ベストプラクティス
データモデル
DorisはDUPLICATE KEYモデル、UNIQUE KEYモデル、AGGREGATE KEYモデルの3つのモデルでデータを整理します。
推奨事項
データモデルはTable作成時に決定され、不変であるため、最も適切なデータモデルを選択することが重要です。
- Duplicate Keyモデルは、任意の次元にわたるアドホッククエリに適しています。事前集約の利点を活用することはできませんが、集約モデルの制限にも制約されないため、列型ストレージの利点を活用できます(すべてのキー列を読む必要なく、関連する列のみを読み取る)。
- Aggregate Keyモデルは、事前集約により、集約クエリでスキャンするデータ量と計算ワークロードを大幅に削減できます。固定パターンのレポートクエリに特に適しています。ただし、このモデルはcount(*)クエリには適していません。また、Value列の集約方法が固定されているため、他のタイプの集約クエリを実行する際は、セマンティックな正確性に特に注意を払う必要があります。
- Unique Keyモデルは、一意の主キー制約が必要なシナリオ向けに設計されています。主キーの一意性を保証できます。欠点は、マテリアライゼーションと事前集約による利点を享受できないことです。集約クエリで高いパフォーマンス要件のあるユーザーには、Doris 1.2以降のUnique KeyモデルのMerge-on-Write機能の使用を推奨します。
- 部分列更新要件のあるユーザーは、以下のデータモデルから選択できます:
- Unique Keyモデル(Merge-on-Writeモード)
- Aggregate Keyモデル(REPLACE_IF_NOT_NULLによる集約)
DUPLICATE KEYモデル
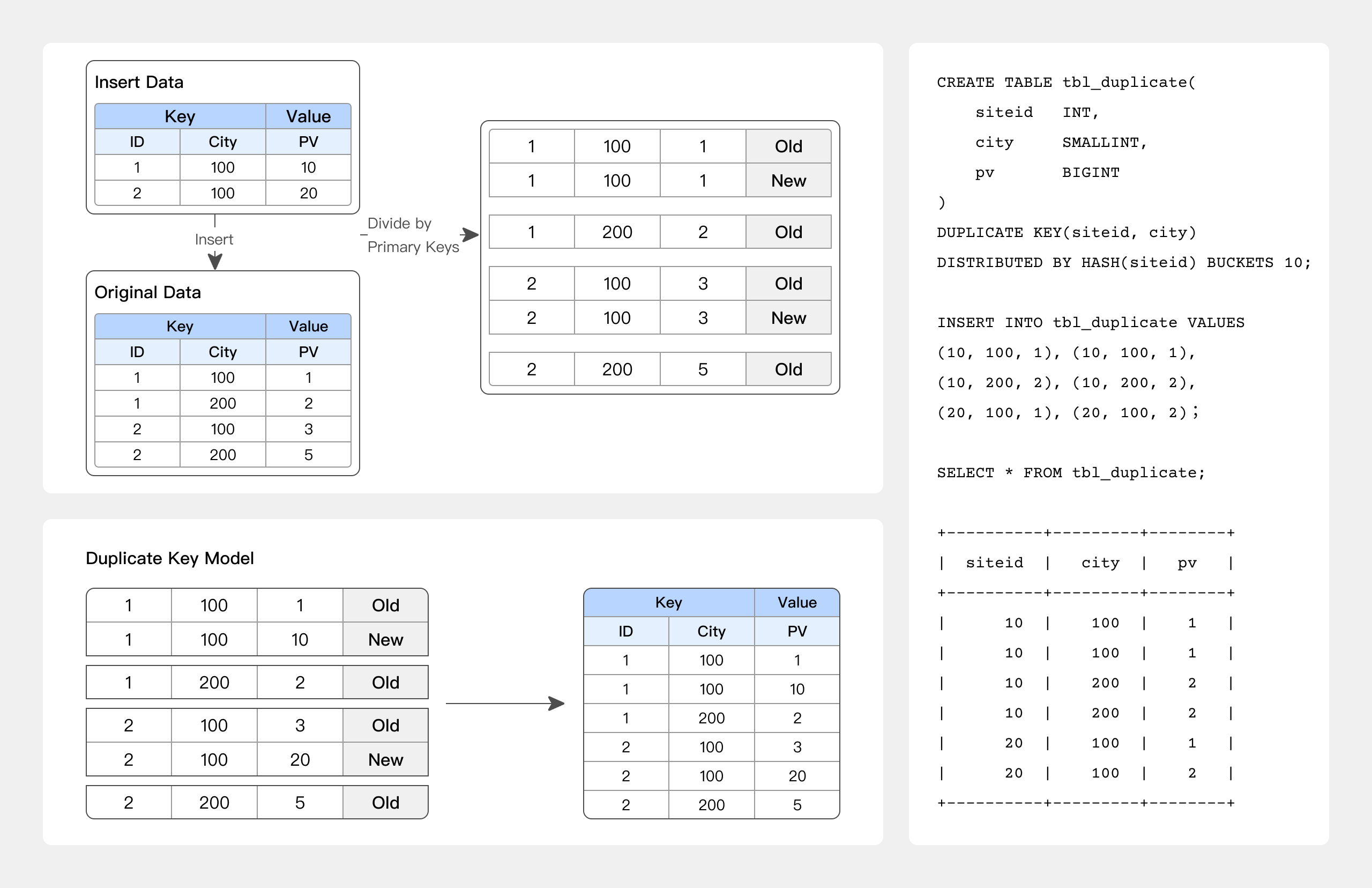
ソート列のみが指定された場合、同じキーを持つ行はマージされません。
これは、データが事前集約を必要としない分析ビジネスシナリオに適用できます:
- 生データの分析
- 新しいデータのみが追加されるログや時系列データの分析
ベストプラクティス
-- For example, log analysis that allows only appending new data with replicated KEYs.
