データバケッティング
パーティションは、ビジネスロジックに基づいて異なるデータバケットにさらに分割できます。各バケットは物理的なデータタブレットとして格納されます。適切なバケット戦略により、クエリ時にスキャンされるデータ量を効果的に削減し、クエリパフォーマンスを向上させ、クエリの同時実行性を高めることができます。
バケット Methods
DorisではHash BucketingとRandom Bucketingの2つのバケット方法をサポートしています。
Hash Bucketing
Tableを作成する際やパーティションを追加する際、ユーザーは1つ以上の列をバケット列として選択し、バケット数を指定する必要があります。同一パーティション内で、システムはバケットキーとバケット数に基づいてハッシュ計算を実行します。同じハッシュ値を持つデータは同じバケットに割り当てられます。例えば、下図では、パーティションp250102がregion列に基づいて3つのバケットに分割され、同じハッシュ値を持つ行が同じバケットに配置されています。
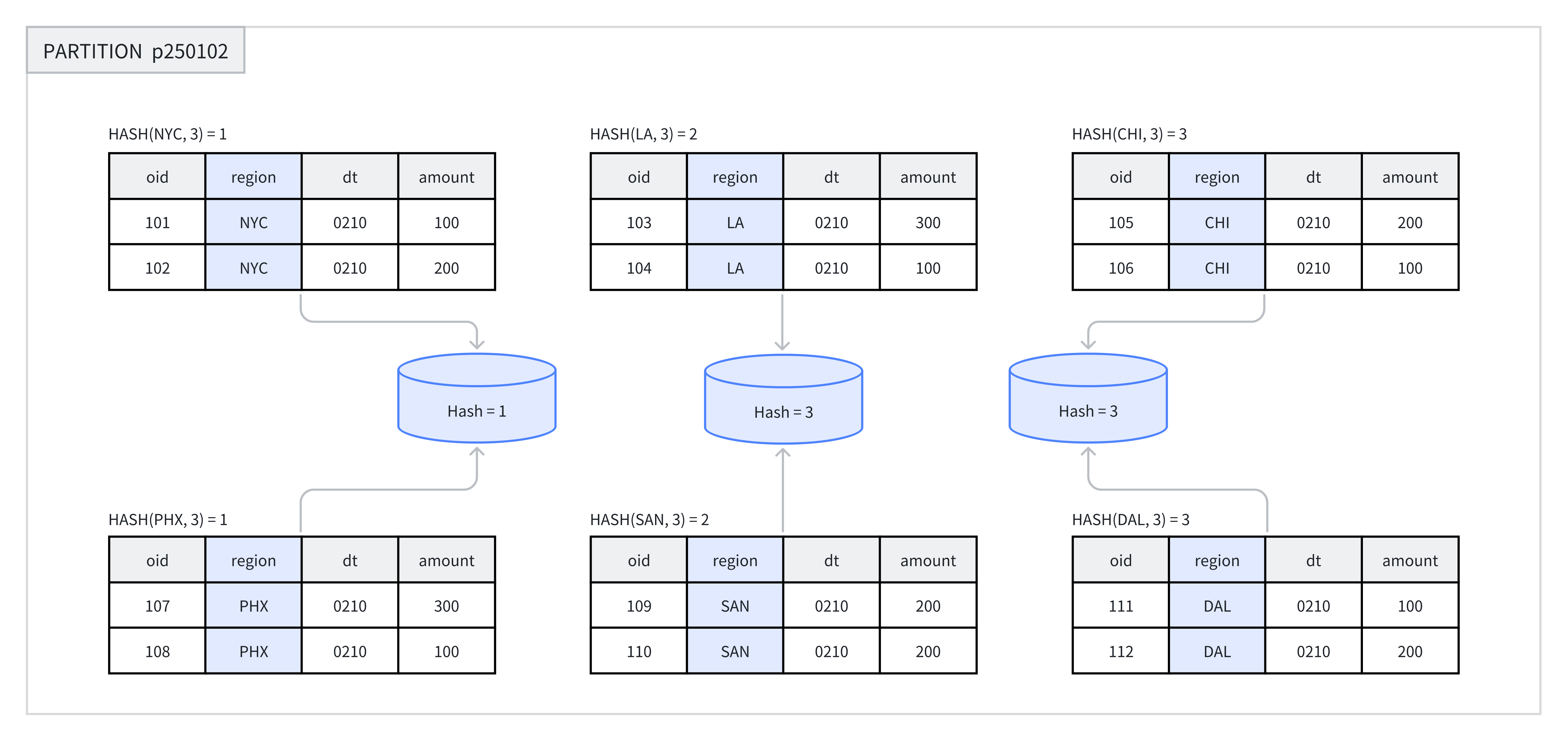
以下のシナリオでHash Bucketingの使用を推奨します:
-
ビジネスで特定のフィールドに基づく頻繁なフィルタリングが必要な場合、このフィールドをバケットキーとしてHash Bucketingに使用することでクエリ効率を向上できます。
-
Table内のデータ分布が比較的均一な場合、Hash Bucketingも適切な選択肢です。
以下の例は、Hash Bucketingを使用してTableを作成する方法を示しています。詳細な構文については、CREATE TABLE文を参照してください。
CREATE TABLE demo.hash_bucket_tbl(
oid BIGINT,
dt DATE,
region VARCHAR(10),
amount INT
)
DUPLICATE KEY(oid)
PARTITION BY RANGE(dt) (
PARTITION p250101 VALUES LESS THAN("2025-01-01"),
PARTITION p250102 VALUES LESS THAN("2025-01-02")
)
DISTRIBUTED BY HASH(region) BUCKETS 8;
この例では、DISTRIBUTED BY HASH(region)はHash Bucketingの作成を指定し、バケットキーとしてregion列を選択します。また、BUCKETS 8は8つのバケットの作成を指定します。
Random Bucketing
各パーティション内で、Random Bucketingは特定のフィールドのハッシュ値に依存せずに、データをさまざまなバケットにランダムに分散します。Random Bucketingは均一なデータ分散を保証し、不適切なバケットキー選択によって引き起こされるデータスキューを回避します。
データインポート中、単一のインポートジョブの各バッチはタブレットにランダムに書き込まれ、均一なデータ分散を保証します。例えば、ある操作では、8つのデータバッチがパーティションp250102配下の3つのバケットにランダムに割り当てられます。
