AWS Glue カタログ
AWS Glueは、AWSが提供する完全管理型のサーバーレスメタデータストレージサービスです。AWS Glue Catalogを作成することで、VeloDB CloudでAWS Glueによって管理されたメタデータを使用して、Amazon S3に保存されているデータレークTableを直接クエリできます。
VeloDB CloudはAWS Glue経由で以下の2つのTable形式へのアクセスをサポートしています:
- Iceberg: ACIDトランザクション、Schema Evolution、Time Travelをサポートする現代的なオープンTable形式。
- Hive: Hadoopエコシステムと幅広く互換性のある従来のHiveTable形式。
前提条件
AWS Glue Catalogを作成する前に、以下の条件が満たされていることを確認してください:
AWSの準備
- AWSアカウントを所有していること。
- Amazon S3バケットを準備すること(IcebergまたはHiveTableデータの保存用)。
- アクセス認証情報(Access KeyまたはIAM Role)を準備し、対応するGlueとS3の権限を設定すること。
- Lake Formation権限を設定すること(Lake Formation権限制御が有効になっている場合)。
AWS権限設定
1. IAM権限ポリシー
VeloDBを使用してAWS Glue Catalog経由でS3に保存されているIcebergまたはHiveTableにアクセスするには、以下のIAM権限ポリシーを設定する必要があります:
{
"Version": "2012-10-17",
"Statement": [
{
"Sid": "GlueCatalogAccess",
"Effect": "Allow",
"Action": [
"glue:GetDatabase",
"glue:GetDatabases",
"glue:CreateDatabase",
"glue:UpdateDatabase",
"glue:DeleteDatabase",
"glue:GetTable",
"glue:GetTables",
"glue:GetTableVersion",
"glue:GetTableVersions",
"glue:CreateTable",
"glue:UpdateTable",
"glue:DeleteTable",
"glue:GetPartition",
"glue:GetPartitions",
"glue:BatchGetPartition",
"glue:CreatePartition",
"glue:UpdatePartition",
"glue:DeletePartition",
"glue:BatchCreatePartition",
"glue:BatchUpdatePartition",
"glue:BatchDeletePartition",
"glue:GetUserDefinedFunction",
"glue:GetUserDefinedFunctions",
"glue:DeleteUserDefinedFunction"
],
"Resource": [
"arn:aws:glue:<region>:<account-id>:catalog",
"arn:aws:glue:<region>:<account-id>:database/*",
"arn:aws:glue:<region>:<account-id>:table/*/*",
"arn:aws:glue:<region>:<account-id>:userDefinedFunction/*/*"
]
},
{
"Sid": "S3DataAccess",
"Effect": "Allow",
"Action": [
"s3:GetObject",
"s3:GetObjectVersion",
"s3:PutObject",
"s3:DeleteObject",
"s3:ListBucket",
"s3:GetBucketLocation",
"s3:AbortMultipartUpload",
"s3:ListMultipartUploadParts"
],
"Resource": [
"arn:aws:s3:::<bucket-name>",
"arn:aws:s3:::<bucket-name>/*"
]
}
]
}
設定手順
<region>を実際のAWSリージョン(例:us-east-1)に置き換えてください。
<account-id>をあなたのAWSアカウントIDに置き換えてください。
<bucket-name>をIcebergまたはHiveTableデータが保存されている実際のS3バケット名に置き換えてください。より細かい権限制御のため、
*を具体的なデータベース名とTable名に置き換えてください。
2. Lake Formation権限設定
あなたのAWSアカウントでLake Formation権限制御が有効になっている場合、Glue データカタログにアクセスするには、IAMポリシーの設定だけでは不十分で、Lake Formationでも対応する権限を付与する必要があります。
有効かどうかを判断する方法は?
