Studio
VeloDB Cloud Studio(「Studio」)は、データ開発シナリオ向けのデータ開発プラットフォームです。VeloDBが提供するクラウド上のデータ開発プラットフォームで、ユーザーがデータを管理・探索することを支援し、Navicatの代替として使用できます。
メイン機能
- ウェアハウスログイン : Studio内で異なるデータベースユーザーを使用してウェアハウスにログインします。
- データクエリ :
- SQL Editor : 使いやすいSQLクエリエディタで、クエリ実行、自動SQL保存、クエリプロファイル、履歴クエリレコードなどをサポートします。
- ログ Analytics : ログシナリオ向けのユーザーフレンドリーな分析ツールで、SQLフィルタリング、検索、その他の機能をサポートします。
- Session Management : 実行中のSQLクエリを管理し、SQLクエリの表示と終了を可能にします。
- Query Audit : スロークエリをフィルタリングし、その実行を表示できるワンストップ履歴クエリ監査ツールです。
- Workload Management : Workload Groupの迅速な作成、編集、表示をサポートします。
- データ管理 : データベース内のデータを表示・管理し、現在は表示をサポートしています。
- 権限管理 : データベース内のユーザーとロールを管理し、権限を付与・取り消しします。
- データ統合 : クラウド上のオブジェクトストレージ内のデータへの簡単な接続、データレイクへの接続、サンプルデータのインポートを行います。
- Import: インポートタスクの表示とインポートタスクの操作をサポートします。
登録とログイン
Studioサービスの使用
VeloDB Cloud Manager(「Manager」)では、各ウェアハウスに対応するStudioサービスがあります。ManagerのConnection モジュールで、プライベートネットワークまたはパブリックネットワーク経由でStudioへの入口を見つけることができます。
また、直接アクセスするためにStudioのエントリアドレスを保存することもできます。
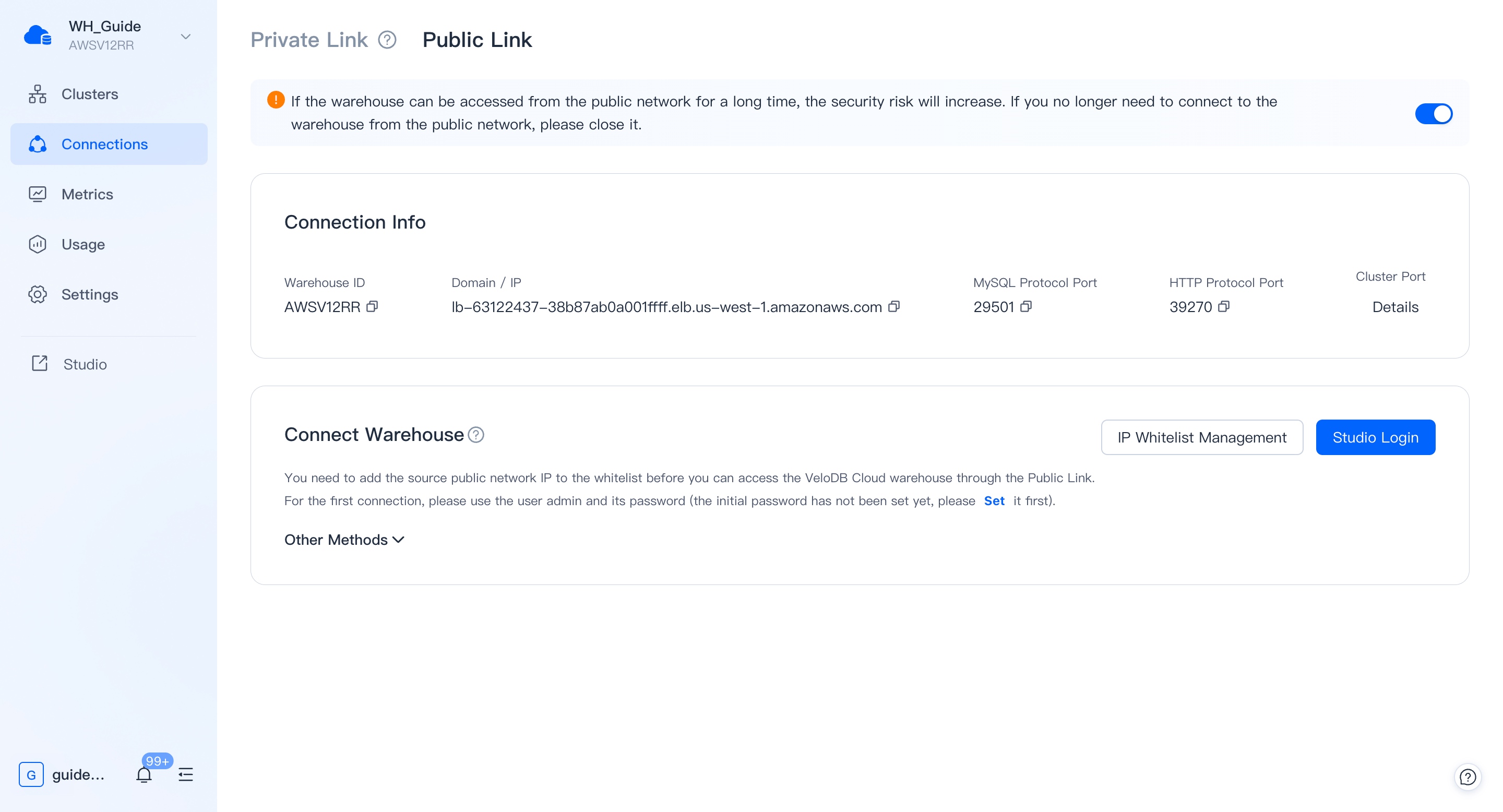
Studioへのログイン
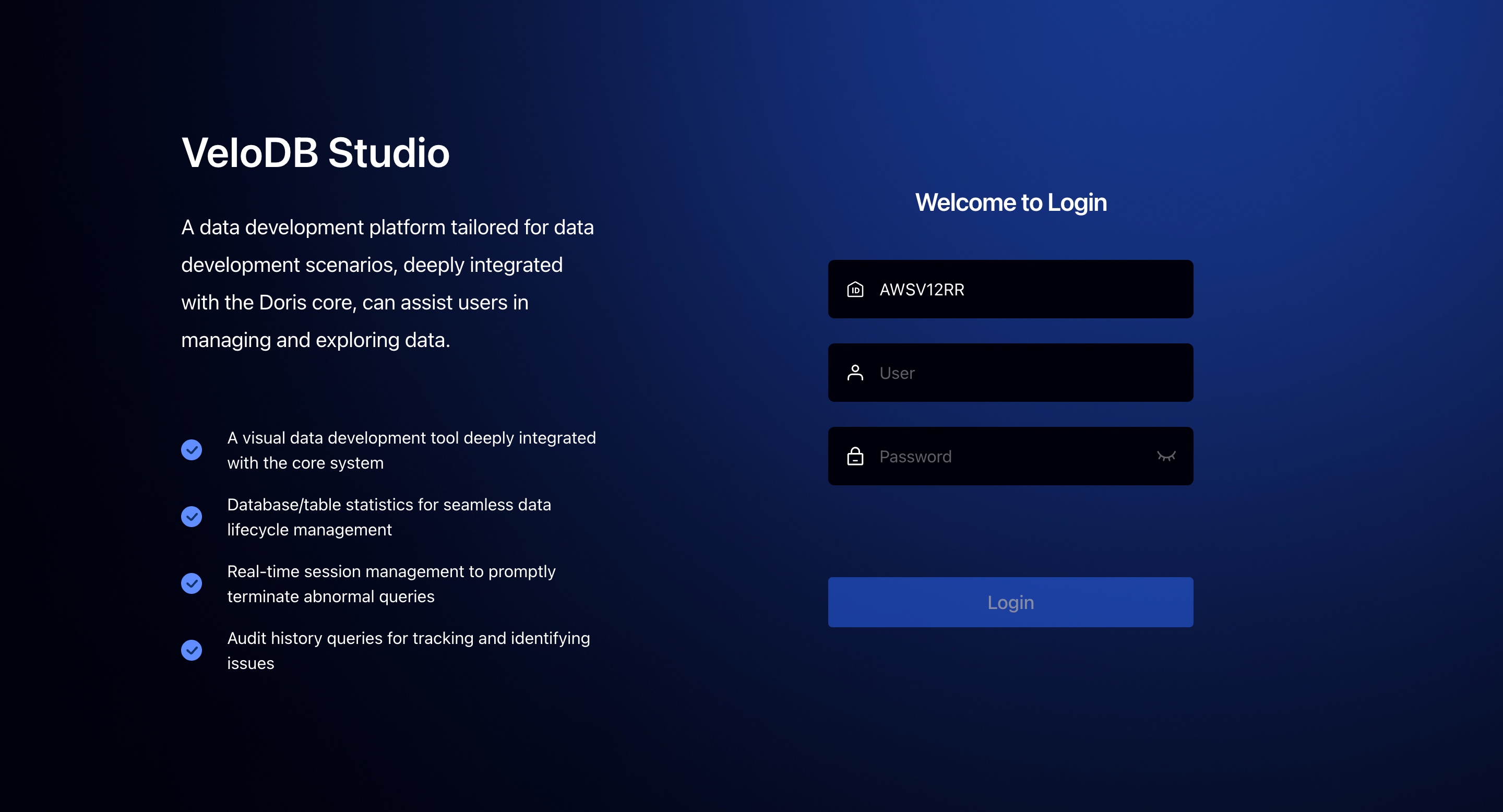
ログインページでウェアハウスのUsernameとPasswordを入力する必要があります。Managerからリンクをクリックしてログインした場合、ウェアハウス名は事前入力されているはずです。
ログインアカウントとパスワードは記録されませんが、ブラウザに付属の記録機能を使用できます。
データ
「データ」モジュールはStudioのデータベース管理の基本機能で、主に2つの機能があります:
-
データとその組織形態の確認、例えばデータベースTable構造、データサイズ、Table作成文、Tableフィールド情報、データプレビューなど。
-
データベースオブジェクトの追加、削除、変更、新規作成、削除、データベースオブジェクトのリネームを含む。
