ランタイムフィルター
Runtime Filterは主にJoin Runtime FilterとTopN Runtime Filterの2つのタイプで構成されています。この記事では、これら2つのタイプのRuntime Filterの動作原理、使用ガイドライン、およびチューニング方法について詳しく紹介します。
Join Runtime Filter
Join Runtime Filter(以下、JRFと呼ぶ)は、Join条件を活用して、実行時データに基づいてJoinノードで動的にフィルターを生成する最適化技術です。この技術は、Join Probeのサイズを削減するだけでなく、データI/Oとネットワーク転送を効果的に最小化します。
原理
TPC-H Schemaに見られるものと類似したJoin操作を使用して、JRFの動作原理を説明しましょう。
データベースに2つのTableがあると仮定します:
-
OrdersTable:1億行のデータを含み、注文キー(
o_orderkey)、顧客キー(o_custkey)、およびその他の注文情報を記録しています。 -
CustomerTable:10万行のデータを含み、顧客キー(
c_custkey)、顧客の国(c_nation)、およびその他の顧客情報を記録しています。このTableは25カ国の顧客を記録しており、1カ国あたり約4,000人の顧客がいます。
中国の顧客からの注文数をカウントするために、クエリ文は以下のようになります:
select count(*)
from orders join customer on o_custkey = c_custkey
where c_nation = "china"
このクエリの実行計画の主要コンポーネントはJoinです。以下に示します:
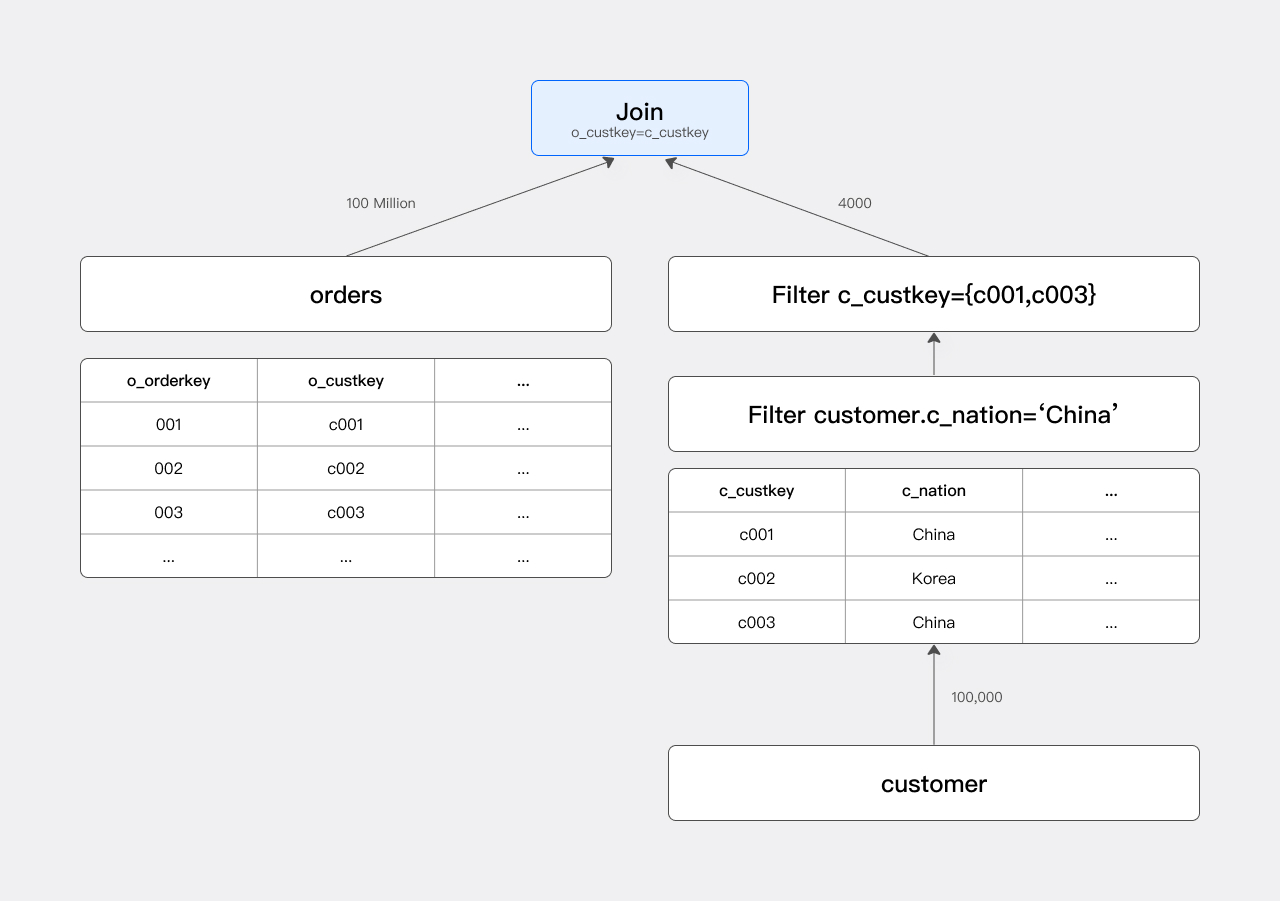
JRFなし:ScanノードはordersTableをスキャンし、1億行のデータを読み取ります。その後、JoinノードはこれらのA億行に対してHash Probeを実行し、Join結果を生成します。
1. 最適化
フィルタ条件 c_nation = 'china' は中国以外の全顧客を除外するため、customerTableの一部(約1/25)のみがJoinに関与します。後続のJoin条件 o_custkey = c_custkey を考慮すると、フィルタされた結果で選択された c_custkey の値に注目する必要があります。フィルタされた c_custkey の値を集合Aとします。以下のテキストでは、集合AはJoinに参加する c_custkey 集合を具体的に指すために使用します。