CREATE TABLE session_data
(
visitorid SMALLINT,
sessionid BIGINT,
visittime DATETIME,
city CHAR(20),
province CHAR(20),
ip varchar(32),
brower CHAR(20),
url VARCHAR(1024)
)
DUPLICATE KEY(visitorid, sessionid) -- Used solely for specifying sorting columns, rows with the same KEY will not be merged.
DISTRIBUTED BY HASH(sessionid, visitorid) BUCKETS 10;
AGGREGATE KEY model
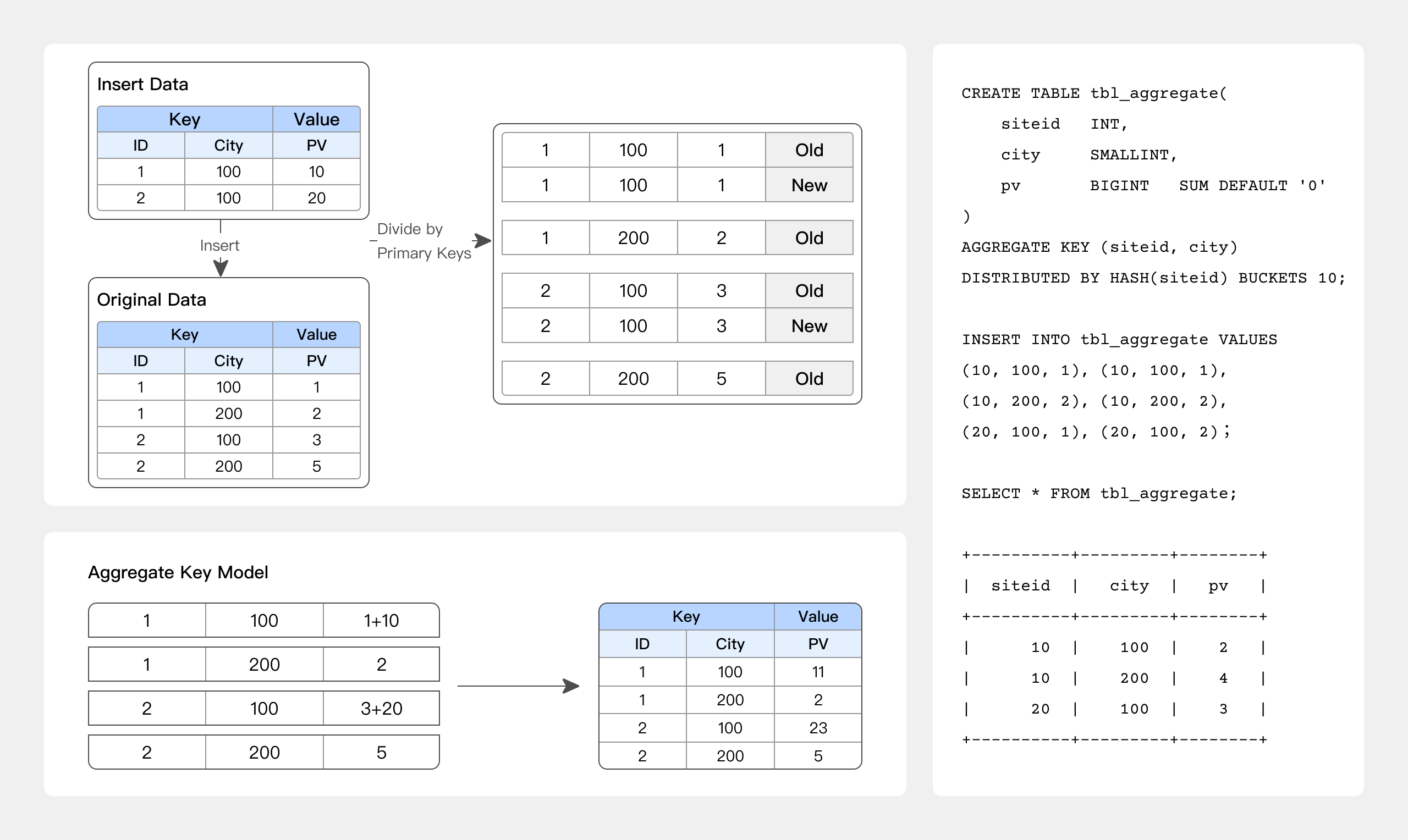
同じAGGREGATE KEYを持つ古いレコードと新しいレコードは集約されます。現在サポートされている集約方法は以下の通りです:
- SUM: 複数行の値を累積して合計を計算します;
- REPLACE: 以前にインポートされた行の値を次のバッチデータからの値で置き換えます;
- MAX: 最大値を保持します;
- MIN: 最小値を保持します;
- REPLACE_IF_NOT_NULL: null以外の値を置き換えます。REPLACEとは異なり、null値は置き換えません;
- HLL_UNION: HyperLogLogアルゴリズムを使用してHLL型の列を集約します;
- BITMAP_UNION: bitmapユニオン集約を使用してBITMAP型の列を集約します;
これは以下のようなレポーティングや多次元分析シナリオに適しています:
- Webサイトのトラフィック分析
- データレポートの多次元分析
ベストプラクティス
-- Example of website traffic analysis
CREATE TABLE site_visit
(
siteid INT,
city SMALLINT,
username VARCHAR(32),
pv BIGINT SUM DEFAULT '0' -- PV caculation
)
AGGREGATE KEY(siteid, city, username) -- Rows with the same KEY will be merged, and non-key columns will be aggregated based on the specified aggregation function.
DISTRIBUTED BY HASH(siteid) BUCKETS 10;
UNIQUE KEY モデル
新しいレコードは、同じ UNIQUE KEY を持つ古いレコードを置き換えます。Doris 1.2 以前では、UNIQUE KEY モデルは AGGREGATE KEY モデルの REPLACE 集約と同じ方法で実装されていました。しかし、Doris 1.2 以降、UNIQUE KEY モデルに Merge-on-Write 実装を導入し、集約クエリのパフォーマンスを向上させています。
これは以下のような更新が必要な分析ビジネスシナリオに適しています:
- 重複排除された注文分析
- 挿入、更新、削除のリアルタイム同期
ベストプラクティス
-- Example of deduplicated order analysis
CREATE TABLE sales_order
(
orderid BIGINT,
status TINYINT,
username VARCHAR(32),
amount BIGINT DEFAULT '0'
)
UNIQUE KEY(orderid) -- Rows of the same KEY will be merged
DISTRIBUTED BY HASH(orderid) BUCKETS 10;
Index
Indexは、データの高速なフィルタリングと検索を促進できます。現在、Dorisは2つのタイプのIndexをサポートしています:
- 内蔵スマートIndex(prefix indexとZoneMap indexを含む)
