VeloDB Cloud クイックスタート
このガイドでは、数分でVeloDB Cloudを使い始める方法を説明します。warehouseを作成し、600万行のSSB-Flatベンチマークデータセットを読み込み、分析クエリを実行します。
クレジットカードは不要です。 VeloDB Cloudは$300のクレジット付きで30日間の無料トライアルを提供しています。
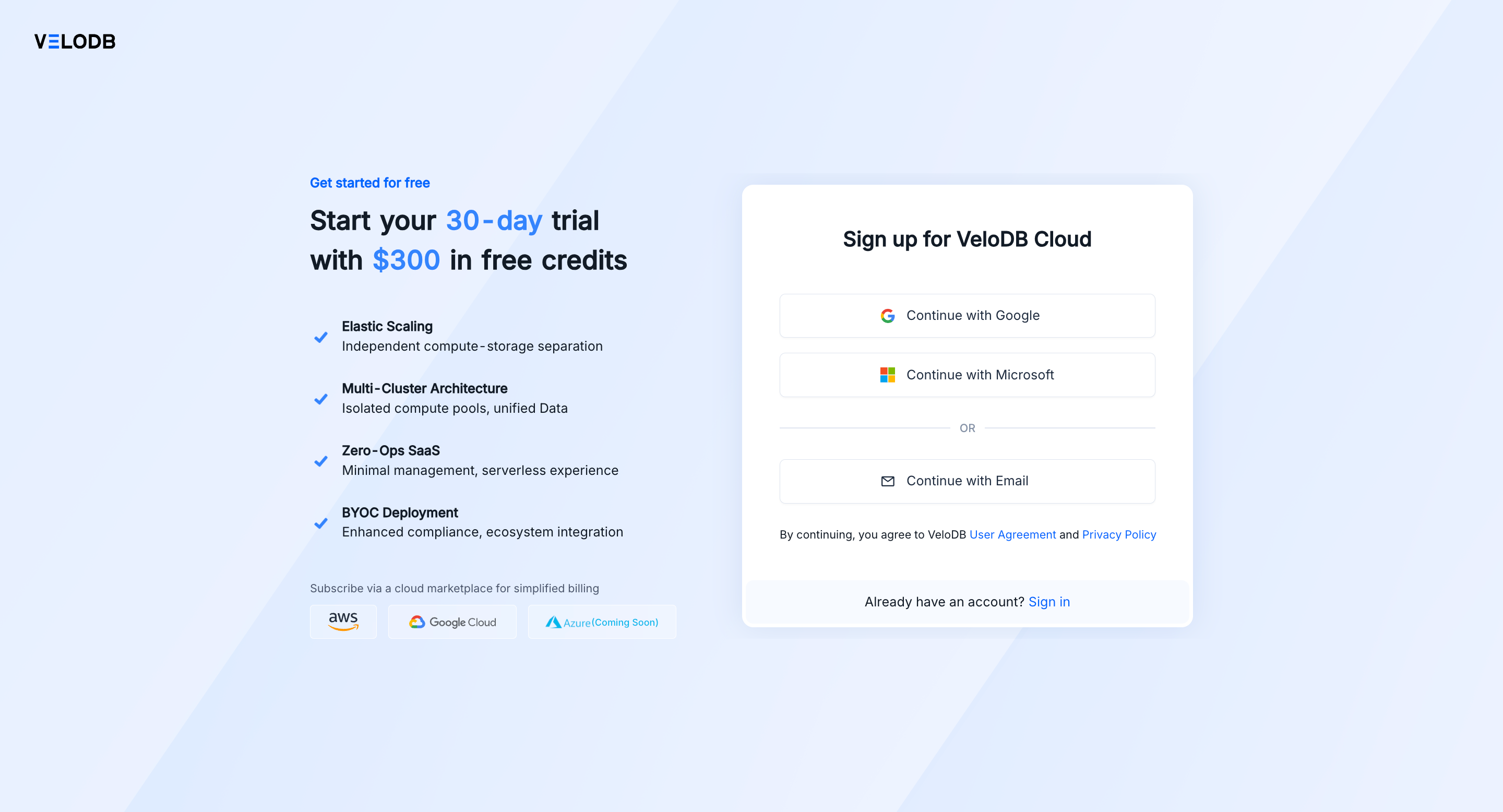
1. アカウントの作成
velodb.cloudにアクセスし、お好みの方法でサインアップしてください:
- Google - Googleアカウントでのシングルサインオン
- Microsoft - Microsoftアカウントでのシングルサインオン
- Email - 従来のメールアドレスとパスワードによる登録
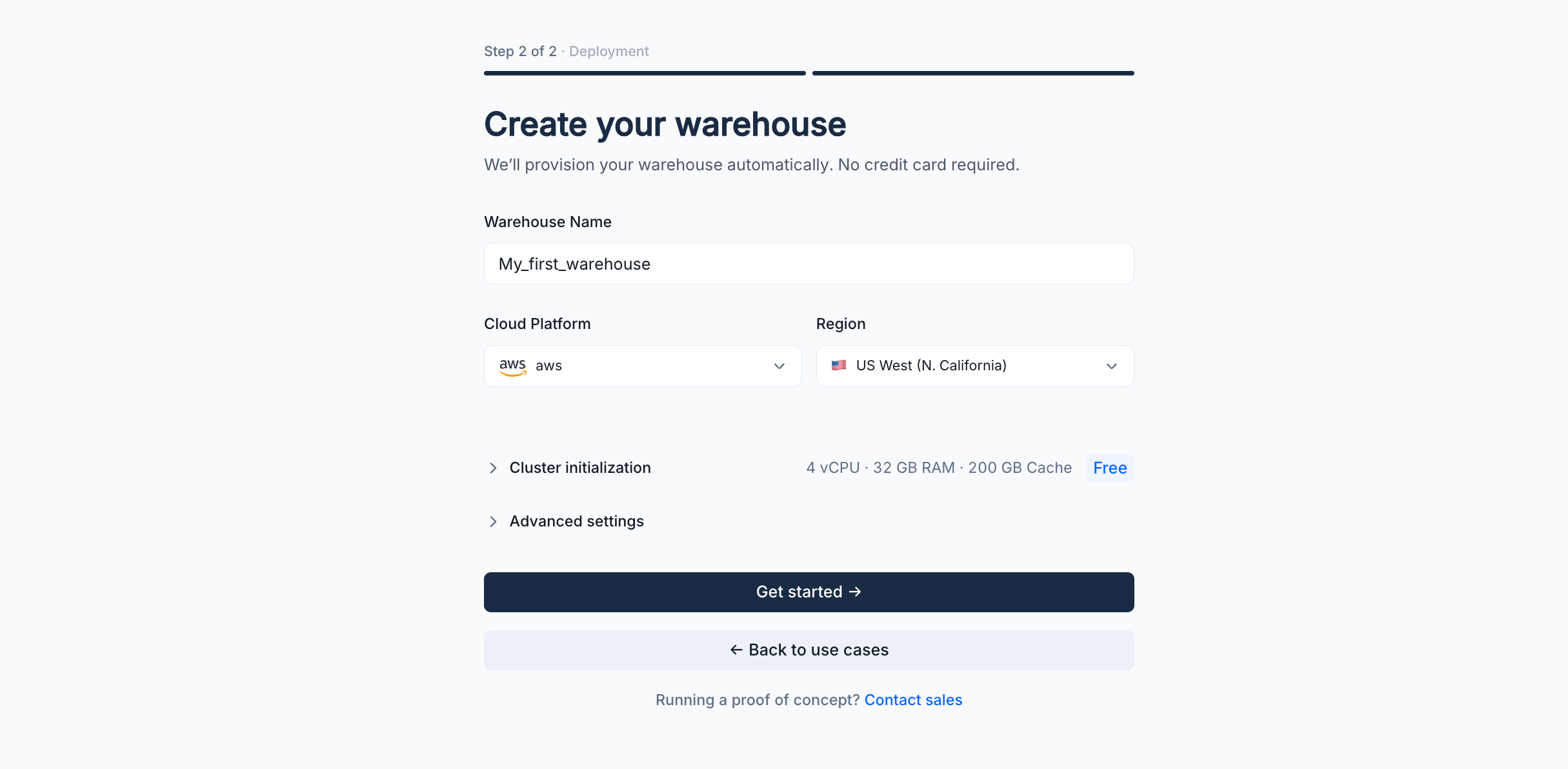
2. Warehouseの作成
warehouseを設定するために、以下のフィールドを入力してください:
| 設定 | 推奨値 |
|---|---|
| Warehouse Name | velodb-quickstart |
| Cloud Platform | AWS |
| Region | 最寄りのリージョンを選択 |
- Cluster initialization — 展開してクラスター仕様を表示・調整します。デフォルトは4 vCPU · 32 GB RAM · 200 GB Cacheです。
- Advanced settings — 展開して暗号化やテーブル名の大文字小文字の区別などの追加オプションを設定します。
**Get started →**をクリックしてwarehouseをプロビジョニングします。
VeloDBはwarehouseを3-5分でプロビジョニングします。完了すると、ステータスがRunningに変わります。
3. Warehouseへの接続
サイドバーのConnectionsに移動して、接続の詳細を確認してください:
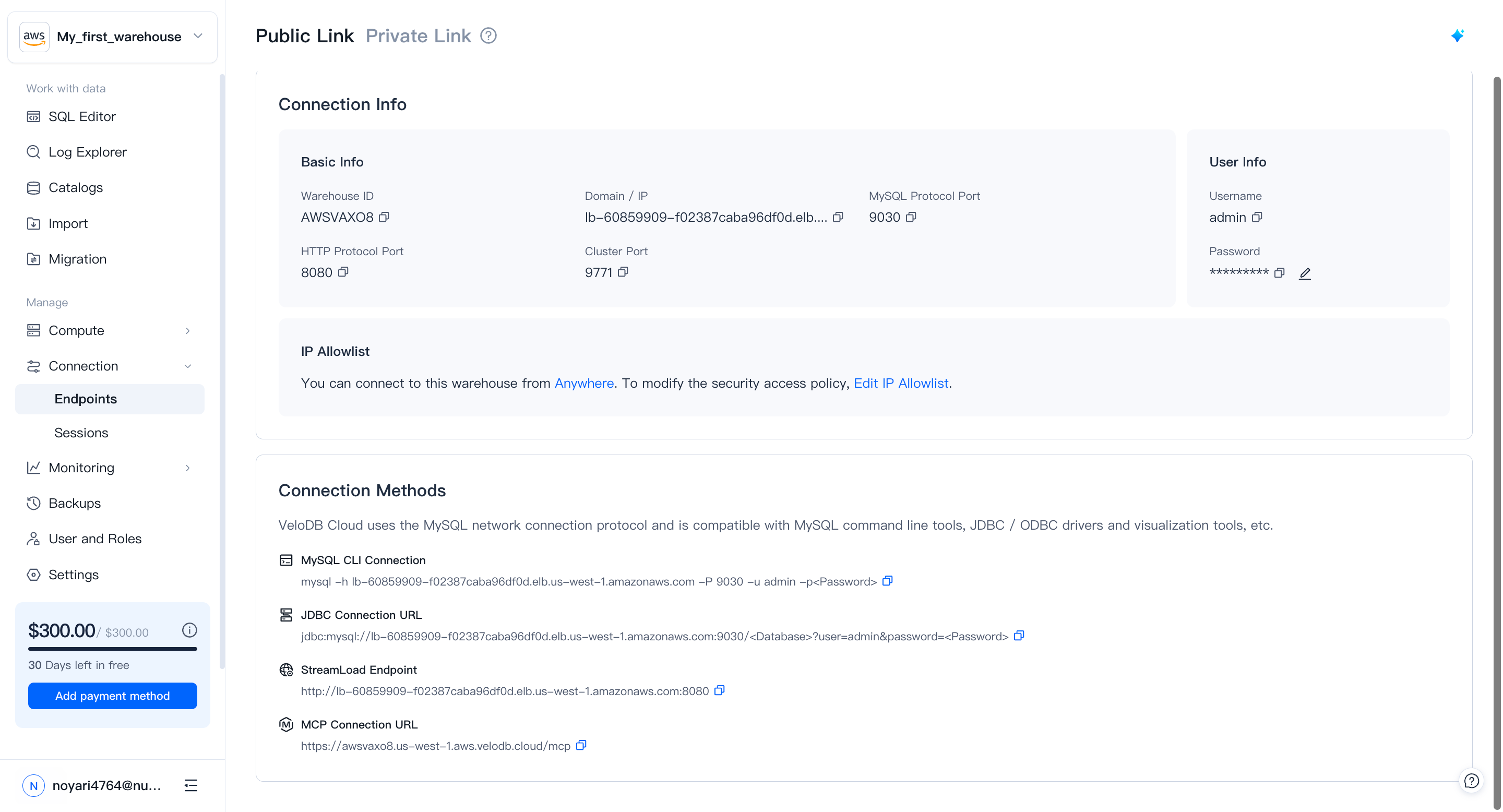
接続方法
- SQL Console (Recommended)
- MySQL CLI
- JDBC
ブラウザベースのSQLアクセスには、VeloDB Consoleサイドバーの内蔵Queryエディターを使用してください。セットアップは不要です。
mysql -h <your-host>.elb.<region>.amazonaws.com -P 9030 -u admin -p
jdbc:mysql://<your-host>.elb.<region>.amazonaws.com:9030/<database>
接続の確認
SHOW DATABASES;
期待される出力:
+--------------------+
| Database |
+--------------------+
| information_schema |
+--------------------+