データモジュールはデータベース内のデータの組織形態に従って表示され、カタログ -Database -Table /View に分かれています。
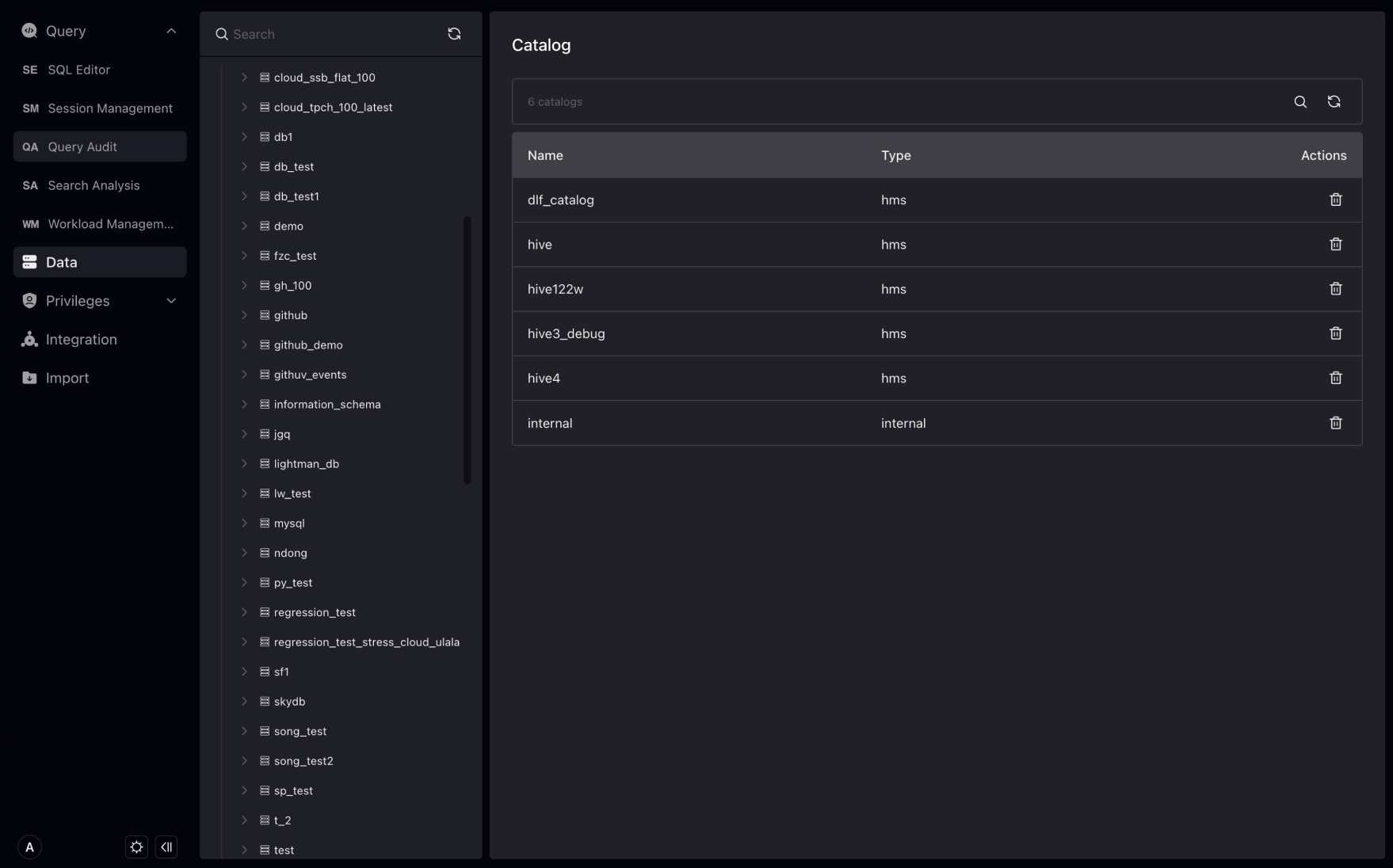
カタログ
カタログはデータベースのコレクションです。
カタログは内部カタログと外部カタログに分かれます。内部カタログはVeloDB独自のデータベースを含み、外部ディレクトリはVeloDBがデータレイク機能をサポートするため、Hive、Iceberg、Hudiなどに接続できます。VeloDB Studioはカタログオブジェクトの直接削除をサポートします。
Database
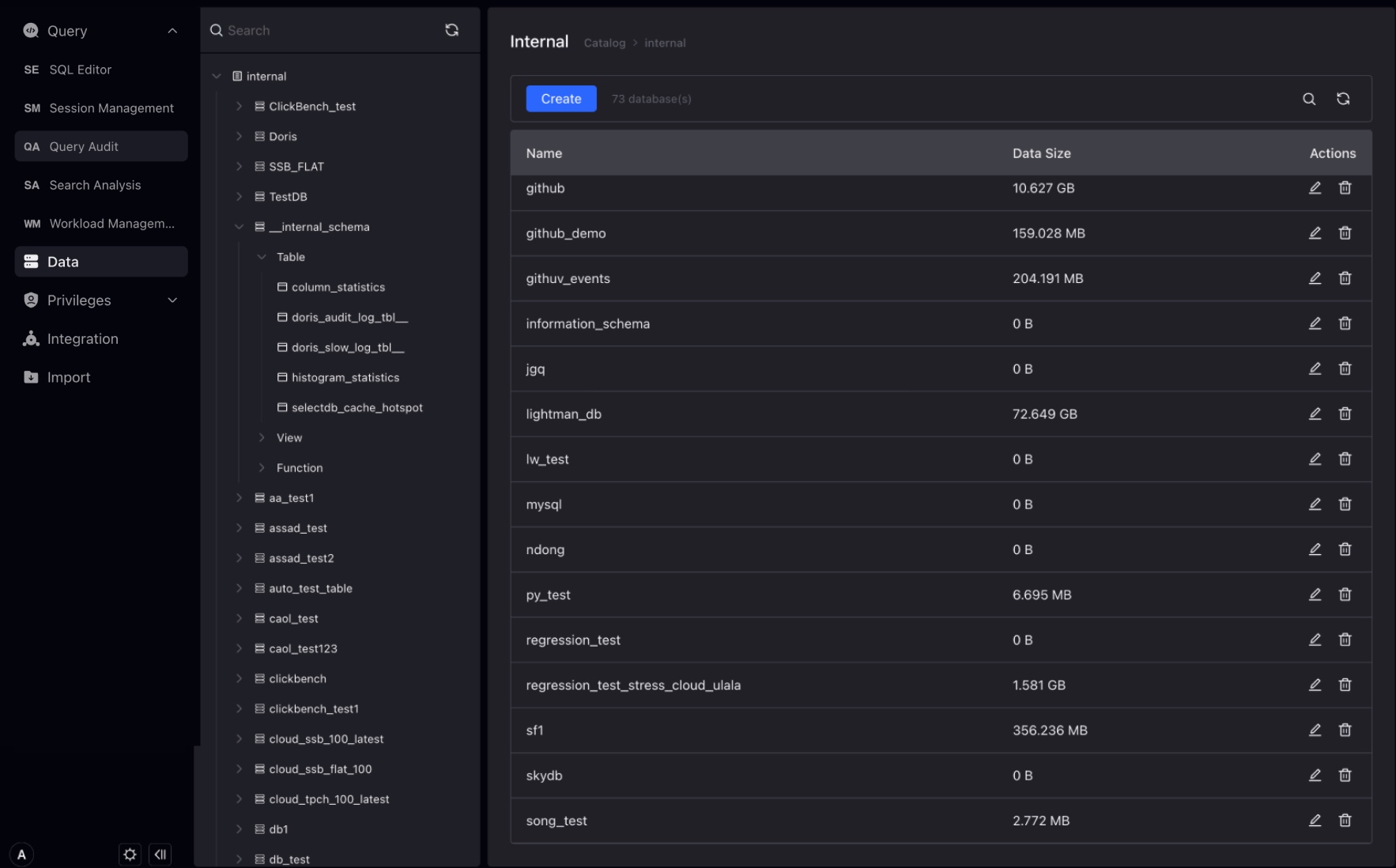
データベースは、Table、ビュー、マテリアライズドビュー、関数のコレクションです。データベースはディレクトリに属します。ディレクトリが選択されると、ディレクトリ下のデータベースとデータベースのサイズを表示できます。同時に、ページ下でデータベースの作成、削除、リネームが可能です。
Table
TableはVeloDBデータウェアハウスの基本単位で、Tableはデータベースに属します。
データベースが選択されると、データベース下のTable、Tableのサイズ、作成・変更時間を確認できます。
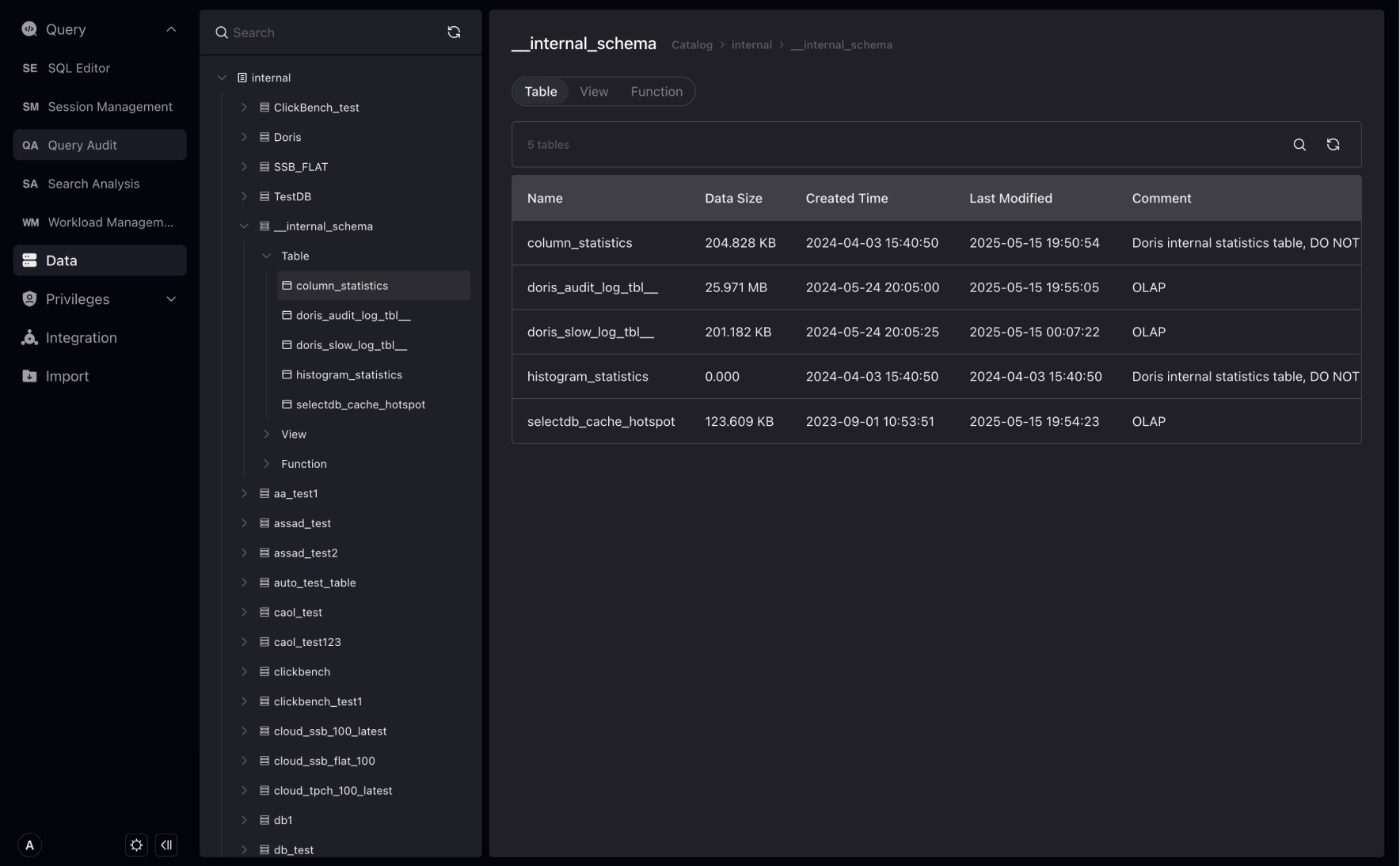
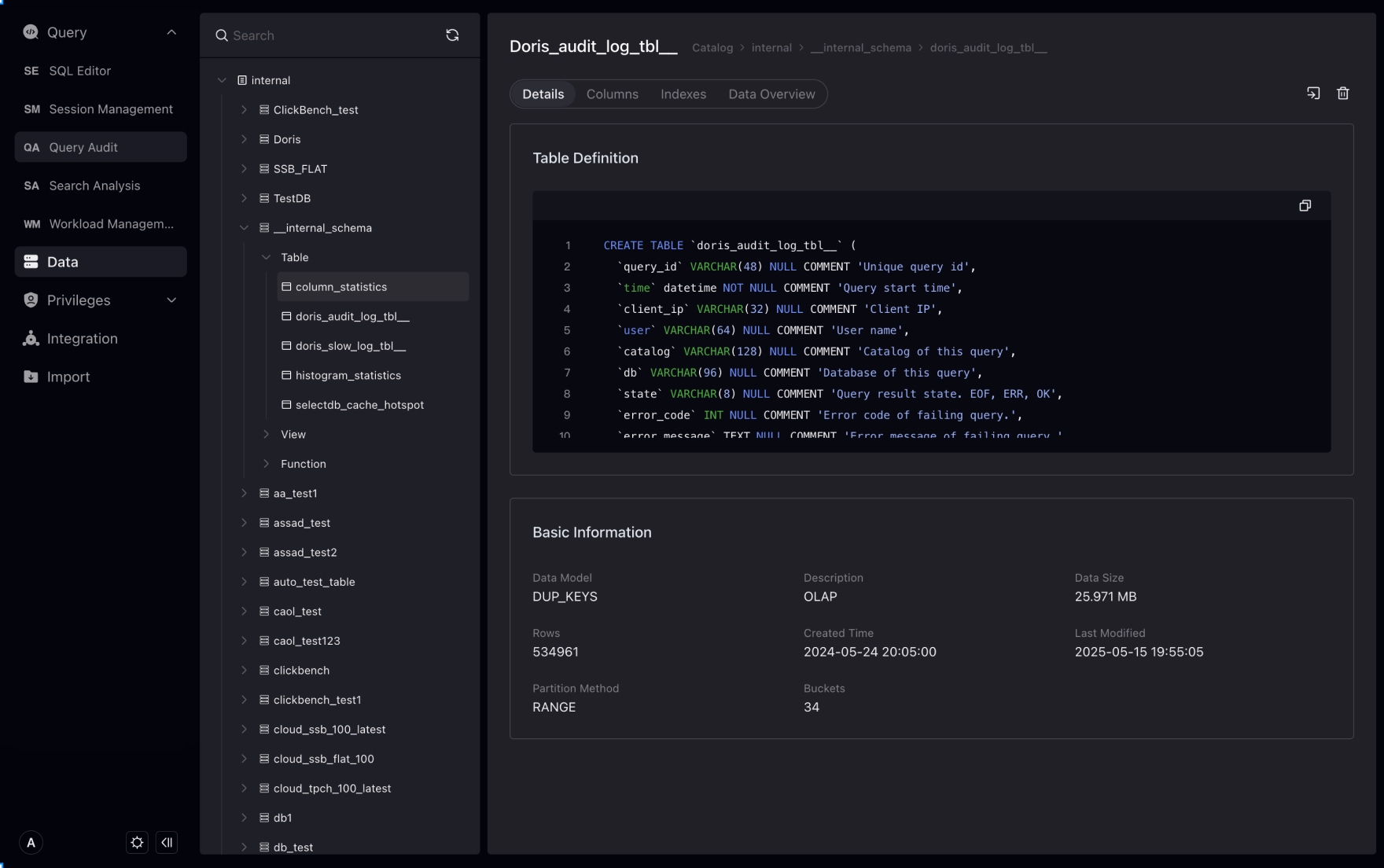
Tableをクリックすると、Tableの詳細管理ページに入り、TableのDDL定義、フィールド、インデックスなどの情報を表示できます。
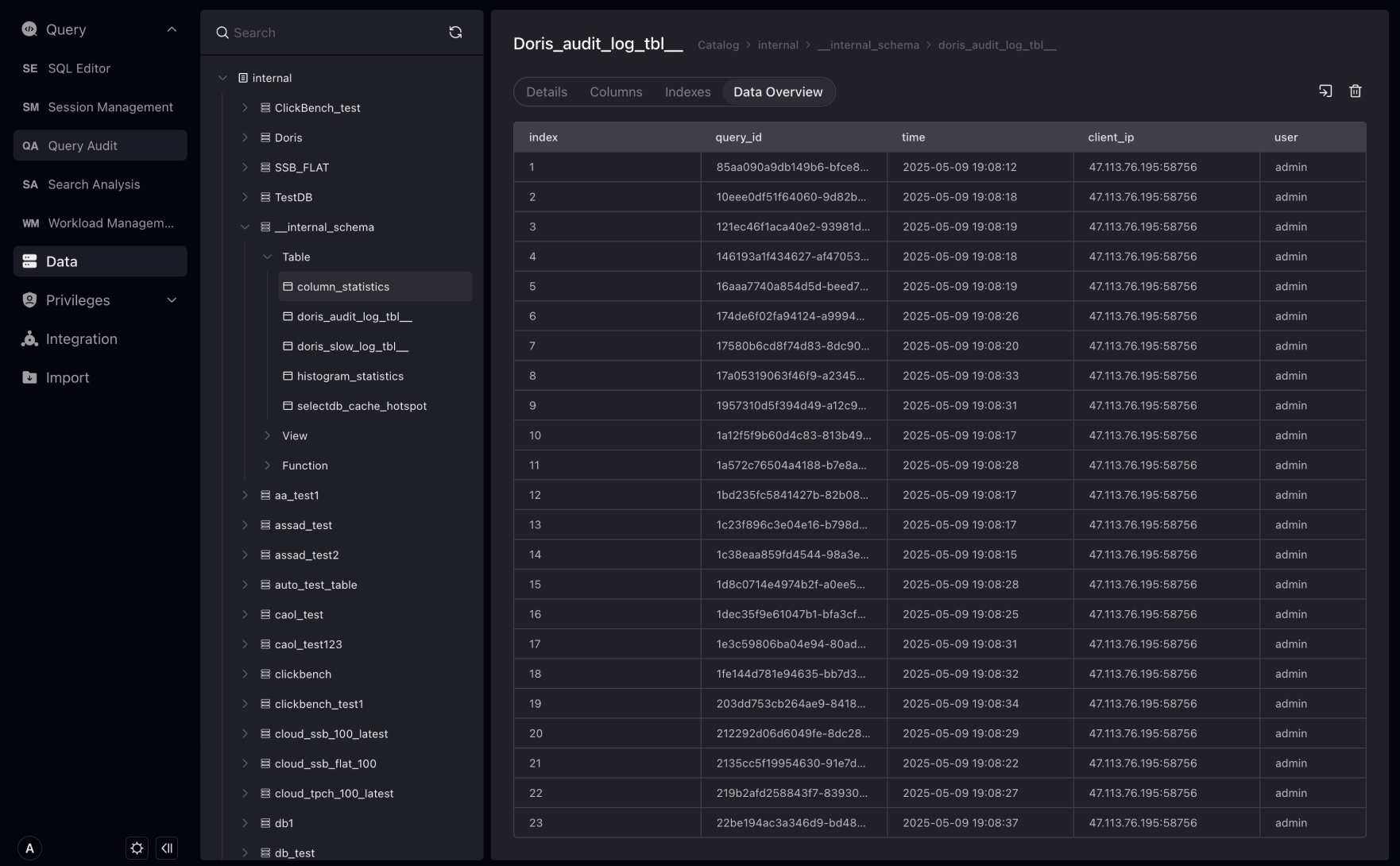
データプレビューページは、Tableのデータを素早くプレビューするために使用され、デフォルトでインターフェースからTableの最初の100件のデータをプレビューします。「合計 x データ」はメタデータサービスから取得されるため、遅延が生じる可能性があります。
View
ビューはSQL文の結果セットに基づく可視的なTableです。ビューページはTableページとほぼ同様です。ビューが持たない属性(インデックス、詳細など)は表示されません。ビューもデータプレビュー機能(最初の100件のデータ)をサポートします。
Materialized View
Materialized Viewは、クエリ結果を事前計算して保存するTableで、クエリパフォーマンスを向上させ、リアルタイム計算の負荷を軽減するために使用できます。Studioデータベースページでは、データベース下のマテリアライズドビュー情報を一覧表示できます。
ファンクション
Studioデータベースページでは、データベース下の関数情報を一覧表示でき、関数タイプ、戻り値タイプ、作成文などの情報の表示をサポートします。
SQL Editor
クエリ結果は編集ボックスの下に返され、クエリによって返されるエラーまたは成功ステータスと情報も、クエリ結果に表示されます。
同時に、Run (LIMIT 1000) の右側のドロップダウンボタンをクリックしてRun and Downloadに切り替えて、クエリ結果をダウンロードできます。