集合AをIN条件としてordersTableにプッシュダウンすると、ordersTableのScanノードは適切にordersをフィルタできます。これは、フィルタ条件 o_custkey IN (c001, c003) を追加することに似ています。
この最適化概念に基づいて、SQLは以下のように最適化できます:
select count(*)
from orders join customer on o_custkey = c_custkey
where c_nation = "china" and o_custkey in (c001, c003)
最適化された実行プランを以下に示します:
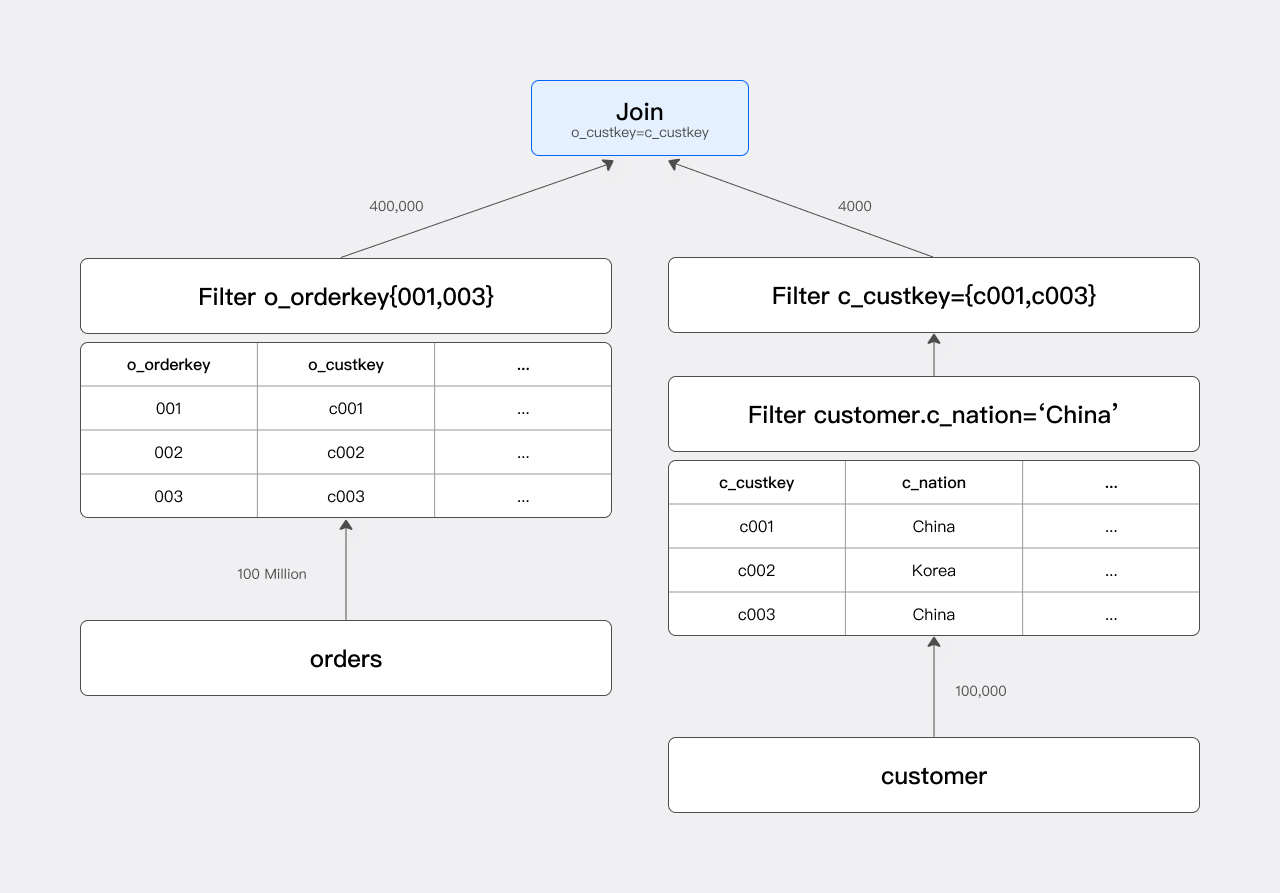
ordersTableにフィルタ条件を追加することで、Joinに参加する実際の注文数が1億件から40万件に削減され、クエリ速度が大幅に向上します。
2. 実装
上記で説明した最適化は重要ですが、オプティマイザは選択された実際のc_custkey値(セットA)を知らないため、最適化フェーズ中に固定のin-predicate filterオペレータを静的に生成することができません。
実際のアプリケーションでは、Joinノードで右側のデータを収集し、実行時にセットAを生成し、セットAをordersTableのScanノードにプッシュダウンします。通常、このJRFをRF(c_custkey -> [o_custkey])と表記します。
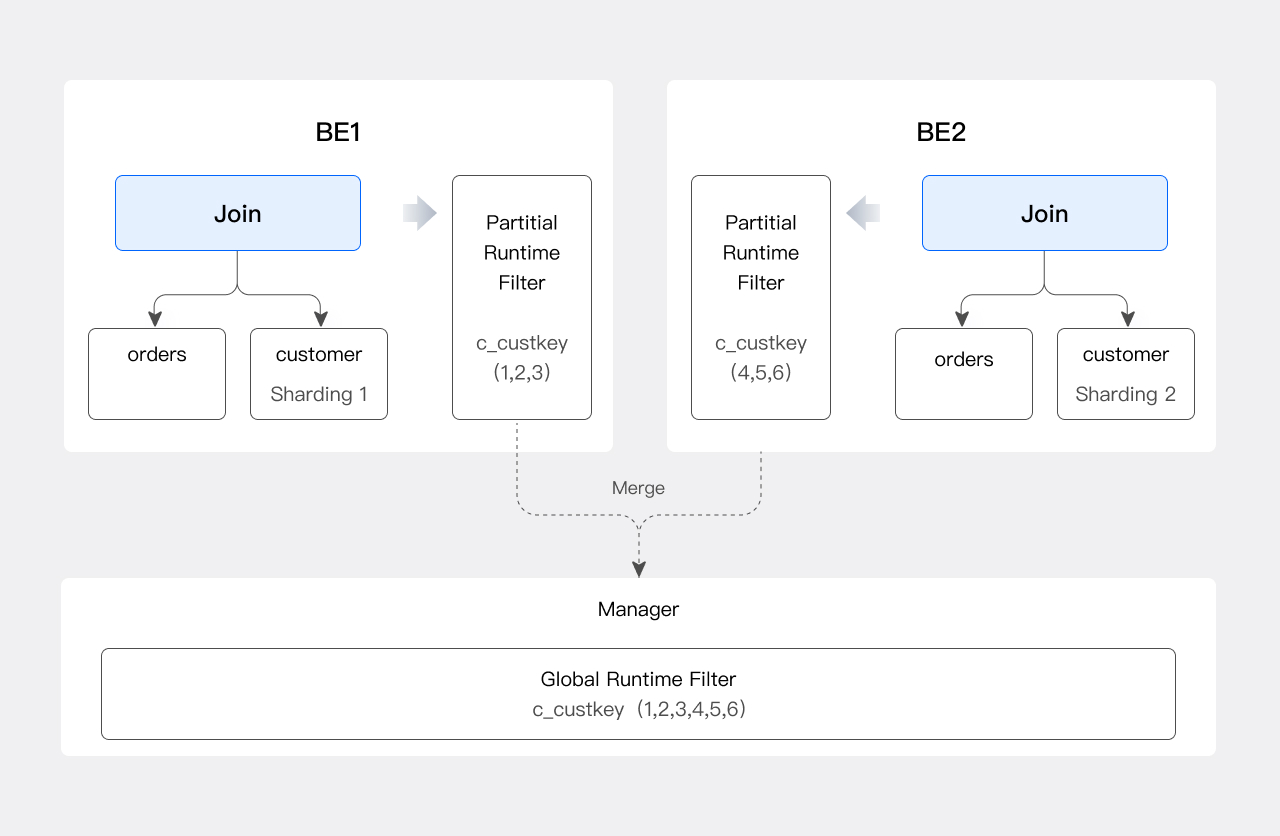
Dorisは分散データベースであるため、JRFは分散シナリオに対応するために追加のマージステップが必要です。例のJoinがShuffle Joinであると仮定すると、このJoinの複数のインスタンスがordersTableとcustomerTableの個々のシャードを処理します。その結果、各JoinインスタンスはセットAの一部のみを取得します。
Dorisの現在のバージョンでは、Runtime Filter Managerとして機能するノードを選択します。各Joinインスタンスは、そのシャード内のc_custkey値に基づいてPartial JRFを生成し、それをManagerに送信します。Managerはすべての Partial JRFを収集し、それらをGlobal JRFにマージして、Global JRFをordersTableのすべてのScanインスタンスに送信します。
