Routine Load
Dorisは、Routine Loadメソッドを通じてKafka Topicからデータを継続的に消費することができます。Routine Loadジョブを提出した後、Dorisは継続的にロードジョブを実行し、Kafkaクラスタ内の指定されたTopicからメッセージを常に消費するリアルタイムローディングタスクを生成します。
Routine Loadは、Exactly-Onceセマンティクスをサポートするストリーミングロードジョブであり、データの欠損や重複がないことを保証します。
使用シナリオ
サポート対象データソース
Routine LoadはKafkaクラスタからのデータ消費をサポートしています。
サポート対象データファイル形式
Routine LoadはCSVおよびJSON形式のデータ消費をサポートしています。
CSV形式をロードする際は、null値と空文字列を明確に区別する必要があります:
-
null値は
\nで表現する必要があります。例えば、a,\n,bは中央の列がnull値であることを示します。 -
空文字列は、データフィールドを空のままにして表現できます。例えば、
a,,bは中央の列が空文字列であることを示します。
使用制限
Routine Loadを使用してKafkaからデータを消費する際、以下の制限があります:
-
サポートされるメッセージ形式は、CSVおよびJSONテキスト形式です。CSV内の各メッセージは個別の行にあり、その行は改行文字で終わらないようにする必要があります。
-
デフォルトでは、Kafkaバージョン0.10.0.0以上をサポートしています。0.10.0.0未満のKafkaバージョン(0.9.0、0.8.2、0.8.1、0.8.0など)を使用する必要がある場合は、
kafka_broker_version_fallbackの値を互換性のある古いバージョンに設定してBE設定を変更するか、Routine Loadを作成する際にproperty.broker.version.fallbackの値を直接設定する必要があります。ただし、古いバージョンを使用すると、時間に基づくKafkaパーティションのオフセット設定など、Routine Loadの一部の新機能が利用できない場合があります。
基本原理
Routine LoadはKafka Topicsからデータを継続的に消費し、Dorisに書き込みます。
DorisでRoutine Loadジョブが作成されると、複数のインポートタスクから構成される常駐インポートジョブが生成されます:
-
Load Job:Routine Load Jobは、データソースからデータを継続的に消費する常駐インポートジョブです。
-
Load Task:インポートジョブは実際の消費のために複数のインポートタスクに分割され、各タスクは独立したトランザクションです。
Routine Loadの具体的なインポートプロセスは以下の図に示されています:
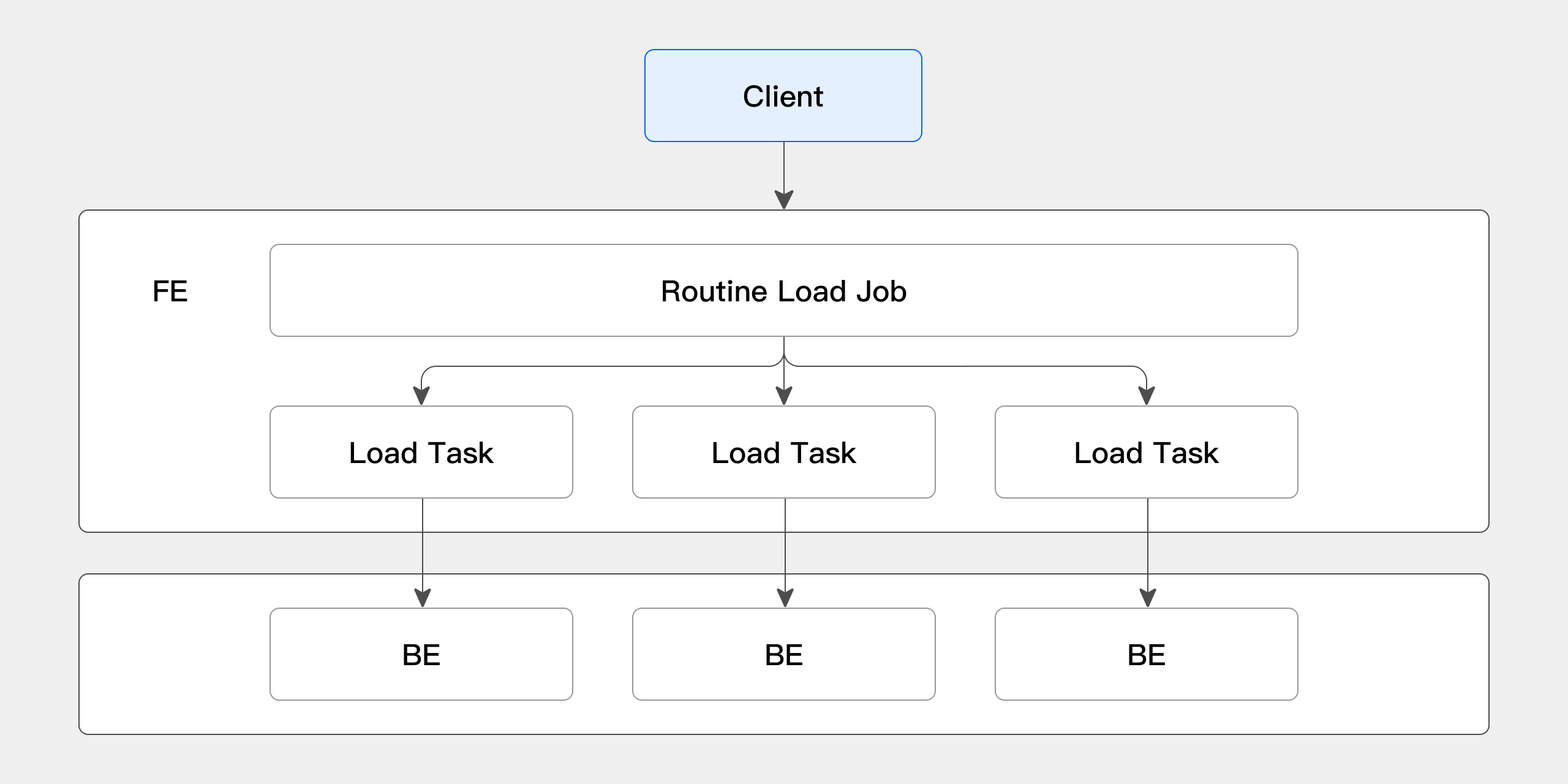
-
ClientはFEにRoutine Loadジョブの作成リクエストを提出し、FEはRoutine Load Managerを通じて常駐インポートジョブ(Routine Load Job)を生成します。
-
FEはJob Schedulerを通じてRoutine Load Jobを複数のRoutine Load Tasksに分割し、Task Schedulerによってスケジュールされ、BEノードに分散されます。
-
BE上で、Routine Load Taskが完了した後、FEにトランザクションを提出し、Jobのメタデータを更新します。
-
Routine Load Taskが提出された後、新しいTaskの生成またはタイムアウトしたTaskの再試行を継続します。
-
新しく生成されたRoutine Load TasksはTask Schedulerによって継続的なサイクルで継続的にスケジュールされます。
Auto Resume
ジョブの高可用性を確保するため、auto-resumeメカニズムが導入されています。予期しない一時停止の場合、Routine Load Schedulerスレッドは自動的にジョブの再開を試行します。予期しないKafka停止やその他システムが機能しないシナリオに対して、auto-resumeメカニズムにより、Kafkaが復旧すれば、手動介入なしでroutine loadジョブが正常に実行を継続できることが保証されます。
auto-resumeが発生しない状況:
-
ユーザーが手動でPAUSE ROUTINE LOADコマンドを実行した場合。
-
データ品質に問題がある場合。
-
データベースTableが削除された場合など、再開が不可能な状況。
これらの3つの状況以外では、その他の一時停止されたジョブは自動的に再開を試行します。
クイックスタート
ジョブの作成
Dorisでは、CREATE ROUTINE LOADコマンドを使用して永続的なRoutine Loadタスクを作成できます。詳細な構文については、CREATE ROUTINE LOADを参照してください。Routine LoadはCSVおよびJSON形式のデータ消費をサポートしています。
CSVデータのロード
-
データロードサンプル
Kafkaには以下のサンプルデータがあります:
kafka-console-consumer.sh --bootstrap-server localhost:9092 --topic test-routine-load-csv --from-beginning
1,Emily,25
2,Benjamin,35
3,Olivia,28
4,Alexander,60
5,Ava,17
6,William,69
7,Sophia,32
8,James,64
9,Emma,37
10,Liam,64 -
Tableの作成
Dorisでは、以下の構文でロード用のTableを作成します:
CREATE TABLE testdb.test_routineload_tbl(
user_id BIGINT NOT NULL COMMENT "User ID",
name VARCHAR(20) COMMENT "User Name",
age INT COMMENT "User Age"
)
DUPLICATE KEY(user_id)
DISTRIBUTED BY HASH(user_id) BUCKETS 10; -
Routine Loadジョブの作成
Dorisでは、
CREATE ROUTINE LOADコマンドを使用してロードジョブを作成します:CREATE ROUTINE LOAD testdb.example_routine_load_csv ON test_routineload_tbl
COLUMNS TERMINATED BY ",",
COLUMNS(user_id, name, age)
FROM KAFKA(
"kafka_broker_list" = "192.168.88.62:9092",
"kafka_topic" = "test-routine-load-csv",
"property.kafka_default_offsets" = "OFFSET_BEGINNING"
);
JSON データの読み込み
-
サンプルデータの読み込み
Kafkaには、以下のサンプルデータがあります:
kafka-console-consumer.sh --bootstrap-server localhost:9092 --topic test-routine-load-json --from-beginning -
Tableの作成
Dorisでは、以下の構文を使用してロード用のTableを作成します:
CREATE TABLE testdb.test_routineload_tbl(
user_id BIGINT NOT NULL COMMENT "User ID",
name VARCHAR(20) COMMENT "User Name",
age INT COMMENT "User Age"
)
DUPLICATE KEY(user_id)
DISTRIBUTED BY HASH(user_id) BUCKETS 10; -
Routine Load ジョブの作成
Doris では、
CREATE ROUTINE LOADコマンドを使用してジョブを作成します:CREATE ROUTINE LOAD testdb.example_routine_load_json ON test_routineload_tbl
COLUMNS(user_id, name, age)
PROPERTIES(
"format"="json",
"jsonpaths"="[\"$.user_id\",\"$.name\",\"$.age\"]"
)
FROM KAFKA(
"kafka_broker_list" = "192.168.88.62:9092"
);
JSON ファイルのルートノードにある JSON オブジェクトを読み込む必要がある場合、jsonpaths は $. として指定する必要があります。例:PROPERTIES("jsonpaths"="$.")"
