Stream Load
Stream Loadは、HTTPプロトコルを通じてローカルファイルまたはデータストリームをDorisにインポートすることをサポートしています。
Stream Loadは同期インポート方式で、インポート実行後にインポート結果を返すため、リクエストレスポンスを通じてインポートの成功を判断することができます。一般的に、ユーザーはStream Loadを使用して10GB未満のファイルをインポートできます。ファイルが大きすぎる場合は、ファイルを分割してからStream Loadを使用してインポートすることが推奨されます。Stream Loadは、一連のインポートタスクの原子性を保証することができ、すべて成功するかすべて失敗するかのいずれかになります。
curlを使用した単一スレッド読み込みと比較して、Doris StreamloaderはApache Dorisにデータを読み込むために設計されたクライアントツールです。同時読み込み機能により、大規模データセットの取り込み遅延を削減します。以下の機能を備えています:
- 並列読み込み: Stream Load方式のマルチスレッド読み込み。
workersパラメータを使用して並列レベルを設定できます。 - マルチファイル読み込み: 複数のファイルとディレクトリを一度に同時読み込み。再帰的ファイル取得をサポートし、ワイルドカード文字でファイル名を指定することができます。
- パストラバーサルサポート: ソースファイルがディレクトリにある場合のパストラバーサルをサポート
- 回復力と継続性: 部分的な読み込み失敗の場合、失敗した地点からデータ読み込みを再開できます。
- 自動リトライメカニズム: 読み込み失敗の場合、デフォルトの回数だけ自動的にリトライできます。読み込みが依然として失敗した場合、手動リトライのためのコマンドを出力します。
詳細な手順とベストプラクティスについてはDoris Streamloaderを参照してください。
ユーザーガイド
Stream LoadはHTTP経由でローカルまたはリモートソースからCSV、JSON、Parquet、ORC形式のデータのインポートをサポートしています。
- null値: nullを表すには
\Nを使用します。例えば、a,\N,bは中央の列がnullであることを示します。 - 空文字列: 2つの区切り文字の間に文字がない場合、空文字列が表されます。例えば、
a,,bでは、2つのカンマの間に文字がなく、中央の列の値が空文字列であることを示します。
基本原理
Stream Loadを使用する際は、HTTPプロトコルを通じてFE(Frontend)ノードにインポートジョブを開始する必要があります。FEは負荷分散を実現するため、ラウンドロビン方式でリクエストをBE(Backend)ノードにリダイレクトします。特定のBEノードに直接HTTPリクエストを送信することも可能です。Stream Loadでは、DorisがCoordinatorノードとして機能する1つのノードを選択します。Coordinatorノードはデータの受信と他のノードへの配信を担当します。
以下の図は、いくつかのインポート詳細を省略したStream Loadの主要なフローを示しています。
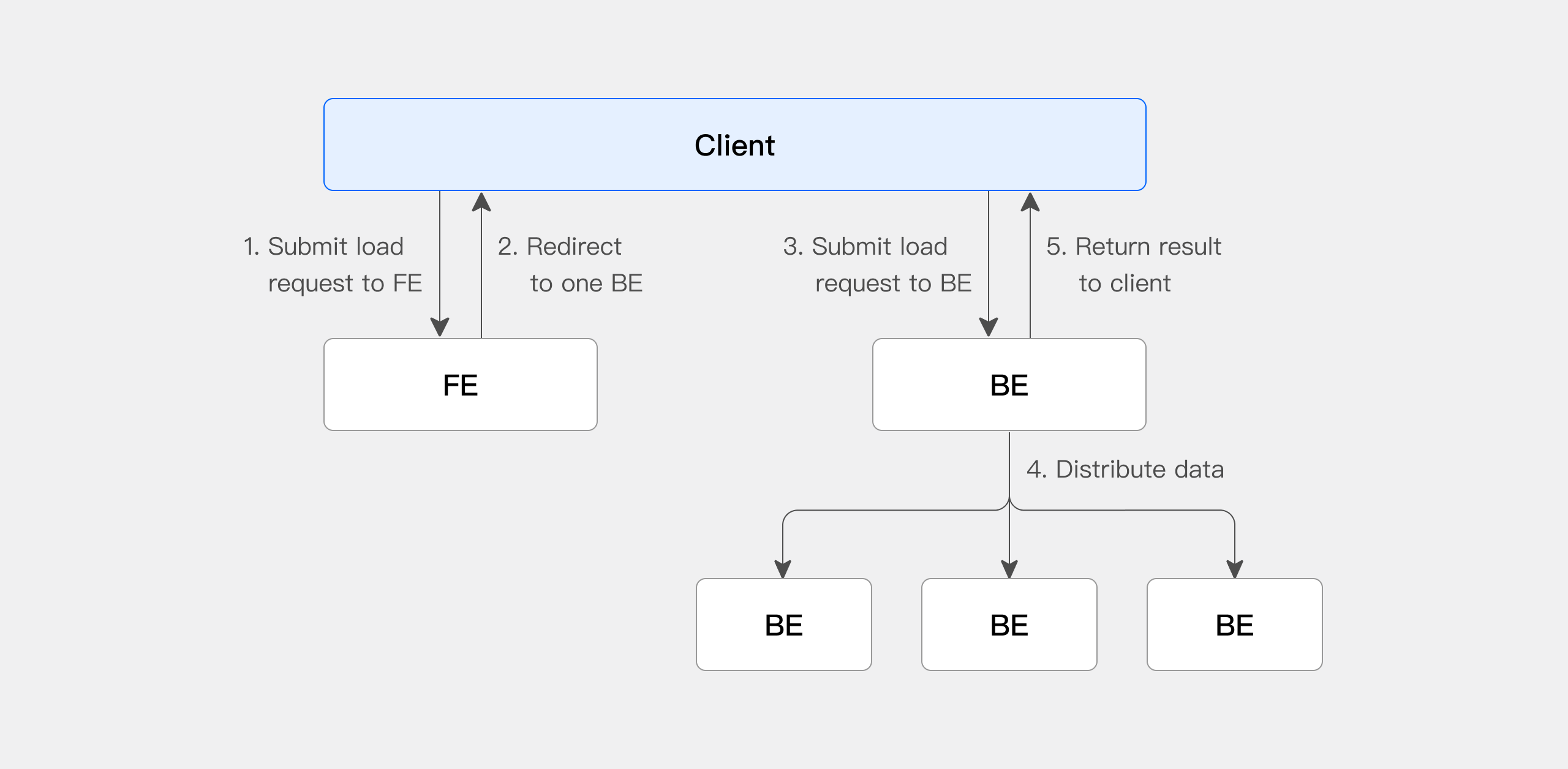
- クライアントがStream LoadインポートジョブリクエストをFE(Frontend)に送信します。
- FEはラウンドロビン方式でBE(Backend)をCoordinatorノードとして選択し、これがインポートジョブのスケジューリングを担当し、その後クライアントにHTTPリダイレクトを返します。
- クライアントがCoordinator BEノードに接続し、インポートリクエストを送信します。
- Coordinator BEが適切なBEノードにデータを配信し、インポート完了後にインポート結果をクライアントに返します。
- または、クライアントが直接BEノードをCoordinatorとして指定し、インポートジョブを直接配信することもできます。
クイックスタート
Stream LoadはHTTPプロトコルを通じてデータをインポートします。以下の例では、curlツールを使用してStream Loadを通じてインポートジョブを送信する方法を示しています。
前提条件チェック
Stream LoadはターゲットTableのINSERT権限を必要とします。INSERT権限がない場合は、GRANTコマンドを通じてユーザーに付与できます。
読み込みジョブの作成
CSVの読み込み
-
読み込みデータの作成
streamload_example.csvという名前のCSVファイルを作成します。具体的な内容は以下の通りです
1,Emily,25
2,Benjamin,35
3,Olivia,28
4,Alexander,60
5,Ava,17
6,William,69
7,Sophia,32
8,James,64
9,Emma,37
10,Liam,64
-
ロード用のTableの作成
以下の特定の構文を使用して、インポート先となるTableを作成します:
CREATE TABLE testdb.test_streamload(
user_id BIGINT NOT NULL COMMENT "User ID",
name VARCHAR(20) COMMENT "User name",
age INT COMMENT "User age"
)
DUPLICATE KEY(user_id)
DISTRIBUTED BY HASH(user_id) BUCKETS 10;
-
ロードジョブを有効化する
Stream Loadジョブは
curlコマンドを使用して送信できます。
curl --location-trusted -u <doris_user>:<doris_password> \
-H "Expect:100-continue" \
-H "column_separator:," \
-H "columns:user_id,name,age" \
-T streamload_example.csv \
-XPUT http://<fe_ip>:<fe_http_port>/api/testdb/test_streamload/_stream_load
Stream Loadは同期的な方法で、結果が直接ユーザーに返されます。
{
"TxnId": 3,
"Label": "123",
"Comment": "",
"TwoPhaseCommit": "false",
"Status": "Success",
"Message": "OK",
"NumberTotalRows": 10,
"NumberLoadedRows": 10,
"NumberFilteredRows": 0,
"NumberUnselectedRows": 0,
"LoadBytes": 118,
"LoadTimeMs": 173,
"BeginTxnTimeMs": 1,
"StreamLoadPutTimeMs": 70,
"ReadDataTimeMs": 2,
"WriteDataTimeMs": 48,
"CommitAndPublishTimeMs": 52
}
- データを表示
mysql> select count(*) from testdb.test_streamload;
+----------+
| count(*) |
+----------+
| 10 |
+----------+
JSON の読み込み
- 読み込みデータの作成
streamload_example.json という名前の JSON ファイルを作成します。具体的な内容は以下の通りです
[
{"userid":1,"username":"Emily","userage":25},
{"userid":2,"username":"Benjamin","userage":35},
{"userid":3,"username":"Olivia","userage":28},
{"userid":4,"username":"Alexander","userage":60},
{"userid":5,"username":"Ava","userage":17},
{"userid":6,"username":"William","userage":69},
{"userid":7,"username":"Sophia","userage":32},
{"userid":8,"username":"James","userage":64},
{"userid":9,"username":"Emma","userage":37},
{"userid":10,"username":"Liam","userage":64}
]
-
ロード用のTableの作成
以下の特定の構文を使用して、インポート先となるTableを作成します:
CREATE TABLE testdb.test_streamload(
user_id BIGINT NOT NULL COMMENT "User ID",
name VARCHAR(20) COMMENT "User name",
age INT COMMENT "User age"
)
DUPLICATE KEY(user_id)
DISTRIBUTED BY HASH(user_id) BUCKETS 10;
-
ロードジョブの有効化
Stream Loadジョブは
curlコマンドを使用して送信できます。
