Confluent Cloudに接続
このガイドでは、ビジュアルインターフェースを使用してVeloDB CloudをConfluent Cloud Kafkaに接続する手順を説明します。
前提条件: 先に進む前に、Confluent Cloud Setup Guideを完了して、クラスター、APIキー、およびサンプルデータトピックを作成してください。
ステップ1: Importに移動
VeloDBウェアハウスで、左サイドバーのDataセクションを探し、Importをクリックします。
Createをクリックして新しいインポートジョブを開始します。
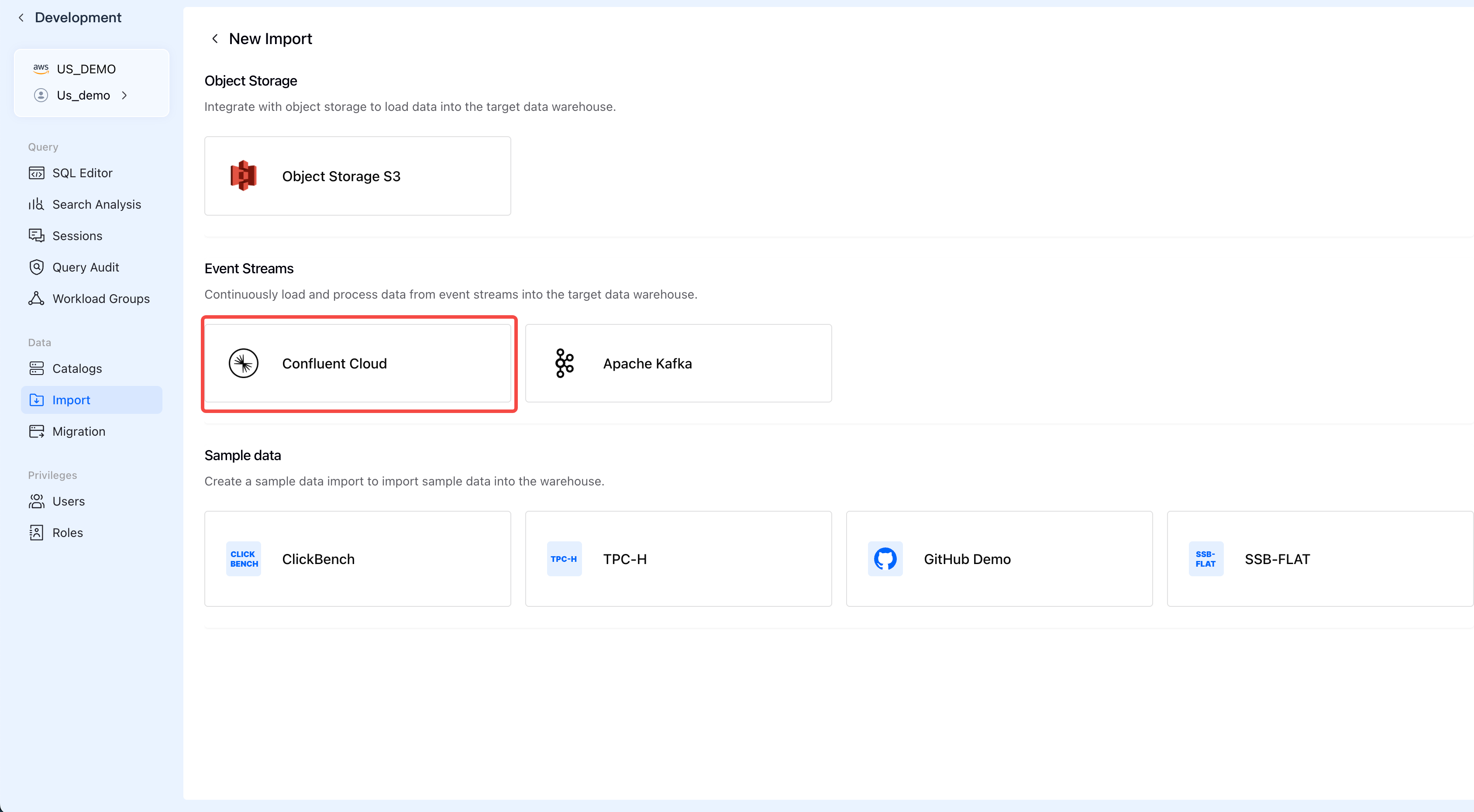
ステップ2: Confluent Cloudを選択
Event Streamsの下で、Confluent Cloudをクリックしてストリーミングインポートウィザードを開始します。
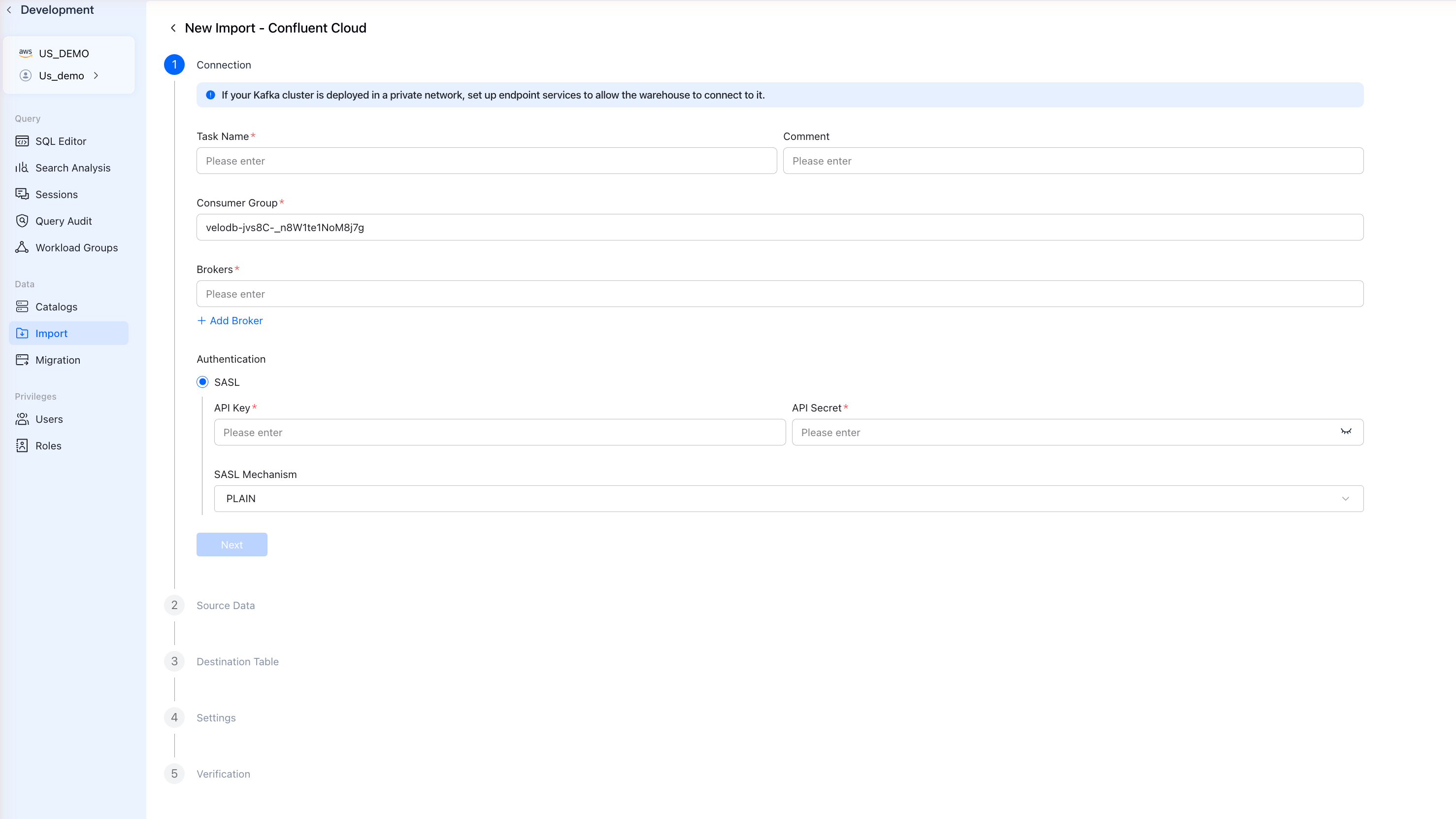
ステップ3: 接続を設定