ステータスの確認
Doris では、以下の方法を使用して Routine Load ジョブとタスクのステータスを確認できます:
-
Load Jobs:ロードタスクに関する情報を表示するために使用されます。対象Table、サブタスク数、ロード遅延ステータス、ロード設定、ロード結果などが含まれます。
-
Load Tasks:個別のロードタスクのステータスを表示するために使用されます。タスク ID、トランザクションステータス、タスクステータス、実行開始時間、BE(Backend)ノード割り当てが含まれます。
01 実行中のジョブの確認
ジョブのステータスを確認するには SHOW ROUTINE LOAD コマンドを使用できます。SHOW ROUTINE LOAD コマンドは、対象Table、ロード遅延ステータス、ロード設定、エラーメッセージなど、現在のジョブに関する情報を提供します。
例えば、testdb.example_routine_load_csv ジョブのステータスを確認するには、以下のコマンドを実行できます:
mysql> SHOW ROUTINE LOAD FOR testdb.example_routine_load\G
*************************** 1. row ***************************
Id: 12025
Name: example_routine_load
CreateTime: 2024-01-15 08:12:42
PauseTime: NULL
EndTime: NULL
DbName: default_cluster:testdb
TableName: test_routineload_tbl
IsMultiTable: false
State: RUNNING
DataSourceType: KAFKA
CurrentTaskNum: 1
JobProperties: {"max_batch_rows":"200000","timezone":"America/New_York","send_batch_parallelism":"1","load_to_single_tablet":"false","column_separator":"','","line_delimiter":"\n","current_concurrent_number":"1","delete":"*","partial_columns":"false","merge_type":"APPEND","exec_mem_limit":"2147483648","strict_mode":"false","jsonpaths":"","max_batch_interval":"10","max_batch_size":"104857600","fuzzy_parse":"false","partitions":"*","columnToColumnExpr":"user_id,name,age","whereExpr":"*","desired_concurrent_number":"5","precedingFilter":"*","format":"csv","max_error_number":"0","max_filter_ratio":"1.0","json_root":"","strip_outer_array":"false","num_as_string":"false"}
DataSourceProperties: {"topic":"test-topic","currentKafkaPartitions":"0","brokerList":"192.168.88.62:9092"}
CustomProperties: {"kafka_default_offsets":"OFFSET_BEGINNING","group.id":"example_routine_load_73daf600-884e-46c0-a02b-4e49fdf3b4dc"}
Statistic: {"receivedBytes":28,"runningTxns":[],"errorRows":0,"committedTaskNum":3,"loadedRows":3,"loadRowsRate":0,"abortedTaskNum":0,"errorRowsAfterResumed":0,"totalRows":3,"unselectedRows":0,"receivedBytesRate":0,"taskExecuteTimeMs":30069}
Progress: {"0":"2"}
Lag: {"0":0}
ReasonOfStateChanged:
ErrorLogUrls:
OtherMsg:
User: root
Comment:
1 row in set (0.00 sec)
02 実行中のタスクの確認
SHOW ROUTINE LOAD TASKコマンドを使用してロードタスクのステータスを確認できます。SHOW ROUTINE LOAD TASKコマンドは、特定のロードジョブの下にある個別のタスクに関する情報を提供します。これには、タスクID、トランザクションステータス、タスクステータス、実行開始時刻、BE IDが含まれます。
例えば、example_routine_load_csvジョブのタスクステータスを確認するには、次のコマンドを実行できます:
mysql> SHOW ROUTINE LOAD TASK WHERE jobname = 'example_routine_load_csv';
+-----------------------------------+-------+-----------+-------+---------------------+---------------------+---------+-------+----------------------+
| TaskId | TxnId | TxnStatus | JobId | CreateTime | ExecuteStartTime | Timeout | BeId | DataSourceProperties |
+-----------------------------------+-------+-----------+-------+---------------------+---------------------+---------+-------+----------------------+
| 8cf47e6a68ed4da3-8f45b431db50e466 | 195 | PREPARE | 12177 | 2024-01-15 12:20:41 | 2024-01-15 12:21:01 | 20 | 10429 | {"4":1231,"9":2603} |
| f2d4525c54074aa2-b6478cf8daaeb393 | 196 | PREPARE | 12177 | 2024-01-15 12:20:41 | 2024-01-15 12:21:01 | 20 | 12109 | {"1":1225,"6":1216} |
| cb870f1553864250-975279875a25fab6 | -1 | NULL | 12177 | 2024-01-15 12:20:52 | NULL | 20 | -1 | {"2":7234,"7":4865} |
| 68771fd8a1824637-90a9dac2a7a0075e | -1 | NULL | 12177 | 2024-01-15 12:20:52 | NULL | 20 | -1 | {"3":1769,"8":2982} |
| 77112dfea5e54b0a-a10eab3d5b19e565 | 197 | PREPARE | 12177 | 2024-01-15 12:21:02 | 2024-01-15 12:21:02 | 20 | 12098 | {"0":3000,"5":2622} |
+-----------------------------------+-------+-----------+-------+---------------------+---------------------+---------+-------+----------------------+
ジョブの一時停止
PAUSE ROUTINE LOADコマンドを使用してロードジョブを一時停止できます。ジョブが一時停止されると、PAUSEDステートに入りますが、ロードジョブは終了されず、RESUME ROUTINE LOADコマンドを使用して再開できます。
testdb.example_routine_load_csvロードジョブを一時停止するには、以下のコマンドを使用できます:
PAUSE ROUTINE LOAD FOR testdb.example_routine_load_csv;
ジョブの再開
RESUME ROUTINE LOAD コマンドを使用して、一時停止されたロードジョブを再開できます。
testdb.example_routine_load_csv ジョブを再開するには、以下のコマンドを使用できます:
RESUME ROUTINE LOAD FOR testdb.example_routine_load_csv;
ジョブの変更
作成したロードジョブは、ALTER ROUTINE LOADコマンドを使用して変更できます。ジョブを変更する前に、PAUSE ROUTINE LOADコマンドを使用してジョブを一時停止する必要があり、変更を行った後は、RESUME ROUTINE LOADコマンドを使用してジョブを再開できます。
ジョブのdesired_concurrent_numberパラメータを変更し、Kafkaトピック情報を更新するには、以下のコマンドを使用できます:
ALTER ROUTINE LOAD FOR testdb.example_routine_load_csv
PROPERTIES(
"desired_concurrent_number" = "3"
)
FROM KAFKA(
"kafka_broker_list" = "192.168.88.60:9092",
"kafka_topic" = "test-topic"
);
ジョブのキャンセル
STOP ROUTINE LOAD コマンドを使用してRoutine Loadジョブを停止および削除できます。削除されると、ロードジョブは復旧できず、SHOW ROUTINE LOAD コマンドを使用して表示することもできません。
testdb.example_routine_load_csv ロードジョブを停止および削除するには、次のコマンドを使用できます:
STOP ROUTINE LOAD FOR testdb.example_routine_load_csv;
Compute Groupの選択
ストレージとコンピュート分離モードでは、Routine LoadがCompute Groupを選択する優先順位のロジックは以下の通りです:
use db@cluster statementで指定されたCompute Groupを選択する;- ユーザープロパティ
