Doris と Iceberg の使用
新しいオープンデータ管理アーキテクチャとして、Data Lakehouseはデータウェアハウスの高いパフォーマンスとリアルタイム機能を、データレイクの低コストと柔軟性と統合し、ユーザーが様々なデータ処理と分析のニーズをより便利に満たすことを支援します。企業のビッグデータシステムにおいて、ますます適用されています。
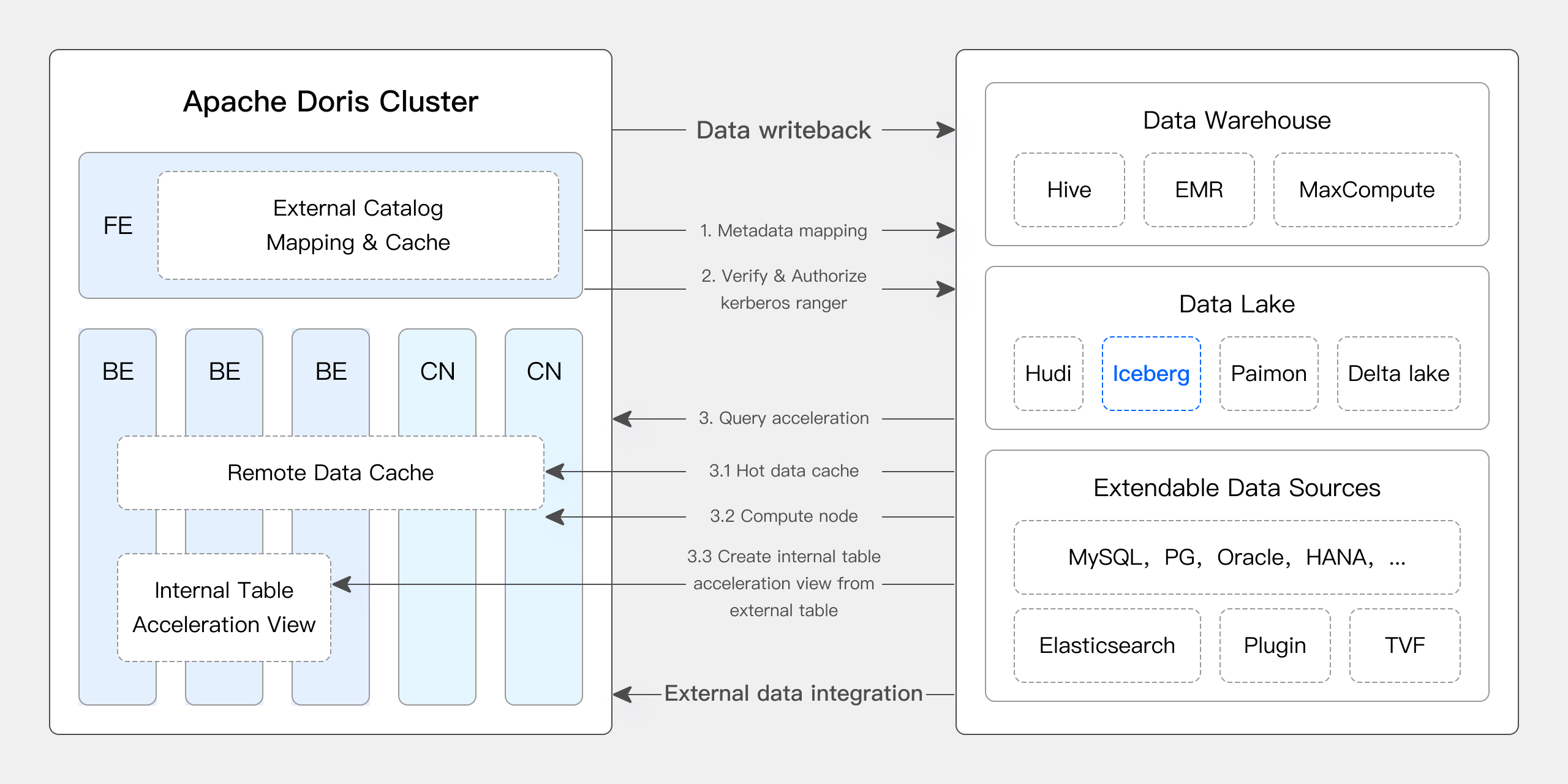
最近のバージョンでは、Apache Dorisはデータレイクとの統合を深め、現在、成熟したData Lakehouseソリューションを提供しています。
- バージョン0.15以降、Apache DorisはHiveとIceberg外部Tableを導入し、データレイク向けのApache Icebergとの組み合わせ機能を探索しました。
- バージョン1.2から、Apache Dorisは正式にMulti-Catalog機能を導入し、様々なデータソースに対する自動メタデータマッピングとデータアクセスを可能にし、外部データ読み取りとクエリ実行における多数のパフォーマンス最適化とともに提供しています。現在、高速でユーザーフレンドリーなLakehouseアーキテクチャの構築を完全にサポートしています。
- バージョン2.1では、Apache DorisはData Lakehouseアーキテクチャをさらに強化し、主要なデータレイクフォーマット(Hudi、Iceberg、Paimonなど)の読み書き機能を向上させ、複数のSQL方言との互換性を導入し、既存システムからApache Dorisへのシームレスな移行を実現しました。データサイエンスと大規模データ読み取りシナリオにおいて、DorisはArrow Flight高速読み取りインターフェースを統合し、データ転送効率の100倍の改善を達成しました。
Apache Doris & Iceberg
Apache Icebergは、大規模データの分析と管理を可能にするオープンソース、高パフォーマンス、高信頼性のデータレイクTableフォーマットです。Apache Dorisを含む様々な主要なクエリエンジンをサポートし、HDFSと様々なオブジェクトクラウドストレージと互換性があり、ACID準拠、スキーマ進化、高度なフィルタリング、隠しパーティショニング、パーティションレイアウト進化などの機能により、高パフォーマンスクエリ、データ信頼性、一貫性、タイムトラベルやバージョンロールバックなどの機能による柔軟性を保証します。
Apache DorisはIcebergのいくつかのコア機能に対してネイティブサポートを提供します:
- Hive Metastore、Hadoop、REST、Glue、Google Dataproc Metastore、DLFなどの複数のIceberg Catalogタイプをサポートします。
- Iceberg V1/V2TableフォーマットとPosition Delete、Equality Deleteファイルの読み取りをネイティブサポートします。
- Table関数を通じてIcebergTableスナップショット履歴のクエリをサポートします。
- Time Travel機能をサポートします。
- IcebergTableエンジンをネイティブサポートします。Apache DorisがIcebergTableを直接作成、管理、書き込みすることを可能にします。包括的なパーティションTransform関数をサポートし、隠しパーティショニングとパーティションレイアウト進化などの機能を提供します。
ユーザーは、Apache Doris + Apache Icebergに基づいて効率的なData Lakehouseソリューションを迅速に構築し、様々なリアルタイムデータ分析と処理のニーズに柔軟に対応できます。
- Dorisの高パフォーマンスクエリエンジンを使用してIcebergTableデータと他のデータソースを関連付けてデータ分析を実行し、統合連合データ分析プラットフォームを構築します。
- Dorisを通じてIcebergTableを直接管理・構築し、Dorisでデータクリーニング、処理、IcebergTableへの書き込みを完了し、データレイク用統合データ処理プラットフォームを構築します。
- IcebergTableエンジンを通じてDorisデータを他の上流・下流システムと共有してさらなる処理を行い、統合オープンデータストレージプラットフォームを構築します。
将来的に、Apache IcebergはApache DorisのネイティブTableエンジンの一つとして機能し、レイクフォーマットデータに対してより包括的な分析・管理機能を提供します。Apache Dorisは、アップデート/Delete/Merge、書き戻し時のソート、増分データ読み取り、メタデータ管理など、Apache Icebergのより高度な機能を段階的にサポートし、統合された高パフォーマンスのリアルタイムデータレイクプラットフォームを共同で構築していきます。
詳細については、Iceberg カタログを参照してください。
ユーザーガイド
このドキュメントでは、主にDocker環境でApache Doris + Apache Icebergのテスト・デモンストレーション環境を迅速にセットアップし、様々な機能の使用方法を実演する方法について説明します。
このドキュメントで言及されているすべてのスクリプトとコードは、こちらのアドレスから入手できます:https://github.com/apache/doris/tree/master/samples/datalake/iceberg_and_paimon
01 環境準備
このドキュメントではDocker Composeを使用してデプロイメントを行い、以下のコンポーネントとバージョンを使用します:
| Component | Version |
|---|---|
| Apache Doris | デフォルト2.1.5、変更可能 |
| Apache Iceberg | 1.4.3 |
| MinIO | RELEASE.2024-04-29T09-56-05Z |
02 環境デプロイメント
-
すべてのコンポーネントを開始
bash ./start_all.sh -
開始後、以下のスクリプトを使用してDorisコマンドラインにログインできます:
-- login doris
bash ./start_doris_client.sh
03 Iceberg Table の作成
Doris コマンドラインにログインした後、Doris クラスタには Iceberg という名前の Iceberg カタログ が既に作成されています(SHOW CATALOGS/SHOW CREATE CATALOG iceberg で表示可能)。以下がこの カタログ の作成ステートメントです:
-- Already created
CREATE CATALOG `iceberg` PROPERTIES (
"type" = "iceberg",
"iceberg.catalog.type" = "rest",
"warehouse" = "s3://warehouse/",
"uri" = "http://rest:8181",
"s3.access_key" = "admin",
"s3.secret_key" = "password",
"s3.endpoint" = "http://minio:9000"
);
Iceberg Catalog内にデータベースとIcebergTableを作成します:
mysql> SWITCH iceberg;
Query OK, 0 rows affected (0.00 sec)
mysql> CREATE DATABASE nyc;
Query OK, 0 rows affected (0.12 sec)
mysql> CREATE TABLE iceberg.nyc.taxis
(
vendor_id BIGINT,
trip_id BIGINT,
trip_distance FLOAT,
fare_amount DOUBLE,
store_and_fwd_flag STRING,
ts DATETIME
)
PARTITION BY LIST (vendor_id, DAY(ts)) ()
PROPERTIES (
"compression-codec" = "zstd",
"write-format" = "parquet"
);
Query OK, 0 rows affected (0.15 sec)
04 データ挿入
IcebergTableにデータを挿入します:
mysql> INSERT INTO iceberg.nyc.taxis
VALUES
(1, 1000371, 1.8, 15.32, 'N', '2024-01-01 9:15:23'),
(2, 1000372, 2.5, 22.15, 'N', '2024-01-02 12:10:11'),
(2, 1000373, 0.9, 9.01, 'N', '2024-01-01 3:25:15'),
(1, 1000374, 8.4, 42.13, 'Y', '2024-01-03 7:12:33');
Query OK, 4 rows affected (1.61 sec)
{'status':'COMMITTED', 'txnId':'10085'}
Iceberg Tableを CREATE TABLE AS SELECT を使用して作成する:
mysql> CREATE TABLE iceberg.nyc.taxis2 AS SELECT * FROM iceberg.nyc.taxis;
Query OK, 6 rows affected (0.25 sec)
{'status':'COMMITTED', 'txnId':'10088'}
05 データクエリ
-
シンプルクエリ
mysql> SELECT * FROM iceberg.nyc.taxis;
+-----------+---------+---------------+-------------+--------------------+----------------------------+
| vendor_id | trip_id | trip_distance | fare_amount | store_and_fwd_flag | ts |
+-----------+---------+---------------+-------------+--------------------+----------------------------+
| 1 | 1000374 | 8.4 | 42.13 | Y | 2024-01-03 07:12:33.000000 |
| 1 | 1000371 | 1.8 | 15.32 | N | 2024-01-01 09:15:23.000000 |
| 2 | 1000373 | 0.9 | 9.01 | N | 2024-01-01 03:25:15.000000 |
| 2 | 1000372 | 2.5 | 22.15 | N | 2024-01-02 12:10:11.000000 |
+-----------+---------+---------------+-------------+--------------------+----------------------------+
4 rows in set (0.37 sec)
mysql> SELECT * FROM iceberg.nyc.taxis2;