- ユーザー作成のセカンダリIndex(inverted index、BloomFilter index、Ngram BloomFilter index、Bitmap indexを含む)
Prefix index
Prefix indexは、Aggregate、Unique、Duplicateデータモデルの内蔵Indexです。基盤となるデータストレージは、それぞれのTable作成ステートメントでAGGREGATE KEY、UNIQUE KEY、またはDUPLICATE KEYとして指定された列に基づいてソートされ、保存されます。ソートされたデータの上に構築されたPrefix indexは、指定されたprefix列に基づく高速なデータクエリを可能にします。
Prefix indexはスパースIndexであり、キーが存在する正確な行を特定することはできません。代わりに、キーが存在する可能性のある範囲を大まかに特定し、その後バイナリ検索アルゴリズムを使用してキーの位置を正確に特定します。
推奨事項
- Table作成時、正しい列順序はクエリ効率を大幅に向上させることができます。
- 列順序はTable作成時に指定されるため、Tableは1つのタイプのprefix indexのみを持つことができます。ただし、これはprefix indexのない列に基づくクエリには十分効率的でない場合があります。このような場合、ユーザーはマテリアライズドビューを作成して列順序を調整できます。
- Prefix indexの最初のフィールドは、常に最も長いクエリ条件のフィールドであり、高カーディナリティフィールドである必要があります。
- バケッティングフィールド:比較的均等なデータ分散を持ち、頻繁に使用される、できれば高カーディナリティフィールドである必要があります。
- Int(4) + Int(4) + varchar(50):prefix indexの長さは28のみです。
- Int(4) + varchar(50) + Int(4):prefix indexの長さは24のみです。
- varchar(10) + varchar(50):prefix indexの長さは30のみです。
- Prefix index(36文字):最初のフィールドが最高のクエリパフォーマンスを提供します。varcharフィールドが遭遇した場合、prefix indexは自動的に最初の20文字に切り詰められます。
- 可能であれば、最も頻繁に使用されるクエリフィールドをprefix indexに含めてください。そうでなければ、それらをバケッティングフィールドとして指定してください。
- Dorisはprefix indexの最初の36バイトのみを利用できるため、prefix index内のフィールド長はできるだけ明示的である必要があります。
- データ範囲のパーティショニング、バケッティング、prefix index戦略の設計が困難な場合は、加速のためにinverted indexの導入を検討してください。
ZoneMap index
ZoneMap indexは、カラムナストレージ形式で列ごとに自動的に維持されるIndex情報です。Min/Max値やNull値の数などの情報が含まれます。データクエリ時に、ZoneMap indexは範囲条件を使用してフィルタリングされたフィールドに基づいて、スキャンするデータ範囲を選択するために利用されます。
例えば、以下のクエリステートメントで「age」フィールドをフィルタリングする場合:
SELECT * FROM table WHERE age > 0 and age < 51;
Short Key Indexがヒットしない場合、ZoneMap indexを使用して「age」フィールドのクエリ条件に基づいてスキャンする必要があるデータ範囲(「ordinary」範囲として知られる)を決定します。これにより、スキャンが必要なページ数が削減されます。
Inverted index
Dorisはバージョン2.0.0からinverted indexをサポートしています。Inverted indexはテキストデータの全文検索や、通常の数値型および日付型での範囲クエリに使用できます。大量のデータから条件に一致する行を高速にフィルタリングすることが可能になります。
Best practice
