Console経由でのデータインポート
このガイドでは、Consoleのビジュアルインターフェースを使用して、オブジェクトストレージ(AWS S3、Google Cloud Storage、Azure Blob Storage)からVeloDBにデータをインポートする手順を説明します。
前提条件
開始前に、以下を準備してください:
- データファイルを含むオブジェクトストレージバケット
- アクセス認証情報(Access Key IDとSecret Access Key)
- アクティブなクラスターを持つVeloDB Cloudアカウント(Quick Startを参照)
サンプルデータでの試用
サンプルデータセットを使用してS3インポートを試すには、以下の認証情報を使用してください:
| フィールド | 値 |
|---|---|
| AK | AKIA3AUKURBS74337SNB |
| SK | ygbR1HGNvMZDTo4DNUWJx0mblpMTF+QpBCCBfxFF |
| Object Storage Path | https://velodb-import-data-us-east-1.s3.us-east-1.amazonaws.com/ssb-flat-sf1/*.parquet |
このサンプルデータセットには**SSB(Star Schema Benchmark)**データが含まれています - 分析データベースで広く使用されているベンチマークです。このデータセットには、注文、顧客、サプライヤー、製品をカバーする42カラムの非正規化された売上データの約600万行が含まれています。
SSBデータセットスキーマ(42カラム)
| カラムグループ | カラム |
|---|---|
| Order | lo_orderkey, lo_linenumber, lo_orderdate, lo_commitdate, lo_orderpriority, lo_shippriority, lo_shipmode, lo_year, lo_month, lo_weeknum |
| Metrics | lo_quantity, lo_extendedprice, lo_discount, lo_revenue, lo_supplycost, lo_tax |
| Date | d_datekey, d_dayofweek, d_month, d_yearmonth |