+-----------+---------+---------------+-------------+--------------------+----------------------------+
| vendor_id | trip_id | trip_distance | fare_amount | store_and_fwd_flag | ts |
+-----------+---------+---------------+-------------+--------------------+----------------------------+
| 1 | 1000374 | 8.4 | 42.13 | Y | 2024-01-03 07:12:33.000000 |
| 1 | 1000371 | 1.8 | 15.32 | N | 2024-01-01 09:15:23.000000 |
| 2 | 1000373 | 0.9 | 9.01 | N | 2024-01-01 03:25:15.000000 |
| 2 | 1000372 | 2.5 | 22.15 | N | 2024-01-02 12:10:11.000000 |
+-----------+---------+---------------+-------------+--------------------+----------------------------+
4 rows in set (0.35 sec) -
パーティション プルーニング
mysql> SELECT * FROM iceberg.nyc.taxis where vendor_id = 2 and ts >= '2024-01-01' and ts < '2024-01-02';
+-----------+---------+---------------+-------------+--------------------+----------------------------+
| vendor_id | trip_id | trip_distance | fare_amount | store_and_fwd_flag | ts |
+-----------+---------+---------------+-------------+--------------------+----------------------------+
| 2 | 1000373 | 0.9 | 9.01 | N | 2024-01-01 03:25:15.000000 |
+-----------+---------+---------------+-------------+--------------------+----------------------------+
1 row in set (0.06 sec)
mysql> EXPLAIN VERBOSE SELECT * FROM iceberg.nyc.taxis where vendor_id = 2 and ts >= '2024-01-01' and ts < '2024-01-02';
....
| 0:VICEBERG_SCAN_NODE(71)
| table: taxis
| predicates: (ts[#5] < '2024-01-02 00:00:00'), (vendor_id[#0] = 2), (ts[#5] >= '2024-01-01 00:00:00')
| inputSplitNum=1, totalFileSize=3539, scanRanges=1
| partition=1/0
| backends:
| 10002
| s3://warehouse/wh/nyc/taxis/data/vendor_id=2/ts_day=2024-01-01/40e6ca404efa4a44-b888f23546d3a69c_5708e229-2f3d-4b68-a66b-44298a9d9815-0.zstd.parquet start: 0 length: 3539
| cardinality=6, numNodes=1
| pushdown agg=NONE
| icebergPredicatePushdown=
| ref(name="ts") < 1704153600000000
| ref(name="vendor_id") == 2
| ref(name="ts") >= 1704067200000000
....
EXPLAIN VERBOSE文の結果を調べることで、述語条件vendor_id = 2 and ts >= '2024-01-01' and ts < '2024-01-02'が最終的に一つのpartitionのみにヒットすることが確認できます(partition=1/0)。
また、Table作成時にpartition Transform関数DAY(ts)が指定されていたため、データ内の元の値2024-01-01 03:25:15.000000がファイルディレクトリ内のpartition情報ts_day=2024-01-01に変換されることも観察できます。
06 Time Travel
さらにいくつかのデータ行を挿入してみましょう:
INSERT INTO iceberg.nyc.taxis VALUES (1, 1000375, 8.8, 55.55, 'Y', '2024-01-01 8:10:22'), (3, 1000376, 7.4, 32.35, 'N', '2024-01-02 1:14:45');
Query OK, 2 rows affected (0.17 sec)
{'status':'COMMITTED', 'txnId':'10086'}
