レイクハウス概要
レイクハウスは、データレイクとデータウェアハウスの利点を組み合わせた現代的なビッグデータソリューションです。データレイクの低コストと高いスケーラビリティを、データウェアハウスの高性能と強力なデータガバナンス機能と統合し、ビッグデータ時代における様々なデータの効率的で安全、かつ品質管理された保存と処理分析を可能にします。標準化されたオープンデータフォーマットとメタデータ管理を通じて、リアルタイムデータと履歴データ、バッチ処理とストリーム処理を統合し、企業のビッグデータソリューションの新たな標準として徐々に確立されています。
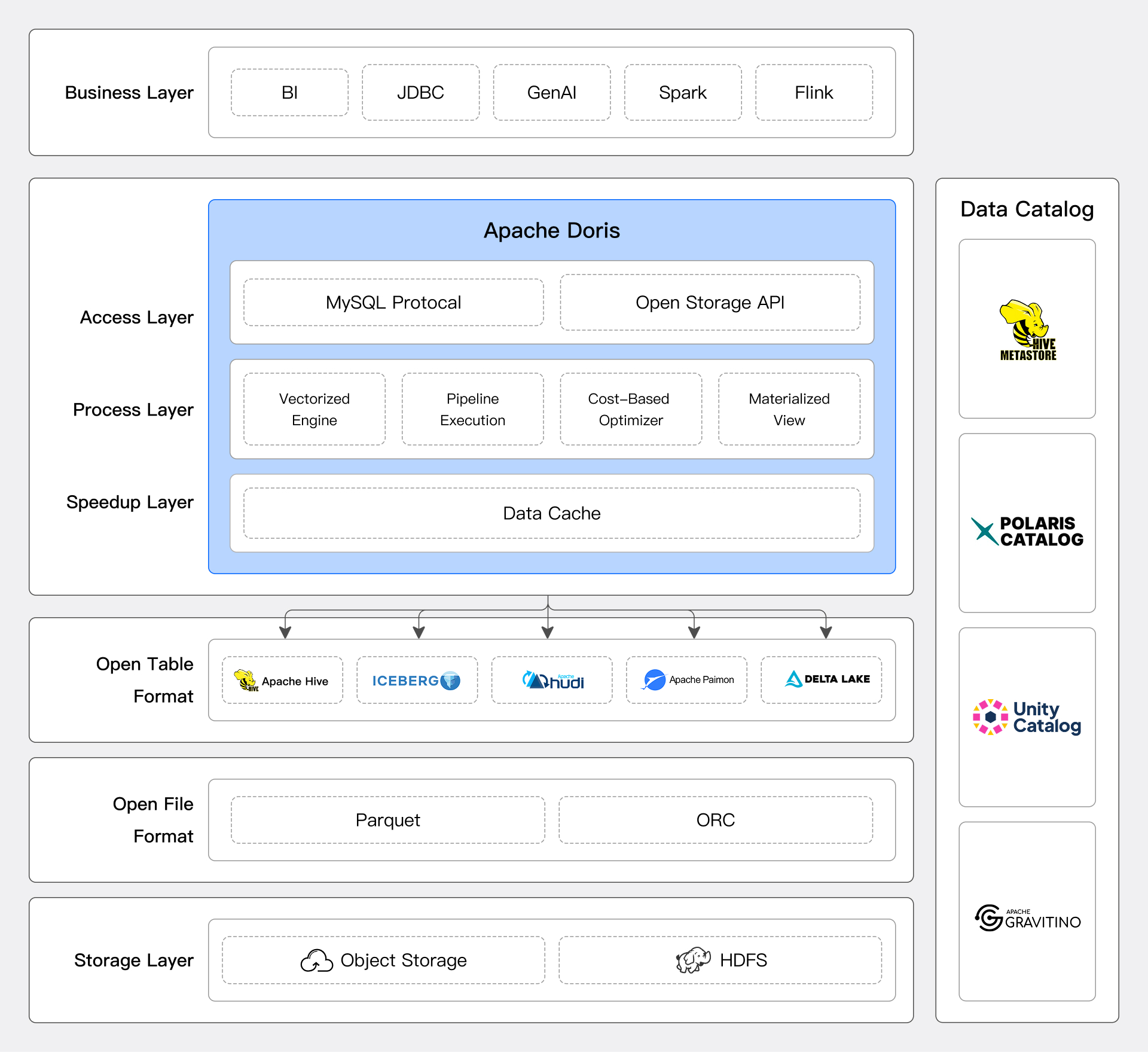
Doris レイクハウスソリューション
Dorisは、拡張可能なconnectorフレームワーク、コンピュート・ストレージ分離アーキテクチャ、高性能データ処理エンジン、およびデータエコシステムの開放性を通じて、ユーザーに優れたレイクハウスソリューションを提供します。
柔軟なデータアクセス
Dorisは、拡張可能なconnectorフレームワークを通じて主要なデータシステムとデータフォーマットアクセスをサポートし、SQLベースの統合データ分析機能を提供します。これにより、ユーザーは既存のデータを移動することなく、クロスプラットフォームデータクエリと分析を簡単に実行できます。詳細については、カタログ 概要を参照してください。
データソースConnector
Hive、Iceberg、Hudi、Paimon、またはJDBCプロトコルをサポートするデータベースシステムのいずれであっても、Dorisは簡単に接続し、効率的にデータにアクセスできます。
レイクハウスシステムに対して、DorisはHive Metastore、AWS Glue、Unity CatalogなどのメタデータサービスからデータTableの構造と分散情報を取得し、合理的なクエリプランニングを実行し、MPPアーキテクチャを活用した分散コンピューティングを行います。
