クラスター管理
有料warehouseでは、データの書き込み、顧客向けレポート、ユーザープロファイル、行動分析など、異なるワークロードをサポートするために複数のクラスターを作成できます。クラスターにはコンピュートリソース、キャッシュリソース、キャッシュされたデータのみが含まれます。同じwarehouse内のすべてのクラスターは保存されたデータを共有します。
左側ナビゲーションのManageグループからComputeを開きます。
クラスターの作成
ComputeページでNew Clusterをクリックします。まだクラスターが存在しない場合は、セットアップウィザードが表示されます。既に存在する場合は、Cluster OverviewページでNew Clusterをクリックします。
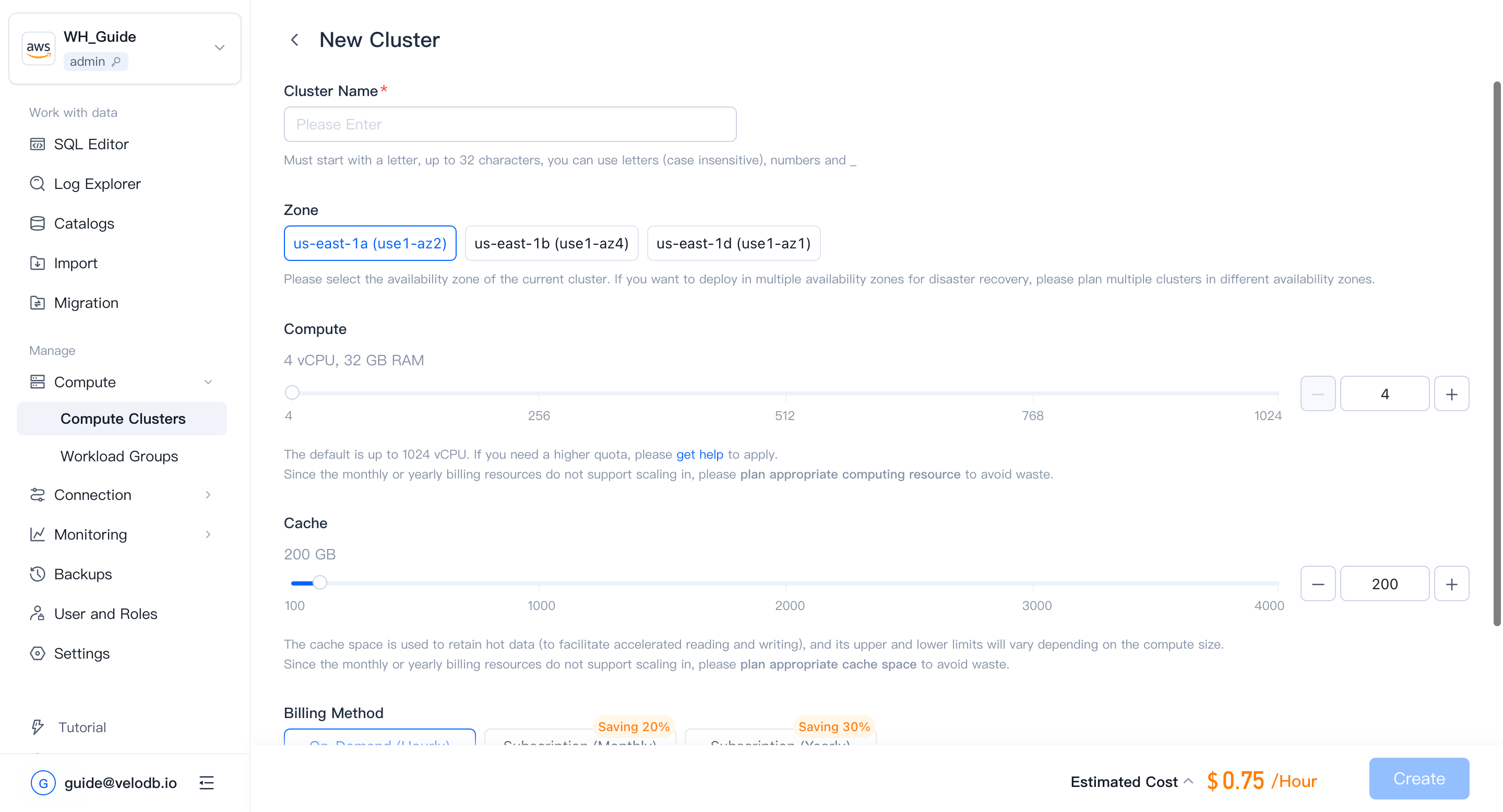
| パラメーター | 説明 |
|---|---|
| Cluster Name | 必須。文字で始まり、最大32文字。文字(大文字小文字を区別しない)、数字、アンダースコア。 |
| Compute | デフォルトの範囲はクラスターあたり4-1024 vCPUです。この上限を増やすには、サポートに問い合わせしてください。vCPUとメモリの比率は1:8で固定されています。 |
| Cache | キャッシュ容量制限はコンピュートサイズに比例します。 |
| Storage | 従量課金制。ストレージの事前割り当てはありません。warehouse内のすべてのクラスターが保存されたデータを共有します。 |