mysql> SELECT * FROM iceberg.nyc.taxis;
+-----------+---------+---------------+-------------+--------------------+----------------------------+
| vendor_id | trip_id | trip_distance | fare_amount | store_and_fwd_flag | ts |
+-----------+---------+---------------+-------------+--------------------+----------------------------+
| 3 | 1000376 | 7.4 | 32.35 | N | 2024-01-02 01:14:45.000000 |
| 2 | 1000372 | 2.5 | 22.15 | N | 2024-01-02 12:10:11.000000 |
| 1 | 1000374 | 8.4 | 42.13 | Y | 2024-01-03 07:12:33.000000 |
| 1 | 1000371 | 1.8 | 15.32 | N | 2024-01-01 09:15:23.000000 |
| 1 | 1000375 | 8.8 | 55.55 | Y | 2024-01-01 08:10:22.000000 |
| 2 | 1000373 | 0.9 | 9.01 | N | 2024-01-01 03:25:15.000000 |
+-----------+---------+---------------+-------------+--------------------+----------------------------+
6 rows in set (0.11 sec)
iceberg_metaTable関数を使用してTableのスナップショット情報を照会します:
mysql> select * from iceberg_meta("table" = "iceberg.nyc.taxis", "query_type" = "snapshots");
+---------------------+---------------------+---------------------+-----------+-----------------------------------------------------------------------------------------------------------+----------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------+
| committed_at | snapshot_id | parent_id | operation | manifest_list | summary |
+---------------------+---------------------+---------------------+-----------+-----------------------------------------------------------------------------------------------------------+----------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------+
| 2024-07-29 03:38:22 | 8483933166442433486 | -1 | append | s3://warehouse/wh/nyc/taxis/metadata/snap-8483933166442433486-1-5f7b7736-8022-4ba1-9db2-51ae7553be4d.avro | {"added-data-files":"4","added-records":"4","added-files-size":"14156","changed-partition-count":"4","total-records":"4","total-files-size":"14156","total-data-files":"4","total-delete-files":"0","total-position-deletes":"0","total-equality-deletes":"0"} |
| 2024-07-29 03:40:23 | 4726331391239920914 | 8483933166442433486 | append | s3://warehouse/wh/nyc/taxis/metadata/snap-4726331391239920914-1-6aa3d142-6c9c-4553-9c04-08ad4d49a4ea.avro | {"added-data-files":"2","added-records":"2","added-files-size":"7078","changed-partition-count":"2","total-records":"6","total-files-size":"21234","total-data-files":"6","total-delete-files":"0","total-position-deletes":"0","total-equality-deletes":"0"} |