詳細については、Iceberg カタログなどの各catalogドキュメントを参照してください。
拡張可能なConnectorフレームワーク
Dorisは優れた拡張性フレームワークを提供し、開発者が企業内の独自のデータソースに迅速に接続し、高速なデータ相互運用性を実現できるように支援します。
Dorisは、カタログ、Database、Tableの3レベルの標準を定義し、開発者が必要なデータソースレベルに簡単にマッピングできるようにします。Dorisはまた、メタデータサービスとストレージサービスアクセスのための標準インターフェースを提供し、開発者は対応するインターフェースを実装するだけでデータソース接続を完了できます。
DorisはTrino Connectorプラグインと互換性があり、TrinoプラグインパッケージをDorisクラスタに直接デプロイし、最小限の設定で対応するデータソースにアクセスできます。DorisはすでにKudu、BigQuery、Delta Lakeなどのデータソースへの接続を完了しています。また、新しいプラグインを自分で適応させることも可能です。
便利なクロスソースデータ処理
Dorisは実行時に複数のデータcatalogの作成をサポートし、SQLを使用してこれらのデータソースに対する連合クエリを実行できます。例えば、ユーザーはHive内のファクトTableデータとMySQL内のディメンションTableデータを関連付けてクエリできます:
SELECT h.id, m.name
FROM hive.db.hive_table h JOIN mysql.db.mysql_table m
ON h.id = m.id;
Dorisの組み込みジョブスケジューリング機能と組み合わせることで、スケジュールされたタスクを作成してシステムの複雑さをさらに簡素化することもできます。例えば、ユーザーは上記のクエリの結果を毎時実行される定期タスクとして設定し、各結果をIcebergTableに書き込むことができます:
CREATE JOB schedule_load
ON SCHEDULE EVERY 1 HOUR DO
INSERT INTO iceberg.db.ice_table
SELECT h.id, m.name
FROM hive.db.hive_table h JOIN mysql.db.mysql_table m
ON h.id = m.id;
高性能データ処理
分析データウェアハウスとして、DorisはレイクハウスデータProcessingと計算において数多くの最適化を行い、豊富なクエリ高速化機能を提供しています:
-
実行エンジン
Doris実行エンジンはMPP実行フレームワークとPipelineデータ処理モデルに基づいており、マルチマシン・マルチコア分散環境で大量データを高速処理できます。完全ベクトル化実行オペレータのおかげで、DorisはTPC-DSのような標準ベンチマークデータセットにおいて計算性能で優位性を持っています。
-
クエリオプティマイザ
Dorisはクエリオプティマイザを通じて複雑なSQLリクエストを自動的に最適化・処理できます。クエリオプティマイザはマルチTablejoin、集約、ソート、ページネーションなど、様々な複雑なSQL演算子を深く最適化し、コストモデルと関係代数変換を十分に活用して、より良いまたは最適な論理・物理実行計画を自動的に取得し、SQL記述の難易度を大幅に削減し、使いやすさと性能を向上させています。
-
データキャッシュとIO最適化
外部データソースへのアクセスは通常ネットワークアクセスであり、高遅延と安定性の問題が生じる場合があります。Apache Dorisは豊富なキャッシュメカニズムを提供し、キャッシュタイプ、適時性、戦略において数多くの最適化を行い、メモリとローカル高速ディスクを十分に活用してホットデータの分析性能を向上させています。さらに、Dorisは高スループット、低IOPS、高遅延などのネットワークIO特性に対して的を絞った最適化を行い、ローカルデータに匹敵する外部データソースアクセス性能を提供しています。