| Customer | c_custkey, c_name, c_nation, c_region, c_city, c_mktsegment |
| Supplier | s_suppkey, s_name, s_nation, s_region, s_city |
| Product | p_partkey, p_name, p_brand, p_category, p_mfgr, p_color, p_type, p_size, p_container |
これは読み取り専用のサンプルデータです。以下のチュートリアル手順に従って使用できます。
ステップ1: 接続
VeloDB ConsoleサイドバーのData > Importに移動し、Create newをクリックしてObject Storage S3を選択します。
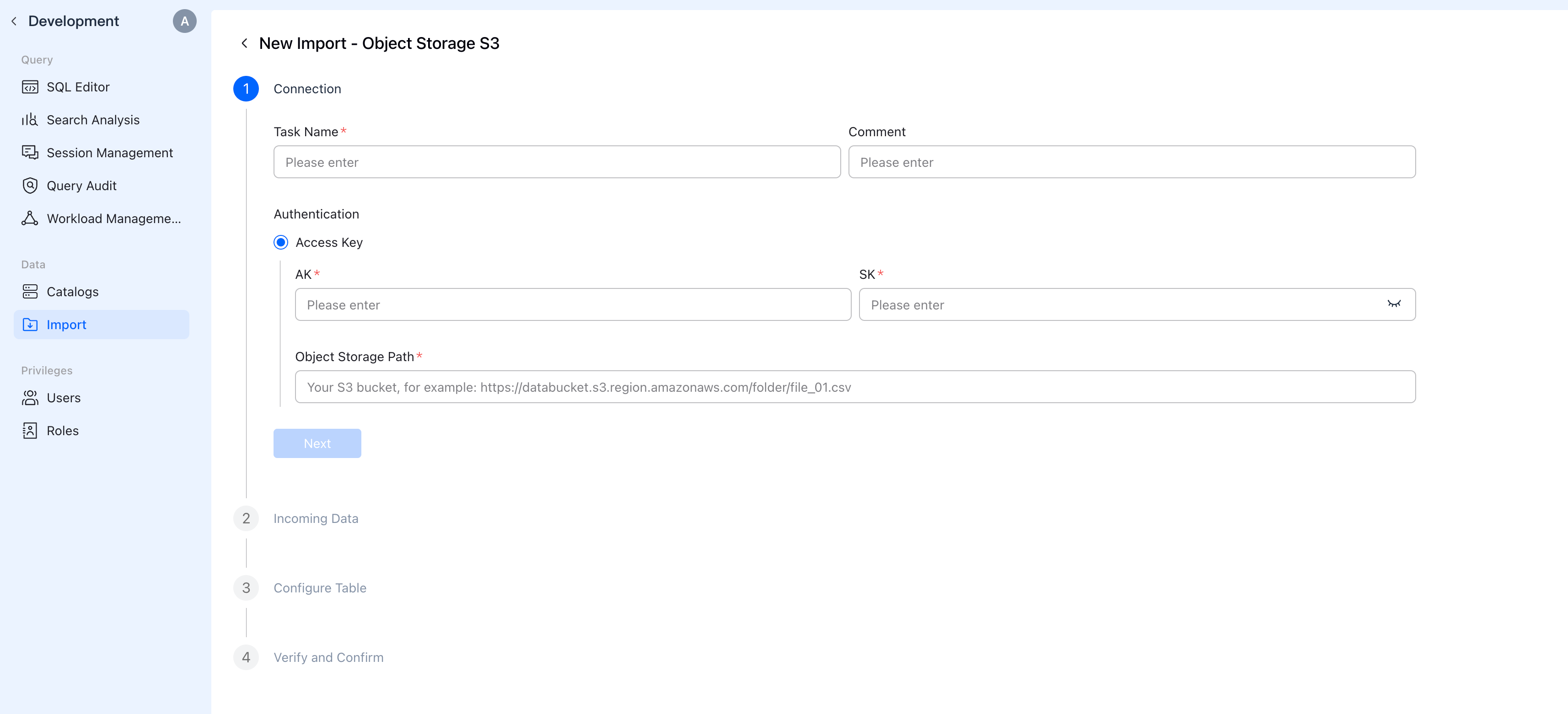
設定
| フィールド | 説明 |
|---|---|
| Task Name | このインポートタスクの一意の名前(例:sales_data、user_logs) |
| コメント | (オプション) インポートタスクの説明 |
| 認証 | Access Key認証を選択 |
| AK | Your Access Key ID(例:AKIAIOSFODNN7EXAMPLE) |
| SK | Your Secret Access Key |
| Object Storage Path | データへのURL(以下の形式を参照) |
Object Storage Pathの形式
https://<bucket-name>.s3.<region>.amazonaws.com/<path>/<filename>
パス形式の例(実際のバケットとファイルパスに置き換えてください):
- 単一ファイル:
https://my-bucket.s3.us-west-1.amazonaws.com/data/orders.csv - ワイルドカードを使用した複数ファイル:
https://my-bucket.s3.us-west-1.amazonaws.com/data/*.csv - Parquetファイル:
https://my-bucket.s3.us-west-1.amazonaws.com/warehouse/*.parquet