curl --location-trusted -u <doris_user>:<doris_password> \
-H "label:124" \
-H "Expect:100-continue" \
-H "format:json" -H "strip_outer_array:true" \
-H "jsonpaths:[\"$.userid\", \"$.username\", \"$.userage\"]" \
-H "columns:user_id,name,age" \
-T streamload_example.json \
-XPUT http://<fe_ip>:<fe_http_port>/api/testdb/test_streamload/_stream_load
JSONファイルがJSON配列ではなく、各行がJSONオブジェクトの場合は、ヘッダー -H "strip_outer_array:false" と -H "read_json_by_line:true" を追加してください。
JSONファイルのルートノードにあるJSONオブジェクトを読み込む必要がある場合は、jsonpathsを $. として指定する必要があります。例:-H "jsonpaths:[\"$.\"]"
Stream Loadは同期方式であり、結果は直接ユーザーに返されます。
{
"TxnId": 7,
"Label": "125",
"Comment": "",
"TwoPhaseCommit": "false",
"Status": "Success",
"Message": "OK",
"NumberTotalRows": 10,
"NumberLoadedRows": 10,
"NumberFilteredRows": 0,
"NumberUnselectedRows": 0,
"LoadBytes": 471,
"LoadTimeMs": 52,
"BeginTxnTimeMs": 0,
"StreamLoadPutTimeMs": 11,
"ReadDataTimeMs": 0,
"WriteDataTimeMs": 23,
"CommitAndPublishTimeMs": 16
}
View load job
デフォルトでは、Stream Loadは同期的にクライアントに結果を返すため、システムはStream Loadの履歴ジョブを記録しません。記録が必要な場合は、be.confに設定enable_stream_load_record=trueを追加してください。具体的な詳細については、BE設定オプションを参照してください。
設定後、show stream loadコマンドを使用して完了したStream Loadジョブを表示できます。
mysql> show stream load from testdb;
+-------+--------+-----------------+---------------+---------+---------+------+-----------+------------+--------------+----------------+-----------+-------------------------+-------------------------+------+---------+
| Label | Db | Table | ClientIp | Status | Message | Url | TotalRows | LoadedRows | FilteredRows | UnselectedRows | LoadBytes | StartTime | FinishTime | User | Comment |
+-------+--------+-----------------+---------------+---------+---------+------+-----------+------------+--------------+----------------+-----------+-------------------------+-------------------------+------+---------+
| 12356 | testdb | test_streamload | 192.168.88.31 | Success | OK | N/A | 10 | 10 | 0 | 0 | 118 | 2023-11-29 08:53:00.594 | 2023-11-29 08:53:00.650 | root | |
+-------+--------+-----------------+---------------+---------+---------+------+-----------+------------+--------------+----------------+-----------+-------------------------+-------------------------+------+---------+
1 row in set (0.00 sec)
Compute Groupの選択
ユーザーはStream Loadを実行する特定のCompute Groupを指定することができます。
ストレージ・コンピュート分離モードでは、Compute Groupは以下の方法で指定できます:
- HTTPヘッダーパラメータで指定する。
-H "cloud_cluster:cluster1"
Doris 4.0.0から、代替としてcompute_groupを使用することができます
-H "compute_group:cluster1"
- Stream LoadにバインドされたユーザープロパティでCompute Groupを指定する。ユーザープロパティとHTTPヘッダーの両方でCompute Groupが指定されている場合、Headerで指定されたCompute Groupが優先される。
set property for user1 'default_compute_group'='cluster1';
- ユーザープロパティとHTTP Headerのいずれも Compute Group を指定していない場合、Stream Load にバインドされたユーザーがアクセス権限を持つ Compute Group が選択されます。 ユーザーがいずれの Compute Group へのアクセス権限も持たない場合、Load は失敗します。
ストレージ・コンピュート統合モードでは、Compute Group の指定は Stream Load にバインドされたユーザープロパティを通じてのみサポートされます。
ユーザープロパティで指定されていない場合、default という名前の Compute Group が選択されます。
set property for user1 'resource_tags.location'='group_1';
load ジョブのキャンセル
ユーザーは Stream Load 操作を手動でキャンセルすることはできません。Stream Load ジョブは、タイムアウト(0に設定)またはインポートエラーが発生した場合、システムによって自動的にキャンセルされます。
リファレンスマニュアル
コマンド
Stream Load の構文は以下の通りです:
curl --location-trusted -u <doris_user>:<doris_password> \
-H "Expect:100-continue" [-H ""...] \
-T <file_path> \
-XPUT http://fe_host:http_port/api/{db}/{table}/_stream_load
Stream Load操作は、HTTPチャンク転送とチャンク転送を使用しないインポート方法の両方をサポートします。チャンク転送を使用しないインポートの場合、アップロードするコンテンツの長さを示すContent-Lengthヘッダーが必要であり、これによりデータの整合性が保証されます。
ロード設定パラメータ
FE設定
-
stream_load_default_timeout_second-
デフォルト値: 259200 (s)
-
動的設定: Yes
-
FE Master-only設定: Yes
-
パラメータ説明: Stream Loadのデフォルトタイムアウト。ロードジョブが設定されたタイムアウト(秒)内に完了しない場合、システムによってキャンセルされます。ソースファイルが指定された時間内にインポートできない場合、ユーザーはStream Loadリクエストで個別のタイムアウトを設定できます。または、FEのstream_load_default_timeout_secondパラメータを調整してグローバルデフォルトタイムアウトを設定することもできます。
BE設定
-
streaming_load_max_mb- デフォルト値: 10240 (MB)
- 動的設定: Yes
- パラメータ説明: Stream Loadの最大インポートサイズ。ユーザーの元ファイルがこの値を超える場合、BEの
streaming_load_max_mbパラメータを調整する必要があります。
-
Headerパラメータ
ロードパラメータはHTTP Headerセクションを通じて渡すことができます。具体的なパラメータ説明については以下を参照してください。
