データ更新の概要
今日のデータ駆動型意思決定の状況において、データの「フレッシュネス」は企業が激しい市場競争で差別化を図るための中核的な競争優位性となっています。従来のT+1データ処理モデルは、その固有のレイテンシにより、現代ビジネスの厳格なリアルタイム要件をもはや満たすことができません。ビジネスデータベースとデータウェアハウス間のミリ秒レベルの同期実現、運用戦略の動的調整、または意思決定精度を確保するための数秒以内でのエラーデータ修正など、堅牢なリアルタイムデータ更新機能が重要です。
Apache Dorisは、現代的なリアルタイム分析データベースとして、究極のデータフレッシュネスの提供をその中核設計目標の一つとしています。強力なデータモデルと柔軟な更新メカニズムを通じて、データ分析レイテンシを日レベル、時間レベルから秒レベルまで圧縮することに成功し、ユーザーがリアルタイムで俊敏なビジネス意思決定ループを構築するための堅実な基盤を提供しています。
この文書は、Apache Dorisのデータ更新機能を体系的に説明する公式ガイドとして機能し、その中核原理、多様な更新・削除方法、典型的なアプリケーションシナリオ、および異なるデプロイメントモードにおけるパフォーマンスベストプラクティスを網羅し、Dorisのデータ更新機能を包括的に習得し効率的に活用することを支援することを目的としています。
1. 中核概念:Tableモデルと更新メカニズム
Dorisでは、データTableのData Modelがデータの組織化と更新動作を決定します。異なるビジネスシナリオをサポートするため、DorisはUnique Key Model、Aggregate Key Model、Duplicate Key Modelの3つのTableモデルを提供しています。これらの中でも、Unique Key Modelが複雑で高頻度なデータ更新を実装するための中核です。
1.1. Tableモデル概要
| Table Model | 主な特徴 | 更新機能 | 使用例 |
|---|---|---|---|
| Unique Key Model | リアルタイム更新用に構築。各データ行は一意のPrimary Keyで識別され、行レベルのUPSERT(アップデート/Insert)と部分列更新をサポート。 | 最強、全ての更新・削除方法をサポート。 | 注文ステータス更新、リアルタイムユーザータグ計算、CDCデータ同期、その他頻繁でリアルタイムな変更を要するシナリオ。 |
| Aggregate Key Model | 指定されたKey列に基づいてデータを事前集約。同じKeyを持つ行について、Value列は定義された集約関数(SUM、MAX、MIN、REPLACEなど)に従ってマージされる。 | 限定的、Key列に基づくREPLACEスタイルの更新・削除をサポート。 | リアルタイムサマリー統計を必要とするシナリオ、例:リアルタイムレポート、広告クリック統計など。 |
| Duplicate Key Model | データは追記のみの書き込みをサポートし、重複排除や集約操作は行わない。同一のデータ行も保持される。 | 限定的、DELETE文による条件付き削除のみサポート。 | ログ収集、ユーザー行動追跡、その他更新なしで追記のみが必要なシナリオ。 |
1.2. データ更新方法
Dorisは2つの主要なデータ更新方法カテゴリを提供しています:データロードによる更新とDML文による更新。