-
マテリアライズドビューと透過的高速化
Dorisは豊富なマテリアライズドビューの更新戦略を提供し、フルおよびパーティションレベルでの増分リフレッシュをサポートして構築コストを削減し、適時性を向上させています。手動リフレッシュに加え、Dorisはスケジュールリフレッシュとデータドリブンリフレッシュもサポートし、メンテナンスコストをさらに削減し、データ一貫性を向上させています。マテリアライズドビューは透過的高速化機能も持ち、クエリオプティマイザが適切なマテリアライズドビューに自動的にルーティングしてシームレスなクエリ高速化を実現できます。さらに、Dorisのマテリアライズドビューは高性能ストレージフォーマットを使用し、列ストレージ、圧縮、インテリジェントインデックス技術を通じて効率的なデータアクセス能力を提供し、データキャッシュの代替として機能し、クエリ効率を向上させています。
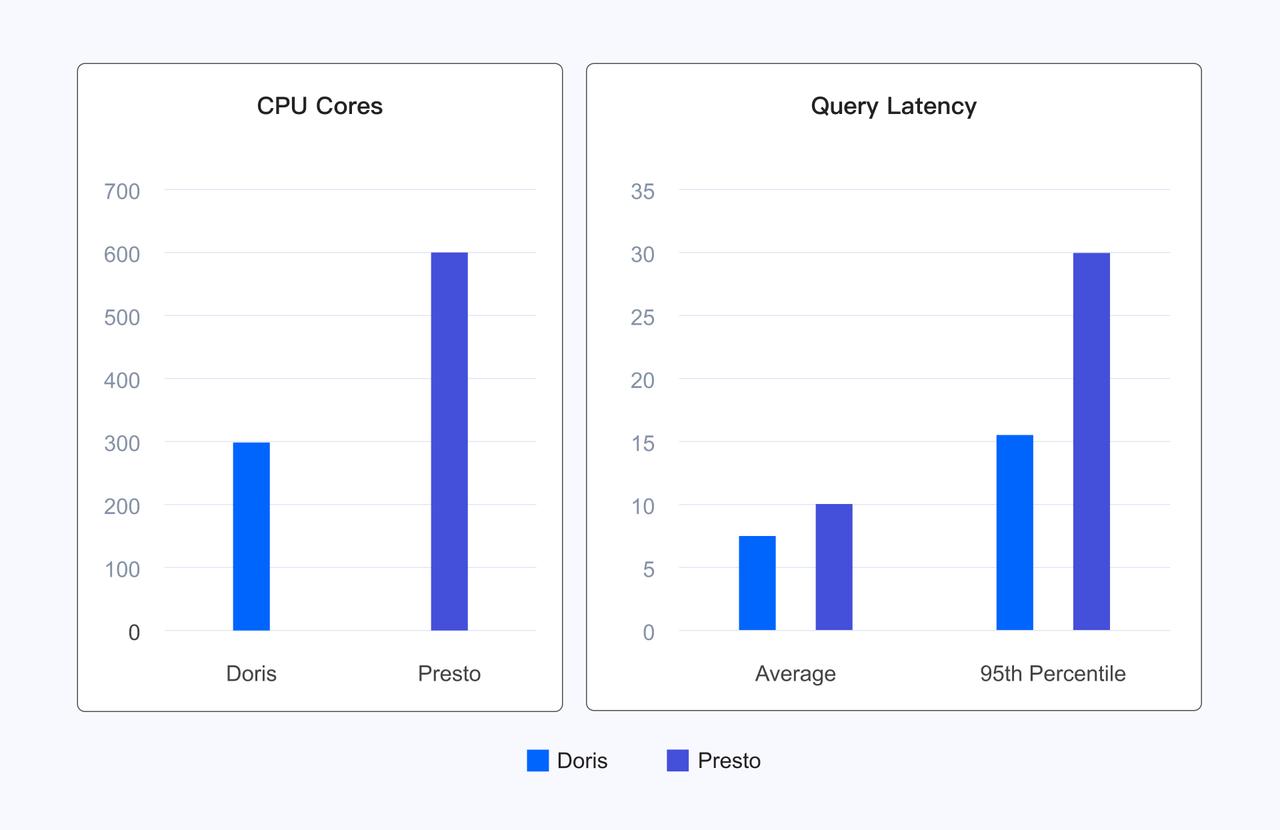
以下に示すように、IcebergTableフォーマットに基づく1TB TPCDSの標準テストセットにおいて、Dorisの99クエリの全体実行時間はTrinoの1/3にすぎません。

実際のユーザーシナリオでは、Dorisはリソース使用量を半分にしながら、Prestoと比較して平均クエリ遅延を20%削減し、95パーセンタイル遅延を50%削減しており、ユーザー体験を向上させながらリソースコストを大幅に削減しています。
便利なサービス移行
複数データソースの統合とレイクハウス変換を実現する過程で、システム間のSQL方言の構文と機能サポートの違いにより、SQLクエリをDorisに移行することは課題となります。適切な移行計画がなければ、ビジネス側は新しいシステムのSQL構文に適応するため大幅な修正が必要になる可能性があります。