| パラメータ | パラメータ description |
|---|---|
| label | このDorisインポートのラベルを指定するために使用されます。同じラベルのデータを複数回インポートすることはできません。ラベルが指定されていない場合、Dorisは自動的に生成します。ユーザーはラベルを指定することで同じデータの重複インポートを回避できます。Dorisはデフォルトで3日間インポートジョブラベルを保持しますが、この期間はlabel_keep_max_secondを使用して調整できます。例えば、このインポートのラベルを123として指定するには、コマンド-H "label:123"を使用します。ラベルの使用により、ユーザーは同じデータを繰り返しインポートすることを防げます。同じバッチのデータには同じラベルを使用することを強く推奨します。これにより、同じバッチのデータに対する重複リクエストが一度だけ受け入れられ、At-Most-Onceセマンティクスが保証されます。ラベルに対応するインポートジョブのステータスがCANCELLEDの場合、そのラベルは再度使用できます。 |
| column_separator | インポートファイル内の列区切り文字を指定するために使用され、デフォルトは\tです。区切り文字が非表示文字の場合、\xを前に付けて16進形式で表現する必要があります。複数の文字を組み合わせて列区切り文字として使用できます。例えば、Hiveファイルの区切り文字を\x01として指定するには、コマンド-H "column_separator:\x01"を使用します。 |
| line_delimiter | インポートファイル内の行区切り文字を指定するために使用され、デフォルトは\nです。複数の文字を組み合わせて行区切り文字として使用できます。例えば、行区切り文字を\nとして指定するには、コマンド-H "line_delimiter:\n"を使用します。 |
| columns | インポートファイル内の列とTable内の列の対応を指定するために使用されます。ソースファイル内の列がTableの内容と正確に一致する場合、このフィールドを指定する必要はありません。ソースファイルのスキーマがTableと一致しない場合、データ変換にはこのフィールドが必要です。2つの形式があります:インポートファイル内のフィールドに対する直接列対応と、式で表現される派生列。詳細な例についてはデータ変換を参照してください。 |
| where | 不要なデータを除外するために使用されます。ユーザーが特定のデータを除外する必要がある場合、このオプションを設定することで実現できます。例えば、k1列が20180601と等しいデータのみをインポートするには、インポート時に-H "where: k1 = 20180601"を指定します。 |
| max_filter_ratio | フィルタリング可能な(不正またはその他の問題のある)データの最大許容比率を指定するために使用され、デフォルトは許容度ゼロです。値の範囲は0から1です。インポートされたデータのエラー率がこの値を超える場合、インポートは失敗します。不正データはwhere条件によってフィルタリングされた行は含まれません。例えば、すべての正しいデータを最大限インポートする(100%許容)には、コマンド-H "max_filter_ratio:1"を指定します。 |
| partitions | このインポートに関係するパーティションを指定するために使用されます。ユーザーがデータに対応するパーティションを決定できる場合、このオプションを指定することを推奨します。これらのパーティション条件を満たさないデータはフィルタリングされます。例えば、パーティションp1とp2へのインポートを指定するには、コマンド-H "partitions: p1, p2"を使用します。 |
| timeout | インポートのタイムアウトを秒単位で指定するために使用されます。デフォルトは600秒で、設定可能範囲は1秒から259200秒です。例えば、インポートタイムアウトを1200秒に指定するには、コマンド-H "timeout:1200"を使用します。 |
| strict_mode | このインポートで厳密モードを有効にするかどうかを指定するために使用され、デフォルトでは無効です。例えば、厳密モードを有効にするには、コマンド-H "strict_mode:true"を使用します。 |
| timezone | このインポートに使用するタイムゾーンを指定するために使用され、デフォルトはGMT+8です。このパラメータはインポートに関係するすべてのタイムゾーン関連関数の結果に影響します。例えば、インポートタイムゾーンをAfrica/Abidjanに指定するには、コマンド-H "timezone:Africa/Abidjan"を使用します。 |
| exec_mem_limit | インポートのメモリ制限で、デフォルトは2GBです。単位はバイトです。 |
| format | インポートされるデータの形式を指定するために使用され、デフォルトはCSVです。現在サポートされている形式には次が含まれます:CSV、JSON、arrow、csv_with_names(csvファイルの最初の行のフィルタリングをサポート)、csv_with_names_and_types(csvファイルの最初の2行のフィルタリングをサポート)、Parquet、ORC。例えば、インポートデータ形式をJSONに指定するには、コマンド-H "format:json"を使用します。 |
| jsonpaths | JSONデータ形式をインポートする方法は2つあります:シンプルモードとマッチングモード。jsonpathsが指定されていない場合、これはJSONデータがオブジェクト型である必要があるシンプルモードです。マッチングモードは、JSONデータが比較的複雑で、jsonpathsパラメータを通じて対応する値をマッチングする必要がある場合に使用されます。シンプルモードでは、JSON内のキーがTable内の列名と一対一で対応する必要があります。例えば、JSONデータ{"k1":1, "k2":2, "k3":"hello"}では、k1、k2、k3がそれぞれTable内の列に対応します。 |
| strip_outer_array | strip_outer_arrayがtrueに設定された場合、JSONデータが配列オブジェクトで始まり、配列内のオブジェクトを平坦化することを示します。デフォルト値はfalseです。JSONデータの最外層が配列を表す[]で表現されている場合、strip_outer_arrayをtrueに設定する必要があります。例えば、次のデータでstrip_outer_arrayをtrueに設定すると、Dorisにインポートされるときに2行のデータが生成されます:[{"k1": 1, "v1": 2}, {"k1": 3, "v1": 4}]。 |
| json_root | json_rootはJSONドキュメントのルートノードを指定する有効なjsonpath文字列で、デフォルト値は""です。 |
| merge_type | データのマージタイプ。3つのタイプがサポートされています: - APPEND(デフォルト):このバッチのすべてのデータが既存のデータに追加されることを示します - DELETE:このバッチのデータとキーが一致するすべての行の削除を示します - MERGE:DELETE条件と組み合わせて使用する必要があります。DELETE条件を満たすデータはDELETEセマンティクスに従って処理され、残りはAPPENDセマンティクスに従って処理されます 例えば、マージモードをMERGEに指定するには: -H "merge_type: MERGE" -H "delete: flag=1" |
| delete | MERGEでのみ意味があり、データの削除条件を表します。 |
| function_column.sequence_col | UNIQUE KEYSモデルでのみ適用されます。同じKey列内で、指定されたsource_sequence列に従ってValue列が置き換えられることを保証します。source_sequenceはデータソースの列またはTable構造の既存の列のいずれかです。 |
| fuzzy_parse | ブール型です。trueに設定されている場合、JSONは最初の行をスキーマとして解析されます。このオプションを有効にするとJSONインポートの効率が向上しますが、すべてのJSONオブジェクトのキーの順序が最初の行と一致している必要があります。デフォルトはfalseで、JSON形式でのみ使用されます。 |
| num_as_string | ブール型です。trueに設定された場合、JSON解析中に数値型が文字列に変換され、インポートプロセス中の精度損失がないことを保証します。 |
| read_json_by_line | ブール型です。trueに設定された場合、1行に1つのJSONオブジェクトの読み取りをサポートし、デフォルトはfalseです。 |
| send_batch_parallelism | バッチ処理されたデータを送信するための並列処理の並列度を設定します。並列度の値がBEで設定されたmax_send_batch_parallelism_per_jobを超える場合、調整BEはmax_send_batch_parallelism_per_job値を使用します。 |