default_compute_groupで指定されたCompute Groupを選択する; - 現在のユーザーがアクセス権限を持つCompute Groupから1つを選択する;
統合ストレージコンピュートモードでは、ユーザープロパティresource_tags.locationで指定されたCompute Groupを選択します;
ユーザープロパティで指定されていない場合は、defaultという名前のCompute Groupを使用します;
注意すべき点として、Routine LoadジョブのCompute Groupは作成時にのみ指定できます。 Routine Loadジョブが作成されると、Routine LoadにバインドされたCompute Groupは変更できません。
リファレンスマニュアル
Loadコマンド
Routine Load永続ロードジョブを作成するための構文は以下の通りです:
CREATE ROUTINE LOAD [<db_name>.]<job_name> [ON <tbl_name>]
[merge_type]
[load_properties]
[job_properties]
FROM KAFKA [data_source_properties]
[COMMENT "<comment>"]
ローディングジョブを作成するためのモジュールについて以下に説明します:
| Module | デスクリプション |
|---|---|
| db_name | ローディングタスクを作成するデータベースの名前を指定します。 |
| job_name | 作成するローディングジョブの名前を指定します。ジョブ名は同じデータベース内で一意である必要があります。 |
| tbl_name | ロードするTableの名前を指定します。このパラメータは任意です。指定しない場合、動的Tableモードが使用され、KafkaデータにTable名情報が含まれている必要があります。 |
| merge_type | データマージタイプを指定します。デフォルト値はAPPENDです。可能なmerge_typeオプションは以下の通りです:
|
| load_properties | 以下を含むロードプロパティを記述します:
|
| job_properties | Routine Loadの一般的なロードパラメータを指定します。 |
| data_source_properties | Kafkaデータソースのプロパティを記述します。 |
| comment | ローディングジョブの追加コメントを記述します。 |
ロードパラメータの説明
01 FE設定パラメータ
| パラメータ名 | デフォルト値 | Dynamic 構成 | FE Master Exclusive 構成 | デスクリプション |
|---|---|---|---|---|
| max_routine_load_task_concurrent_num | 256 | Yes | Yes | Routine Loadジョブの同時実行サブタスクの最大数を制限します。デフォルト値を維持することを推奨します。高く設定しすぎると、同時実行タスクが過多となり、クラスターリソースを消費する可能性があります。 |
| max_routine_load_task_num_per_be | 1024 | Yes | Yes | BE毎に許可されるRoutine Loadタスクの最大同時実行数。max_routine_load_task_num_per_beはroutine_load_thread_pool_sizeより小さい値である必要があります。 |
| max_routine_load_job_num | 100 | Yes | Yes | NEED_SCHEDULED、RUNNING、PAUSEを含むRoutine Loadジョブの最大数を制限します。 |
| max_tolerable_backend_down_num | 0 | Yes | Yes | いずれかのBEが停止している場合、Routine Loadは自動復旧できません。特定の条件下で、DorisはPAUSEDタスクをRUNNING状態に再スケジューリングできます。0の値は、すべてのBEノードが稼働している場合のみ再スケジューリングが許可されることを意味します。 |
| period_of_auto_resume_min | 5 (minutes) | Yes | Yes | Routine Loadを自動的に再開する期間。 |
02 BE設定パラメータ
| パラメータ名 | デフォルト値 | Dynamic 構成 | デスクリプション |
|---|---|---|---|
| max_consumer_num_per_group | 3 | Yes | サブタスクがデータを消費するために生成できるコンシューマーの最大数。Kafkaデータソースの場合、1つのコンシューマーは1つまたは複数のKafkaパーティションを消費する可能性があります。タスクが6つのKafkaパーティションを消費する必要がある場合、3つのコンシューマーを生成し、それぞれが2つのパーティションを消費します。パーティションが2つしかない場合、2つのコンシューマーのみを生成し、それぞれが1つのパーティションを消費します。 |
ロード設定パラメータ
Routine Loadジョブを作成する際、CREATE ROUTINE LOADコマンドを使用して異なるモジュールのロード設定パラメータを指定できます。
tbl_name句
ロードするTableの名前を指定します。このパラメータは任意です。
指定しない場合、動的Tableモードが使用され、Kafka内のデータにTable名情報が含まれている必要があります。現在、KafkaのValueフィールドからTable名を抽出することのみがサポートされています。フォーマットは以下の通りで、JSONを例とします: table_name|{"col1": "val1", "col2": "val2"}、ここでtbl_nameはTable名、|はTable名とTableデータ間のセパレータとして使用されます。同じフォーマットがCSVデータにも適用されます(例: table_name|val1,val2,val3)。ここでのtable_nameはDorisのTable名と一致している必要があり、そうでなければロードは失敗します。動的Tableは後述のcolumn_mapping設定をサポートしないことに注意してください。
merge_type句
merge_typeモジュールはデータマージのタイプを指定します。merge_typeには3つのオプションがあります:
-
APPEND: 追記ロードモード。
-
MERGE: マージロードモード。Unique Keyモデルにのみ適用可能。Delete Flagカラムをマークするために[DELETE ON]モジュールと併用する必要があります。
-
DELETE: ロードされるすべてのデータは削除が必要なデータです。
load_properties句
load_propertiesモジュールは以下の構文を使用してロードされるデータのプロパティを記述します:
[COLUMNS TERMINATED BY <column_separator>,]
[COLUMNS (<column1_name>[, <column2_name>, <column_mapping>, ...]),]
[WHERE <where_expr>,]
[PARTITION(<partition1_name>, [<partition2_name>, <partition3_name>, ...]),]
[DELETE ON <delete_expr>,]
[ORDER BY <order_by_column1>[, <order_by_column2>, <order_by_column3>, ...]]
各モジュールの具体的なパラメータは以下の通りです:
| サブモジュール | パラメータ | 説明 |
|---|---|---|
| COLUMNS TERMINATED BY | <column_separator> | カラム区切り文字を指定します。デフォルトは \t です。例えば、カンマを区切り文字として指定するには、COLUMNS TERMINATED BY ","を使用します。空の値を処理する際は、以下の点に注意してください:
|
| COLUMNS | <column_name> | 対応するカラム名を指定します。例えば、ロードするカラムを (k1, k2, k3) として指定するには、COLUMNS(k1, k2, k3) を使用します。COLUMNS句は以下の場合に省略できます:
|
<column_mapping> | ロードプロセス中に、カラムマッピングを使用してカラムのフィルタリングや変換を行うことができます。例えば、対象カラムがデータソースのカラムに基づいて派生計算を実行する必要がある場合(例:対象カラム k4 が k3 カラムに基づいて k3 + 1 として計算される)、COLUMNS(k1, k2, k3, k4 = k3 + 1) を使用できます。詳細については、Data Conversion ドキュメントを参照してください。 | |
| WHERE | <where_expr> | ロードするデータソースをフィルタリングする条件を指定します。例えば、age > 30 のデータのみをロードするには、WHERE age > 30 を使用します。 |
| PARTITION | <partition_name> | 対象Tableのどのパーティションにロードするかを指定します。指定されない場合、自動的に対応するパーティションにロードされます。例えば、対象Tableのパーティション p1 と p2 にロードするには、PARTITION(p1, p2) を使用します。 |
| DELETE ON | <delete_expr> | MERGE ロードモードにおいて、delete_expr を使用してどのカラムを削除する必要があるかをマークします。例えば、MERGE プロセス中に age > 30 のカラムを削除するには、DELETE ON age > 30 を使用します。 |
| ORDER BY | <order_by_column> | Unique Key モデルでのみ有効です。ロードするデータの Sequence Column を指定してデータの順序を保証します。例えば、Unique Key Tableにロードし、create_time を Sequence Column として指定するには、ORDER BY create_time を使用します。Unique Key モデルの Sequence Column の詳細については、Data アップデート/Sequence Columns を参照してください。 |
job_properties 句
job_properties 句は、Routine Load ジョブを作成する際にそのプロパティを指定するために使用されます。構文は以下の通りです:
PROPERTIES ("<key1>" = "<value1>"[, "<key2>" = "<value2>" ...])