1.2.1. ロードによる更新(UPSERT)
これはDorisの推奨する高パフォーマンス、高並行性更新方法で、主にUnique Key Modelを対象としています。全てのロード方法(Stream Load、Broker Load、Routine Load、INSERT INTO)は自然にUPSERTセマンティクスをサポートしています。新しいデータがロードされる際、そのプライマリキーが既に存在する場合、Dorisは新しい行データで古い行データを上書きし、プライマリキーが存在しない場合は新しい行を挿入します。
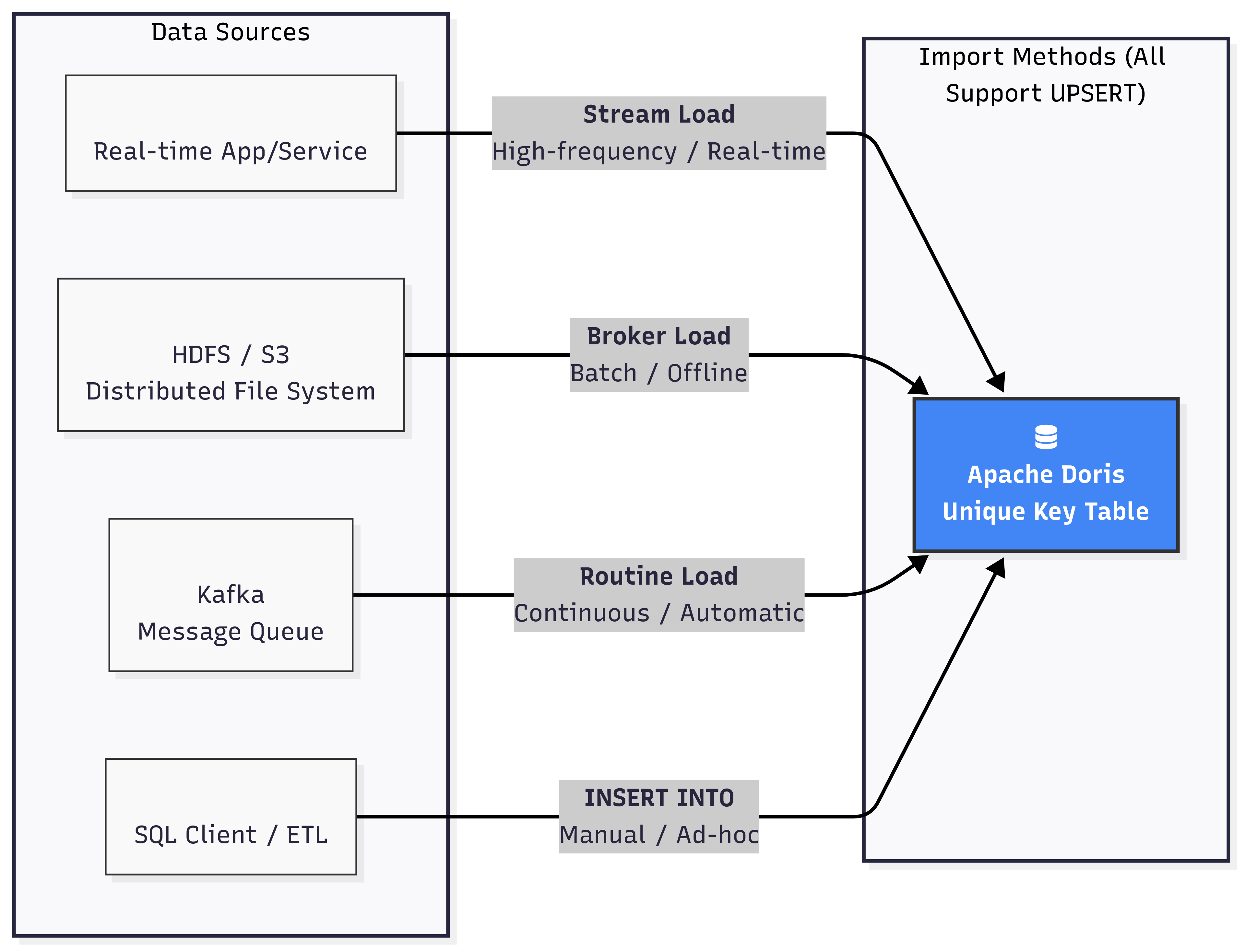
1.2.2. UPDATE DML文による更新
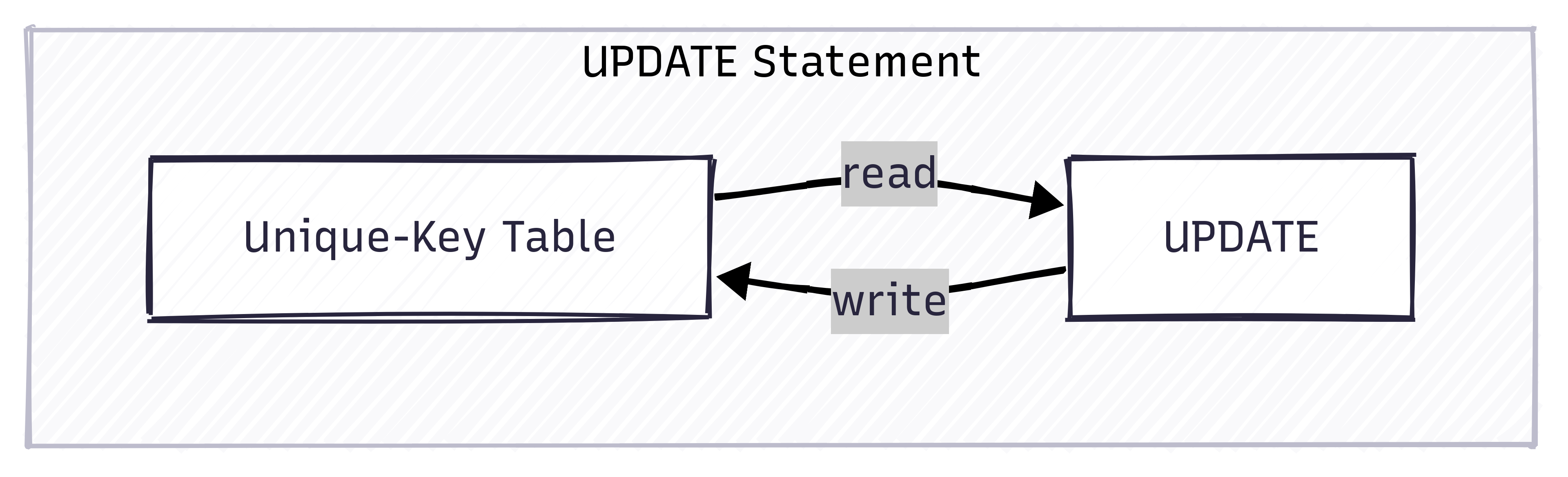
Dorisは標準SQL UPDATE文をサポートし、ユーザーがWHERE句で指定した条件に基づいてデータを更新できます。この方法は非常に柔軟で、Table間結合更新などの複雑な更新ロジックをサポートしています。
-- Simple update
UPDATE user_profiles SET age = age + 1 WHERE user_id = 1;
-- Cross-table join update
UPDATE sales_records t1
SET t1.user_name = t2.name
FROM user_profiles t2
WHERE t1.user_id = t2.user_id;
注意: UPDATE文の実行プロセスでは、まず条件に一致するデータをスキャンし、その後更新されたデータをTableに書き戻します。これは低頻度のバッチ更新タスクに適しています。UPDATE文の高並行処理操作は推奨されません。同じプライマリキーに関わる並行UPDATE操作では、データ分離を保証できないためです。
1.2.3. INSERT INTO SELECT DML文による更新
DorisはデフォルトでUPSERTセマンティクスを提供するため、INSERT INTO SELECTを使用することでUPDATEと同様の更新効果を実現することもできます。
1.3. データ削除方法
更新と同様に、DorisはロードとDML文の両方を通じたデータ削除もサポートしています。
1.3.1. ロードによる論理削除
これは効率的なバッチ削除方法であり、主にUnique Key Modelで使用されます。ユーザーはデータロード時に特別な隠し列DORIS_DELETE_SIGNを追加できます。ある行のこの列の値が1またはtrueの場合、Dorisはそのプライマリキーを持つ対応するデータ行を削除済みとしてマークします(delete signの原理については後で詳しく説明します)。
// Stream Load load data, delete row with user_id = 2
// curl --location-trusted -u user:passwd -H "columns:user_id, __DORIS_DELETE_SIGN__" -T delete.json http://fe_host:8030/api/db_name/table_name/_stream_load
// delete.json content
[
{"user_id": 2, "__DORIS_DELETE_SIGN__": "1"}
]
1.3.2. DELETE DML文による削除