| hidden_columns | インポートされたデータの隠し列を指定するために使用され、HeaderにColumnsが含まれていない場合に有効になります。複数の隠し列はカンマで区切られます。システムはユーザーが指定したデータをインポートに使用します。次の例では、インポートされたデータの最後の列は__DORIS_SEQUENCE_COL__です。hidden_columns: __DORIS_DELETE_SIGN__,__DORIS_SEQUENCE_COL__。 |
| load_to_single_tablet | ブール型です。trueに設定された場合、パーティションに対応する単一のTabletへのデータインポートのみをサポートし、デフォルトはfalseです。このパラメータは、ランダムバケッティングを使用するOLAPTableへのインポート時にのみ許可されます。 |
| compress_type | 現在、CSVファイルの圧縮のみがサポートされています。圧縮形式には、gz、lzo、bz2、lz4、lzop、deflateが含まれます。 |
| trim_double_quotes | ブール型です。trueに設定された場合、CSVファイルの各フィールドの最外側の二重引用符のトリミングを示し、デフォルトはfalseです。 |
| skip_lines | 整数型です。CSVファイルの先頭でスキップする行数を指定するために使用され、デフォルトは0です。formatがcsv_with_namesまたはcsv_with_names_and_typesに設定されている場合、このパラメータは無効になります。 |
| comment | 文字列型で、デフォルト値は空文字列です。タスクに追加情報を追加するために使用されます。 |
| enclose | 囲み文字を指定します。CSVデータフィールドに行区切り文字または列区切り文字が含まれている場合、予期しない切り捨てを防ぐために、保護のため単一バイト文字を囲み文字として指定できます。例えば、列区切り文字が","で囲み文字が"'"の場合、データ"a,'b,c'"では"b,c"が単一フィールドとして解析されます。注:囲み文字が二重引用符(")に設定されている場合、trim_double_quotesをtrueに設定してください。 |
| escape | エスケープ文字を指定します。フィールド内の囲み文字と同じ文字をエスケープするために使用されます。例えば、データが"a,'b,'c'"で、囲み文字が"'"で、"b,'c"を単一フィールドとして解析したい場合、""などの単一バイトエスケープ文字を指定し、データを"a,'b','c'"に変更する必要があります。 |
| memtable_on_sink_node | データロード時にDataSinkノードでMemTableを有効にするかどうか、デフォルトはfalseです。 |
| unique_key_update_mode | UniqueTableでの更新モード、現在はMerge-On-Write UniqueTableでのみ有効です。3つのタイプをサポート:UPSERT、UPDATE_FIXED_COLUMNS、UPDATE_FLEXIBLE_COLUMNS。UPSERT:データがupsertセマンティクスでロードされることを示します;UPDATE_FIXED_COLUMNS:データが部分更新を通じてロードされることを示します;UPDATE_FLEXIBLE_COLUMNS:データが柔軟な部分更新を通じてロードされることを示します。 |
| partial_update_new_key_behavior | UniqueTableで部分列更新または柔軟な列更新を実行する場合、このパラメータは新しい行の処理方法を制御します。2つのタイプがあります:APPENDとERROR。- APPEND:新しい行データの挿入を許可- ERROR:新しい行を挿入するときに失敗してエラーを報告 |
ロード戻り値
Stream Loadは同期インポート方法であり、ロード結果はロード戻り値の作成を通じてユーザーに直接提供されます。以下に示すとおりです:
{
"TxnId": 1003,
"Label": "b6f3bc78-0d2c-45d9-9e4c-faa0a0149bee",
"Status": "Success",
"ExistingJobStatus": "FINISHED", // optional
"Message": "OK",
"NumberTotalRows": 1000000,
"NumberLoadedRows": 1000000,
"NumberFilteredRows": 1,
"NumberUnselectedRows": 0,
"LoadBytes": 40888898,
"LoadTimeMs": 2144,
"BeginTxnTimeMs": 1,
"StreamLoadPutTimeMs": 2,
"ReadDataTimeMs": 325,
"WriteDataTimeMs": 1933,
"CommitAndPublishTimeMs": 106,
"ErrorURL": "http://192.168.1.1:8042/api/_load_error_log?file=__shard_0/error_log_insert_stmt_db18266d4d9b4ee5-abb00ddd64bdf005_db18266d4d9b4ee5_abb00ddd64bdf005"
}
戻り値パラメータは以下の表で説明されています:
| パラメータ | パラメータ description |
|---|---|
| TxnId | インポートトランザクションID |
| Label | ロードジョブのラベル、-H "label:<label_id>"で指定されます。 |
| Status | 最終ロードStatus。Success: ロードジョブが成功しました。Publish Timeout: ロードジョブは完了しましたが、データの可視性に遅延がある可能性があります。Label Already Exists: ラベルが重複しており、新しいラベルが必要です。Fail: ロードジョブが失敗しました。 |
| ExistingJobStatus | 既に存在するラベルに対応するロードジョブのステータス。このフィールドはStatusがLabel Already Existsの場合のみ表示されます。ユーザーはこのステータスを使用して、既存のラベルに対応するインポートジョブのステータスを知ることができます。RUNNINGはジョブがまだ実行中であることを意味し、FINISHEDはジョブが成功したことを意味します。 |
| Message | ロードジョブに関連するエラー情報。 |
| NumberTotalRows | ロードジョブ中に処理された行の総数。 |
| NumberLoadedRows | 正常にロードされた行数。 |
| NumberFilteredRows | データ品質基準を満たさなかった行数。 |
| NumberUnselectedRows | WHERE条件に基づいてフィルタリングされた行数。 |
| LoadBytes | データ量(バイト単位)。 |
| LoadTimeMs | ロードジョブの完了にかかった時間(ミリ秒単位)。 |
| BeginTxnTimeMs | Frontend node (FE)からトランザクションの開始を要求するのにかかった時間(ミリ秒単位)。 |
| StreamLoadPutTimeMs | FEからロードジョブデータの実行計画を要求するのにかかった時間(ミリ秒単位)。 |
| ReadDataTimeMs | ロードジョブ中にデータの読み取りに費やした時間(ミリ秒単位)。 |
| WriteDataTimeMs | ロードジョブ中にデータ書き込み操作を実行するのにかかった時間(ミリ秒単位)。 |
| CommitAndPublishTimeMs | FEからトランザクションのコミットと公開を要求するのにかかった時間(ミリ秒単位)。 |
| ErrorURL | データ品質に問題がある場合、ユーザーはこのURLにアクセスしてエラーのある特定の行を確認できます。 |
ユーザーはErrorURLにアクセスして、データ品質の問題によりインポートに失敗したデータを確認できます。コマンドcurl "<ErrorURL>"を実行することで、ユーザーはエラーのあるデータに関する情報を直接取得できます。
ロード例
ロードタイムアウトと最大サイズの設定
ロードジョブのタイムアウトは秒単位で測定されます。指定されたタイムアウト期間内にロードジョブが完了しない場合、システムによってキャンセルされ、CANCELLEDとしてマークされます。timeoutパラメータを指定するか、fe.confファイルにstream_load_default_timeout_secondパラメータを追加することで、Stream Loadジョブのタイムアウトを調整できます。
ロードを開始する前に、ファイルサイズに基づいてタイムアウトを計算する必要があります。例えば、推定ロードパフォーマンスが50MB/sの100GBファイルの場合:
Load time ≈ 100GB / 50MB/s ≈ 2048s
以下のコマンドを使用して、Stream Loadジョブの作成時に3000秒のタイムアウトを指定できます:
curl --location-trusted -u <doris_user>:<doris_password> \
-H "Expect:100-continue" \
