レイクハウス概要
lakehouseは、データレイクとデータウェアハウスの利点を組み合わせた最新のビッグデータソリューションです。データレイクの低コストと高いスケーラビリティを、データウェアハウスの高性能と強力なデータガバナンス機能と統合し、ビッグデータ時代における様々なデータの効率的で安全、かつ品質管理された保存と処理分析を可能にします。標準化されたオープンデータ形式とメタデータ管理を通じて、リアルタイムと履歴データ、バッチ処理とストリーム処理を統一し、企業のビッグデータソリューションの新たな標準として徐々に確立されています。
Doris Lakehouseソリューション
Dorisは、拡張可能なコネクターフレームワーク、コンピュート・ストレージ分離アーキテクチャ、高性能データ処理エンジン、およびデータエコシステムの開放性を通じて、ユーザーに優れたlakehouseソリューションを提供します。
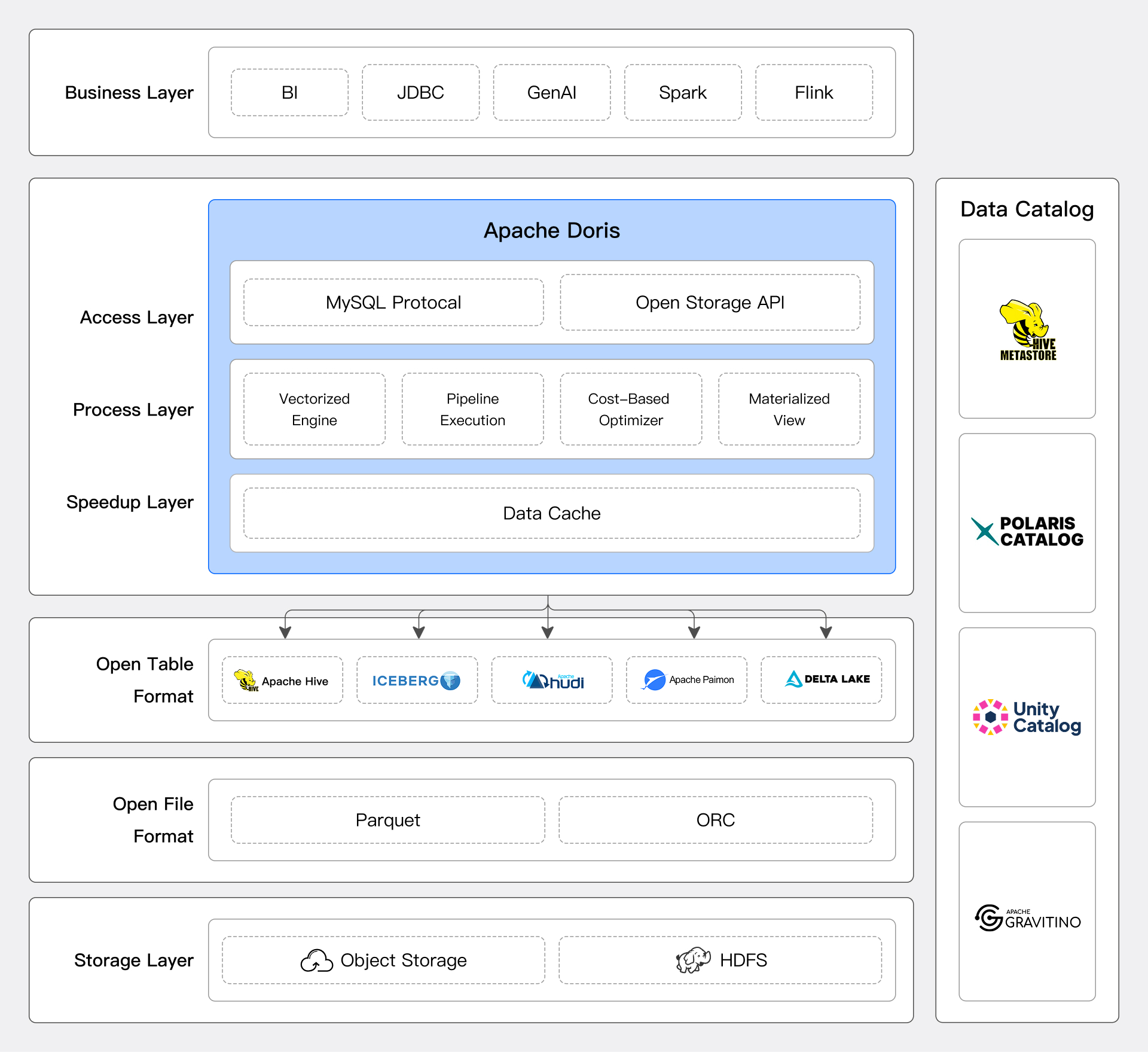
柔軟なデータアクセス
Dorisは拡張可能なコネクターフレームワークを通じて主要なデータシステムとデータ形式のアクセスをサポートし、SQLベースの統一されたデータ分析機能を提供することで、ユーザーが既存のデータを移動することなく、容易にクロスプラットフォームのデータクエリと分析を実行できます。詳細については、Catalog Overviewを参照してください
データソースコネクター
Hive、Iceberg、Hudi、Paimon、またはJDBCプロトコルをサポートするデータベースシステムのいずれであっても、Dorisは簡単に接続し、効率的にデータにアクセスできます。
lakehouseシステムについては、DorisはHive Metastore、AWS Glue、Unity Catalogなどのメタデータサービスからデータテーブルの構造と分散情報を取得し、適切なクエリプランニングを実行し、MPPアーキテクチャを活用した分散コンピューティングを行います。