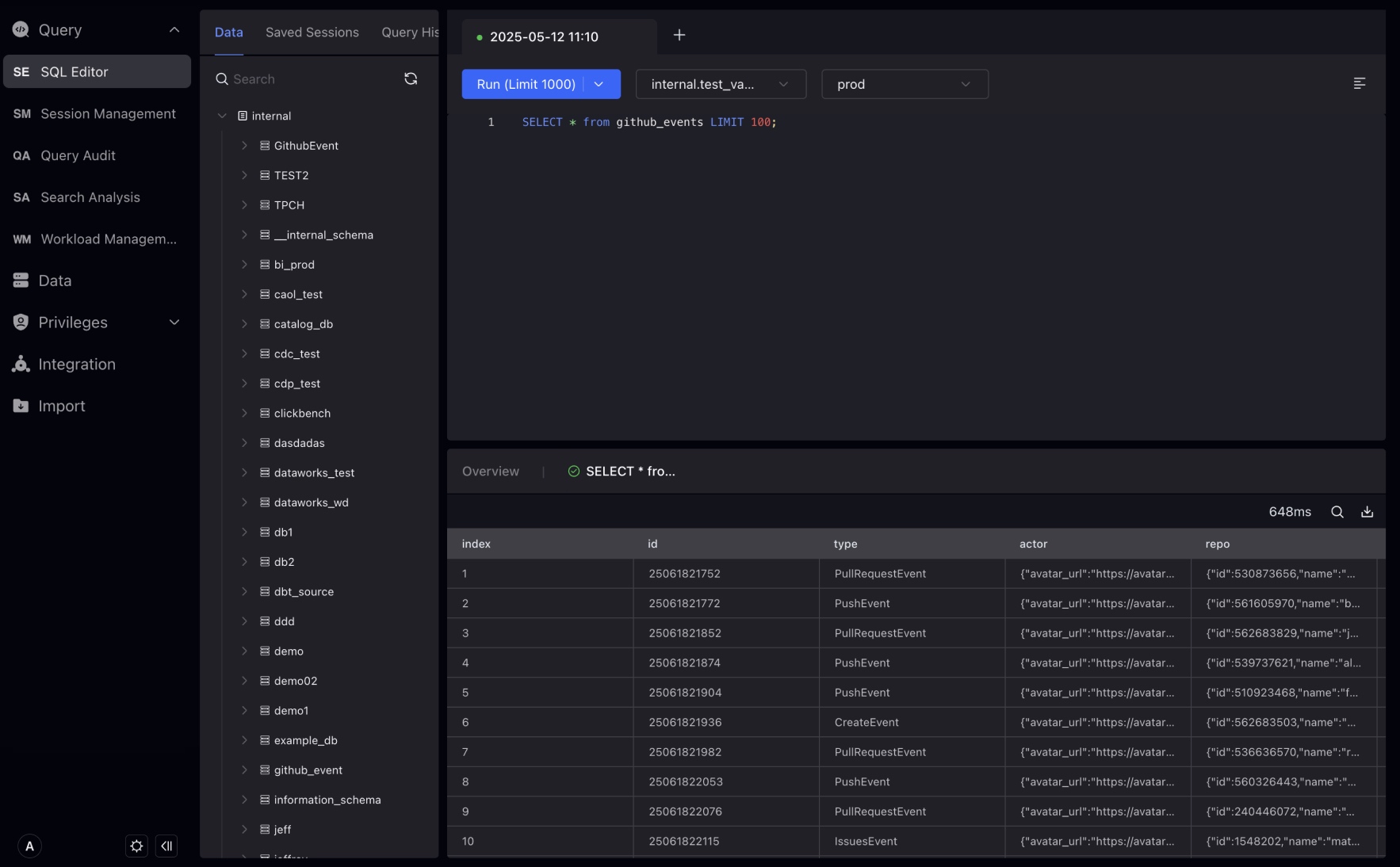
セッションレコードは、SQL Editorで開いたTabの履歴です。レコード内のSQL文をクリックして、SQL Editorにコピーして実行できます。
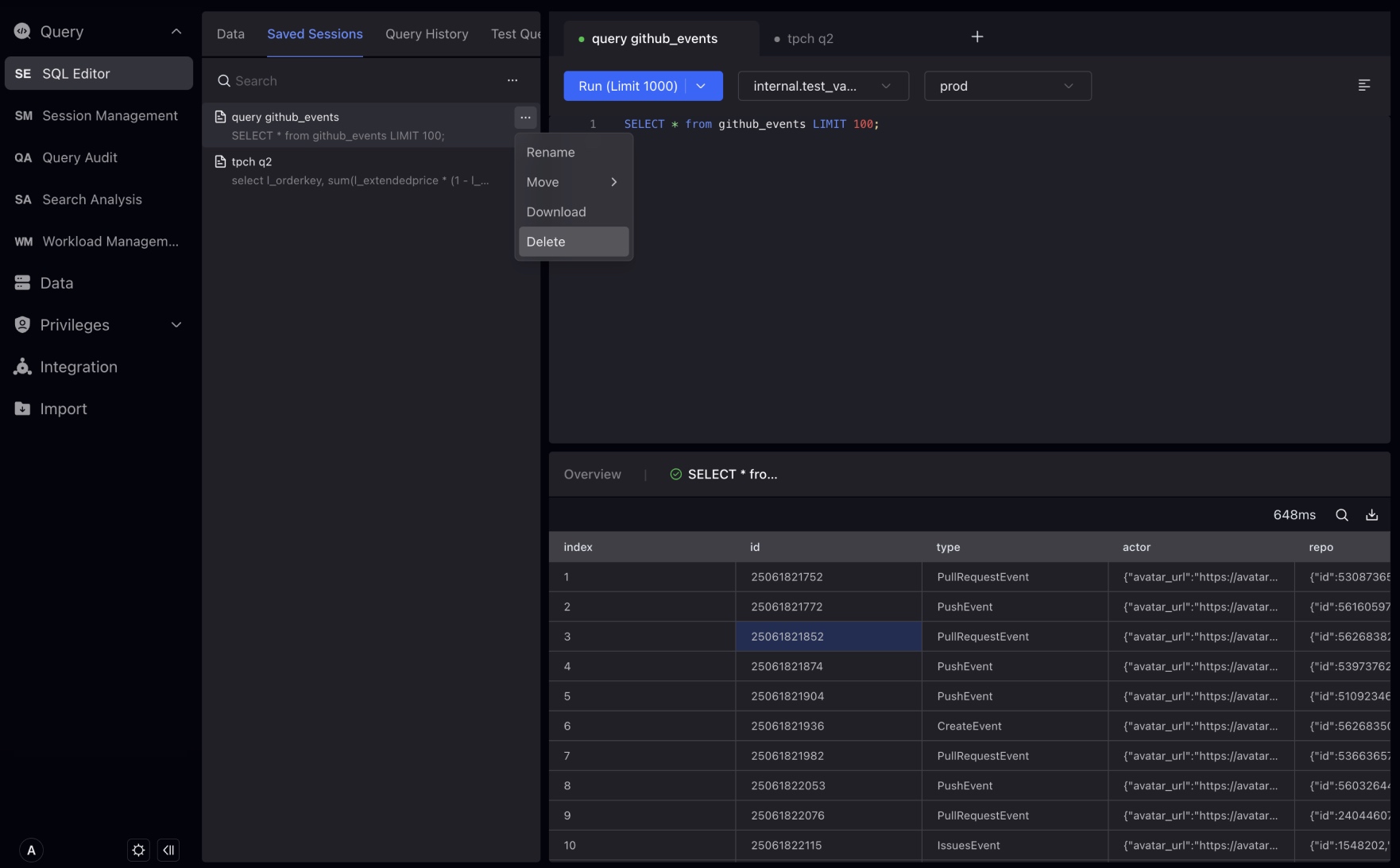
クエリ履歴は、SQLエディタで実行したSQL文の履歴です。レコード内のSQL文をクリックして、文のProfile情報を表示できます。
注記 クエリ以外の文および失敗した文にはQuery IDがありません。
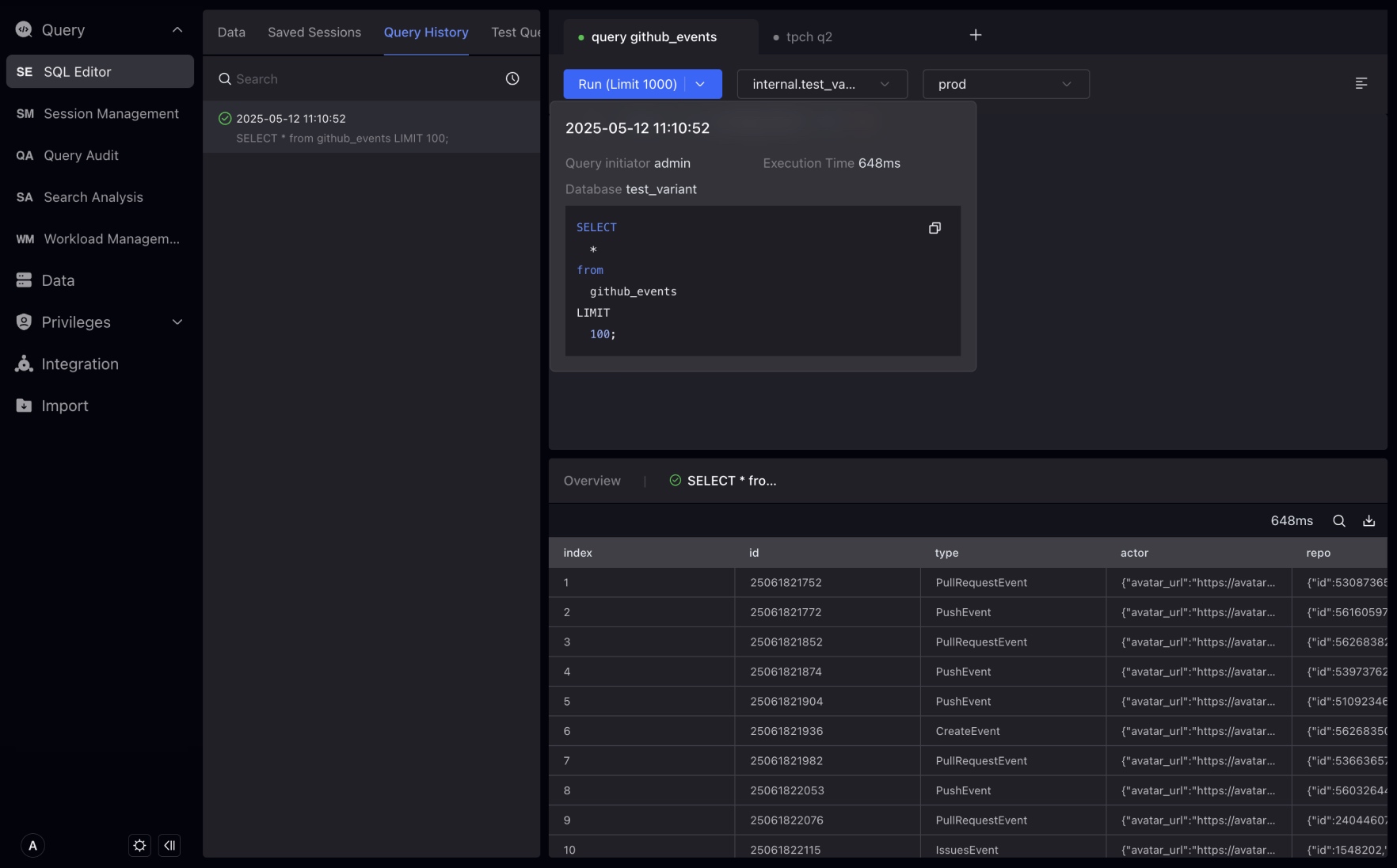
デフォルトでは、Studioで開始されるクエリに対してクエリプランが有効になっており、これは単一クエリのパフォーマンスに影響しません。「Query Statement」をクリックして実行プランページに入ります。
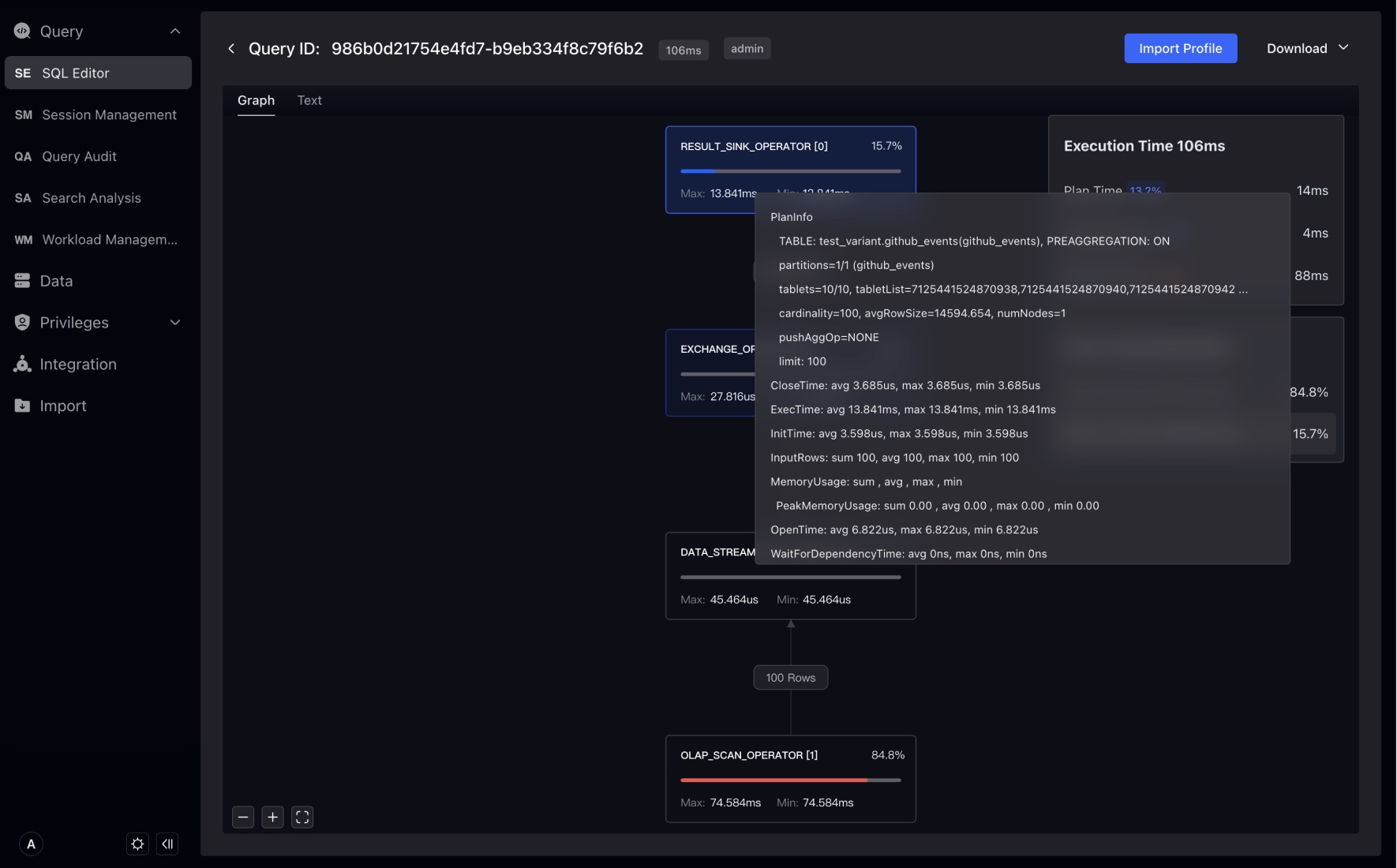
ダウンロードボタンは、純粋なTEXT形式のProfile情報と視覚的なProfile画像を含むProfile情報をダウンロードできます。
Import ProfileボタンはTEXT形式のProfile情報をインポートでき、インポート後に視覚的にProfileを表示できます。これにより、他のクライアントから開始されたクエリを視覚的に分析できます。
Studioには、いくつかのテストデータセット用のサンプルクエリ文を内蔵しており、簡単なパフォーマンステストの実行に役立ちます。
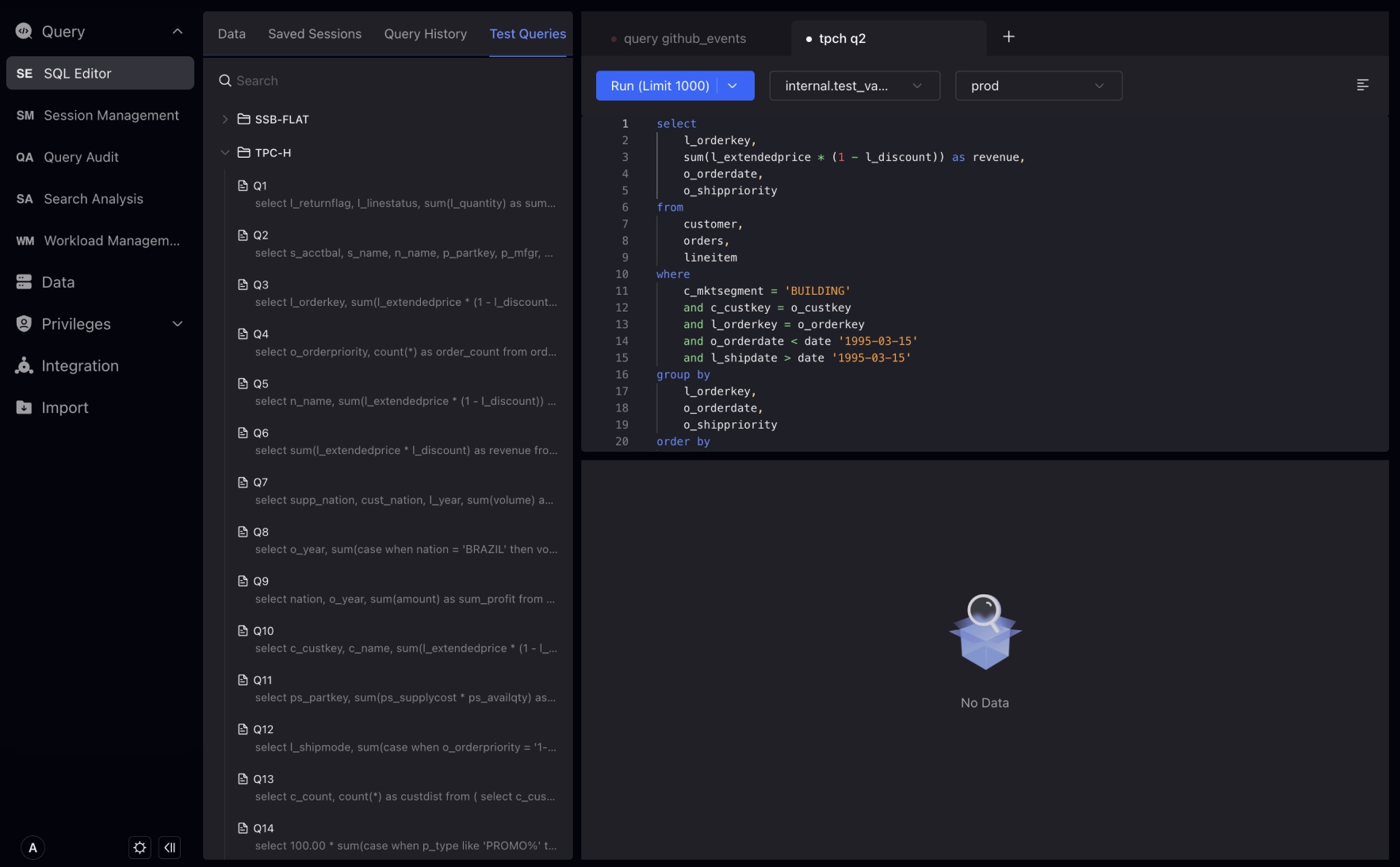
結果パネルでは、クエリ結果、実行時間、行数などを含むSQL文の実行結果を確認できます。検索ボックスで結果を検索したり、Tableヘッダーをクリックして結果をソートしたりすることもできます。
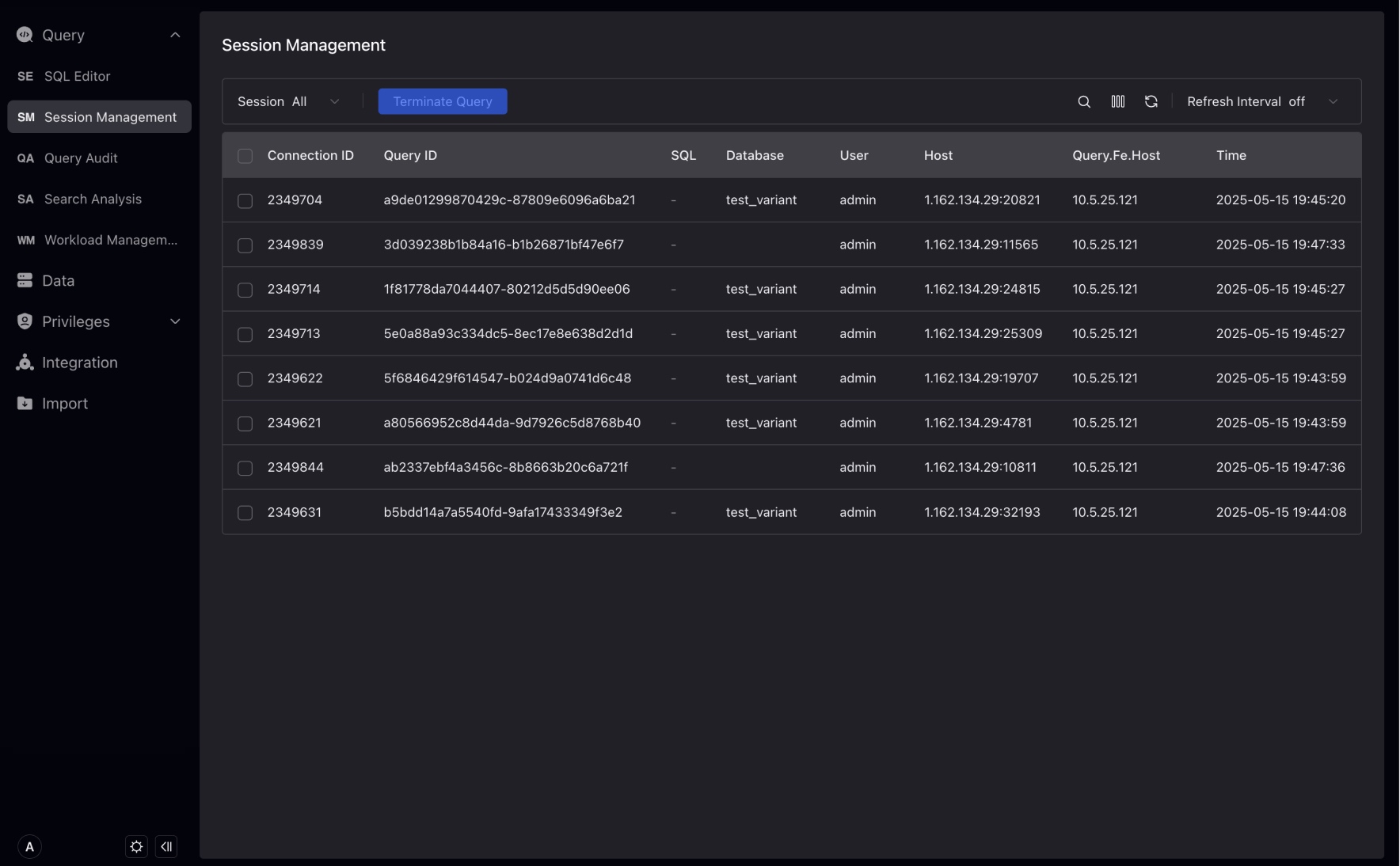
Session Management
セッション管理により、管理者ユーザーはリソースの使用を管理し、重要なクエリを優先してシステムパフォーマンスを向上させることができ、実行時間、クエリを開始したユーザー、使用されているリソースなど、各セッションに関する詳細情報を提供します。
現在実行中のすべてのSQLクエリを表示し、問題を引き起こすまたは実行時間が予想を超えるクエリを終了できます。
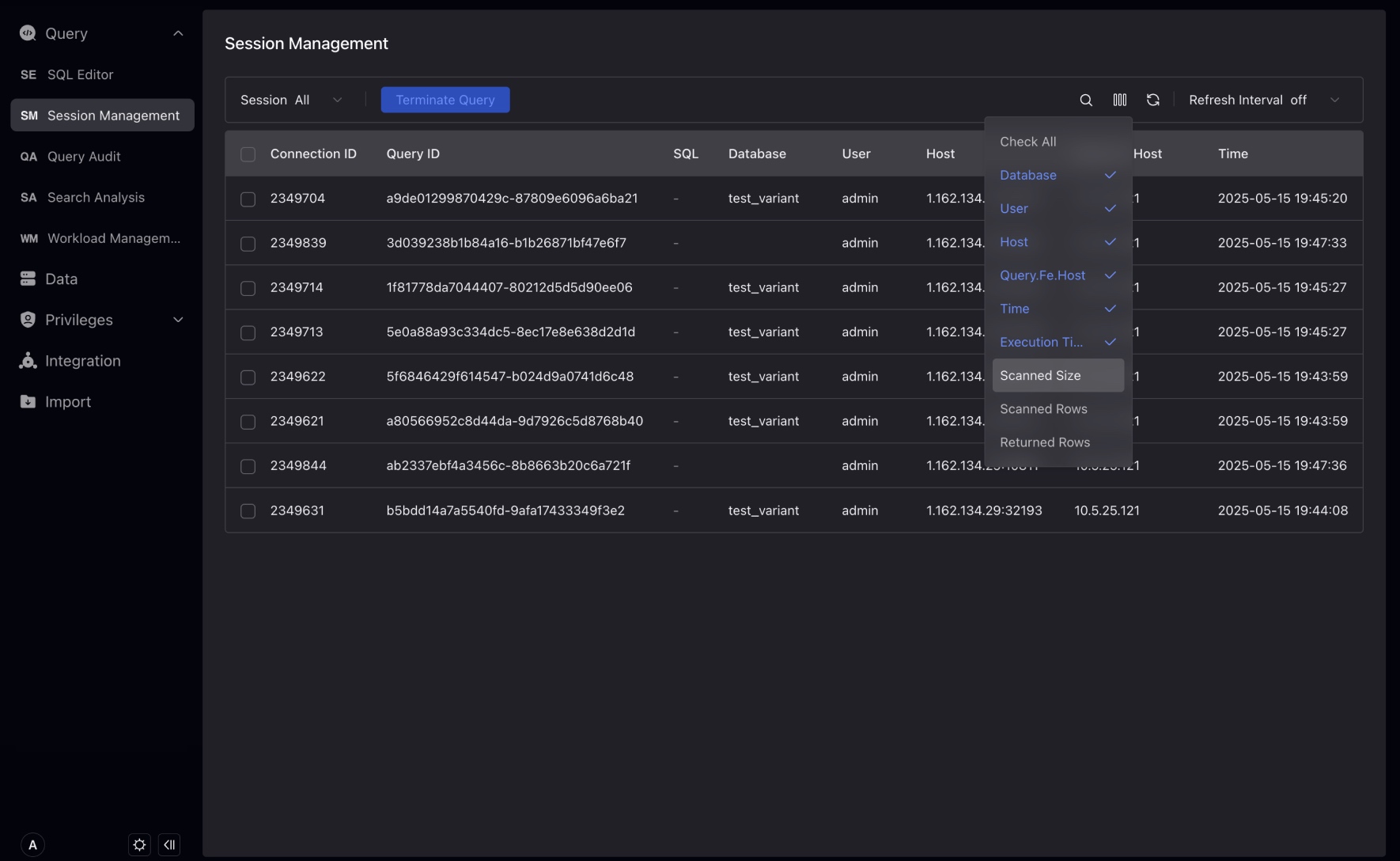
Tableをチェックして、スキャンサイズ、スキャン行数、返却行数などの実行中SQLクエリに関するより多くの情報を表示できます。
セッションのQuery IDをクリックして、実行ユーザー、セッションを受信したFEノード、SQLの実行プラン(Profile)を含むセッションの完全な情報をさらに表示します。
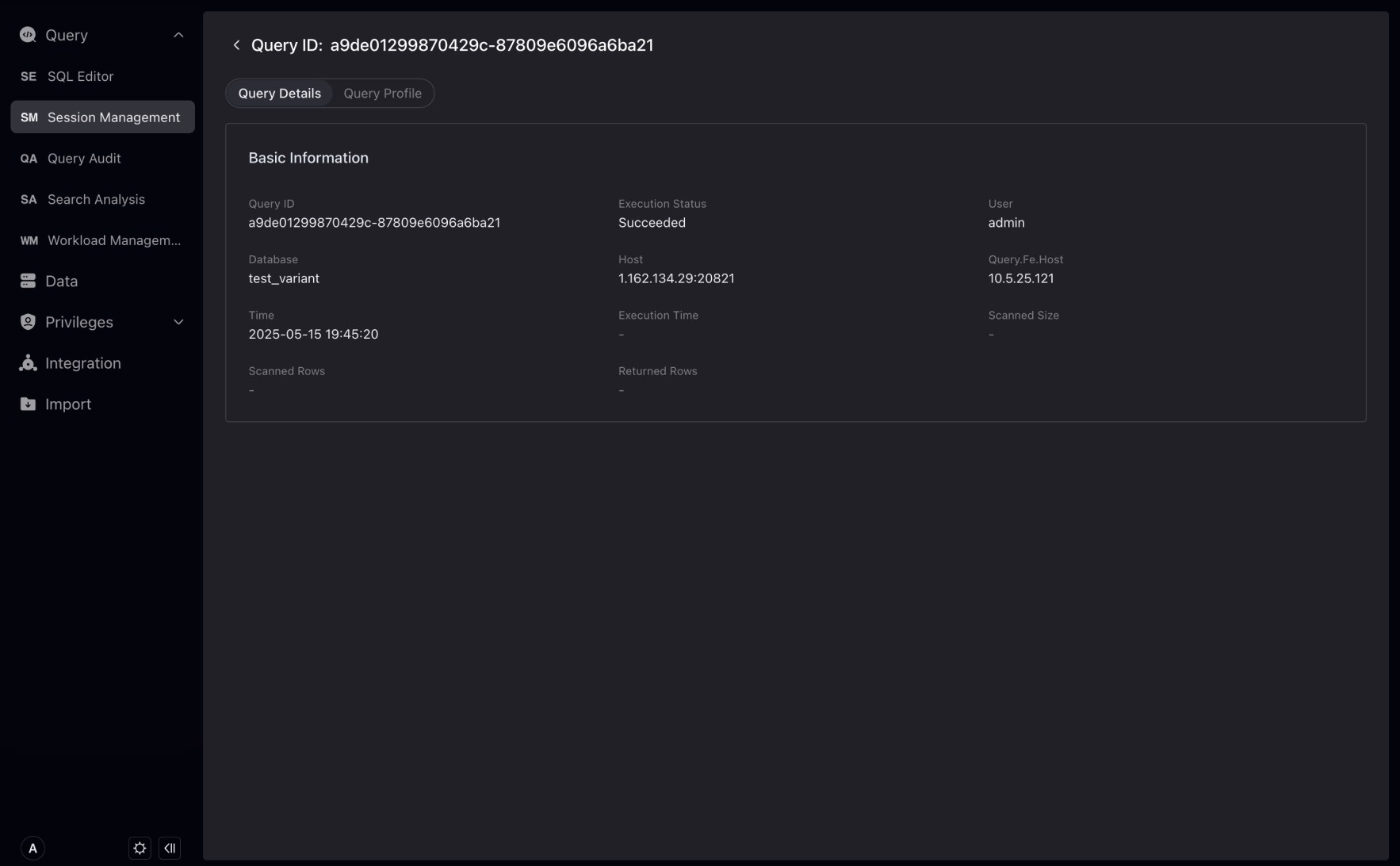
Query Audit
クエリ監査は、システムで実行されたクエリ履歴を監査・分析するために使用されます。これにより、パフォーマンスの悪いクエリをフィルタリングして特定し、データベースパフォーマンスを最適化できます。