4. SSB-Flat ベンチマークデータセットの読み込み
公開されている SSB-Flat SF1 データセット(600万行)を探索できるよう準備しました。この非正規化されたStar Schema Benchmarkデータセットは分析クエリに最適です。
認証情報不要! サンプルデータバケットはVeloDBから公開アクセス可能です。
S3からのデータプレビュー
読み込み前に、S3から直接データをプレビューします。最適なパフォーマンスを得るため、お使いのウェアハウスリージョンに合致するタブを選択してください:
- US East (N. Virginia)
- US West (北カリフォルニア)
- 米国西部(オレゴン)
- EU(フランクフルト)
- EU(アイルランド)
- アジア太平洋 (シンガポール)
- アジア太平洋 (東京)
- 中東(バーレーン)
SELECT
lo_orderkey,
lo_orderdate,
c_name,
c_nation,
lo_revenue,
p_brand
FROM S3(
"uri" = "s3://velodb-import-data-us-east-1/ssb-flat-sf1/ssb_flat_001.parquet",
"format" = "parquet",
"s3.endpoint" = "s3.us-east-1.amazonaws.com",
"s3.region" = "us-east-1"
)
LIMIT 5;
SELECT
lo_orderkey,
lo_orderdate,
c_name,
c_nation,
lo_revenue,
p_brand
FROM S3(
"uri" = "s3://velodb-import-data-us-west-1/ssb-flat-sf1/ssb_flat_001.parquet",
"format" = "parquet",
"s3.endpoint" = "s3.us-west-1.amazonaws.com",
"s3.region" = "us-west-1"
)
LIMIT 5;
SELECT
lo_orderkey,
lo_orderdate,
c_name,
c_nation,
lo_revenue,
p_brand
FROM S3(
"uri" = "s3://velodb-import-data-us-west-2/ssb-flat-sf1/ssb_flat_001.parquet",
"format" = "parquet",
"s3.endpoint" = "s3.us-west-2.amazonaws.com",
"s3.region" = "us-west-2"
)
LIMIT 5;
SELECT
lo_orderkey,
lo_orderdate,
c_name,
c_nation,
lo_revenue,
p_brand
FROM S3(
"uri" = "s3://velodb-import-data-eu-central-1/ssb-flat-sf1/ssb_flat_001.parquet",
"format" = "parquet",
