並列実行
Dorisの並列実行モデルはPipeline実行モデルであり、主にHyper論文で説明されている実装からインスピレーションを得ています。Pipeline実行モデルは、Doris内のクエリスレッド数を制限しながらマルチコアCPUの計算能力を最大限に活用し、実行時のスレッド爆発の問題に対処します。その設計、実装、および有効性の詳細については、[DSIP-027](DSIP-027: Support Pipeline Exec Engine - DORIS - Apache Software Foundation)および[DSIP-035](DSIP-035: PipelineX Execution Engine - DORIS - Apache Software Foundation)を参照してください。
Doris 3.0以降、Pipeline実行モデルは元のVolcanoモデルを完全に置き換えました。Pipeline実行モデルに基づいて、DorisはQuery、DDL、およびDMLステートメントの並列処理をサポートしています。
Physical Plan
Pipeline実行モデルをより深く理解するために、まず物理クエリプランにおける2つの重要な概念を紹介する必要があります:PlanFragmentとPlanNodeです。以下のSQLステートメントを例として使用します:
SELECT k1, SUM(v1) FROM A,B WHERE A.k2 = B.k2 GROUP BY k1 ORDER BY SUM(v1);
FEは最初にこれを以下の論理プランに変換します。各ノードはPlanNodeを表しています。各ノードタイプの詳細な意味は、物理プランの概要で確認できます。
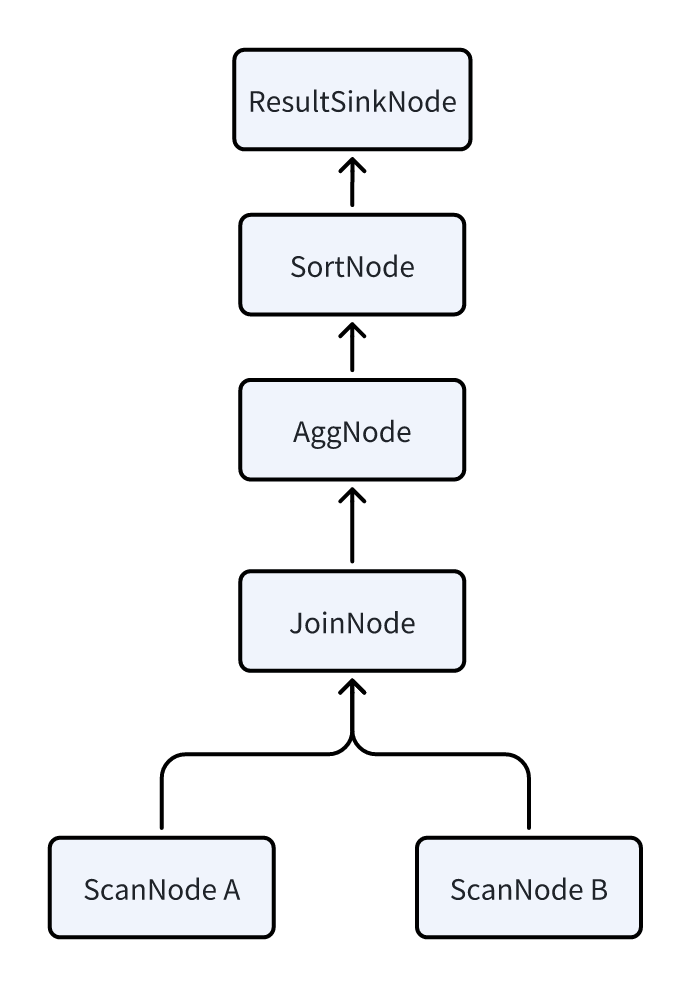
DorisはMPPアーキテクチャ上に構築されているため、各クエリはクエリのレイテンシを削減するために、可能な限り全てのBEを並列実行に関与させることを目指します。そのため、論理プランは物理プランに変換される必要があります。この変換は本質的に、論理プランにDataSinkとExchangeNodeを挿入することを含みます。これら2つのノードは複数のBE間でのデータシャッフリングを促進します。
変換後、各PlanFragmentはPlanNodeの一部に対応し、独立したタスクとしてBEに送信できます。各BEはPlanFragment内に含まれるPlanNodeを処理し、その後DataSinkとExchangeNodeオペレーターを使用して、後続の計算のために他のBEにデータをシャッフルします。
