0.97325 |
| 48 | 120 | 32 | 0.97 | 0.78335 |
| 48 | 120 | 64 | 1 | 0.9089 |
| 48 | 120 | 96 | 1 | 0.95325 |
| 48 | 160 | 32 | 0.975 | 0.79745 |
| 48 | 160 | 64 | 0.995 | 0.9192 |
| 48 | 160 | 96 | 0.995 | 0.9601 |
| 64 | 80 | 32 | 1 | 0.9026 |
| 64 | 80 | 64 | 1 | 0.97025 |
| 64 | 80 | 96 | 1 | 0.9862 |
| 64 | 120 | 32 | 0.985 | 0.8548 |
| 64 | 120 | 64 | 0.99 | 0.94755 |
| 64 | 120 | 96 | 0.995 | 0.97645 |
| 64 | 160 | 32 | 0.97 | 0.80585 |
| 64 | 160 | 64 | 0.99 | 0.91925 |
| 64 | 160 | 96 | 0.995 | 0.96165 |
結果は、複数のハイパーパラメータの組み合わせが同様のrecallレベルに到達できることを示しています。例えば、recall@100 > 0.95を望む場合、以下の組み合わせがすべて要件を満たします:
| max_degree | ef_construction | ef_search | recall_at_1 | recall_at_100 |
|---|---|---|---|---|
| 32 | 160 | 96 | 0.995 | 0.95485 |
| 48 | 80 | 96 | 1 | 0.97325 |
| 48 | 120 | 96 | 1 | 0.95325 |
| 48 | 160 | 96 | 0.995 | 0.9601 |
| 64 | 80 | 64 | 1 | 0.97025 |
| 64 | 80 | 96 | 1 | 0.9862 |
| 64 | 120 | 96 | 0.995 | 0.97645 |
| 64 | 160 | 96 | 0.995 | 0.96165 |
事前に単一の最適設定を提供するのは困難ですが、ハイパーパラメータ選択のための実用的なワークフローに従うことができます:
- インデックスなしでTable
table_multi_indexを作成します。2つまたは3つのベクトル列を含めることができます。 - Stream Loadまたはその他の取り込み方法を使用して
table_multi_indexにデータを読み込みます。 CREATE INDEXとBUILD INDEXを使用してすべてのベクトル列にANNインデックスを構築します。- 異なる列で異なるインデックスパラメータ設定を使用します。インデックス構築が完了した後、各列でrecallを計算し、最適なパラメータの組み合わせを選択します。
インデックスあたりのカバー行数
内部的に、Dorisはデータを複数の層で組織化します。
- 最上位はTableで、分散キーを使用してN個のタブレットにパーティション化されます。タブレットはデータシャーディング、再配置、リバランスの単位として機能します。
- 各データ取り込みまたはコンパクションは、タブレット下に新しいrowsetを生成します。rowsetはデータのバージョン管理されたコレクションです。
- rowset内のデータは実際にはセグメントファイルに保存されます。
転置インデックスと同様に、ベクトルインデックスはセグメントレベルで構築されます。セグメントサイズは、write_buffer_sizeやvertical_compaction_max_segment_sizeなどのBE設定オプションによって決定されます。取り込みとコンパクション中、インメモリmemtableが特定のサイズに達すると、セグメントファイルとしてディスクにフラッシュされ、そのセグメントに対してベクトルインデックス(または複数のベクトル列に対する複数のインデックス)が構築されます。インデックスはそのセグメント内の行のみをカバーします。
HNSWパラメータの固定セットが与えられた場合、インデックスが高いrecallを維持できるベクトル数には常に制限があります。セグメント内のベクトル数がその制限を超えると、recallが劣化し始めます。
特定のハイパーパラメータ下で良好なrecallを維持しながらセグメントが保持できる行数についての実証値を以下に示します:
| max_degree | ef_construction | ef_search | num_segment | recall_at_100 |
|---|---|---|---|---|
| 32 | 160 | 96 | 1M | 0.95485 |
| 48 | 80 | 96 | 1M | 0.97325 |
| 32 | 160 | 32 | 3M | 0.66983 |
| 128 | 512 | 128 | 3M | 0.9931 |
SHOW TABLETS FROM tableを使用してTableのコンパクション状況を検査できます。対応するURLをたどることで、セグメント数を確認できます。
