ブローカーロード
Broker LoadはMySQL APIを通じて開始されます。DorisはLOAD文の情報に従って、リモートデータソースからデータを能動的にプルします。これは非同期インポート方式です。送信後、SHOW LOAD文を使用してインポートの進行状況と結果を確認する必要があります。
この方式は非推奨であり、バージョン5.0で削除される予定です。代わりに「insert into table select xxx from tvf or catalog table」を使用してください。
Broker Loadは以下の典型的なシナリオに適しています:
- ソースデータがリモートシステム(オブジェクトストレージやHDFSなど)に格納されている場合
- 単一インポートのデータ量が大きい場合(GBからTBレベル)
- Doris自体が並行性と再試行を制御して、データを非同期でバッチインポートしたい場合
Lakehouse / TVFのHDFS TVFやS3 TVFを
INSERT INTOと組み合わせてデータをインポートすることも可能です。TVFに基づくINSERT INTOは現在同期インポートですが、Broker Loadは非同期インポートです。
Dorisの初期バージョンでは、S3 LoadとHDFS Loadの両方がWITH BROKERを通じて特定のBrokerプロセスに接続していました。バージョンの進歩に伴い、S3 LoadとHDFS Loadは追加のBrokerプロセスに依存しなくなりましたが、依然としてBroker Loadと類似の構文を使用します。歴史的な理由と構文の類似性により、S3 Load、HDFS Load、およびBroker Loadは総称してBroker Loadと呼ばれます。
制限事項
以下の表はBroker Loadの機能をまとめたものです:
| 次元 | サポート範囲 |
|---|---|
| ストレージバックエンド | S3プロトコル、HDFSプロトコル、その他のプロトコル(対応するBrokerプロセスが必要) |
| ファイルパスパターン | ワイルドカード *、?、[abc]、[a-z];範囲展開 {1..10}、{a,b,c}。完全な構文については、File Path Patternを参照してください。 |
| データフォーマット | CSV、JSON、PARQUET、ORC |
| 圧縮タイプ | PLAIN、GZ、LZO、BZ2、LZ4FRAME、DEFLATE、LZOP、LZ4BLOCK、SNAPPYBLOCK、ZLIB、ZSTD |
基本原理
インポートジョブを送信した後:
- FEが対応するプランを生成し、現在のBE数とファイルサイズに基づいて複数のBEに実行のために配布します。
- 各BEはデータの一部をインポートする責任を負います:Brokerからデータをプルし、データ変換を実行し、Dorisシステムにデータを書き込みます。
- すべてのBEがインポートを完了した後、FEがインポートが成功したかどうかを最終決定します。
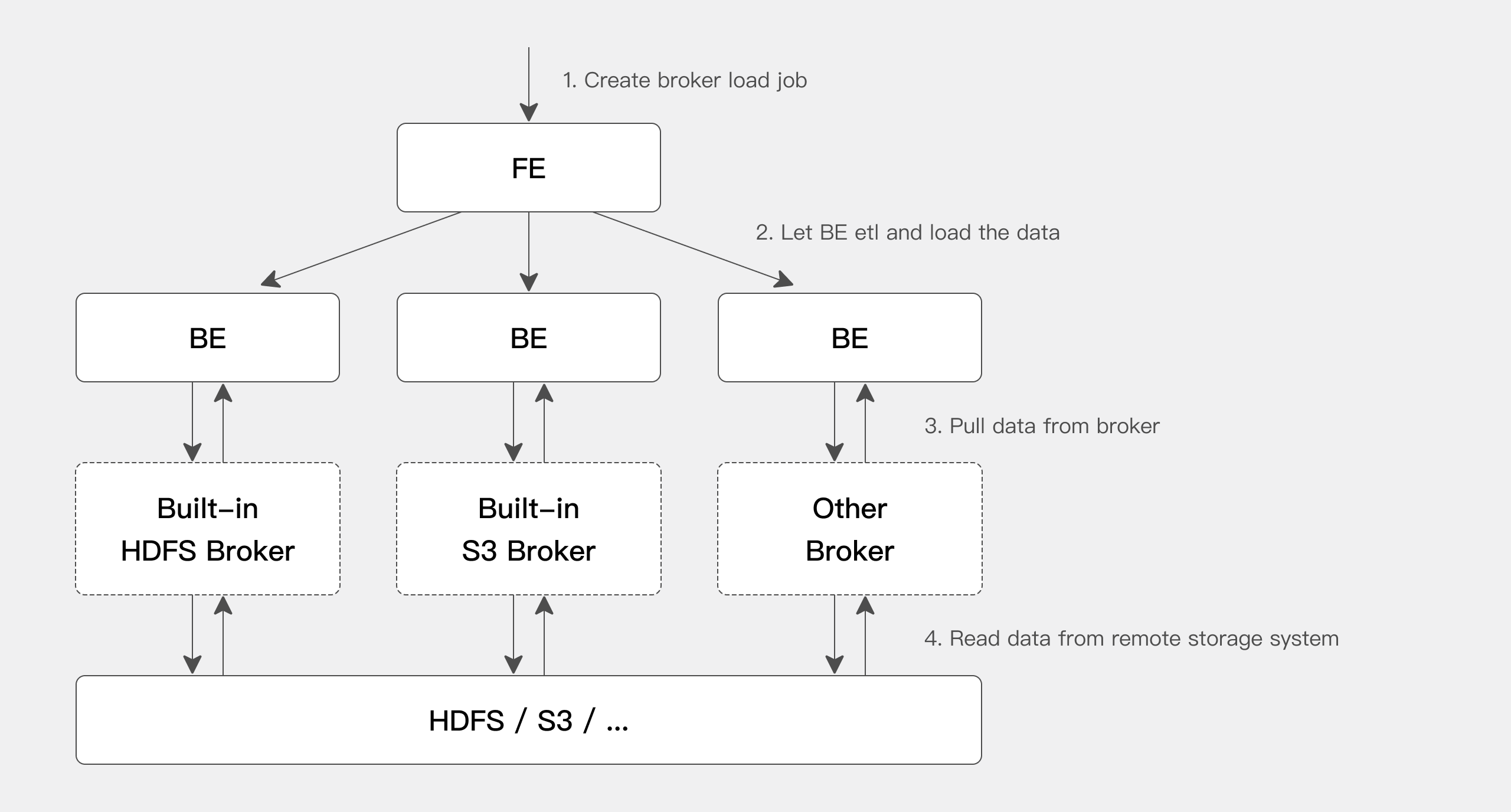
BEはBrokerプロセスを通じてリモートストレージシステムからデータを読み取ります。Brokerを導入する主な目的は:
- エコシステム互換性:Broker標準に従ってJavaで開発できるため、ビッグデータエコシステムの様々なストレージシステムを簡単にサポートできます。
- エラー分離:BrokerプロセスがBEプロセスから分離されているため、BEの安定性が向上します。
BEにはHDFSとS3のサポートが組み込まれているため、HDFSやS3からデータをインポートする場合は追加のBrokerプロセスを開始する必要がありません。カスタムBroker実装がある場合は、対応するBrokerプロセスをデプロイする必要があります。
クイックスタート
このセクションでは、S3 Loadを例に完全なプロセスを説明します。完全な構文については、SQLマニュアルのBroker Loadを参照してください。
事前チェック
1. Dorisテーブル権限
Broker Loadには対象テーブルのINSERT権限が必要です。この権限がない場合は、GRANTコマンドで付与してください。
2. S3認証と接続情報
AWS S3を例として(他のオブジェクトストレージシステムも参考にできます):
| 情報 | 取得方法 |
|---|---|
| AK / SK | AWSコンソールのMy Security CredentialsでAccess keysを表示または作成します。 |
| REGION | バケット作成時に選択するか、バケットリストで表示できます。 |
| ENDPOINT | AWSドキュメント: S3 Endpointsを参照してください。 |
インポートジョブの作成
ステップ1:S3上にCSVファイルを準備
以下の内容でbrokerload_example.csvを作成します:
1,Emily,25
2,Benjamin,35
3,Olivia,28
4,Alexander,60
5,Ava,17
6,William,69
7,Sophia,32
8,James,64
9,Emma,37
10,Liam,64
ステップ2: Dorisでターゲットテーブルを作成する
