Monitoring
VeloDB CloudはMonitoringとAlertingを提供し、warehouseとclusterの健全性とパフォーマンスを追跡し、何か変化があった際に対応することができます。
左ナビゲーションのManageグループからMonitoringを開きます。Monitoringには4つのサブページがあります:Metrics、Alerts、Query Audit、Usage。
Metrics
Metricsページでは以下のことができます:
- warehouseまたはcluster別にmetricsを表示。
- Starredを使用して、warehouse間やcluster間で関心のあるmetricsをピン留めし、一緒に表示。
- 時間セレクターを調整して、過去15日までの履歴データを確認。
- ほぼリアルタイムの更新(5秒間隔)のために自動更新を有効化。
Metricsは2つのカテゴリに分かれています:Basic Metrics(物理リソース使用率)とService Metrics(query / workload パフォーマンス)。
Basic metrics
Basic metricsはnode別にclusterの物理使用率を追跡します。これらは指定された時間範囲でclusterが健全かどうかを判断し、過去または現在のqueryがパフォーマンスに影響しているかどうかを把握するのに役立ちます — scale up、scale down、またはSQL最適化を計画する際の有用な入力情報です。
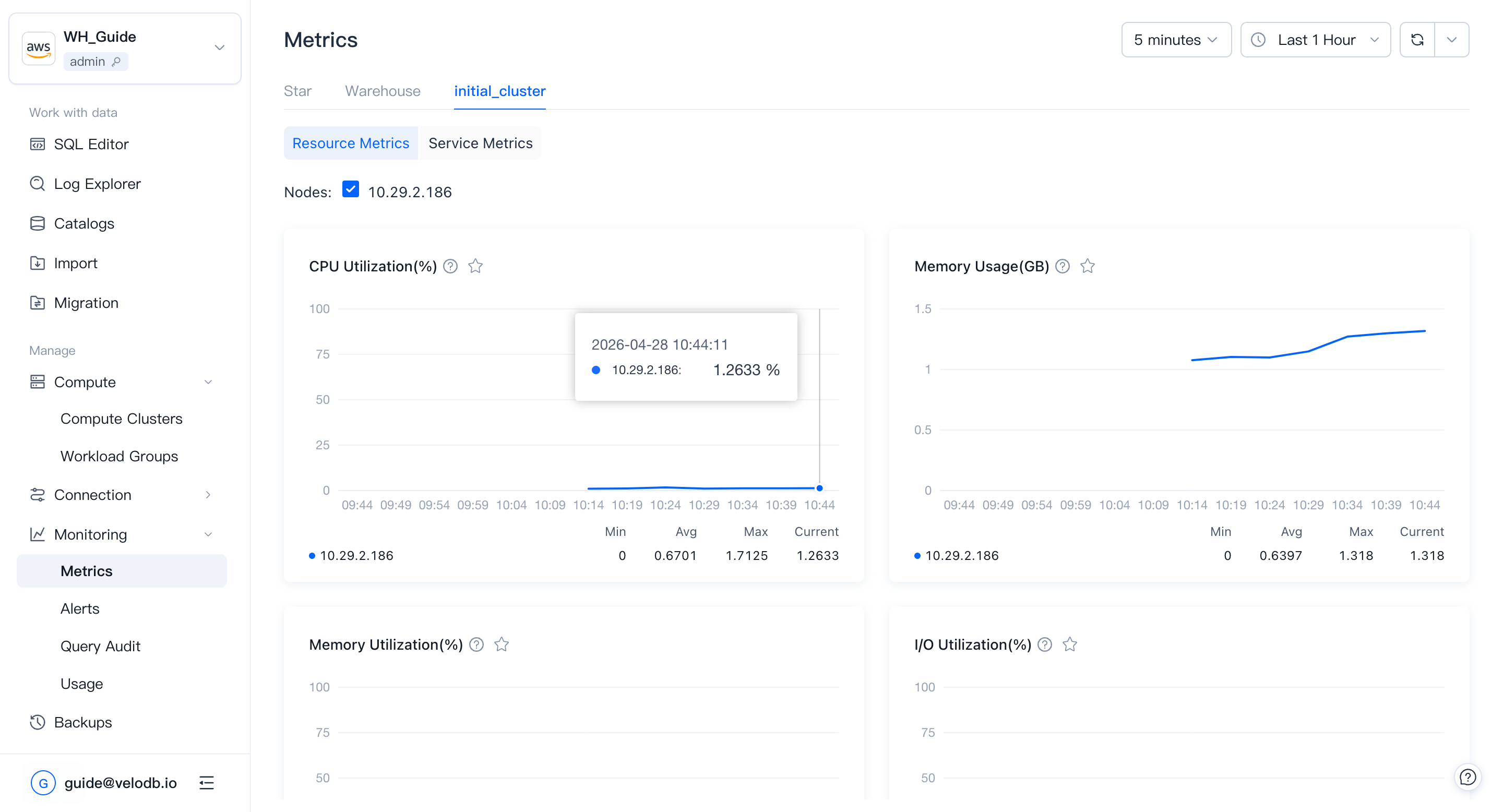