Insufficient Lake Formation permission(s)のようなエラーが発生した場合、Lake Formation権限の設定が必要であることを示しています。
-
AWS Lake Formationコンソールにログインします。
-
左側のナビゲーションバーでData permissionsを選択します。
-
Grantをクリックします。
-
以下のオプションを設定します:
- Principals: IAM users and rolesを選択し、あなたのIAMユーザーまたはロールを選択します。
- LF-Tags or catalog resources: Named データカタログ resourcesを選択します。
- カタログ: あなたのカタログを選択します。
- Databases: 対象データベースまたはAll databasesを選択します。
- Tables: 対象TableまたはAll tablesを選択します。
-
必要な権限にチェックを入れます:
- Database permissions: Create database、Alter、Drop、Describe。
- Table permissions: Select、Insert、Delete、Describe、Alter、Drop。
-
Grantをクリックします。
ネットワーク要件
- VeloDB CloudがAWS Glueサービスエンドポイントにアクセスできる必要があります。
- VeloDB Cloudがデータストレージ(例:S3)にアクセスできる必要があります。
SaaSモードのVeloDB Cloudの場合
- Warehouseと同じリージョンのGlue EndpointsとS3 Bucketsにのみアクセス可能です。
BYOCモードのVeloDB Cloudの場合
- Glue EndpointとS3 Bucketサービスへのアクセスには、デプロイ時のネットワークポリシーを参照する必要があります。create-vpc-network-resourcesを参照してください。
Catalog作成
以下の手順に従って、VeloDB CloudでAWS Glue Catalogを作成します。
ステップ1:作成ページに入る
- VeloDB Cloudコンソールにログインします。
- 左側のナビゲーションバーでCatalogsをクリックします。
- Add 外部カタログボタンをクリックします。
- Data Lakeカテゴリの下でAWS Glueを選択します。
ステップ2:基本情報を入力
Basic Informationセクションで、Catalogの基本識別情報を設定します。

| フィールド | 必須 | 説明 |
|---|---|---|
| カタログ Name | ✓ | Catalogの一意名で、SQLクエリでこのデータソースを識別するために使用されます。 |