+---------------------+---------------------+---------------------+-----------+-----------------------------------------------------------------------------------------------------------+----------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------+
2 rows in set (0.07 sec)
指定されたスナップショットをFOR VERSION AS OF文を使用してクエリします:
mysql> SELECT * FROM iceberg.nyc.taxis FOR VERSION AS OF 8483933166442433486;
+-----------+---------+---------------+-------------+--------------------+----------------------------+
| vendor_id | trip_id | trip_distance | fare_amount | store_and_fwd_flag | ts |
+-----------+---------+---------------+-------------+--------------------+----------------------------+
| 1 | 1000371 | 1.8 | 15.32 | N | 2024-01-01 09:15:23.000000 |
| 1 | 1000374 | 8.4 | 42.13 | Y | 2024-01-03 07:12:33.000000 |
| 2 | 1000372 | 2.5 | 22.15 | N | 2024-01-02 12:10:11.000000 |
| 2 | 1000373 | 0.9 | 9.01 | N | 2024-01-01 03:25:15.000000 |
+-----------+---------+---------------+-------------+--------------------+----------------------------+
4 rows in set (0.05 sec)
mysql> SELECT * FROM iceberg.nyc.taxis FOR VERSION AS OF 4726331391239920914;
+-----------+---------+---------------+-------------+--------------------+----------------------------+
| vendor_id | trip_id | trip_distance | fare_amount | store_and_fwd_flag | ts |
+-----------+---------+---------------+-------------+--------------------+----------------------------+
| 1 | 1000374 | 8.4 | 42.13 | Y | 2024-01-03 07:12:33.000000 |
| 1 | 1000375 | 8.8 | 55.55 | Y | 2024-01-01 08:10:22.000000 |
| 3 | 1000376 | 7.4 | 32.35 | N | 2024-01-02 01:14:45.000000 |
| 2 | 1000372 | 2.5 | 22.15 | N | 2024-01-02 12:10:11.000000 |
| 2 | 1000373 | 0.9 | 9.01 | N | 2024-01-01 03:25:15.000000 |
| 1 | 1000371 | 1.8 | 15.32 | N | 2024-01-01 09:15:23.000000 |
+-----------+---------+---------------+-------------+--------------------+----------------------------+
6 rows in set (0.04 sec)
指定されたスナップショットをFOR TIME AS OF文を使用してクエリする:
mysql> SELECT * FROM iceberg.nyc.taxis FOR TIME AS OF "2024-07-29 03:38:23";
+-----------+---------+---------------+-------------+--------------------+----------------------------+
| vendor_id | trip_id | trip_distance | fare_amount | store_and_fwd_flag | ts |
+-----------+---------+---------------+-------------+--------------------+----------------------------+
| 1 | 1000374 | 8.4 | 42.13 | Y | 2024-01-03 07:12:33.000000 |
| 1 | 1000371 | 1.8 | 15.32 | N | 2024-01-01 09:15:23.000000 |
| 2 | 1000372 | 2.5 | 22.15 | N | 2024-01-02 12:10:11.000000 |
| 2 | 1000373 | 0.9 | 9.01 | N | 2024-01-01 03:25:15.000000 |