"s3.endpoint" = "s3.eu-central-1.amazonaws.com",
"s3.region" = "eu-central-1"
)
LIMIT 5;
SELECT
lo_orderkey,
lo_orderdate,
c_name,
c_nation,
lo_revenue,
p_brand
FROM S3(
"uri" = "s3://velodb-import-data-eu-west-1/ssb-flat-sf1/ssb_flat_001.parquet",
"format" = "parquet",
"s3.endpoint" = "s3.eu-west-1.amazonaws.com",
"s3.region" = "eu-west-1"
)
LIMIT 5;
SELECT
lo_orderkey,
lo_orderdate,
c_name,
c_nation,
lo_revenue,
p_brand
FROM S3(
"uri" = "s3://velodb-import-data-ap-southeast-1/ssb-flat-sf1/ssb_flat_001.parquet",
"format" = "parquet",
"s3.endpoint" = "s3.ap-southeast-1.amazonaws.com",
"s3.region" = "ap-southeast-1"
)
LIMIT 5;
SELECT
lo_orderkey,
lo_orderdate,
c_name,
c_nation,
lo_revenue,
p_brand
FROM S3(
"uri" = "s3://velodb-import-data-ap-northeast-1/ssb-flat-sf1/ssb_flat_001.parquet",
"format" = "parquet",
"s3.endpoint" = "s3.ap-northeast-1.amazonaws.com",
"s3.region" = "ap-northeast-1"
)
LIMIT 5;
SELECT
lo_orderkey,
lo_orderdate,
c_name,
c_nation,
lo_revenue,
p_brand
FROM S3(
"uri" = "s3://velodb-import-data-me-south-1/ssb-flat-sf1/ssb_flat_001.parquet",
"format" = "parquet",
"s3.endpoint" = "s3.me-south-1.amazonaws.com",
"s3.region" = "me-south-1"
)
LIMIT 5;
データベースとテーブルの作成
-- Create database
CREATE DATABASE IF NOT EXISTS ssb;
USE ssb;
-- Create the SSB flat table
CREATE TABLE IF NOT EXISTS ssb_flat (