| Metric | What it shows |
|---|---|
| CPU Utilization | 全nodeでのCPU使用率のパーセンテージ。scalingやその他のリソース集約的な操作のための静穏な時間帯を見つけるのに有用。 |
| Memory Usage | 全nodeで消費されるメモリ。継続的に高い使用量はscale upのシグナル。 |
| Memory Utilization | 全nodeのメモリ使用率。継続的に高い使用率はscale upのシグナル。 |
| I/O Utilization | ディスクI/O使用率。継続的に高い値はqueryパフォーマンスのためにより多くのnodeを追加することを示唆。 |
| Network Outbound Throughput | node1つあたりの1秒間の平均アウトバウンド速度(MB/s)。ネットワーク経由でデータを読み取るqueryは遅くなる — ネットワーク読み取りを削減するためにcachingを設定。 |
| Network Inbound Throughput | node1つあたりの1秒間の平均インバウンド速度(MB/s)。 |
| Cache Read Throughput | 1秒あたりのcache読み取りスループット(MB/s)。 |
| Cache Write Throughput | 1秒あたりのcache書き込みスループット(MB/s)。 |
サポート範囲:
| Metric | Warehouse | Cluster |
|---|---|---|
| CPU Utilization | ✓ | ✓ |
| Memory Usage | ✓ | ✓ |
| Memory Utilization | ✓ | ✓ |
| I/O Utilization | ✓ | ✓ |
| Network Outbound Throughput | ✓ | ✓ |
| Network Inbound Throughput | ✓ | ✓ |
| Cache Read Throughput | — | ✓ |
| Cache Write Throughput | — | ✓ |
Service metrics
Service metricsはqueryとworkloadの動作を追跡します:queryの実行速度、成功した数、書き込みパスの動作。
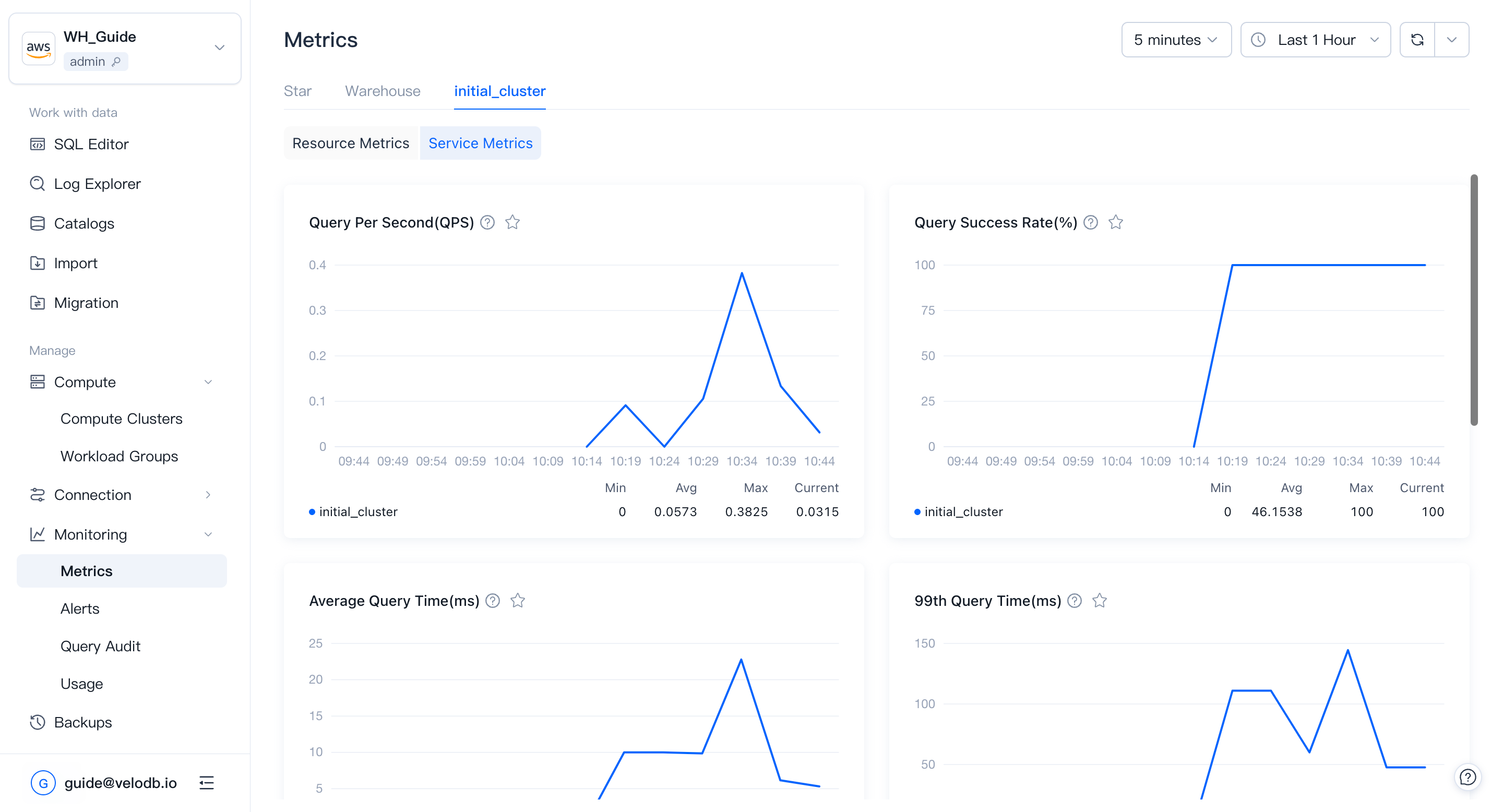
| Metric | What it shows |
|---|---|
| Query Per Second (QPS) | 1秒あたりのqueryリクエスト数。ピークQPSはclusterのサイジング時の有用な入力情報。 |
| Query Success Rate | 成功したqueryのパーセンテージ、毎分更新。異常な下降はclusterまたはnode障害を示す可能性。 |
| Dead Nodes | cluster内のdeadなnodeの数。 |
| Average Query Runtime | 平均query時間、毎分更新。異常な上昇は調査のシグナル。 |
| Query 99th Latency | 99パーセンタイルqueryの応答時間。遅いqueryの速度を反映。 |