| Billing Method | デフォルトは**On-Demand (Hourly)**で、いつでも変更や削除が必要なワークロードに適しています。 |
| Auto Pause/Resume | 有効にすると、クラスターは非アクティブ期間後に自動的に一時停止し、次のクエリで再開されます。 |
クラスターの作成には料金が発生します。確認する前に、組織に十分な現金残高があるか、cloud-marketplace控除チャネルが開いていることを確認してください。そうでないと、次のエラーが表示されます。

Note
- 確認後、新しいクラスターがCluster Overviewページに表示されます。作成には約3分かかり、ステータスはCreatingからRunningに変わります。
- SaaS無料トライアルwarehouseでは、追加のクラスターの作成はサポートされていません。
クラスターの再起動
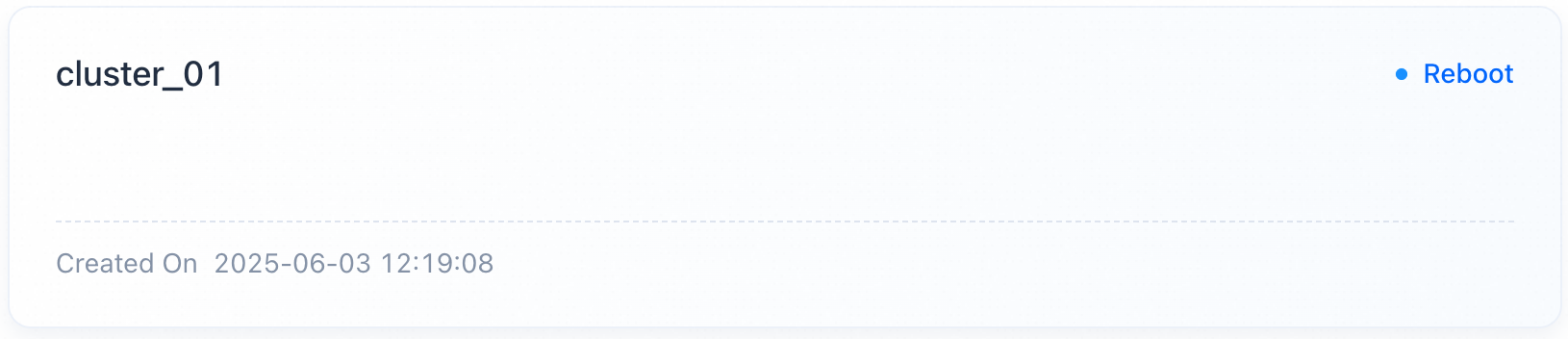
場合によって(クラスターの例外、パラメーター変更など)は、クラスターを再起動する必要があります。Cluster Overviewページで対象のクラスターカードを見つけ、Rebootをクリックして確認します。ステータスがRebootingに変わり、復旧するまで他の操作は許可されません。
Note
- 再起動には約3分かかり、ステータスはRebootingからRunningに戻ります。