Confluent Cloud Setupからの接続詳細を入力します:
| フィールド | 説明 | 例 |
|---|---|---|
| Task Name | このインポートジョブの一意の名前 | confluent_orders |
| Consumer Group | KafkaコンシューマーグループID | velodb-consumer |
| Brokers | BootstrapサーバーURL | pkc-xxxxx.us-east-1.aws.confluent.cloud:9092 |
| API Key | Confluent Cloud APIキー | Your API Key |
| API Secret | Confluent Cloud APIシークレット | Your API Secret |
| SASL Mechanism | 認証方法 | PLAIN |
すべてのフィールドを入力後、Nextをクリックします。
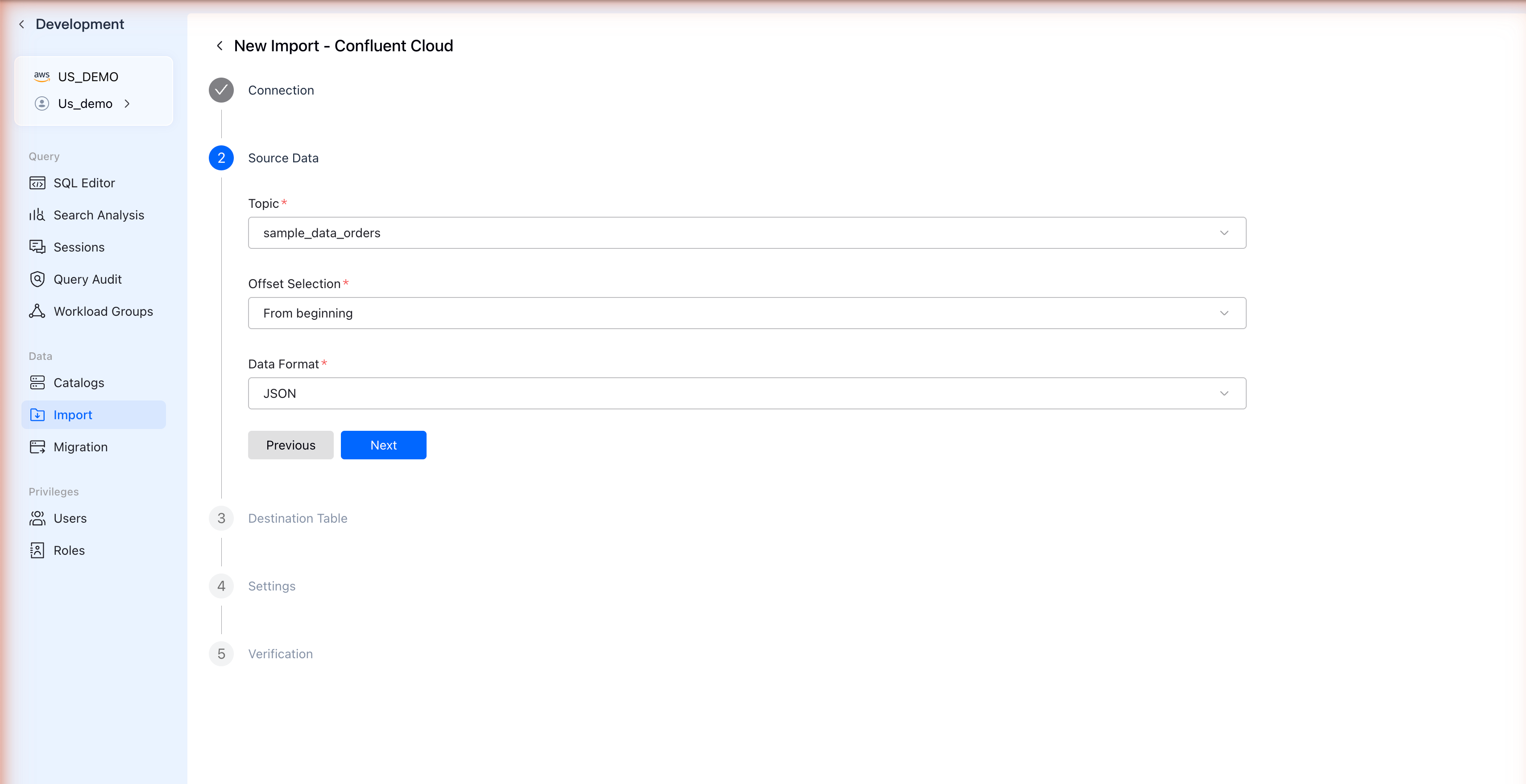