最適なパフォーマンスのため、オブジェクトストレージバケットはVeloDBクラスターと同じリージョンに配置する必要があります。
Nextをクリックして続行します。
ステップ2:受信データ
VeloDBがデータファイルを解析する方法を設定します。

ファイル設定
| フィールド | 説明 |
|---|---|
| File タイプ | ファイル形式を選択:CSV、Parquet、ORC、またはJSON |
| File Compression | 自動検出または指定:GZ、BZ2、LZ4、LZO、DEFLATE、ZSTD、ZLIB |
| Specify Delimiter | 列区切り文字(CSVの場合は,、TSVの場合は\t) |
| Enclose | テキストフィールドの引用符文字(通常は空のままにします) |
| Escape | エスケープ文字(通常は空のままにします) |
| Trim Double Quotes | 値から引用符を削除するかどうか |
| File Size | サイズ制限を設定するか、Unlimitedのままにします |
ロード設定
| フィールド | 説明 |
|---|---|
| Strict Mode | ON = エラーのある行を拒否、OFF = 不正な行をスキップ |
標準的なCSVファイルの場合、通常はデフォルト設定で動作します。解析エラーを避けるため、EncloseとEscapeは空のままにしてください。
Nextをクリックして続行します。
ステップ3:Table設定
データをプレビューし、宛先Tableを設定します。
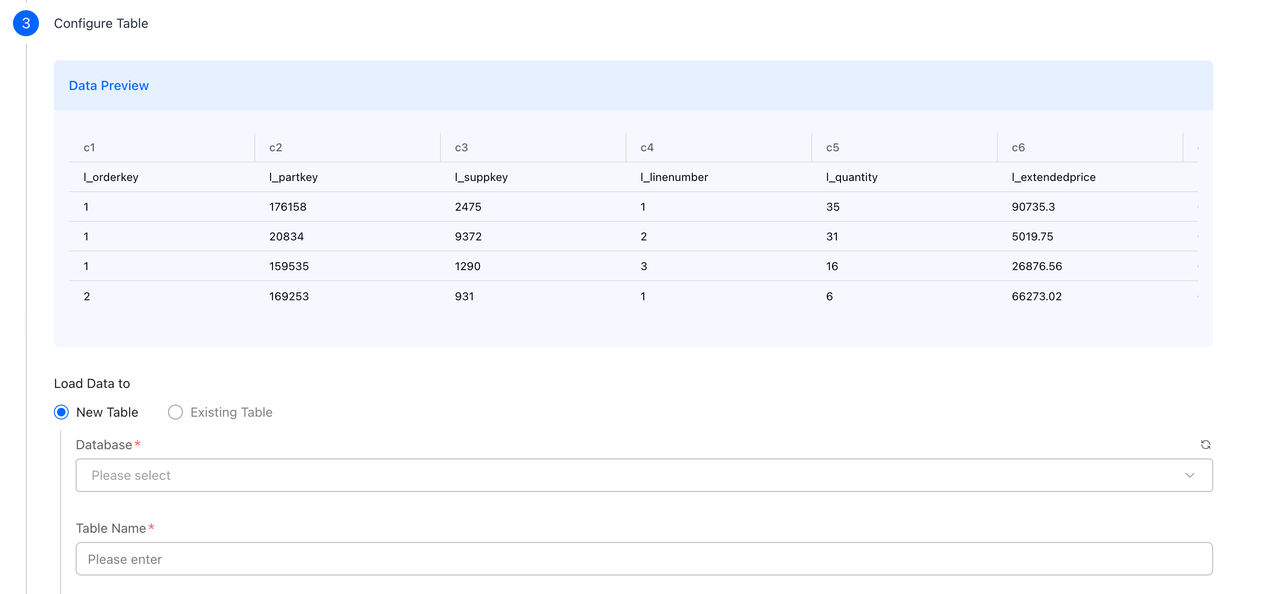
データプレビュー
コンソールには以下の情報を含むデータのプレビューが表示されます:
- 自動検出された列名(c1、c2、c3、...またはCSVヘッダー行から)
- サンプルデータ行
- 推測された列の型
データのロード先
| オプション | 説明 |
|---|---|
| New Table | 自動生成されたスキーマで新しいTableを作成 |
| Existing Table | 既存のVeloDBTableにロード |
Table設定
| フィールド | 説明 |
|---|---|
| Database | ドロップダウンからターゲットデータベースを選択 |