lo_orderkey BIGINT NOT NULL,
lo_linenumber BIGINT NOT NULL,
lo_custkey BIGINT NOT NULL,
lo_partkey BIGINT NOT NULL,
lo_suppkey BIGINT NOT NULL,
lo_orderdate DATE NOT NULL,
lo_commitdate DATE NOT NULL,
lo_orderpriority VARCHAR(15) NOT NULL,
lo_shippriority BIGINT NOT NULL,
lo_shipmode VARCHAR(10) NOT NULL,
lo_year INT NOT NULL,
lo_month INT NOT NULL,
lo_weeknum INT NOT NULL,
d_datekey BIGINT NOT NULL,
d_dayofweek VARCHAR(10) NOT NULL,
d_month VARCHAR(10) NOT NULL,
d_yearmonth VARCHAR(10) NOT NULL,
lo_quantity BIGINT NOT NULL,
lo_extendedprice DOUBLE NOT NULL,
lo_discount DOUBLE NOT NULL,
lo_revenue DOUBLE NOT NULL,
lo_supplycost DOUBLE NOT NULL,
lo_tax DOUBLE NOT NULL,
c_custkey BIGINT NOT NULL,
c_name VARCHAR(25) NOT NULL,
c_nation VARCHAR(15) NOT NULL,
c_region VARCHAR(12) NOT NULL,
c_city VARCHAR(10) NOT NULL,
c_mktsegment VARCHAR(10) NOT NULL,
s_suppkey BIGINT NOT NULL,
s_name VARCHAR(25) NOT NULL,
s_nation VARCHAR(15) NOT NULL,
s_region VARCHAR(12) NOT NULL,
s_city VARCHAR(10) NOT NULL,
p_partkey BIGINT NOT NULL,
p_name VARCHAR(22) NOT NULL,
p_brand VARCHAR(9) NOT NULL,
p_category VARCHAR(7) NOT NULL,
p_mfgr VARCHAR(6) NOT NULL,
p_color VARCHAR(11) NOT NULL,
p_type VARCHAR(25) NOT NULL,
p_size BIGINT NOT NULL,
p_container VARCHAR(10) NOT NULL,
INDEX idx_p_type (p_type) USING INVERTED PROPERTIES("parser" = "english")
)
DUPLICATE KEY(lo_orderkey)