詳細については、Iceberg Catalogなどの各catalogドキュメントを参照してください
拡張可能なコネクターフレームワーク
Dorisは、開発者が企業内の固有のデータソースに迅速に接続し、高速なデータ相互運用性を実現するための優れた拡張性フレームワークを提供します。
Dorisは、Catalog、Database、Tableの3つのレベルの標準を定義し、開発者が必要なデータソースレベルに容易にマッピングできるようにします。Dorisはまた、メタデータサービスとストレージサービスのアクセス用の標準インターフェースを提供し、開発者は対応するインターフェースを実装するだけでデータソース接続を完了できます。
DorisはTrino Connectorプラグインと互換性があり、TrinoプラグインパッケージをDorisクラスターに直接デプロイでき、最小限の設定で対応するデータソースにアクセスできます。Dorisは既にKudu、BigQuery、Delta Lakeなどのデータソースへの接続を完了しています。新しいプラグインを自分で適応することも可能です。
便利なクロスソースデータ処理
Dorisは実行時に複数のデータcatalogの作成をサポートし、SQLを使用してこれらのデータソースに対してフェデレーテッドクエリを実行できます。例えば、ユーザーはHive内のファクトテーブルデータとMySQL内のディメンションテーブルデータを関連付けてクエリできます:
SELECT h.id, m.name
FROM hive.db.hive_table h JOIN mysql.db.mysql_table m
ON h.id = m.id;