job_properties句に使用可能なパラメータは以下の通りです:
| パラメータ | 説明 |
|---|---|
| desired_concurrent_number |
|
| max_batch_interval | 各サブタスクの最大実行時間(秒単位)。0より大きい値である必要があり、デフォルト値は60秒です。max_batch_interval/max_batch_rows/max_batch_sizeは一緒にサブタスクの実行しきい値を構成します。これらのパラメータのいずれかがしきい値に達すると、ロードサブタスクが終了し、新しいものが生成されます。 |
| max_batch_rows | 各サブタスクで読み取る最大行数。200,000以上である必要があります。デフォルト値は20,000,000です。max_batch_interval/max_batch_rows/max_batch_sizeは一緒にサブタスクの実行しきい値を構成します。これらのパラメータのいずれかがしきい値に達すると、ロードサブタスクが終了し、新しいものが生成されます。 |
| max_batch_size | 各サブタスクで読み取る最大バイト数。単位はバイトで、範囲は100MBから10GBです。デフォルト値は1Gです。max_batch_interval/max_batch_rows/max_batch_sizeは一緒にサブタスクの実行しきい値を構成します。これらのパラメータのいずれかがしきい値に達すると、ロードサブタスクが終了し、新しいものが生成されます。 |
| max_error_number | サンプリングウィンドウ内で許可される最大エラー行数。0以上である必要があります。デフォルト値は0で、エラー行が許可されないことを意味します。サンプリングウィンドウはmax_batch_rows * 10です。サンプリングウィンドウ内のエラー行数がmax_error_numberを超えると、通常のジョブは一時停止され、SHOW ROUTINE LOADコマンドとErrorLogUrlsを使用してデータ品質の問題をチェックするための手動介入が必要になります。WHERE条件でフィルタリングされた行はエラー行としてカウントされません。 |
| strict_mode | ストリクトモードを有効にするかどうか。デフォルト値は無効です。ストリクトモードは、ロードプロセス中の型変換に厳密なフィルタリングを適用します。有効にすると、型変換後にNULLになる非null元データがフィルタリングされます。ストリクトモードでのフィルタリングルールは以下の通りです:
|
| timezone | ロードジョブで使用するタイムゾーンを指定します。デフォルトはセッションのtimezoneパラメータを使用します。このパラメータは、ロードに関連するすべてのタイムゾーン関連関数の結果に影響します。 |
| format | ロードのデータ形式を指定します。デフォルトはCSVで、JSON形式がサポートされています。 |
| jsonpaths | データ形式がJSONの場合、jsonpathsを使用してネストした構造からデータを抽出するJSONパスを指定できます。これは文字列のJSON配列で、各文字列はJSONパスを表します。 |
| json_root | JSON形式のデータをインポートする際、json_rootを通じてJSONデータのルートノードを指定できます。Dorisはルートノードから要素を抽出して解析します。デフォルトは空です。例えば、JSONルートノードを指定するには:"json_root" = "$.RECORDS" |
| strip_outer_array | JSON形式のデータをインポートする際、strip_outer_arrayがtrueの場合、JSONデータが配列として表示され、データ内の各要素が1行として扱われることを示します。デフォルト値はfalseです。通常、KafkaのJSONデータは最外層に角括弧[]を持つ配列として表現される場合があります。この場合、"strip_outer_array" = "true"を指定してTopicデータを配列モードで消費できます。例えば、次のデータは2行に解析されます:[{"user_id":1,"name":"Emily","age":25},{"user_id":2,"name":"Benjamin","age":35}] |
| send_batch_parallelism | バッチデータ送信の並列度を設定するために使用されます。並列度の値がBE設定のmax_send_batch_parallelism_per_jobを超える場合、調整BEはmax_send_batch_parallelism_per_jobの値を使用します。 |
| load_to_single_tablet | タスクごとに対応するパーティション内の1つのタブレットのみにデータをインポートすることをサポートします。デフォルト値はfalseです。このパラメータは、ランダムバケティングを持つOLAPTableにデータをインポートする場合にのみ設定できます。 |
| partial_columns | 部分列更新機能を有効にするかどうかを指定します。デフォルト値はfalseです。このパラメータは、TableモデルがUniqueでMerge on Writeを使用している場合にのみ設定できます。マルチTableストリーミングはこのパラメータをサポートしていません。詳細については、Partial Column アップデートを参照してください。 |
| partial_update_new_key_behavior | Unique Merge on WriteTableで部分列更新を実行する際、このパラメータは新しい行の処理方法を制御します。APPENDとERRORの2つのタイプがあります。- APPEND:新しい行データの挿入を許可します- ERROR:新しい行の挿入時に失敗してエラーを報告します |
| max_filter_ratio | サンプリングウィンドウ内で許可される最大フィルタ比率。0から1の間(両端を含む)である必要があります。デフォルト値は1.0で、任意のエラー行を許容できることを示します。サンプリングウィンドウはmax_batch_rows * 10です。サンプリングウィンドウ内のエラー行と総行数の比率がmax_filter_ratioを超えると、ルーチンジョブは中断され、データ品質の問題をチェックするための手動介入が必要になります。WHERE条件でフィルタリングされた行はエラー行としてカウントされません。 |
| enclose | 囲み文字を指定します。CSVデータフィールドに行または列の区切り文字が含まれている場合、偶発的な切り捨てを防ぐために、単一バイト文字を保護用の囲み文字として指定できます。例えば、列区切り文字が「,」で囲み文字が「'」の場合、データ「a,'b,c'」は「b,c」が1つのフィールドとして解析されます。 |
| escape | エスケープ文字を指定します。囲み文字と同じフィールド内の文字をエスケープするために使用されます。例えば、データが「a,'b,'c'」で、囲み文字が「'」であり、「b,'c」を1つのフィールドとして解析したい場合、「\」などの単一バイトエスケープ文字を指定し、データを「a,'b,'c'」に変更する必要があります。 |
これらのパラメータは、特定の要件に応じてRoutine Loadジョブの動作をカスタマイズするために使用できます。
04 data_source_properties句
Routine Loadジョブを作成する際、data_source_properties句を指定してKafkaデータソースのプロパティを指定できます。構文は以下の通りです:
FROM KAFKA ("<key1>" = "<value1>"[, "<key2>" = "<value2>" ...])
data_source_properties句で使用可能なオプションは以下の通りです:
| パラメータ | 説明 |
|---|---|
| kafka_broker_list | Kafkaブローカーの接続情報を指定します。形式は<kafka_broker_ip>:<kafka_port>です。複数のブローカーはカンマで区切ります。例えば、デフォルトポート9092でBroker Listを指定する場合、以下のコマンドを使用できます:"kafka_broker_list" = "<broker1_ip>:9092,<broker2_ip>:9092" |
| kafka_topic | 購読するKafkaトピックを指定します。ロードジョブは1つのKafkaトピックのみを消費できます。 |
| kafka_partitions | 購読するKafkaパーティションを指定します。指定されない場合、デフォルトですべてのパーティションが消費されます。 |
| kafka_offsets | Kafkaパーティションの消費開始オフセットを指定します。タイムスタンプが指定された場合、そのタイムスタンプ以上の最も近いオフセットから消費を開始します。オフセットは0以上の特定のオフセットにするか、以下の形式を使用できます:
|
| property | カスタムKafkaパラメータを指定します。これはKafka shellの"--property"パラメータと同等です。パラメータの値がファイルの場合、値の前にキーワード"FILE:"を追加する必要があります。ファイルの作成については、CREATE FILEコマンドドキュメントを参照してください。サポートされているカスタムパラメータの詳細については、librdkafkaの公式CONFIGURATIONドキュメントのクライアント側設定オプションを参照してください。例:"property.client.id" = "12345"、"property.group.id" = "group_id_0"、"property.ssl.ca.location" = "FILE:ca.pem" |
data_source_propertiesでKafka propertyパラメータを設定することで、セキュリティアクセスオプションを設定できます。現在、Dorisはplaintext(デフォルト)、SSL、PLAIN、Kerberosなどの様々なKafkaセキュリティプロトコルをサポートしています。
ロードステータス
SHOW ROUTINE LOADコマンドを使用してロードジョブのステータスを確認できます。コマンドの構文は以下の通りです:
SHOW [ALL] ROUTINE LOAD [FOR jobName];
例えば、SHOW ROUTINE LOADを実行すると、以下のような結果セットが返されます:
mysql> SHOW ROUTINE LOAD FOR testdb.example_routine_load\G
*************************** 1. row ***************************
Id: 12025
Name: example_routine_load
CreateTime: 2024-01-15 08:12:42
PauseTime: NULL
EndTime: NULL
DbName: default_cluster:testdb
TableName: test_routineload_tbl
IsMultiTable: false
State: RUNNING
DataSourceType: KAFKA
CurrentTaskNum: 1
JobProperties: {"max_batch_rows":"200000","timezone":"America/New_York","send_batch_parallelism":"1","load_to_single_tablet":"false","column_separator":"','","line_delimiter":"\n","current_concurrent_number":"1","delete":"*","partial_columns":"false","merge_type":"APPEND","exec_mem_limit":"2147483648","strict_mode":"false","jsonpaths":"","max_batch_interval":"10","max_batch_size":"104857600","fuzzy_parse":"false","partitions":"*","columnToColumnExpr":"user_id,name,age","whereExpr":"*","desired_concurrent_number":"5","precedingFilter":"*","format":"csv","max_error_number":"0","max_filter_ratio":"1.0","json_root":"","strip_outer_array":"false","num_as_string":"false"}
DataSourceProperties: {"topic":"test-topic","currentKafkaPartitions":"0","brokerList":"192.168.88.62:9092"}
CustomProperties: {"kafka_default_offsets":"OFFSET_BEGINNING","group.id":"example_routine_load_73daf600-884e-46c0-a02b-4e49fdf3b4dc"}
Statistic: {"receivedBytes":28,"runningTxns":[],"errorRows":0,"committedTaskNum":3,"loadedRows":3,"loadRowsRate":0,"abortedTaskNum":0,"errorRowsAfterResumed":0,"totalRows":3,"unselectedRows":0,"receivedBytesRate":0,"taskExecuteTimeMs":30069}
Progress: {"0":"2"}
Lag: {"0":0}
ReasonOfStateChanged:
ErrorLogUrls:
OtherMsg:
User: root
Comment:
1 row in set (0.00 sec)
結果セットの列は以下の情報を提供します:
| Column Name | デスクリプション |
|---|---|