このツールには、各クエリの実行プランとリソース使用量についての洞察を得るための分析が含まれています。クエリパフォーマンスの追跡、トレンドの発見、問題の診断のためのワンストップソリューションとして機能します。
履歴クエリをフィルタリングでき、List Selectionで、分析を支援するより多くの次元を選択できます。
「Query ID」をクリックしてクエリ詳細ページに入ります。より多くのQuery情報を表示できます。Profileが有効になっている場合、このページでクエリプロファイルを表示できます。
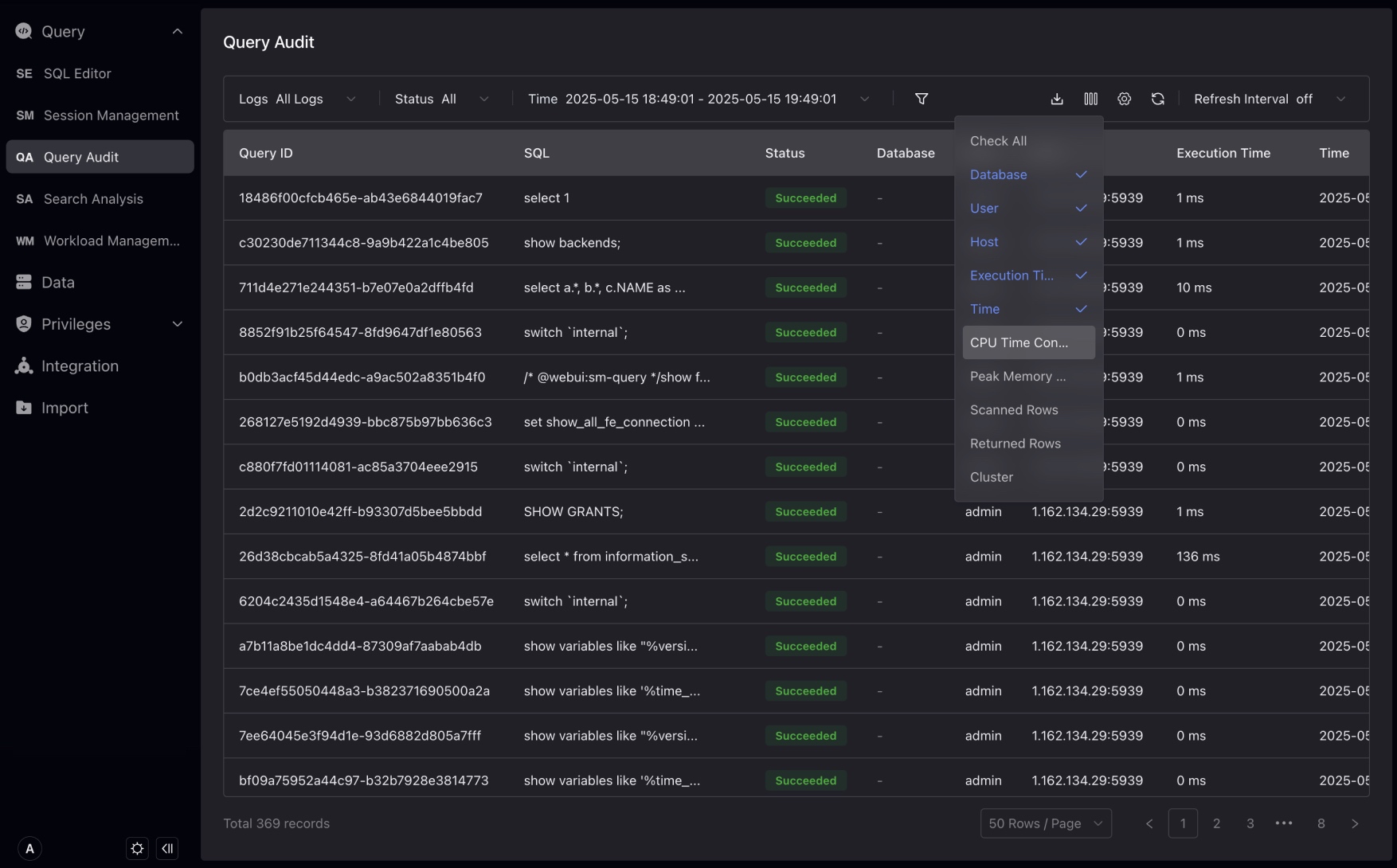
検索分析
検索分析は、VeloDB Studioによってローンチされました。これは、ログ分析シナリオ用のクエリツールで、ログの検索、クエリ、カウントを簡単に行えます。
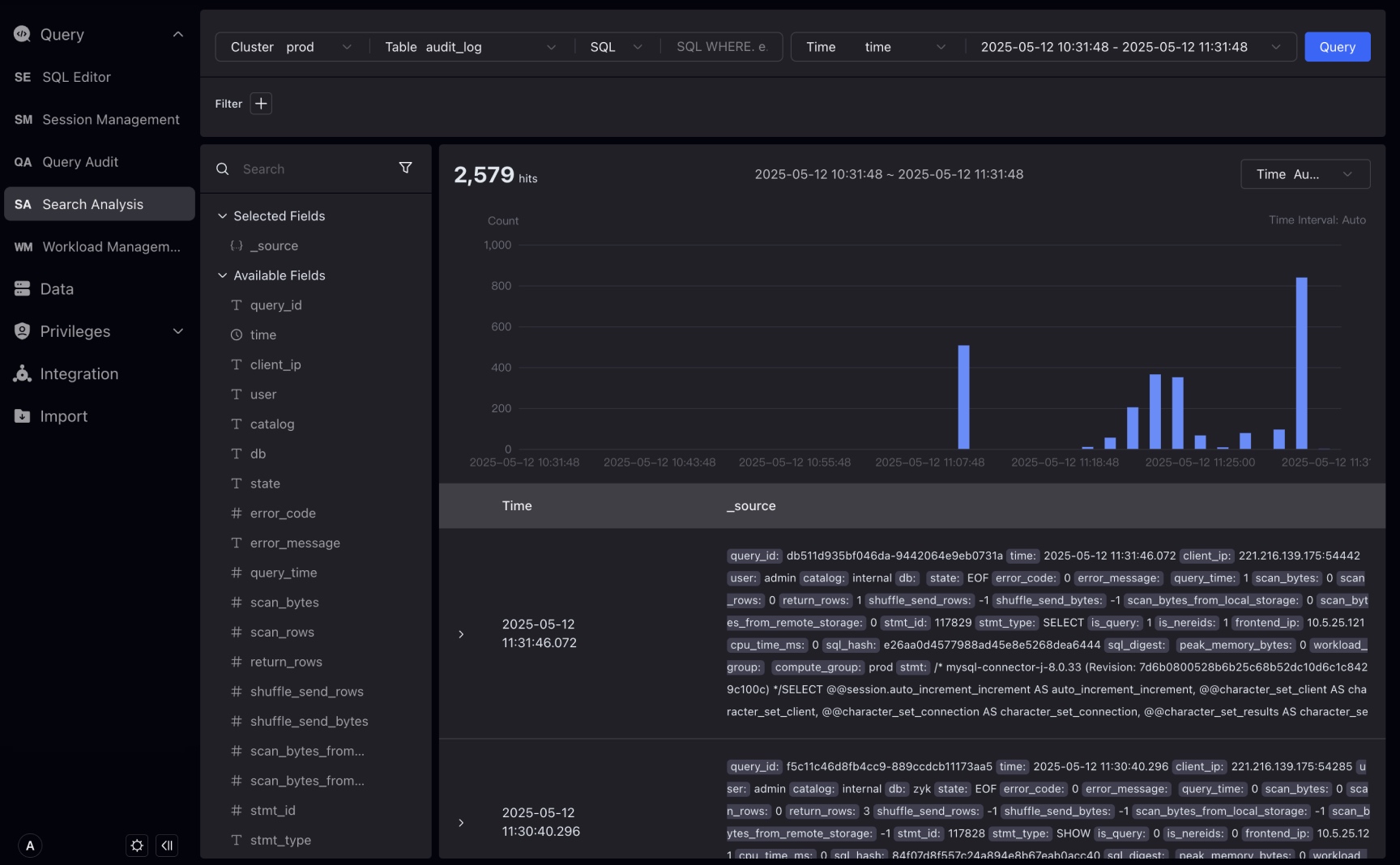
インタラクティブな検索分析インターフェースはKibana Discoverページに似ており、ログ検索のための詳細体験を最適化し、4つの領域に分かれています:
-
上部の入力領域 : クラスタ、Table、時間フィールド、クエリ時間期間を選択します。メイン入力ボックスは2つのモードをサポート:キーワード検索とSQL。
-
左側のフィールド表示と選択領域 : 現在のTable内のすべてのフィールドを表示します。右側の詳細表示領域に表示するフィールドを選択できます。フィールドにホバーすると5つの値とこのフィールドの出現割合が表示されます。値でさらにフィルタリングできます。フィルタリング条件は入力領域のフィルタリング部分に反映されます。
-
中央のトレンドチャート表示とインタラクション領域 : 特定の時間間隔で条件を満たすログ数を表示します。ユーザーはトレンドチャート上のボックスで期間を選択してクエリ時間期間を調整できます。
-
下部の詳細データ表示とインタラクション領域 :: ログ詳細を表示し、クリックして特定のログの詳細を表示できます。TableとJSONの2つの形式をサポートします。Table形式は、フィルター条件のインタラクティブ作成もサポートします。
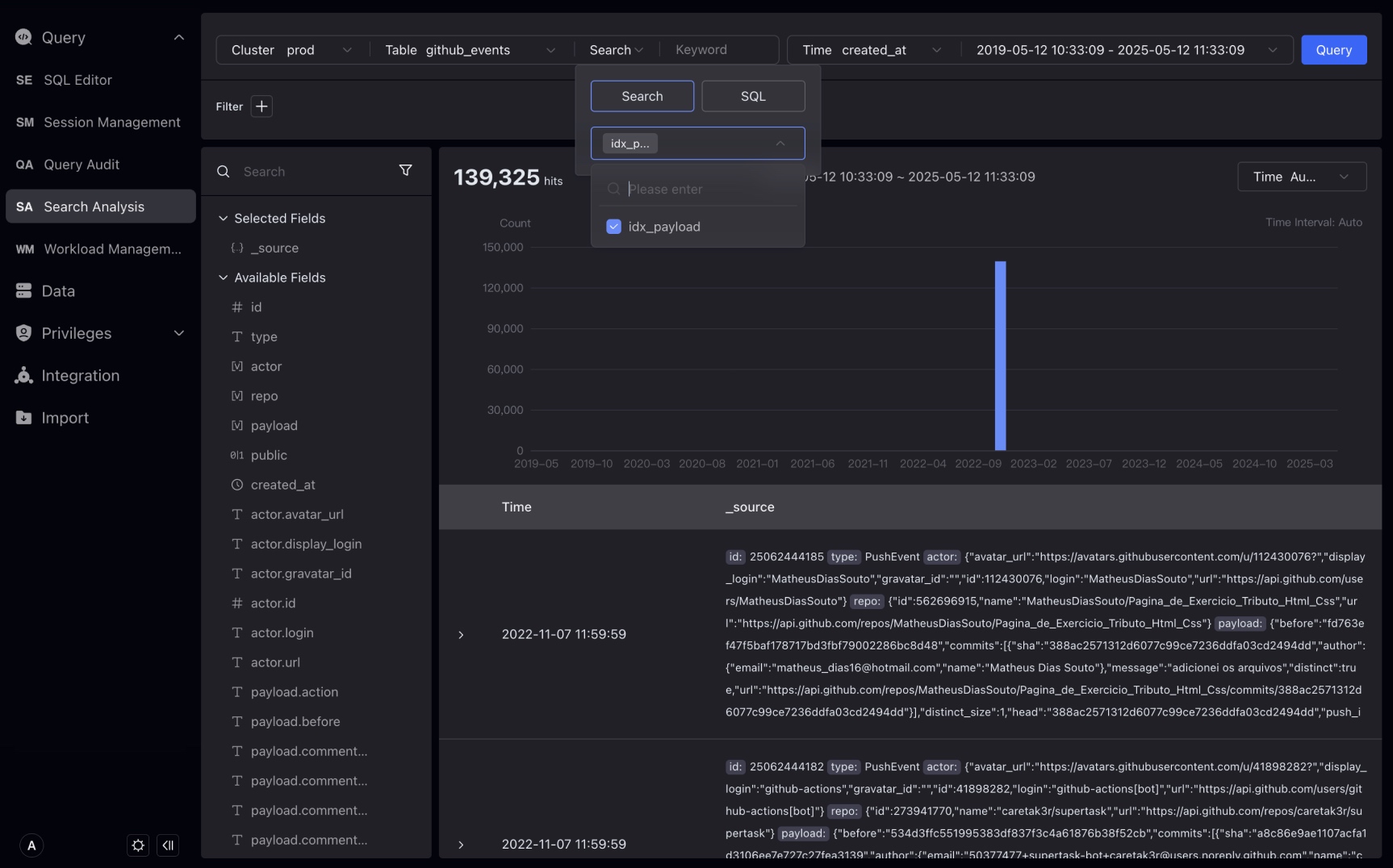
Query > Search Analysisをクリックして、Tableをinternal_schema > audit_logとして選択すると、Studioは自動的にTable内のフィールドをクエリし、最初の時間フィールドを選択します。
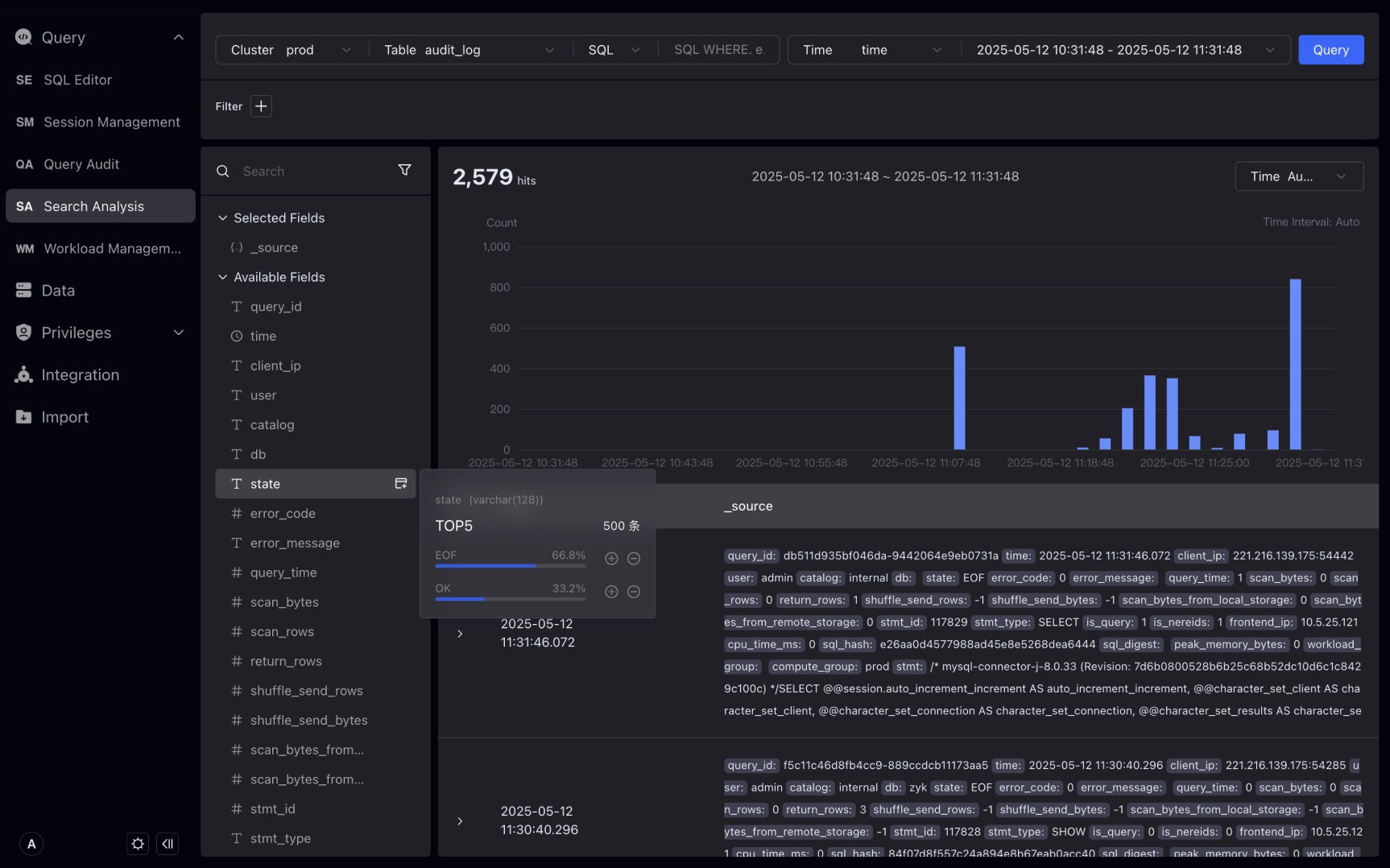
左側のstateフィールドにホバーすると、最高頻度のstate値EOF、OK、ERRが表示され、割合も表示できます。さらに、プラス記号(+)またはマイナス記号(—)ボタンをクリックしてフィルター条件を作成することもできます。例えば、ERRの右側のマイナス記号(—)ボタンをクリックすることで、ERRの右側のマイナス記号(—)ボタンをクリックしてstate != ERRがフィルター条件に表示されます。