Dorisは標準SQL DELETE文をサポートしており、WHERE条件に基づいてデータを削除できます。
- Unique Key Model:
DELETE文は、条件を満たす行のプライマリキーを削除マークで書き換えます。そのため、そのパフォーマンスは削除するデータ量に比例します。Unique Key ModelにおけるDELETE文の実行原理はUPDATE文と非常に似ており、まずクエリを通じて削除するデータを読み取り、次に削除マークを付けて再度書き込みます。UPDATE文と比較すると、DELETE文はKeyカラムと削除マークカラムのみを書き込むため、比較的軽量です。 - Duplicate/Aggregate Models:
DELETE文は削除述語を記録することで実装されます。クエリ時には、この述語がランタイムフィルターとして機能し、削除されたデータをフィルタリングします。そのため、DELETE操作自体は非常に高速で、削除データ量にほぼ依存しません。ただし、Duplicate/Aggregate Modelに対する高頻度のDELETE操作は多くのランタイムフィルターを蓄積し、その後のクエリパフォーマンスに深刻な影響を与えることに注意してください。
DELETE FROM user_profiles WHERE last_login < '2022-01-01';
以下の表は、削除におけるDML文の使用方法の概要を示しています:
| Unique Key Model | Aggregate Model | Duplicate Model | |
|---|---|---|---|
| Implementation | Delete Sign | Delete Predicate | Delete Predicate |
| Limitations | None | Delete conditions only for Key columns | None |
| Deletion Performance | Moderate | Fast | Fast |
2. Unique Key Modelの詳細解説:原理と実装
Unique Key ModelはDorisの高性能リアルタイム更新の基盤となっています。その内部動作原理を理解することは、そのパフォーマンスを最大限に活用するために重要です。
2.1. Merge-on-Write (MoW) vs. Merge-on-Read (MoR)
Unique Key Modelには、Merge-on-Write (MoW)とMerge-on-Read (MoR)という2つのデータマージ戦略があります。Doris 2.1以降、MoWがデフォルトおよび推奨実装となっています。
| Feature | Merge-on-Write (MoW) | Merge-on-Read (MoR) - (Legacy) |
|---|---|---|
| Core Concept | データ書き込み時にデータ重複排除とマージを完了し、ストレージ内の主キーごとに最新レコードを1つだけ保持することを保証します。 | データ書き込み時に複数のバージョンを保持し、クエリ時にリアルタイムマージを実行して最新バージョンを返します。 |
| Query Performance | 極めて高い。クエリ時に追加のマージ操作が不要で、パフォーマンスは更新されていない詳細Tableに近づきます。 | 低い。クエリ時にデータマージが必要で、MoWより約3-10倍時間がかかり、CPUとメモリをより多く消費します。 |