CREATE TABLE testdb.test_brokerload(
user_id BIGINT NOT NULL COMMENT "user id",
name VARCHAR(20) COMMENT "name",
age INT COMMENT "age"
)
DUPLICATE KEY(user_id)
DISTRIBUTED BY HASH(user_id) BUCKETS 10;
ステップ3: Broker Loadジョブを送信する
バケット名とS3認証情報を実際の値に置き換えてください:
LOAD LABEL broker_load_2022_04_01
(
DATA INFILE("s3://your_bucket_name/brokerload_example.csv")
INTO TABLE test_brokerload
COLUMNS TERMINATED BY ","
FORMAT AS "CSV"
(user_id, name, age)
)
WITH S3
(
"provider" = "S3",
"AWS_ENDPOINT" = "https://s3.us-west-2.amazonaws.com",
"AWS_ACCESS_KEY" = "<your-ak>",
"AWS_SECRET_KEY"="<your-sk>",
"AWS_REGION" = "us-west-2",
"compress_type" = "PLAIN"
)
PROPERTIES
(
"timeout" = "3600"
);
provider フィールドは、実際のオブジェクトストレージサービスプロバイダーに応じて入力する必要があります。Dorisがサポートする provider 値のリストは以下の通りです:
| provider | Vendor |
|---|---|
S3 | Amazon AWS |
AZURE | Microsoft Azure |
GCP | Google GCP |
OSS | Alibaba Cloud |
COS | Tencent Cloud |
OBS | Huawei Cloud |
BOS | Baidu Cloud |
プロバイダーがリストにない場合(例:MinIO)、S3(AWS互換モード)を使用してみてください。
インポートジョブの確認
Broker Loadは非同期インポートです。具体的な結果はSHOW LOADコマンドで確認できます:
mysql> show load order by createtime desc limit 1\G;
*************************** 1. row ***************************
JobId: 41326624
Label: broker_load_2022_04_01
State: FINISHED
Progress: ETL:100%; LOAD:100%
Type: BROKER
EtlInfo: unselected.rows=0; dpp.abnorm.ALL=0; dpp.norm.ALL=27
TaskInfo: cluster:N/A; timeout(s):1200; max_filter_ratio:0.1
ErrorMsg: NULL
CreateTime: 2022-04-01 18:59:06
EtlStartTime: 2022-04-01 18:59:11
EtlFinishTime: 2022-04-01 18:59:11
LoadStartTime: 2022-04-01 18:59:11
LoadFinishTime: 2022-04-01 18:59:11
URL: NULL
JobDetails: {"Unfinished backends":{"5072bde59b74b65-8d2c0ee5b029adc0":[]},"ScannedRows":27,"TaskNumber":1,"All backends":{"5072bde59b74b65-8d2c0ee5b029adc0":[36728051]},"FileNumber":1,"FileSize":5540}
1 row in set (0.01 sec)
Import Jobのキャンセル
Broker Load jobのステータスがCANCELLEDまたはFINISHEDでない場合、手動でキャンセルできます。キャンセル時には、キャンセルするjobのlabelを指定する必要があります。構文については、CANCEL LOADを参照してください。
例えば、データベースdemoでlabel broker_load_2022_04_01のimport jobをキャンセルするには:
CANCEL LOAD FROM demo WHERE LABEL = "broker_load_2022_04_01";
Compute Groupのバインド
ストレージ・コンピュート分離モードでは、Broker Loadがcompute groupを選択する優先順位は以下の通りです:
use db@cluster文で指定されたcompute groupを選択する。- ユーザープロパティ
default_compute_groupで指定されたcompute groupを選択する。 - 現在のユーザーが権限を持つcompute groupから1つを選択する。