Global JRFを生成するプロセスを以下に示します:
フィルタタイプ
JRF(Join Runtime Filter)の実装には様々なデータ構造を使用でき、それぞれ生成、マージ、送信、適用における効率が異なるため、異なるシナリオに適しています。
1. In Filter
JRFを実装する最もシンプルなアプローチは、In Filterを使用することです。前の例を用いると、In Filterを使用する場合、実行エンジンは左Tableに述語o_custkey in (...セットA内の要素のリスト...)を生成します。このIn filter条件は、ordersTableをフィルタリングするために適用できます。セットA内の要素数が少ない場合、In Filterは効率的です。
しかし、セットA内の要素数が多い場合、In Filterの使用は問題となります:
-
まず、In Filterの生成コストが高く、特にJRFマージが必要な場合はそうです。異なるデータパーティションに対応するJoinノードから収集された値には重複が含まれる可能性があります。例えば、
c_custkeyがTableの主キーでない場合、c001やc003のような値が複数回現れる可能性があり、時間のかかる重複除去プロセスが必要になります。 -
次に、セットAに多くの要素が含まれる場合、JoinノードとordersTableのScanノード間のデータ送信コストが大きくなります。
-
最後に、ordersTableのScanノードでIn述語を実行することも時間がかかります。
これらの要因を考慮して、Bloom Filterを導入します。
2. Bloom Filter
Bloom Filterに馴染みがない方のために説明すると、これは重ね合わされたハッシュTableのセットと考えることができます。フィルタリングにBloom Filter(またはハッシュTable)を使用することで、以下の特性を活用します:
-
セットAに基づいてハッシュTableTが生成されます。要素がハッシュTableTにない場合、その要素はセットAにないと確定的に結論できます。ただし、その逆は真ではありません。
したがって、