ステップ4: ソースデータを選択
Kafkaトピックとデータフォーマットを設定します:
| フィールド | 説明 |
|---|---|
| Topic | ドロップダウンからKafkaトピックを選択 |
| Offset Selection | すべてのデータを読み込む場合はFrom beginning、新しいデータのみの場合はFrom latest |
| Data Format | JSONを選択 |
VeloDBはJSONとCSVフォーマットのみをサポートします。ConfluentトピックでAVROを使用している場合は、Confluent CloudでJSONフォーマットの新しいトピックを作成する必要があります。
Nextをクリックして続行します。
ステップ5: 宛先Tableを設定
VeloDBはKafkaメッセージからスキーマを自動的に検出します:
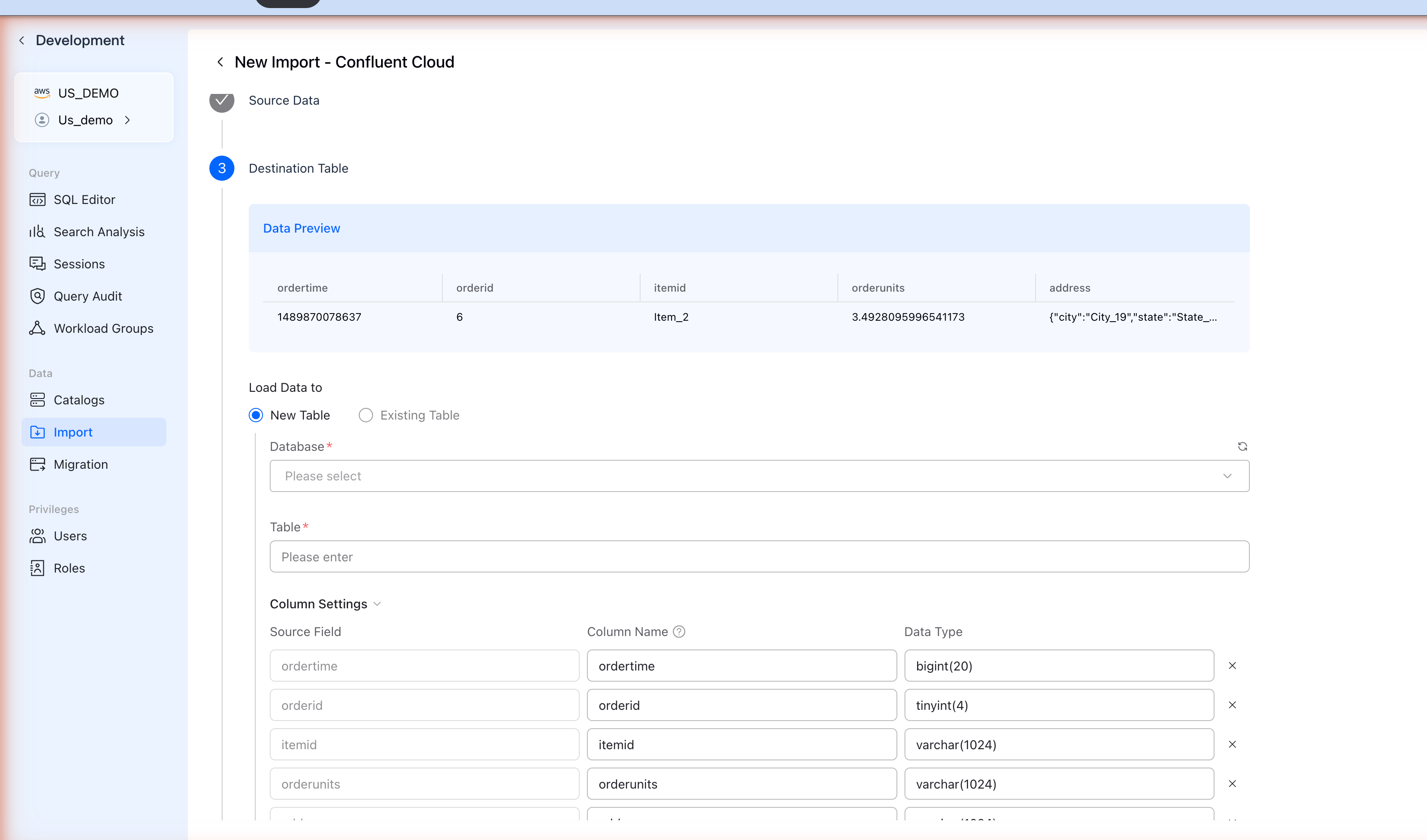
Data Previewセクションには、トピックからのサンプルレコードが表示されます。