Dorisの組み込みjob scheduling機能と組み合わせることで、スケジュールされたタスクを作成してシステムの複雑さをさらに簡素化することもできます。例えば、ユーザーは上記のクエリの結果を1時間ごとに実行されるルーチンタスクとして設定し、各結果をIcebergテーブルに書き込むことができます:
CREATE JOB schedule_load
ON SCHEDULE EVERY 1 HOUR DO
INSERT INTO iceberg.db.ice_table
SELECT h.id, m.name
FROM hive.db.hive_table h JOIN mysql.db.mysql_table m
ON h.id = m.id;
高性能データ処理
分析データウェアハウスとして、Dorisはlakehouseデータ処理と計算において数多くの最適化を行い、豊富なクエリ高速化機能を提供します:
-
実行エンジン
Doris実行エンジンはMPP実行フレームワークとPipelineデータ処理モデルに基づいており、マルチマシン・マルチコア分散環境で大量データを迅速に処理できます。完全なベクトル化実行オペレータにより、DorisはTPC-DSなどの標準ベンチマークデータセットにおいて計算性能で優位に立っています。
-
クエリオプティマイザ
Dorisはクエリオプティマイザを通じて複雑なSQLリクエストを自動的に最適化・処理できます。クエリオプティマイザは、マルチテーブルjoin、集約、ソート、ページネーションなど様々な複雑なSQLオペレータを深く最適化し、コストモデルと関係代数変換を完全に活用して、より良い、または最適な論理・物理実行プランを自動的に取得し、SQLの記述難易度を大幅に軽減し、使いやすさと性能を向上させます。
-
データキャッシュとIO最適化