| Comment | オプションの説明情報。 |
ステップ3:Metastoreを設定
Metastoreセクションで、AWS Glueメタデータサービスの接続情報を設定します。
Table形式を選択
まず、アクセスしたいTable形式を選択します。Table形式が異なれば、必要なパラメータも異なります。
| Table形式 | 説明 |
|---|---|
| Iceberg | Apache IcebergオープンTable形式。 |
| Hive | 従来のHiveTable形式。 |
Iceberg形式設定
Iceberg形式を選択した場合、以下のパラメータを設定する必要があります:
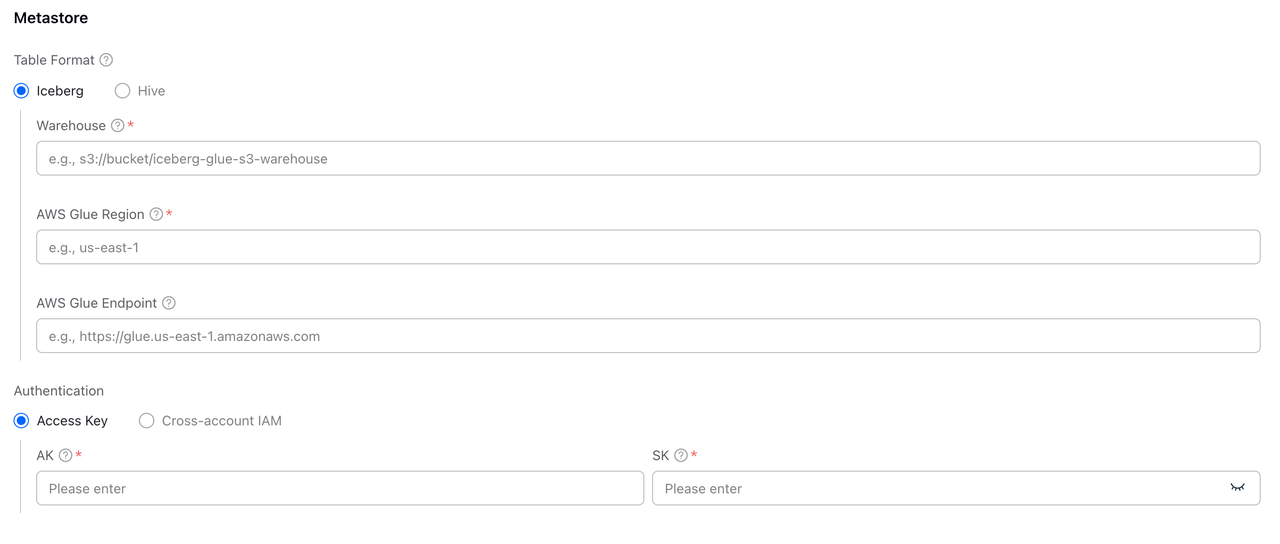
| フィールド | 必須 | 説明 |
|---|---|---|
| Warehouse | ✓ | VeloDBがIcebergデータベースを作成する際のデフォルトのデータファイル保存場所。形式はS3 URI、例:s3://my-bucket/iceberg-warehouse。 |
| AWS Glue Region | ✓ | AWS Glueサービスが配置されているリージョン。 |
| AWS Glue Endpoint | ✓ | AWS Glue APIエンドポイント、例:https://glue.us-east-1.amazonaws.com。 |
Hive形式設定
Hive形式を選択した場合、以下のパラメータを設定する必要があります:
注意: Hive形式は現在クエリのみをサポートし、データベースやTableの作成はサポートしていません。
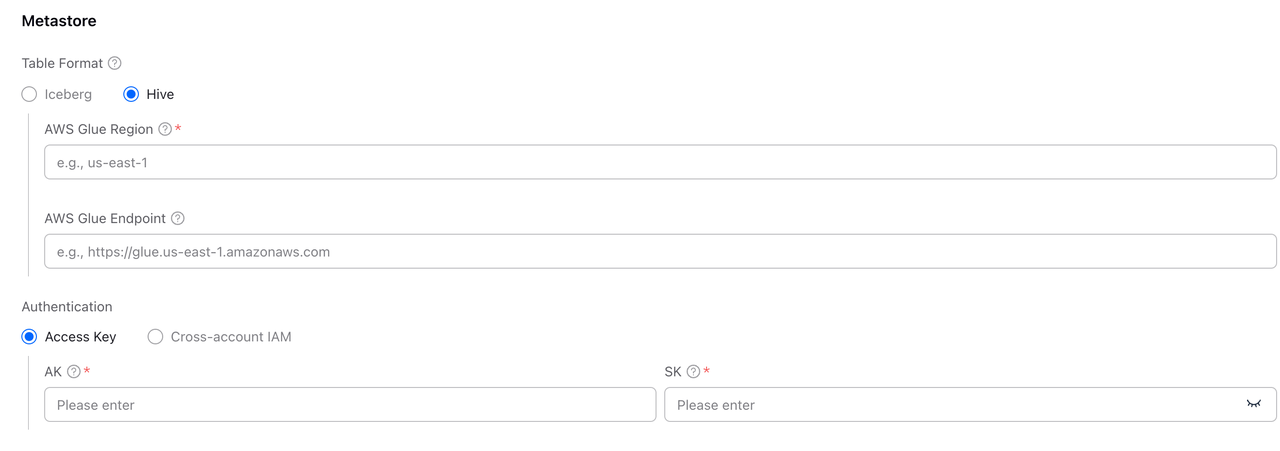
| フィールド | 必須 | 説明 |
|---|---|---|
| AWS Glue Region | ✓ | AWS Glueサービスが配置されているリージョン。 |
| AWS Glue Endpoint | ✓ | AWS Glue APIエンドポイント、例:https://glue.us-east-1.amazonaws.com。 |
ステップ4:Metastore認証を設定
認証セクションで、AWS Glueメタデータサービスにアクセスするための認証情報を設定します。
VeloDB Cloudは2つの認証方式をサポートしています:
方式1:Access Key
AWS IAMユーザーのアクセスキーを使用して認証します。最もシンプルな設定方法で、迅速なテストや開発環境に適しています。

| フィールド | 必須 | 説明 |
|---|---|---|
| AK | ✓ | AWS Access Key ID。 |
| SK | ✓ | AWS Secret Access Key。 |