| Cache Hit Rate | cacheから提供されるI/O操作のパーセンテージ。低い値はcacheポリシーの見直しまたはcache領域の増加を示唆。 |
| Remote Storage Read Throughput | 単位時間あたりにremote storageから読み取られるデータ量。 |
| Sessions | warehouseのsession数(clusterごとには分割されない)。 |
| Load Rows Per Second | レコードが正常に書き込まれる速度。 |
| Load Bytes Per Second | データ量が書き込まれる速度。 |
| Finished Load Tasks | 最近の期間で完了したloadタスクの数。急激な変化はビジネス異常を示す可能性。 |
| Compaction Score | データファイルのマージ圧力。高いスコアはより多くのマージ圧力を意味。 |
| Transaction Latency | 書き込みタスクのtransaction latency。低いほどデータがより早くクエリ可能になる。 |
サポート範囲:
| Metric | Warehouse | Cluster |
|---|---|---|
| Query Per Second | ✓ | ✓ |
| Query Success Rate | ✓ | ✓ |
| Dead Nodes | — | ✓ |
| Average Query Time | ✓ | ✓ |
| Query 99th Latency | ✓ | ✓ |
| Cache Hit Rate | — | ✓ |
| Remote Storage Read Throughput | — | ✓ |
| Sessions | ✓ | — |
| Load Rows Per Second | ✓ | ✓ |
| Load Bytes Per Second | ✓ | ✓ |
| Finished Load Tasks | ✓ | — |
| Compaction Score | — | ✓ |
| Transaction Latency | ✓ | — |
Alerts
VeloDB Cloudは追加料金なしでmonitoringとalertingを提供します(SMS alert通知を除く)。clusterのmonitoringメトリクスが変化した際に通知を受けるようにalertルールを設定できます。
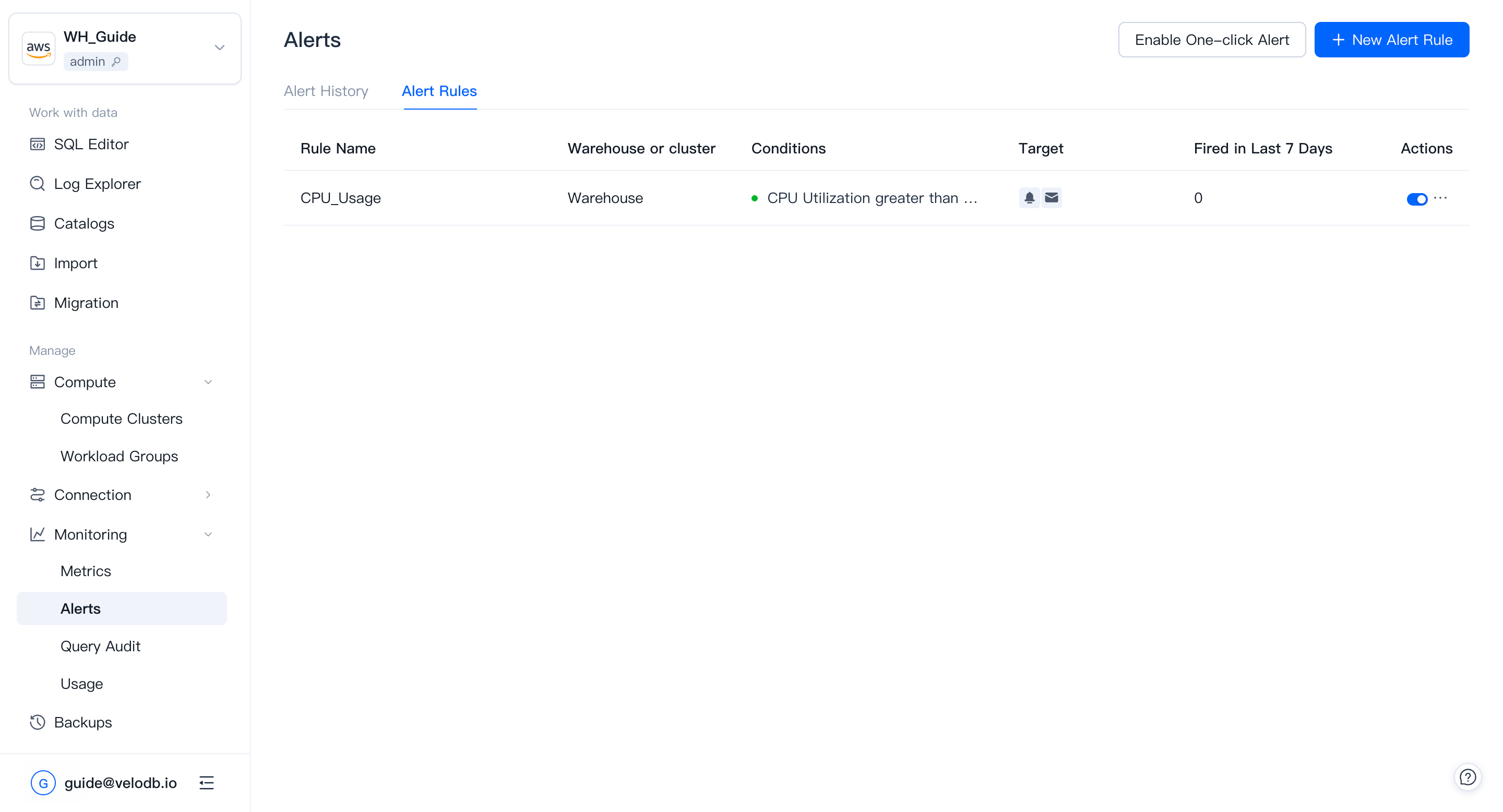
alertルールの表示
Alertsリストは既存のalertルールとその現在のアラート状態を表示します:赤いドットはルールが発火していることを意味し、緑のドットはルールがトリガーされていないことを意味します。
ワンクリックalerts
Enable One-Click Alertをクリックして、基本的なルールセットを自動的に設定します。このルールセットは現在のwarehouseとcluster、および後で作成するものの両方に適用されます。
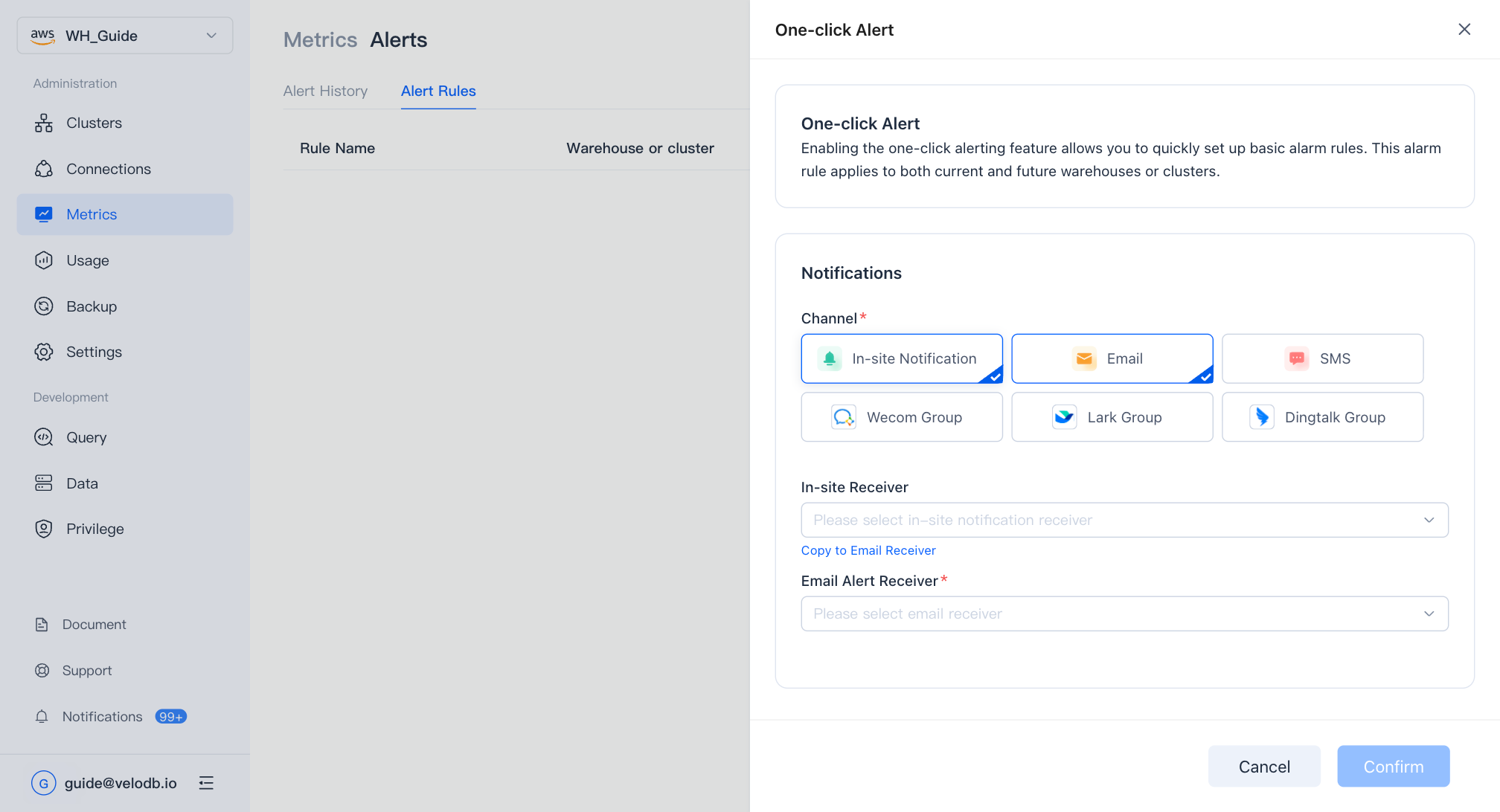
alertルールの作成または編集
New Alert Ruleをクリックするか、既存のルールをコピーします。