外部データソースへのアクセスは通常ネットワークアクセスであり、高レイテンシと低安定性を持つ可能性があります。Apache Dorisは豊富なキャッシュメカニズムを提供し、キャッシュタイプ、適時性、戦略において数多くの最適化を行い、メモリとローカル高速ディスクを完全に活用してホットデータの分析性能を向上させます。さらに、Dorisは高スループット、低IOPS、高レイテンシなどのネットワークIO特性に対して的を絞った最適化を行い、ローカルデータに匹敵する外部データソースアクセス性能を提供します。
-
マテリアライズドビューと透明な高速化
Dorisは豊富なマテリアライズドビュー更新戦略を提供し、フルおよびパーティションレベルの増分リフレッシュをサポートして構築コストを削減し、適時性を向上させます。手動リフレッシュに加えて、Dorisはスケジュールリフレッシュとデータドリブンリフレッシュもサポートし、メンテナンスコストをさらに削減し、データ整合性を向上させます。マテリアライズドビューは透明な高速化機能も持ち、クエリオプティマイザが適切なマテリアライズドビューに自動的にルーティングしてシームレスなクエリ高速化を実現できます。さらに、Dorisのマテリアライズドビューは高性能ストレージフォーマットを使用し、カラムストレージ、圧縮、インテリジェントインデックス技術により効率的なデータアクセス機能を提供し、データキャッシュの代替として機能し、クエリ効率を向上させます。
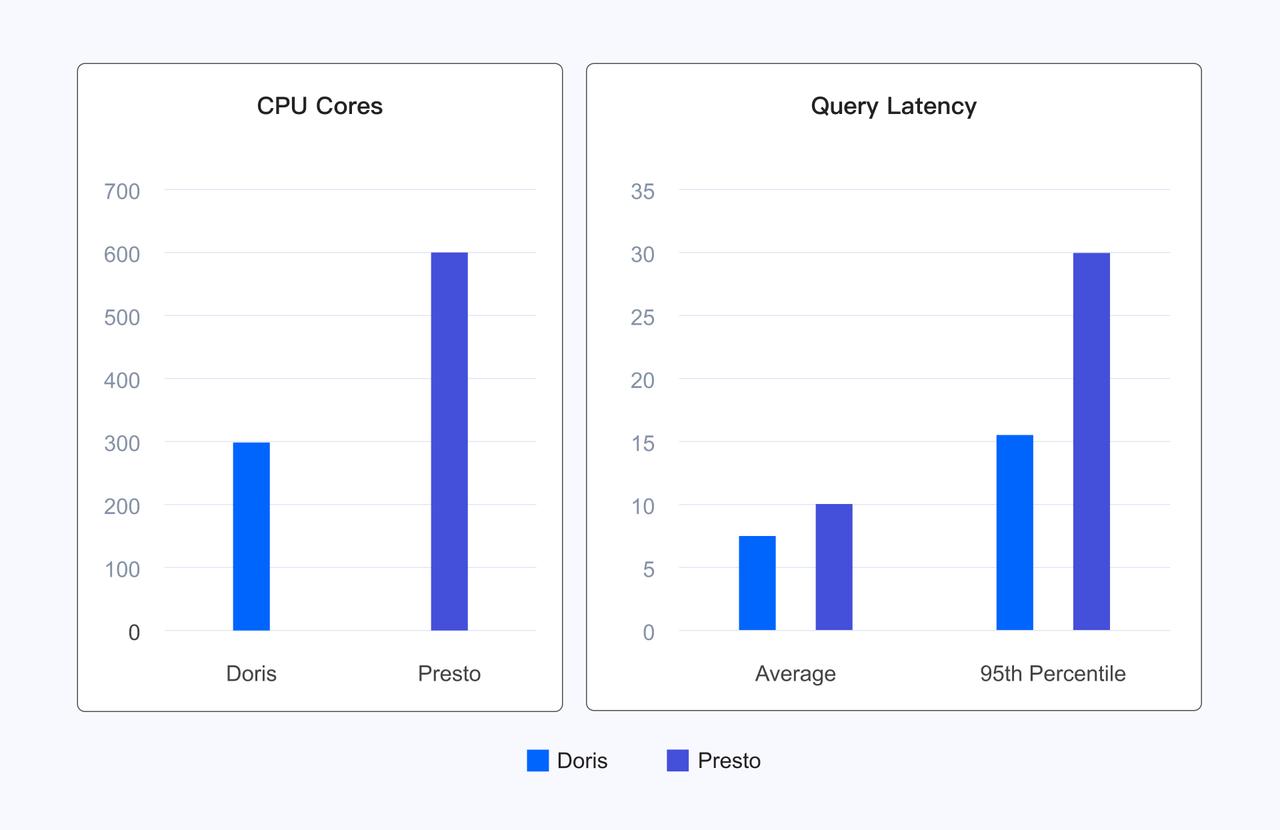
以下に示すように、Icebergテーブルフォーマットに基づく1TB TPCDSの標準テストセットにおいて、Dorisの99クエリの全体実行時間はTrinoの1/3のみです。

実際のユーザーシナリオにおいて、Dorisはリソースを半分使用しながら、Prestoと比較して平均クエリレイテンシを20%削減し、95パーセンタイルレイテンシを50%削減し、ユーザーエクスペリエンスを向上させながらリソースコストを大幅に削減します。
