概要
生成AI アプリケーションにおいて、大規模モデルの内部パラメータ「メモリ」のみに依存することには明確な限界があります:(1) モデルの知識は古くなり、最新の情報をカバーできない;(2) モデルに直接回答を「生成」させることで、ハルシネーションのリスクが増加する。これによりRAG(検索-Augmented Generation)が生まれました。RAGの主要なタスクは、モデルに何もないところから回答を作り出させることではなく、外部の知識ベースから最も関連性の高いTop-K個の情報チャンクを取得し、それらを根拠となるコンテキストとしてモデルに供給することです。
これを実現するために、ユーザークエリと知識ベース内のドキュメント間の意味的関連性を測定するメカニズムが必要です。ベクトル表現は標準的なツールです:クエリとドキュメントの両方を意味ベクトルにエンコードすることで、ベクトル類似度を使用して関連性を測定できます。事前訓練済み言語モデルの進歩により、高品質な埋め込みの生成が主流となっています。したがって、RAGの検索段階は典型的なベクトル類似検索問題になります:大規模なベクトルコレクションから、クエリに最も類似するK個のベクトル(すなわち、候補となる知識の断片)を見つけることです。
RAGにおけるベクトル検索はテキストに限定されません;マルチモーダルなシナリオにも自然に拡張されます。マルチモーダルRAGシステムでは、画像、音声、動画、その他のデータタイプもベクトルにエンコードして検索し、その後生成モデルにコンテキストとして供給できます。例えば、ユーザーが画像をアップロードした場合、システムは最初に関連する説明や知識スニペットを検索し、その後説明コンテンツを生成できます。医療QAでは、RAGは患者記録と文献を検索して、より正確な診断提案をサポートできます。
Approximate Nearest Neighbor Search
バージョン4.0から、Apache DorisはANN検索を正式にサポートしています。追加のデータタイプは導入されていません:ベクトルは固定長配列として格納されます。距離ベースのインデックス化のために、Faissに基づいてANNという新しいインデックスタイプが実装されています。
一般的なSIFTデータセットを例として使用して、次のようにTableを作成できます:
CREATE TABLE sift_1M (
id int NOT NULL,
embedding array<float> NOT NULL COMMENT "",
INDEX ann_index (embedding) USING ANN PROPERTIES(
"index_type"="hnsw",
"metric_type"="l2_distance",
"dim"="128",
"quantizer"="flat"
)
) ENGINE=OLAP
DUPLICATE KEY(id) COMMENT "OLAP"
DISTRIBUTED BY HASH(id) BUCKETS 1
PROPERTIES (
"replication_num" = "1"
);
- index_type:
hnswはHierarchical Navigable Small World algorithmの使用を意味します - metric_type:
l2_distanceは距離関数としてL2距離の使用を意味します - dim:
128はベクトル次元が128であることを意味します - quantizer:
flatは各ベクトル次元が元のfloat32として格納されることを意味します
| Parameter | Required | Supported/Options | Default | デスクリプション |
|---|---|---|---|---|
index_type | Yes | hnsw only | (none) | ANNインデックスアルゴリズム。現在はHNSWのみサポート。 |
metric_type | Yes | l2_distance, inner_product | (none) | ベクトル類似度/距離メトリック。L2 = ユークリッド距離;inner_productはベクトルが正規化されている場合、コサイン距離を近似可能。 |
dim | Yes | 正の整数 (> 0) | (none) | ベクトル次元。インポートされるすべてのベクトルが一致する必要があり、そうでなければエラーが発生。 |
max_degree | No | 正の整数 | 32 | HNSW M(ノードあたりの最大近傍数)。インデックスメモリと検索性能に影響。 |
ef_construction | No | 正の整数 | 40 | HNSW efConstruction(構築時の候補キューサイズ)。大きくすると品質が向上するが構築が遅くなる。 |
quantizer | No | flat, sq8, sq4, pq | flat | ベクトルエンコーディング/量子化: flat = 生データ;sq8/sq4 = スカラー量子化(8/4ビット)、pq = メモリ削減のためのproduct quantization。 |
pq_m | Required when 'quantizer=pq' | 正の整数 | (none) | 使用するサブベクトル数を指定(ベクトル次元dimはpq_mで割り切れる必要がある)。 |
pq_nbits | Required when 'quantizer=pq' | 正の整数 | (none) | 各サブベクトルの表現に使用するビット数。faissではpq_nbitsは一般的に24以下である必要がある。 |
S3 TVF経由でのインポート:
INSERT INTO sift_1M
SELECT *
FROM S3(
"uri" = "https://selectdb-customers-tools-bj.oss-cn-beijing.aliyuncs.com/sift_database.tsv",
"format" = "csv");
SELECT count(*) FROM sift_1M