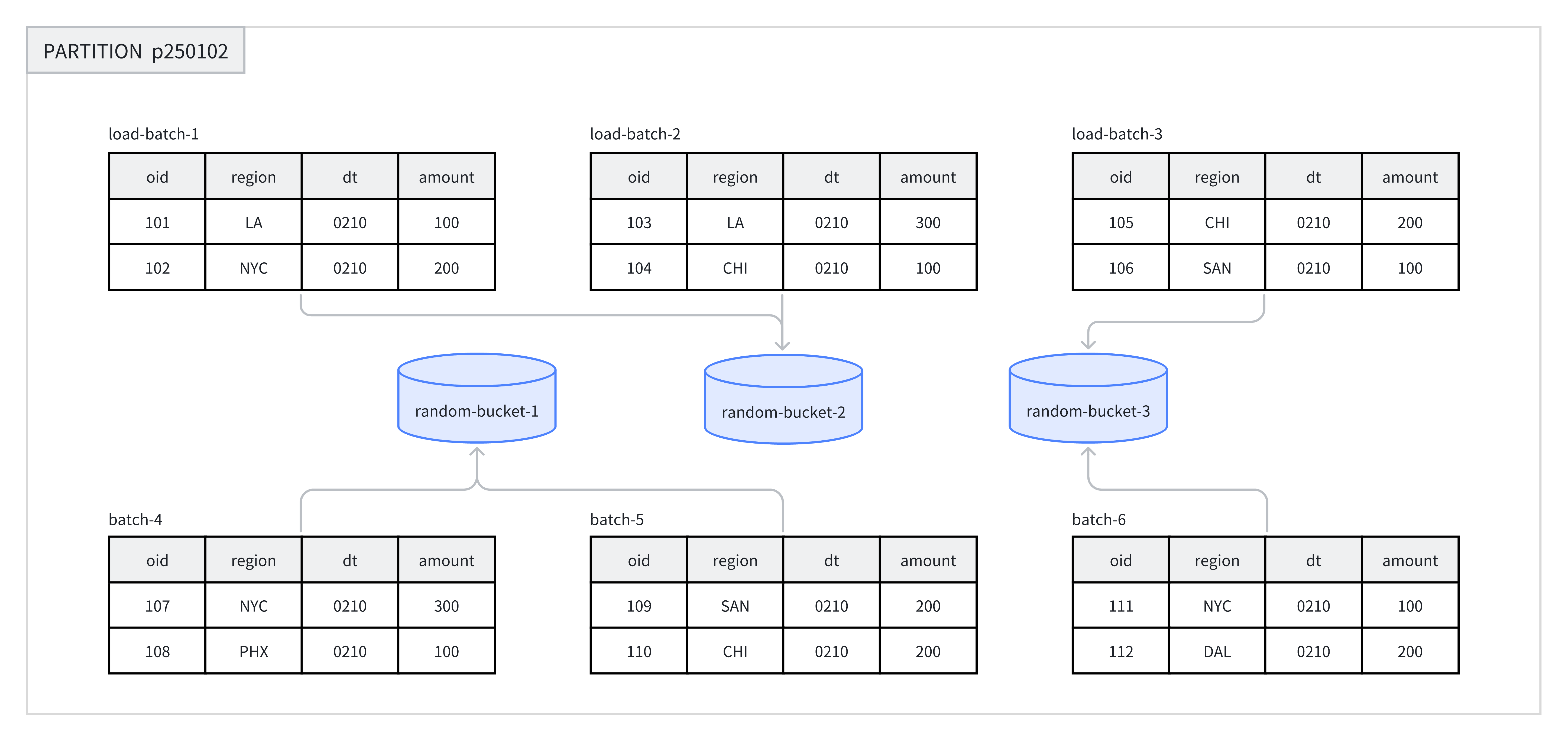
Random Bucketingを使用する際は、単一タブレットインポートモード(load_to_single_tabletをtrueに設定)を有効にできます。大規模なデータインポート中、1つのデータバッチは1つのデータタブレットのみに書き込まれるため、データインポートの同時実行性とスループットの向上に役立ち、データインポートとCompactionによって引き起こされる書き込み増幅を削減し、クラスタの安定性を確保します。
以下のシナリオではRandom Bucketingの使用を推奨します:
-
任意の次元分析のシナリオで、ビジネスが特定の列に基づくフィルタやjoinクエリを頻繁に行わない場合、Random Bucketingを選択できます。
-
頻繁にクエリされる列または列の組み合わせのデータ分散が極めて不均一な場合、Random Bucketingを使用することでデータスキューを回避できます。
-
Random Bucketingはバケットキーに基づく枝刈りができず、ヒットしたパーティション内のすべてのデータをスキャンするため、ポイントクエリのシナリオには推奨されません。
-
DUPLICATETableのみがRandom partitioningを使用できます。UNIQUETableとAGGREGATETableはRandom Bucketingを使用できません。
以下の例は、Random BucketingでTableを作成する方法を示します。詳細な構文については、CREATE TABLE文を参照してください:
CREATE TABLE demo.random_bucket_tbl(
oid BIGINT,
dt DATE,
region VARCHAR(10),
amount INT
)
DUPLICATE KEY(oid)
PARTITION BY RANGE(dt) (
PARTITION p250101 VALUES LESS THAN("2025-01-01"),
PARTITION p250102 VALUES LESS THAN("2025-01-02")
)
DISTRIBUTED BY RANDOM BUCKETS 8;
この例では、DISTRIBUTED BY RANDOM文によってRandom Bucketingの使用を指定しています。Random Bucketingの作成では、バケットキーを選択する必要がなく、BUCKETS 8文によって8個のバケットの作成を指定しています。
バケットキーの選択
Hash Bucketingのみがバケットキーの選択を必要とし、Random Bucketingではバケットキーの選択は必要ありません。
バケットキーは1つまたは複数の列にすることができます。DUPLICATETableの場合、任意のKey列またはValue列をバケットキーとして使用できます。AGGREGATEまたはUNIQUETableの場合、段階的な集約を確保するため、バケット列はKey列である必要があります。
一般的に、以下のルールに基づいてバケットキーを選択できます:
-