| Id | Dorisによって自動生成される、ロードジョブのIDです。 |
| Name | ロードジョブの名前です。 |
| CreateTime | ジョブが作成された時刻です。 |
| PauseTime | ジョブが最後に一時停止された時刻です。 |
| EndTime | ジョブが終了した時刻です。 |
| DbName | 関連付けられたデータベースの名前です。 |
| TableName | 関連付けられたTableの名前です。マルチTableシナリオの場合、"multi-table"として表示されます。 |
| IsMultiTbl | マルチTableロードかどうかを示します。 |
| State | ジョブの実行状態で、5つの値を取ることができます:
|
| DataSourceType | この例では、KAFKAであるデータソースのタイプです。 |
| CurrentTaskNum | サブタスクの現在の数です。 |
| JobProperties | ジョブ設定の詳細です。 |
| DataSourceProperties | データソース設定の詳細です。 |
| CustomProperties | カスタム設定プロパティです。 |
| Statistic | ジョブの実行ステータスの統計です。 |
| Progress | ジョブの進捗状況です。Kafkaデータソースの場合、各パーティションで消費されたoffsetを表示します。例えば、{"0":"2"}はパーティション0が2つのoffsetを消費したことを示します。 |
| Lag | ジョブのlagです。Kafkaデータソースの場合、各パーティションの消費lagを表示します。例えば、{"0":10}はパーティション0の消費lagが10であることを示します。 |
| ReasonOfStateChanged | ジョブの状態変更の理由です。 |
| ErrorLogUrls | フィルタリングされた低品質データを表示するURLです。 |
| OtherMsg | その他のエラーメッセージです。 |
ロード例
最大エラー許容値の設定
-
サンプルデータをロード:
1,Benjamin,18
2,Emily,20
3,Alexander,dirty_data -
Tableの作成:
CREATE TABLE demo.routine_test01 (
id INT NOT NULL COMMENT "User ID",
name VARCHAR(30) NOT NULL COMMENT "Name",
age INT COMMENT "Age"
)
DUPLICATE KEY(`id`)
DISTRIBUTED BY HASH(`id`) BUCKETS 1; -
Loadコマンド:
CREATE ROUTINE LOAD demo.kafka_job01 ON routine_test01
COLUMNS TERMINATED BY ","
PROPERTIES
(
"max_filter_ratio"="0.5",
"max_error_number" = "100",
"strict_mode" = "true"
)
FROM KAFKA
(
"kafka_broker_list" = "10.16.10.6:9092",
"kafka_topic" = "routineLoad01",
"property.kafka_default_offsets" = "OFFSET_BEGINNING"
); -
結果の読み込み:
mysql> select * from routine_test01;
+------+------------+------+
| id | name | age |
+------+------------+------+
| 1 | Benjamin | 18 |
| 2 | Emily | 20 |
+------+------------+------+
2 rows in set (0.01 sec)
指定されたOffsetからのデータ消費
-
サンプルデータを読み込む:
1,Benjamin,18
2,Emily,20
3,Alexander,22
4,Sophia,24
5,William,26
6,Charlotte,28 -
Tableの作成:
CREATE TABLE demo.routine_test02 (
id INT NOT NULL COMMENT "User ID",
name VARCHAR(30) NOT NULL COMMENT "Name",
age INT COMMENT "Age"
)
DUPLICATE KEY(`id`)
DISTRIBUTED BY HASH(`id`) BUCKETS 1; -
Loadコマンド:
CREATE ROUTINE LOAD demo.kafka_job02 ON routine_test02
COLUMNS TERMINATED BY ","
FROM KAFKA
(
"kafka_broker_list" = "10.16.10.6:9092",
"kafka_topic" = "routineLoad02",
"kafka_partitions" = "0",
"kafka_offsets" = "3"
); -
読み込み結果:
mysql> select * from routine_test02;
+------+--------------+------+
| id | name | age |
+------+--------------+------+
| 4 | Sophia | 24 |
| 5 | William | 26 |
| 6 | Charlotte | 28 |
+------+--------------+------+
3 rows in set (0.01 sec)
Consumer Groupのgroup.idとclient.idの指定
-
サンプルデータをロードします:
1,Benjamin,18
2,Emily,20
3,Alexander,22 -
Tableを作成する:
CREATE TABLE demo.routine_test03 (
id INT NOT NULL COMMENT "User ID",
name VARCHAR(30) NOT NULL COMMENT "Name",
age INT COMMENT "Age"
)
DUPLICATE KEY(`id`)
DISTRIBUTED BY HASH(`id`) BUCKETS 1; -
Loadコマンド:
CREATE ROUTINE LOAD demo.kafka_job03 ON routine_test03
COLUMNS TERMINATED BY ","
FROM KAFKA
(
"kafka_broker_list" = "10.16.10.6:9092",
"kafka_topic" = "routineLoad01",
"property.group.id" = "kafka_job03",
"property.client.id" = "kafka_client_03",
"property.kafka_default_offsets" = "OFFSET_BEGINNING"
); -
読み込み結果:
mysql> select * from routine_test03;
+------+------------+------+
| id | name | age |
+------+------------+------+
| 1 | Benjamin | 18 |
| 2 | Emily | 20 |
| 3 | Alexander | 22 |
+------+------------+------+
3 rows in set (0.01 sec)
ロード時のフィルタリング条件の設定
-
サンプルデータをロードする:
1,Benjamin,18
2,Emily,20
3,Alexander,22
4,Sophia,24
5,William,26
6,Charlotte,28 -
Tableを作成する:
CREATE TABLE demo.routine_test04 (
id INT NOT NULL COMMENT "User ID",
name VARCHAR(30) NOT NULL COMMENT "Name",
age INT COMMENT "Age"
)
DUPLICATE KEY(`id`)
DISTRIBUTED BY HASH(`id`) BUCKETS 1; -
ロードコマンド:
CREATE ROUTINE LOAD demo.kafka_job04 ON routine_test04
COLUMNS TERMINATED BY ",",
WHERE id >= 3
FROM KAFKA
(
"kafka_broker_list" = "10.16.10.6:9092",
"kafka_topic" = "routineLoad04",
"property.kafka_default_offsets" = "OFFSET_BEGINNING"
); -
結果の読み込み:
mysql> select * from routine_test04;
+------+--------------+------+
| id | name | age |
+------+--------------+------+
| 4 | Sophia | 24 |
| 5 | William | 26 |
| 6 | Charlotte | 28 |
+------+--------------+------+
3 rows in set (0.01 sec)
指定されたパーティションデータの読み込み
-
サンプルデータを読み込みます:
1,Benjamin,18,2024-02-04 10:00:00
2,Emily,20,2024-02-05 11:00:00
3,Alexander,22,2024-02-06 12:00:00 -
Tableを作成:
CREATE TABLE demo.routine_test05 (
id INT NOT NULL COMMENT "ID",
name VARCHAR(30) NOT NULL COMMENT "Name",
age INT COMMENT "Age",
date DATETIME COMMENT "Date"
)
DUPLICATE KEY(`id`)
PARTITION BY RANGE(`id`)
(PARTITION partition_a VALUES [("0"), ("1")),
PARTITION partition_b VALUES [("1"), ("2")),
PARTITION partition_c VALUES [("2"), ("3")))
DISTRIBUTED BY HASH(`id`) BUCKETS 1; -
Load コマンド:
CREATE ROUTINE LOAD demo.kafka_job05 ON routine_test05
COLUMNS TERMINATED BY ",",
PARTITION(partition_b)
FROM KAFKA
(
"kafka_broker_list" = "10.16.10.6:9092",
"kafka_topic" = "routineLoad05",
"property.kafka_default_offsets" = "OFFSET_BEGINNING"
); -
読み込み結果:
mysql> select * from routine_test05;
+------+----------+------+---------------------+
| id | name | age | date |
+------+----------+------+---------------------+
| 1 | Benjamin | 18 | 2024-02-04 10:00:00 |
+------+----------+------+---------------------+
1 rows in set (0.01 sec)
load の時刻設定
-
サンプルデータをロードする:
1,Benjamin,18,2024-02-04 10:00:00
2,Emily,20,2024-02-05 11:00:00
3,Alexander,22,2024-02-06 12:00:00 -
Tableの作成:
CREATE TABLE demo.routine_test06 (
id INT NOT NULL COMMENT "id",
name VARCHAR(30) NOT NULL COMMENT "name",
age INT COMMENT "age",
date DATETIME COMMENT "date"
)
DUPLICATE KEY(id)
DISTRIBUTED BY HASH(id) BUCKETS 1; -
Loadコマンド:
CREATE ROUTINE LOAD demo.kafka_job06 ON routine_test06
COLUMNS TERMINATED BY ","
PROPERTIES
(
"timezone" = "Asia/Shanghai"
)
FROM KAFKA
(
"kafka_broker_list" = "10.16.10.6:9092",
"kafka_topic" = "routineLoad06",
"property.kafka_default_offsets" = "OFFSET_BEGINNING"
); -
読み込み結果:
mysql> select * from routine_test06;
+------+-------------+------+---------------------+
| id | name | age | date |
+------+-------------+------+---------------------+
| 1 | Benjamin | 18 | 2024-02-04 10:00:00 |
| 2 | Emily | 20 | 2024-02-05 11:00:00 |
| 3 | Alexander | 22 | 2024-02-06 12:00:00 |
+------+-------------+------+---------------------+
3 rows in set (0.00 sec)
Setting merge_type
