インポート
Importモジュールは、データ統合のための統一されたビジュアルインターフェースを提供します。外部ソースから VeloDB Cloud のターゲットデータウェアハウスへデータをシームレスに取り込むことができます。バッチデータロードと自動テーブル作成による継続的データ取り込みの両方をサポートし、このモジュールはデータパイプライン構築の障壁を大幅に下げます。
この機能には、VeloDB Studio の左サイドバーの Data -> Import に移動し、Add Import Job ボタンをクリックして新しいタスクを作成することでアクセスできます。
サポートされるデータソース
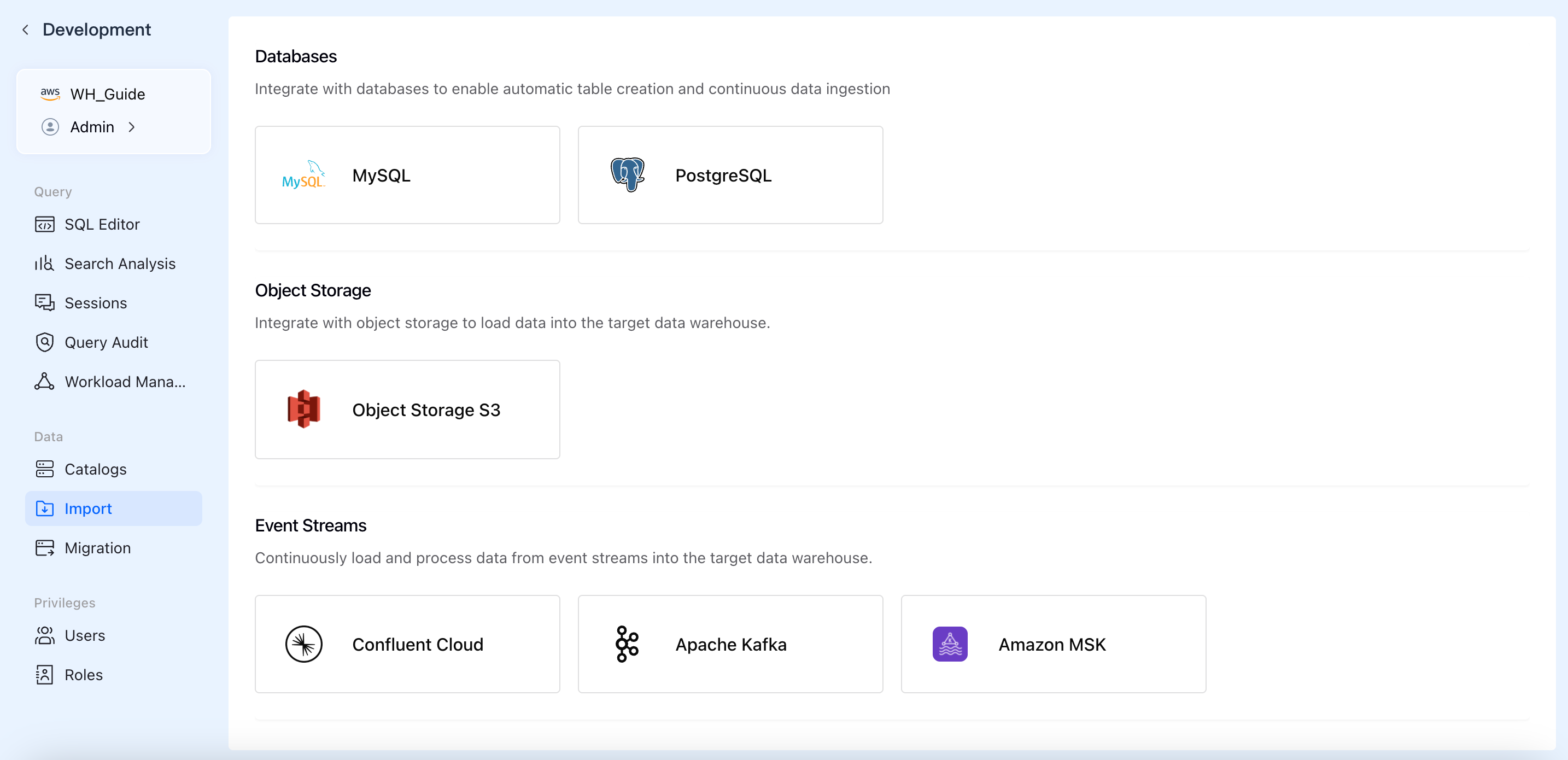
ビジネスシナリオとデータストレージタイプに応じて、VeloDB Cloud は現在3つの主要カテゴリからのデータインポートをサポートしています:
- データベース
- MySQL
- PostgreSQL
- オブジェクトストレージ
- Object Storage S3
- イベントストリーム
- Confluent Cloud
- Apache Kafka
- Amazon MSK
インポートジョブの作成
設定の詳細はデータソースによって若干異なりますが、VeloDB Cloud は一貫した5ステップのウィザード駆動体験を提供します。以下は、データベースインポートを例とした一般的なガイドです:
1. データソースの選択
- VeloDB Cloud コンソールにログインし、Data セクションの左ナビゲーションペインで Import をクリックします。
- 右上の + Add Import Job ボタンをクリックします。
- 対応するカテゴリから希望するデータソースカード(例:
PostgreSQL)を選択します。
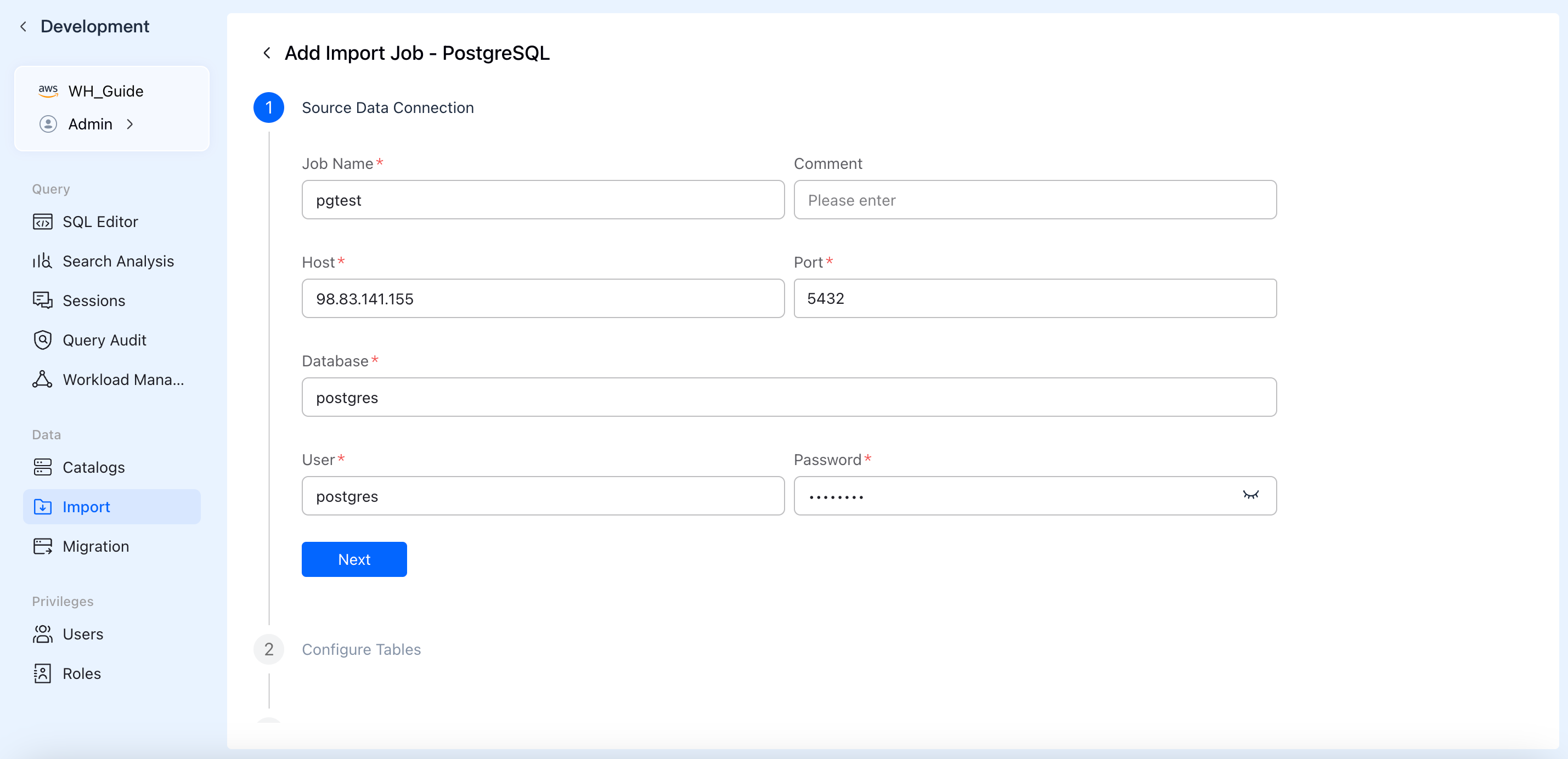
2. ソースデータ接続の設定
データソースとの安全な接続を確立するために認証詳細を入力します。
- Job Name:管理と識別を容易にするため、インポートジョブのグローバルに一意な名前を指定します。
- Connection Credentials:ソースに応じて、Host、Port、Database Name、Username、Password、または AK/SK キーなどの詳細を入力します。
- Next をクリックします。システムはバックグラウンドでネットワーク接続と認証情報の有効性を自動的に検証します。
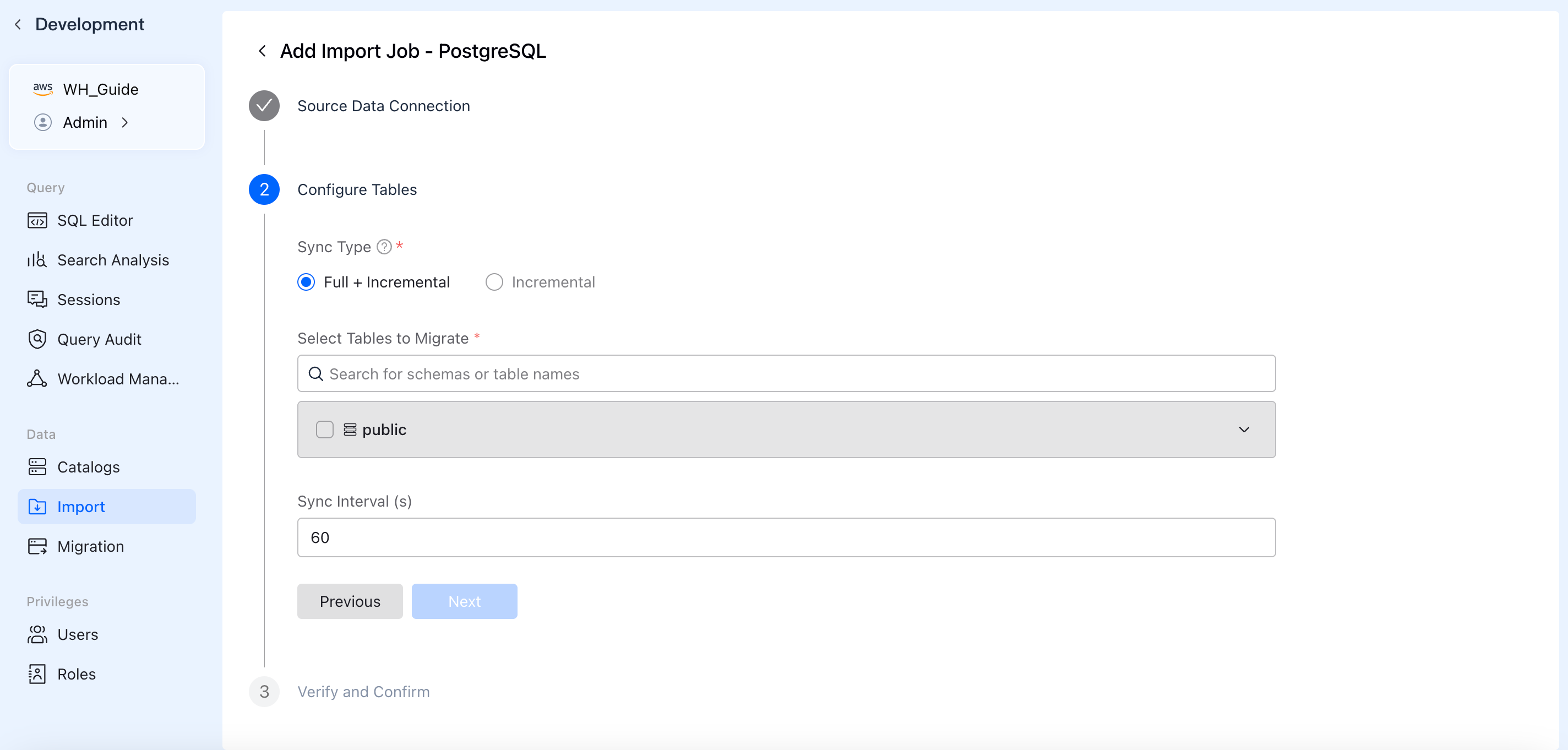
3. 同期範囲の設定(テーブル / トピック)
プルするデータと書き込み方法を定義します。