-- Inverted index can be specified during table creation or added later. This is an example of specifying it during table creation:
CREATE TABLE table_name
(
columns_difinition,
INDEX idx_name1(column_name1) USING INVERTED [PROPERTIES("parser" = "english|unicode|chinese")] [COMMENT 'your comment']
INDEX idx_name2(column_name2) USING INVERTED [PROPERTIES("parser" = "english|unicode|chinese")] [COMMENT 'your comment']
INDEX idx_name3(column_name3) USING INVERTED [PROPERTIES("parser" = "chinese", "parser_mode" = "fine_grained|coarse_grained")] [COMMENT 'your comment']
INDEX idx_name4(column_name4) USING INVERTED [PROPERTIES("parser" = "english|unicode|chinese", "support_phrase" = "true|false")] [COMMENT 'your comment']
INDEX idx_name5(column_name4) USING INVERTED [PROPERTIES("char_filter_type" = "char_replace", "char_filter_pattern" = "._"), "char_filter_replacement" = " "] [COMMENT 'your comment']
INDEX idx_name5(column_name4) USING INVERTED [PROPERTIES("char_filter_type" = "char_replace", "char_filter_pattern" = "._")] [COMMENT 'your comment']
)
table_properties;
-- Example: keyword matching in full-text searches, implemented by MATCH_ANY MATCH_ALL
SELECT * FROM table_name WHERE column_name MATCH_ANY | MATCH_ALL 'keyword1 ...';
推奨事項
- データ範囲に対するパーティショニング、バケッティング、プレフィックスインデックス戦略の設計が困難な場合は、高速化のためにinverted indexの導入を検討してください。
制限事項
- データモデルによってinverted indexに対する制限が異なります。
- Aggregate KEYモデル: Keyカラムに対してのみinverted indexが許可されます
- Unique KEYモデル: Merge-on-Writeを有効にした後、任意のカラムにinverted indexが許可されます
- Duplicate KEYモデル: 任意のカラムにinverted indexが許可されます
BloomFilter index
DorisはBloomFilter indexを値の識別性が高いフィールドに追加することをサポートしており、高いカーディナリティを持つカラムでの等価クエリを含むシナリオに適しています。
ベストプラクティス
-- Example: add "bloom_filter_columns"="k1,k2,k3" in the PROPERTIES of the table creation statement.
-- To create BloomFilter index for saler_id and category_id in the table.