セキュリティ推奨事項:
- AWSルートアカウントのアクセスキーを使用しないでください。
- VeloDB Cloud専用のIAMユーザーを作成してください。
- 最小権限の原則に従い、必要なGlueとS3権限のみを付与してください。
- アクセスキーを定期的にローテーションしてください。
方式2:クロスアカウントIAM
クロスアカウントIAMロールを使用して認証します。より安全な方式で、本番環境での使用を推奨します。
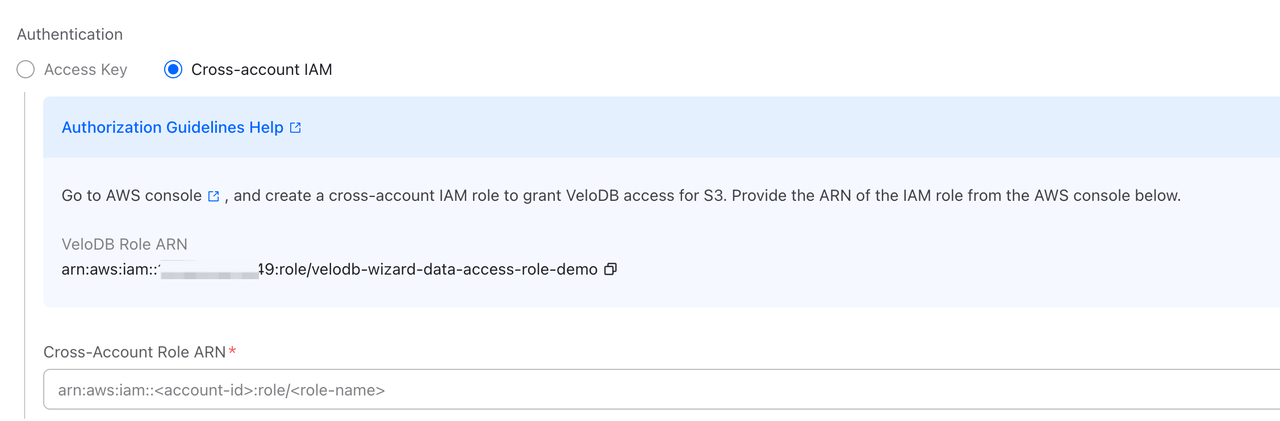
| フィールド | 必須 | 説明 |
|---|---|---|
| Cross-Account Role ARN | ✓ | あなたのAWSアカウントで作成したIAMロールのARN。形式はarn:aws:iam::<your-account-id>:role/<role-name>。 |
設定手順:
ページ上のAuthorization Guidelines Helpリンクをクリックして詳細な設定手順を確認してください。
ステップ5:ストレージアクセスを設定
Storageセクションで、S3のデータファイルにアクセスするための認証情報を設定します。
VeloDB CloudはS3に保存されている実際のデータファイルにアクセスする必要があります。Metastore認証情報を再利用するか、ストレージアクセス認証情報を別々に設定することができます。
Metastore認証を再利用
Use the authentication details configured for Metastore accessスイッチをオンにして、MetastoreとしてS3にアクセスするのと同じ認証情報を使用します。

適用シナリオ:
- GlueメタデータとS3データが同じAWSアカウントにある。
- 同じIAMユーザー/ロールを使用してGlueとS3にアクセスする。
- 設定を簡素化したい。
ストレージ認証を個別に設定
Use the authentication details configured for Metastore accessスイッチをオフにして、S3アクセス用の認証情報を別々に設定します。
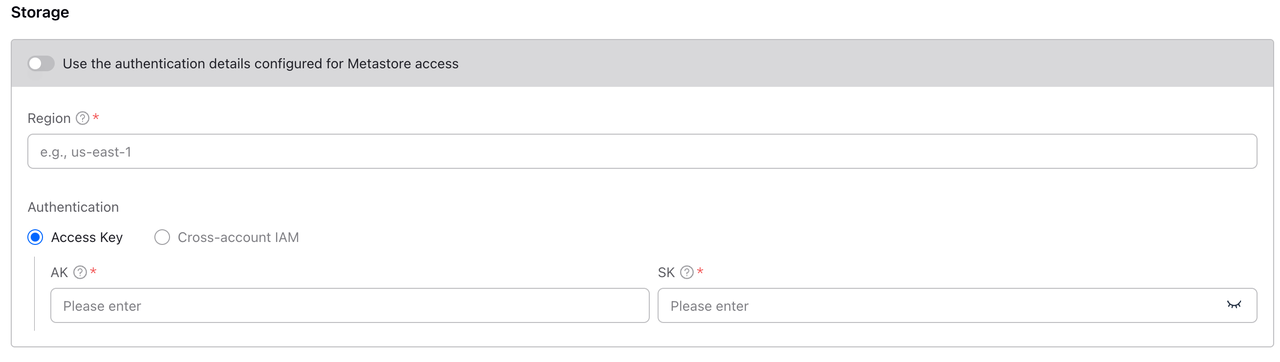
| フィールド | 必須 | 説明 |
|---|---|---|
| Region | ✓ | S3バケットが配置されているリージョン。Glueと同じリージョンである必要があります。 |
| 認証 | ✓ | Access KeyまたはCross-account IAMを選択;設定方法はMetastore認証と同じです。 |
認証方式1:Access Key
AWS IAMユーザーのアクセスキーを使用して認証します。

| フィールド | 必須 | 説明 |
|---|---|---|