o_orderkeyがBloom Filterによってフィルタリングされた場合、Joinの右側に一致するc_custkeyがないと結論できます。しかし、ハッシュ衝突のため、一致するc_custkeyがない場合でも、一部のo_custkeyがBloom Filterを通過する可能性があります。Bloom Filterは精密なフィルタリングを実現できませんが、それでも一定レベルのフィルタリング効果を提供します。
-
ハッシュTable内のバケット数がフィルタリングの精度を決定します。バケット数が多いほど、Filterは大きくなり、より正確になりますが、生成、送信、使用における計算オーバーヘッドが増加するというコストがあります。
したがって、Bloom Filterのサイズは、フィルタリング効果と使用コストの間のバランスを取る必要があります。この目的のため、
RUNTIME_BLOOM_FILTER_MIN_SIZEとRUNTIME_BLOOM_FILTER_MAX_SIZEによって定義される、Bloom Filterのサイズの設定可能な範囲を設けています。
3. Min/Max Filter
Bloom Filterに加えて、Min-Max Filterも近似フィルタリングに使用できます。データカラムが順序付けられている場合、Min-Max Filterは優れたフィルタリング結果を達成できます。さらに、Min-Max Filterの生成、マージ、使用のコストは、In FilterやBloom Filterよりもはるかに低くなります。
非等価Joinの場合、In FilterとBloom Filterの両方が効果的でなくなりますが、Min-Max Filterは依然として機能します。前の例からクエリを修正して以下のようにするとします:
select count(*)
from orders join customer on o_custkey > c_custkey
where c_name = "China"
この場合、フィルタリングされたc_custkeyの最大値を選択し、それをnとして表記し、ordersTableのScanノードに渡すことができます。Scanノードはそれによりo_custkey > nの行のみを出力します。
Join Runtime Filterの確認
特定のクエリに対してどのJRF(Join Runtime Filters)が生成されたかを確認するには、explain、explain shape plan、またはexplain physical planコマンドを使用できます。
TPC-H Schemaを例として、これら3つのコマンドを使用してJRFを確認する方法を詳しく説明します。