メイン入力ボックスで、検索とSQLモードを使用してキーワードをクエリします。検索モードは転置インデックスを持つTableでのみサポートされます。
検索ボックスの下で検索を選択し、右側にGETを入力してクエリをクリックします。検索モードでは、キーワードGETを含むログを検索します。詳細内のGETがハイライトされ、トレンドチャート内のデータストリップ数が相応に変化します。
注記 任意のキーワードにマッチするMATCH_ANY文の検索は、ログ内の任意のフィールドにマッチできます。検索結果のハイライトは可能な限りすべての検索キーワードにマッチしますが、特殊文字の影響で、常に検索キーワードに完全にマッチするとは限りません。
検索で二重引用符を使ってフレーズをラップできます。例えば"GET /api/v1/user"。フレーズ全体にマッチします。フレーズはMATCH_PHRASEを使用してフレーズにマッチします。
より精密なマッチが必要な場合は、SQLパターンを使用できます。
検索ボックス下でSQLを選択し、SQLモードでSQL WHERE条件を入力してQueryをクリックします。
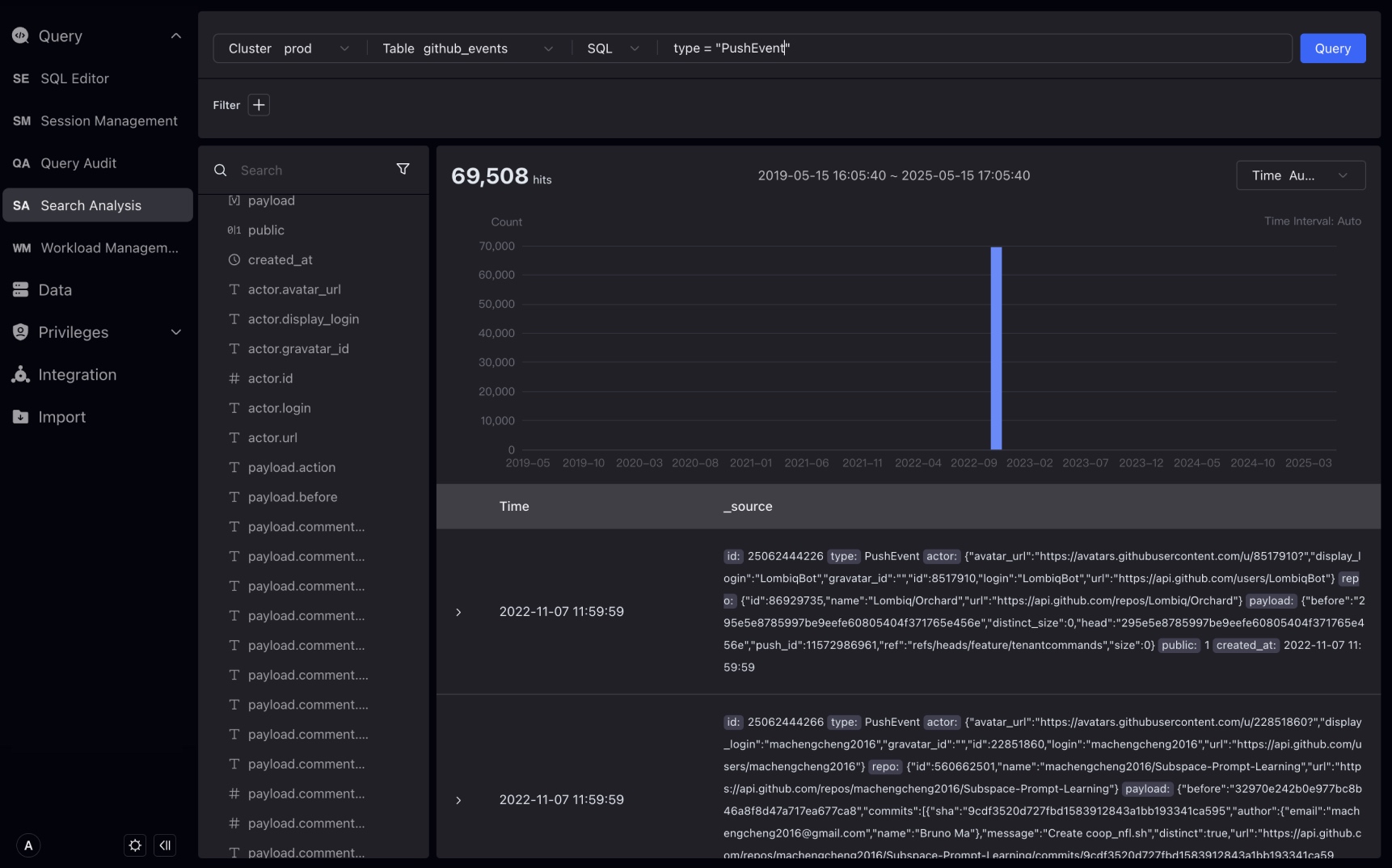
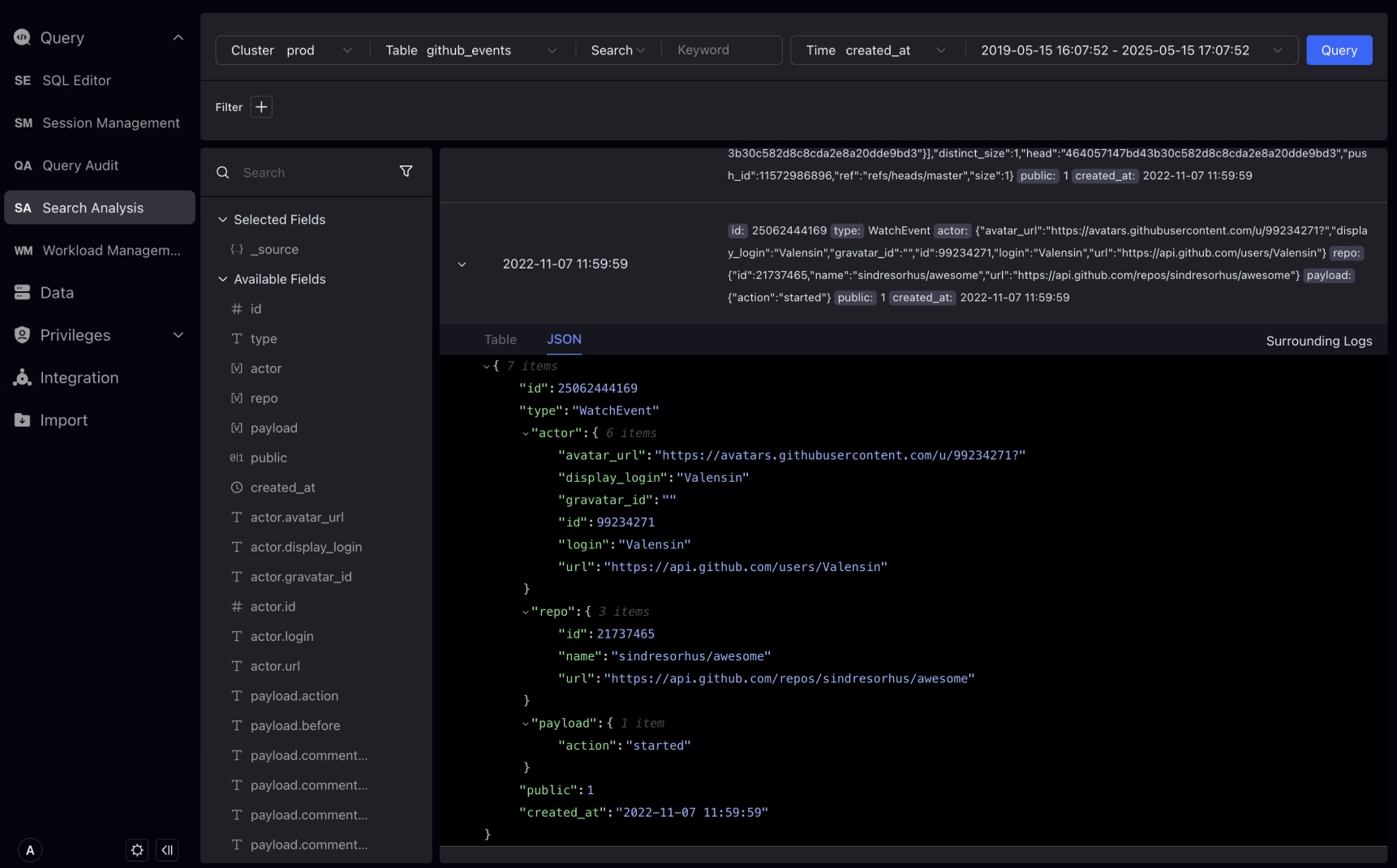
ログ詳細を展開し、TableまたはJSON形式をオプション選択でき、Table形式はフィルターのインタラクティブ作成をサポートします。
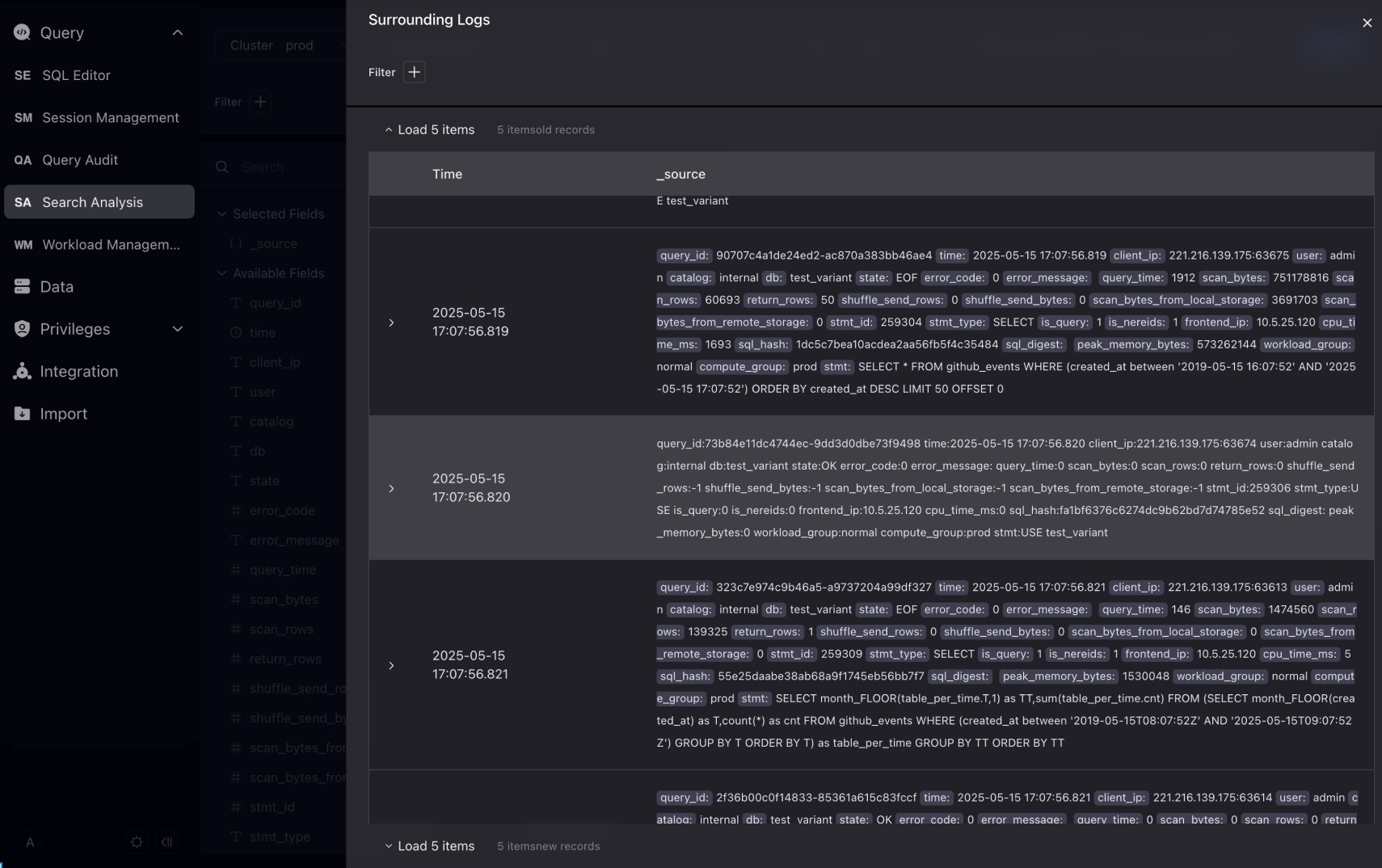
右側のコンテキスト検索をクリックして、このログの前後10件のログを表示します。コンテキスト検索でフィルター条件を追加し続けることができます。
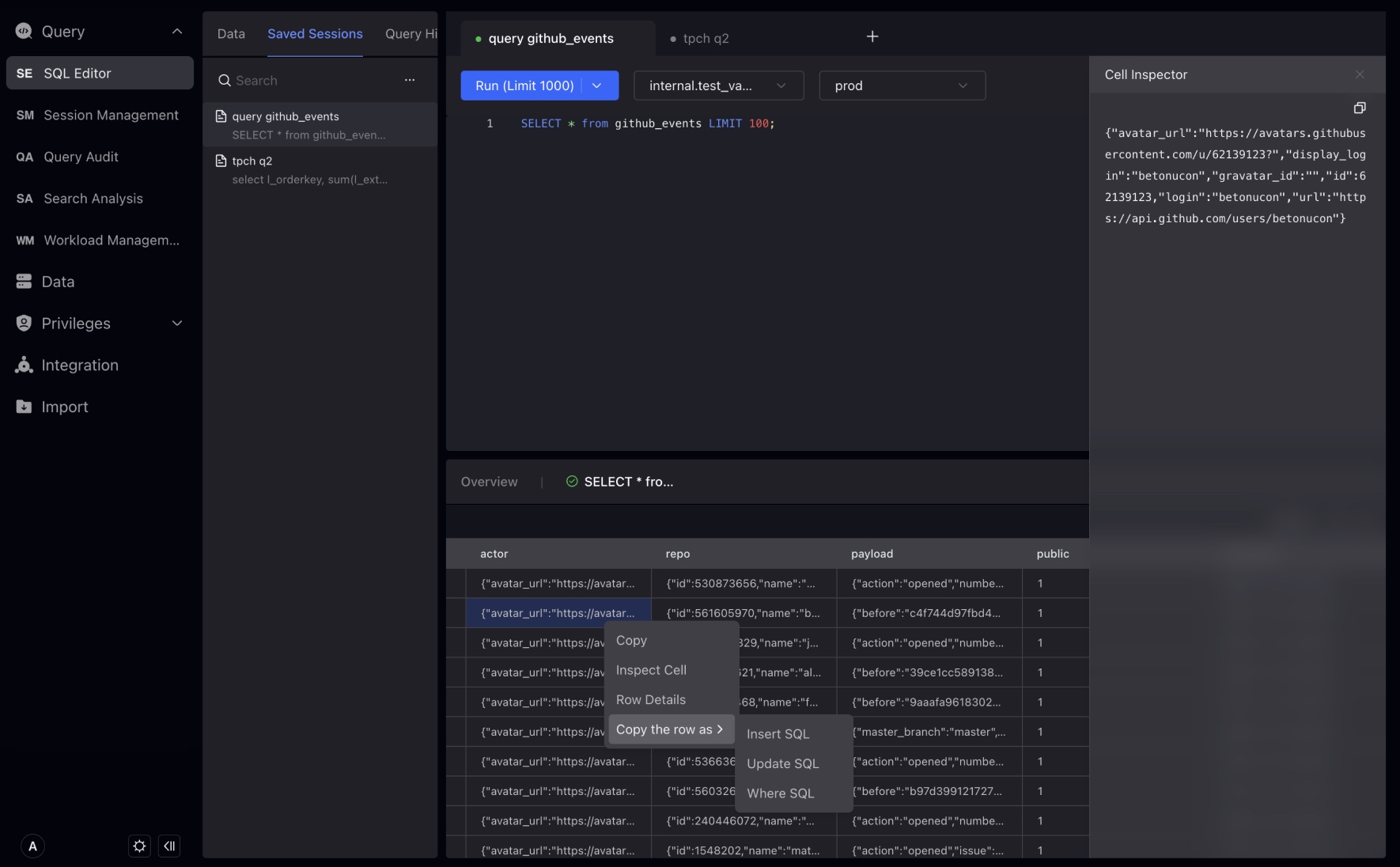
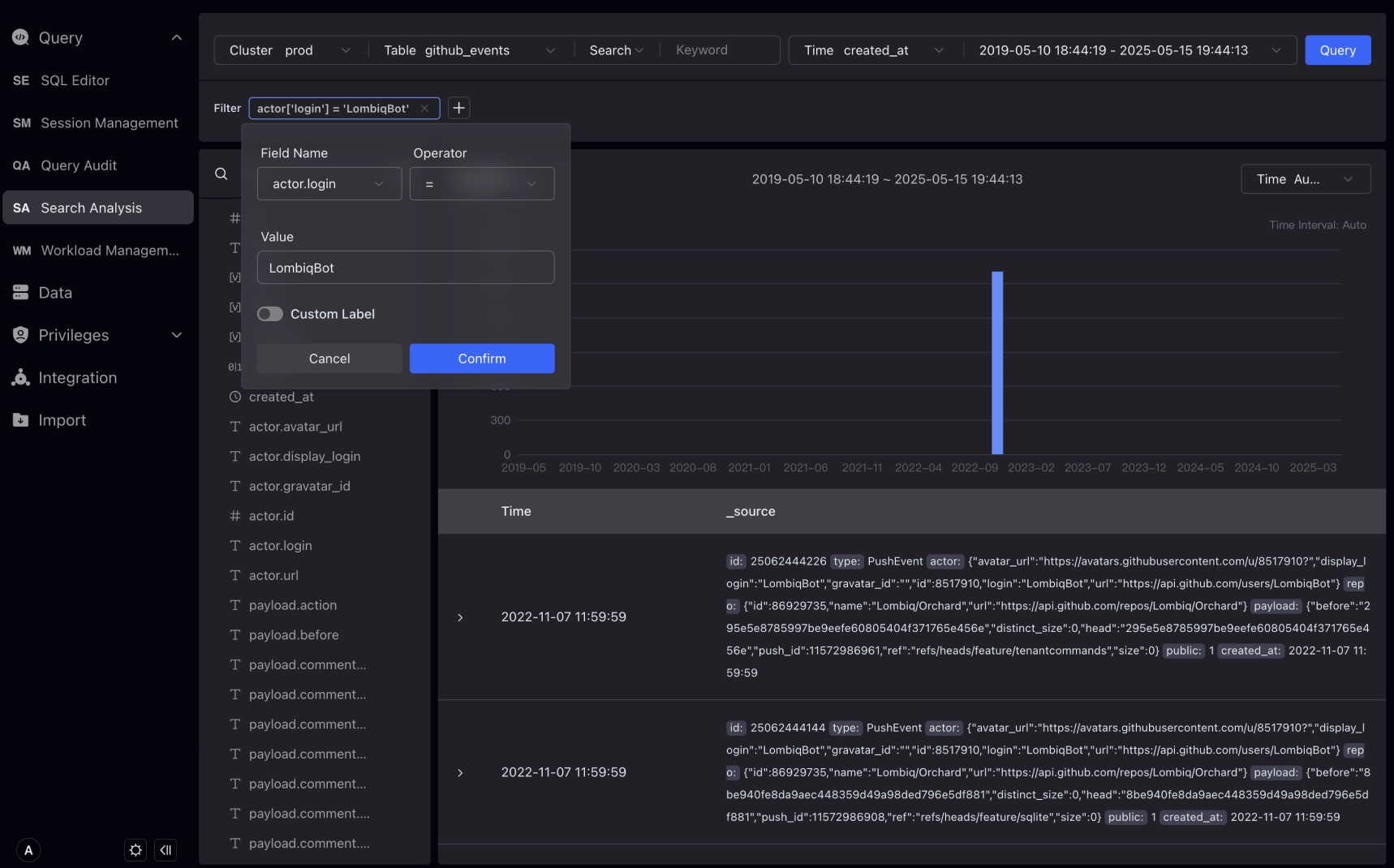
新しいデータ型VARIANTを導入しました。これは半構造化JSONデータを保存できます。VARIANT型は、いつでも変更される可能性のある複雑なネストした構造を処理するのに特に適しています。
StudioはVARIANTデータ型を認識し、そのデータ型の階層を自動展開し、特別なフィルタリング方法を提供します。
github_eventsTableを例として、VARIANTデータ型のフィールドをフィルタリングする方法を示しましょう。
フィルタリング条件で、VARIANTデータ型のフィールドを選択し、その中のサブフィールドを選択してフィルタリングできます。
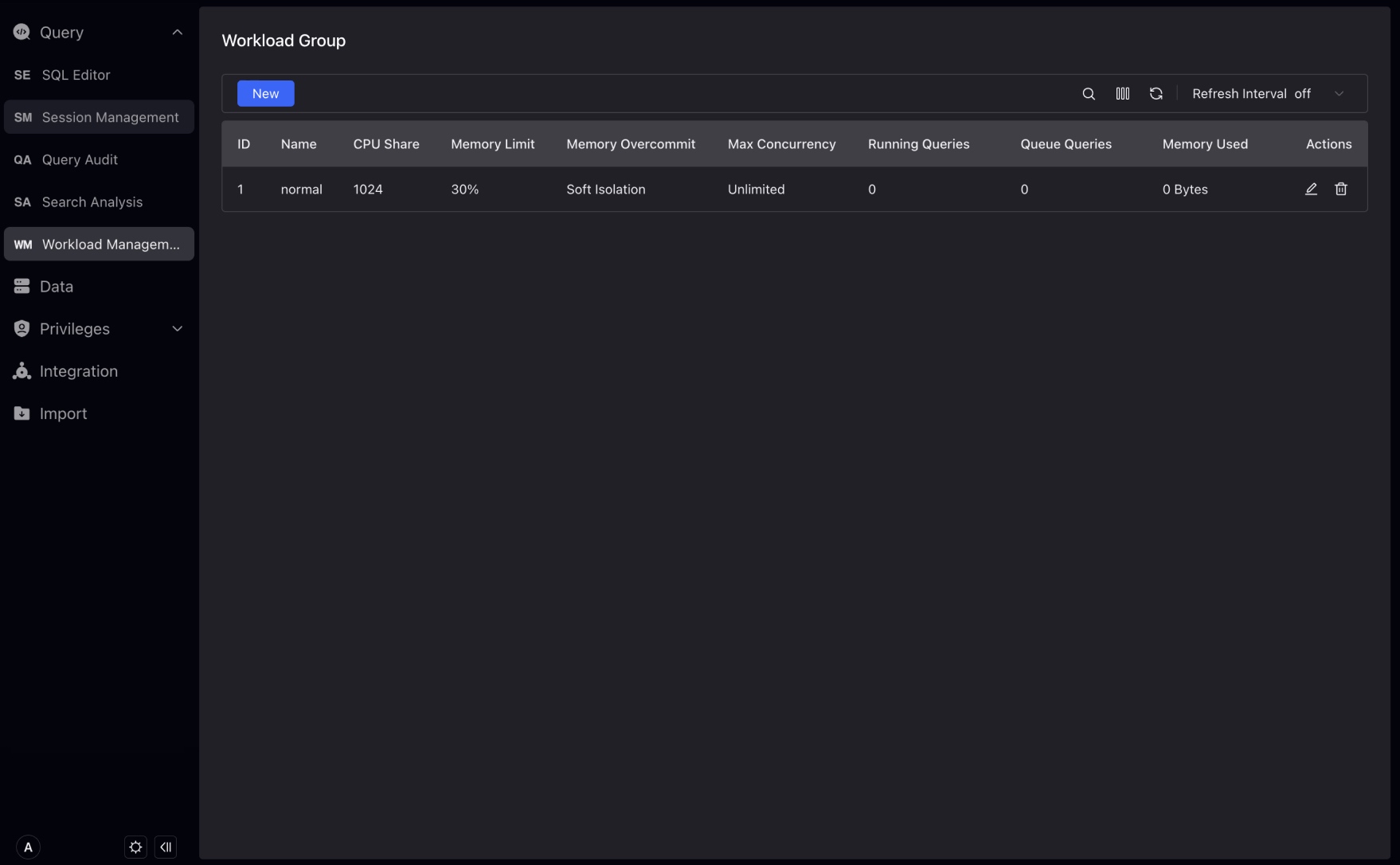
Workload Group管理
注記 Workload Group管理はVeloDB Cloud 4.0.0以上をサポートします。
Workload Group管理は、Workload Groupの迅速な作成、編集、表示をサポートします。Workload Groupを使用することで、クラスタ内のクエリおよびインポート負荷で使用されるCPU/メモリ/IOリソース使用量を管理し、クラスタ内のクエリの最大同時実行数を制御できます。
Workload Groupリストの上にあるTableフィルターで、より多くの項目を表示できます。