CREATE TABLE IF NOT EXISTS sale_detail_bloom (
sale_date date NOT NULL COMMENT "Sale data",
customer_id int NOT NULL COMMENT "Customer ID",
saler_id int NOT NULL COMMENT "Saler ID",
sku_id int NOT NULL COMMENT "SKU ID",
category_id int NOT NULL COMMENT "Category ID",
sale_count int NOT NULL COMMENT "Sale count",
sale_price DECIMAL(12,2) NOT NULL COMMENT "Sale price",
sale_amt DECIMAL(20,2) COMMENT "Sale amount"
)
Duplicate KEY(sale_date, customer_id,saler_id,sku_id,category_id)
DISTRIBUTED BY HASH(saler_id) BUCKETS 10
PROPERTIES (
"bloom_filter_columns"="saler_id,category_id"
);
制限事項
- BloomFilterインデックスは、Tinyint、Float、Doubleタイプの列ではサポートされていません。
- BloomFilterインデックスは、"in"と"="演算子を使用したフィルタリングのみを高速化できます。
- BloomFilterインデックスは、"in"または"="演算子を含むクエリ条件で、高カーディナリティ列(5000以上)に構築する必要があります。
- BloomFilterインデックスは、非プレフィックスフィルタリングに適しています。
- クエリは列内の高頻度値に基づいてフィルタリングし、フィルタリング条件は主に"in"と"="です。
- Bitmapインデックスとは異なり、BloomFilterインデックスはUserIDなどの高カーディナリティ列に適しています。「性別」のような低カーディナリティ列に作成した場合、各ブロックにはほぼすべての値が含まれるため、BloomFilterインデックスは意味がなくなります。
- データカーディナリティが全体範囲の約半分程度のケースに適しています。
- ID番号など、等価(=)クエリを使用する高カーディナリティ列では、BloomFilterインデックスを使用することでパフォーマンスを大幅に向上させることができます。
Ngram BloomFilterインデックス
2.0.0以降、Dorisは"LIKE"クエリのパフォーマンスを向上させるためにNGram BloomFilterインデックスを導入しました。
ベストプラクティス
-- Example of creating NGram BloomFilter index in table creation statement
CREATE TABLE `nb_table` (
`siteid` int(11) NULL DEFAULT "10" COMMENT "",
`citycode` smallint(6) NULL COMMENT "",
`username` varchar(32) NULL DEFAULT "" COMMENT "",
INDEX idx_ngrambf (`username`) USING NGRAM_BF PROPERTIES("gram_size"="3", "bf_size"="256") COMMENT 'username ngram_bf index'
) ENGINE=OLAP
AGGREGATE KEY(`siteid`, `citycode`, `username`) COMMENT "OLAP"
DISTRIBUTED BY HASH(`siteid`) BUCKETS 10;
-- PROPERTIES("gram_size"="3", "bf_size"="256"), representing the number of grams and the byte size of the BloomFilter
-- The number of grams is determined according to the query cases and is typically set to the length of the majority of query strings. The number of bytes in the BloomFilter can be determined after testing. Generally, a larger number of bytes leads to better filtering results, and it is recommended to start with a value of 256 for testing and evaluating the effectiveness. However, it's important to note that a larger number of bytes also increases the storage cost of the index.
-- With high data cardinality, there is no need to set a large BloomFilter size. Conversely, with low data cardinality, increase the BloomFilter size to enhance filtering efficiency.