ストレージ・コンピュート統合モードでは:ユーザープロパティresource_tags.locationで指定されたcompute groupを選択します。ユーザープロパティで指定されていない場合は、defaultという名前のcompute groupを使用します。
リファレンス
インポートコマンド構文
LOAD LABEL load_label
(
data_desc1[, data_desc2, ...]
[format_properties]
)
WITH [S3|HDFS|BROKER broker_name]
[broker_properties]
[load_properties]
[COMMENT "comments"];
WITH句はストレージシステムへのアクセス方法を指定し、broker_propertiesはそのアクセス方法の設定パラメータを提供します:
| 句 | 説明 |
|---|---|
S3 | S3プロトコルを使用するストレージシステム。 |
HDFS | HDFSプロトコルを使用するストレージシステム。 |
BROKER broker_name | その他のプロトコルを使用するストレージシステム。利用可能なbroker_nameリストはSHOW BROKERで確認できます。詳細は以下の「その他のBrokerインポート」を参照してください。 |
インポート設定パラメータ
Load Properties
| プロパティ名 | 型 | デフォルト | 説明 |
|---|---|---|---|
timeout | Long | 14400 | インポートタイムアウト(秒)。範囲:1から259200秒。 |
max_filter_ratio | Float | 0.0 | 不正な形式のデータの最大許容比率。デフォルトはゼロ許容です。値の範囲は0から1です。エラー率がこの値を超えると、インポートは失敗します。不正な形式のデータには、WHERE条件によってフィルタリングされた行は含まれません。 |
strict_mode | Boolean | false | 厳密モードを有効にするかどうか。 |
partial_columns | Boolean | false | 部分列更新を使用するかどうか。Merge on WriteのUnique Keyテーブルでのみ有効です。 |
timezone | String | "Asia/Shanghai" | このインポートで使用されるタイムゾーン。すべてのタイムゾーン関連関数の結果に影響します。 |
load_parallelism | Integer | 8 | 各BEでの同時実行インスタンス数の上限。 |
send_batch_parallelism | Integer | 1 | データ送信時のsinkノードの同時実行数。memtable-on-sinkが無効な場合のみ有効です。 |
load_to_single_tablet | Boolean | false | パーティションごとに1つのタブレットのみにインポートするかどうか。ランダムバケティングを使用するOLAPテーブルでのみ許可されます。 |
priority | HIGH / NORMAL / LOW | NORMAL | インポートジョブの優先度。 |
Format Properties
| パラメータ名 | 型 | デフォルト | 説明 |
|---|---|---|---|
skip_lines | Integer | 0 | CSVファイルの先頭で指定された行数をスキップします。フォーマットがcsv_with_namesまたはcsv_with_names_and_typesの場合は無効です。 |
trim_double_quotes | Boolean | false | フィールドの外側のダブルクォートをトリムするかどうか。 |
enclose | String | "" | フィールドが改行文字やデリミタを含む場合に使用される囲み文字。例えば、デリミタが,で囲み文字が'の場合、'b,c'は単一のフィールドとして解析されます。 |
escape | String | "" | 囲み文字をエスケープするために使用されるエスケープ文字。例えば、エスケープ文字が\で囲み文字が'の場合、フィールド'b,\'c'は正しく'b,'c'として解析されます。 |
- Formatパラメータは、ソースファイルの解析方法(デリミタやクォート処理など)を定義するために使用されます。これらは
LOAD文の内部のPROPERTIES句に設定する必要があります。 - Loadパラメータは、インポートの動作(タイムアウトやリトライなど)を制御するために使用されます。これらは
LOAD文の外部の最も外側のPROPERTIESブロックに設定する必要があります。
LOAD LABEL s3_load_example (
DATA INFILE("s3://bucket/path/file.csv")
INTO TABLE users
COLUMNS TERMINATED BY ","
FORMAT AS "CSV"
(user_id, name, age)
PROPERTIES (
"trim_double_quotes" = "true" -- Format parameter
)
)
WITH S3 (
...