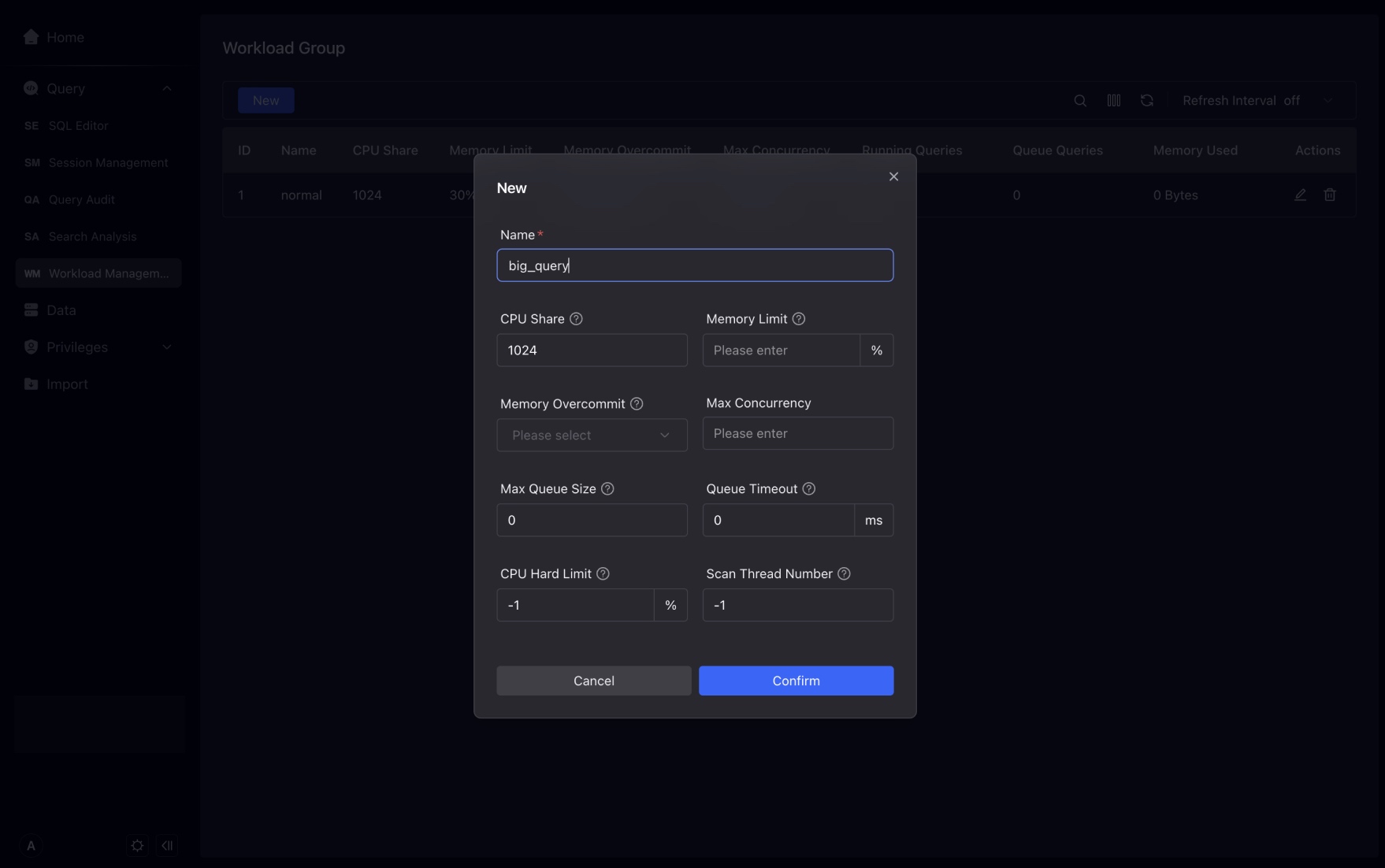
New Workload Groupインターフェースで、パラメータのクエスチョンマークをクリックすると、パラメータの説明が表示されます。
統合
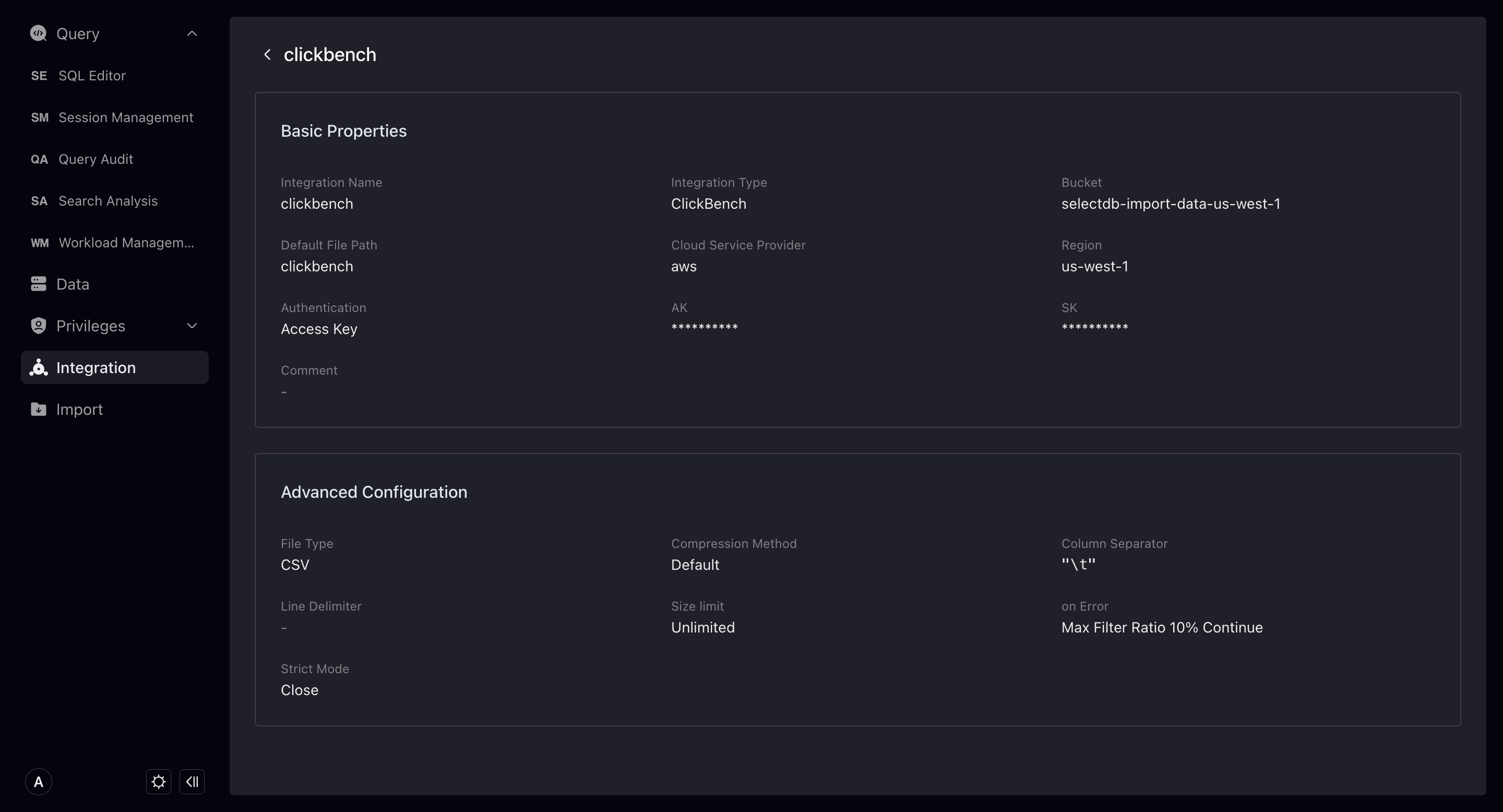
統合は、VeloDB Cloudとウェアハウス外部のデータを接続するポータルです。
現在、2つの新しい統合を作成できます:Stage統合(オブジェクトストレージ)とサンプルデータです。
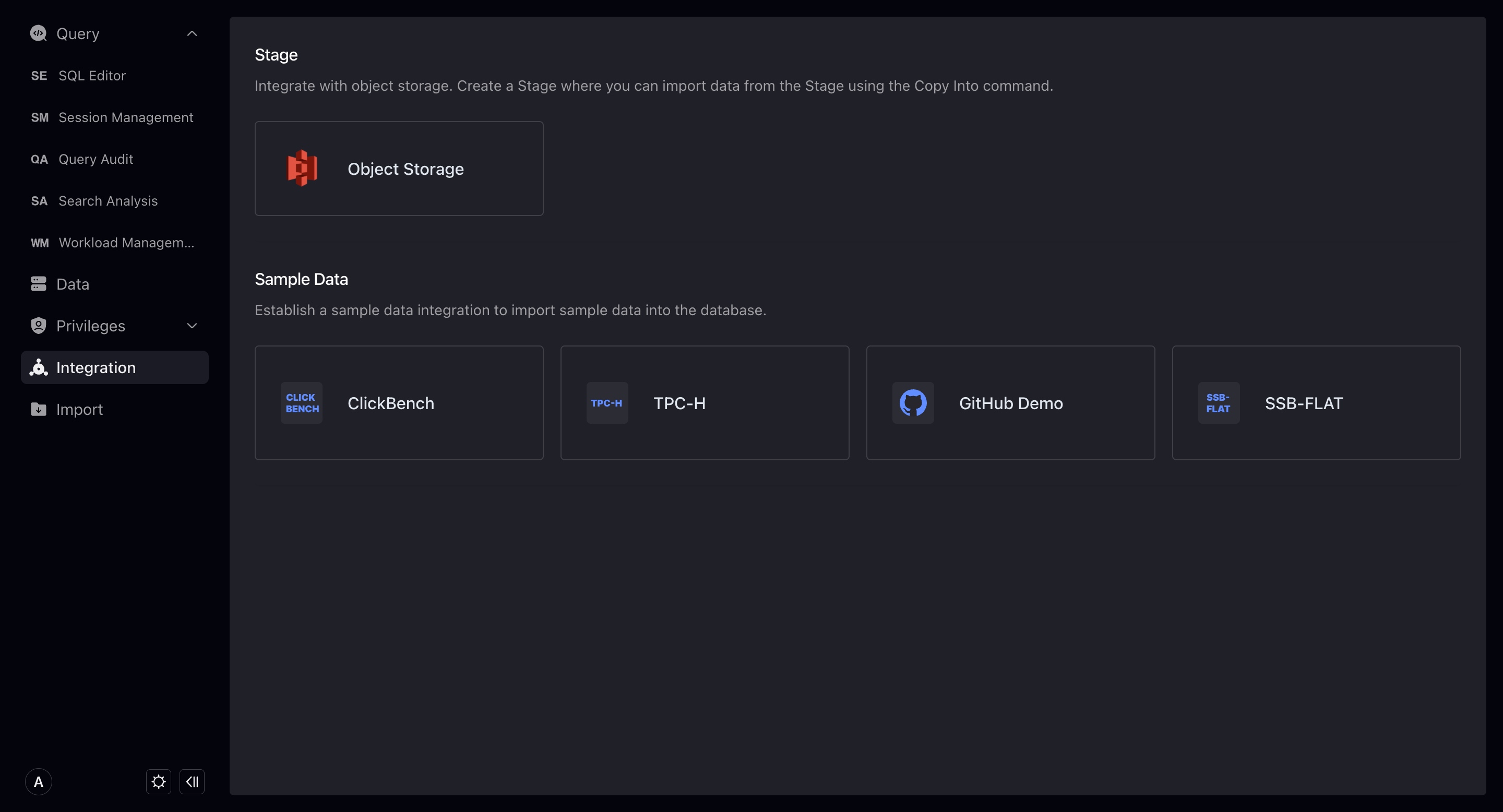
オブジェクトストレージ
新しいオブジェクトストレージ統合を作成することで、オブジェクトストレージ内のデータとのConnectionを確立できます。Integrate + Copy Intoコマンドを通じて、オブジェクトストレージ内のデータをウェアハウスにImportできます。
新しいオブジェクトストレージ統合を作成する際は、以下を入力する必要があります:
- 統合 Name: データベースオブジェクトの命名規則と一致し、最大64文字、英数字、アンダースコアが使用できます。
- コメントs: 統合コメント。
- バケット : 統合する必要があるバケット。
- Default file path: バケット内でアクセスするファイルパス。VeloDBは入力したパス下のファイルのみにアクセスします。入力しない場合、デフォルトではバケット全体のデータにアクセス可能です。
- Access Authorization: VeloDBがバケットにアクセスすることを許可する方法。Access keyとクロスアカウント認証に分かれます。セキュリティ向上のため、クロスアカウント認証の使用を推奨します。クロスアカウント認証のガイドラインについては、 IAM Cross-Account Access Guide を参照してください。統合を正常に作成するには権限チェックに合格する必要があります。
- Advanced 構成: 詳細は以下。
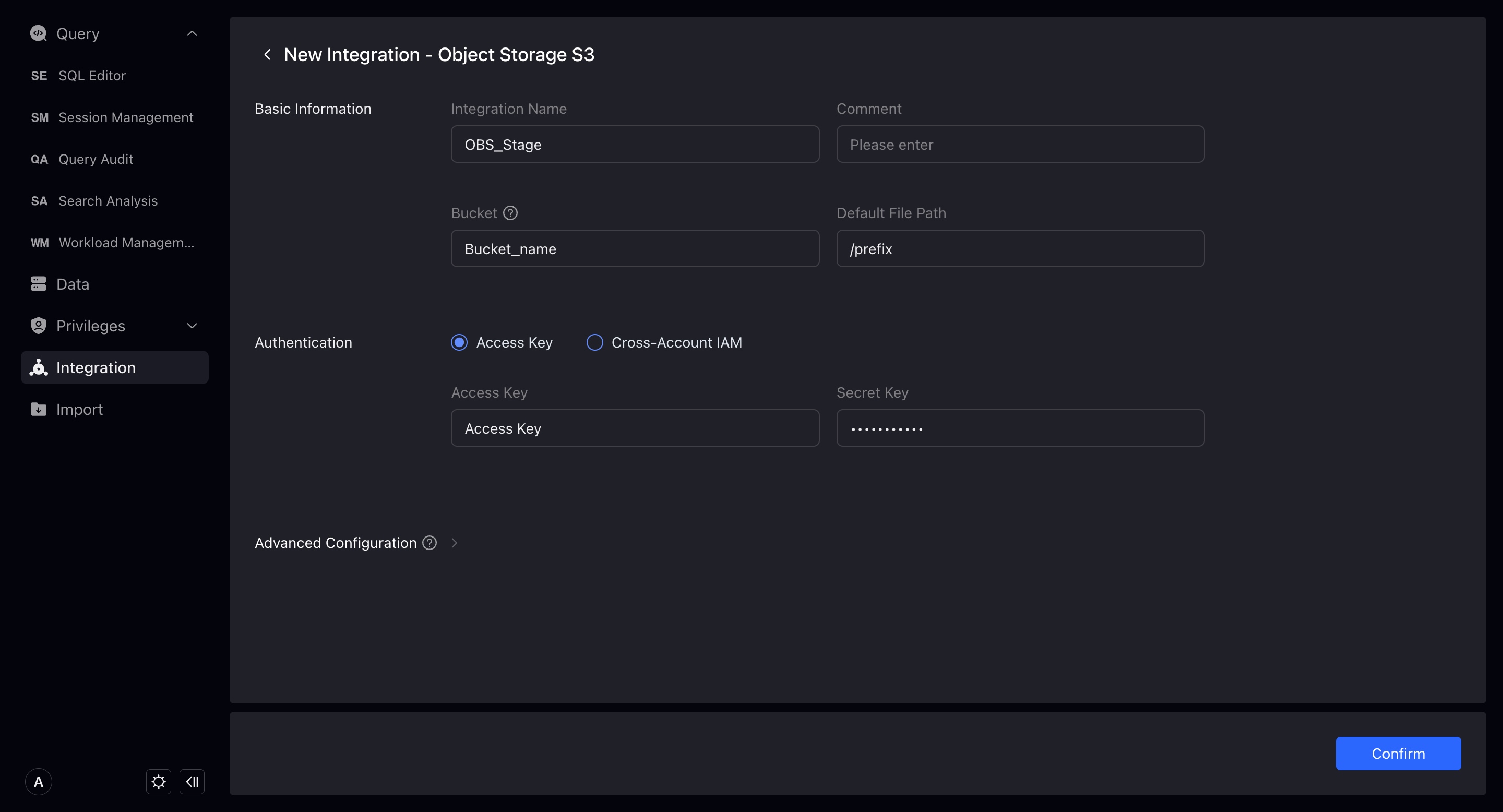
File タイプとImport 構成に分かれます。これらは統合データをインポートする際に使用する可能性があるパラメータです。ここで設定するか、インポート時に指定できます。設定または指定しない場合、システムはデフォルト設定で統合のインポートタスクを実行します。
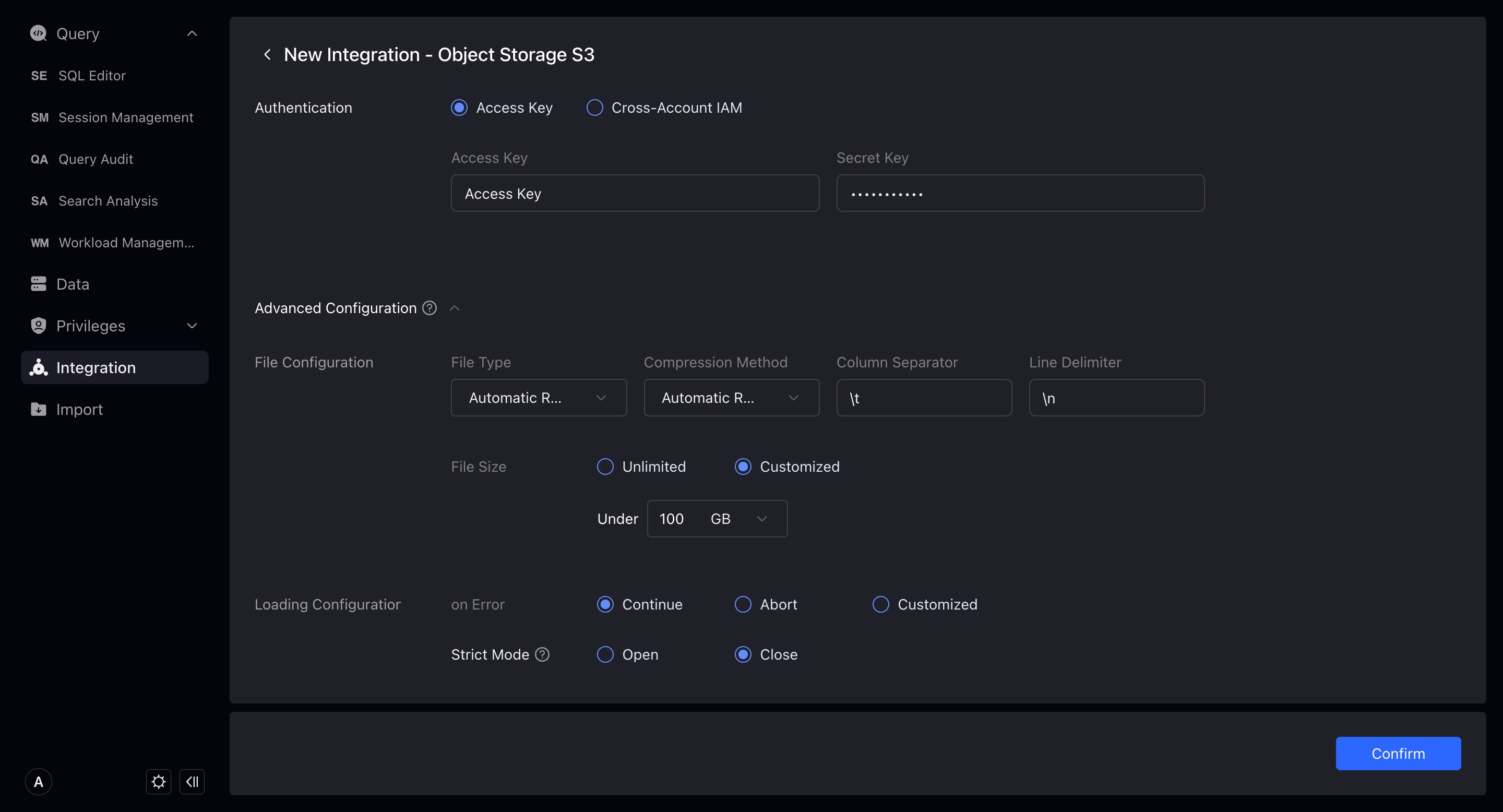
- File type: 統合ストレージファイルのデフォルトタイプ。現在
csv、json、orc、parquetをサポート。デフォルトではシステムがファイル名サフィックスから推測します。 - Compression method: 統合ストレージファイルのデフォルト圧縮タイプ。現在
gz、bz2、lz4、lzo、deflateをサポート。デフォルトではシステムがファイル名サフィックスから推測します。 - Column separator: 統合ストレージファイルのデフォルト列セパレータ。デフォルト