+----------+
| count(*) |
+----------+
| 1000000 |
+----------+
l2_distance_approximate / inner_product_approximateを使用するとANNインデックスパスがトリガーされます。関数はインデックスのmetric_typeと正確に一致する必要があります(例:metric_type=l2_distance → l2_distance_approximateを使用、metric_type=inner_product → inner_product_approximateを使用)。順序について:L2は昇順の距離を使用し(小さいほど近い)、inner productは降順のスコアを使用します(大きいほど近い)。
SELECT id,
l2_distance_approximate(
embedding,
[0,11,77,24,3,0,0,0,28,70,125,8,0,0,0,0,44,35,50,45,9,0,0,0,4,0,4,56,18,0,3,9,16,17,59,10,10,8,57,57,100,105,125,41,1,0,6,92,8,14,73,125,29,7,0,5,0,0,8,124,66,6,3,1,63,5,0,1,49,32,17,35,125,21,0,3,2,12,6,109,21,0,0,35,74,125,14,23,0,0,6,50,25,70,64,7,59,18,7,16,22,5,0,1,125,23,1,0,7,30,14,32,4,0,2,2,59,125,19,4,0,0,2,1,6,53,33,2]
) AS distance
FROM sift_1M
ORDER BY distance
LIMIT 10;
--------------
+--------+----------+
| id | distance |
+--------+----------+
| 178811 | 210.1595 |
| 177646 | 217.0161 |
| 181997 | 218.5406 |
| 181605 | 219.2989 |
| 821938 | 221.7228 |
| 807785 | 226.7135 |
| 716433 | 227.3148 |
| 358802 | 230.7314 |
| 803100 | 230.9112 |
| 866737 | 231.6441 |
+--------+----------+
10 rows in set (0.02 sec)
正確なground truthと比較するには、l2_distance または inner_product(_approximate 接尾辞なし)を使用してください。この例では、正確な検索に約290ミリ秒かかります:
10 rows in set (0.29 sec)
この例では、ANNインデックスによってクエリレイテンシが約290ミリ秒から約20ミリ秒に短縮されます。
ANNインデックスはセグメント単位で構築されます。分散Tableでは、各セグメントがローカルのTopNを返し、その後TopN演算子がタブレットとセグメント間で結果をマージしてグローバルなTopNを生成します。
順序に関する注意点:
metric_type = l2_distanceの場合、距離が小さいほど近いベクトルとなるため →ORDER BY dist ASCを使用します。metric_type = inner_productの場合、値が大きいほど近いベクトルとなるため → インデックス経由でTopNを取得するにはORDER BY dist DESCを使用します。
近似範囲検索
一般的なTopN最近傍検索(最も近いN件のレコードを返す)に加えて、もう一つの典型的なパターンは閾値ベースの範囲検索です。固定数の結果を返すのではなく、対象ベクトルまでの距離が述語(>, >=, <, <=)を満たすすべての点を返します。例えば、距離が閾値より大きいまたは小さいベクトルが必要な場合があります。これは「十分に類似している」または「十分に類似していない」候補が必要な場合に有用です。推薦システムでは多様性を向上させるために近いが同一ではないアイテムを取得する場合があり、異常検知では正常分布から離れた点を探します。
SQLの例:
SELECT count(*)
FROM sift_1M
WHERE l2_distance_approximate(
embedding,
[0,11,77,24,3,0,0,0,28,70,125,8,0,0,0,0,44,35,50,45,9,0,0,0,4,0,4,56,18,0,3,9,16,17,59,10,10,8,57,57,100,105,125,41,1,0,6,92,8,14,73,125,29,7,0,5,0,0,8,124,66,6,3,1,63,5,0,1,49,32,17,35,125,21,0,3,2,12,6,109,21,0,0,35,74,125,14,23,0,0,6,50,25,70,64,7,59,18,7,16,22,5,0,1,125,23,1,0,7,30,14,32,4,0,2,2,59,125,19,4,0,0,2,1,6,53,33,2])
> 300
--------------
+----------+
| count(*) |
+----------+
| 999271 |
+----------+
1 row in set (0.19 sec)
これらの範囲ベースのベクトル検索も ANN インデックスによって高速化されます:インデックスがまず候補を絞り込み、その後近似距離が計算されるため、コストが削減され、レイテンシが改善されます。サポートされる述語:>、>=、<、<=。
Compound Search
Compound Search は、同一の SQL 文で ANN TopN 検索と範囲述語を組み合わせ、距離制約も満たす TopN 結果を返します。
SELECT id,