- Sync Type:Full + Incremental 同期または Incremental のみを選択します。
- Data Scope:
- データベースの場合:同期するスキーマとテーブルを選択します。
Column Settings下でカラムレベルのフィルタリングを適用するためにテーブルを展開できます。 - イベントストリームの場合:消費するトピックと開始オフセットを指定します。
- オブジェクトストレージの場合:バケットパスとファイルマッチングパターンを指定します。
- データベースの場合:同期するスキーマとテーブルを選択します。
- Sync Interval:データ取得の頻度を設定します(デフォルトは通常60秒です)。
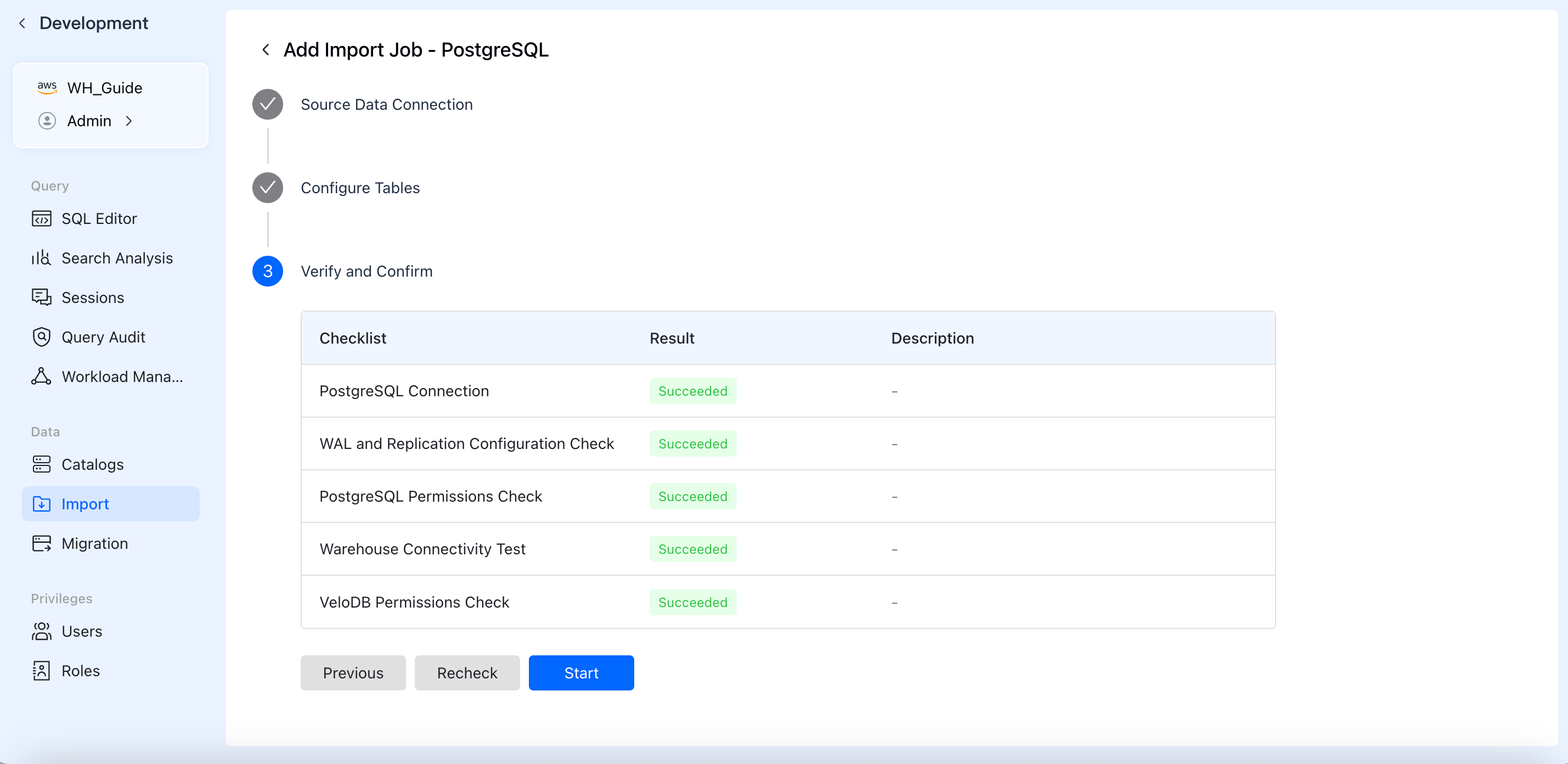
4. 検証と確認
ジョブが正常に実行されることを確実にするため、システムは自動的に事前チェック Checklist を実行します。