delete操作に対するmerge_typeの指定
-
サンプルデータの読み込み:
3,Alexander,22
5,William,26
Tableデータロード前:
```sql
mysql> SELECT * FROM routine_test07;
+------+----------------+------+
| id | name | age |
+------+----------------+------+
| 1 | Benjamin | 18 |
| 2 | Emily | 20 |
| 3 | Alexander | 22 |
| 4 | Sophia | 24 |
| 5 | William | 26 |
| 6 | Charlotte | 28 |
+------+----------------+------+
```
2. Tableを作成する:
```sql
CREATE TABLE demo.routine_test07 (
id INT NOT NULL COMMENT "id",
name VARCHAR(30) NOT NULL COMMENT "name",
age INT COMMENT "age"
)
UNIQUE KEY(id)
DISTRIBUTED BY HASH(id) BUCKETS 1;
```
3. Load コマンド:
```sql
CREATE ROUTINE LOAD demo.kafka_job07 ON routine_test07
WITH DELETE
COLUMNS TERMINATED BY ","
FROM KAFKA
(
"kafka_broker_list" = "10.16.10.6:9092",
"kafka_topic" = "routineLoad07",
"property.kafka_default_offsets" = "OFFSET_BEGINNING"
);
```
4. 読み込み結果:
```sql
mysql> SELECT * FROM routine_test07;
+------+----------------+------+
| id | name | age |
+------+----------------+------+
| 1 | Benjamin | 18 |
| 2 | Emily | 20 |
| 4 | Sophia | 24 |
| 6 | Charlotte | 28 |
+------+----------------+------+
```
merge操作でmerge_typeを指定する
-
サンプルデータを読み込む:
1,xiaoxiaoli,28
2,xiaoxiaowang,30
3,xiaoxiaoliu,32
4,dadali,34
5,dadawang,36
6,dadaliu,38
Tableデータ(ロード前):
```sql
mysql> SELECT * FROM routine_test08;
+------+----------------+------+
| id | name | age |
+------+----------------+------+
| 1 | Benjamin | 18 |
| 2 | Emily | 20 |
| 3 | Alexander | 22 |
| 4 | Sophia | 24 |
| 5 | William | 26 |
| 6 | Charlotte | 28 |
+------+----------------+------+
6 rows in set (0.01 sec)
```
2. Tableの作成:
```sql
CREATE TABLE demo.routine_test08 (
id INT NOT NULL COMMENT "id",
name VARCHAR(30) NOT NULL COMMENT "name",
age INT COMMENT "age"
)
UNIQUE KEY(id)
DISTRIBUTED BY HASH(id) BUCKETS 1;
```
3. Loadコマンド:
```sql
CREATE ROUTINE LOAD demo.kafka_job08 ON routine_test08
WITH MERGE
COLUMNS TERMINATED BY ",",
DELETE ON id = 2
FROM KAFKA
(
"kafka_broker_list" = "10.16.10.6:9092",
"kafka_topic" = "routineLoad08",
"property.kafka_default_offsets" = "OFFSET_BEGINNING"
);
```
4. 読み込み結果:
```sql
mysql> SELECT * FROM routine_test08;
+------+-------------+------+
| id | name | age |
+------+-------------+------+
| 1 | xiaoxiaoli | 28 |
| 3 | xiaoxiaoliu | 32 |
| 4 | dadali | 34 |
| 5 | dadawang | 36 |
| 6 | dadaliu | 38 |
+------+-------------+------+
5 rows in set (0.00 sec)
```
マージする順序列の指定
-
サンプルデータを読み込む:
1,xiaoxiaoli,28
2,xiaoxiaowang,30
3,xiaoxiaoliu,32
4,dadali,34
5,dadawang,36
6,dadaliu,38
Table内のデータ(ロード前):
```sql
mysql> SELECT * FROM routine_test09;
+------+----------------+------+
| id | name | age |
+------+----------------+------+
| 1 | Benjamin | 18 |
| 2 | Emily | 20 |
| 3 | Alexander | 22 |
| 4 | Sophia | 24 |
| 5 | William | 26 |
| 6 | Charlotte | 28 |
+------+----------------+------+
6 rows in set (0.01 sec)
```
2. Tableを作成する
```sql
CREATE TABLE demo.routine_test08 (
id INT NOT NULL COMMENT "id",
name VARCHAR(30) NOT NULL COMMENT "name",
age INT COMMENT "age",
)
UNIQUE KEY(id)
DISTRIBUTED BY HASH(id) BUCKETS 1
PROPERTIES (
"function_column.sequence_col" = "age"
);
```
3. Loadコマンド
```sql
CREATE ROUTINE LOAD demo.kafka_job09 ON routine_test09
WITH MERGE
COLUMNS TERMINATED BY ",",
COLUMNS(id, name, age),
DELETE ON id = 2,
ORDER BY age
PROPERTIES
(
"desired_concurrent_number"="1",
"strict_mode" = "false"
)
FROM KAFKA
(
"kafka_broker_list" = "10.16.10.6:9092",
"kafka_topic" = "routineLoad09",
"property.kafka_default_offsets" = "OFFSET_BEGINNING"
);
```
4. 読み込み結果:
```sql
mysql> SELECT * FROM routine_test09;
+------+-------------+------+
| id | name | age |
+------+-------------+------+
| 1 | xiaoxiaoli | 28 |
| 3 | xiaoxiaoliu | 32 |
| 4 | dadali | 34 |
| 5 | dadawang | 36 |
| 6 | dadaliu | 38 |
+------+-------------+------+
5 rows in set (0.00 sec)
```
列マッピングと派生列計算を使用した読み込み
-
サンプルデータを読み込む:
1,Benjamin,18
2,Emily,20
3,Alexander,22 -
Tableを作成:
CREATE TABLE demo.routine_test10 (
id INT NOT NULL COMMENT "id",
name VARCHAR(30) NOT NULL COMMENT "name",
age INT COMMENT "age",
num INT COMMENT "number"
)
DUPLICATE KEY(`id`)
DISTRIBUTED BY HASH(`id`) BUCKETS 1; -
Loadコマンド:
CREATE ROUTINE LOAD demo.kafka_job10 ON routine_test10
COLUMNS TERMINATED BY ",",
COLUMNS(id, name, age, num=age*10)
FROM KAFKA
(
"kafka_broker_list" = "10.16.10.6:9092",
"kafka_topic" = "routineLoad10",
"property.kafka_default_offsets" = "OFFSET_BEGINNING"
); -
読み込み結果:
mysql> SELECT * FROM routine_test10;
+------+----------------+------+------+
| id | name | age | num |
+------+----------------+------+------+
| 1 | Benjamin | 18 | 180 |
| 2 | Emily | 20 | 200 |
| 3 | Alexander | 22 | 220 |
+------+----------------+------+------+
3 rows in set (0.01 sec)
囲まれたデータでロード
-
サンプルデータをロード:
1,"Benjamin",18
2,"Emily",20
3,"Alexander",22 -
Tableを作成する:
CREATE TABLE demo.routine_test11 (
id INT NOT NULL COMMENT "id",
name VARCHAR(30) NOT NULL COMMENT "name",
age INT COMMENT "age",
num INT COMMENT "number"
)
DUPLICATE KEY(`id`)
DISTRIBUTED BY HASH(`id`) BUCKETS 1; -
Loadコマンド:
CREATE ROUTINE LOAD demo.kafka_job11 ON routine_test11
COLUMNS TERMINATED BY ","
PROPERTIES
(
"desired_concurrent_number"="1",
"enclose" = "\""
)
FROM KAFKA
(
"kafka_broker_list" = "10.16.10.6:9092",
"kafka_topic" = "routineLoad12",
"property.kafka_default_offsets" = "OFFSET_BEGINNING"
); -
読み込み結果:
mysql> SELECT * FROM routine_test11;
+------+----------------+------+------+
| id | name | age | num |
+------+----------------+------+------+
| 1 | Benjamin | 18 | 180 |
| 2 | Emily | 20 | 200 |
| 3 | Alexander | 22 | 220 |
+------+----------------+------+------+
3 rows in set (0.02 sec)
JSON Format Load
simple modeでJSON format dataを読み込み
-
サンプルデータを読み込み:
{ "id" : 1, "name" : "Benjamin", "age":18 }
{ "id" : 2, "name" : "Emily", "age":20 }
{ "id" : 3, "name" : "Alexander", "age":22 } -
Tableを作成する:
CREATE TABLE demo.routine_test12 (
id INT NOT NULL COMMENT "id",
name VARCHAR(30) NOT NULL COMMENT "name",
age INT COMMENT "age"
)
DUPLICATE KEY(`id`)
DISTRIBUTED BY HASH(`id`) BUCKETS 1; -
Loadコマンド:
CREATE ROUTINE LOAD demo.kafka_job12 ON routine_test12
PROPERTIES
(
"format" = "json"
)
FROM KAFKA
(
"kafka_broker_list" = "10.16.10.6:9092",
"kafka_topic" = "routineLoad12",
"property.kafka_default_offsets" = "OFFSET_BEGINNING"
); -
読み込み結果:
mysql> select * from routine_test12;
+------+----------------+------+
| id | name | age |
+------+----------------+------+
| 1 | Benjamin | 18 |
| 2 | Emily | 20 |