モダンなデプロイメントアーキテクチャ
バージョン3.0以降、Dorisはクラウドネイティブなコンピュート・ストレージ分離アーキテクチャをサポートします。このアーキテクチャは、低コストと高い弾力性により、リソース利用率を効果的に向上させ、コンピュートとストレージの独立したスケーリングを実現します。
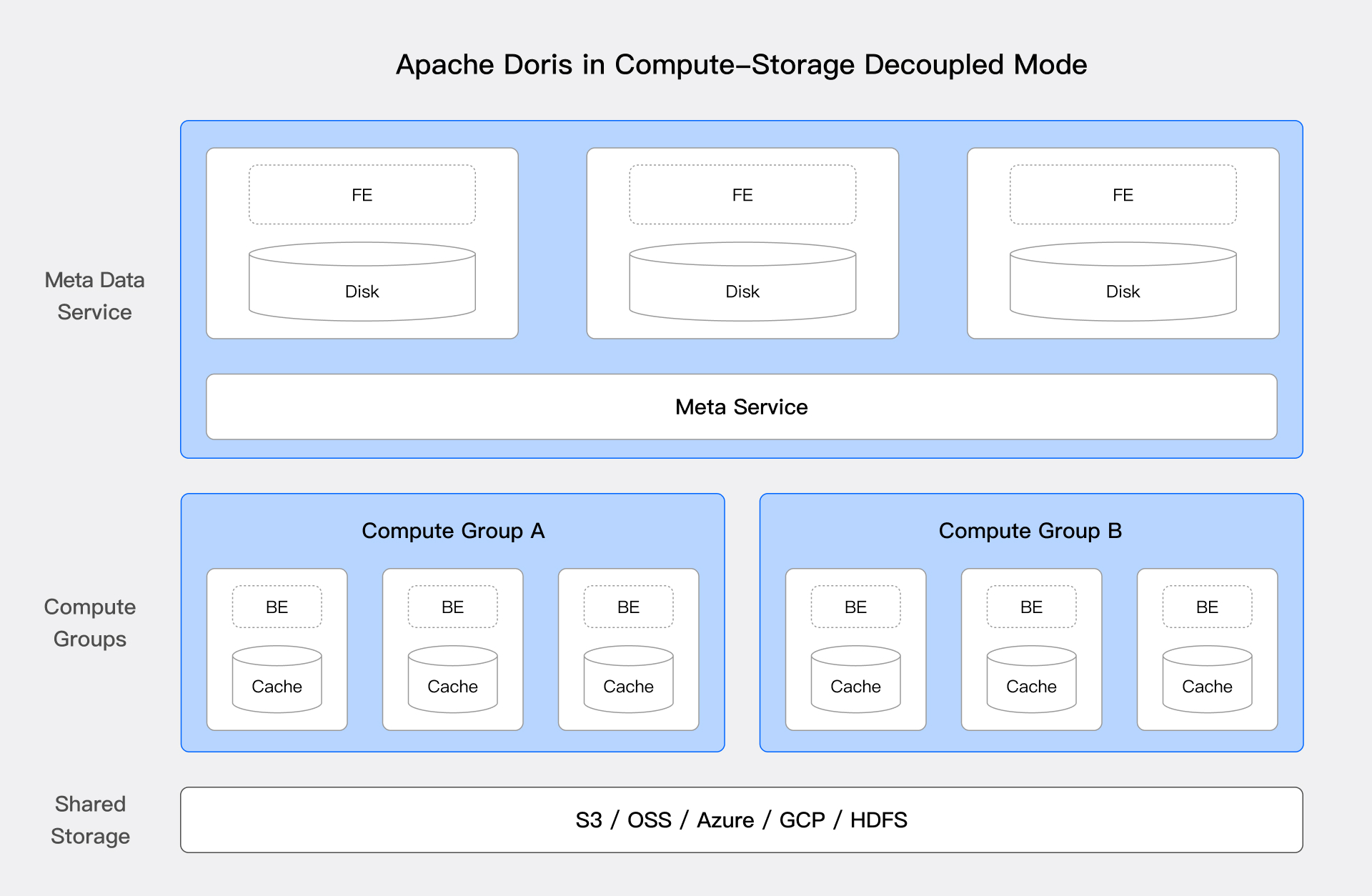
上記の図は、Dorisのコンピュート・ストレージ分離のシステムアーキテクチャを示しており、コンピュートとストレージを分離しています。コンピュートノードは主データを格納せず、基盤の共有ストレージ層(HDFSとオブジェクトストレージ)が統一された主データ格納スペースとして機能し、コンピュートとストレージリソースの独立したスケーリングをサポートします。コンピュート・ストレージ分離アーキテクチャは、lakehouseソリューションに大きな利点をもたらします:
-
低コストストレージ: ストレージとコンピュートリソースを独立してスケールでき、企業はコンピュートリソースを増やすことなくストレージ容量を増加できます。さらに、クラウドオブジェクトストレージを使用することで、企業はより低いストレージコストとより高い可用性を享受でき、相対的に低い比率のホットデータをキャッシュするためにローカル高速ディスクを使用し続けることができます。
-
単一の真実のソース: すべてのデータが統一されたストレージ層に格納され、同じデータを異なるコンピュートクラスタがアクセス・処理でき、データ整合性と完全性を確保し、データ同期と重複ストレージの複雑性を削減します。
-