| AK | ✓ | AWS Access Key ID。 |
| SK | ✓ | AWS Secret Access Key。 |
認証方式2:クロスアカウントIAM
クロスアカウントIAMロールを使用して認証します。より安全で本番環境での使用を推奨します。
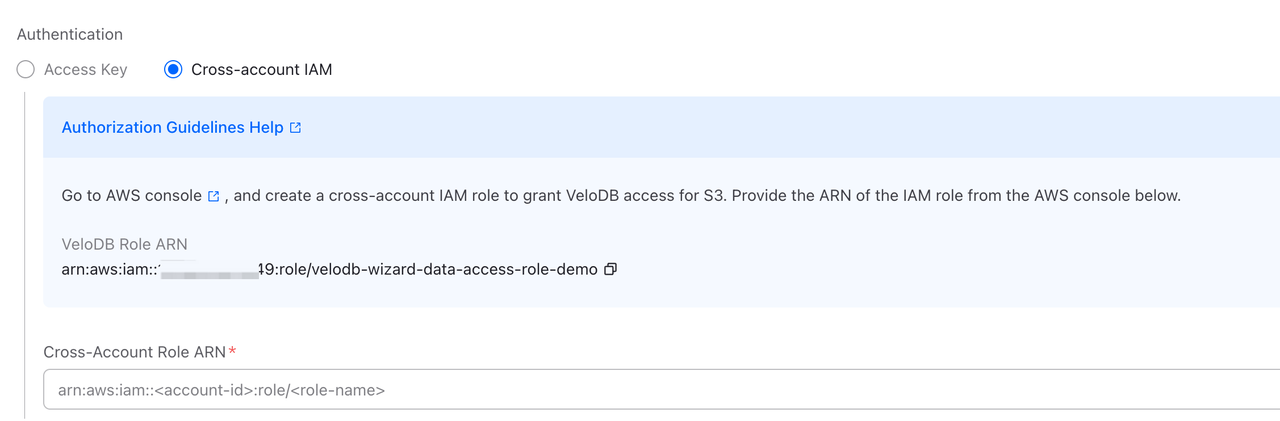
| フィールド | 必須 | 説明 |
|---|---|---|
| Cross-Account Role ARN | ✓ | あなたのAWSアカウントで作成したIAMロールのARN。形式はarn:aws:iam::<your-account-id>:role/<role-name>。 |
設定手順:
Authorization Guidelines Helpリンクをクリックして詳細な設定手順を確認してください。
適用シナリオ:
- GlueとS3データが異なるAWSアカウントにある。
- メタデータアクセスとデータアクセスに異なる権限制御を使用する必要がある。
ステップ6:詳細設定(オプション)
Advanced Settingsをクリックしてより多くの設定オプションを展開します。

詳細設定には通常以下が含まれます:
- メタデータキャッシュ設定。
- 接続タイムアウト設定。
ヒント: ほとんどのシナリオでは、デフォルト値で十分です。
ステップ7:作成確認
- すべての設定情報が正しいかどうかを確認します。
- ConfirmボタンをクリックしてCatalogを作成します。
- 接続検証の完了を待ちます。
作成成功後、Catalogリストで新しく作成されたAWS Glue Catalogを確認できます。
Catalogの使用
作成成功後、SQL EditorでCatalogを使用してデータをクエリできます。
データベースとTableの表示
-- View all databases under the カタログ
SHOW DATABASES FROM my_glue_catalog;
-- View all tables under a database
SHOW TABLES FROM my_glue_catalog.my_database;
-- View table schema
DESCRIBE my_glue_catalog.my_database.my_table;
Query Data
-- Query data
SELECT * FROM my_glue_catalog.my_database.my_table LIMIT 100;
-- Query with conditions
SELECT column1, column2
FROM my_glue_catalog.my_database.my_table
WHERE date_column >= '2024-01-01';