- 再起動によりビジネスリクエストがクラッシュしたり遅延したりする可能性があります。
- VeloDB Cloudは再起動中もクラスターの計測と課金を継続します。
クラスターの一時停止と再開
手動一時停止/再開
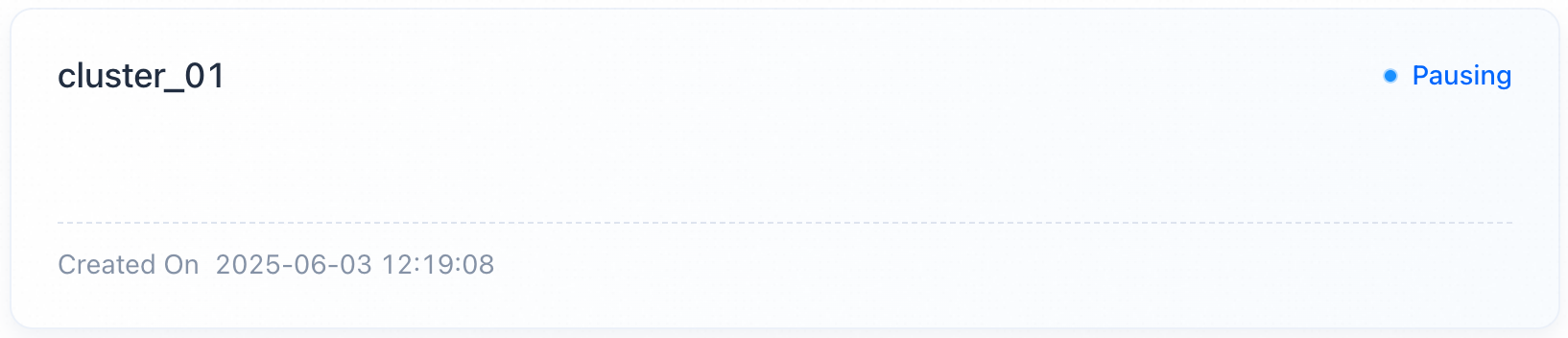
クラスターがアイドル状態の時にコストを節約するには、対象のクラスターカードを見つけ、ワークロードがアクティブでないことを確認し、Pauseをクリックして確認します。ステータスがPausingに変わり、完了するまで他の操作は許可されません。VeloDB Cloudはコンピュートリソースを解放し、キャッシュ容量とそのデータを保持します。
Note
- 一時停止には約3分かかり、ステータスはPausingからPausedに変わります。
- 一時停止したクラスターはビジネスリクエストに応答しません。
- 一時停止中はコンピュートの計測と課金が停止しますが、キャッシュ容量の計測は継続されます。
- 月次/年次課金リソースを含むクラスターは一時停止/再開をサポートしていません。
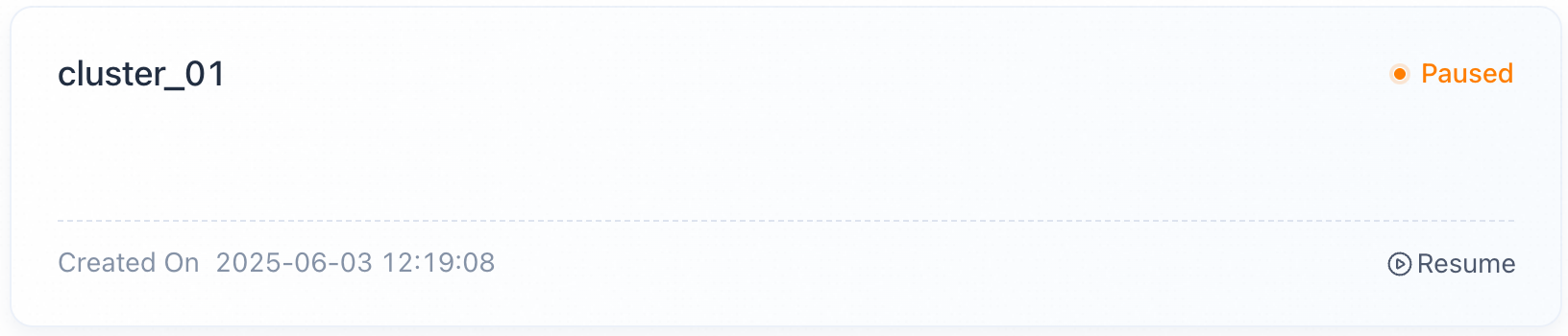
一時停止したクラスターを再開するには、そのカードでResumeをクリックして確認します。ステータスがResumingに変わり、VeloDB Cloudがコンピュートリソースを復旧し、保持されたキャッシュをマウントします。
Note
- 再開には約3分かかり、ステータスはResumingからRunningに変わります。