ワークロードの多様性: ユーザーは異なるワークロードニーズに基づいてコンピュートリソースを動的に割り当てることができ、バッチ処理、リアルタイム分析、機械学習などの様々なアプリケーションシナリオをサポートします。ストレージとコンピュートを分離することで、企業はリソース使用をより柔軟に最適化でき、異なる負荷下での効率的な運用を確保できます。
さらに、ストレージ・コンピュート結合アーキテクチャ下では、elastic computing nodesを使用してlake warehouseデータクエリシナリオにおいて弾力的なコンピューティング機能を提供できます。
オープン性
Dorisはオープンなlakeテーブルフォーマットへのアクセスをサポートするだけでなく、自身が格納するデータに対しても良好なオープン性を持ちます。DorisはオープンなストレージAPIを提供し、Arrow Flight SQLプロトコルに基づく高速データリンクを実装し、Arrow Flightの速度上の利点とJDBC/ODBCの使いやすさを提供します。このインターフェースに基づいて、ユーザーはPython/Java/Spark/FlinkのABDCクライアントを使用してDorisに格納されたデータにアクセスできます。
オープンファイルフォーマットと比較して、オープンストレージAPIは基盤となるファイルフォーマットの具体的な実装を抽象化し、Dorisが豊富なインデックスメカニズムなど、ストレージフォーマットの高度な機能を通じてデータアクセスを高速化できるようにします。さらに、上位層のコンピュートエンジンは基盤となるストレージフォーマットの変更や新機能に適応する必要がなく、サポートされているすべてのコンピュートエンジンが新機能から同時に恩恵を受けることができます。
Lakehouse ベストプラクティス
lakehouseソリューションにおいて、Dorisは主にlakehouseクエリ高速化、マルチソース連合分析、lakehouseデータ処理に使用されます。
Lakehouseクエリ高速化