\t。 - Line separator: 統合ストレージファイルのデフォルト行セパレータ。デフォルト
\n。 - File size: この統合下のファイルをインポートする際の、デフォルトインポートサイズ制限。デフォルトでは無制限。
- On Error: この統合下のファイルをインポートする際、データ品質が不適格な場合のデフォルトエラー処理方法。3つのタイプがあります:インポート継続、インポート停止、エラーデータの割合が特定値を超えない場合のインポート継続。
- Strict Mode: インポートプロセス中の列タイプ変換を厳密にフィルタリング。デフォルトはオフ。
サンプルデータ
新しいサンプルデータ統合を作成すると、オブジェクトストレージ統合を作成する基盤の上で、サンプルデータをデータベースにインポートします。そのため、新規作成を完了するためにクラスタを選択する必要があります。 TPCH、Github Event、SSB-FLATテストデータサイズには以下の選択肢があります:sf1(1GB)、sf10(10GB)、sf100(100GB)、ドロップダウンメニューで選択し、テストウェアハウスは1sf(1GB)のみ選択可能です。
Clickbenchにはsf100(100GB)のオプションのみがあり、Clickbenchサンプルデータをインポートするためには、より大きなクラスタを使用することを推奨します。
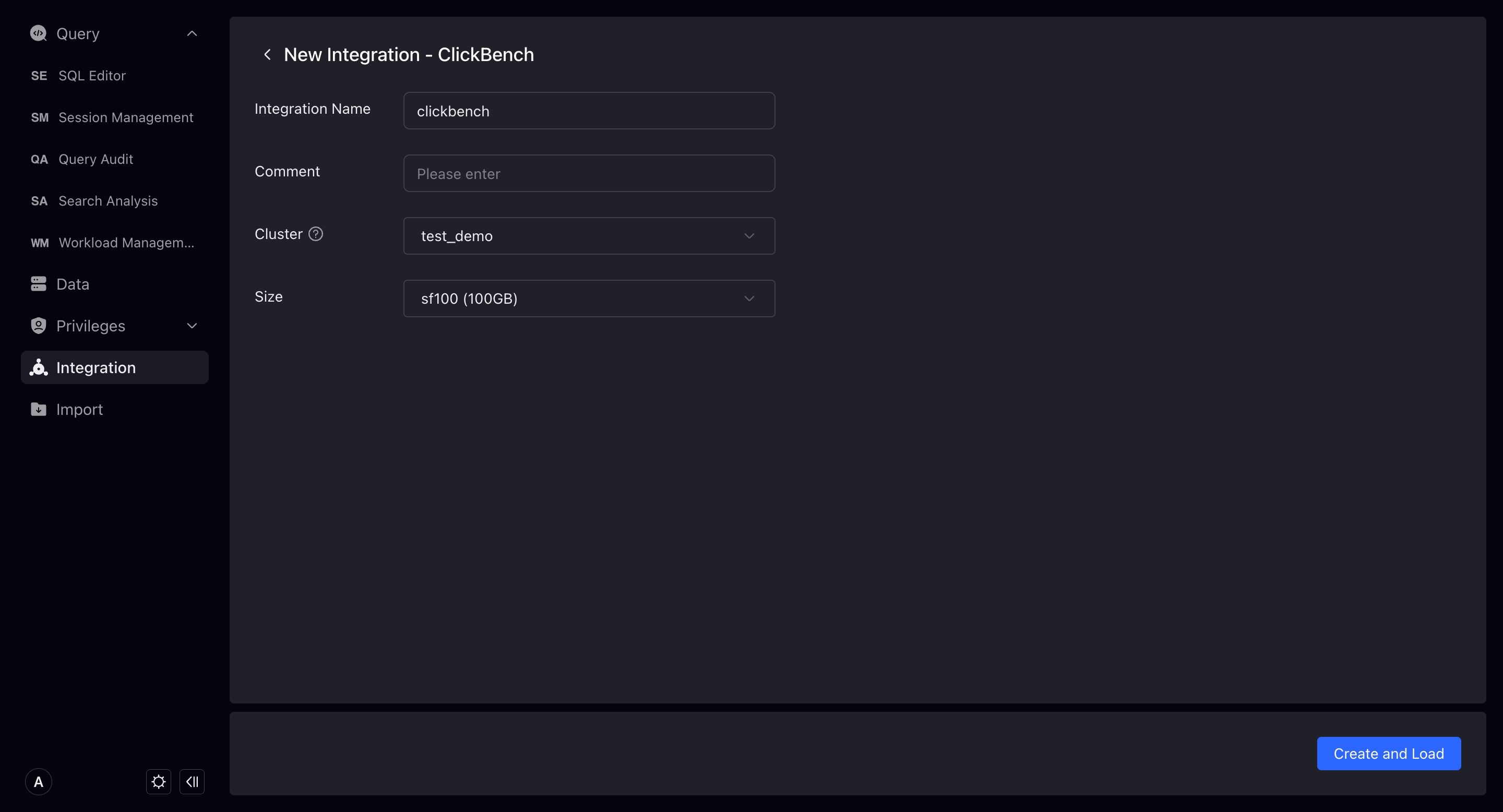
サンプルデータ詳細でインポート進捗を表示できます。
権限
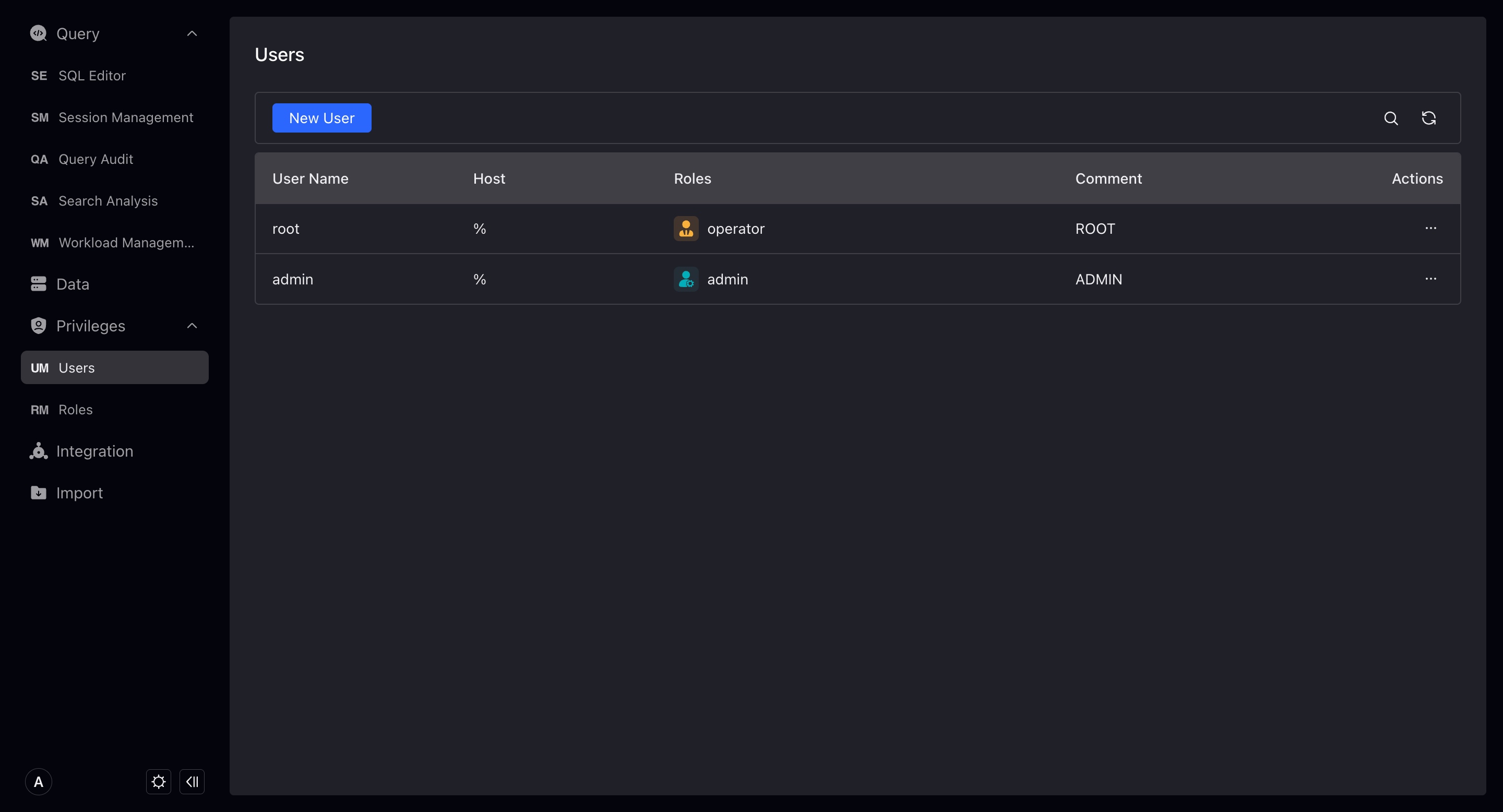
User
VeloDBリポジトリ内のユーザーを表示します。rootユーザーはここに表示されないことに注意してください。
Admin権限を持つユーザーのみが他のユーザーを追加・変更できます。
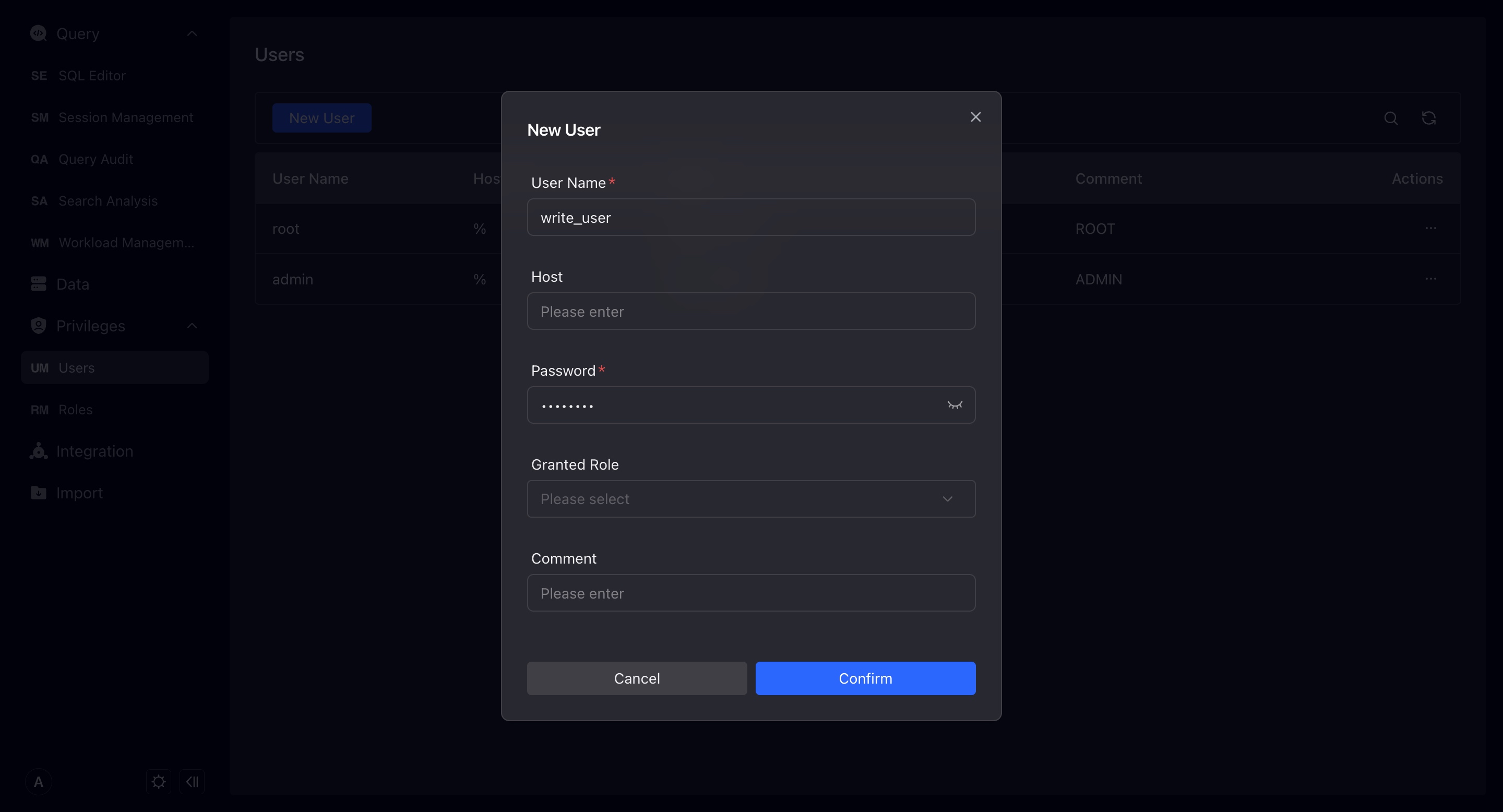
このページで新しいユーザーを作成できます。ユーザー名以外の内容はオプションです。ただし、セキュリティ強化のため、ユーザーにパスワードを追加し、ホストへのアクセスを制限することを強く推奨します。
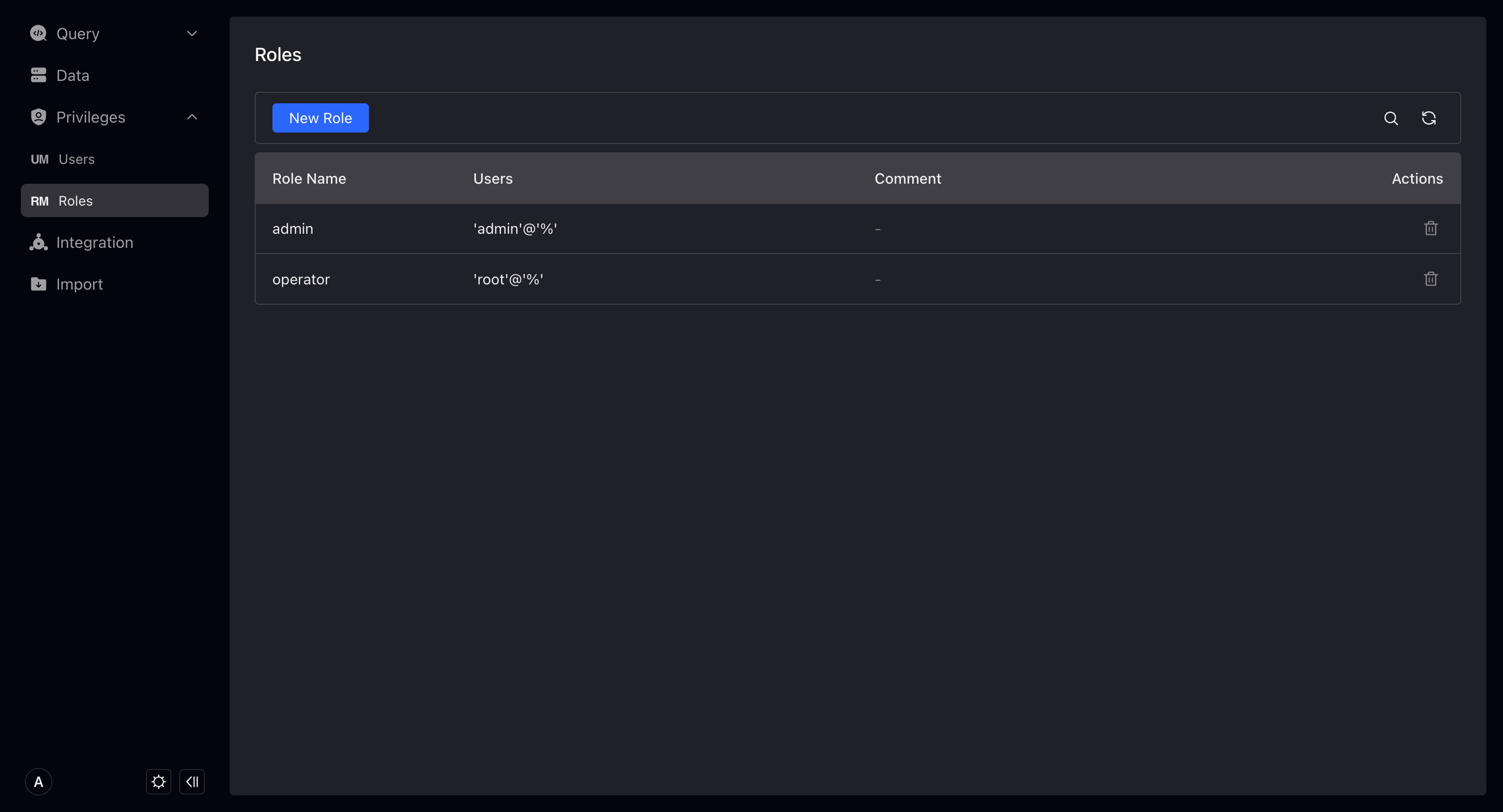
Role
ここでVeloDB内のロールを管理し、ロールに対して認証操作を実行できます。
Admin権限を持つユーザーのみが他のロールを追加・変更できます。
VeloDBは現在、ロールを通じてロール下のユーザーを管理することをサポートしていません。つまり、ユーザーを作成または変更する際にロールを指定する必要があります。
認証
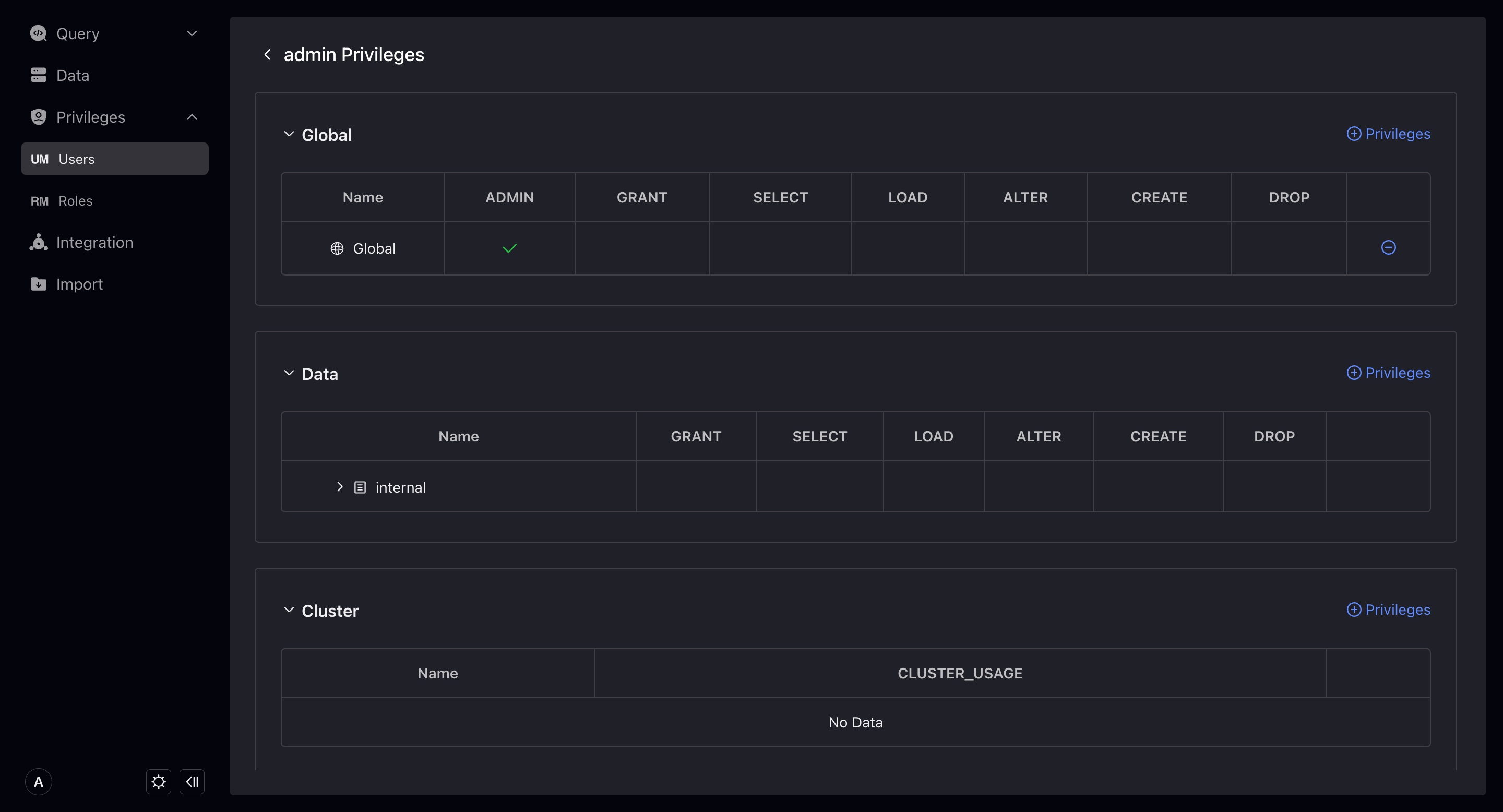
ユーザーまたはロール詳細ページで、特定のユーザーまたはロール名をクリックして権限設定ページに入り、認証/取り消し操作を実行できます。認証/取り消しを実行するには、対応するレベルでAdminまたはGrant権限を持つ必要があります。
VeloDBでは、権限は以下のカテゴリに分かれます:
- Global: グローバル権限はデータベース全体レベルの権限で、グローバル権限を持つと、データベース内のすべての対応するオブジェクトに対する対応権限を自動的に持ちます。