- クラスターは再開中はリクエストに応答しません。
- 再開後、復旧したコンピュートの計測と課金が再開されます。
- 月次/年次課金リソースを含むクラスターは一時停止/再開をサポートしていません。
自動一時停止/再開
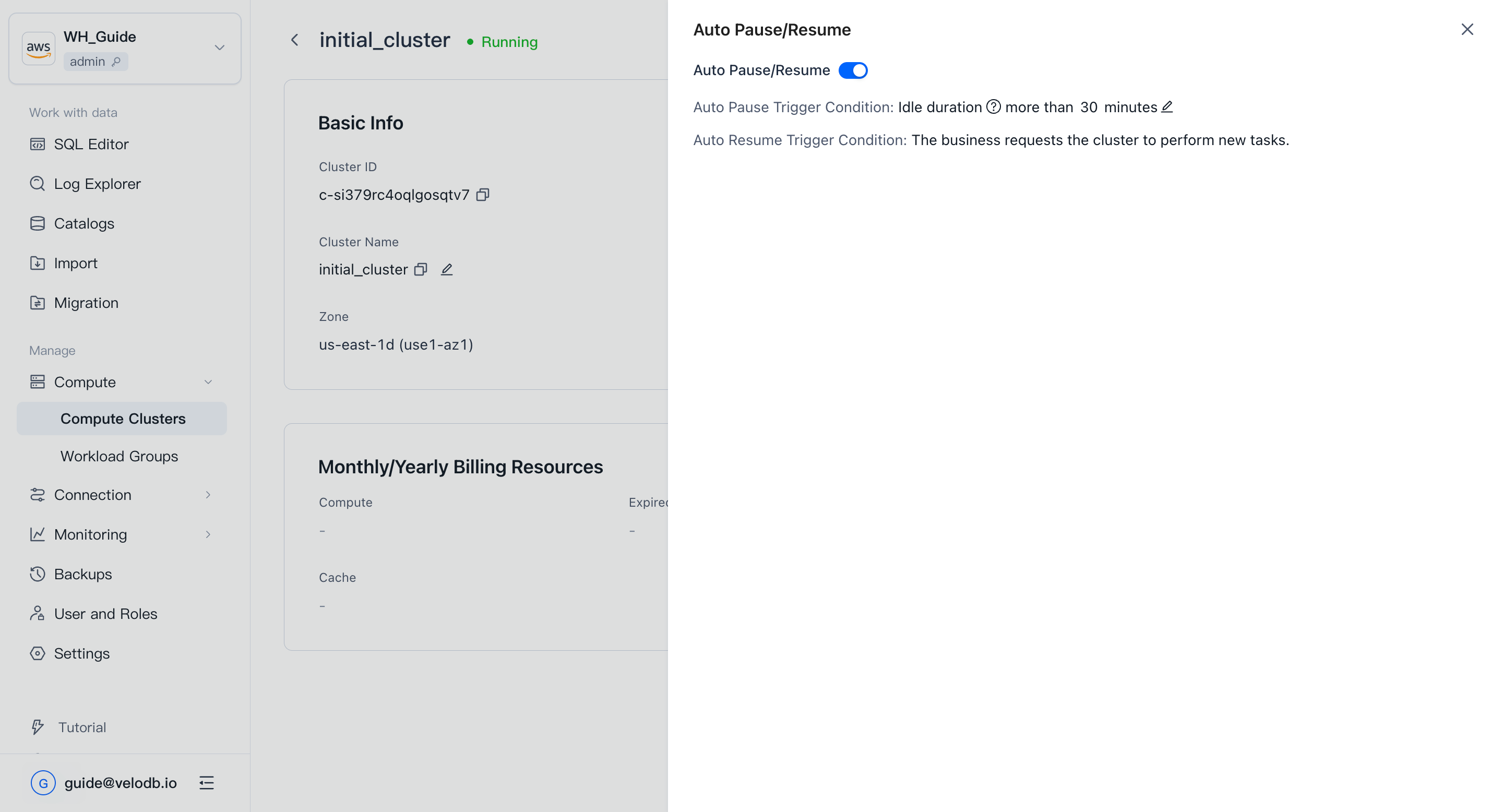
アイドルクラスターを自動的に開始・停止するには、クラスターのDetailsページを開き、Started Onの横にあるSet Auto Start/Stopをクリックし、Auto Start/Stopを有効にしてアイドル期間のしきい値を設定します。
クラスターの詳細
Cluster Overviewページでクラスターカードをクリックすると、Cluster Detailsページが開きます(クラスターのステータスが許可する場合に利用可能)。
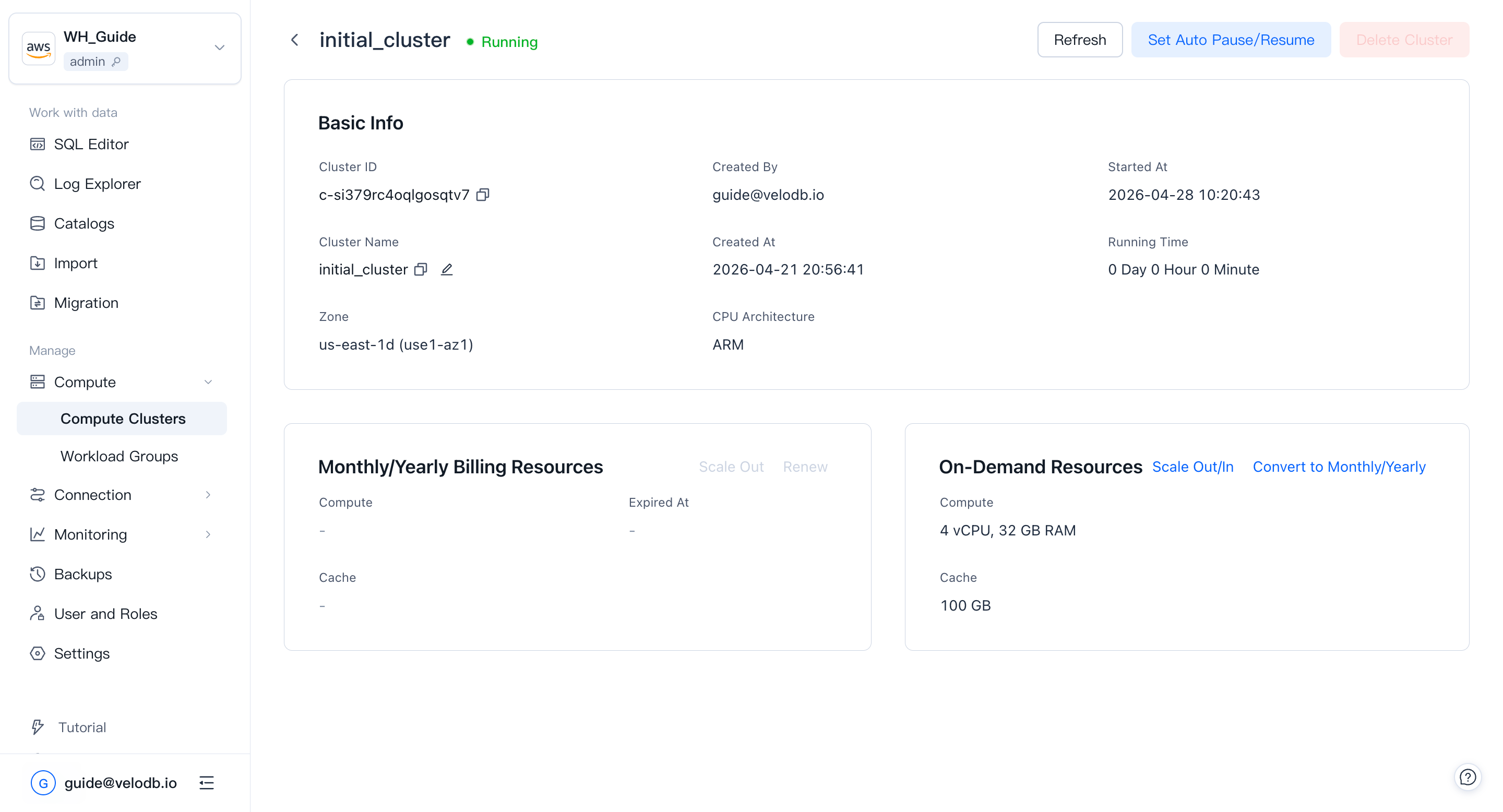
基本情報:
| パラメーター | 説明 |
|---|---|
| Cluster ID | グローバルに一意。c-で始まり、小文字26文字と数字10文字から成る18文字が続きます。 |
| Cluster Name | warehouse内で一意。ワンクリックコピーとその場での名前変更をサポートします。編集アイコンをクリックし、新しい名前を入力して2回確認します。名前は文字で始まり、最大32文字。文字(大文字小文字を区別しない)、数字、アンダースコア。 |
| Created By | クラスターを作成したユーザー。 |