制限事項
- NGram BloomFilter インデックスは文字列カラムのみサポートします。
- NGram BloomFilter インデックスと BloomFilter インデックスは相互排他的であり、同じカラムに対してはどちらか一方のみ設定できます。
- NGram と BloomFilter のサイズは、実際の状況に基づいて最適化できます。NGram サイズが比較的小さい場合は、BloomFilter サイズを増やすことができます。
- 数十億規模以上のデータにおいて、あいまい検索が必要な場合は、転置インデックスまたは NGram BloomFilter の使用を推奨します。
Bitmap インデックス
データクエリを高速化するため、Doris はユーザーが特定のフィールドに Bitmap インデックスを追加することをサポートしています。これは、カーディナリティが低いカラムに対する等価クエリや範囲クエリを含むシナリオに適しています。
ベストプラクティス
-- Example: create Bitmap index for siteid on bitmap_table
CREATE INDEX [IF NOT EXISTS] bitmap_index_name ON
bitmap_table (siteid)
USING BITMAP COMMENT 'bitmap_siteid';
制限事項
- Bitmapインデックスは単一カラムにのみ作成できます。
- Bitmapインデックスは
DuplicateおよびUniqueKeyモデルのすべてのカラム、ならびにAggregateKeyモデルのkeyカラムに適用できます。 - Bitmapインデックスは以下のデータタイプをサポートします:
TINYINTSMALLINTINTBIGINTCHARVARCHARDATEDATETIMELARGEINTDECIMALBOOL
- BitmapインデックスはSegment V2でのみ有効です。Bitmapインデックスを持つTableのストレージフォーマットは、デフォルトで自動的にV2フォーマットに変換されます。
- Bitmapインデックスは特定のカーディナリティ範囲内で構築する必要があります。極端に高いまたは低いカーディナリティのケースには適していません。
- カーディナリティが100から100,000の間のカラム(職業フィールドや都市フィールドなど)に推奨されます。重複率が高すぎる場合、他の種類のインデックスと比較してBitmapインデックスを構築する大きな利点はありません。重複率が低すぎる場合、Bitmapインデックスは空間効率とパフォーマンスを大幅に低下させる可能性があります。count、OR、AND操作などの特定のタイプのクエリでは、ビット演算のみが必要です。
- Bitmapインデックスは直交クエリにより適しています。
フィールドタイプ
DorisはBITMAPを使用した精密重複除去、HLLを使用したファジー重複除去、ARRAY/MAP/JSONなどの半構造化データタイプ、および一般的な数値、文字列、時刻タイプを含む様々なフィールドタイプをサポートします。
推奨事項
- VARCHAR
- 長さ範囲が1-65533バイトの可変長文字列。UTF-8エンコーディングで格納され、英語文字は通常1バイトを占有します。
- varchar(255)とvarchar(65533)のパフォーマンス差について、しばしば誤解があります。両方のケースで格納されるデータが同じであれば、パフォーマンスも同じです。Tableを作成する際、フィールドの最大長が不明な場合は、文字列が長すぎることによるインポートエラーを防ぐためにvarchar(65533)の使用を推奨します。
- STRING
- デフォルトサイズが1048576バイト(1MB)の可変長文字列で、2147483643バイト(2GB)まで増やすことができます。UTF-8エンコーディングで格納され、英語文字は通常1バイトを占有します。
- valueカラムでのみ使用でき、keyカラムやパーティショニングカラムでは使用できません。
- 大きなテキストコンテンツの格納に適しています。ただし、そのような要件が存在しない場合は、VARCHARの使用を推奨します。STRINGカラムはkeyカラムやパーティショニングカラムで使用できないという制限があります。
- 数値フィールド:必要な精度に基づいて適切なデータタイプを選択してください。これについて特別な制限はありません。
- 時刻フィールド:高精度要件(ミリ秒まで正確なタイムスタンプ)がある場合は、datetime(6)の使用を指定する必要があります。そうでなければ、そのようなタイムスタンプはデフォルトでサポートされません。
- JSONデータの格納には、string型の代わりにJSONデータタイプの使用を推奨します。
Table作成
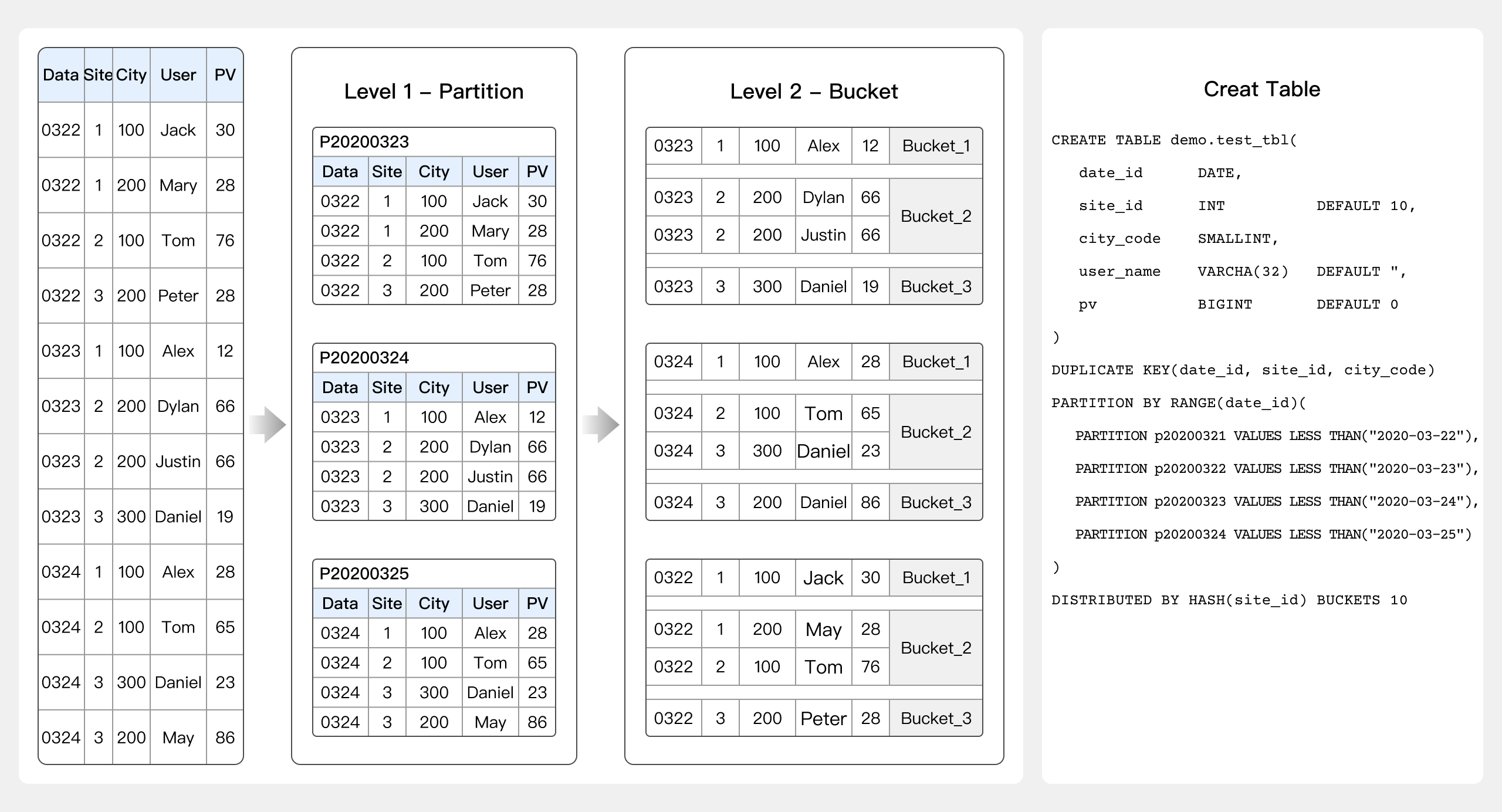
Table作成における考慮事項には、データモデル、インデックス、フィールドタイプに加えて、データパーティションとバケットの設定が含まれます。
ベストプラクティス
-- Take Merge-on-Write tables in the Unique Key model as an example:
-- Merge-on-Write in the Unique Key model is implemented in a different way from the Aggregate Key model. The performance of it is similar to that on the Duplicate Key model.