select count(*) from orders join customer on o_custkey=c_custkey;
1. Explain
従来のExplain出力では、JRF情報は通常、以下の例に示すようにJoinノードとScanノードに表示されます。
4: VHASH JOIN(258)
| join op: INNER JOIN(PARTITIONED)[]
| equal join conjunct: (o_custkey[#10] = c_custkey[#0])
| runtime filters: RF000[bloom] <- c_custkey[#0] (150000000/134217728/16777216)
| cardinality=1,500,000,000
| vec output tuple id: 3
| output tuple id: 3
| vIntermediate tuple ids: 2
| hash output slot ids: 10
| final projections: o_custkey[#17]
| final project output tuple id: 3
| distribute expr lists: o_custkey[#10]
| distribute expr lists: c_custkey[#0]
|
|---1: VEXCHANGE
| offset: 0
| distribute expr lists: c_custkey[#0]
3: VEXCHANGE
| offset: 0
| distribute expr lists:
PLAN FRAGMENT 2
| PARTITION: HASH_PARTITIONED: o_orderkey[#8]
| HAS_COLO_PLAN_NODE: false
| STREAM DATA SINK
| EXCHANGE ID: 03
| HASH_PARTITIONED: o_custkey[#10]
2: VOlapScanNode(242)
| TABLE: regression_test_nereids_tpch_shape_sf1000_p0.orders(orders)
| PREAGGREGATION: ON
| runtime filters: RF000[bloom] -> o_custkey[#10]
| partitions=1/1 (orders)
| tablets=96/96, tabletList=54990,54992,54994 ...