この問題に対処するため、Dorisは SQL Dialect Conversion Service を提供し、ユーザーが他のシステムのSQL方言を直接使用してデータクエリを実行できるようにしています。変換サービスはこれらのSQL方言をDoris SQLに変換し、ユーザーの移行コストを大幅に削減します。現在、DorisはPresto/Trino、Hive、PostgreSQL、Clickhouseなどの一般的なクエリエンジンのSQL方言変換をサポートし、一部の実際のユーザーシナリオでは99%を超える互換性を実現しています。
モダンなデプロイメントアーキテクチャ
バージョン3.0以降、Dorisはクラウドネイティブなコンピュート・ストレージ分離アーキテクチャをサポートしています。このアーキテクチャは低コストと高弾性性により、リソース使用率を効果的に向上させ、コンピュートとストレージの独立したスケーリングを可能にします。
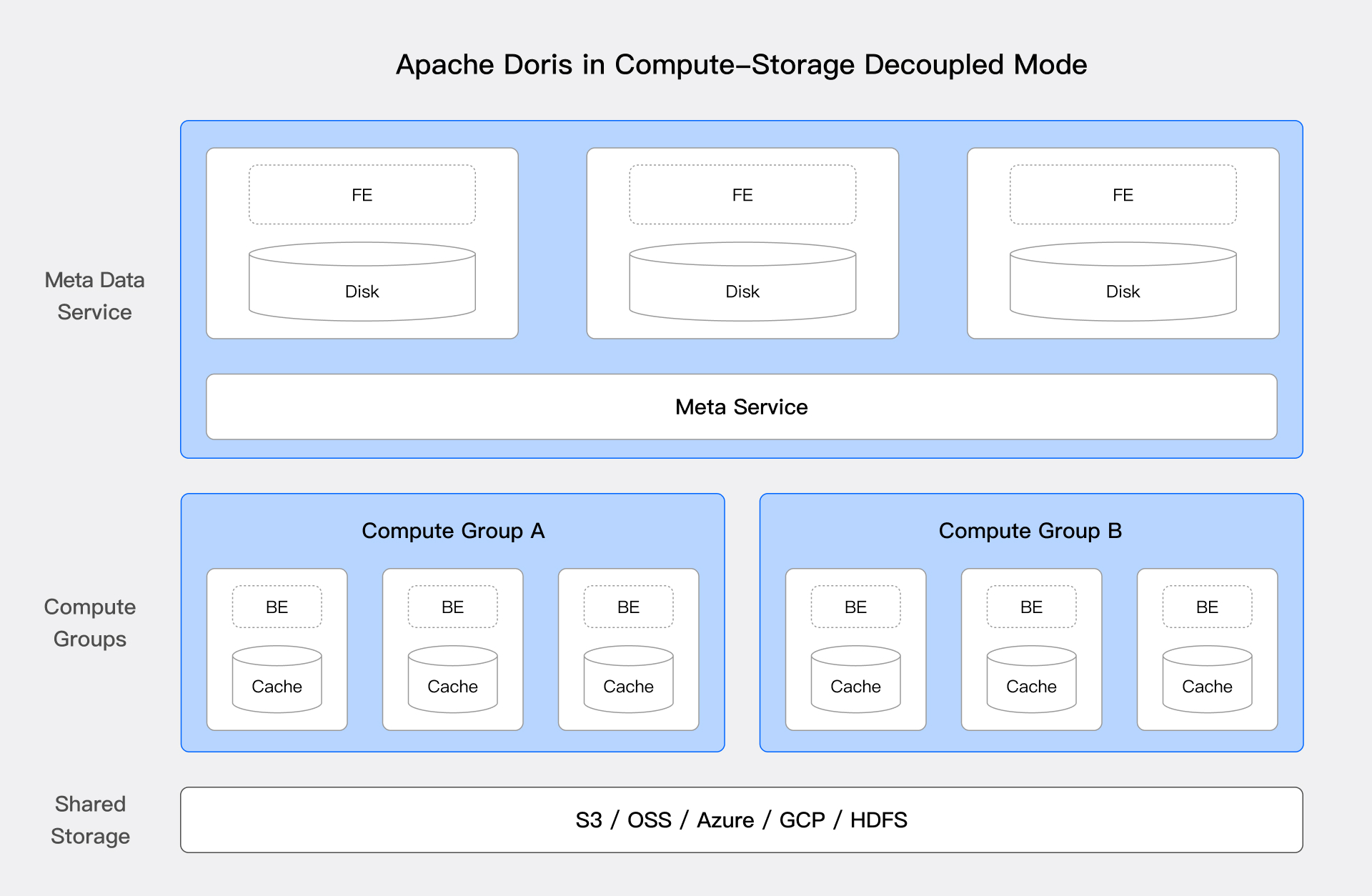
上図はDorisのコンピュート・ストレージ分離のシステムアーキテクチャを示し、コンピュートとストレージを分離しています。コンピュートノードはもはや主データを保存せず、基盤となる共有ストレージ層(HDFSとオブジェクトストレージ)が統一された主データストレージ空間として機能し、コンピュートとストレージリソースの独立したスケーリングをサポートします。コンピュート・ストレージ分離アーキテクチャはレイクハウスソリューションに重要な利点をもたらします:
-
低コストストレージ:ストレージとコンピュートリソースを独立してスケーリングでき、企業はコンピュートリソースを増やすことなくストレージ容量を増やせます。さらに、クラウドオブジェクトストレージを使用することで、企業はより低いストレージコストとより高い可用性を享受でき、相対的に低い割合のホットデータのキャッシュにはローカル高速ディスクを使用できます。
-