-- In use cases requiring primary key constraints, the Aggregate Key model can deliver much better query performance compared to the Duplicate Key model, especially in aggregate queries and queries that involve filtering a large amount of data using indexes.
-- For non-partitioned tables
CREATE TABLE IF NOT EXISTS tbl_unique_merge_on_write
(
`user_id` LARGEINT NOT NULL COMMENT "Use ID",
`username` VARCHAR(50) NOT NULL COMMENT "Username",
`register_time` DATE COMMENT "User registration time",
`city` VARCHAR(20) COMMENT "User city",
`age` SMALLINT COMMENT "User age",
`sex` TINYINT COMMENT "User gender",
`phone` LARGEINT COMMENT "User phone number",
`address` VARCHAR(500) COMMENT "User address"
)
UNIQUE KEY(`user_id`, `username`)
-- Data volume of 3~5G
DISTRIBUTED BY HASH(`user_id`) BUCKETS 10
PROPERTIES (
-- In Doris 1.2.0, as a new feature, Merge-on-Write is disabled by default. Users can enable it by adding the following property.
"enable_unique_key_merge_on_write" = "true"
);
-- For partitioned tables
CREATE TABLE IF NOT EXISTS tbl_unique_merge_on_write_p
(
`user_id` LARGEINT NOT NULL COMMENT "Use ID",
`username` VARCHAR(50) NOT NULL COMMENT "Username",
`register_time` DATE COMMENT "User registration time",
`city` VARCHAR(20) COMMENT "User city",
`age` SMALLINT COMMENT "User age",
`sex` TINYINT COMMENT "User gender",
`phone` LARGEINT COMMENT "User phone number",
`address` VARCHAR(500) COMMENT "User address"
)
UNIQUE KEY(`user_id`, `username`, `register_time`)
PARTITION BY RANGE(`register_time`) (
PARTITION p00010101_1899 VALUES [('0001-01-01'), ('1900-01-01')),
PARTITION p19000101 VALUES [('1900-01-01'), ('1900-01-02')),
PARTITION p19000102 VALUES [('1900-01-02'), ('1900-01-03')),
PARTITION p19000103 VALUES [('1900-01-03'), ('1900-01-04')),
PARTITION p19000104_1999 VALUES [('1900-01-04'), ('2000-01-01')),
FROM ("2000-01-01") TO ("2022-01-01") INTERVAL 1 YEAR,
PARTITION p30001231 VALUES [('3000-12-31'), ('3001-01-01')),
PARTITION p99991231 VALUES [('9999-12-31'), (MAXVALUE))
)
-- Data volume of 3~5G
DISTRIBUTED BY HASH(`user_id`) BUCKETS 10
PROPERTIES (
-- In Doris 1.2.0, as a new feature, Merge-on-Write is disabled by default. Users can enable it by adding the following property.
"enable_unique_key_merge_on_write" = "true",
-- The unit for dynamic partition scheduling can be specified as HOUR, DAY, WEEK, MONTH, or YEAR.
"dynamic_partition.time_unit" = "MONTH",
-- The starting offset for dynamic partitioning is specified as a negative number. Depending on the value of the time_unit, it uses the current day (week/month) as the reference point, partitions prior to this offset will be deleted (TTL). If not specified, the default value is -2147483648, indicating that historical partitions will not be deleted.
"dynamic_partition.start" = "-3000",
-- The ending offset for dynamic partitioning is specified as a positive number. Depending on the value of the time_unit, it uses the current day (week/month) as the reference point. Create the corresponding partitions of the specified range in advance.