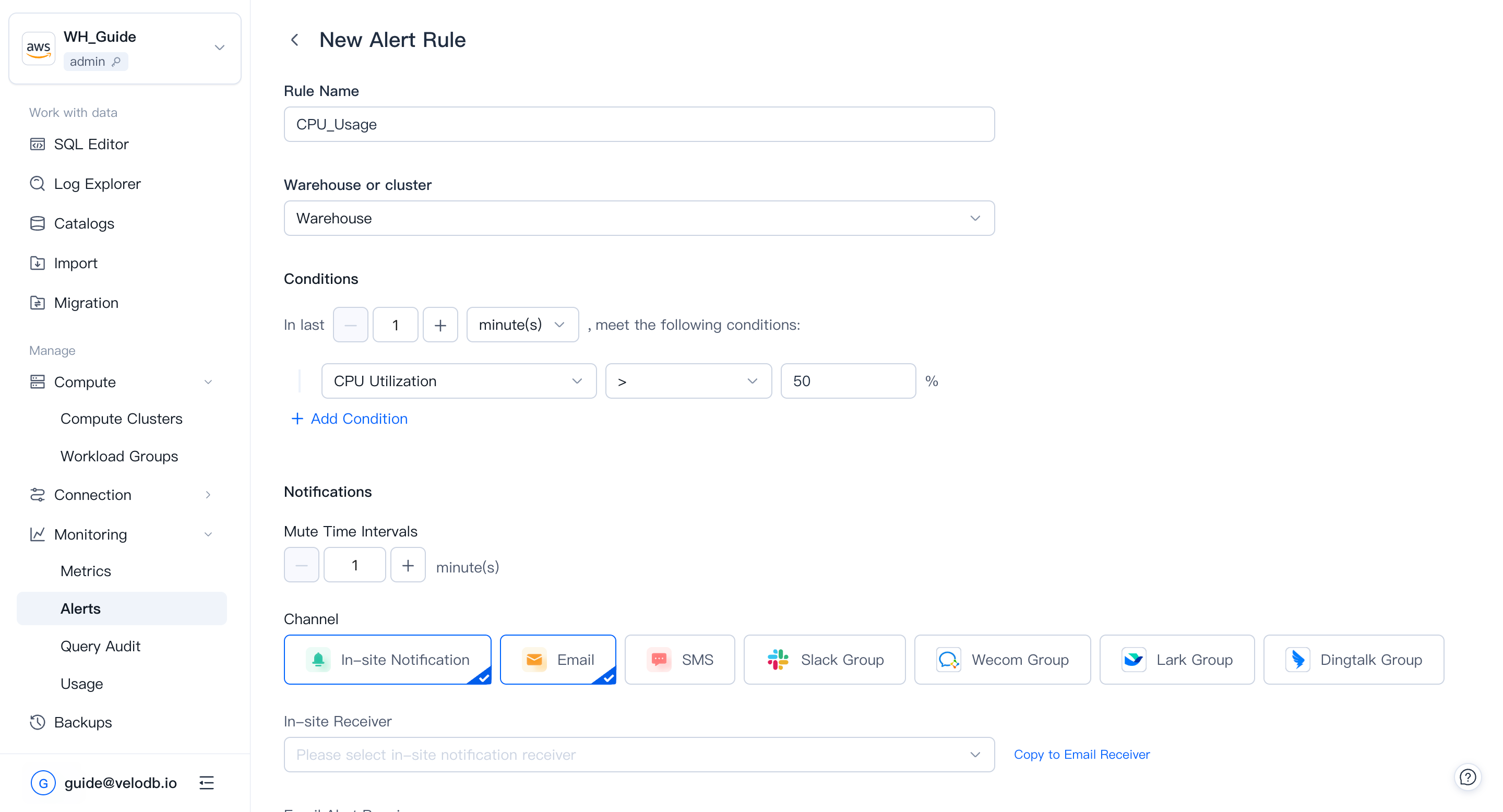
alertルールには4つの部分があります:
| Part | Description |
|---|---|
| Rule Name | warehouse内で一意の名前。 |
| Cluster | ルールが適用されるcluster。clusterが削除された場合、そのルールは削除されませんが無効化されます。 |
| Conditions | and / orで結合された1つ以上のmetric閾値。 |
| In Last | ルールが発火する前に条件が維持されなければならない時間。適時性とノイズのバランス。 |
通知チャンネル
すべてのalertルールは1つ以上のチャンネルにプッシュできます;各チャンネルは独立してalertメッセージをプッシュします。
In-site notificationとEmail — 通知するユーザーを選択。
SMS — ユーザーを選択するか、電話番号を直接入力。
WeCom — グループロボットを追加し、そのwebhook URLを貼り付け。
- PC版WeComで、alertを受信すべきグループを開く。
- グループを右クリックしてAdd Group Bot、次にCreate a Botをクリック。
- botに名前を付けてAddをクリック。
- webhook URLをalertチャンネル設定にコピー。
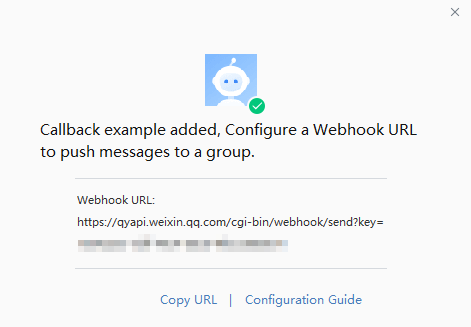
注意 メッセージソースを制限するには、webhook IP allowlistを設定してください。VeloDB Cloud serverのIPは