| Table Name | 新しいTableの名前(例:orders、user_events、products) |
ステップ4:詳細設定
Tableモデルと分散設定を構成します。
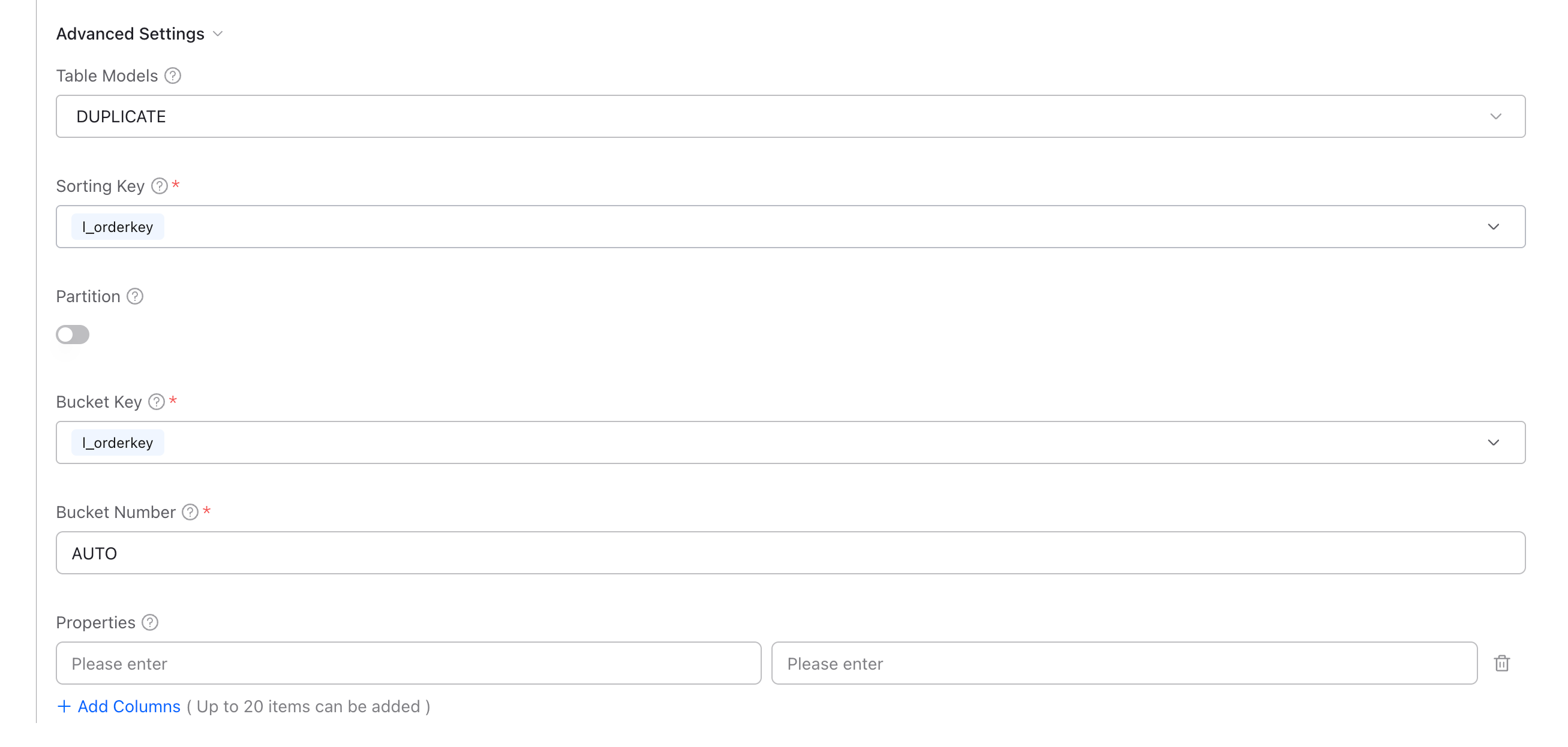
Tableモデル
| モデル | 用途 | 例 |
|---|---|---|
| DUPLICATE | 生データ、アドホッククエリ - 書き込まれたすべての行を保持 | イベントログ、クリックストリーム、生のトランザクション |
| UNIQUE | 更新を含むデータ - キーごとに最新の行のみを保持 | ユーザープロフィール、商品カタログ、ディメンションTable |
| AGGREGATE | 事前集計されたメトリクス - キー列で自動集計 | 売上サマリー、時系列メトリクス、カウンター |
分散設定
| フィールド | 説明 |
|---|---|
| Sorting Key | データ順序付けのための列 - WHERE句やJOINで頻繁に使用される列を選択 |
| パーティション | 日付/時間やその他のディメンションによるパーティショニングを有効にしてクエリパフォーマンスを向上 |
| バケット Key | ノード間でのハッシュ分散のための列(クエリ同時実行性を向上させるためtenant_idやuser_idを使用) |
| バケット Number | データバケットの数(ほとんどの場合AUTOが推奨) |
| Properties | 追加のTableプロパティ(通常は空のまま) |
Nextをクリックして続行し、Submitをクリックしてインポートを開始します。
ステップ5:インポートの監視
送信後、インポートリストでインポートタスクを確認できます。
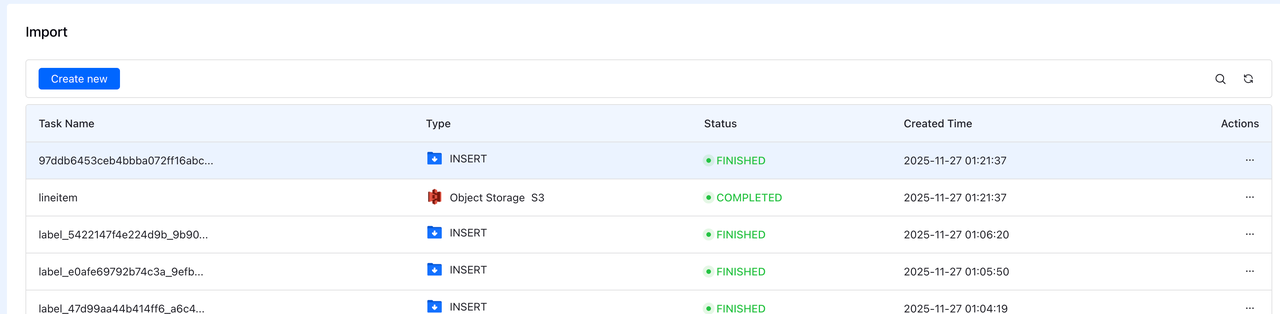
インポートの検証
インポートが完了したら、SQLエディターでデータを検証します:
-- Check row count
SELECT COUNT(*) FROM your_database.your_table;
-- Preview data
SELECT * FROM your_database.your_table LIMIT 10;
-- Check table schema
DESC your_database.your_table;
SSB データのサンプルクエリ