単一の信頼できる情報源:すべてのデータが統一されたストレージ層に保存され、同じデータが異なるコンピュートクラスタからアクセス・処理でき、データ一貫性と整合性を確保し、データ同期と重複ストレージの複雑さを削減します。
-
ワークロードの多様性:ユーザーは異なるワークロードニーズに基づいてコンピュートリソースを動的に割り当て、バッチ処理、リアルタイム分析、機械学習など様々なアプリケーションシナリオをサポートできます。ストレージとコンピュートを分離することで、企業はリソース使用をより柔軟に最適化し、異なる負荷下での効率的な運用を確保できます。
さらに、ストレージ・コンピュート結合アーキテクチャの下でも、elastic computing nodesを使用してlakewarehouseデータクエリシナリオにおける弾性コンピュート機能を提供できます。
オープン性
DorisはオープンなlakeTableフォーマットへのアクセスをサポートするだけでなく、自身の保存データに対しても良好なオープン性を持っています。DorisはオープンなストレージAPIを提供し、Arrow Flight SQLプロトコルに基づく高速データリンクを実装し、Arrow Flightの速度優位性とJDBC/ODBCの使いやすさを提供しています。このインターフェースに基づいて、ユーザーはPython/Java/Spark/FlinkのABDCクライアントを使用してDorisに保存されたデータにアクセスできます。
オープンファイルフォーマットと比較して、オープンストレージAPIは基盤となるファイルフォーマットの具体的な実装を抽象化し、Dorisが豊富なインデックスメカニズムなど、ストレージフォーマットの高度な機能を通じてデータアクセスを高速化できるようにします。さらに、上位層のコンピュートエンジンは基盤となるストレージフォーマットの変更や新機能に適応する必要がなく、サポートされているすべてのコンピュートエンジンが同時に新機能の恩恵を受けることができます。