Table設定を構成
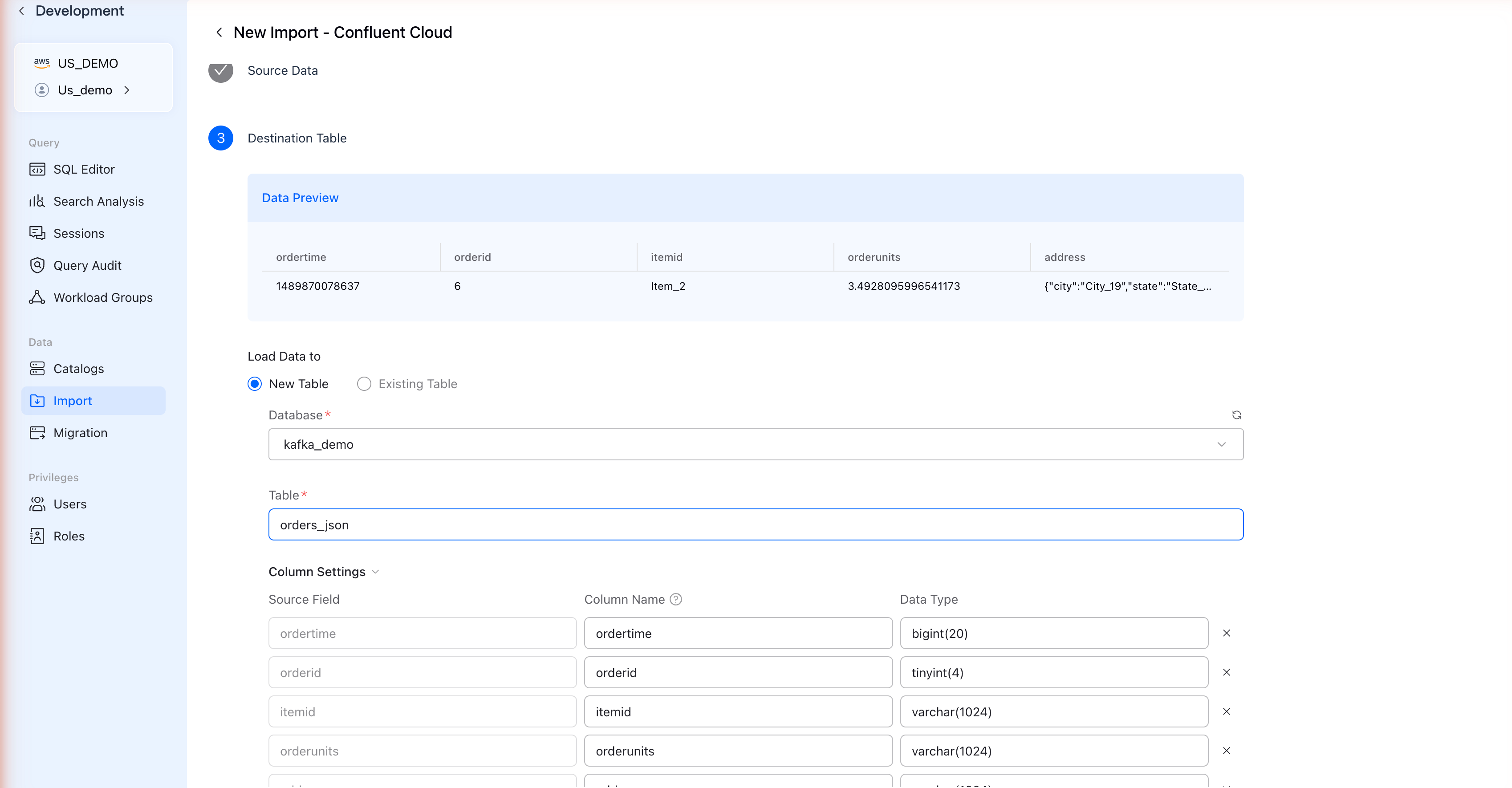
| フィールド | 説明 |
|---|---|
| Load Data to | 新しいTableを作成するにはNew Tableを選択 |
| Database | データベースを選択または作成 |
| Table | Table名を入力 |
カラム設定
カラムマッピングを確認して調整します:
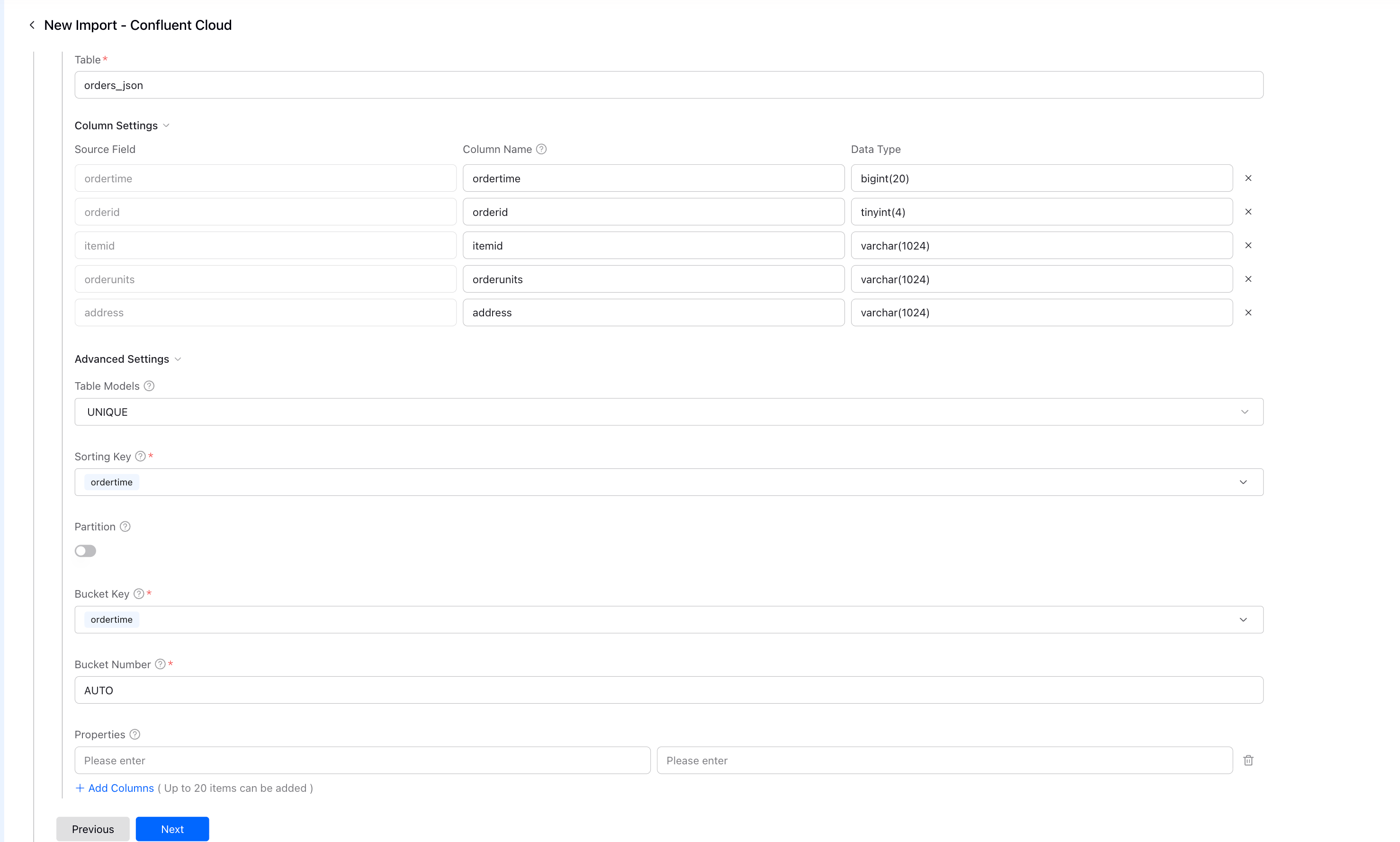
| 設定 | 説明 |
|---|---|
| Source Field | KafkaメッセージからのJSONフィールド |
| Column Name | VeloDBTableのカラム名 |
| Data タイプ | VeloDBデータタイプ(自動検出) |
詳細設定
| 設定 | 説明 |
|---|---|
| Table Models | 追記専用の場合はDUPLICATE、アップサートの場合はUNIQUE |