| Write Performance | 書き込み時にマージオーバーヘッドがあり、MoRと比較してある程度のパフォーマンス低下があります(小バッチで約10-20%、大バッチで30-50%)。 | 書き込み速度が高速で、詳細Tableに近づきます。 |
| Resource Consumption | 書き込み時およびバックグラウンドCompaction時により多くのCPUとメモリを消費します。 | クエリ時により多くのCPUとメモリを消費します。 |
| Use Cases | ほとんどのリアルタイム更新シナリオ。読み取り重視、書き込み軽量のビジネスに特に適しており、最高のクエリ分析パフォーマンスを提供します。 | 書き込み重視、読み取り軽量のシナリオに適していますが、もはや主流の推奨ではありません。 |
MoWメカニズムは、書き込みフェーズでの小さなコストと引き換えに、クエリパフォーマンスの大幅な改善を実現し、OLAPシステムの「読み取り重視、書き込み軽量」という特性と完全に合致しています。
2.2. 条件付き更新(Sequence Column)
分散システムでは、データの順序が乱れて到着することは一般的な問題です。たとえば、注文ステータスが順次「支払済み」と「出荷済み」に変更されるとき、ネットワーク遅延により「出荷済み」を表すデータが「支払済み」を表すデータよりも先にDorisに到着する可能性があります。
この問題を解決するため、DorisはSequence Columnメカニズムを導入しています。ユーザーはTable作成時に列(通常はタイムスタンプまたはバージョン番号)をSequence columnとして指定できます。同じ主キーを持つデータを処理する際、DorisはそれらのSequence column値を比較し、常にSequence値が最大の行を保持することで、データが順序を乱れて到着してもeventual consistencyを保証します。
CREATE TABLE order_status (
order_id BIGINT,
status_name STRING,
update_time DATETIME
)
UNIQUE KEY(order_id)
DISTRIBUTED BY HASH(order_id)
PROPERTIES (
"function_column.sequence_col" = "update_time" -- Specify update_time as Sequence column
);
-- 1. Write "Shipped" record (larger update_time)
-- {"order_id": 1001, "status_name": "Shipped", "update_time": "2023-10-26 12:00:00"}
-- 2. Write "Paid" record (smaller update_time, arrives later)
-- {"order_id": 1001, "status_name": "Paid", "update_time": "2023-10-26 11:00:00"}
-- Final query result, retains record with largest update_time
-- order_id: 1001, status_name: "Shipped", update_time: "2023-10-26 12:00:00"