-H "timeout:3000"
-H "column_separator:," \
-H "columns:user_id,name,age" \
-T streamload_example.csv \
-XPUT http://<fe_ip>:<fe_http_port>/api/testdb/test_streamload/_stream_load
最大エラー許容率の設定
Load jobは、フォーマットエラーのあるデータを一定量許容することができます。許容率はmax_filter_ratioパラメータを使用して設定されます。デフォルトでは0に設定されており、これは単一の誤ったデータ行であっても、Load job全体が失敗することを意味します。ユーザーが一部の問題のあるデータ行を無視したい場合は、このパラメータを0から1の間の値に設定できます。Dorisは不正なデータフォーマットの行を自動的にスキップします。許容率の計算に関する詳細情報については、Data Transformationドキュメントを参照してください。
以下のコマンドを使用して、Stream Load jobの作成時に0.4のmax_filter_ratio許容値を指定できます:
curl --location-trusted -u <doris_user>:<doris_password> \
-H "Expect:100-continue" \
-H "max_filter_ratio:0.4" \
-H "column_separator:," \
-H "columns:user_id,name,age" \
-T streamload_example.csv \
-XPUT http://<fe_ip>:<fe_http_port>/api/testdb/test_streamload/_stream_load
ロード フィルタリング条件の設定
ロードジョブの実行中に、WHEREパラメータを使用してインポートデータに条件付きフィルタリングを適用できます。フィルタリングされたデータはフィルタ比率の計算に含まれず、max_filter_ratioの設定に影響しません。ロードジョブが完了した後、num_rows_unselectedを確認することでフィルタリングされた行数を確認できます。
Stream Loadジョブを作成する際にWHEREフィルタリング条件を指定するには、以下のコマンドを使用できます:
curl --location-trusted -u <doris_user>:<doris_password> \
-H "Expect:100-continue" \
-H "where:age>=35" \
-H "column_separator:," \
-H "columns:user_id,name,age" \
-T streamload_example.csv \
-XPUT http://<fe_ip>:<fe_http_port>/api/testdb/test_streamload/_stream_load
特定のパーティションへのデータロード
ローカルファイルからTableのパーティションp1およびp2にデータをロードし、20%のエラー率を許可します。
curl --location-trusted -u <doris_user>:<doris_password> \
-H "label:123" \
-H "Expect:100-continue" \
-H "max_filter_ratio:0.2" \
-H "column_separator:," \
-H "columns:user_id,name,age" \
-H "partitions: p1, p2" \
-T streamload_example.csv \
-XPUT http://<fe_ip>:<fe_http_port>/api/testdb/test_streamload/_stream_load
特定のタイムゾーンへのデータ読み込み
Dorisには現在組み込みのタイムゾーン時刻型がないため、すべてのDATETIME関連型は絶対的な時点のみを表し、タイムゾーン情報を含まず、Dorisシステムタイムゾーンの変更によって変わることはありません。したがって、タイムゾーンを持つデータのインポートに対しては、統一された処理方法として特定のターゲットタイムゾーンのデータに変換します。Dorisシステムでは、これはセッション変数time_zoneによって表されるタイムゾーンです。
インポートでは、ターゲットタイムゾーンをパラメータtimezoneで指定します。この変数は、タイムゾーン変換が発生し、タイムゾーンに敏感な関数が計算される際に、セッション変数time_zoneを置き換えます。したがって、特別な事情がない限り、インポートトランザクションではtimezoneを現在のDorisクラスタのtime_zoneと一致するように設定する必要があります。これは、タイムゾーンを持つすべての時刻データがこのタイムゾーンに変換されることを意味します。
例えば、Dorisシステムタイムゾーンが"+08:00"で、インポートデータの時刻列に"2012-01-01 01:00:00+00:00"と"2015-12-12 12:12:12-08:00"の2つのデータが含まれている場合、インポート時に-H "timezone: +08:00"でインポートトランザクションのタイムゾーンを指定すると、両方のデータがそのタイムゾーンに変換され、"2012-01-01 09:00:00"と"2015-12-13 04:12:12"という結果が得られます。
タイムゾーンの解釈に関する詳細については、Time Zoneドキュメントを参照してください。
ストリーミングインポート
Stream LoadはHTTPプロトコルベースのインポートで、Java、Go、Pythonなどのプログラミング言語を使用したストリーミングインポートをサポートします。これがStream Loadと呼ばれる理由です。
以下の例では、bashコマンドパイプラインを通じてこの使用方法を示します。インポートデータは、ローカルファイルからではなく、プログラムによってストリーミング的に生成されます。
seq 1 10 | awk '{OFS="\t"}{print $1, $1 * 10}' | curl --location-trusted -u root -T - http://host:port/api/testDb/testTbl/_stream_load
CSV最初の行のフィルタリングを設定
ファイルデータ:
id,name,age
1,doris,20
2,flink,10
format=csv_with_namesを指定することで、読み込み時に最初の行をフィルタリング
curl --location-trusted -u root -T test.csv -H "label:1" -H "format:csv_with_names" -H "column_separator:," http://host:port/api/testDb/testTbl/_stream_load
DELETE操作におけるmerge_typeの指定
Stream Loadには、APPEND、DELETE、MERGEの3つのインポートタイプがあります。これらはmerge_typeパラメータを指定することで調整できます。インポートされたデータと同じキーを持つすべてのデータを削除することを指定したい場合は、以下のコマンドを使用できます:
curl --location-trusted -u <doris_user>:<doris_password> \
-H "Expect:100-continue" \
-H "merge_type: DELETE" \
-H "column_separator:," \
-H "columns:user_id,name,age" \
-T streamload_example.csv \
-XPUT http://<fe_ip>:<fe_http_port>/api/testdb/test_streamload/_stream_load
読み込み前:
+--------+----------+----------+------+
| siteid | citycode | username | pv |
+--------+----------+----------+------+
| 3 | 2 | tom | 2 |
| 4 | 3 | bush | 3 |
| 5 | 3 | helen | 3 |
+--------+----------+----------+------+
インポートされたデータは以下の通りです:
3,2,tom,0
インポート後、元のTableデータは削除され、以下の結果となります:
+--------+----------+----------+------+
| siteid | citycode | username | pv |
+--------+----------+----------+------+
| 4 | 3 | bush | 3 |
| 5 | 3 | helen | 3 |
+--------+----------+----------+------+
MERGE操作における merge_type の指定
