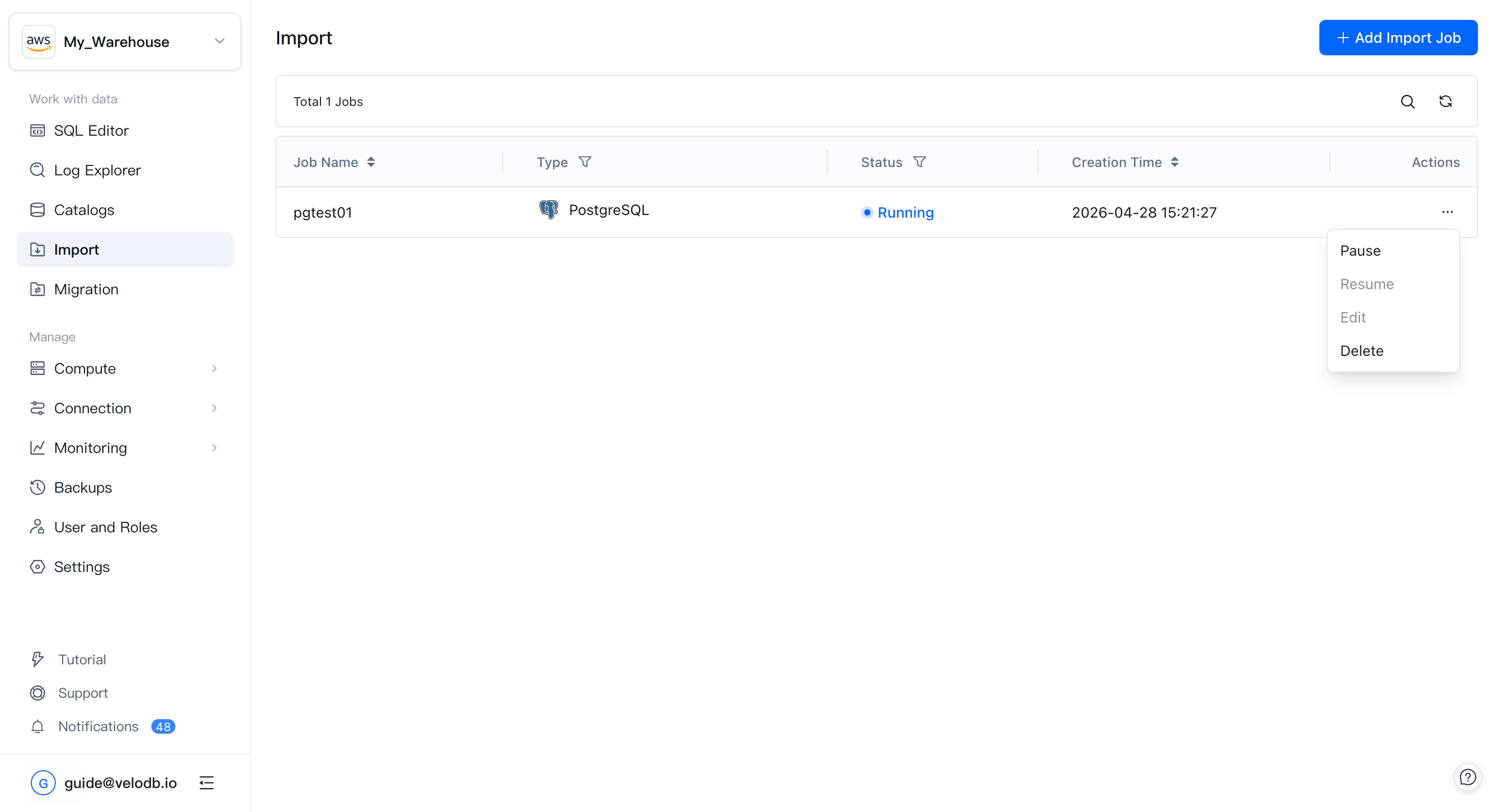
Import
Importモジュールは、データ統合のための統一されたビジュアルインターフェースを提供します。外部ソースからVeloDB Cloudウェアハウスへのデータの取り込みをシームレスに行うことができ、バッチ読み込みと自動テーブル作成による継続的な取り込みの両方をサポートします。
左側ナビゲーションのWork with dataグループからImportを開き、右上角の**+ Add Import Job**をクリックして新しいタスクを開始します。
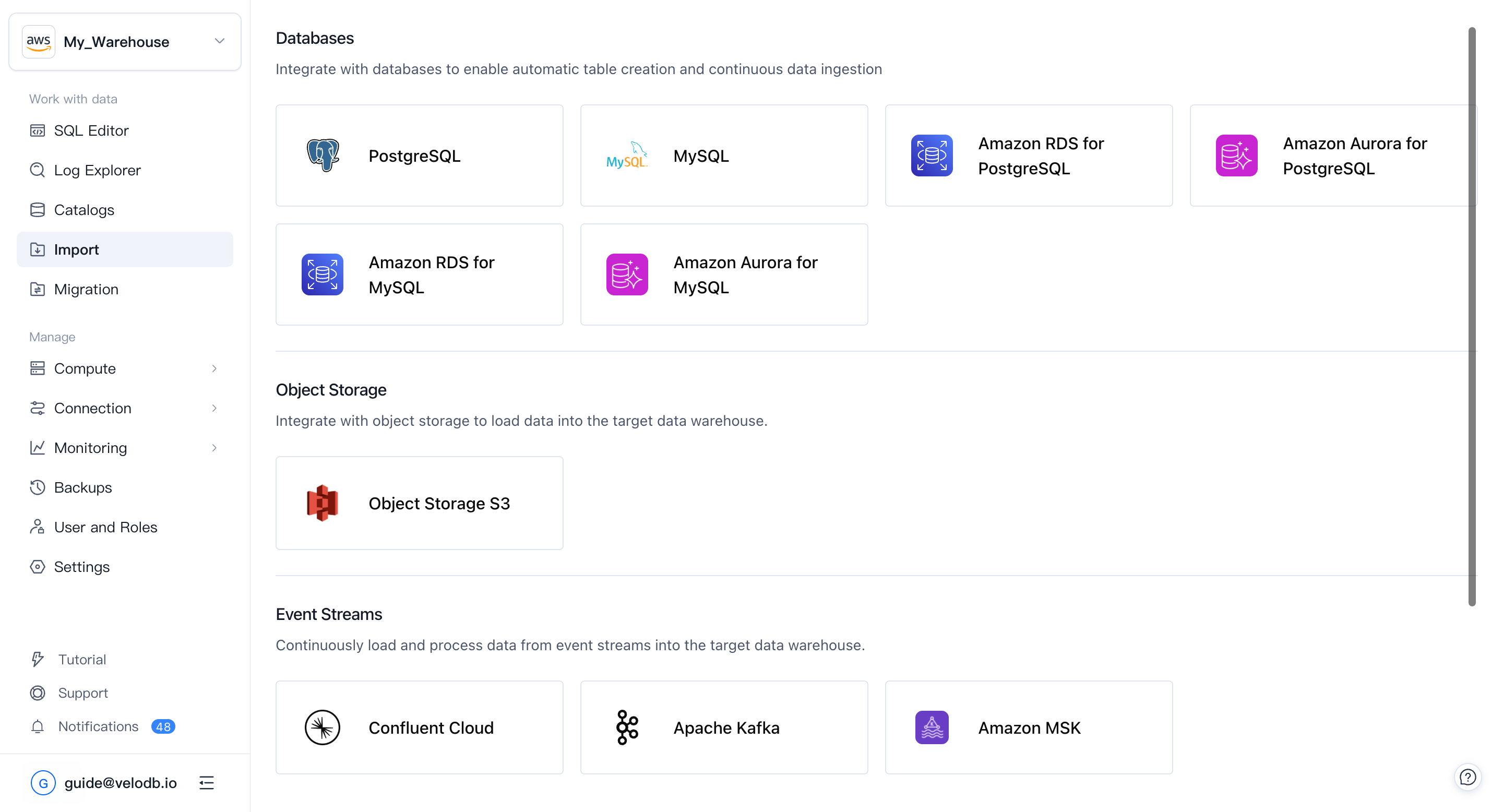
サポートされるデータソース
Importは現在3つのカテゴリのソースをサポートしています:
| Category | Sources |
|---|---|
| Databases | MySQL、PostgreSQL |
| Object Storage | Amazon S3(およびS3互換ストレージ) |
| Event Streams | Confluent Cloud、Apache Kafka、Amazon MSK |
importジョブの作成
設定の詳細はソースタイプによって異なりますが、すべてのソースで同じ4ステップのウィザードと継続的な管理ビューを使用します。以下のウォークスルーでは、データベースソース(PostgreSQL)を例として使用します。
1. データソースの選択
Importページで**+ Add Import Jobをクリックし、必要なカテゴリから、たとえばPostgreSQL**などのソースカードを選択します。
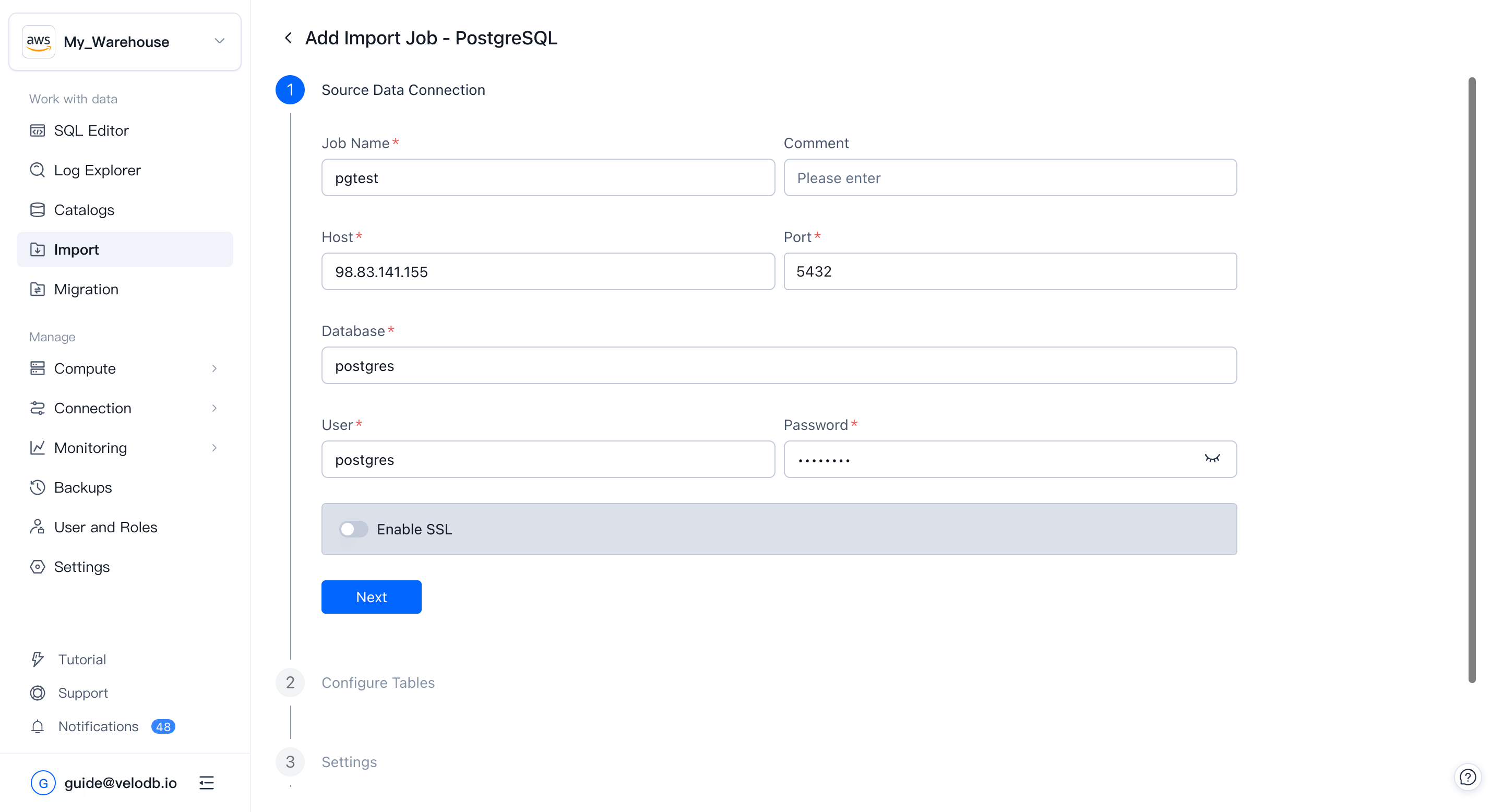
2. ソース接続の設定
VeloDB Cloudがソースに到達できるよう、ウィザードが要求するフィールドを入力します:
- Job Name — ジョブの一意で分かりやすい名前。
- Connection credentials — ソースに応じて、ホスト、ポート、データベース、ユーザー名、パスワード、またはAK/SK。オプションでSSLを有効にします。
Nextをクリックします。ウィザードはバックグラウンドでネットワーク接続と認証情報を検証します。
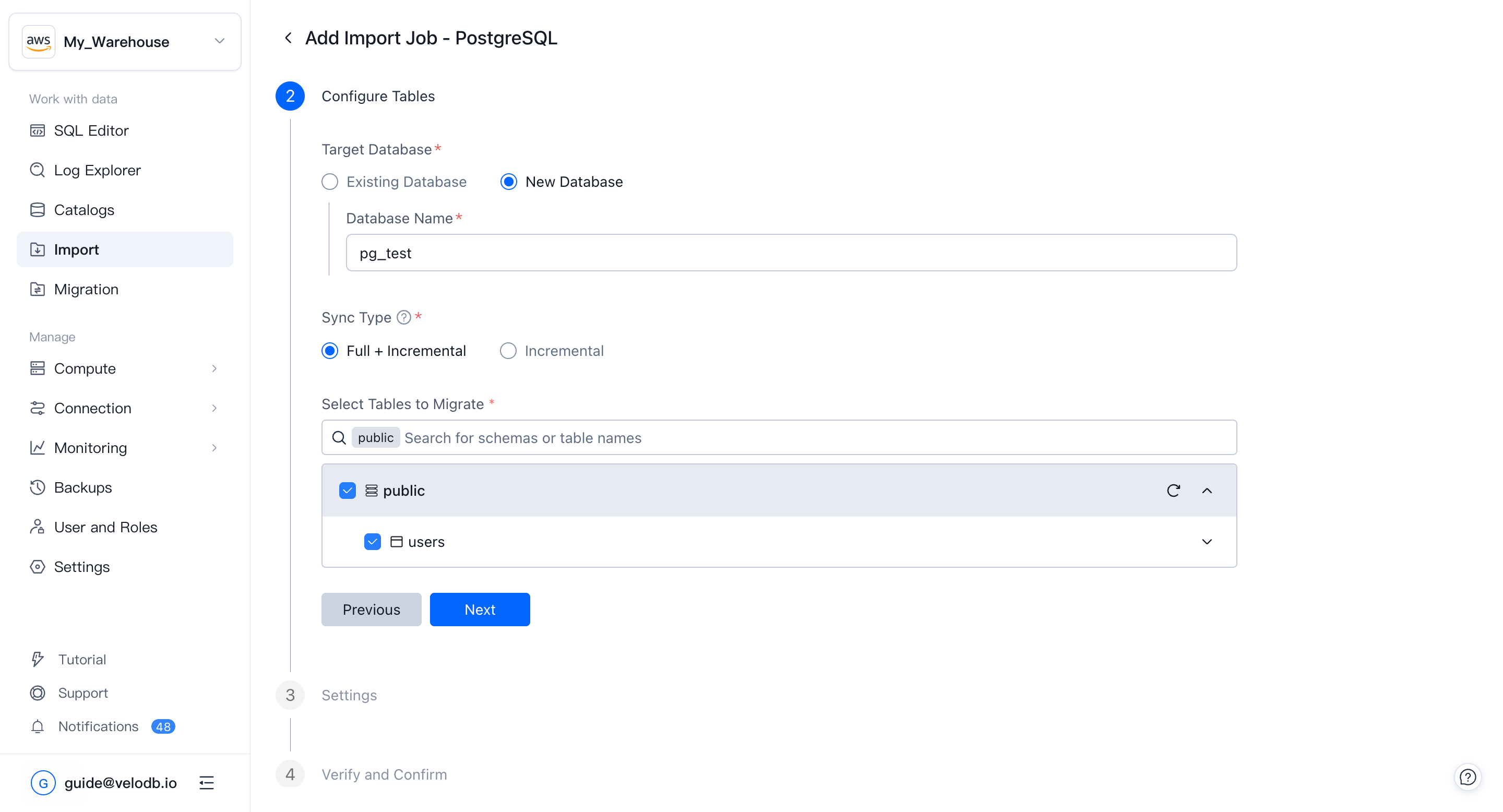
3. テーブルの設定
ターゲットデータベースと読み取るデータを定義します:
- Target Database — 既存のデータベースに書き込むか、新しいデータベースを作成します。
- Sync Type — Full + IncrementalまたはIncrementalのみ。
- Tables to migrate
- Databases: 同期するスキーマとテーブルを選択します。テーブルを展開してColumn Settings下でカラムレベルのフィルタリングを適用します。
- Event Streams: 消費するトピックと開始オフセットを指定します。
- Object Storage: バケットパスとファイルマッチングパターンを指定します。
4. Settings
ジョブの実行方法を調整します:
- Sync Interval — データの取得頻度(秒;デフォルトは60)。
- Strict Mode — インポート中の厳密なカラムタイプ変換を強制します。
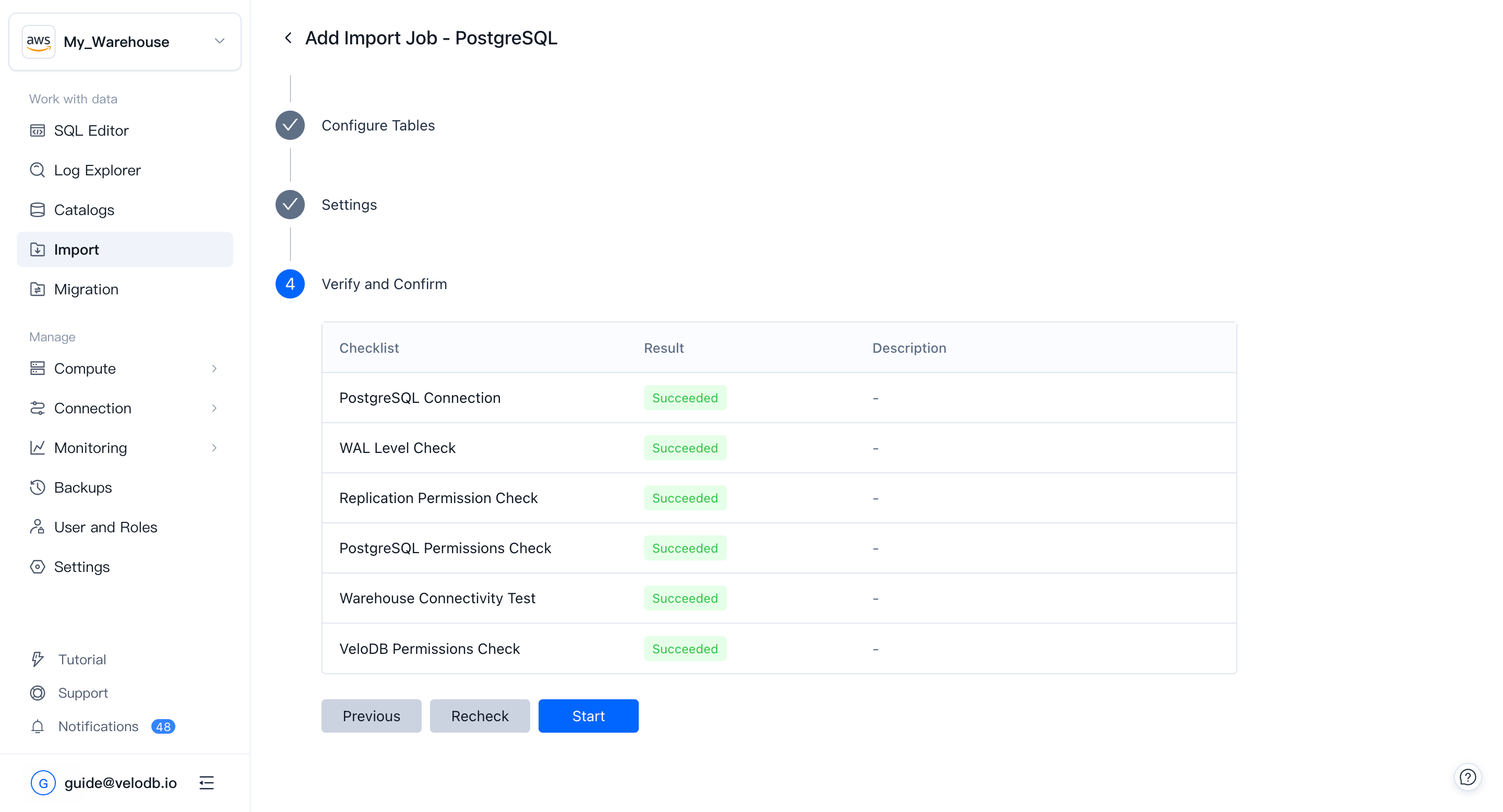
5. 検証と確認
事前チェックが自動的に実行されます:ネットワーク到達性、ソース側の権限(たとえば、CDCに必要なWAL / binlogアクセス)、およびターゲット側のテーブル作成と書き込み権限。
すべての項目がSucceededと表示されたら、Startをクリックしてジョブを開始します。
6. 管理と監視
開始後、Importジョブリストに戻り、各ジョブのステータス(Running、Paused、Failedなど)と作成時間を追跡できます。ジョブの横にある...メニューを使用して、Pause、Resume、Edit、またはDeleteを行います。