| Sorting Key | データ順序付けのためのカラム |
| バケット Key | データ分散のためのカラム |
| バケット Number | AUTOを推奨 |
Nextをクリックして続行します。
ステップ6: 設定を構成
インポートジョブの設定を調整します:
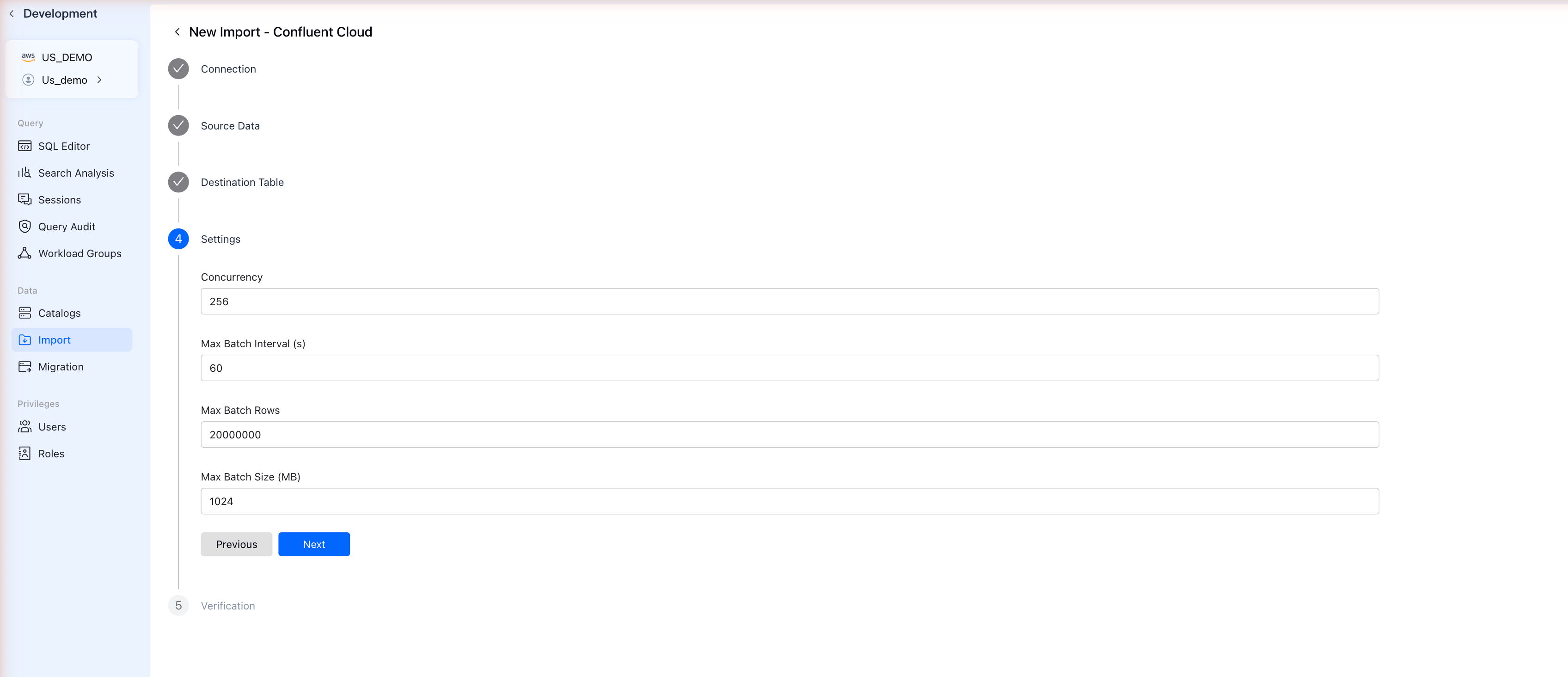
| 設定 | デフォルト | 説明 |
|---|---|---|
| Concurrency | 256 | 並列コンシューマー数 |
| Max Batch Interval (s) | 60 | コミット前の最大待機時間 |
| Max Batch Rows | 20000000 | バッチあたりの最大行数 |
| Max Batch Size (MB) | 1024 | 最大バッチサイズ |
デフォルトは大部分のユースケースで適切に動作します。Nextをクリックして続行します。
ステップ7: 検証
VeloDBが設定を検証します:
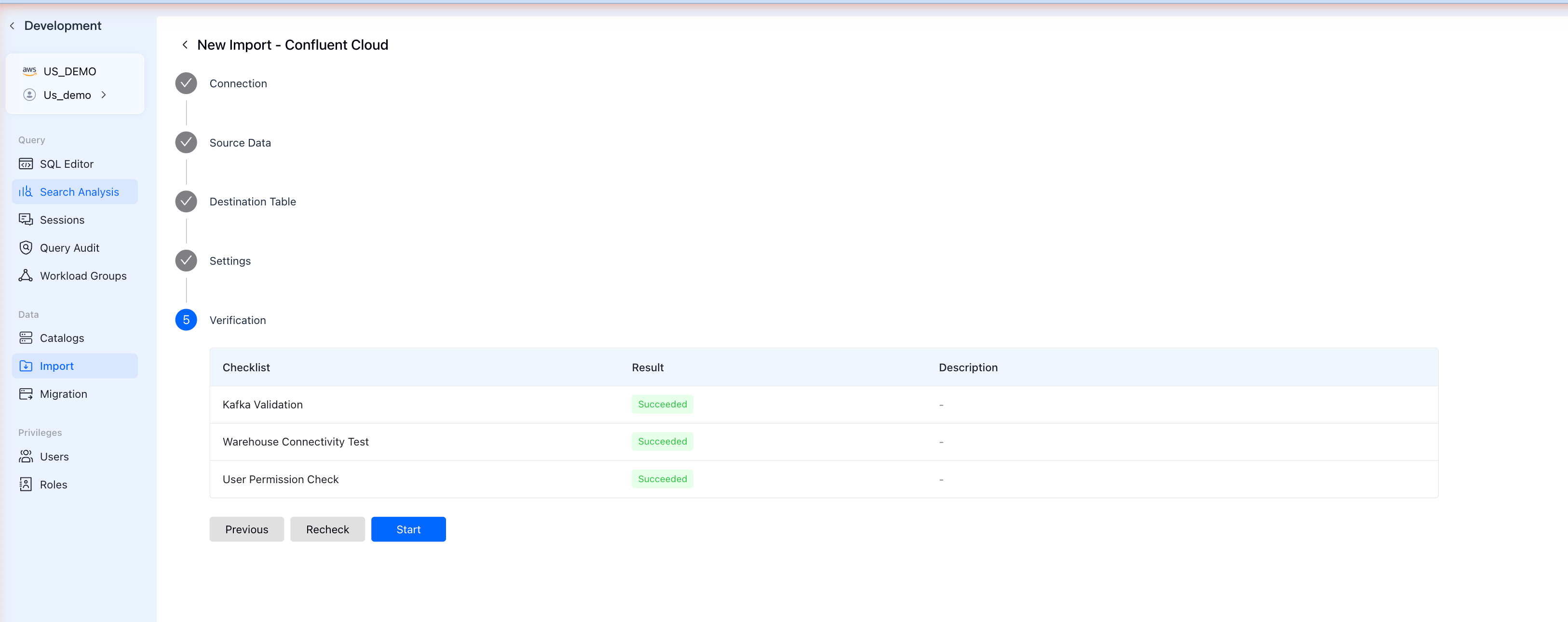
チェックリストが以下を検証します:
- Kafka Validation - Confluent Cloudへの接続
- Warehouse Connectivity Test - VeloDBがKafkaに到達可能か
- User 許可 Check - インポート作成の権限があるか
すべてのチェックがSucceededと表示された場合、Startをクリックしてデータストリーミングを開始します。
データインポートを確認
インポートを開始した後、データが流れているか確認します:
インポートステータスを確認
サイドバーのImportに移動してジョブステータスを確認します:
- RUNNING - ジョブがアクティブにデータを消費中
- PAUSED - ジョブが一時停止中(エラーを確認)
データをクエリ
SQL Editorに移動して次を実行します:
-- Check row count
SELECT COUNT(*) FROM your_database.your_table;