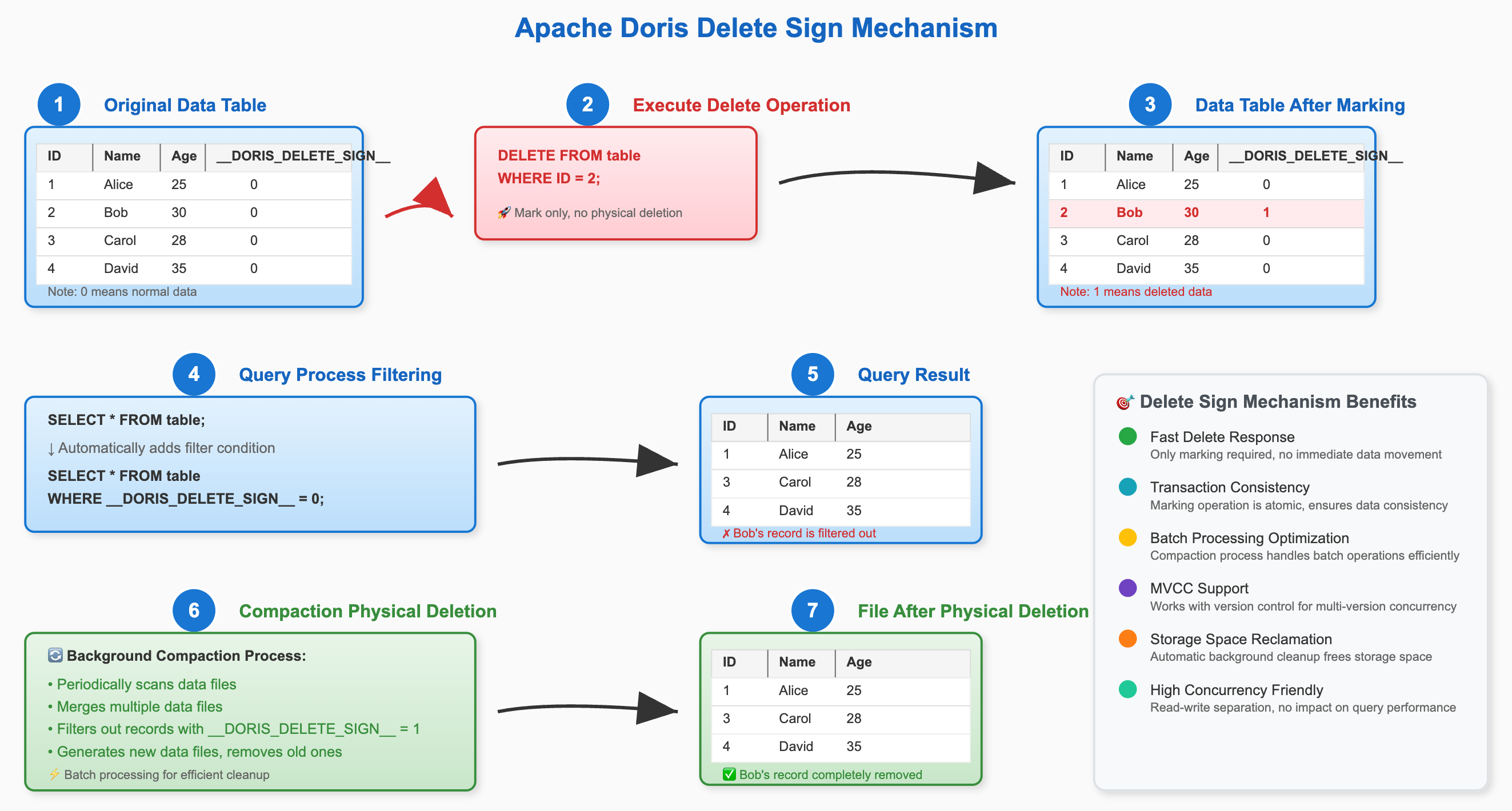
2.3. 削除メカニズム(DORIS_DELETE_SIGN)のワークフロー
DORIS_DELETE_SIGNの動作原理は「論理的マーキング、バックグラウンドクリーンアップ」として要約できます。
- 削除実行: ユーザーがloadまたは
DELETE文によってデータを削除する際、Dorisは物理ファイルからデータを即座に削除しません。代わりに、削除対象のプライマリキーに対して新しいレコードを書き込み、DORIS_DELETE_SIGN列を1にマーキングします。 - クエリフィルタリング: ユーザーがデータをクエリする際、Dorisは自動的にクエリプランに
WHERE DORIS_DELETE_SIGN = 0というフィルタ条件を追加し、削除マークされたすべてのデータをクエリ結果から隠します。 - バックグラウンドCompaction: DorisのバックグラウンドCompactionプロセスがデータを定期的にスキャンします。通常レコードと削除マークレコードの両方を持つプライマリキーを見つけた場合、マージプロセス中に両方のレコードを物理的に削除し、最終的にストレージ領域を解放します。
このメカニズムにより、削除操作に対する迅速な応答を保証しながら、バックグラウンドタスクを通じて物理的なクリーンアップを非同期で完了し、オンラインビジネスへのパフォーマンス影響を回避します。
以下の図はDORIS_DELETE_SIGNの動作を示しています:
2.4 部分列更新
バージョン2.0以降、DorisはUnique Key Models (MoW)において強力な部分列更新機能をサポートしています。データロード時、ユーザーはプライマリキーと更新対象列のみを提供すれば十分で、未提供の列は元の値を変更せずに維持されます。これにより、ワイドTable結合やリアルタイムタグ更新などのシナリオにおけるETLプロセスが大幅に簡素化されます。
この機能を有効にするには、Unique Key ModelTable作成時にMerge-on-Write (MoW)モードを有効にし、enable_unique_key_partial_updateプロパティをtrueに設定するか、データロード時に"partial_columns"パラメータを設定する必要があります。
CREATE TABLE user_profiles (
user_id BIGINT,
name STRING,
age INT,
last_login DATETIME
)
UNIQUE KEY(user_id)
DISTRIBUTED BY HASH(user_id)
PROPERTIES (
"enable_unique_key_partial_update" = "true"
);
-- Initial data
-- user_id: 1, name: 'Alice', age: 30, last_login: '2023-10-01 10:00:00'
-- load partial update data through Stream Load, only updating age and last_login
-- {"user_id": 1, "age": 31, "last_login": "2023-10-26 18:00:00"}
-- Updated data