l2_distance_approximate(
embedding, [0,11,77,24,3,0,0,0,28,70,125,8,0,0,0,0,44,35,50,45,9,0,0,0,4,0,4,56,18,0,3,9,16,17,59,10,10,8,57,57,100,105,125,41,1,0,6,92,8,14,73,125,29,7,0,5,0,0,8,124,66,6,3,1,63,5,0,1,49,32,17,35,125,21,0,3,2,12,6,109,21,0,0,35,74,125,14,23,0,0,6,50,25,70,64,7,59,18,7,16,22,5,0,1,125,23,1,0,7,30,14,32,4,0,2,2,59,125,19,4,0,0,2,1,6,53,33,2]) as dist
FROM sift_1M
WHERE l2_distance_approximate(
embedding, [0,11,77,24,3,0,0,0,28,70,125,8,0,0,0,0,44,35,50,45,9,0,0,0,4,0,4,56,18,0,3,9,16,17,59,10,10,8,57,57,100,105,125,41,1,0,6,92,8,14,73,125,29,7,0,5,0,0,8,124,66,6,3,1,63,5,0,1,49,32,17,35,125,21,0,3,2,12,6,109,21,0,0,35,74,125,14,23,0,0,6,50,25,70,64,7,59,18,7,16,22,5,0,1,125,23,1,0,7,30,14,32,4,0,2,2,59,125,19,4,0,0,2,1,6,53,33,2])
> 300
ORDER BY dist limit 10
--------------
+--------+----------+
| id | dist |
+--------+----------+
| 243590 | 300.005 |
| 549298 | 300.0317 |
| 429685 | 300.0533 |
| 690172 | 300.0916 |
| 123410 | 300.1333 |
| 232540 | 300.1649 |
| 547696 | 300.2066 |
| 855437 | 300.2782 |
| 589017 | 300.3048 |
| 930696 | 300.3381 |
+--------+----------+
10 rows in set (0.12 sec)
重要な問題は、述語フィルタリングがTopNの前に実行されるか後に実行されるかです。述語が最初にフィルタリングを行い、削減されたセットにTopNが適用される場合、これは事前フィルタリングです。そうでなければ、事後フィルタリングです。事後フィルタリングは高速になる可能性がありますが、再現率を大幅に低下させる場合があります。Dorisは再現率を保持するために事前フィルタリングを使用します。
Dorisはインデックスを使用して両方のフェーズを高速化できます。ただし、最初のフェーズ(範囲フィルタ)の選択性が高すぎる場合、両方のフェーズでインデックスを使用すると再現率が低下する可能性があります。Dorisは述語の選択性とインデックスタイプに基づいて、インデックスを2回使用するかどうかを適応的に決定します。
ANN Search with Additional Filters
これは、ANN TopNの前に他の述語を適用し、それらの制約の下でTopNを返すことを指します。
小さな8次元ベクトルとテキストフィルタの例:
CREATE TABLE ann_with_fulltext (
id int NOT NULL,
embedding array<float> NOT NULL,
comment String NOT NULL,
value int NULL,
INDEX idx_comment(`comment`) USING INVERTED PROPERTIES("parser" = "english") COMMENT 'inverted index for comment',
INDEX ann_embedding(`embedding`) USING ANN PROPERTIES("index_type"="hnsw","metric_type"="l2_distance","dim"="8")
) DUPLICATE KEY (`id`)
DISTRIBUTED BY HASH(`id`) BUCKETS 1
PROPERTIES("replication_num"="1");
サンプルデータを挿入し、commentに「music」が含まれる行のみを対象として検索する:
INSERT INTO ann_with_fulltext VALUES
(1, [0.1,0.2,0.3,0.4,0.5,0.6,0.7,0.8], 'this is about music', 10),
(2, [0.2,0.1,0.5,0.3,0.9,0.4,0.7,0.1], 'sports news today', 20),
(3, [0.9,0.8,0.7,0.6,0.5,0.4,0.3,0.2], 'latest music trend', 30),
(4, [0.05,0.06,0.07,0.08,0.09,0.1,0.2,0.3], 'politics update',40);
SELECT id, comment,
l2_distance_approximate(embedding, [0.1,0.1,0.2,0.2,0.3,0.3,0.4,0.4]) AS dist
FROM ann_with_fulltext
WHERE comment MATCH_ANY 'music' -- Filter using inverted index
ORDER BY dist ASC -- Ann topn calculation after predicates evaluate.