merge_typeをMERGEとして指定することで、インポートされたデータをTableにマージできます。MERGEセマンティクスはDELETE条件と組み合わせて使用する必要があります。これは、DELETE条件を満たすデータがDELETEセマンティクスに従って処理され、残りのデータがAPPENDセマンティクスに従ってTableに追加されることを意味します。以下の操作は、siteidが1の行を削除し、残りのデータをTableに追加することを表しています:
curl --location-trusted -u <doris_user>:<doris_password> \
-H "Expect:100-continue" \
-H "merge_type: MERGE" \
-H "delete: siteid=1" \
-H "column_separator:," \
-H "columns:user_id,name,age" \
-T streamload_example.csv \
-XPUT http://<fe_ip>:<fe_http_port>/api/testdb/test_streamload/_stream_load
読み込み前:
+--------+----------+----------+------+
| siteid | citycode | username | pv |
+--------+----------+----------+------+
| 4 | 3 | bush | 3 |
| 5 | 3 | helen | 3 |
| 1 | 1 | jim | 2 |
+--------+----------+----------+------+
インポートされたデータは以下の通りです:
2,1,grace,2
3,2,tom,2
1,1,jim,2
ロード後、条件に従ってsiteid = 1の行が削除され、siteidが2と3の行がTableに追加されます:
+--------+----------+----------+------+
| siteid | citycode | username | pv |
+--------+----------+----------+------+
| 4 | 3 | bush | 3 |
| 2 | 1 | grace | 2 |
| 3 | 2 | tom | 2 |
| 5 | 3 | helen | 3 |
+--------+----------+----------+------+
マージ用のシーケンスカラムの指定
Unique Keyを持つTableにSequenceカラムがある場合、Sequenceカラムの値は、同じKeyカラムの下でREPLACE集約関数における置換順序の基準として機能します。より大きな値は、より小さな値を置換できます。このようなTableに対してDORIS_DELETE_SIGNに基づいて削除をマークする場合、Keyが同じであり、Sequenceカラムの値が現在の値以上であることを確認する必要があります。function_column.sequence_colパラメータを指定することで、merge_type: DELETEと組み合わせて削除操作を実行できます。
curl --location-trusted -u <doris_user>:<doris_password> \
-H "Expect:100-continue" \
-H "merge_type: DELETE" \
-H "function_column.sequence_col: age" \
-H "column_separator:," \
-H "columns: name, gender, age"
-T streamload_example.csv \
-XPUT http://<fe_ip>:<fe_http_port>/api/testdb/test_streamload/_stream_load
以下のTableスキーマが与えられた場合:
SET show_hidden_columns=true;
Query OK, 0 rows affected (0.00 sec)
DESC table1;
+------------------------+--------------+------+-------+---------+---------+
| Field | Type | Null | Key | Default | Extra |
+------------------------+--------------+------+-------+---------+---------+
| name | VARCHAR(100) | No | true | NULL | |
| gender | VARCHAR(10) | Yes | false | NULL | REPLACE |
| age | INT | Yes | false | NULL | REPLACE |
| __DORIS_DELETE_SIGN__ | TINYINT | No | false | 0 | REPLACE |
| __DORIS_SEQUENCE_COL__ | INT | Yes | false | NULL | REPLACE |
+------------------------+--------------+------+-------+---------+---------+
4 rows in set (0.00 sec)
元のTableデータは以下の通りです:
+-------+--------+------+
| name | gender | age |
+-------+--------+------+
| li | male | 10 |
| wang | male | 14 |
| zhang | male | 12 |
+-------+--------+------+
-
Sequenceパラメータは効果を持ち、loading sequenceカラムの値はTable内の既存データ以上である必要があります。
データのloading方法:
li,male,10
function_column.sequence_colにageが指定されており、ageの値がTable内の既存の列以上であるため、元のTableデータが削除されます。Tableデータは以下のようになります:
+-------+--------+------+
| name | gender | age |
+-------+--------+------+
| wang | male | 14 |
| zhang | male | 12 |
+-------+--------+------+
-
Sequenceパラメータが効果を発揮しない場合、ロードするsequence列の値がTable内の既存データ以下である:
データのロードは以下のようになる:
li,male,9
function_column.sequence_colがageとして指定されているが、ageの値がTable内の既存の列より小さいため、削除操作は実行されません。Tableデータは変更されず、プライマリキーがliの行は引き続き表示されます:
+-------+--------+------+
| name | gender | age |
+-------+--------+------+
| li | male | 10 |
| wang | male | 14 |
| zhang | male | 12 |
+-------+--------+------+
これは削除されません。なぜなら、基礎となる依存関係レベルで、まず同じキーを持つ行をチェックするためです。より大きなsequence列の値を持つ行データを表示します。その後、その行のDORIS_DELETE_SIGN値をチェックします。値が1の場合、外部には表示されません。値が0の場合、まだ読み取られて表示されます。
囲み文字を使用したデータの読み込み
CSVファイルのデータにデリミタや区切り文字が含まれている場合、データが切り捨てられることを防ぐために、単一バイト文字を囲み文字として指定できます。
例えば、以下のデータでは、コンマが区切り文字として使用されていますが、フィールド内にも存在しています:
zhangsan,30,'Shanghai, HuangPu District, Dagu Road'
単一引用符 ' などの囲み文字を指定することで、Shanghai, HuangPu District, Dagu Road 全体を単一のフィールドとして扱うことができます。
curl --location-trusted -u <doris_user>:<doris_password> \
-H "Expect:100-continue" \
-H "column_separator:," \
-H "enclose:'" \
-H "columns:username,age,address" \
-T streamload_example.csv \
-XPUT http://<fe_ip>:<fe_http_port>/api/testdb/test_streamload/_stream_load
囲み文字がフィールド内にも現れる場合、例えば Shanghai City, Huangpu District, \'Dagu Road を単一のフィールドとして扱いたい場合は、まず列内で文字列エスケープを実行する必要があります:
Zhang San,30,'Shanghai, Huangpu District, \'Dagu Road'