| Created At | クラスターが作成された日時。 |
| Started At | クラスターが最後に再起動または再開された日時。 |
| Running Time | 最後の再起動または再開からの実行時間。 |
| Zone | クラスターが実行される可用性ゾーン。 |
| CPU Architecture | コンピュートCPUアーキテクチャ(x86またはARM)。現在はAWSベースのwarehouseでのみ表示されます。ARMクラスターの作成にはコアバージョン4.0.4以上が必要です。同じ仕様で、ARMはx86より30%以上高いパフォーマンスを提供します。アーキテクチャは作成後に変更できません。 |
Note クラスターの名前変更はSQL(
USE { [catalog_name.]database_name[@cluster_name] })およびクラスターを参照するすべての接続文字列に影響します。名前変更後、クライアントを更新するか、関連するデータベースユーザーのデフォルトクラスターを設定してください。そうでないと関連リクエストが失敗します。
オンデマンドリソース:
| パラメーター | 説明 |
|---|---|
| Compute | クラスターの現在のコンピュートリソース。 |
| Cache | クラスターの現在のキャッシュ容量。 |
| Scale Out / In | Scale Out/Inをクリックしてコンピュートまたはキャッシュを調整します。 |
スケーリング
手動スケーリング
クラスターのDetailsページのOn-Demand Resourcesの下で、Scale Out/In → Manual Scalingをクリックしてクラスターのサイズを変更します。
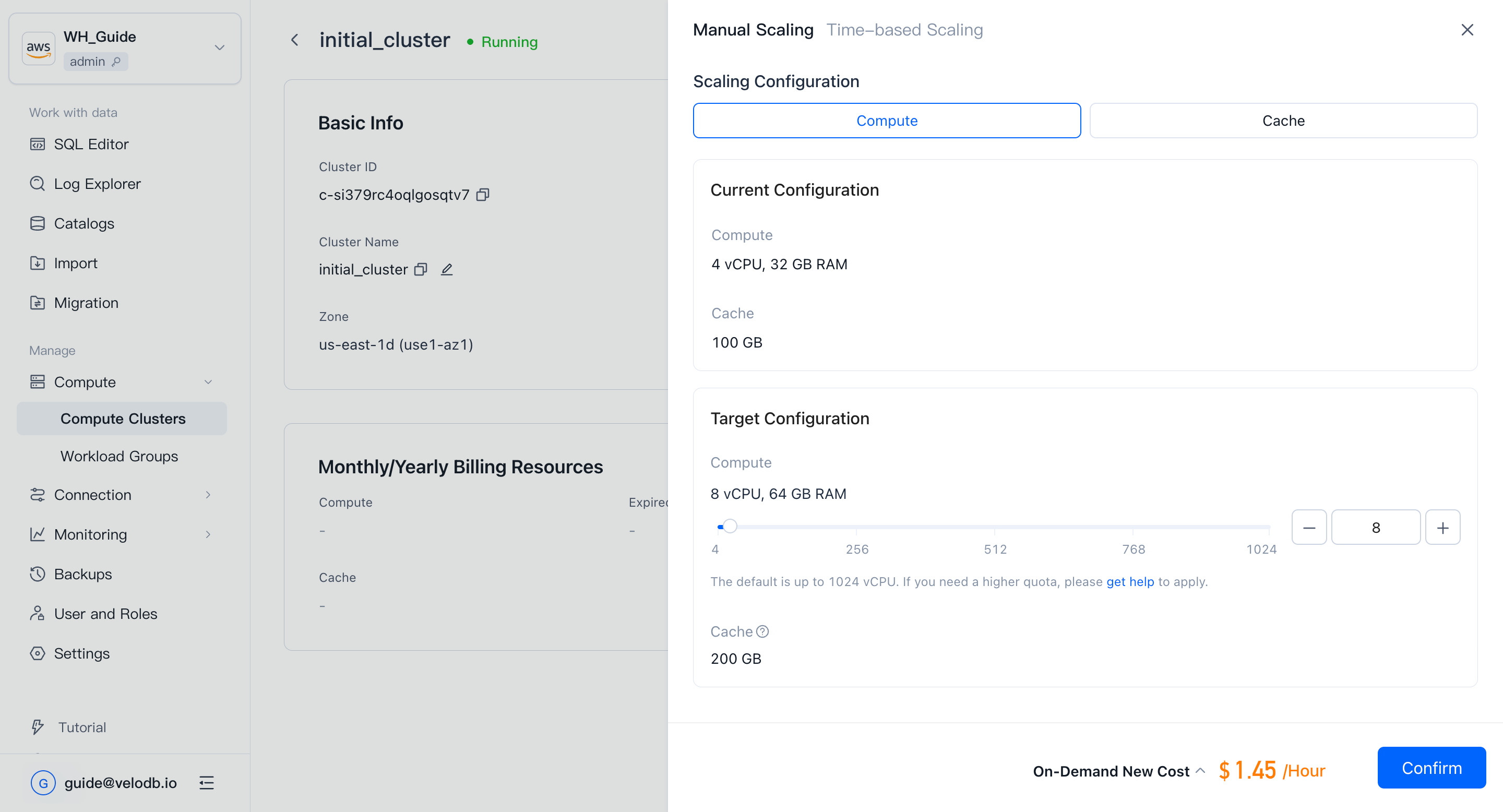
Note
- スケーリングには約3分かかり、ステータスはRunningからScalingに変わり、再び戻ります。
- SaaS無料トライアルクラスターはスケーリングをサポートしていません。
時間ベースのスケーリング
ワークロードに予測可能なピークとトラフがある場合は、時間ベースのスケーリングを設定します。Detailsページで、Scale Out/In → Time-based scalingをクリックし、異なる目標vCPU値を持つ少なくとも2つのルールを追加し、ポリシーを有効にします。
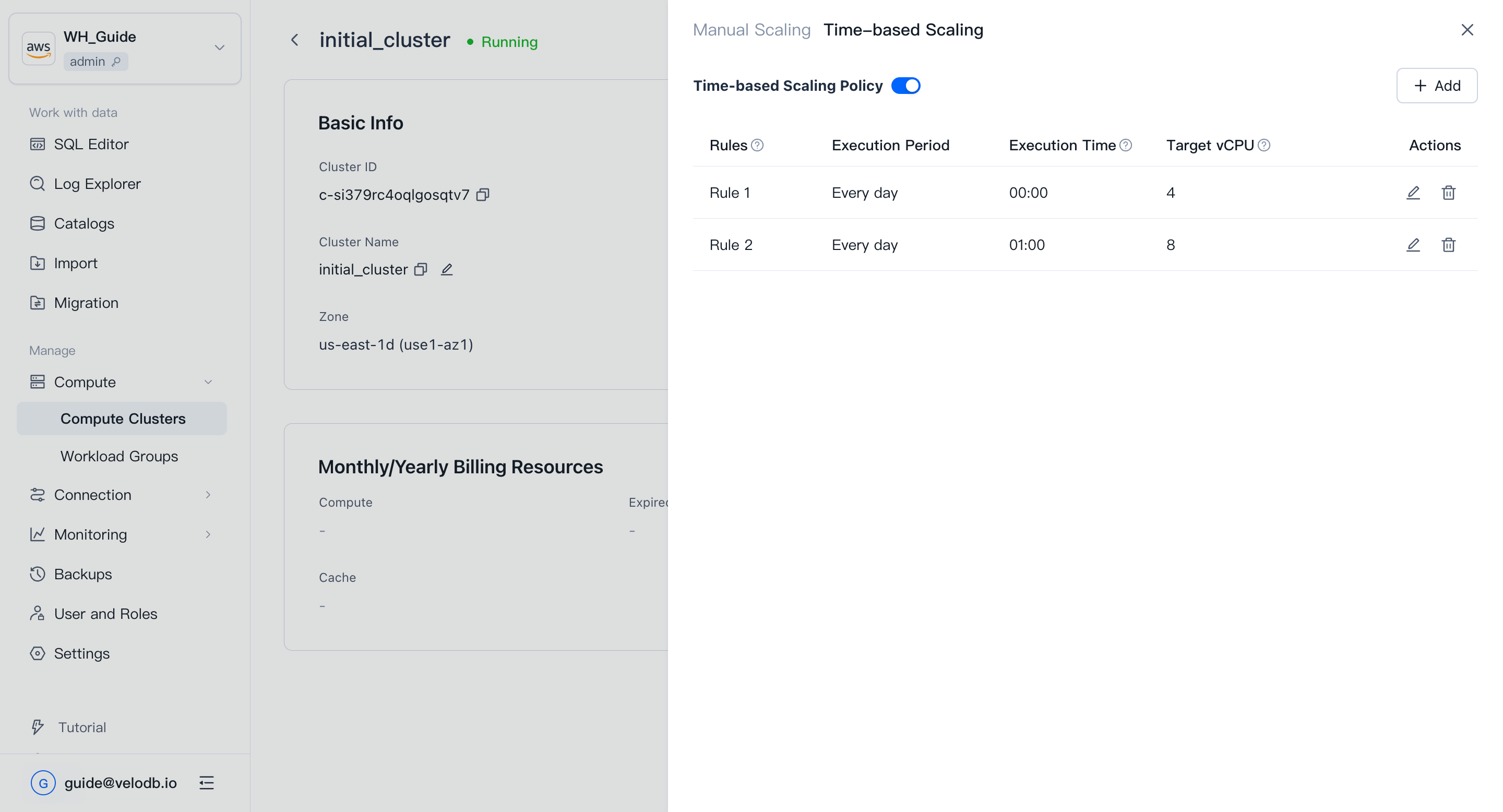
Note
- SaaS無料トライアルクラスターはスケーリングをサポートしていません。
- オンデマンドクラスターは目標vCPUが0のルールを持つことはできません。
- ルールはクラスターが正常に実行されている間のみ実行されます。クラスターが一時停止、再起動、またはアップグレード中の場合、ルールは再試行を待機します。30分以内に実行できない場合、スキップされます。
- 組織に十分な現金残高やcloud-marketplace控除チャネルがない場合、ルールは無効化されます。
- スケジュールは毎日固定されており、期間の編集はサポートされていません。