LIMIT 2;
+------+---------------------+----------+
| id | comment | dist |
+------+---------------------+----------+
| 1 | this is about music | 0.663325 |
| 3 | latest music trend | 1.280625 |
+------+---------------------+----------+
2 rows in set (0.04 sec)
TopNがベクトルインデックス経由で高速化されることを保証するには、すべての述語列に適切なセカンダリインデックス(例:転置インデックス)が必要です。
ANN検索関連のセッション変数
HNSWのビルド時パラメータ以外に、セッション変数を通じて検索時パラメータを渡すことができます:
- hnsw_ef_search: EF検索パラメータ。候補キューの最大長を制御します;大きいほど精度が高く、レイテンシも高くなります。デフォルト32。
- hnsw_check_relative_distance: 精度向上のために相対距離チェックを有効にするかどうか。デフォルトtrue。
- hnsw_bounded_queue: パフォーマンス最適化のために有界優先キューを使用するかどうか。デフォルトtrue。
ベクトル量子化
FLATエンコーディングでは、HNSWインデックス(生ベクトル+グラフ構造)は大量のメモリを消費する可能性があります。HNSWが機能するには完全にメモリ上に常駐する必要があるため、大規模環境ではメモリがボトルネックになることがあります。
スカラー量子化(SQ)はfloat32ストレージを圧縮してメモリを削減します。積量子化(PQ)は高次元ベクトルをより小さなサブベクトルに圧縮し、各サブベクトルを独立して量子化することでメモリオーバーヘッドを削減します。スカラー量子化について、Dorisは現在2つのスカラー量子化スキーム(INT8とINT4(SQ8 / SQ4))をサポートしています。SQ8を使用した例:
CREATE TABLE sift_1M (
id int NOT NULL,
embedding array<float> NOT NULL COMMENT "",
INDEX ann_index (embedding) USING ANN PROPERTIES(
"index_type"="hnsw",
"metric_type"="l2_distance",
"dim"="128",
"quantizer"="sq8"
)
) ENGINE=OLAP
DUPLICATE KEY(id) COMMENT "OLAP"
DISTRIBUTED BY HASH(id) BUCKETS 1
PROPERTIES (
"replication_num" = "1"
);
768次元のCohere-MEDIUM-1MおよびCohere-LARGE-10Mデータセットにおいて、SQ8はFLATと比較してインデックスサイズを約3分の1に削減します。
| Dataset | Dim | Storage/Index Scheme | Total Disk | Data Part | Index Part | 注釈 |
|---|---|---|---|---|---|---|
| Cohere-MEDIUM-1M | 768D | Doris (FLAT) | 5.647 GB (2.533 + 3.114) | 2.533 GB | 3.114 GB | 1M vectors |
| Cohere-MEDIUM-1M | 768D | Doris SQ INT8 | 3.501 GB (2.533 + 0.992) | 2.533 GB | 0.992 GB | INT8 symmetric quantization |
| Cohere-MEDIUM-1M | 768D | Doris PQ(pq_m=384,pq_nbits=8) | 3.149 GB (2.535 + 0.614) | 2.535 GB | 0.614 GB | product quantization |
| Cohere-LARGE-10M | 768D | Doris (FLAT) | 56.472 GB (25.328 + 31.145) | 25.328 GB | 31.145 GB | 10M vectors |
| Cohere-LARGE-10M | 768D | Doris SQ INT8 | 35.016 GB (25.329 + 9.687) | 25.329 GB | 9.687 GB | INT8 quantization |
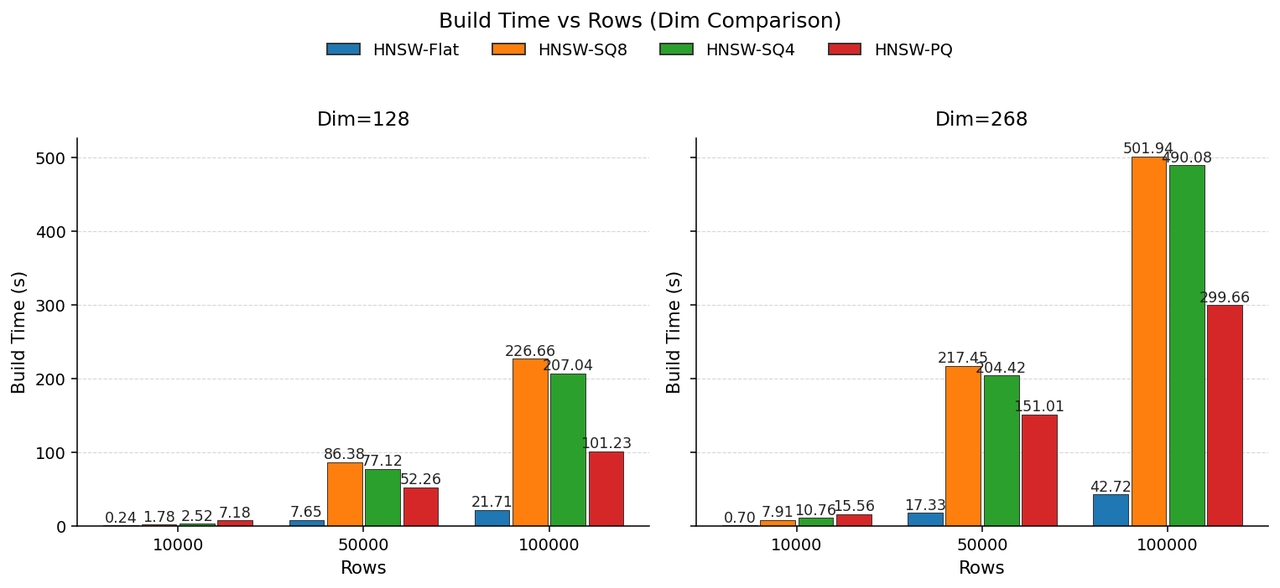