エスケープ文字は単一バイト文字であり、escapeパラメータを使用して指定できます。この例では、バックスラッシュ\がエスケープ文字として使用されています。
curl --location-trusted -u <doris_user>:<doris_password> \
-H "Expect:100-continue" \
-H "column_separator:," \
-H "enclose:'" \
-H "escape:\\" \
-H "columns:username,age,address" \
-T streamload_example.csv \
-XPUT http://<fe_ip>:<fe_http_port>/api/testdb/test_streamload/_stream_load
DEFAULT CURRENT_TIMESTAMP型を含むフィールドの読み込み
DEFAULT CURRENT_TIMESTAMP型のフィールドを含むTableにデータを読み込む例を以下に示します:
Tableスキーマ:
`id` bigint(30) NOT NULL,
`order_code` varchar(30) DEFAULT NULL COMMENT '',
`create_time` datetimev2(3) DEFAULT CURRENT_TIMESTAMP
JSON データ型:
{"id":1,"order_Code":"avc"}
コマンド:
curl --location-trusted -u root -T test.json -H "label:1" -H "format:json" -H 'columns: id, order_code, create_time=CURRENT_TIMESTAMP()' http://host:port/api/testDb/testTbl/_stream_load
JSON形式データ読み込み用のSimple mode
JSONフィールドがTable内のカラム名と一対一で対応している場合、パラメータ "strip_outer_array:true" と "format:json" を指定することで、JSON データ形式をTableにインポートできます。
例えば、Tableが以下のように定義されている場合:
CREATE TABLE testdb.test_streamload(
user_id BIGINT NOT NULL COMMENT "User ID",
name VARCHAR(20) COMMENT "User name",
age INT COMMENT "User age"
)
DUPLICATE KEY(user_id)
DISTRIBUTED BY HASH(user_id) BUCKETS 10;
そして、データフィールド名はTable内のカラム名と一対一で対応します:
[
{"user_id":1,"name":"Emily","age":25},
{"user_id":2,"name":"Benjamin","age":35},
{"user_id":3,"name":"Olivia","age":28},
{"user_id":4,"name":"Alexander","age":60},
{"user_id":5,"name":"Ava","age":17},
{"user_id":6,"name":"William","age":69},
{"user_id":7,"name":"Sophia","age":32},
{"user_id":8,"name":"James","age":64},
{"user_id":9,"name":"Emma","age":37},
{"user_id":10,"name":"Liam","age":64}
]
次のコマンドを使用して、JSONデータをTableに読み込むことができます:
curl --location-trusted -u <doris_user>:<doris_password> \
-H "Expect:100-continue" \
-H "format:json" \
-H "strip_outer_array:true" \
-T streamload_example.json \
-XPUT http://<fe_ip>:<fe_http_port>/api/testdb/test_streamload/_stream_load
複雑なJSON形式データを読み込むためのマッチングモード
JSONデータがより複雑で、Table内のカラム名と一対一で対応できない場合や、余分なカラムがある場合は、jsonpathsパラメータを使用してカラム名のマッピングを完成させ、データマッチングインポートを実行できます。例えば、以下のデータの場合:
[
{"userid":1,"hudi":"lala","username":"Emily","userage":25,"userhp":101},
{"userid":2,"hudi":"kpkp","username":"Benjamin","userage":35,"userhp":102},
{"userid":3,"hudi":"ji","username":"Olivia","userage":28,"userhp":103},
{"userid":4,"hudi":"popo","username":"Alexander","userage":60,"userhp":103},
{"userid":5,"hudi":"uio","username":"Ava","userage":17,"userhp":104},
{"userid":6,"hudi":"lkj","username":"William","userage":69,"userhp":105},
{"userid":7,"hudi":"komf","username":"Sophia","userage":32,"userhp":106},
{"userid":8,"hudi":"mki","username":"James","userage":64,"userhp":107},
{"userid":9,"hudi":"hjk","username":"Emma","userage":37,"userhp":108},
{"userid":10,"hudi":"hua","username":"Liam","userage":64,"userhp":109}
]
指定した列にマッチさせるためにjsonpathsパラメータを指定できます:
curl --location-trusted -u <doris_user>:<doris_password> \
-H "Expect:100-continue" \
-H "format:json" \
-H "strip_outer_array:true" \
-H "jsonpaths:[\"$.userid\", \"$.username\", \"$.userage\"]" \
-H "columns:user_id,name,age" \
-T streamload_example.json \
-XPUT http://<fe_ip>:<fe_http_port>/api/testdb/test_streamload/_stream_load
データロードのJSONルートノードの指定
JSONデータにネストしたJSONフィールドが含まれている場合、インポートするJSONのルートノードを指定する必要があります。デフォルト値は""です。
例えば、以下のデータで、commentカラム内のデータをTableにインポートしたい場合:
[
{"user":1,"comment":{"userid":101,"username":"Emily","userage":25}},
{"user":2,"comment":{"userid":102,"username":"Benjamin","userage":35}},
{"user":3,"comment":{"userid":103,"username":"Olivia","userage":28}},
{"user":4,"comment":{"userid":104,"username":"Alexander","userage":60}},
{"user":5,"comment":{"userid":105,"username":"Ava","userage":17}},
{"user":6,"comment":{"userid":106,"username":"William","userage":69}},
{"user":7,"comment":{"userid":107,"username":"Sophia","userage":32}},
{"user":8,"comment":{"userid":108,"username":"James","userage":64}},
{"user":9,"comment":{"userid":109,"username":"Emma","userage":37}},
{"user":10,"comment":{"userid":110,"username":"Liam","userage":64}}
]
まず、json_rootパラメータを使用してコメントとしてルートノードを指定し、次にjsonpathsパラメータに従ってカラム名マッピングを完了する必要があります。