- ルールは少なくとも1時間間隔である必要があるため、クラスターあたり最大23ルールです。
- ルール実行時間は既存のルールと重複できません。
- スケーリングにより、一部のリクエストがクラッシュしたり遅延したりする可能性があります。
- スケールイン時、キャッシュ容量はコンピュート(vCPU)に比例して縮小し、余分なデータは削除されます。この期間中、一部のリクエストが著しく遅くなる可能性があります。
プライマリ-スタンバイ(仮想クラスター)
仮想クラスターは、2つの物理クラスターを可用性ゾーン間でアクティブ/スタンバイとしてペアリングし、クロスAZ高可用性とディザスタリカバリを提供します。プライマリAZで障害が発生すると、VeloDBは自動的にスタンバイクラスターにフェイルオーバーします。リアルタイムデータ同期により、中断やデータ損失を防ぎます。
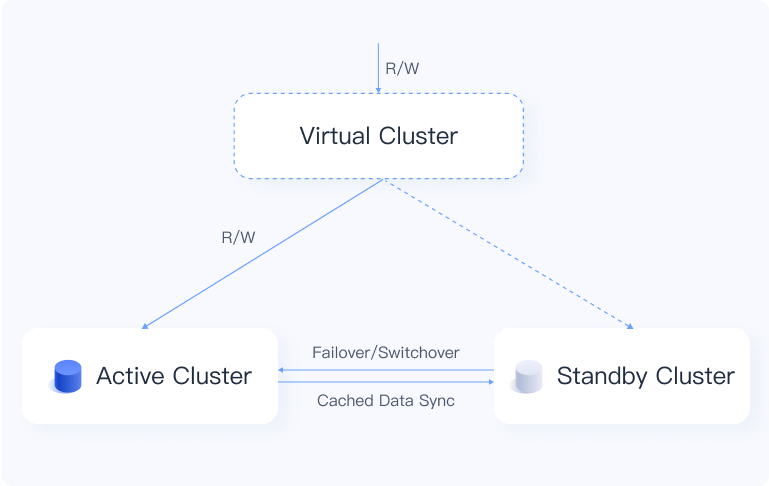
仮想クラスターを作成する前に、Running状態で異なる可用性ゾーンに配置された2つの物理クラスターを準備します。
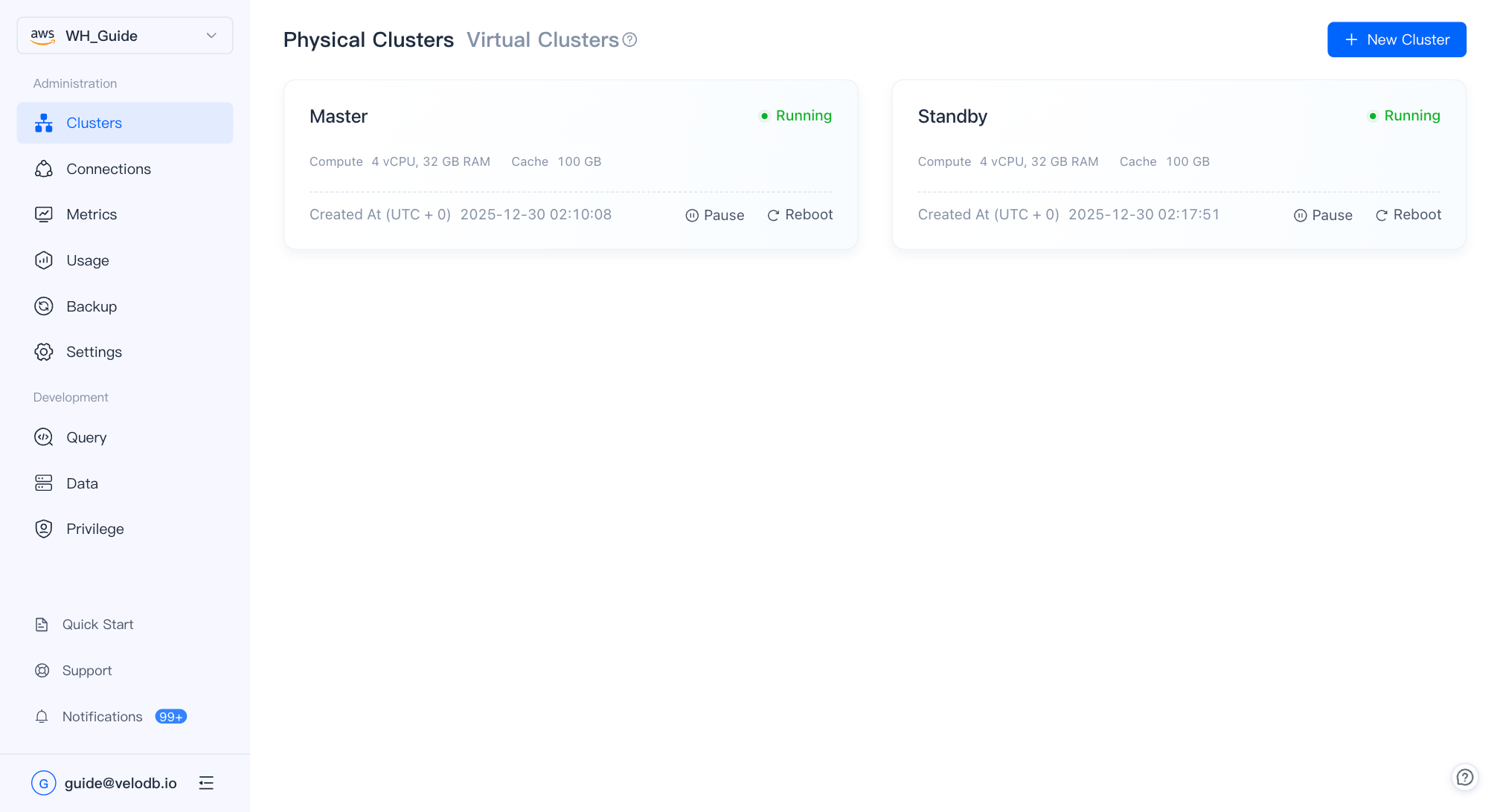
Virtual ClusterページでNew Virtual Clusterをクリックします。
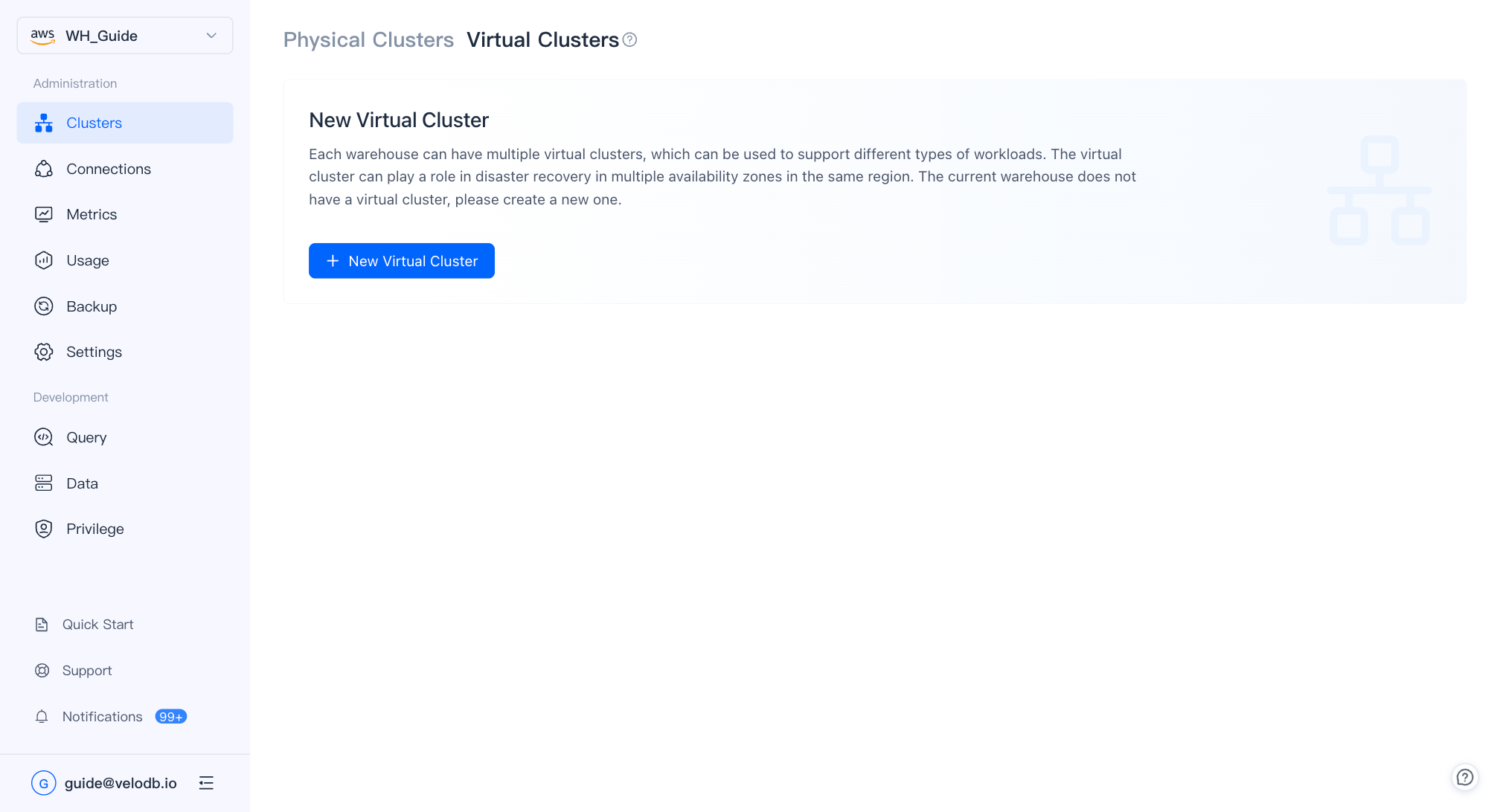
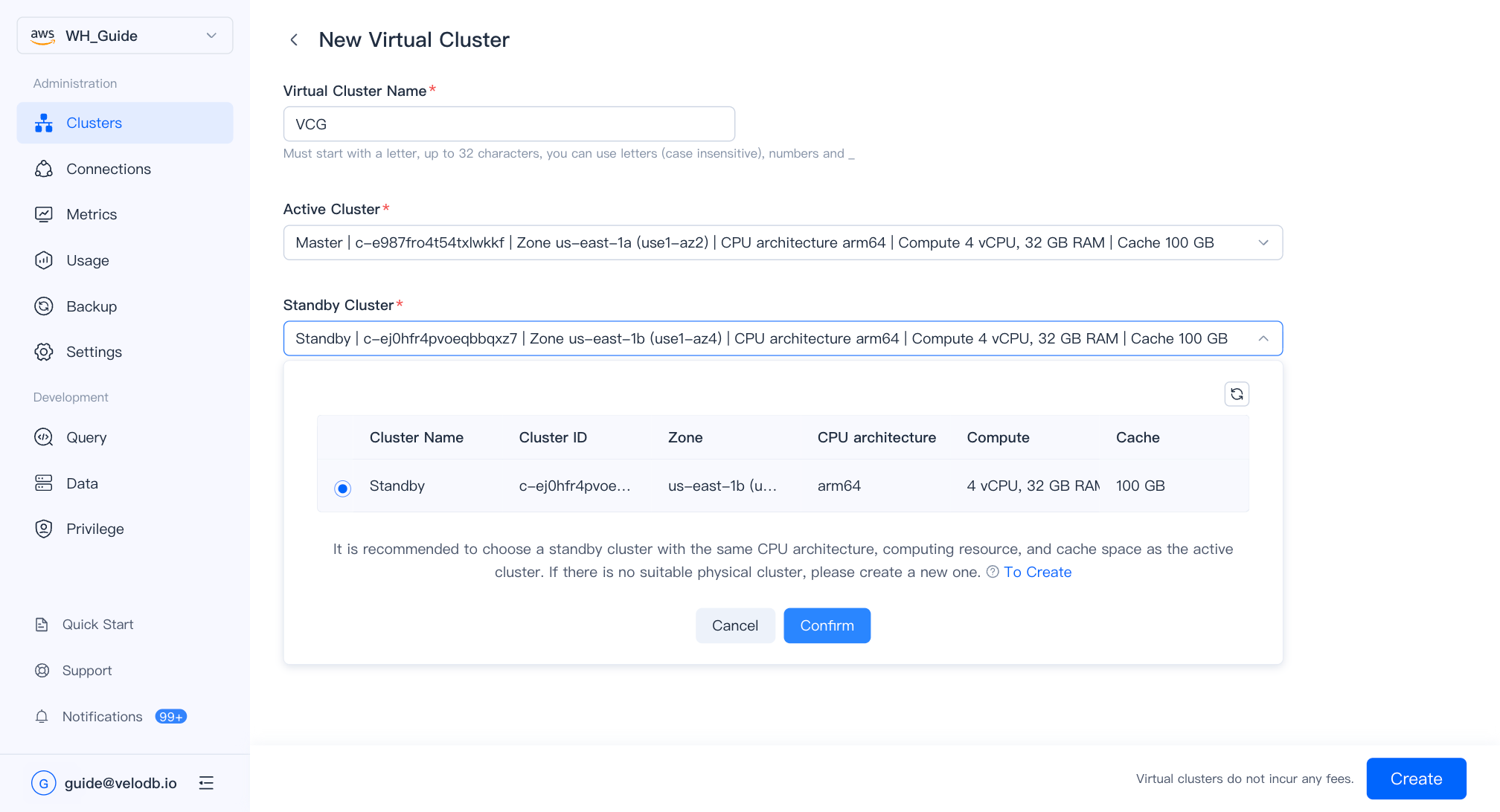