| 3 | Alexander | 22 |
+------+----------------+------+
3 rows in set (0.02 sec)
match モードで複雑な JSON 形式データを読み込む
-
サンプルデータの読み込み
{ "name" : "Benjamin", "id" : 1, "num":180 , "age":18 }
{ "name" : "Emily", "id" : 2, "num":200 , "age":20 }
{ "name" : "Alexander", "id" : 3, "num":220 , "age":22 } -
Tableの作成:
CREATE TABLE demo.routine_test13 (
id INT NOT NULL COMMENT "id",
name VARCHAR(30) NOT NULL COMMENT "name",
age INT COMMENT "age",
num INT COMMENT "num"
)
DUPLICATE KEY(`id`)
DISTRIBUTED BY HASH(`id`) BUCKETS 1; -
Loadコマンド:
CREATE ROUTINE LOAD demo.kafka_job13 ON routine_test13
COLUMNS(name, id, num, age)
PROPERTIES
(
"format" = "json",
"jsonpaths" = "[\"$.name\",\"$.id\",\"$.num\",\"$.age\"]"
)
FROM KAFKA
(
"kafka_broker_list" = "10.16.10.6:9092",
"kafka_topic" = "routineLoad13",
"property.kafka_default_offsets" = "OFFSET_BEGINNING"
); -
読み込み結果:
mysql> select * from routine_test13;
+------+----------------+------+------+
| id | name | age | num |
+------+----------------+------+------+
| 1 | Benjamin | 18 | 180 |
| 2 | Emily | 20 | 200 |
| 3 | Alexander | 22 | 220 |
+------+----------------+------+------+
3 rows in set (0.01 sec)
指定されたJSONルートノードでデータを読み込む
-
サンプルデータを読み込む
{"id": 1231, "source" :{ "id" : 1, "name" : "Benjamin", "age":18 }}
{"id": 1232, "source" :{ "id" : 2, "name" : "Emily", "age":20 }}
{"id": 1233, "source" :{ "id" : 3, "name" : "Alexander", "age":22 }} -
Tableを作成:
CREATE TABLE demo.routine_test14 (
id INT NOT NULL COMMENT "id",
name VARCHAR(30) NOT NULL COMMENT "name",
age INT COMMENT "age"
)
DUPLICATE KEY(`id`)
DISTRIBUTED BY HASH(`id`) BUCKETS 1; -
Load コマンド
CREATE ROUTINE LOAD demo.kafka_job14 ON routine_test14
PROPERTIES
(
"format" = "json",
"json_root" = "$.source"
)
FROM KAFKA
(
"kafka_broker_list" = "10.16.10.6:9092",
"kafka_topic" = "routineLoad14",
"property.kafka_default_offsets" = "OFFSET_BEGINNING"
); -
結果の読み込み
mysql> select * from routine_test14;
+------+----------------+------+
| id | name | age |
+------+----------------+------+
| 1 | Benjamin | 18 |
| 2 | Emily | 20 |
| 3 | Alexander | 22 |
+------+----------------+------+
3 rows in set (0.01 sec)
カラムマッピングと派生カラム計算によるデータの読み込み
-
サンプルデータを読み込む:
{ "id" : 1, "name" : "Benjamin", "age":18 }
{ "id" : 2, "name" : "Emily", "age":20 }
{ "id" : 3, "name" : "Alexander", "age":22 } -
Tableを作成:
CREATE TABLE demo.routine_test15 (
id INT NOT NULL COMMENT "id",
name VARCHAR(30) NOT NULL COMMENT "name",
age INT COMMENT "age",
num INT COMMENT "num"
)
DUPLICATE KEY(`id`)
DISTRIBUTED BY HASH(`id`) BUCKETS 1; -
Loadコマンド:
CREATE ROUTINE LOAD demo.kafka_job15 ON routine_test15
COLUMNS(id, name, age, num=age*10)
PROPERTIES
(
"format" = "json",
)
FROM KAFKA
(
"kafka_broker_list" = "10.16.10.6:9092",
"kafka_topic" = "routineLoad15",
"property.kafka_default_offsets" = "OFFSET_BEGINNING"
); -
読み込み結果:
mysql> select * from routine_test15;
+------+----------------+------+------+
| id | name | age | num |
+------+----------------+------+------+
| 1 | Benjamin | 18 | 180 |
| 2 | Emily | 20 | 200 |
| 3 | Alexander | 22 | 220 |
+------+----------------+------+------+
3 rows in set (0.01 sec)
複雑なデータ型の読み込み
配列データ型の読み込み
-
サンプルデータを読み込む:
{ "id" : 1, "name" : "Benjamin", "age":18, "array":[1,2,3,4,5]}
{ "id" : 2, "name" : "Emily", "age":20, "array":[6,7,8,9,10]}
{ "id" : 3, "name" : "Alexander", "age":22, "array":[11,12,13,14,15]} -
Tableの作成:
CREATE TABLE demo.routine_test16
(
id INT NOT NULL COMMENT "id",
name VARCHAR(30) NOT NULL COMMENT "name",
age INT COMMENT "age",
array ARRAY<int(11)> NULL COMMENT "test array column"
)
DUPLICATE KEY(`id`)
DISTRIBUTED BY HASH(`id`) BUCKETS 1; -
ロードコマンド:
CREATE ROUTINE LOAD demo.kafka_job16 ON routine_test16
PROPERTIES
(
"format" = "json"
)
FROM KAFKA
(
"kafka_broker_list" = "10.16.10.6:9092",
"kafka_topic" = "routineLoad16",
"property.kafka_default_offsets" = "OFFSET_BEGINNING"
); -
結果の読み込み:
mysql> select * from routine_test16;
+------+----------------+------+----------------------+
| id | name | age | array |
+------+----------------+------+----------------------+
| 1 | Benjamin | 18 | [1, 2, 3, 4, 5] |
| 2 | Emily | 20 | [6, 7, 8, 9, 10] |
| 3 | Alexander | 22 | [11, 12, 13, 14, 15] |
+------+----------------+------+----------------------+
3 rows in set (0.00 sec)
マップデータ型の読み込み
-
サンプルデータを読み込む:
{ "id" : 1, "name" : "Benjamin", "age":18, "map":{"a": 100, "b": 200}}
{ "id" : 2, "name" : "Emily", "age":20, "map":{"c": 300, "d": 400}}
{ "id" : 3, "name" : "Alexander", "age":22, "map":{"e": 500, "f": 600}} -
Tableを作成する:
CREATE TABLE demo.routine_test17 (
id INT NOT NULL COMMENT "id",
name VARCHAR(30) NOT NULL COMMENT "name",
age INT COMMENT "age",
map Map<STRING, INT> NULL COMMENT "test column"
)
DUPLICATE KEY(`id`)
DISTRIBUTED BY HASH(`id`) BUCKETS 1; -
Loadコマンド:
CREATE ROUTINE LOAD demo.kafka_job17 ON routine_test17
PROPERTIES
(
"format" = "json"
)
FROM KAFKA
(
"kafka_broker_list" = "10.16.10.6:9092",
"kafka_topic" = "routineLoad17",
"property.kafka_default_offsets" = "OFFSET_BEGINNING"
); -
ロード結果:
mysql> select * from routine_test17;
+------+----------------+------+--------------------+
| id | name | age | map |
+------+----------------+------+--------------------+
| 1 | Benjamin | 18 | {"a":100, "b":200} |
| 2 | Emily | 20 | {"c":300, "d":400} |
| 3 | Alexander | 22 | {"e":500, "f":600} |
+------+----------------+------+--------------------+
3 rows in set (0.01 sec)
Bitmapデータタイプの読み込み
-
サンプルデータを読み込む
{ "id" : 1, "name" : "Benjamin", "age":18, "bitmap_id":243}
{ "id" : 2, "name" : "Emily", "age":20, "bitmap_id":28574}
{ "id" : 3, "name" : "Alexander", "age":22, "bitmap_id":8573} -
Tableの作成:
CREATE TABLE demo.routine_test18 (
id INT NOT NULL COMMENT "id",
name VARCHAR(30) NOT NULL COMMENT "name",
age INT COMMENT "age",
bitmap_id INT COMMENT "test",
device_id BITMAP BITMAP_UNION COMMENT "test column"
)
AGGREGATE KEY (`id`,`name`,`age`,`bitmap_id`)
DISTRIBUTED BY HASH(`id`) BUCKETS 1; -
Load コマンド:
CREATE ROUTINE LOAD demo.kafka_job18 ON routine_test18
COLUMNS(id, name, age, bitmap_id, device_id=to_bitmap(bitmap_id))
PROPERTIES
(
"format" = "json"
)
FROM KAFKA
(
"kafka_broker_list" = "10.16.10.6:9092",
"kafka_topic" = "routineLoad18",
"property.kafka_default_offsets" = "OFFSET_BEGINNING"
); -
読み込み結果:
mysql> select id, BITMAP_UNION_COUNT(pv) over(order by id) uv from(
-> select id, BITMAP_UNION(device_id) as pv
-> from routine_test18
-> group by id
-> ) final;
+------+------+