-- View sample data
SELECT * FROM your_database.your_table LIMIT 10;
インポートジョブの管理
| アクション | 方法 |
|---|---|
| 一時停止 | ジョブをクリックし、Pauseをクリック |
| 再開 | ジョブをクリックし、Resumeをクリック |
| 削除 | ジョブをクリックし、Deleteをクリック |
またはSQLを使用:
-- Pause job
PAUSE ROUTINE LOAD FOR database.job_name;
-- Resume job
RESUME ROUTINE LOAD FOR database.job_name;
-- Stop job
STOP ROUTINE LOAD FOR database.job_name;
-- View job status
SHOW ROUTINE LOAD FOR database.job_name;
トラブルシューティング
| 問題 | 解決方法 |
|---|---|
| "Incorrect credentials" | Confluent CloudからAPI KeyとSecretを確認してください |
| "Broker transport failure" | SASL MechanismがPLAINに設定されていることを確認してください |
| "Topic not found" | トピック名が正確に一致することを確認してください(大文字小文字を区別) |
| JSON parse error | ConfluentトピックがAVROではなくJSON形式を使用していることを確認してください |
| Job paused with errors | エラーの詳細についてSHOW ROUTINE LOADを確認してください |
参考資料
- Confluent Cloud Setup Guide
- Kafka 統合 Guide - SQLベースのセットアップとその他のKafkaプロバイダー向け
- CREATE ROUTINE LOAD