クエリフィルター条件の使用: Hash Bucketingでクエリフィルター条件を使用することで、データプルーニングが促進され、データスキャン量が削減されます;
-
高カーディナリティ列の使用: Hash Bucketingで高カーディナリティ(多くの一意な値を持つ)列を選択することで、各バケット間でデータを均等に分散させることができます;
-
高同時実行ポイントクエリシナリオ: バケッティングには単一列またはより少ない列を選択することを推奨します。ポイントクエリでは1つのバケットのスキャンのみがトリガーされ、異なるクエリが異なるバケットのスキャンをトリガーする確率が高いため、クエリ間のIO影響を削減できます。
-
高スループットクエリシナリオ: データをより均等に分散させるために、バケッティングには複数の列を選択することを推奨します。クエリ条件がすべてのバケットキーの等価条件を含められない場合、クエリスループットが向上し、単一クエリのレイテンシが削減されます。
バケット数の選択
Dorisでは、バケットは物理ファイル(tablet)として保存されます。Table内のtablet数はpartition_num(パーティション数)にbucket_num(バケット数)を乗じた値と等しくなります。パーティション数を指定した後、それを変更することはできません。
バケット数を決定する際は、マシンの拡張を事前に検討する必要があります。バージョン2.0以降、Dorisはマシンリソースとクラスター情報に基づいて、パーティション内のバケット数を自動的に設定することをサポートしています。
バケット数の手動設定
DISTRIBUTED文を使用してバケット数を指定できます:
-- Set hash bucket num to 8
DISTRIBUTED BY HASH(region) BUCKETS 8
-- Set random bucket num to 8
DISTRIBUTED BY RANDOM BUCKETS 8
bucket数を決定する際、通常は数量とサイズという2つの原則に従います。この2つの間で競合がある場合、サイズ原則が優先されます:
-
サイズ原則: tabletのサイズは1-10GBの範囲内にすることが推奨されます。tabletが小さすぎると集約効果が悪くなり、メタデータ管理の負荷が増加する可能性があります;tabletが大きすぎるとレプリカの移行や補完に不利であり、Schema Change操作の再試行コストが増加します。
-
数量原則: 拡張を考慮しない場合、Tableのtablet数はクラスタ全体のディスク数よりわずかに多くすることが推奨されます。
例えば、BEマシンが10台あり、各BEにディスクが1つある場合、以下の推奨事項に従ってデータのbucketingを行うことができます:
| Tableサイズ | 推奨bucket数 |
|---|---|
| 500MB | 4-8 buckets |
| 5GB | 6-16 buckets |
| 50GB | 32 buckets |
| 500GB | パーティション推奨、パーティションあたり50GB、パーティションあたり16-32 buckets |