| cardinality=0, avgRowSize=0.0, numNodes=1
| pushAggOp=NONE
-
Join Side:
runtime filters: RF000[bloom] <- c_custkey[#0] (150000000/134217728/16777216)これは、ID 000のBloom Filterが生成され、
c_custkeyを入力として使用してJRFを作成することを示しています。その後に続く3つの数値はBloom Filterサイズ計算に関連しており、現在のところは無視できます。 -
Scan Side:
runtime filters: RF000[bloom] -> o_custkey[#10]これは、JRF 000がordersTableのScanノードに適用され、
o_custkeyフィールドをフィルタリングすることを示しています。
2. Shape Planの説明
Explain Planシリーズでは、JRFの表示方法を示す例としてShape Planを使用します。
mysql> explain shape plan select count(*) from orders join customer on o_custkey=c_custkey where c_nationkey=5;
+--------------------------------------------------------------------------------------------------------------------------+
Explain String(Nereids Planner) |
+--------------------------------------------------------------------------------------------------------------------------+
PhysicalResultSink |
--hashAgg[GLOBAL] |
----PhysicalDistribute[DistributionSpecGather] |
------hashAgg[LOCAL] |
--------PhysicalProject |
----------hashJoin[INNER_JOIN shuffle] |
------------hashCondition=((orders.o_custkey=customer.c_custkey)) otherCondition=() buildRFs:RF0 c_custkey->[o_custkey] |
--------------PhysicalProject |
----------------Physical0lapScan[orders] apply RFs: RF0 |
--------------PhysicalProject |
----------------filter((customer.c_nationkey=5)) |
------------------Physical0lapScan[customer] |
+--------------------------------------------------------------------------------------------------------------------------+
11 rows in set (0.02 sec)
上記の通り:
-
Join Side:
build RFs: RF0 c_custkey -> [o_custkey]は、JRF 0がc_custkeyデータを使用して生成され、o_custkeyに適用されることを示しています。 -
Scan Side:
PhysicalOlapScan[orders] apply RFs: RF0は、ordersTableがJRF 0によってフィルタリングされることを示しています。
3. Profile
実際の実行中、BEはJRF使用の詳細をProfileに出力します(set enable_profile=trueが必要)。同じSQLクエリを例として使用し、ProfileでJRF実行の詳細を確認できます。
-
Join Side
HASH_JOIN_SINK_OPERATOR (id=3 , nereids_id=367):(ExecTime: 703.905us)
- JoinType: INNER_JOIN
。。。
- BuildRows: 617
。。。
- RuntimeFilterComputeTime: 70.741us
- RuntimeFilterInitTime: 10.882us
これはJoinのBuild側のプロファイルです。この例では、JRFの生成に617行の入力データで70.741us要しました。JRFのサイズとタイプはScan側に表示されています。
-
Scan Side
OLAP_SCAN_OPERATOR (id=2. nereids_id=351. table name = orders(orders)):(ExecTime: 13.32ms)
- RuntimeFilters: : RuntimeFilter: (id = 0, type = bloomfilter, need_local_merge: false, is_broadcast: true, build_bf_cardinality: false,
。。。
- RuntimeFilterInfo:
- filter id = 0 filtered: 714.761K (714761)
- filter id = 0 input: 747.862K (747862)
。。。
- WaitForRuntimeFilter: 6.317ms
RuntimeFilter: (id = 0, type = bloomfilter):