"dynamic_partition.end" = "10",
-- The prefix for names of the dynamically created partitions (required).
"dynamic_partition.prefix" = "p",
-- The number of buckets corresponding to the dynamically created partitions.
"dynamic_partition.buckets" = "10",
"dynamic_partition.enable" = "true",
-- The following is the number of replicas corresponding to dynamically created partitions. If not specified, the default value will be the replication factor specified when creating the table, which is typically 3.
"dynamic_partition.replication_num" = "3",
"replication_num" = "3"
);
-- View existing partitions
-- The actual number of created partitions is determined by a combination of dynamic_partition.start, dynamic_partition.end, and the settings of PARTITION BY RANGE.
show partitions from tbl_unique_merge_on_write_p;
制限事項
-
UTF-8のみがサポートされているため、データベースの文字セットはUTF-8として指定する必要があります。
-
Tableのレプリケーション係数は3である必要があります(指定されていない場合、デフォルトで3になります)。
-
個々のtabletのデータ量(Tablet Count = パーティション Count * バケット Count * Replication Factor)は理論的に上限や下限はありませんが、小さなTable(数百メガバイトから1ギガバイトの範囲)を除き、1 GBから10 GBの範囲内に収まるように確保する必要があります:
- 個々のtabletのデータ量が小さすぎると、データ集約のパフォーマンスが低下し、メタデータ管理のオーバーヘッドが増加する可能性があります。
- データ量が大きすぎると、レプリカの移行や同期が阻害され、スキーマ変更やマテリアライゼーション操作のコストが増加します(これらの操作はtabletの粒度で再試行されます)。
-
5億レコードを超えるデータについては、パーティショニングとバケッティング戦略を実装する必要があります:
- バケッティングの推奨事項:
- 大きなTableの場合、各tabletは1 GBから10 GBの範囲内にして、過度に小さなファイルの生成を防ぎます。
- 約100メガバイトのディメンションTableの場合、tabletの数を3から5の範囲内に制御します。これにより、過度に小さなファイルを生成することなく、一定レベルの並行性を確保します。
- パーティショニングが実現不可能で、動的な時間ベースのパーティショニングの可能性なしにデータが急速に増加する場合、データ保持期間(180日)に基づいてデータ量に対応するためにバケット数を増やすことが推奨されます。各バケットのサイズを1 GBから10 GBの間に保つことが依然として推奨されます。
- バケッティングフィールドにsaltingを適用し、bucket pruning機能を活用するためにクエリに同じsalting戦略を使用します。
- ランダムバケッティング:
- OLAPTableに更新が必要なフィールドがない場合、データバケッティングモードをRANDOMに設定することで、深刻なデータスキューを回避できます。データ取り込み時に、各バッチのデータは書き込み用にランダムにtabletに割り当てられます。
- TableのバケッティングモードがRANDOMに設定されている場合、バケッティングカラムがないため、Tableのクエリではバケッティングカラムの値に基づいて特定のバケットをクエリするのではなく、ヒットしたパーティション内のすべてのバケットをスキャンします。この設定は、高並行性のポイントクエリではなく、全体的な集約・分析クエリに適しています。
- OLAPTableのデータがランダムに分散している場合、データ取り込み時に
load_to_single_tabletパラメータをtrueに設定することで、各タスクが単一のtabletに書き込むことができます。これにより、大規模データ取り込み時の並行性とスループットが向上します。また、データ取り込みとコンパクションによる書き込み増幅を減らし、クラスタの安定性を確保できます。
- 成長が遅いディメンションTableは、単一のパーティションを使用し、一般的に使用されるクエリ条件に基づいてバケッティングを適用できます(バケッティングフィールドのデータ分散が比較的均等である場合)。
- ファクトTable。
- バケッティングの推奨事項:
-
大量の履歴パーティションデータがあるが、履歴データが比較的小さい、不均衡、またはクエリ頻度が低いシナリオでは、以下のアプローチを使用してデータを特別なパーティションに配置できます。小さなサイズの履歴データ用に履歴パーティション(例:年次パーティション、月次パーティション)を作成できます。例えば、データ
FROM ("2000-01-01") TO ("2022-01-01") INTERVAL 1 YEARの履歴パーティションを作成できます:
PARTITION p00010101_1899 VALUES [('0001-01-01'), ('1900-01-01')),
PARTITION p19000101 VALUES [('1900-01-01'), ('1900-01-02')),
...
PARTITION p19000104_1999 VALUES [('1900-01-04'), ('2000-01-01')),
FROM ("2000-01-01") TO ("2022-01-01") INTERVAL 1 YEAR,
PARTITION p30001231 VALUES [('3000-12-31'), ('3001-01-01')),
PARTITION p99991231 VALUES [('9999-12-31'), (MAXVALUE))