)
PROPERTIES (
"timeout" = "3600" -- Load parameter
);
fe.conf システムレベル設定
以下の設定は、すべてのBroker Loadインポートジョブに適用されるBroker Loadのシステムレベル設定です。主にfe.confを変更することで調整されます。
| 設定項目 | 型 | デフォルト | 説明 |
|---|---|---|---|
min_bytes_per_broker_scanner | Long | 67108864 (64 MB) | 単一のBEが処理するデータの最小量(バイト単位)。 |
max_bytes_per_broker_scanner | Long | 536870912000 (500 GB) | 単一のBEが処理するデータの最大量(バイト単位)。単一のインポートジョブがサポートするデータの最大量は、おおよそmax_bytes_per_broker_scanner * BEノード数です。より大きなデータ量が必要な場合は、この値を適切に増やしてください。 |
max_broker_concurrency | Integer | 10 | 単一ジョブの最大インポート並行性。 |
default_load_parallelism | Integer | 8 | BEノードあたりの最大同時実行インスタンス数。 |
broker_load_default_timeout_second | Integer | 14400 | Broker Loadインポートのデフォルトタイムアウト(秒単位)。 |
インポート並行性の計算
処理するデータの最小量、最大並行性、ソースファイルサイズ、およびクラスター内の現在のBE数が、このインポートの並行性を共同で決定します:
このインポートの並行性 = Math.min(ソースファイルサイズ / min_bytes_per_broker_scanner, max_broker_concurrency, 現在のBEノード数 * load_parallelism)
このインポートで単一のBEが処理する量 = ソースファイルサイズ / このインポートの並行性
セッション変数
| セッション変数 | 型 | デフォルト | 説明 |
|---|---|---|---|
time_zone | String | "Asia/Shanghai" | デフォルトタイムゾーン。インポート時のタイムゾーン関連関数の結果に影響します。 |
send_batch_parallelism | Integer | 1 | データ送信時のsinkノードの並行性。memtable-on-sinkが無効な場合のみ有効です。 |
インポート例
以下の典型的なシナリオは、Broker Loadの一般的な使用法を示しています。
シナリオ1: HDFSからTXTファイルをインポート
LOAD LABEL demo.label_20220402
(
DATA INFILE("hdfs://host:port/tmp/test_hdfs.txt")
INTO TABLE `load_hdfs_file_test`
COLUMNS TERMINATED BY "\t"
(id,age,name)
)
with HDFS
(
"fs.defaultFS"="hdfs://host:port",
"hadoop.username" = "user"
)
PROPERTIES
(
"timeout"="1200",
"max_filter_ratio"="0.1"
);
シナリオ2: NameNode HA構成でのHDFS
LOAD LABEL demo.label_20220402
(
DATA INFILE("hdfs://hafs/tmp/test_hdfs.txt")
INTO TABLE `load_hdfs_file_test`
COLUMNS TERMINATED BY "\t"
(id,age,name)
)
with HDFS
(
"hadoop.username" = "user",
"fs.defaultFS"="hdfs://hafs",
"dfs.nameservices" = "hafs",
"dfs.ha.namenodes.hafs" = "my_namenode1, my_namenode2",
"dfs.namenode.rpc-address.hafs.my_namenode1" = "nn1_host:rpc_port",
"dfs.namenode.rpc-address.hafs.my_namenode2" = "nn2_host:rpc_port",
"dfs.client.failover.proxy.provider.hafs" = "org.apache.hadoop.hdfs.server.namenode.ha.ConfiguredFailoverProxyProvider"
)
PROPERTIES
(
"timeout"="1200",
"max_filter_ratio"="0.1"
);
シナリオ3: ワイルドカードを使用して2つのファイルバッチをマッチさせ、2つのテーブルにインポートする
Broker Loadは、ファイルパス内でワイルドカード(*、?、[...])および範囲パターン({1..10})をサポートしています。完全な構文については、File Path Patternを参照してください。
LOAD LABEL example_db.label2
(
DATA INFILE("hdfs://host:port/input/file-10*")
INTO TABLE `my_table1`
PARTITION (p1)
COLUMNS TERMINATED BY ","
(k1, tmp_k2, tmp_k3)
SET (
k2 = tmp_k2 + 1,
k3 = tmp_k3 + 1
),
DATA INFILE("hdfs://host:port/input/file-20*")
INTO TABLE `my_table2`
COLUMNS TERMINATED BY ","
(k1, k2, k3)
)
with HDFS
(
"fs.defaultFS"="hdfs://host:port",
"hadoop.username" = "user"
);