-- user_id: 1, name: 'Alice', age: 31, last_login: '2023-10-26 18:00:00'
Partial Column アップデート の基本原理概要
従来のOLTPデータベースとは異なり、DorisのPartial Column Updateはインプレースなデータ更新ではありません。Dorisでより良い書き込みスループットとクエリパフォーマンスを実現するため、Unique Key ModelのPartial Column Updateは**「書き込み時の不足フィールド補完に続く全行書き込み」**の実装アプローチを採用しています。
そのため、DorisのPartial Column Updateの使用には**「リード・アンプリフィケーション」と「ライト・アンプリフィケーション」**の効果があります。たとえば、100カラムの幅広いTableで10フィールドを更新する場合、Dorisは書き込みプロセス中に不足している90フィールドを補完する必要があります。各フィールドが同様のサイズであると仮定すると、1MBの10フィールド更新により、Dorisシステムでは約9MBのデータ読み取り(不足フィールドの補完)と10MBのデータ書き込み(完全な行を新しいファイルに書き込み)が発生し、約9倍のリード・アンプリフィケーションと10倍のライト・アンプリフィケーションが生じます。
Partial Column アップデート のパフォーマンス推奨事項
Partial Column Updateでのリードとライトのアンプリフィケーション、およびDorisがカラムナーストレージシステムであることから、データ読み取りプロセスは大幅なランダムI/Oを生成する可能性があり、ストレージから高いランダム読み取りIOPSが要求されます。従来の機械式ディスクはランダムI/Oにおいて大幅なボトルネックがあるため、高頻度書き込みでPartial Column Update機能を使用したい場合は、SSDドライブ、できればNVMeインターフェースを推奨します。これにより最高のランダムI/Oサポートを提供できます。
さらに、Tableが非常に幅広い場合は、ランダムI/Oを削減するためにrow storageを有効にすることも推奨されます。row storageを有効にすると、Dorisはカラムナーストレージと併せて行ベースデータの追加コピーを保存します。行ベースデータは各行を連続して保存するため、単一のI/O操作で全行を読み取れます(カラムナーストレージでは不足するすべてのフィールドを読み取るためにN回のI/O操作が必要です。たとえば前述の100カラムの幅広いTableで10カラムを更新する例では、すべてのフィールドを読み取るために行ごとに90回のI/O操作が必要です)。
3. 典型的なアプリケーションシナリオ
Dorisの強力なデータ更新機能により、さまざまな要求の厳しいリアルタイム分析シナリオを処理できます。
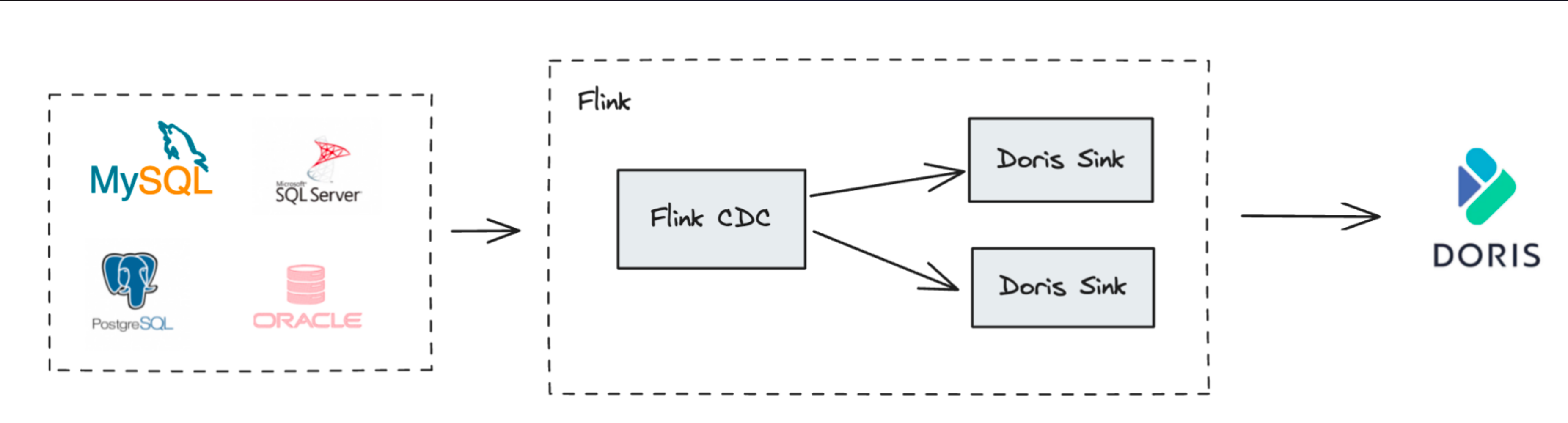
3.1. CDCリアルタイムデータ同期
Flink CDCなどのツールを通じて上流のビジネスデータベース(MySQL、PostgreSQL、Oracleなど)から変更データ(Binlog)をキャプチャし、DorisのUnique Key ModelTableにリアルタイムで書き込むことは、リアルタイムデータウェアハウス構築の最も典型的なシナリオです。