このシナリオでは、Dorisはコンピュートエンジンとして機能し、lakehouseデータのクエリ分析を高速化します。
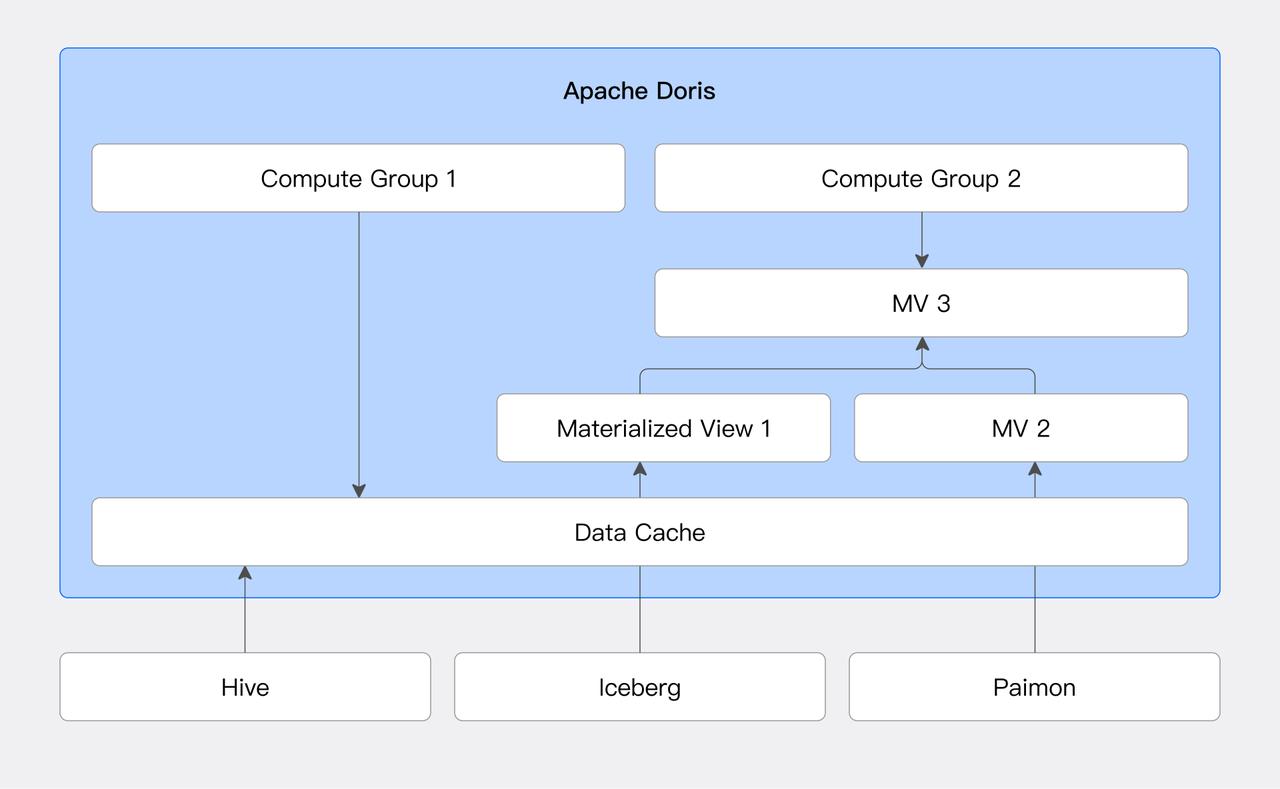
キャッシュ高速化
HiveやIcebergなどのlakehouseシステムでは、ユーザーはローカルディスクキャッシングを設定できます。ローカルディスクキャッシングは、クエリで設計されたデータファイルをローカルキャッシュディレクトリに自動的に格納し、LRU戦略を使用してキャッシュエビクションを管理します。詳細については、Data Cacheドキュメントを参照してください。
マテリアライズドビューと透明な書き換え
Dorisは外部データソースに対するマテリアライズドビューの作成をサポートします。マテリアライズドビューは、SQL定義文に基づいて事前計算された結果をDoris内部テーブルフォーマットとして格納します。さらに、DorisのクエリオプティマイザはSPJG(SELECT-PROJECT-JOIN-GROUP-BY)パターンに基づく透明な書き換えアルゴリズムをサポートします。このアルゴリズムはSQLの構造情報を分析し、透明な書き換えに適したマテリアライズドビューを自動的に見つけ、クエリSQLに応答する最適なマテリアライズドビューを選択できます。
この機能は、実行時計算を削減することでクエリ性能を大幅に向上させることができます。また、ビジネス側の認識なしに透明な書き換えを通じてマテリアライズドビューのデータにアクセスすることも可能にします。詳細については、Materialized Viewsドキュメントを参照してください。
マルチソース連合分析
Dorisは統一SQLクエリエンジンとして機能し、異なるデータソースを接続して連合分析を行い、データサイロの問題を解決できます。
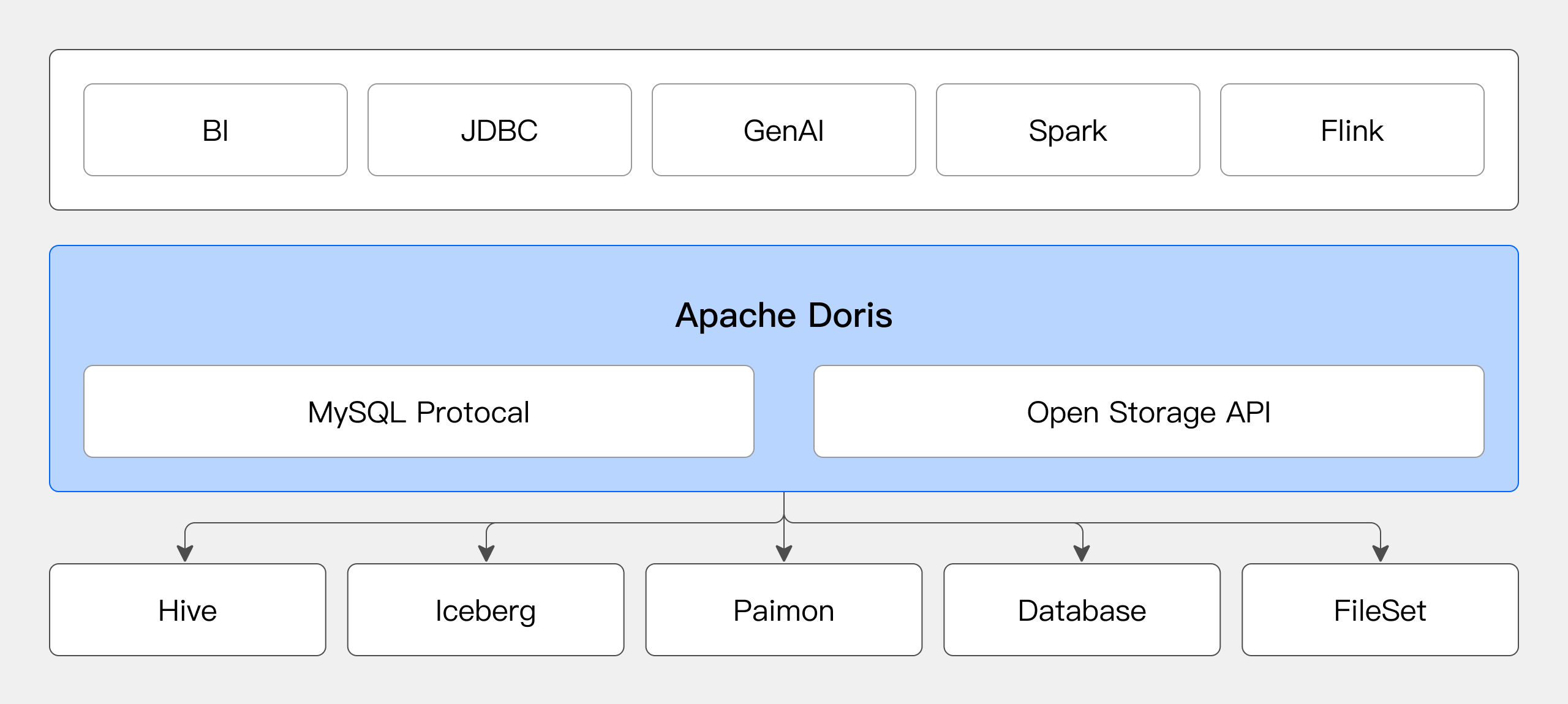