ワイルドカードを使用して2つのファイルバッチ file-10* と file-20* をマッチさせ、それぞれを my_table1 と my_table2 にインポートします。my_table1 はパーティション p1 にインポートされ、ソースファイルの2番目と3番目の列の値は1だけ増分された後にインポートされます。
シナリオ4: ワイルドカードを使用してHDFSからデータのバッチをインポートする
LOAD LABEL example_db.label3
(
DATA INFILE("hdfs://host:port/user/doris/data/*/*")
INTO TABLE `my_table`
COLUMNS TERMINATED BY "\\x01"
)
with HDFS
(
"fs.defaultFS"="hdfs://host:port",
"hadoop.username" = "user"
);
\\x01をデリミタとして指定します。これはHiveで一般的に使用されるデフォルトのデリミタです。ワイルドカード*を使用して、dataディレクトリ下のすべてのサブディレクトリ内のすべてのファイルを指定します。
シナリオ5: Parquet形式のデータのインポート
LOAD LABEL example_db.label4
(
DATA INFILE("hdfs://host:port/input/file")
INTO TABLE `my_table`
FORMAT AS "parquet"
(k1, k2, k3)
)
with HDFS
(
"fs.defaultFS"="hdfs://host:port",
"hadoop.username" = "user"
);
FORMAT ASが指定されていない場合、デフォルトでファイルの拡張子によってフォーマットが決定されます。
シナリオ6: ファイルパスからパーティションフィールドを抽出する
LOAD LABEL example_db.label5
(
DATA INFILE("hdfs://host:port/input/city=beijing/*/*")
INTO TABLE `my_table`
FORMAT AS "csv"
(k1, k2, k3)
COLUMNS FROM PATH AS (city, utc_date)
)
with HDFS
(
"fs.defaultFS"="hdfs://host:port",
"hadoop.username" = "user"
);
my_tableの列はk1, k2, k3, city, utc_dateです。
ディレクトリhdfs://hdfs_host:hdfs_port/user/doris/data/input/dir/city=beijingには以下のファイルが含まれています:
hdfs://hdfs_host:hdfs_port/input/city=beijing/utc_date=2020-10-01/0000.csv
hdfs://hdfs_host:hdfs_port/input/city=beijing/utc_date=2020-10-02/0000.csv
hdfs://hdfs_host:hdfs_port/input/city=tianji/utc_date=2020-10-03/0000.csv
hdfs://hdfs_host:hdfs_port/input/city=tianji/utc_date=2020-10-04/0000.csv
ファイルにはk1, k2, k3の3つの列のみが含まれています。cityとutc_dateの2つの列は、ファイルパスから抽出されます。
シナリオ7: インポートデータのフィルタリング
LOAD LABEL example_db.label6
(
DATA INFILE("hdfs://host:port/input/file")
INTO TABLE `my_table`
(k1, k2, k3)
SET (
k2 = k2 + 1
)
PRECEDING FILTER k1 = 1
WHERE k1 > k2
)
with HDFS
(
"fs.defaultFS"="hdfs://host:port",
"hadoop.username" = "user"
);
ソースデータで k1 = 1 かつ変換後に k1 > k2 である行のみがインポートされます。
シナリオ 8: ファイルパスから時間パーティションフィールドを抽出する
LOAD LABEL example_db.label7
(
DATA INFILE("hdfs://host:port/user/data/*/test.txt")
INTO TABLE `tbl12`
COLUMNS TERMINATED BY ","
(k2,k3)
COLUMNS FROM PATH AS (data_time)
SET (
data_time=str_to_date(data_time, '%Y-%m-%d %H%%3A%i%%3A%s')
)
)
with HDFS
(
"fs.defaultFS"="hdfs://host:port",
"hadoop.username" = "user"
);
時刻には%3Aが含まれています。HDFSパスでは:が許可されていないため、すべての:文字は%3Aに置き換えられます。
パスには以下のファイルが含まれています:
/user/data/data_time=2020-02-17 00%3A00%3A00/test.txt
/user/data/data_time=2020-02-18 00%3A00%3A00/test.txt
テーブルスキーマ:
CREATE TABLE IF NOT EXISTS tbl12 (
data_time DATETIME,
k2 INT,
k3 INT
) DISTRIBUTED BY HASH(data_time) BUCKETS 10
PROPERTIES (
"replication_num" = "3"
);
シナリオ 9: Merge を使用したインポート
LOAD LABEL example_db.label8
(
MERGE DATA INFILE("hdfs://host:port/input/file")
INTO TABLE `my_table`
(k1, k2, k3, v2, v1)
DELETE ON v2 > 100
)
with HDFS
(
"fs.defaultFS"="hdfs://host:port",
"hadoop.username"="user"
)
PROPERTIES
(