- Info: [IsPushDown = true, RuntimeFilterState = READY, HasRemoteTarget = false, HasLocalTarget = true, Ignored = false]
- RealRuntimeFilterType: bloomfilter
- BloomFilterSize: 1024
注意:
-
5-6行目では入力行数とフィルタ済み行数を示しています。フィルタ済み行数が多いほど、JRFの効果が高いことを示します。
-
10行目の
IsPushDown = trueは、JRFの計算がストレージ層にプッシュダウンされていることを示し、遅延マテリアライゼーションによってIOを削減するのに役立ちます。 -
10行目の
RuntimeFilterState = READYは、ScanノードがJRFを適用したかどうかを示します。JRFはtry-bestメカニズムを使用するため、JRFの生成に時間がかかりすぎる場合、Scanノードは待機期間後にデータのスキャンを開始し、フィルタされていないデータを出力する可能性があります。 -
12行目の
BloomFilterSize: 1024は、Bloom Filterのサイズをバイト単位で示しています。
チューニング
Join Runtime Filterのチューニングについて、ほとんどの場合、この機能は適応的であり、ユーザーが手動でチューニングする必要はありません。しかし、パフォーマンスを最適化するために行うことができるいくつかの調整があります。
1. JRFの有効化または無効化
セッション変数runtime_filter_modeはJRFが生成されるかどうかを制御します。
-
JRFを有効にする場合:
set runtime_filter_mode = GLOBAL -
JRFを無効にする場合:
set runtime_filter_mode = OFF
2. JRFタイプの設定
セッション変数runtime_filter_typeはJRFのタイプを制御し、以下を含みます:
-
IN(1) -
BLOOM(2) -
MIN_MAX(4) -
IN_OR_BLOOM(8)
IN_OR_BLOOM FilterはBEが実際のデータ行数に基づいてIN FilterまたはBLOOM Filterの生成を適応的に選択することを可能にします。
runtime_filter_typeを対応する列挙値の合計に設定することで、単一のJoin条件に対して複数のJRFタイプを生成できます。
例:
-
各Join条件に対して
BLOOMFilterとMIN_MAXFilterの両方を生成する場合:set runtime_filter_type = 6 -
バージョン2.1では、
runtime_filter_typeのデフォルト値は12で、MIN_MAXFilterとIN_OR_BLOOMFilterの両方を生成します。
括弧内の整数は、Runtime Filter Typesの列挙値を表します。
3. 待機時間の設定
前述のように、JRFはTry-bestメカニズムを使用し、ScanノードはJRFを待ってから開始します。Dorisは実行時の条件に基づいて待機時間を計算します。しかし、場合によっては、計算された待機時間が十分でない可能性があり、JRFが完全に効果的でなくなり、Scanノードが期待よりも多くの行を出力する可能性があります。Profileセクションで説明したように、ScanノードのProfileでRuntimeFilterState = falseの場合、ユーザーは手動でより長い待機時間を設定できます。
セッション変数runtime_filter_wait_time_msはScanノードがJRFを待機する待機時間を制御します。デフォルト値は1000ミリ秒です。
4. JRFのプルーニング
場合によっては、JRFがフィルタリングの利点を提供しない可能性があります。例えば、ordersTableとcustomerTableに主キー-外部キー関係があるが、customerTableにフィルタ条件がない場合、JRFへの入力はすべてのcustkeysになり、ordersTableのすべての行がJRFを通過することを可能にします。オプティマイザは列統計に基づいて効果のないJRFをプルーニングします。
セッション変数enable_runtime_filter_prune = true/falseはプルーニングが実行されるかどうかを制御します。デフォルト値はtrueです。
TopN Runtime Filter
原理
Dorisでは、データはブロックストリーミング方式で処理されます。したがって、SQL文にtopN演算子が含まれている場合、Dorisはすべての結果を計算するのではなく、代わりに動的フィルタを生成して早期にデータを事前フィルタリングします。
例として次のSQL文を考えてみます:
select o_orderkey from orders order by o_orderdate limit 5;
このSQL文の実行計画を以下に示します:
mysql> explain select o_orderkey from orders order by o_orderdate limit 5;
+-----------------------------------------------------+
| Explain String(Nereids Planner) |
+-----------------------------------------------------+
| PLAN FRAGMENT 0 |
| OUTPUT EXPRS: |
| o_orderkey[#11] |
| PARTITION: UNPARTITIONED |
| |
| HAS_COLO_PLAN_NODE: false |
| |