DISTRIBUTED BY HASH(lo_orderkey) BUCKETS 48;
データの読み込み
最高のパフォーマンスを得るには、ウェアハウスと同じリージョンのS3バケットを使用してください。
- US East (N. Virginia)
- US West (北カリフォルニア)
- US West (Oregon)
- EU(フランクフルト)
- EU(アイルランド)
- アジア太平洋 (シンガポール)
- アジア太平洋(東京)
- 中東(バーレーン)
INSERT INTO ssb.ssb_flat
SELECT * FROM S3(
"uri" = "s3://velodb-import-data-us-east-1/ssb-flat-sf1/*.parquet",
"format" = "parquet",
"s3.endpoint" = "s3.us-east-1.amazonaws.com",
"s3.region" = "us-east-1"
);
INSERT INTO ssb.ssb_flat
SELECT * FROM S3(
"uri" = "s3://velodb-import-data-us-west-1/ssb-flat-sf1/*.parquet",
"format" = "parquet",
"s3.endpoint" = "s3.us-west-1.amazonaws.com",
"s3.region" = "us-west-1"
);
INSERT INTO ssb.ssb_flat
SELECT * FROM S3(
"uri" = "s3://velodb-import-data-us-west-2/ssb-flat-sf1/*.parquet",
"format" = "parquet",
"s3.endpoint" = "s3.us-west-2.amazonaws.com",
"s3.region" = "us-west-2"
);
INSERT INTO ssb.ssb_flat
SELECT * FROM S3(
"uri" = "s3://velodb-import-data-eu-central-1/ssb-flat-sf1/*.parquet",
"format" = "parquet",
"s3.endpoint" = "s3.eu-central-1.amazonaws.com",
"s3.region" = "eu-central-1"
);
INSERT INTO ssb.ssb_flat
SELECT * FROM S3(
"uri" = "s3://velodb-import-data-eu-west-1/ssb-flat-sf1/*.parquet",
"format" = "parquet",
"s3.endpoint" = "s3.eu-west-1.amazonaws.com",
"s3.region" = "eu-west-1"
);
INSERT INTO ssb.ssb_flat
SELECT * FROM S3(