レイクハウスベストプラクティス
レイクハウスソリューションにおいて、Dorisは主にレイクハウスクエリ高速化、マルチソース連合分析、レイクハウスデータ処理に使用されます。
レイクハウスクエリ高速化
このシナリオでは、Dorisはコンピュートエンジンとして機能し、レイクハウスデータのクエリ分析を高速化します。
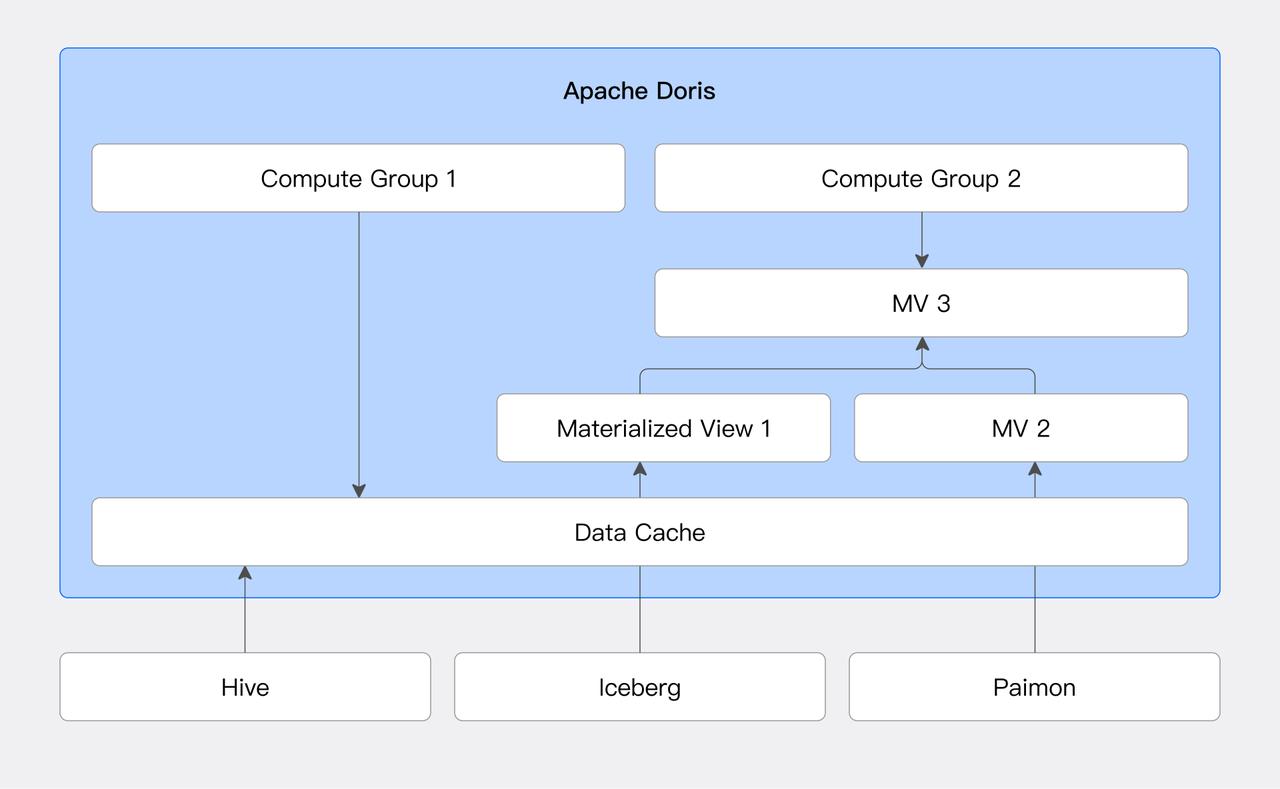
キャッシュ高速化
HiveやIcebergのようなレイクハウスシステムに対して、ユーザーはローカルディスクキャッシュを設定できます。ローカルディスクキャッシュはクエリに関連するデータファイルをローカルキャッシュディレクトリに自動的に保存し、LRU戦略を使用してキャッシュエビクションを管理します。詳細については、Data Cacheドキュメントを参照してください。
マテリアライズドビューと透過的リライト
Dorisは外部データソースに対してマテリアライズドビューの作成をサポートしています。マテリアライズドビューはSQL定義文に基づいて事前計算された結果をDoris内部Tableフォーマットとして保存します。さらに、DorisのクエリオプティマイザはSPJG(SELECT-PROJECT-JOIN-GROUP-BY)パターンに基づく透過的リライトアルゴリズムをサポートしています。このアルゴリズムはSQLの構造情報を分析し、透過的リライトに適したマテリアライズドビューを自動的に見つけ、クエリSQLに応答する最適なマテリアライズドビューを選択できます。
この機能は実行時計算を削減することでクエリ性能を大幅に向上させることができます。また、ビジネス側の認識なしに透過的リライトを通じてマテリアライズドビュー内のデータにアクセスできます。詳細については、Materialized Viewsドキュメントを参照してください。
マルチソース連合分析
Dorisは統一SQLクエリエンジンとして機能し、異なるデータソースを接続して連合分析を行い、データサイロの問題を解決できます。