"timeout" = "3600",
"max_filter_ratio" = "0.1"
);
my_tableはUnique Keyテーブルである必要があります。インポートされたデータでv2 > 100の場合、その行は削除として扱われます。インポートのタイムアウトは3600秒で、許可されるエラー率は10%です。
シナリオ10: source_sequenceカラムを指定して置換順序を保証する
LOAD LABEL example_db.label9
(
DATA INFILE("hdfs://host:port/input/file")
INTO TABLE `my_table`
COLUMNS TERMINATED BY ","
(k1,k2,source_sequence,v1,v2)
ORDER BY source_sequence
)
with HDFS
(
"fs.defaultFS"="hdfs://host:port",
"hadoop.username"="user"
);
my_tableはSequence列が指定されたUnique Keyモデルテーブルである必要があります。データの順序は、ソースデータのsource_sequence列の値によって保証されます。
シナリオ11: json_root / jsonpathsを使用したJSONのインポート
LOAD LABEL example_db.label10
(
DATA INFILE("hdfs://host:port/input/file.json")
INTO TABLE `my_table`
FORMAT AS "json"
PROPERTIES(
"json_root" = "$.item",
"jsonpaths" = "[\"$.id\", \"$.city\", \"$.code\"]"
)
)
with HDFS
(
"fs.defaultFS"="hdfs://host:port",
"hadoop.username"="user"
);
jsonpathsはcolumn listやSET (column_mapping)と組み合わせて使用することもできます:
LOAD LABEL example_db.label10
(
DATA INFILE("hdfs://host:port/input/file.json")
INTO TABLE `my_table`
FORMAT AS "json"
(id, code, city)
SET (id = id * 10)
PROPERTIES(
"json_root" = "$.item",
"jsonpaths" = "[\"$.id\", \"$.city\", \"$.code\"]"
)
)
with HDFS
(
"fs.defaultFS"="hdfs://host:port",
"hadoop.username"="user"
);
JSONファイルのルートノードでJSONオブジェクトをインポートするには、jsonpathsを$.に設定します。つまり、PROPERTIES("jsonpaths"="$.")とします。
高度な設定
S3 Load URL Access Style
S3 SDKはデフォルトでvirtual-hosted-styleアクセスを使用します。ただし、一部のオブジェクトストレージシステムはvirtual-hosted-styleを有効にしていない、またはサポートしていません。use_path_styleパラメータを追加してpath-styleを強制できます:
WITH S3
(
"AWS_ENDPOINT" = "AWS_ENDPOINT",
"AWS_ACCESS_KEY" = "AWS_ACCESS_KEY",
"AWS_SECRET_KEY"="AWS_SECRET_KEY",
"AWS_REGION" = "AWS_REGION",
"use_path_style" = "true"
)
S3 Load 一時認証情報
一時認証情報(TOKEN)は、S3プロトコルをサポートするあらゆるオブジェクトストレージへのアクセスにサポートされています:
WITH S3
(
"AWS_ENDPOINT" = "AWS_ENDPOINT",
"AWS_ACCESS_KEY" = "AWS_TEMP_ACCESS_KEY",
"AWS_SECRET_KEY" = "AWS_TEMP_SECRET_KEY",
"AWS_TOKEN" = "AWS_TEMP_TOKEN",
"AWS_REGION" = "AWS_REGION"
)
HDFS認証
1. Simple認証
Simple認証とは、Hadoopの設定hadoop.security.authenticationをsimpleに設定することを意味します:
(
"username" = "user",
"password" = ""
);
usernameをアクセスするユーザーに設定し、パスワードは空のままにしてください。
2. Kerberos Authentication
この認証方法には以下の情報が必要です:
| Parameter | Description |
|---|---|
hadoop.security.authentication | 認証方法をkerberosとして指定します。 |
hadoop.kerberos.principal | Kerberosプリンシパルを指定します。 |
hadoop.kerberos.keytab | Kerberos keytabファイルのパスを指定します。ファイルはBrokerプロセスが存在するサーバー上の絶対パスである必要があり、Brokerプロセスがアクセス可能である必要があります。 |
kerberos_keytab_content | keytabファイルのbase64エンコードされたコンテンツを指定します。これかhadoop.kerberos.keytabのいずれかを使用してください。 |
例:
(
"hadoop.security.authentication" = "kerberos",
"hadoop.kerberos.principal" = "doris@YOUR.COM",
"hadoop.kerberos.keytab" = "/home/doris/my.keytab"
)
(
"hadoop.security.authentication" = "kerberos",
"hadoop.kerberos.principal" = "doris@YOUR.COM",