+-----------+---------+---------------+-------------+--------------------+----------------------------+
4 rows in set (0.04 sec)
mysql> SELECT * FROM iceberg.nyc.taxis FOR TIME AS OF "2024-07-29 03:40:22";
+-----------+---------+---------------+-------------+--------------------+----------------------------+
| vendor_id | trip_id | trip_distance | fare_amount | store_and_fwd_flag | ts |
+-----------+---------+---------------+-------------+--------------------+----------------------------+
| 2 | 1000373 | 0.9 | 9.01 | N | 2024-01-01 03:25:15.000000 |
| 1 | 1000374 | 8.4 | 42.13 | Y | 2024-01-03 07:12:33.000000 |
| 2 | 1000372 | 2.5 | 22.15 | N | 2024-01-02 12:10:11.000000 |
| 1 | 1000371 | 1.8 | 15.32 | N | 2024-01-01 09:15:23.000000 |
+-----------+---------+---------------+-------------+--------------------+----------------------------+
4 rows in set (0.05 sec)
07 PyIcebergとの連携
Doris 2.1.8/3.0.4以上をご使用ください。
icebergTableをロードする:
from pyiceberg.catalog import load_catalog
catalog = load_catalog(
"iceberg",
**{
"warehouse" = "warehouse",
"uri" = "http://rest:8181",
"s3.access-key-id" = "admin",
"s3.secret-access-key" = "password",
"s3.endpoint" = "http://minio:9000"
},
)
table = catalog.load_table("nyc.taxis")
TableをArrow Tableとして読み取る:
print(table.scan().to_arrow())
pyarrow.Table
vendor_id: int64
trip_id: int64
trip_distance: float
fare_amount: double
store_and_fwd_flag: large_string
ts: timestamp[us]
----
vendor_id: [[1],[1],[2],[2]]
trip_id: [[1000371],[1000374],[1000373],[1000372]]
trip_distance: [[1.8],[8.4],[0.9],[2.5]]
fare_amount: [[15.32],[42.13],[9.01],[22.15]]
store_and_fwd_flag: [["N"],["Y"],["N"],["N"]]
ts: [[2024-01-01 09:15:23.000000],[2024-01-03 07:12:33.000000],[2024-01-01 03:25:15.000000],[2024-01-02 12:10:11.000000]]
TableをPandas DataFrameとして読み込む:
print(table.scan().to_pandas())
vendor_id trip_id trip_distance fare_amount store_and_fwd_flag ts
0 1 1000371 1.8 15.32 N 2024-01-01 09:15:23
1 1 1000374 8.4 42.13 Y 2024-01-03 07:12:33
2 2 1000373 0.9 9.01 N 2024-01-01 03:25:15
3 2 1000372 2.5 22.15 N 2024-01-02 12:10:11
TableをPolars DataFrameとして読み取り:
import polars as pl
print(pl.scan_iceberg(table).collect())
shape: (4, 6)
┌───────────┬─────────┬───────────────┬─────────────┬────────────────────┬─────────────────────┐
│ vendor_id ┆ trip_id ┆ trip_distance ┆ fare_amount ┆ store_and_fwd_flag ┆ ts │
│ --- ┆ --- ┆ --- ┆ --- ┆ --- ┆ --- │
│ i64 ┆ i64 ┆ f32 ┆ f64 ┆ str ┆ datetime[μs] │
╞═══════════╪═════════╪═══════════════╪═════════════╪════════════════════╪═════════════════════╡
│ 1 ┆ 1000371 ┆ 1.8 ┆ 15.32 ┆ N ┆ 2024-01-01 09:15:23 │