"uri" = "s3://velodb-import-data-ap-southeast-1/ssb-flat-sf1/*.parquet",
"format" = "parquet",
"s3.endpoint" = "s3.ap-southeast-1.amazonaws.com",
"s3.region" = "ap-southeast-1"
);
INSERT INTO ssb.ssb_flat
SELECT * FROM S3(
"uri" = "s3://velodb-import-data-ap-northeast-1/ssb-flat-sf1/*.parquet",
"format" = "parquet",
"s3.endpoint" = "s3.ap-northeast-1.amazonaws.com",
"s3.region" = "ap-northeast-1"
);
INSERT INTO ssb.ssb_flat
SELECT * FROM S3(
"uri" = "s3://velodb-import-data-me-south-1/ssb-flat-sf1/*.parquet",
"format" = "parquet",
"s3.endpoint" = "s3.me-south-1.amazonaws.com",
"s3.region" = "me-south-1"
);
600万行の読み込みには約30秒から1分かかります。
読み込みの確認
SELECT COUNT(*) AS total_rows FROM ssb.ssb_flat;
期待される出力:
+------------+
| total_rows |
+------------+
| 6000000 |
+------------+
5. 分析クエリの実行
データセットに対して分析クエリを実行してみましょう。
Query 1: リアルタイム集計
顧客地域別に収益と割引のメトリクスを集計します:
SELECT
c_region,
COUNT(*) AS order_count,
SUM(lo_revenue) AS total_revenue,
AVG(lo_discount) AS avg_discount
FROM ssb.ssb_flat
GROUP BY c_region
ORDER BY total_revenue DESC;
Query 2: Window Functions - YoY Growth
Window関数を使用して前年同期比の売上成長率を計算する:
SELECT
lo_year,
SUM(lo_revenue) AS yearly_revenue,
LAG(SUM(lo_revenue)) OVER (ORDER BY lo_year) AS prev_year_revenue,
ROUND(
(SUM(lo_revenue) - LAG(SUM(lo_revenue)) OVER (ORDER BY lo_year))
/ LAG(SUM(lo_revenue)) OVER (ORDER BY lo_year) * 100,
2
) AS yoy_growth_pct