"kerberos_keytab_content" = "ASDOWHDLAWIDJHWLDKSALDJSDIWALD"
)
Kerberos認証を使用する場合、krb5.confファイルが必要です。このファイルはKerberos設定情報を含み、通常/etcディレクトリにインストールされます。KRB5_CONFIG環境変数を通じてデフォルトの場所を上書きすることもできます。krb5.confの内容の例:
[libdefaults]
default_realm = DORIS.HADOOP
default_tkt_enctypes = des3-hmac-sha1 des-cbc-crc
default_tgs_enctypes = des3-hmac-sha1 des-cbc-crc
dns_lookup_kdc = true
dns_lookup_realm = false
[realms]
DORIS.HADOOP = {
kdc = kerberos-doris.hadoop.service:7005
}
HDFS HAモード
この設定は、HAモードでデプロイされたHDFSクラスタにアクセスするために使用されます。
| Parameter | Description |
|---|---|
dfs.nameservices | HDFSサービスの名前を指定します(ユーザー定義)。例:"dfs.nameservices" = "my_ha"。 |
dfs.ha.namenodes.xxx | ユーザー定義のNameNode名(複数の名前はカンマで区切ります)。xxxはdfs.nameservicesで定義されたユーザー定義名です。例:"dfs.ha.namenodes.my_ha" = "my_nn"。 |
dfs.namenode.rpc-address.xxx.nn | NameNodeのRPCアドレスを指定します。nnはdfs.ha.namenodes.xxxで定義されたNameNode名です。例:"dfs.namenode.rpc-address.my_ha.my_nn" = "host:port"。 |
dfs.client.failover.proxy.provider.[nameservice ID] | クライアントがNameNodeへの接続に使用するプロバイダーを指定します。デフォルトはorg.apache.hadoop.hdfs.server.namenode.ha.ConfiguredFailoverProxyProviderです。 |
例:
(
"fs.defaultFS" = "hdfs://my_ha",
"dfs.nameservices" = "my_ha",
"dfs.ha.namenodes.my_ha" = "my_namenode1, my_namenode2",
"dfs.namenode.rpc-address.my_ha.my_namenode1" = "nn1_host:rpc_port",
"dfs.namenode.rpc-address.my_ha.my_namenode2" = "nn2_host:rpc_port",
"dfs.client.failover.proxy.provider.my_ha" = "org.apache.hadoop.hdfs.server.namenode.ha.ConfiguredFailoverProxyProvider"
)
HAモードは上記の2つの認証方法と組み合わせることができます。例えば、simple認証を通じてHA HDFSにアクセスするには:
(
"username"="user",
"password"="passwd",
"fs.defaultFS" = "hdfs://my_ha",
"dfs.nameservices" = "my_ha",
"dfs.ha.namenodes.my_ha" = "my_namenode1, my_namenode2",
"dfs.namenode.rpc-address.my_ha.my_namenode1" = "nn1_host:rpc_port",
"dfs.namenode.rpc-address.my_ha.my_namenode2" = "nn2_host:rpc_port",
"dfs.client.failover.proxy.provider.my_ha" = "org.apache.hadoop.hdfs.server.namenode.ha.ConfiguredFailoverProxyProvider"
)
その他のBrokerインポート
他のリモートストレージシステム用のBrokerは、Dorisクラスタ内のオプションプロセスです。主にリモートストレージ内のファイルやディレクトリの読み書きをサポートするために使用されます。Dorisは現在、以下のリモートストレージシステム用のBroker実装を提供しています:
- Tencent Cloud CHDFS
- Tencent Cloud GFS
- JuiceFS
過去のバージョンでは、Dorisは様々なオブジェクトストレージシステム用のBrokerもサポートしていましたが、現在は**WITH S3がオブジェクトストレージからデータをインポートする推奨方法**です;WITH BROKERはもはや推奨されません。
Brokerは、RPCサービスポートを通じてサービスを提供するステートレスなJavaプロセスです。リモートストレージでの読み書き操作のために、POSIX風のファイル操作(open、pread、pwriteなど)をカプセル化します。Brokerはその他の情報を記録しません。接続情報、ファイル情報、リモートストレージの権限情報を含むすべての必要な情報は、RPC呼び出しのパラメータとして渡される必要があります。
Brokerはデータパスとしてのみ機能し、計算には参加しないため、メモリ使用量は少なくなっています。通常、Dorisシステムには1つまたは複数のBrokerプロセスがデプロイされます。同じタイプのBrokerは、名前(Broker名)を持つグループを形成します。
Broker情報
Broker情報は2つの部分で構成されます:名前と認証情報。一般的な構文は:
WITH BROKER "broker_name"
(
"username" = "xxx",
"password" = "yyy",
"other_prop" = "prop_value",
...