量子化は、距離計算のたびに量子化された値をデコードする必要があるため、ビルド時間に追加のオーバーヘッドをもたらします。128次元のベクトルの場合、ビルド時間は行数とともに増加し、SQとFLATの比較では最大約10倍遅くなる可能性があります。
同様に、Dorisはproduct quantizationもサポートしていますが、PQを使用する場合は追加のパラメータを提供する必要があることに注意してください:
pq_m:元の高次元ベクトルをいくつのサブベクトルに分割するかを示します(ベクトル次元dimはpq_mで割り切れる必要があります)。pq_nbits:各サブベクトル量子化のビット数を示し、各サブスペースコードブックのサイズを決定します。faissではpq_nbitsは一般的に24以下である必要があります。
PQ量子化は訓練時に十分なデータが必要であり、訓練点の数はクラスタ数以上である必要があることに注意してください(n >= 2 ^ pq_nbits)。
CREATE TABLE sift_1M (
id int NOT NULL,
embedding array<float> NOT NULL COMMENT "",
INDEX ann_index (embedding) USING ANN PROPERTIES(
"index_type"="hnsw",
"metric_type"="l2_distance",
"dim"="128",
"quantizer"="pq", -- Specify using PQ for quantization
"pq_m"="2", -- Required when using PQ, indicates splitting high-dimensional vector into pq_m low-dimensional sub-vectors
"pq_nbits"="2" -- Required when using PQ, indicates the number of bits for each subspace codebook
)
) ENGINE=OLAP
DUPLICATE KEY(id) COMMENT "OLAP"
DISTRIBUTED BY HASH(id) BUCKETS 1
PROPERTIES (
"replication_num" = "1"
);
パフォーマンスチューニング
ベクトル検索は典型的なセカンダリインデックスポイント検索シナリオです。高QPSと低レイテンシーを実現するには、以下を検討してください:
チューニングにより、ハードウェアFE 32C 64GB + BE 32C 64GBにおいて、Dorisは3000+ QPSに到達できます(データセット:Cohere-MEDIUM-1M)。
クエリパフォーマンス
| Concurrency | Scheme | QPS | Avg Latency (s) | P99 (s) | CPU Usage | Recall |
|---|---|---|---|---|---|---|
| 240 | Doris | 3340.4399 | 0.071368168 | 0.163399825 | 40% | 91.00% |
| 240 | Doris SQ INT8 | 3188.6359 | 0.074728852 | 0.160370195 | 40% | 88.26% |
| 240 | Doris SQ INT4 | 2818.2291 | 0.084663868 | 0.174826815 | 43% | 80.38% |
| 240 | Doris brute force | 3.6787 | 25.554878826 | 29.363227973 | 100% | 100.00% |
| 480 | Doris | 4155.7220 | 0.113387271 | 0.261086075 | 60% | 91.00% |
| 480 | Doris SQ INT8 | 3833.1130 | 0.123040214 | 0.276912867 | 50% | 88.26% |
| 480 | Doris SQ INT4 | 3431.0538 | 0.137636995 | 0.281631249 | 57% | 80.38% |
| 480 | Doris brute force | 3.6787 | 25.554878826 | 29.363227973 | 100% | 100.00% |
Prepared Statementの使用