3.222.235.198です。
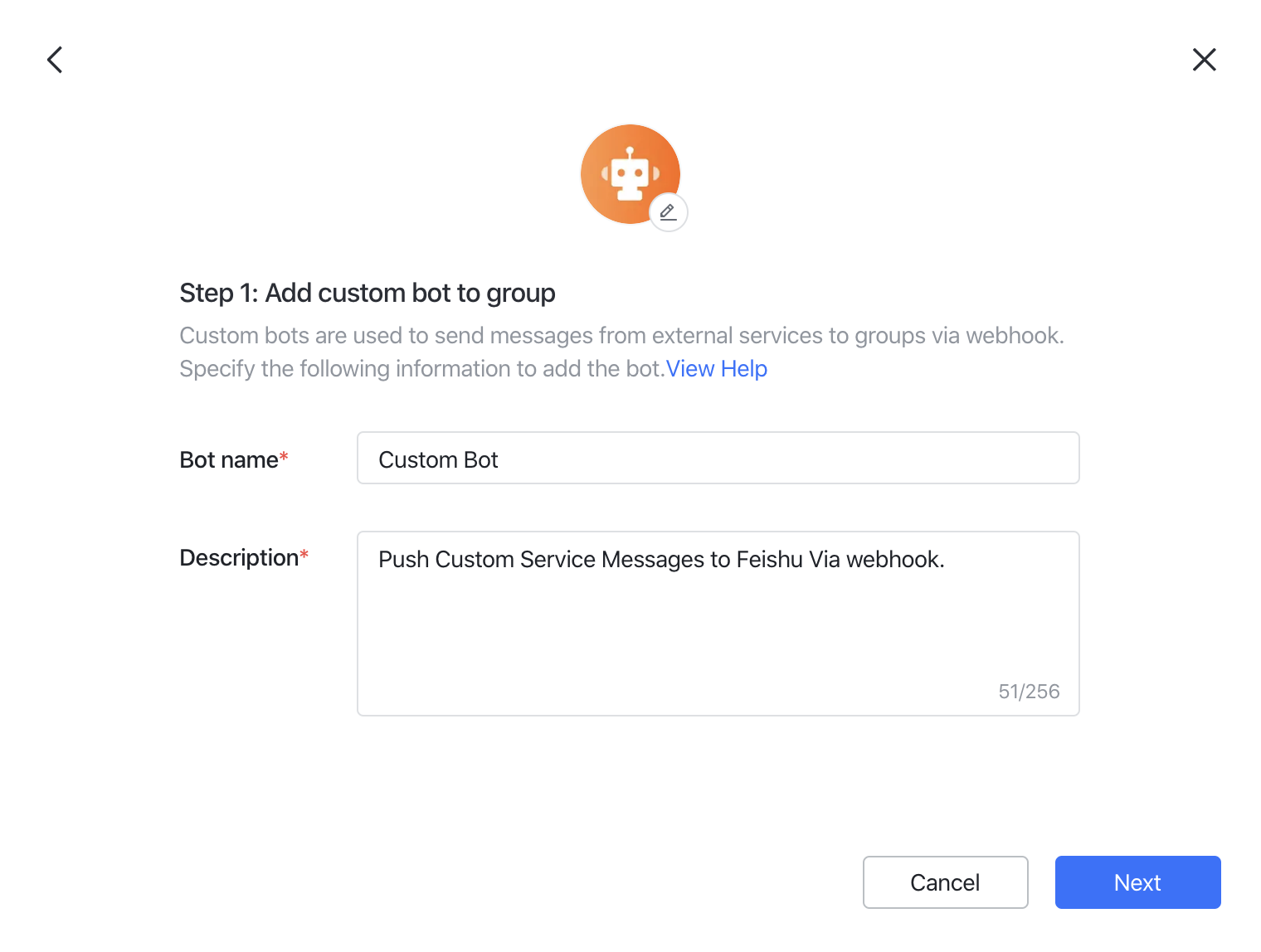
Lark — カスタムbotを追加し、そのwebhook URLを貼り付け。
- 対象グループで、Settings → BOTs → Add Bot → Custom Botをクリック。
- botに名前と説明を付けて、Nextをクリック。
- webhook URLをalertチャンネル設定にコピー。
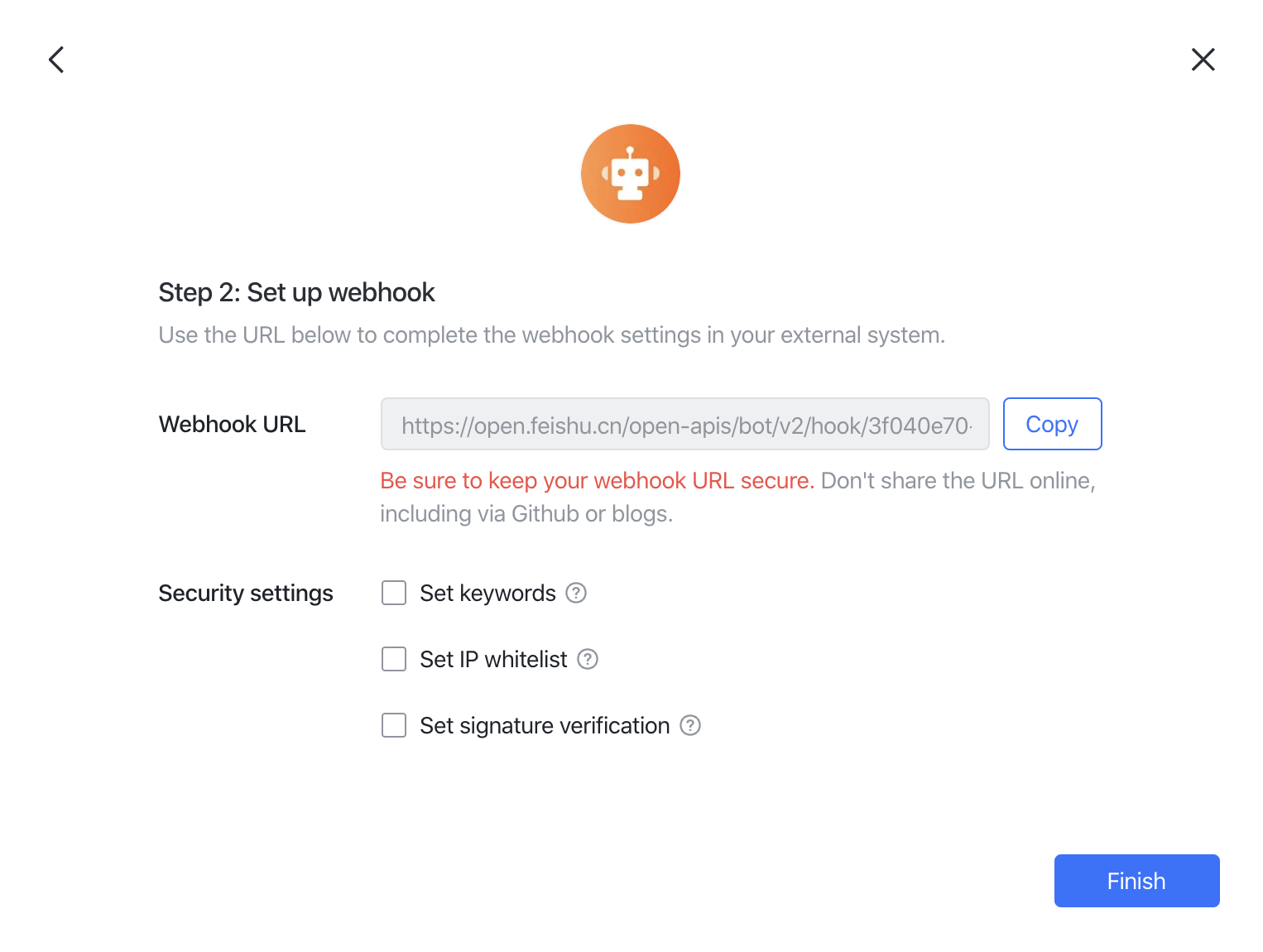
注意 メッセージソースを制限するには、webhook IP allowlistを設定してください。VeloDB Cloud serverのIPは
3.222.235.198です。
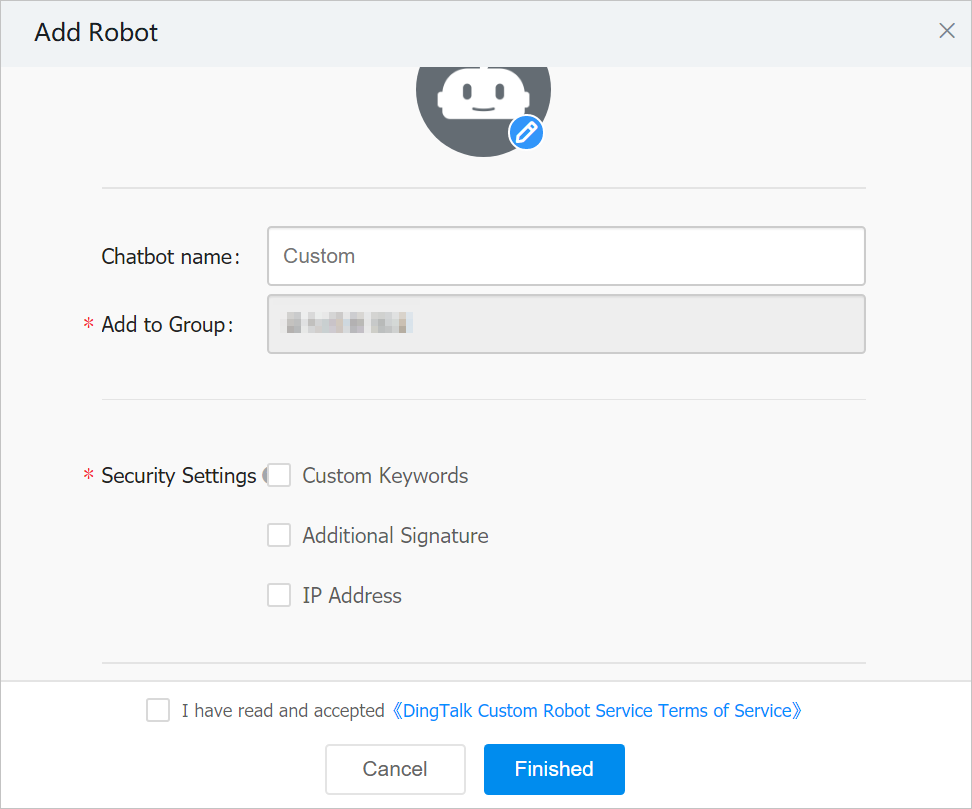
DingTalk — カスタムロボットを追加し、そのwebhook URLを貼り付け。完全な手順についてはDingTalkのガイドを参照してください。要約すると:
- 対象のDingTalkグループで、Group Settings → Group Assistant → Add Robot → Customを開く。
- プロフィール画像、名前、セキュリティ設定を設定(Custom Keywordsを使用して
alertを入力)。 - 規約に同意してFinishedをクリック。
- webhook URLをalertチャンネル設定にコピー。

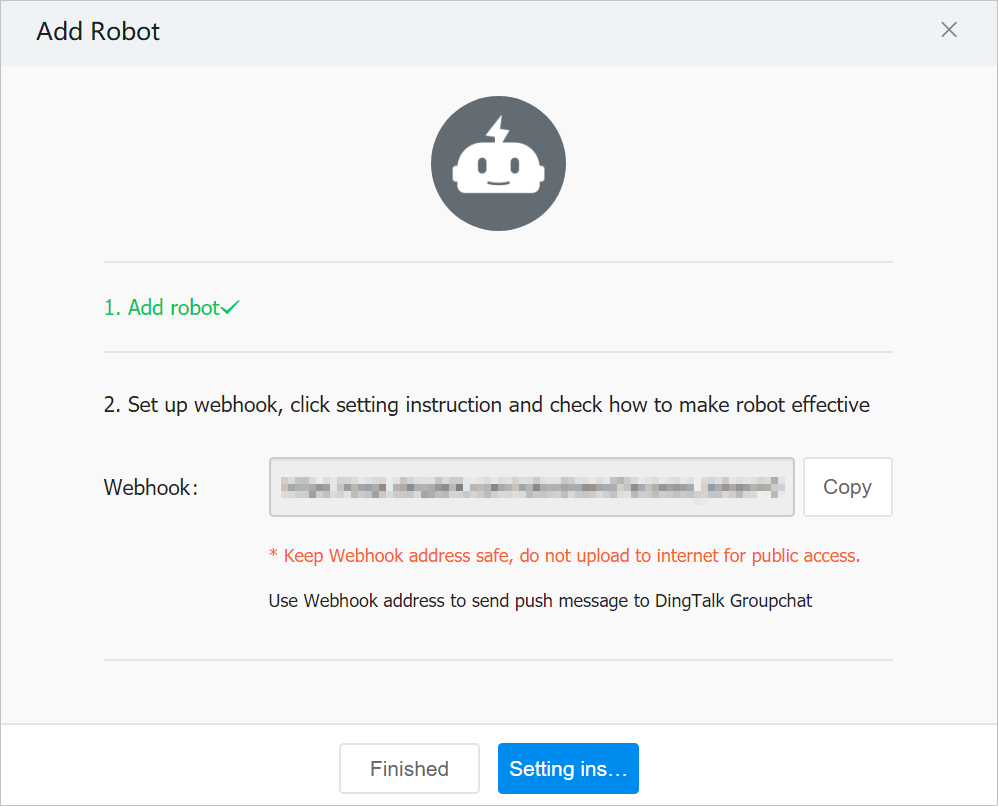