| id | uv |
+------+------+
| 1 | 1 |
| 2 | 2 |
| 3 | 3 |
+------+------+
3 rows in set (0.00 sec)
HLL Data タイプ の読み込み
-
サンプルデータの読み込み:
2022-05-05,10001,Test01,Beijing,windows
2022-05-05,10002,Test01,Beijing,linux
2022-05-05,10003,Test01,Beijing,macos
2022-05-05,10004,Test01,Hebei,windows
2022-05-06,10001,Test01,Shanghai,windows
2022-05-06,10002,Test01,Shanghai,linux
2022-05-06,10003,Test01,Jiangsu,macos
2022-05-06,10004,Test01,Shaanxi,windows -
Tableを作成:
create table demo.routine_test19 (
dt DATE,
id INT,
name VARCHAR(10),
province VARCHAR(10),
os VARCHAR(10),
pv hll hll_union
)
Aggregate KEY (dt,id,name,province,os)
distributed by hash(id) buckets 10; -
Load コマンド:
CREATE ROUTINE LOAD demo.kafka_job19 ON routine_test19
COLUMNS TERMINATED BY ",",
COLUMNS(dt, id, name, province, os, pv=hll_hash(id))
FROM KAFKA
(
"kafka_broker_list" = "10.16.10.6:9092",
"kafka_topic" = "routineLoad19",
"property.kafka_default_offsets" = "OFFSET_BEGINNING"
); -
読み込み結果:
mysql> select * from routine_test19;
+------------+-------+----------+----------+---------+------+
| dt | id | name | province | os | pv |
+------------+-------+----------+----------+---------+------+
| 2022-05-05 | 10001 | Test01 | Beijing | windows | NULL |
| 2022-05-06 | 10001 | Test01 | Shanghai | windows | NULL |
| 2022-05-05 | 10002 | Test01 | Beijing | linux | NULL |
| 2022-05-06 | 10002 | Test01 | Shanghai | linux | NULL |
| 2022-05-05 | 10004 | Test01 | Hebei | windows | NULL |
| 2022-05-06 | 10004 | Test01 | Shaanxi | windows | NULL |
| 2022-05-05 | 10003 | Test01 | Beijing | macos | NULL |
| 2022-05-06 | 10003 | Test01 | Jiangsu | macos | NULL |
+------------+-------+----------+----------+---------+------+
8 rows in set (0.01 sec)
mysql> SELECT HLL_UNION_AGG(pv) FROM routine_test19;
+-------------------+
| hll_union_agg(pv) |
+-------------------+
| 4 |
+-------------------+
1 row in set (0.01 sec)
Kafka Security 認証
SSL認証を使用したKafkaデータの読み込み
読み込みコマンドの例:
CREATE ROUTINE LOAD demo.kafka_job20 ON routine_test20
PROPERTIES
(
"format" = "json"
)
FROM KAFKA
(
"kafka_broker_list" = "192.168.100.129:9092",
"kafka_topic" = "routineLoad21",
"property.security.protocol" = "ssl",
"property.ssl.ca.location" = "FILE:ca.pem",
"property.ssl.certificate.location" = "FILE:client.pem",
"property.ssl.key.location" = "FILE:client.key",
"property.ssl.key.password" = "ssl_passwd"
);
パラメータの説明:
| Parameter | デスクリプション |
|---|---|
| property.security.protocol | 使用するセキュリティプロトコル、この例ではSSLです |
| property.ssl.ca.location | CA(証明書機関)証明書の場所 |
| property.ssl.certificate.location | クライアントの公開鍵の場所(Kafkaサーバーでクライアント認証が有効になっている場合に必要) |
| property.ssl.key.location | クライアントの秘密鍵の場所(Kafkaサーバーでクライアント認証が有効になっている場合に必要) |
| property.ssl.key.password | クライアントの秘密鍵のパスワード(Kafkaサーバーでクライアント認証が有効になっている場合に必要) |
Kerberos認証を使用したKafkaデータの読み込み
読み込みコマンドの例:
CREATE ROUTINE LOAD demo.kafka_job21 ON routine_test21
PROPERTIES
(
"format" = "json"
)
FROM KAFKA
(
"kafka_broker_list" = "192.168.100.129:9092",
"kafka_topic" = "routineLoad21",
"property.security.protocol" = "SASL_PLAINTEXT",
"property.sasl.kerberos.service.name" = "kafka",
"property.sasl.kerberos.keytab"="/opt/third/kafka/kerberos/kafka_client.keytab",
"property.sasl.kerberos.principal" = "clients/stream.dt.local@EXAMPLE.COM"
);
パラメータの説明:
| Parameter | デスクリプション |
|---|---|
| property.security.protocol | 使用するセキュリティプロトコル、この例ではSASL_PLAINTEXTです |
| property.sasl.kerberos.service.name | ブローカーサービス名を指定します、デフォルトはKafkaです |
| property.sasl.kerberos.keytab | keytabファイルの場所 |
| property.sasl.kerberos.principal | Kerberosプリンシパルを指定します |
PLAIN認証を使用したKafkaクラスターの読み込み
- 読み込みコマンドの例:
CREATE ROUTINE LOAD demo.kafka_job22 ON routine_test22
PROPERTIES
(
"format" = "json"
)
FROM KAFKA
(
"kafka_broker_list" = "192.168.100.129:9092",
"kafka_topic" = "routineLoad22",
"property.security.protocol"="SASL_PLAINTEXT",
"property.sasl.mechanism"="PLAIN",
"property.sasl.username"="admin",
"property.sasl.password"="admin"
);
パラメータの説明:
| パラメータ | 説明 |
|---|---|
| property.security.protocol | 使用されるセキュリティプロトコル、この例ではSASL_PLAINTEXTです |
| property.sasl.mechanism | SASL認証メカニズムをPLAINとして指定します |
| property.sasl.username | SASLのユーザー名 |
| property.sasl.password | SASLのパスワード |
単一タスクによる複数Tableへの読み込み
"example_db"に対して"test1"という名前のKafkaルーチン動的Table読み込みタスクを作成します。カラム区切り文字、group.id、client.idを指定します。すべてのパーティションを自動的に消費し、利用可能なデータ位置(OFFSET_BEGINNING)から購読を開始します。
Kafkaから"example_db"の"tbl1"と"tbl2"Tableにデータを読み込む必要があると仮定し、"test1"という名前のRoutine Loadタスクを作成します。このタスクはKafkaのトピックmy_topicから"tbl1"と"tbl2"の両方に同時にデータを読み込みます。このようにして、単一のroutine loadタスクを使用してKafkaから2つのTableにデータを読み込むことができます。
CREATE ROUTINE LOAD example_db.test1
FROM KAFKA
(
"kafka_broker_list" = "broker1:9092,broker2:9092,broker3:9092",
"kafka_topic" = "my_topic",
"property.kafka_default_offsets" = "OFFSET_BEGINNING"
);
現在、KafkaのValueフィールドからTable名を抽出することのみがサポートされています。形式は以下のようにする必要があり、JSONを例として使用します:table_name|{"col1": "val1", "col2": "val2"}、ここでtbl_nameはTable名であり、|はTable名とTableデータの間のセパレータとして使用されます。同じ形式がCSVデータにも適用され、例えばtable_name|val1,val2,val3のようになります。ここでのtable_nameはDorisのTable名と一致している必要があり、そうでなければロードは失敗します。動的Tableは後述するcolumn_mapping設定をサポートしないことに注意してください。
Strict Mode Load
"example_db"と"example_tbl"に対して"test1"という名前のKafka routine loadタスクを作成します。ロードタスクはstrict modeに設定されます。
CREATE ROUTINE LOAD example_db.test1 ON example_tbl
COLUMNS(k1, k2, k3, v1, v2, v3 = k1 * 100),
PRECEDING FILTER k1 = 1,
WHERE k1 < 100 and k2 like "%doris%"
PROPERTIES
(
"strict_mode" = "true"
)
FROM KAFKA
(
"kafka_broker_list" = "broker1:9092,broker2:9092,broker3:9092",
"kafka_topic" = "my_topic"
);
SASL Kafka サービスへの接続
ここでは、StreamNative メッセージサービスにアクセスする例を示します:
CREATE ROUTINE LOAD example_db.test1 ON example_tbl
COLUMNS(user_id, name, age)
FROM KAFKA (
"kafka_broker_list" = "pc-xxxx.aws-mec1-test-xwiqv.aws.snio.cloud:9093",
"kafka_topic" = "my_topic",
"property.security.protocol" = "SASL_SSL",
"property.sasl.mechanism" = "PLAIN",
"property.sasl.username" = "user",
"property.sasl.password" = "token:eyJhbxxx",
"property.group.id" = "my_group_id_1",
"property.client.id" = "my_client_id_1",
"property.enable.ssl.certificate.verification" = "false"
);
信頼できるCA証明書パスがBE側で設定されていない場合、サーバー証明書が信頼できるかどうかを検証しないように "property.enable.ssl.certificate.verification" = "false" を設定する必要があります。
そうでなければ、信頼できるCA証明書パスを設定する必要があります:"property.ssl.ca.location" = "/path/to/ca-cert.pem"。
詳細情報
Routine LoadのSQLマニュアルを参照してください。また、クライアントのコマンドラインで HELP ROUTINE LOAD を入力することで、より詳しいヘルプを表示できます。