最新のembeddingモデルは多くの場合、768次元以上のベクトルを出力します。768次元のリテラルをSQLにインライン化すると、解析時間が実行時間を超える場合があります。prepared statementを使用してください。現在DorisはMySQLクライアントのprepareコマンドを直接サポートしていないため、JDBCを使用してください:
- JDBC URLでサーバーサイドprepared statementを有効にする:
jdbc:mysql://127.0.0.1:9030/demo?useServerPrepStmts=true - プレースホルダー(
?)を使用してPreparedStatementを使用し、それを再利用する。
セグメント数の削減
ANNインデックスはセグメントごとに構築されます。セグメントが多すぎるとオーバーヘッドが発生します。理想的には、ANNインデックス付きTableでは各tabletが約5セグメント以下になるようにしてください。be.confのwrite_buffer_sizeとvertical_compaction_max_segment_sizeを調整してください(例:両方を10737418240に設定)。
Rowset数の削減
セグメント削減と同じ動機:スケジューリングオーバーヘッドを最小化します。各ロードはrowsetを作成するため、バッチ取り込みにはstream loadまたはINSERT INTO SELECTを使用することを推奨します。
ANNインデックスをメモリに保持
現在のANNアルゴリズムはメモリベースです。セグメントのインデックスがメモリにない場合、ディスクI/Oが発生します。ANNインデックスを常駐させるために、be.confでenable_segment_cache_prune=falseを設定してください。
parallel_pipeline_task_num = 1
ANN TopNクエリは各scannerから非常に少数の行を返すため、高いpipelineタスク並列度は不要です。parallel_pipeline_task_num = 1を設定してください。
enable_profile = false
超低レイテンシーが重要なクエリでは、クエリプロファイリングを無効にしてください。
Python SDK
AIの時代において、Pythonはデータ処理とインテリジェントアプリケーション開発の主流言語となっています。開発者がPython環境でDorisのベクトル検索機能をより簡単に使用できるよう、コミュニティの貢献者たちがDoris用のPython SDKを開発しています。
- https://github.com/uchenily/doris_vector_search:ベクトル距離検索に最適化されており、現在利用可能な最高パフォーマンスのDorisベクトル検索Python SDKです。
使用制限
-
ANNインデックス列はNOT NULL
Array<Float>である必要があり、インポートされるすべてのベクトルは宣言されたdimと一致する必要があります。そうでない場合、エラーが発生します。 -
ANNインデックスはDuplicateKeyTableモデルでのみサポートされます。
-
Dorisはpre-filterセマンティクス(ANN TopNより前に述語が適用される)を使用します。述語に行を正確に特定できるセカンダリインデックスのない列(例:inverted indexなし)が含まれる場合、正確性を保持するためにDorisはbrute forceにフォールバックします。 例:
SELECT id, l2_distance_approximate(embedding, [xxx]) AS distance
FROM sift_1M
WHERE round(id) > 100
ORDER BY distance LIMIT 10;
idはキーですが、セカンダリインデックス(転置インデックスなど)がない場合、その述語はインデックス解析後に適用されるため、Dorisはpre-filterセマンティクスを満たすためにブルートフォースにフォールバックします。
- SQLの距離関数がインデックスDDLで定義されたmetric typeと一致しない場合、
l2_distance_approximate/inner_product_approximateを呼び出してもDorisはTopNにANNインデックスを使用できません。 - metric type
inner_productの場合、ORDER BY inner_product_approximate(...) DESC LIMIT N(DESCが必要)のみがANNインデックスによって高速化されます。 xxx_approximate()の最初のパラメータはColumnArrayである必要があり、2番目のパラメータはCASTまたはArrayLiteralである必要があります。これらを逆にするとブルートフォース検索が実行されます。