- Data: データリソースの権限を指します。レベルに応じて認証でき、親レベルで権限を持つと、その子コンテンツの対応権限を自動的に持ちます。
- Workload Group: Usage権限のみ。
- Resource: Resourceの権限で、GrantとUsageを含みます。
- Compute Group: メモリ分離クラスタはVeloDB 3.0に存在し、異なるコンピューティンググループのUsage権限を制御します。
- Cluster: VeloDB Cloud接続に存在し、異なるクラスタのUsage権限を制御します。
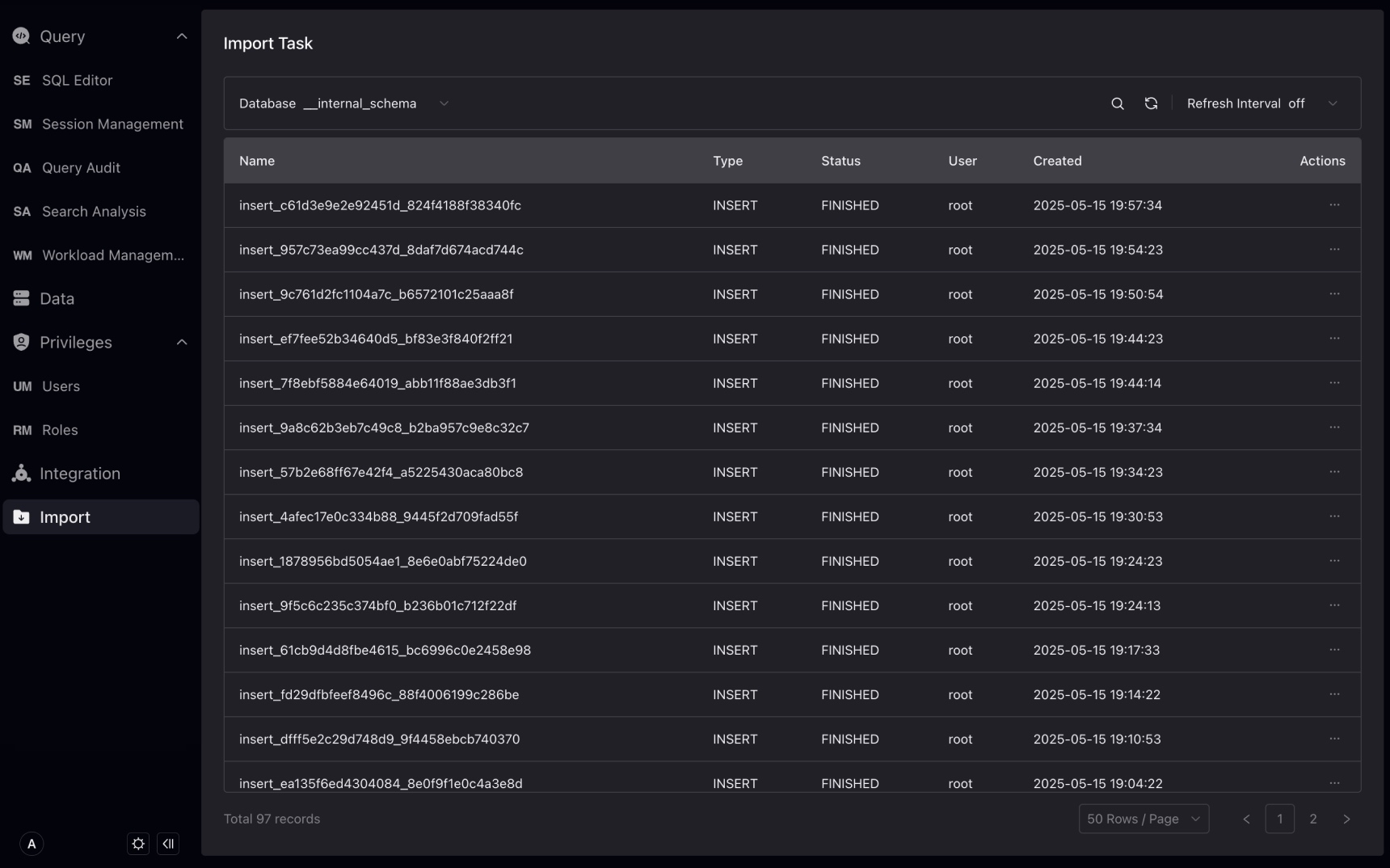
インポート
VeloDB Studioは、接続でのStream Load、Routine Load、Broker Load、Insert Intoなどのロードタスクの管理をサポートし、現在以下の操作をサポートしています:
- ロードタスクの情報クエリ
- Routine Load、Broker Load、Insert Intoの停止
- Routine Loadの一時停止/編集/復旧
まずデータベースを選択し、そのデータベース下のすべてのロードタスクをロードタスクリストで表示します。
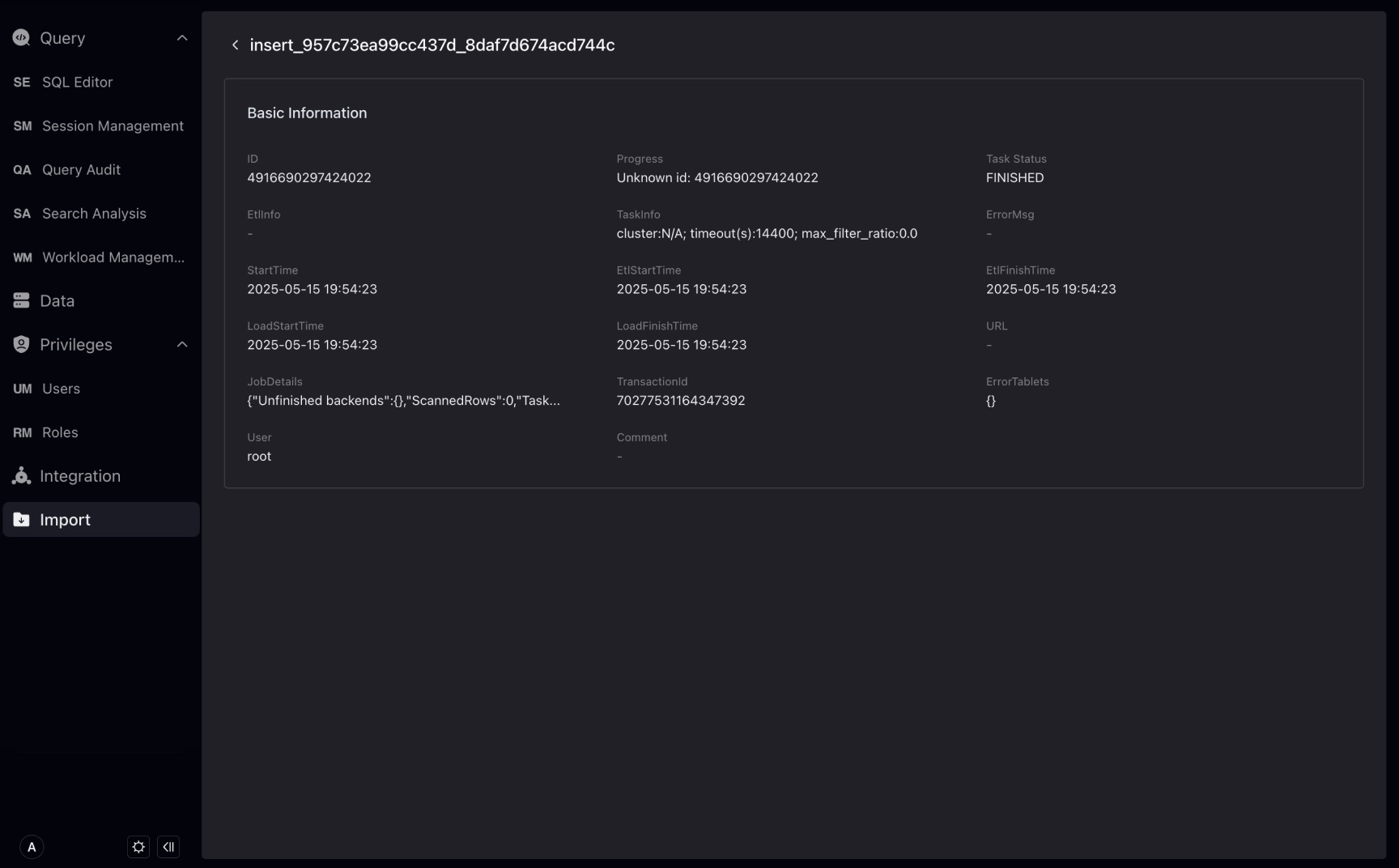
ロードタスク名をクリックして、ロードタスクの詳細情報を表示します。
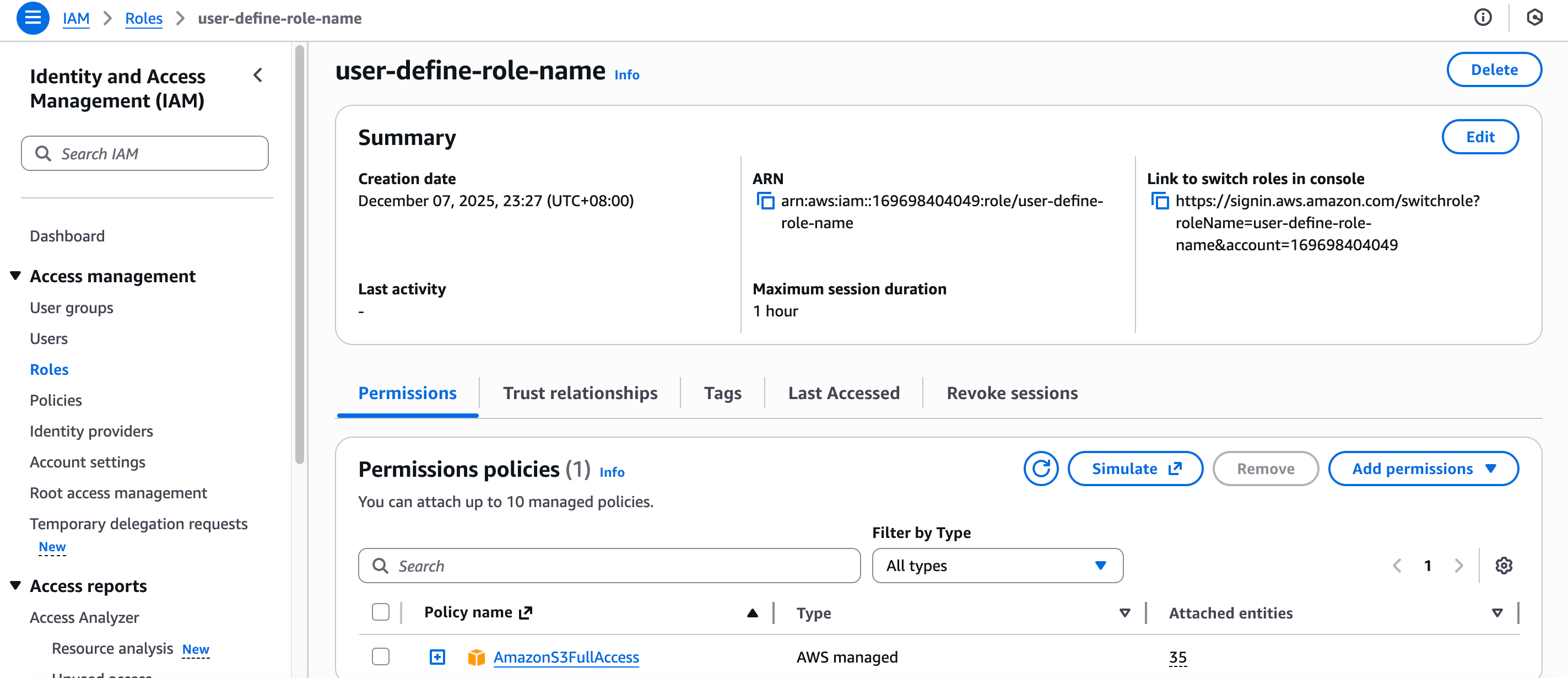
IAMロールセットアップガイド(AWS)
AWSコンソールでロールを作成し、権限を追加するために、以下の手順を使用してください:
- IAMサービスにアクセスし、メニューからRolesを選択します。Create roleボタンをクリックします。
- Select trusted entityセクションでCustom trust policyを選択します。
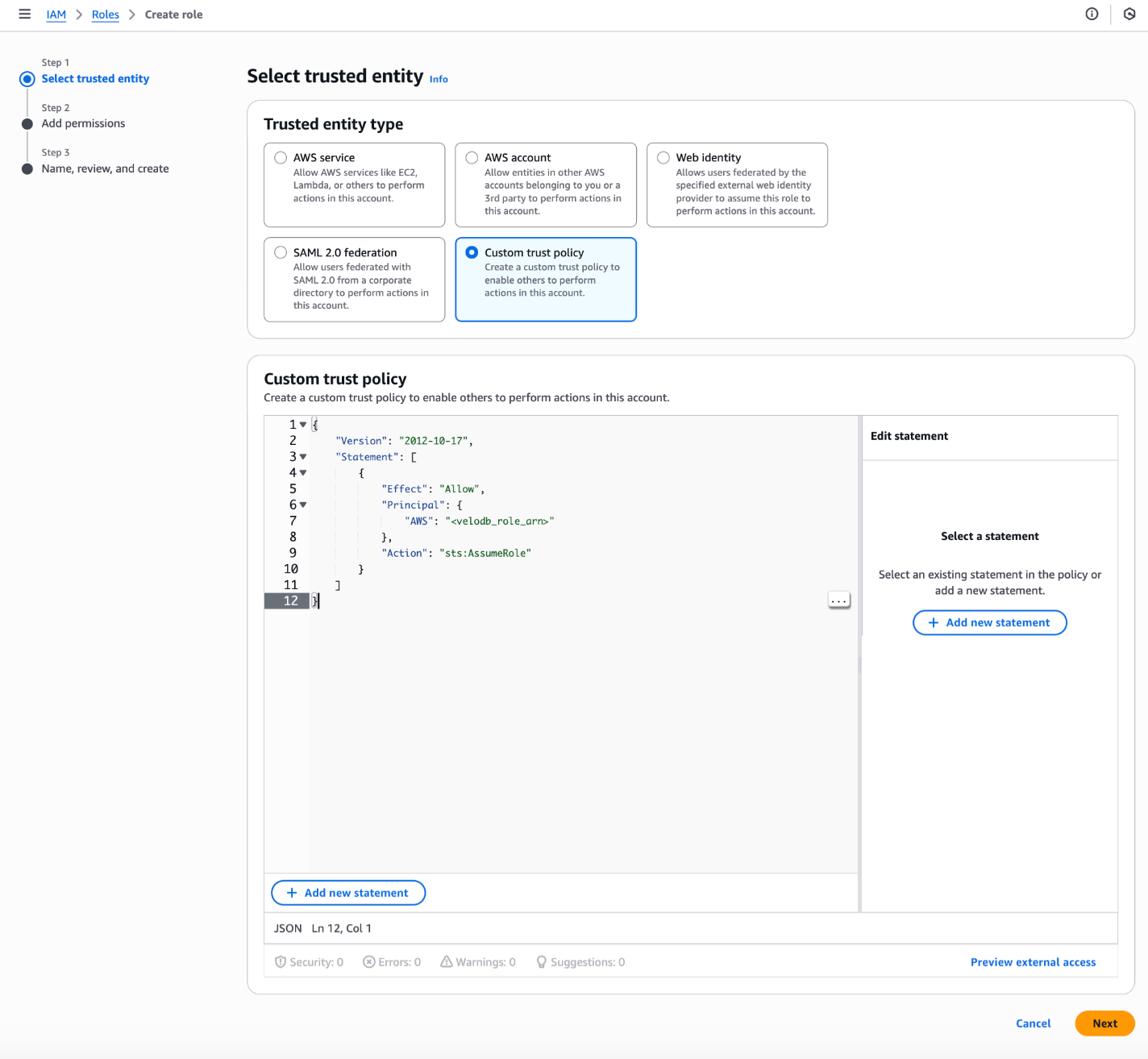 以下の信頼ポリシーの
以下の信頼ポリシーの<velodb_role_arn>を、VeloDBウェアハウスの実際のIAM Role ARNに置き換えてください。
{
"Version": "2012-10-17",
"Statement": [
{
"Effect": "Allow",
"Principal": {
"AWS": "<velodb_role_arn>"
},
"Action": "sts:AssumeRole"
}
]
}
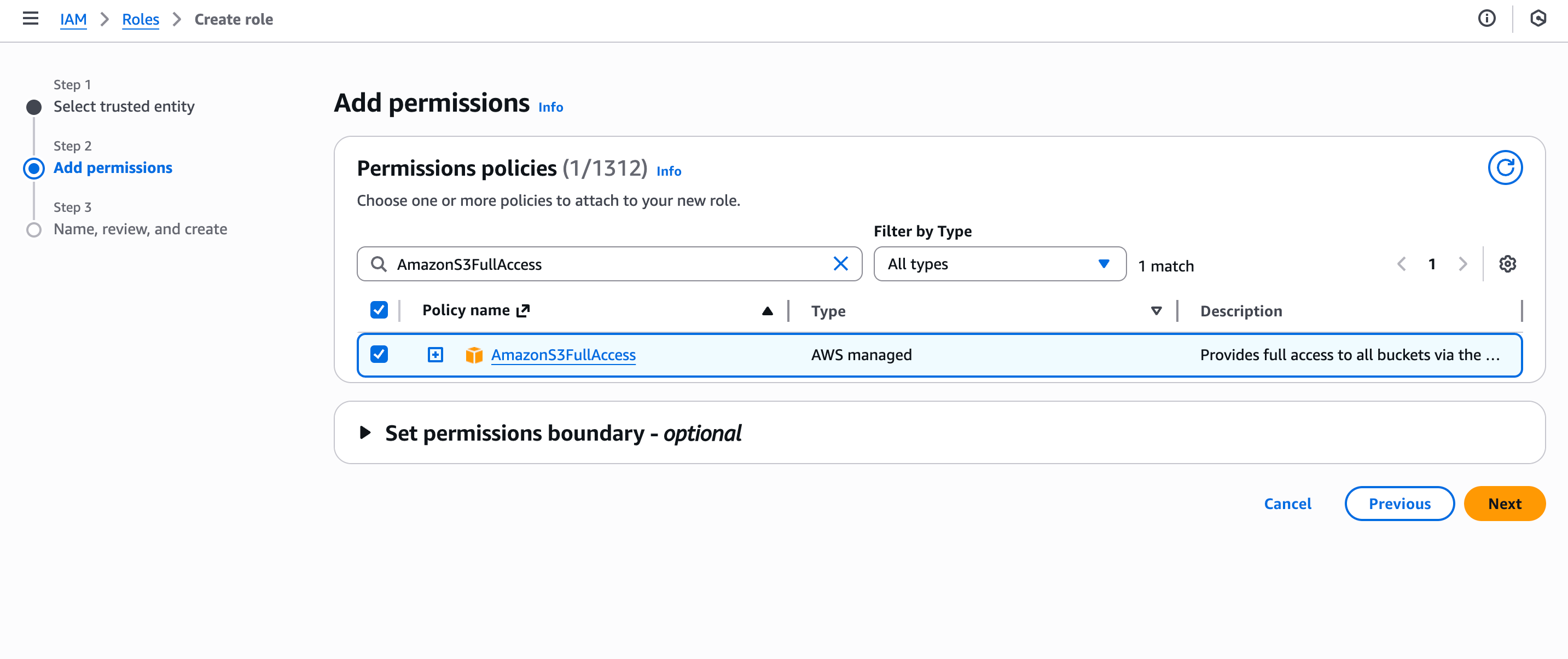
- ロールにアタッチしたいパーミッションポリシーを選択します。Nextボタンをクリックします。
- Role nameを設定し、Create roleボタンをクリックして完了します。
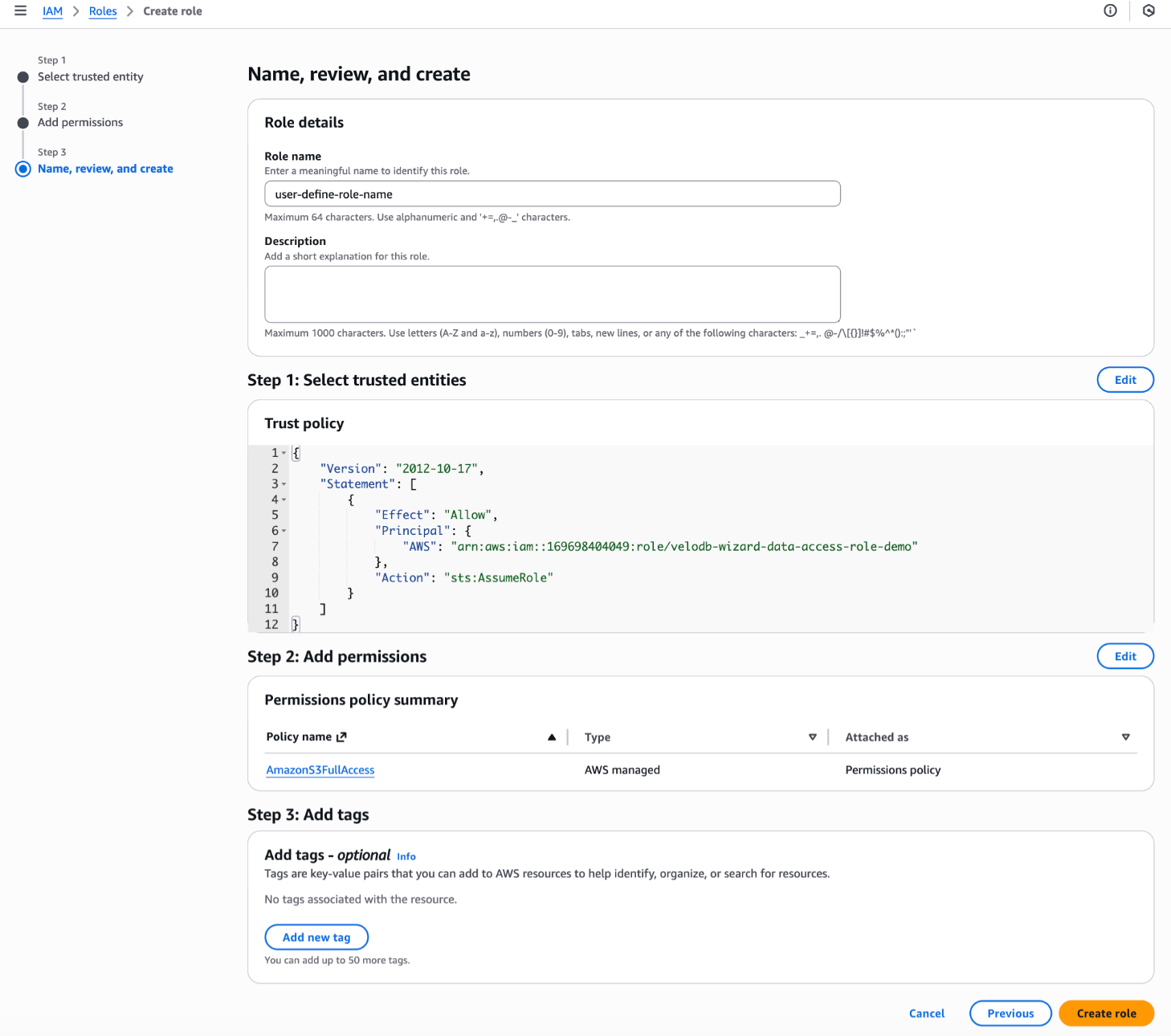
- ロールリスト内のロール名をクリックします。要約セクションからARNの値をコピーして、VeloDB Cloudで使用する値として提供します。