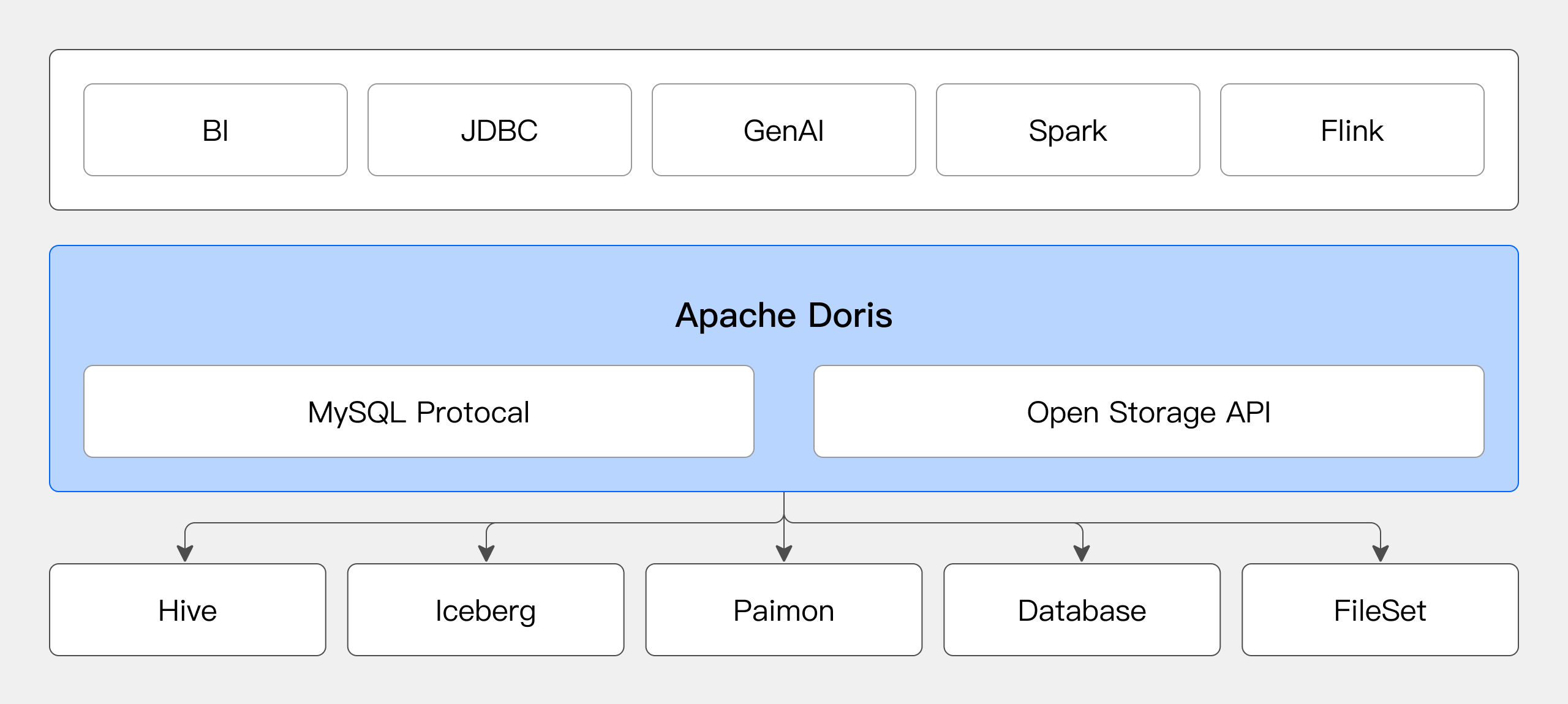
ユーザーはDoris内で複数のカタログを動的に作成して異なるデータソースに接続できます。SQL文を使用して異なるデータソースからのデータに対して任意のjoinクエリを実行できます。詳細については、カタログ 概要を参照してください。
レイクハウスデータ処理
このシナリオでは、Dorisはデータ処理エンジンとして機能し、レイクハウスデータを処理します。
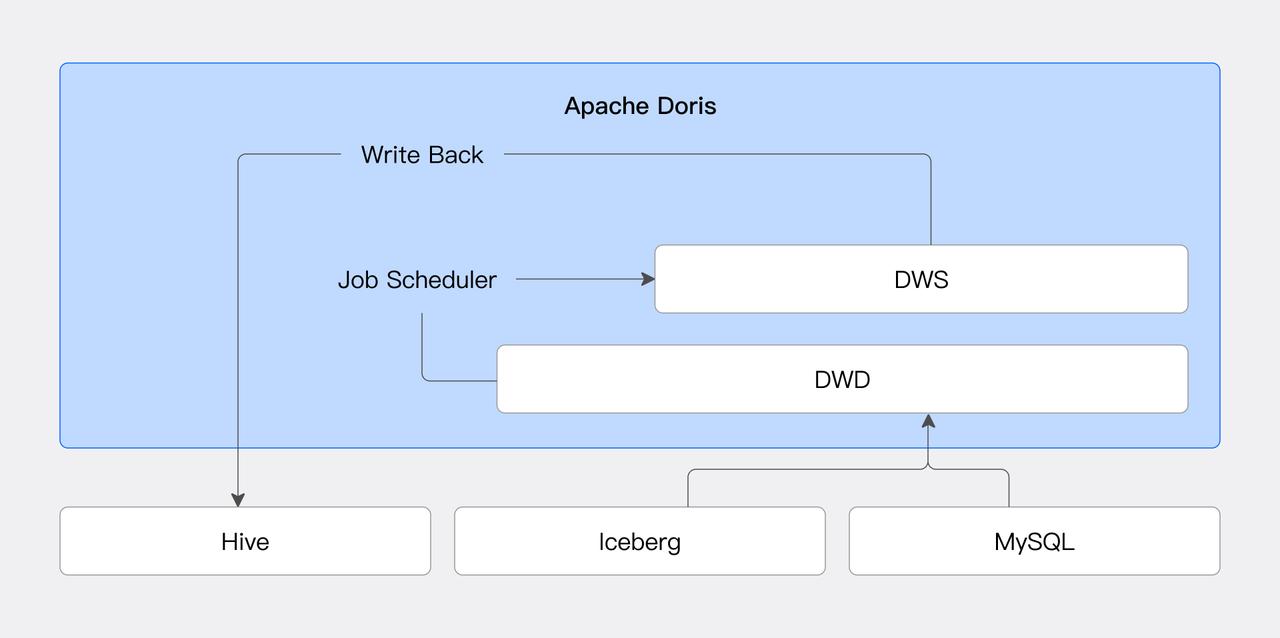
タスクスケジューリング
DorisはJob Scheduler機能を導入し、効率的で柔軟なタスクスケジューリングを可能にし、外部システムへの依存を削減します。データソースコネクタと組み合わせることで、ユーザーは外部データの定期的な処理と保存を実現できます。詳細については、Job Schedulerを参照してください。
データモデリング
ユーザーは通常、データレイクを使用して生データを保存し、これを基盤として階層的なデータ処理を実行し、異なる層のデータを異なるビジネスニーズに利用できるようにします。Dorisのマテリアライズドビュー機能は外部データソースに対するマテリアライズドビューの作成をサポートし、マテリアライズドビューに基づくさらなる処理をサポートして、システムの複雑さを削減し、データ処理効率を向上させます。
データライトバック
データライトバック機能はDorisのレイクハウスデータ処理能力のクローズドループを形成します。ユーザーはDorisを通じて外部データソースに直接データベースとTableを作成し、データを書き込むことができます。現在、JDBC、Hive、Icebergデータソースがサポートされており、将来的にはより多くのデータソースが追加される予定です。詳細については、対応するデータソースのドキュメントを参照してください。