| VRESULT SINK |
| MYSQL_PROTOCAL |
| |
| 2:VMERGING-EXCHANGE |
| offset: 0 |
| limit: 5 |
| final projections: o_orderkey[#9] |
| final project output tuple id: 2 |
| distribute expr lists: |
| |
| PLAN FRAGMENT 1 |
| |
| PARTITION: HASH_PARTITIONED: O_ORDERKEY[#0] |
| |
| HAS_COLO_PLAN_NODE: false |
| |
| STREAM DATA SINK |
| EXCHANGE ID: 02 |
| UNPARTITIONED |
| |
| 1:VTOP-N(119) |
| | order by: o_orderdate[#10] ASC |
| | TOPN OPT |
| | offset: 0 |
| | limit: 5 |
| | distribute expr lists: O_ORDERKEY[#0] |
| | |
| 0:VOlapScanNode(113) |
| TABLE: tpch.orders(orders), PREAGGREGATION: ON |
| TOPN OPT:1 |
| partitions=1/1 (orders) |
| tablets=3/3, tabletList=135112,135114,135116 |
| cardinality=150000, avgRowSize=0.0, numNodes=1 |
| pushAggOp=NONE |
+-----------------------------------------------------+
41 rows in set (0.06 sec)
topn filterがない場合、scanノードはordersTableから各データブロックを順次読み取り、TopNノードに渡します。TopNノードはヒープソートを通じてordersTableから現在のトップ5行を維持します。
データブロックは通常約1024行を含むため、TopNノードは最初のデータブロックを処理した後、そのブロック内で5番目にランクされた行を特定できます。
このo_orderdateが1995-01-01であると仮定すると、scanノードは2番目のデータブロックを出力する際に1995-01-01をフィルター条件として使用し、o_orderdateが1995-01-01より大きい行をTopNノードに送信して追加処理する必要がなくなります。
この閾値は動的に更新されます。例えば、TopNノードが2番目のフィルタリングされたデータブロックを処理する際により小さいo_orderdateを発見した場合、最初の2つのデータブロックの中で5番目にランクされたo_orderdateに閾値を更新します。
TopN Runtime Filterの確認
Explainコマンドを使用して、オプティマイザーによって計画されたTopN Runtime Filterを確認できます。
1:VTOP-N(119)
| order by: o_orderdate[#10] ASC
| TOPN OPT
| offset: 0
| limit: 5
| distribute expr lists: O_ORDERKEY[#0]
|
0:VLapScanNode[113]
TABLE: regression_test_nereids_tpch_p0.(orders), PREAGGREGATION: ON
TOPN OPT: 1
partitions=1/1 (orders)
tablets=3/3, tabletList=135112,135114,135116
cardinality=150000, avgRowSize=0.0, numNodes=1
pushAggOp: NONE
上記の例に示すように:
-
TopNノードは
TOPN OPTを表示し、このTopNノードがTopN Runtime Filterを生成することを示しています。 -
ScanノードはどのTopNノードが使用するTopN Runtime Filterを生成するかを示します。例えば、この例では11行目で、
ordersTableのScanノードがTopNノード1によって生成されたRuntime Filterを使用することを示しており、プランではTOPN OPT: 1として表示されています。
分散データベースとして、DorisはTopNノードとScanノードが実際に実行される物理マシンを考慮します。BE間通信のコストが高いため、BEはTopN Runtime Filterを使用するかどうか、またどの程度使用するかを適応的に決定します。現在、TopNとScanが同じBE上に存在するBEレベルのTopN Runtime Filterを実装しています。これは、TopN Runtime Filterの閾値を更新するにはスレッド間通信のみが必要で、比較的低コストであるためです。
チューニング
セッション変数topn_filter_ratioは、TopN Runtime Filterを生成するかどうかを制御します。
SQLのlimit句で指定される行数が少ないほど、TopN Runtime Filterのフィルタリング効果が強くなります。そのため、デフォルトでは、Dorisはlimit数がTable内のデータの半分未満の場合のみ、対応するTopN Runtime Filterの生成を有効にします。
例えば、set topn_filter_ratio=0を設定すると、以下のクエリに対してTopN Runtime Filterの生成を防ぐことになります:
select o_orderkey from orders order by o_orderdate limit 20;