注意 メッセージソースを制限するには、webhook IP allowlistを設定してください。VeloDB Cloud serverのIPは
3.222.235.198です。
Alert履歴
Alertsページでalert発火履歴を表示し、時間、ルール、またはclusterでフィルタリングできます。
Query Audit
Query Auditは、warehouseで実行されたqueryの監査と分析のためのワンストップツールです。パフォーマンスの悪いqueryを見つけ、トレンドを調査し、個々の問題を診断するために使用します。
リストビューで過去のqueryをフィルタリングし、List Selectionを使用してフィルターにより多くの次元を追加します。
Query IDをクリックしてquery詳細ページを開きます。profileキャプチャが有効化されていた場合、profileがそこで利用できます。
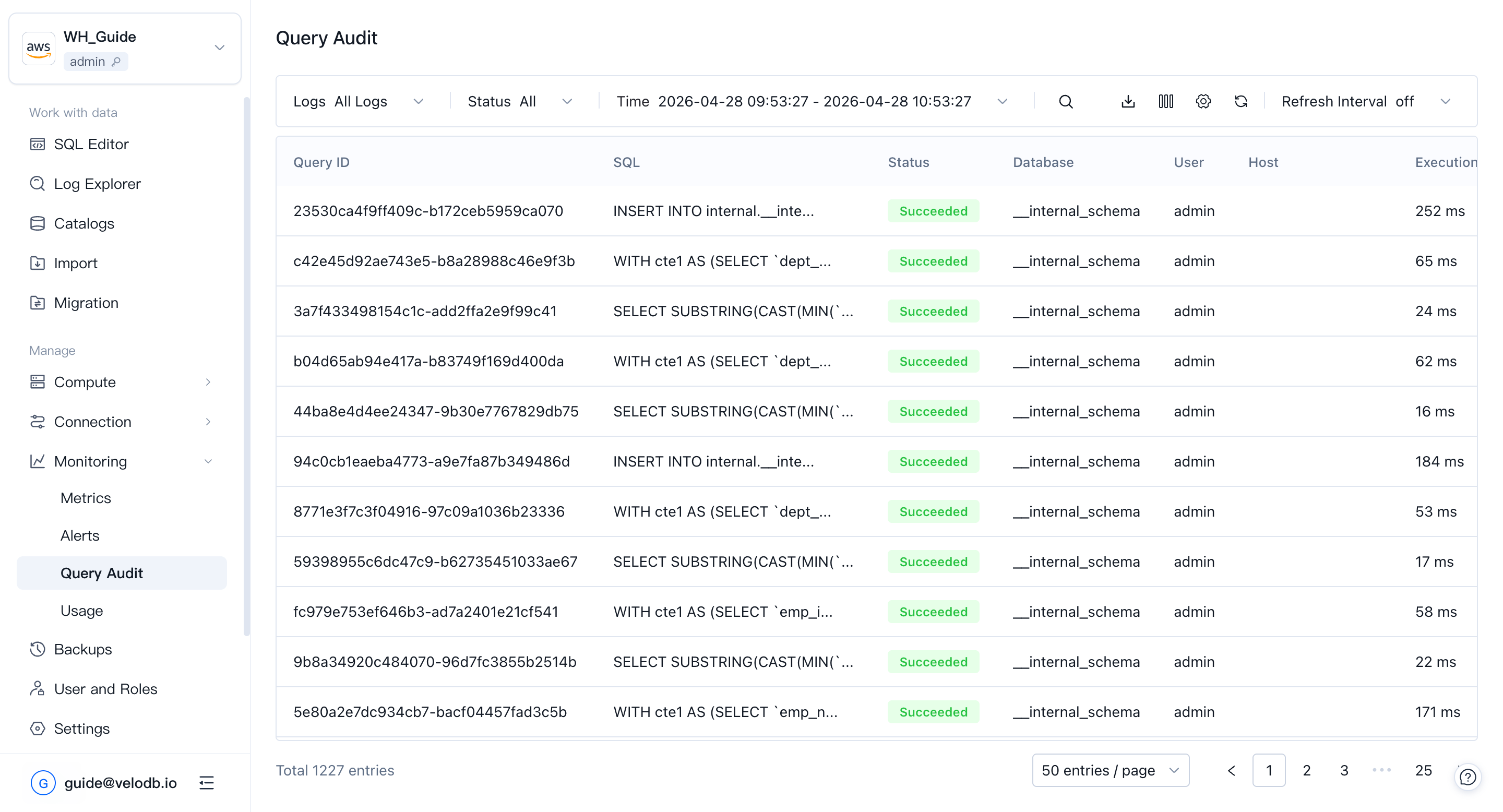
注意 非queryステートメントと失敗したステートメントにはQuery IDがありません。
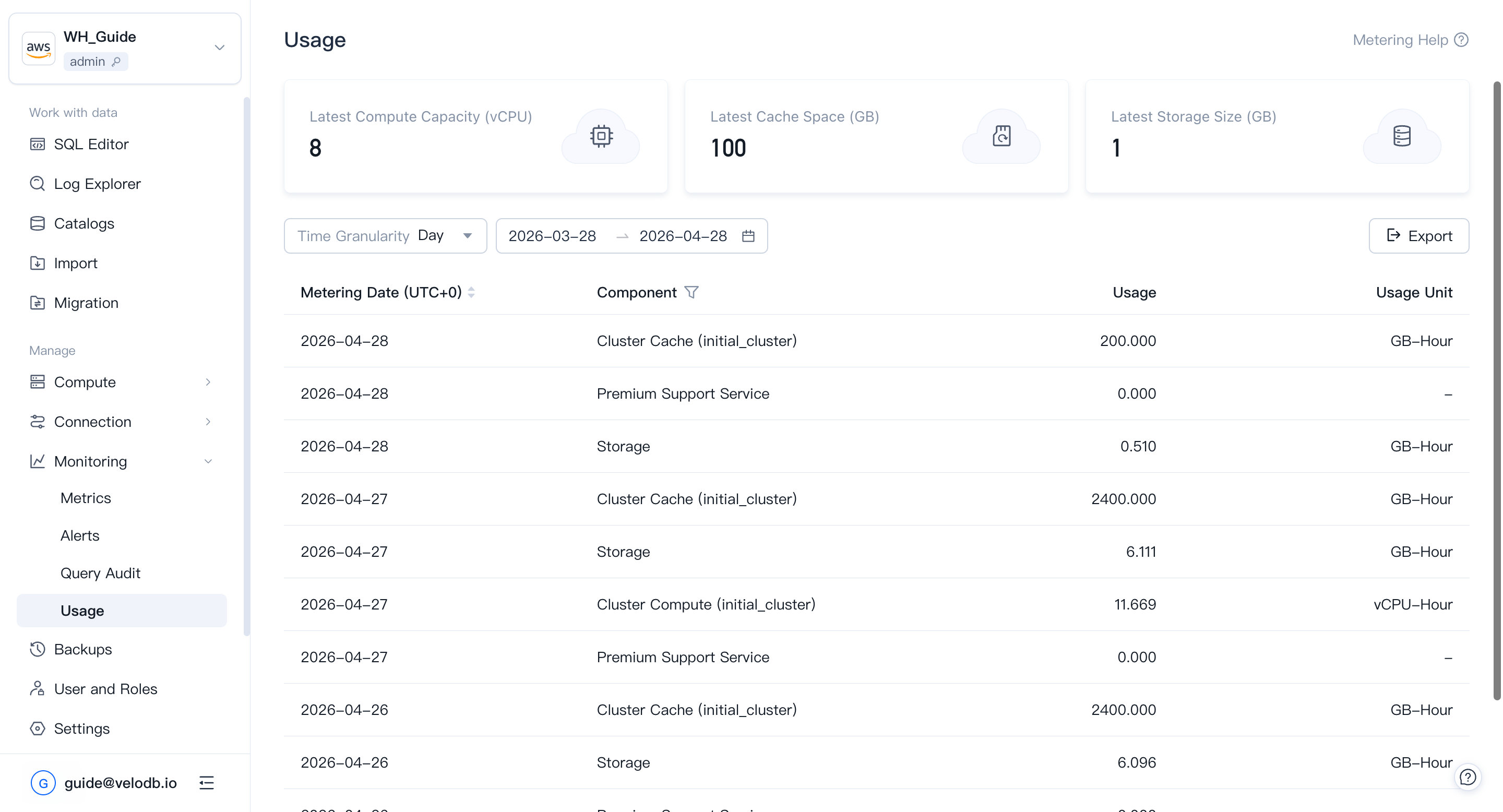
Usage
Usageは現在のwarehouse内でcompute、cache、storageがどのように消費されているかを表示し、コストがどこに向かっているかを確認できます。
左ナビゲーションからMonitoring → Usageを開きます。
組織レベルの請求と支払いチャンネルについては、Billingを参照してください。