| 5TB | パーティション推奨、パーティションあたり50GB、パーティションあたり16-32 buckets |
Tableのデータ量はSHOW DATAコマンドで確認できます。結果はレプリカ数とTableのデータ量で除算する必要があります。
自動Bucket数設定
自動bucket数計算機能は、一定期間のパーティションサイズに基づいて将来のパーティションサイズを自動的に予測し、それに応じてbucket数を決定します。
-- Set hash bucket auto
DISTRIBUTED BY HASH(region) BUCKETS AUTO
properties("estimate_partition_size" = "20G")
-- Set random bucket auto
DISTRIBUTED BY HASH(region) BUCKETS AUTO
properties("estimate_partition_size" = "20G")
bucketを作成する際、estimate_partition_size属性を通じて推定パーティションサイズを調整できます。このパラメータはオプションであり、指定されない場合、Dorisはデフォルトで10GBを使用します。このパラメータは、履歴パーティションデータに基づいてシステムが計算する将来のパーティションサイズとは関係がないことに注意してください。
Data Bucketの維持
現在、Dorisは新しく追加されたパーティションでのbucket数の変更のみをサポートしており、以下の操作はサポートしていません:
- bucketingタイプの変更
- bucket keyの変更
- 既存のbucketのbucket数の変更
Tableを作成する際、各パーティションのbucket数はDISTRIBUTED文を通じて統一的に指定されます。データの増加や減少に対応するため、パーティションを動的に追加する際に新しいパーティションのbucket数を指定できます。以下の例は、ALTER TABLEコマンドを使用して新しく追加されたパーティションのbucket数を変更する方法を示しています:
-- Modify hash bucket table
ALTER TABLE demo.hash_bucket_tbl
ADD PARTITION p250103 VALUES LESS THAN("2025-01-03")
DISTRIBUTED BY HASH(region) BUCKETS 16;
-- Modify random bucket table
ALTER TABLE demo.random_bucket_tbl
ADD PARTITION p250103 VALUES LESS THAN("2025-01-03")
DISTRIBUTED BY RANDOM BUCKETS 16;
-- Modify dynamic partition table
ALTER TABLE demo.dynamic_partition_tbl
SET ("dynamic_partition.buckets"="16");
バケット数を変更した後、SHOW PARTITION コマンドを使用して、更新されたバケット数を確認できます。