- データベース全体の同期: Flink Doris ConnectorはFlink CDCを内部で統合し、上流データベースからDorisへの自動化されたエンドツーエンドのデータベース全体同期を、手動でのTable作成やフィールドマッピング設定なしに実現します。
- 一貫性の確保: Unique Key Modelの
UPSERT機能を利用して上流のINSERTとUPDATE操作を処理し、DORIS_DELETE_SIGNを使用してDELETE操作を処理し、Sequenceカラム(Binlogのタイムスタンプなど)と組み合わせて順序の乱れたデータを処理し、上流データベースの状態を完全に複製してミリ秒レベルのデータ同期遅延を実現します。
3.2. リアルタイム幅広Tableの結合
多くの分析シナリオでは、異なるビジネスシステムからのデータをユーザー幅広Tableや製品幅広Tableに結合する必要があります。従来のアプローチでは、定期的な(T+1)結合にオフラインETLタスク(SparkやHiveなど)を使用し、リアルタイム性能が悪く、メンテナンスコストが高くなります。または、Flinkを使用してリアルタイム幅広Table結合計算を行い、結合されたデータをデータベースに書き込む場合、通常は大幅な計算リソースが必要です。
DorisのPartial Column アップデート機能を使用することで、このプロセスを大幅に簡素化できます:
- DorisでUnique Key Model幅広Tableを作成します。
- 異なるソース(ユーザー基本情報、ユーザー行動データ、取引データなど)からのデータストリームをStream LoadやRoutine Loadを通じてこの幅広Tableにリアルタイムで書き込みます。
- 各データストリームは関連するフィールドのみを更新します。たとえば、ユーザー行動データストリームは
page_view_count、last_login_timeなどのフィールドのみを更新し、取引データストリームはtotal_orders、total_amountなどのフィールドのみを更新します。
このアプローチにより、幅広Tableの構築をオフラインETLからリアルタイムストリーム処理に変換し、データの新鮮さを大幅に改善するだけでなく、変更されたカラムのみを書き込むことでI/Oオーバーヘッドを削減し、書き込みパフォーマンスを向上させます。
4. ベストプラクティス
これらのベストプラクティスに従うことで、Dorisのデータ更新機能をより安定的かつ効率的に使用できます。
4.1. 一般的なパフォーマンスプラクティス
- load更新を優先する: 高頻度、大容量の更新操作では、
UPDATEDMLステートメントよりもStream LoadやRoutine Loadなどのloadメソッドを優先します。 - バッチ書き込み: 個別の高頻度書き込み(> 100 TPSなど)に
INSERT INTOステートメントの使用を避けます。各INSERTにはトランザクションオーバーヘッドが発生するためです。必要な場合は、Group Commit機能を有効にして複数の小さなバッチコミットを1つの大きなトランザクションにマージすることを検討してください。 - 高頻度
DELETEの慎重な使用: DuplicateおよびAggregateモデルでは、クエリパフォーマンスの低下を防ぐため、高頻度のDELETE操作を避けます。 - パーティションデータ削除には