ユーザーはDorisで複数のcatalogを動的に作成して異なるデータソースに接続できます。SQL文を使用して、異なるデータソースからのデータに対して任意のjoinクエリを実行できます。詳細については、Catalog Overviewを参照してください。
Lakehouseデータ処理
このシナリオでは、Dorisはデータ処理エンジンとして機能し、lakehouseデータを処理します。
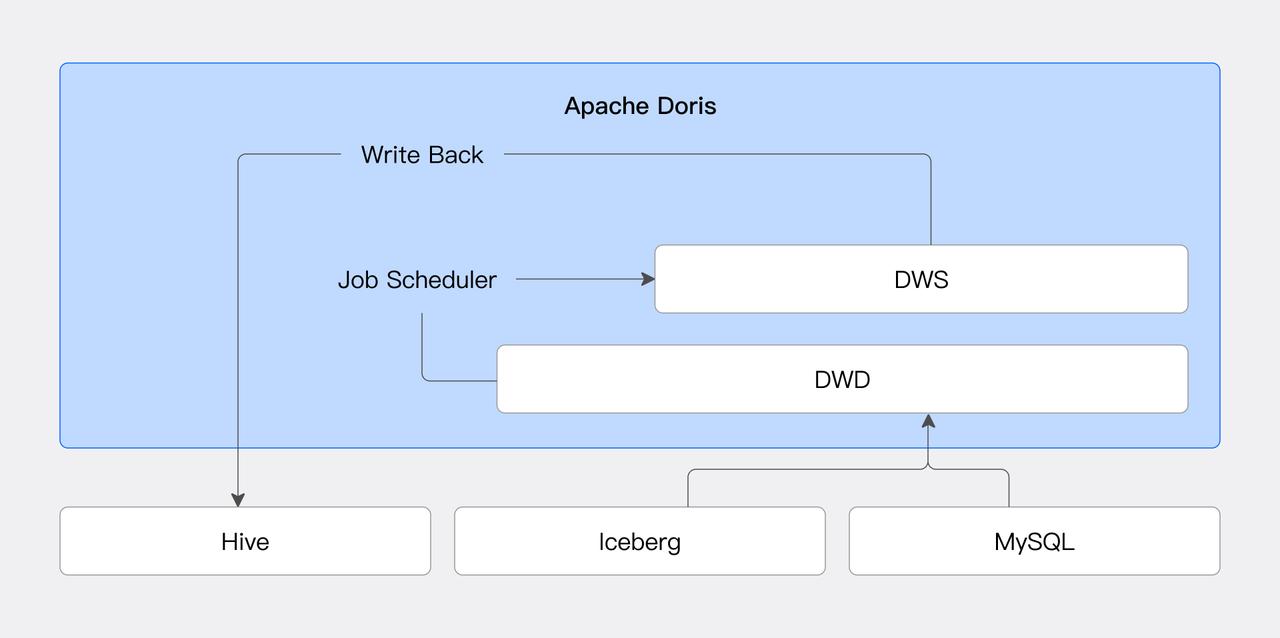
タスクスケジューリング
DorisはJob Scheduler機能を導入し、効率的で柔軟なタスクスケジューリングを実現し、外部システムへの依存を削減します。データソースコネクタと組み合わせることで、ユーザーは外部データの定期的な処理と格納を実現できます。詳細については、Job Schedulerを参照してください。
データモデリング
ユーザーは通常、データレイクを使用して生データを格納し、これに基づいて階層化されたデータ処理を実行し、異なる層のデータを異なるビジネスニーズに対応させます。Dorisのマテリアライズドビュー機能は、外部データソースに対するマテリアライズドビューの作成をサポートし、マテリアライズドビューに基づくさらなる処理をサポートして、システムの複雑性を削減し、データ処理効率を向上させます。
データライトバック
データライトバック機能は、Dorisのlakehouseデータ処理機能のクローズドループを形成します。ユーザーはDorisを通じて外部データソースでデータベースとテーブルを直接作成し、データを書き込むことができます。現在、JDBC、Hive、Icebergデータソースがサポートされており、将来的にはより多くのデータソースが追加される予定です。詳細については、対応するデータソースのドキュメントを参照してください。