サンプル SSB データセットをインポートした場合は、以下の分析クエリを試してください:
-- Total revenue by year
SELECT
lo_year,
SUM(lo_revenue) as total_revenue
FROM ssb_flat
GROUP BY lo_year
ORDER BY lo_year;
-- Top 10 customers by revenue
SELECT
c_name,
c_nation,
SUM(lo_revenue) as total_revenue
FROM ssb_flat
GROUP BY c_name, c_nation
ORDER BY total_revenue DESC
LIMIT 10;
-- Revenue by region and year
SELECT
c_region,
lo_year,
SUM(lo_revenue) as revenue,
COUNT(*) as order_count
FROM ssb_flat
GROUP BY c_region, lo_year
ORDER BY c_region, lo_year;
-- Product category performance
SELECT
p_category,
p_brand,
SUM(lo_revenue) as revenue,
AVG(lo_discount) as avg_discount
FROM ssb_flat
GROUP BY p_category, p_brand
ORDER BY revenue DESC
LIMIT 20;
トラブルシューティング
| 問題 | 解決方法 |
|---|---|
| "Can not found files" | オブジェクトストレージのパス形式と末尾のスラッシュを確認してください |
| "Access Denied" | AK/SKクレデンシャルとIAMアクセス許可を確認してください |
| Connection timeout | バケットがVeloDBと同じリージョンにあることを確認してください |
| Parsing errors | EncloseフィールドとEscapeフィールドを空のままにしてください |
| Wrong column types | 事前定義されたスキーマでExisting Tableを使用してください |