コンパクションのrecallへの影響
コンパクションは、元のハイパーパラメータによって暗示される「カバレッジ容量」を超える可能性のある、より大きなセグメントを作成する可能性があるため、recallに影響を与える可能性があります。その結果、コンパクション前に達成されたrecallレベルは、コンパクション後には維持されなくなる可能性があります。
BUILD INDEXを実行する前に完全なコンパクションをトリガーすることをお勧めします。完全にコンパクションされたセグメントでインデックスを構築することで、recallが安定し、インデックス再構築によって引き起こされる書き込み増幅も削減されます。
クエリパフォーマンス
インデックスファイルのコールドローディング
DorisのHNSW ANNインデックスは、MetaのオープンソースライブラリFaissを使用して実装されています。HNSWインデックスは、セグメントの完全なグラフ構造がメモリに読み込まれた後にのみ有効になります。したがって、高並行性ワークロードを実行する前に、関連するすべてのセグメントインデックスがメモリに読み込まれていることを確認するためにウォームアップクエリを実行することをお勧めします。そうしないと、ディスクI/Oオーバーヘッドがクエリパフォーマンスを大幅に悪化させる可能性があります。
メモリフットプリント vs パフォーマンス
量子化や圧縮なしでは、HNSWインデックスのメモリフットプリントは、インデックス対象のすべてのベクトルのメモリフットプリントの約1.2~1.3倍です。
例えば、100万個の128次元ベクトルの場合、HNSW-FLATインデックスには約以下が必要です:
128 * 4 * 1,000,000 * 1.3 ≈ 650 MB。
参考値:
| dim | rows | estimated memory |
|---|---|---|
| 128 | 1M | 650 MB |
| 768 | 10M | 48 GB |
| 768 | 100M | 110 GB |
安定したパフォーマンスを維持するために、各BEに十分なメモリがあることを確認してください。そうしないと、頻繁なスワップとインデックスファイルでのI/Oがクエリレイテンシを深刻に悪化させます。
ベンチマーク
16コア、64GBマシンでDoris HNSWインデックスのクエリパフォーマンスをベンチマークしました。典型的な本番デプロイメントでは、FEとBEは別々のマシンに配置されるため、そのような2台のマシンが必要です。典型的な(分離FE/BE)デプロイメントと単一マシンでの混合FE/BEデプロイメントの両方の結果を提供します。
ベンチマークフレームワークはVectorDBBenchです。
ロードジェネレーターは別の16コアマシンで実行されます。
Performance768D1M
ベンチマークコマンド:
NUM_PER_BATCH=1000000 python3.11 -m vectordbbench doris --host 127.0.0.1 --port 9030 --case-type Performance768D1M --db-name Performance768D1M --search-concurrent --search-serial --num-concurrency 10,40,80 --stream-load-rows-per-batch 500000 --index-prop max_degree=128,ef_construction=512 --session-var hnsw_ef_search=128
| Doris (FE/BE separate) | Doris (FE/BE mixed) | |
|---|---|---|
| インデックスプロパティ | max_degree=128, ef_construction=512, hnsw_ef_search=128 | max_degree=128, ef_construction=512, hnsw_ef_search=156 |
| Recall@100 | 0.9931 | 0.9929 |
| 並行性 (クライアント) | 10, 40, 80 | 10, 40, 80 |
| 結果 QPS | 163.1567 (10) 606.6832 (40) 859.3842 (80) | 162.3002 (10) 542.3488 (40) 607.7951 (80) |
| 平均レイテンシ (秒) | 0.06123 (10) 0.06579 (40) 0.09281 (80) | 0.06154 (10) 0.07351 (40) 0.13093 (80) |
| P95 レイテンシ (秒) | 0.06560 (10) 0.07747 (40) 0.12967 (80) | 0.06726 (10) 0.08789 (40) 0.18719 (80) |
| P99 レイテンシ (秒) | 0.06889 (10) 0.08618 (40) 0.14605 (80) | 0.06154 (10) 0.07351 (40) 0.13093 (80) |