| パラメーター | 説明 |
|---|---|
| Virtual Cluster Name | 文字で始まり、最大32文字。文字、数字、アンダースコア。 |
| Active Cluster | トラフィックを積極的に処理するクラスター。 |
| Standby Cluster | フェイルオーバー時に引き継ぐスタンバイクラスター。同じ仕様が推奨されます。 |
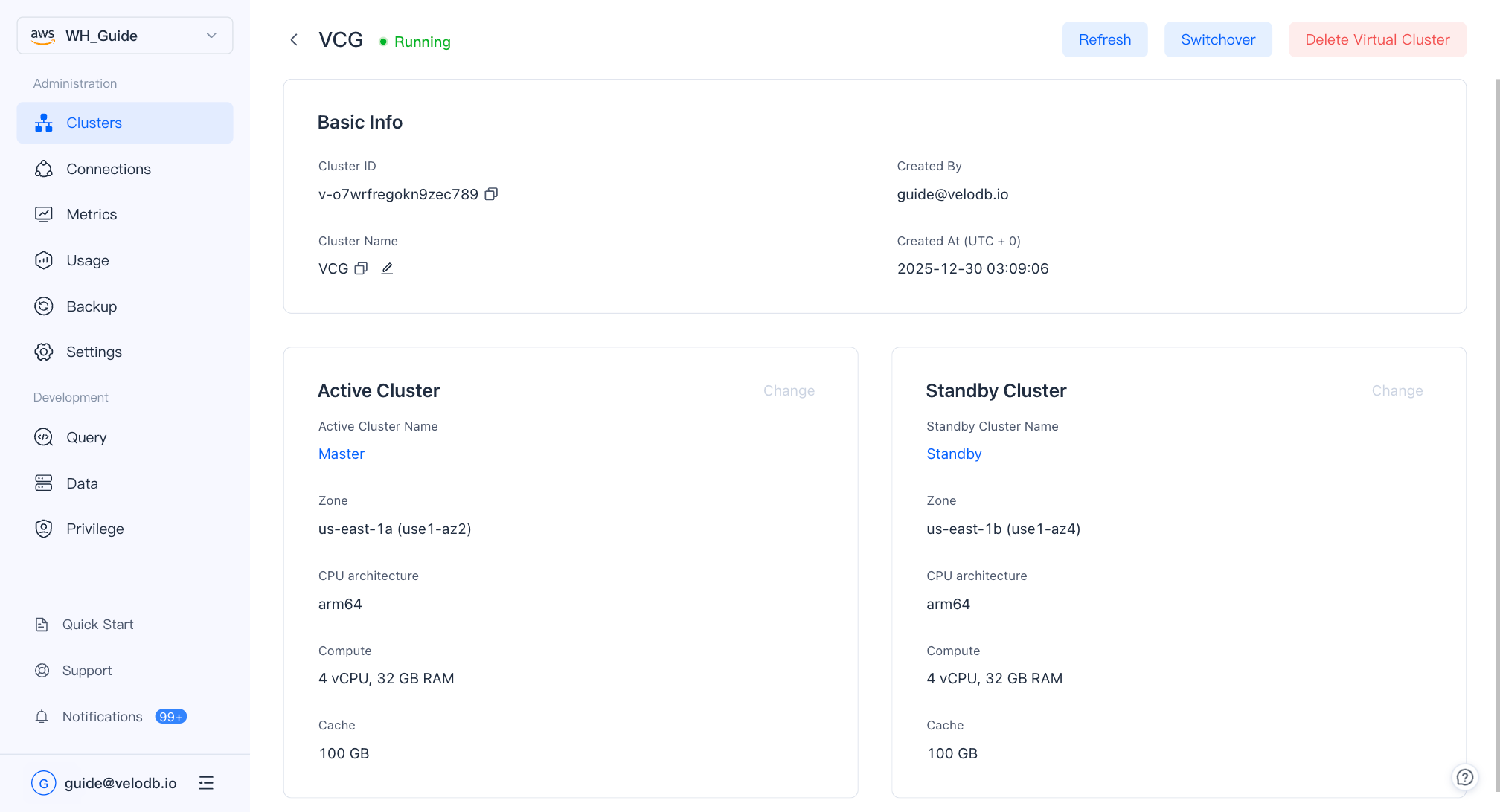
仮想クラスターが作成されたら、概要ページでそのカードをクリックして詳細ページを開き、アクティブ/スタンバイの割り当てを変更したり、仮想クラスターを削除したりできます。
クラスターの削除
Detailsページで、右上のDelete Clusterをクリックして確認します。
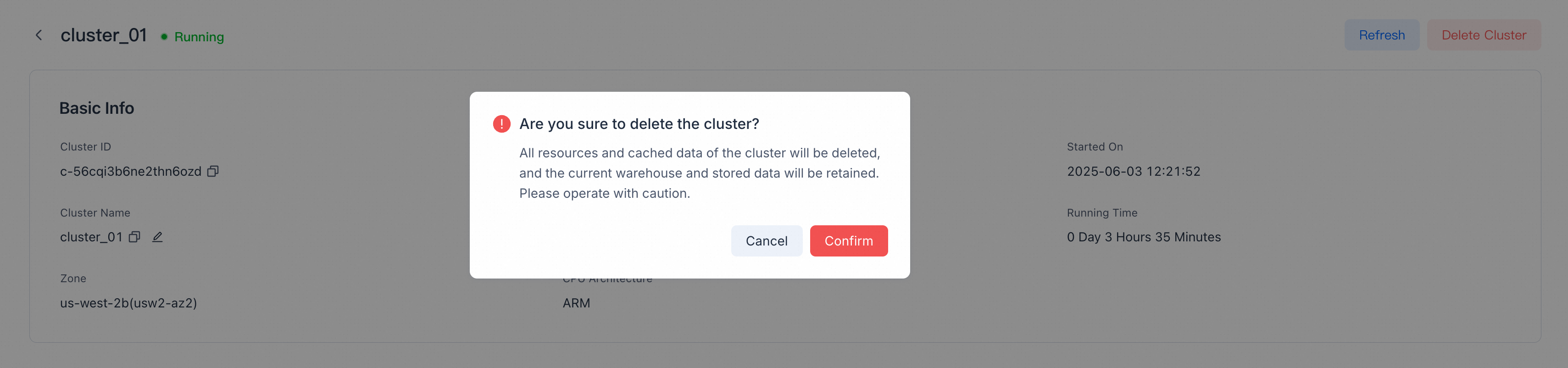
Note
- SaaS無料トライアルクラスターを削除すると、無料トライアルwarehouse、そのストレージ、データも削除されます。
- 月次/年次課金リソースを含むクラスターは早期削除できません。期限が切れてオンデマンド課金に変換されるまで待つか、自動更新がオフになっていることを確認してください。そうでないとクラスターは更新を続けます。
- すべてのリソースとキャッシュされたデータはVeloDB Cloudによって削除されます。削除前にクラスターにアクセスするビジネスを更新またはリダイレクトしてください。そうでないと関連リクエストが失敗します。