);
Name (Broker Name)
WITH BROKER "broker_name" 句を通じて既存のBroker名を指定します。Broker名は、ALTER SYSTEM ADD BROKER コマンドを通じてBrokerプロセスを追加する際にユーザーが指定した名前です。通常、1つの名前は1つ以上のBrokerプロセスに対応し、Dorisは名前によって利用可能なBrokerプロセスを選択します。SHOW BROKER を通じてクラスター内の既存のBrokerを確認できます。
Broker名は単なるユーザー定義の名前であり、Brokerのタイプを表すものではありません。
認証情報
異なるBrokerタイプと異なるアクセス方法には、異なる認証情報が必要です。認証情報は通常、WITH BROKER "broker_name" の後のプロパティマップ内でキーバリューペアとして提供されます。
各種Brokerの接続設定
Alibaba Cloud OSS
(
"fs.oss.accessKeyId" = "",
"fs.oss.accessKeySecret" = "",
"fs.oss.endpoint" = ""
)
Baidu Cloud BOS
BOSを使用する場合は、対応するSDKパッケージをダウンロードしてください。具体的な設定と使用方法については、BOS HDFS official documentationを参照してください。ダウンロードして展開した後、JARパッケージをBrokerのlibディレクトリに配置してください。
(
"fs.bos.access.key" = "xx",
"fs.bos.secret.access.key" = "xx",
"fs.bos.endpoint" = "xx"
)
Huawei Cloud OBS
(
"fs.obs.access.key" = "xx",
"fs.obs.secret.key" = "xx",
"fs.obs.endpoint" = "xx"
)
JuiceFS
(
"fs.defaultFS" = "jfs://xxx/",
"fs.jfs.impl" = "io.juicefs.JuiceFileSystem",
"fs.AbstractFileSystem.jfs.impl" = "io.juicefs.JuiceFS",
"juicefs.meta" = "xxx",
"juicefs.access-log" = "xxx"
)
GCS
Brokerを通じてGCSにアクセスする際は、Project IDが必要です。その他のパラメータはオプションです。すべてのパラメータ設定については、GCS Configを参照してください:
(
"fs.gs.project.id" = "Your Project ID",
"fs.AbstractFileSystem.gs.impl" = "com.google.cloud.hadoop.fs.gcs.GoogleHadoopFS",
"fs.gs.impl" = "com.google.cloud.hadoop.fs.gcs.GoogleHadoopFileSystem",
)
FAQ とトラブルシューティング
よくあるエラー
1. インポートエラー: Scan bytes per broker scanner exceed limit:xxx
「インポートタイムアウト」セクションを参照してください。FE設定項目 max_bytes_per_broker_scanner と max_broker_concurrency を変更してください。
2. インポートエラー: failed to send batch または TabletWriter add batch with unknown id
query_timeout と streaming_load_rpc_max_alive_time_sec を適切に調整してください。
3. インポートエラー: LOAD_RUN_FAIL; msg:Invalid Column Name:xxx
PARQUETまたはORCデータの場合、ファイルヘッダーの列名はDorisテーブルの列名と一致する必要があります。例:
(tmp_c1,tmp_c2)
SET
(
id=tmp_c2,
name=tmp_c1
)
これは以下を意味します: Parquet または ORC ファイルから (tmp_c1, tmp_c2) という名前の列を取得し、Doris テーブルの (id, name) 列にマップします。SET が指定されていない場合、column 内の列がマッピングとして使用されます。
注意: 一部の Hive バージョンで直接生成された ORC ファイルでは、ファイルヘッダーが Hive メタデータではなく
(_col0, _col1, _col2, ...)となっており、Invalid Column Nameエラーが発生する可能性があります。この場合、マッピングにはSETを使用してください。
4. インポートエラー: Failed to get S3 FileSystem for bucket is null/empty
バケット情報が正しくないか存在しない、またはバケット形式がサポートされていません。例えば、GCS を使用して _ を含むバケット名を作成した場合(s3://gs_bucket/load_tbl など)、S3 クライアントが GCS にアクセスする際にエラーを返します。バケットパスを作成する際は _ を使用しないことを推奨します。
5. インポートタイムアウト
インポートのデフォルト timeout は 4 時間です。タイムアウトが発生した場合、最大タイムアウトを直接増やすことは推奨されません。単一のインポートが 4 時間を超える場合は、インポートするファイルを分割して複数のバッチでインポートすることを推奨します。これは、非常に大きなタイムアウトを設定すると、単一の失敗後の再試行コストが非常に高くなるためです。
Doris クラスターが処理できると予想されるインポートあたりの最大データ量は、以下の式を使用して見積もることができます:
Expected maximum import file data volume = 14400s * 10M/s * number of BEs
For example, if the number of BEs in the cluster is 10:
Expected maximum import file data volume = 14400s * 10M/s * 10 = 1440000M ≈ 1440G
Note: A typical user environment may not reach 10M/s, so it is recommended to split files larger than 500G before importing.
詳細なヘルプ
Broker Loadの詳細な構文とベストプラクティスについては、Broker Loadコマンドマニュアルを参照してください。また、MySQLクライアントのコマンドラインでHELP BROKER LOADを実行することで、より詳しいヘルプを表示できます。