FROM ssb.ssb_flat
GROUP BY lo_year
ORDER BY lo_year;
Query 3: CTE を用いた複雑な BI
Common Table Expressions を使用して地域の利益階層を分析します:
WITH regional_stats AS (
SELECT
c_region,
s_region,
SUM(lo_revenue) AS revenue,
SUM(lo_supplycost) AS cost,
SUM(lo_revenue - lo_supplycost) AS profit
FROM ssb.ssb_flat
GROUP BY c_region, s_region
)
SELECT
c_region,
s_region,
revenue,
profit,
CASE
WHEN profit > 1000000000 THEN 'High'
WHEN profit > 500000000 THEN 'Medium'
ELSE 'Low'
END AS profit_tier
FROM regional_stats
ORDER BY profit DESC;
クエリ4:自己結合による期間比較
自己結合を使用して1997年と1993年の収益を比較する:
SELECT
t1.c_nation,
t1.revenue_1997,
t2.revenue_1993,
ROUND((t1.revenue_1997 - t2.revenue_1993) / t2.revenue_1993 * 100, 2) AS growth_pct
FROM (
SELECT c_nation, SUM(lo_revenue) AS revenue_1997
FROM ssb.ssb_flat
WHERE lo_year = 1997
GROUP BY c_nation
) t1
JOIN (
SELECT c_nation, SUM(lo_revenue) AS revenue_1993
FROM ssb.ssb_flat
WHERE lo_year = 1993
GROUP BY c_nation
) t2 ON t1.c_nation = t2.c_nation
ORDER BY growth_pct DESC;
クエリ 5: 全文検索
転置インデックスを使用して、製品タイプに「STEEL」を含む製品を検索:
SELECT
p_type,
p_brand,
COUNT(*) AS product_count,
SUM(lo_revenue) AS total_revenue
FROM ssb.ssb_flat
WHERE p_type MATCH 'STEEL'
GROUP BY p_type, p_brand
ORDER BY total_revenue DESC
LIMIT 10;
次のステップ
- 課金の設定 - Billing Center経由で支払い方法を追加
- 独自データのインポート - S3 Import Guideを参照
- 詳細を学ぶ - VeloDB documentationを探索