curl --location-trusted -u <doris_user>:<doris_password> \
-H "Expect:100-continue" \
-H "format:json" \
-H "strip_outer_array:true" \
-H "json_root: $.comment" \
-H "jsonpaths:[\"$.userid\", \"$.username\", \"$.userage\"]" \
-H "columns:user_id,name,age" \
-T streamload_example.json \
-XPUT http://<fe_ip>:<fe_http_port>/api/testdb/test_streamload/_stream_load
配列データタイプの読み込み
例えば、以下のデータが配列タイプを含む場合:
1|Emily|[1,2,3,4]
2|Benjamin|[22,45,90,12]
3|Olivia|[23,16,19,16]
4|Alexander|[123,234,456]
5|Ava|[12,15,789]
6|William|[57,68,97]
7|Sophia|[46,47,49]
8|James|[110,127,128]
9|Emma|[19,18,123,446]
10|Liam|[89,87,96,12]
以下のTable構造にデータをロードします:
CREATE TABLE testdb.test_streamload(
typ_id BIGINT NOT NULL COMMENT "ID",
name VARCHAR(20) NULL COMMENT "Name",
arr ARRAY<int(10)> NULL COMMENT "Array"
)
DUPLICATE KEY(typ_id)
DISTRIBUTED BY HASH(typ_id) BUCKETS 10;
テキストファイルからARRAY型を、Stream Loadジョブを使用してTableに直接読み込むことができます。
curl --location-trusted -u <doris_user>:<doris_password> \
-H "Expect:100-continue" \
-H "column_separator:|" \
-H "columns:typ_id,name,arr" \
-T streamload_example.csv \
-XPUT http://<fe_ip>:<fe_http_port>/api/testdb/test_streamload/_stream_load
mapデータ型の読み込み
インポートされたデータがmapタイプを含む場合、以下の例のように:
[
{"user_id":1,"namemap":{"Emily":101,"age":25}},
{"user_id":2,"namemap":{"Benjamin":102,"age":35}},
{"user_id":3,"namemap":{"Olivia":103,"age":28}},
{"user_id":4,"namemap":{"Alexander":104,"age":60}},
{"user_id":5,"namemap":{"Ava":105,"age":17}},
{"user_id":6,"namemap":{"William":106,"age":69}},
{"user_id":7,"namemap":{"Sophia":107,"age":32}},
{"user_id":8,"namemap":{"James":108,"age":64}},
{"user_id":9,"namemap":{"Emma":109,"age":37}},
{"user_id":10,"namemap":{"Liam":110,"age":64}}
]
以下のTable構造にデータをロードします:
CREATE TABLE testdb.test_streamload(
user_id BIGINT NOT NULL COMMENT "ID",
namemap Map<STRING, INT> NULL COMMENT "Name"
)
DUPLICATE KEY(user_id)
DISTRIBUTED BY HASH(user_id) BUCKETS 10;
テキストファイルからマップ型を Stream Load タスクを使用してTableに直接ロードできます。
curl --location-trusted -u <doris_user>:<doris_password> \
-H "Expect:100-continue" \
-H "format: json" \
-H "strip_outer_array:true" \
-T streamload_example.json \
-XPUT http://<fe_ip>:<fe_http_port>/api/testdb/test_streamload/_stream_load
Bitmapデータ型の読み込み
インポートプロセス中に、Bitmap型のデータに遭遇した場合、to_bitmapを使用してデータをBitmapに変換するか、bitmap_empty関数を使用してBitmapを埋めることができます。
例えば、以下のデータの場合:
1|koga|17723
2|nijg|146285
3|lojn|347890
4|lofn|489871
5|jfin|545679
6|kon|676724
7|nhga|767689
8|nfubg|879878
9|huang|969798
10|buag|97997
Bitmapタイプを含む以下のTableにデータを読み込みます:
CREATE TABLE testdb.test_streamload(
typ_id BIGINT NULL COMMENT "ID",
hou VARCHAR(10) NULL COMMENT "one",
arr BITMAP BITMAP_UNION NOT NULL COMMENT "two"
)
AGGREGATE KEY(typ_id,hou)
DISTRIBUTED BY HASH(typ_id,hou) BUCKETS 10;
そして、to_bitmapを使用してデータをBitmap型に変換します。
curl --location-trusted -u <doris_user>:<doris_password> \
-H "Expect:100-continue" \
-H "columns:typ_id,hou,arr,arr=to_bitmap(arr)" \
-T streamload_example.csv \
-XPUT http://<fe_ip>:<fe_http_port>/api/testdb/test_streamload/_stream_load
HyperLogLogデータ型の読み込み
hll_hash関数を使用してデータをhll型に変換できます。以下の例を参照してください:
1001|koga
1002|nijg
1003|lojn
1004|lofn
1005|jfin
1006|kon
1007|nhga
1008|nfubg
1009|huang
1010|buag
以下のTableにデータを読み込みます:
CREATE TABLE testdb.test_streamload(
typ_id BIGINT NULL COMMENT "ID",
typ_name VARCHAR(10) NULL COMMENT "NAME",
pv hll hll_union NOT NULL COMMENT "hll"
)
AGGREGATE KEY(typ_id,typ_name)
DISTRIBUTED BY HASH(typ_id) BUCKETS 10;
そして、インポートにはhll_hashコマンドを使用します。
curl --location-trusted -u <doris_user>:<doris_password> \
-H "column_separator:|" \
-H "columns:typ_id,typ_name,pv=hll_hash(typ_id)" \
-T streamload_example.csv \
-XPUT http://<fe_ip>:<fe_http_port>/api/testdb/test_streamload/_stream_load
カラムマッピング、派生カラム、およびフィルタリング
Dorisは、loadステートメントにおいて非常に豊富なカラム変換およびフィルタリング操作をサポートしています。ほとんどの組み込み関数をサポートしています。この機能を正しく使用する方法については、Data Transformationドキュメントを参照してください。
厳密モードインポートの有効化
strict_mode属性は、インポートタスクが厳密モードで実行されるかどうかを設定するために使用されます。この属性は、カラムマッピング、変換、およびフィルタリングの結果に影響します。厳密モードの具体的な手順については、Handling Messy Dataドキュメントを参照してください。
インポート中の部分カラム更新/柔軟な部分更新の実行
インポート中に部分カラム更新を表現する方法については、Partial Column アップデートドキュメントを参照してください。