- チェックには通常以下が含まれます:ネットワーク接続テスト、ソース側権限検証(例:CDC に必要な WAL/Binlog 権限)、およびターゲット側テーブル作成/書き込み権限。
- すべてのチェックリスト項目が緑色の Succeeded を表示したら、Start をクリックしてデータインポートジョブを正式に開始します。
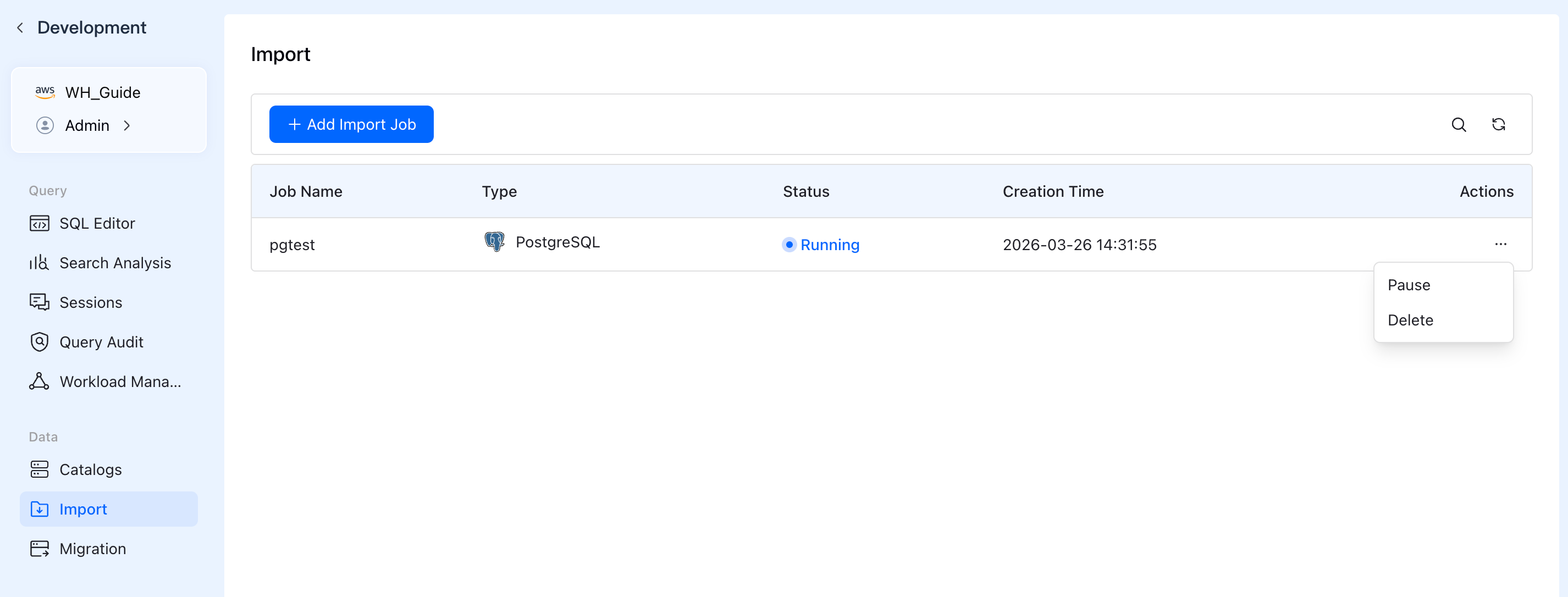
5. 管理と監視
ジョブ開始後、Import ジョブリストに戻ります。
- ステータス表示:ジョブのリアルタイム
Status(例:*Running*、*Paused*、*Failed*)と作成時間を監視します。 - アクション:ビジネスニーズの変化に応じて、ジョブの横の
...(Actions)メニューをクリックしてインポートタスクを Pause、Resume、または Delete します。