TRUNCATE PARTITIONを使用: パーティション全体のデータを削除する必要がある場合は、DELETEよりもはるかに効率的なTRUNCATE PARTITIONを使用します。 UPDATEの連続実行: 同じデータ行に影響する可能性があるUPDATEタスクの同時実行を避けます。
4.2. コンピュート・ストレージ分離アーキテクチャにおけるUnique Key Modelプラクティス
Doris 3.0では、究極の弾力性とより低いコストをもたらす先進的なコンピュート・ストレージ分離アーキテクチャが導入されています。このアーキテクチャでは、BEノードがステートレスであるため、Merge-on-Writeプロセス中にload/compaction/schema change操作間の書き込み-書き込み競合を解決するためにMetaServiceを通じてグローバル状態を維持する必要があります。Unique Key ModelのMoW実装は、書き込み操作の一貫性を確保するためにMeta Serviceベースの分散Tableロックに依存しています。以下の図に示されています:
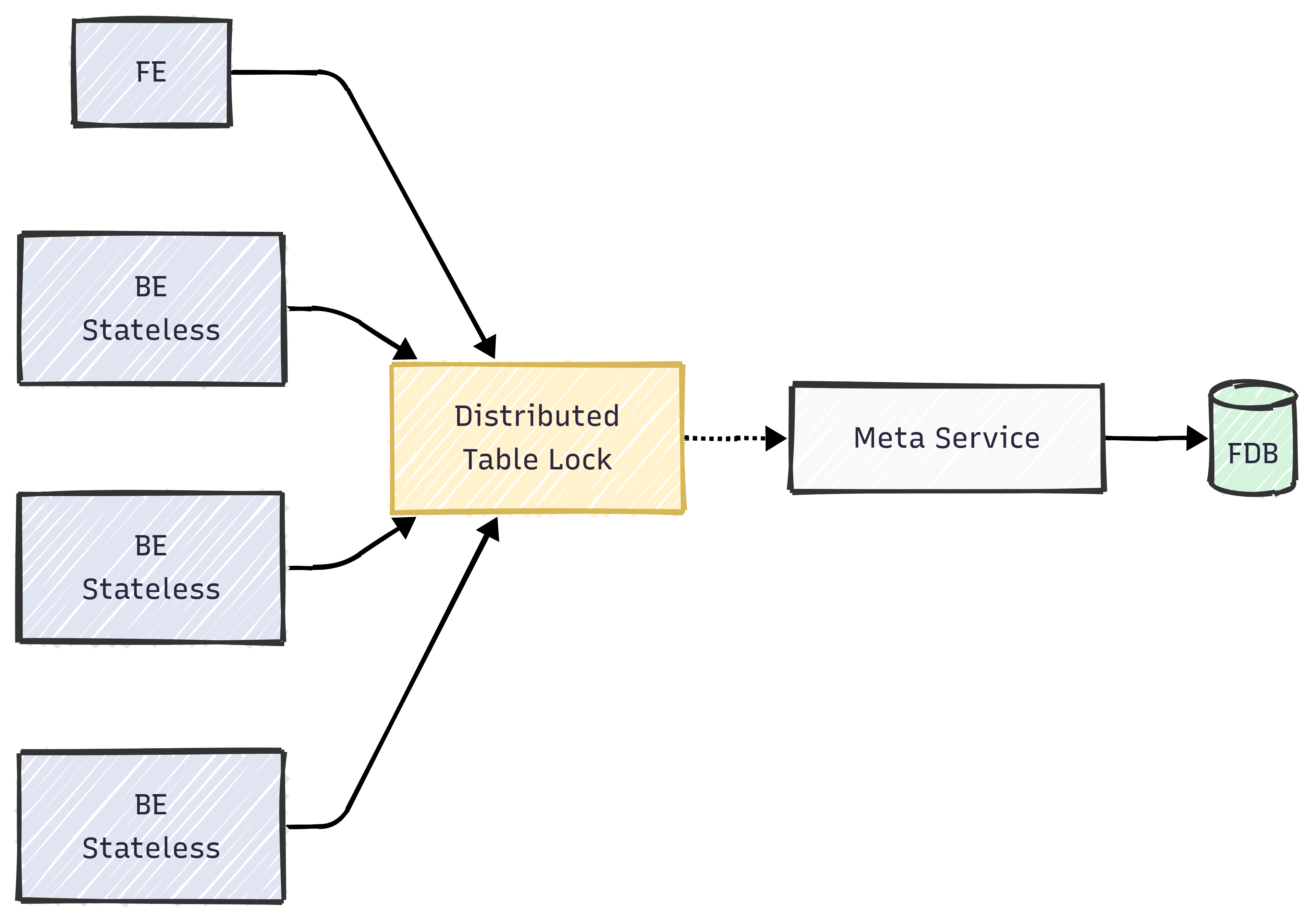
高頻度のloadとCompactionはTableロックの頻繁な競合を引き起こすため、以下の点に特別な注意を払う必要があります:
- 単一Tableのload頻度の制御: 単一のUnique Key Tableのload頻度を毎秒60回以内に制御することを推奨します。これはバッチ処理とload同時実行数の調整により実現できます。
- 合理的なパーティションとバケット設計:
- パーティション: 時間パーティション(日または時間単位など)を使用することで、単一のloadが少数のパーティションのみを更新することが保証され、ロック競合の範囲が削減されます。
- バケット: バケット数(Tablet数)は、データ量に基づいて合理的に設定すべきで、通常8-64の間です。Tabletが多すぎるとロック競合が激化します。
- Compaction戦略の調整: 非常に高い書き込み圧力のシナリオでは、Compaction頻度を削減するためにCompaction戦略を適切に調整し、Compactionとloadタスク間のロック競合を削減できます。
- 最新バージョンへのアップグレード: Dorisコミュニティは、コンピュート・ストレージ分離アーキテクチャでのUnique Key Modelパフォーマンスを継続的に最適化しています。たとえば、今後の3.1リリースでは分散Tableロック実装が大幅に最適化されます。最適なパフォーマンスのために常に最新の安定バージョンの使用を推奨します。
結論
Apache Dorisは、Unique Key Modelを中心とした強力で柔軟かつ効率的なデータ更新機能により、データの新鮮さにおける従来のOLAPシステムのボトルネックを真に打破します。UPSERTとPartial Column Updateを実装する高性能loadであろうと、順序の乱れたデータの一貫性を確保するSequenceカラムの使用であろうと、Dorisはエンドツーエンドのリアルタイム分析アプリケーション構築のための完全なソリューションを提供します。
その核心原理を深く理解し、異なる更新メソッドの適用可能なシナリオを習得し、この文書で提供されるベストプラクティスに従うことで、Dorisの潜在能力を完全に引き出し、リアルタイムデータを真にビジネス成長を推進する強力なエンジンにすることができるでしょう。