│ 1 ┆ 1000374 ┆ 8.4 ┆ 42.13 ┆ Y ┆ 2024-01-03 07:12:33 │
│ 2 ┆ 1000373 ┆ 0.9 ┆ 9.01 ┆ N ┆ 2024-01-01 03:25:15 │
│ 2 ┆ 1000372 ┆ 2.5 ┆ 22.15 ┆ N ┆ 2024-01-02 12:10:11 │
└───────────┴─────────┴───────────────┴─────────────┴────────────────────┴─────────────────────┘
PyIceberg で iceberg table を書き込む場合は、step を参照してください
08 付録
PyIceberg で iceberg table を書き込む
iceberg table をロードする:
from pyiceberg.catalog import load_catalog
catalog = load_catalog(
"iceberg",
**{
"warehouse" = "warehouse",
"uri" = "http://rest:8181",
"s3.access-key-id" = "admin",
"s3.secret-access-key" = "password",
"s3.endpoint" = "http://minio:9000"
},
)
table = catalog.load_table("nyc.taxis")
Arrow Table でTableを書く:
import pyarrow as pa
df = pa.Table.from_pydict(
{
"vendor_id": pa.array([1, 2, 2, 1], pa.int64()),
"trip_id": pa.array([1000371, 1000372, 1000373, 1000374], pa.int64()),
"trip_distance": pa.array([1.8, 2.5, 0.9, 8.4], pa.float32()),
"fare_amount": pa.array([15.32, 22.15, 9.01, 42.13], pa.float64()),
"store_and_fwd_flag": pa.array(["N", "N", "N", "Y"], pa.string()),
"ts": pa.compute.strptime(
["2024-01-01 9:15:23", "2024-01-02 12:10:11", "2024-01-01 3:25:15", "2024-01-03 7:12:33"],
"%Y-%m-%d %H:%M:%S",
"us",
),
}
)
table.append(df)
Pandas DataFrame でTableを書く:
import pyarrow as pa
import pandas as pd
df = pd.DataFrame(
{
"vendor_id": pd.Series([1, 2, 2, 1]).astype("int64[pyarrow]"),
"trip_id": pd.Series([1000371, 1000372, 1000373, 1000374]).astype("int64[pyarrow]"),
"trip_distance": pd.Series([1.8, 2.5, 0.9, 8.4]).astype("float32[pyarrow]"),
"fare_amount": pd.Series([15.32, 22.15, 9.01, 42.13]).astype("float64[pyarrow]"),
"store_and_fwd_flag": pd.Series(["N", "N", "N", "Y"]).astype("string[pyarrow]"),
"ts": pd.Series(["2024-01-01 9:15:23", "2024-01-02 12:10:11", "2024-01-01 3:25:15", "2024-01-03 7:12:33"]).astype("timestamp[us][pyarrow]"),
}
)
table.append(pa.Table.from_pandas(df))
Polars DataFrame でTableを書き込む:
import polars as pl
df = pl.DataFrame(
{
"vendor_id": [1, 2, 2, 1],
"trip_id": [1000371, 1000372, 1000373, 1000374],
"trip_distance": [1.8, 2.5, 0.9, 8.4],
"fare_amount": [15.32, 22.15, 9.01, 42.13],
"store_and_fwd_flag": ["N", "N", "N", "Y"],
"ts": ["2024-01-01 9:15:23", "2024-01-02 12:10:11", "2024-01-01 3:25:15", "2024-01-03 7:12:33"],
},
{
"vendor_id": pl.Int64,
"trip_id": pl.Int64,
"trip_distance": pl.Float32,
"fare_amount": pl.Float64,
"store_and_fwd_flag": pl.String,
"ts": pl.String,
},
).with_columns(pl.col("ts").str.strptime(pl.Datetime, "%Y-%m-%d %H:%M:%S"))
table.append(df.to_arrow())