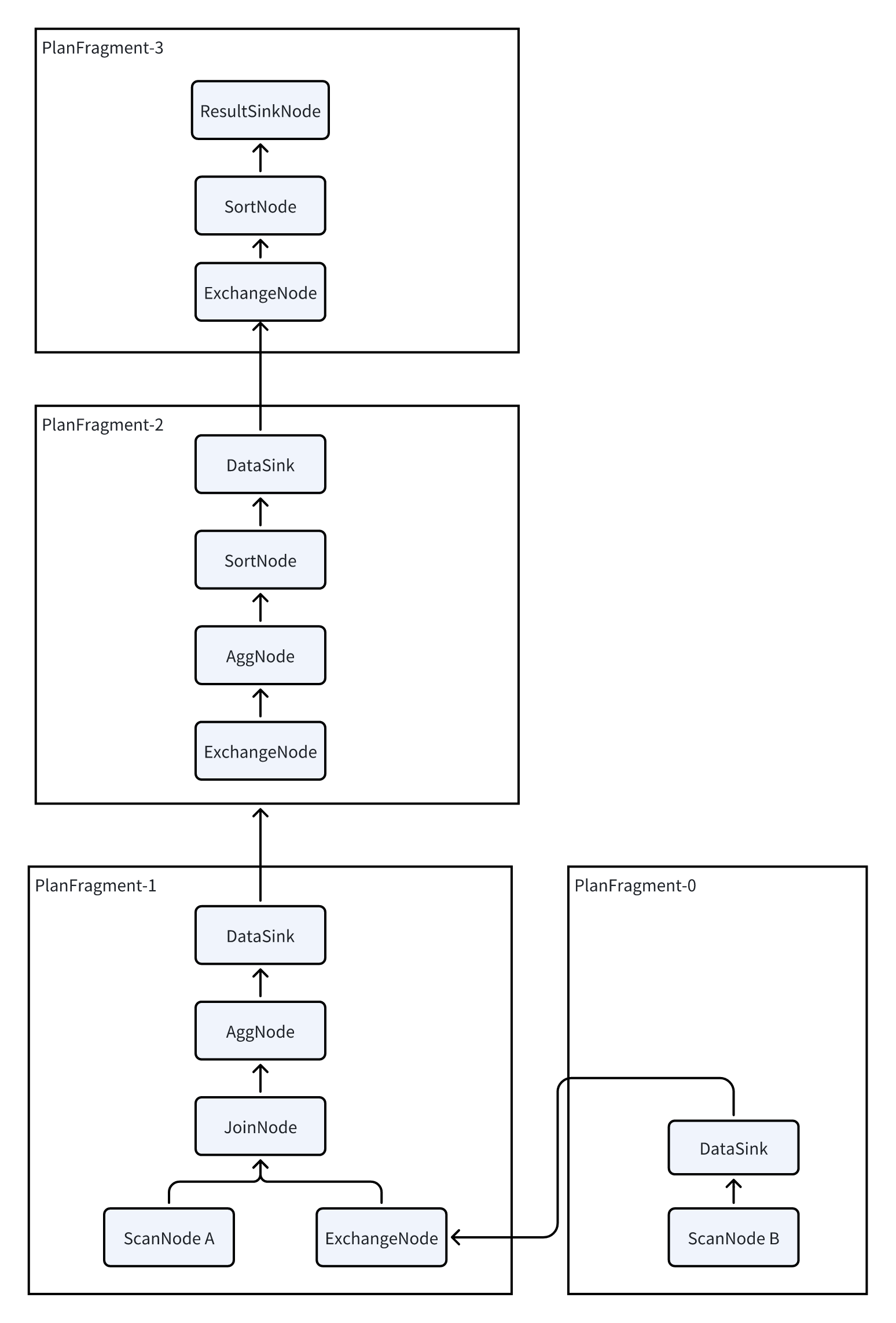
Dorisのプランは3つのレイヤーに分かれています:
-
PLAN: 実行プラン。SQL文はクエリプランナーによって実行プランに変換され、実行エンジンに実行用として提供されます。
-
FRAGMENT: Dorisは分散実行エンジンであるため、完全な実行プランは複数の単一マシン実行フラグメントに分割されます。FRAGMENTは完全な単一マシン実行フラグメントを表します。複数のフラグメントが組み合わさって完全なPLANを形成します。
-
PLAN NODE: オペレーター。実行プランの最小単位です。FRAGMENTは複数のオペレーターで構成され、各オペレーターは集約や結合操作など、特定の実行ロジックを担当します。
Pipeline実行
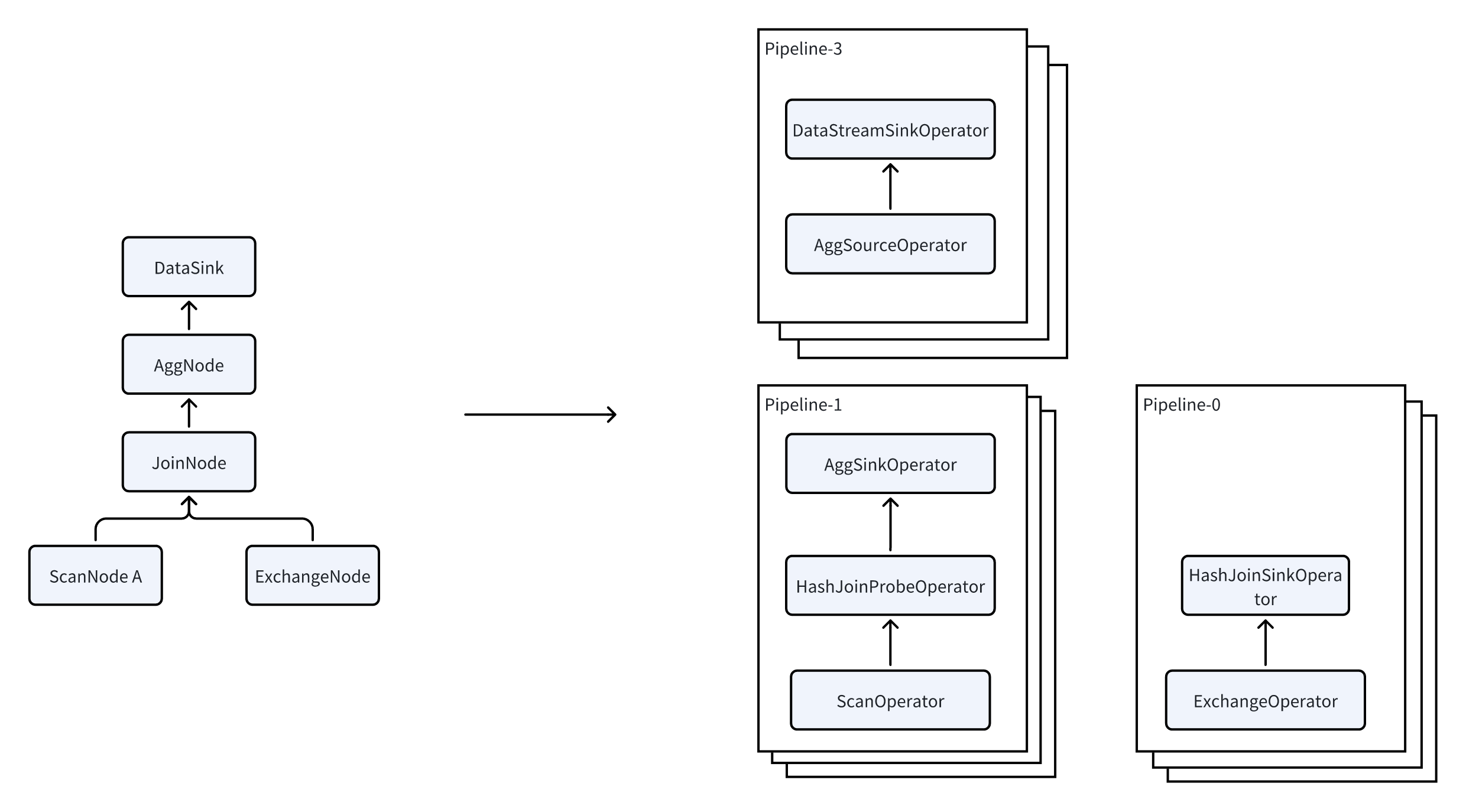
PlanFragmentはFEがBEに実行のために送信するタスクの最小単位です。BEは同じクエリに対して複数の異なるPlanFragmentを受信する場合があり、各PlanFragmentは独立して処理されます。PlanFragmentを受信すると、BEはそれを複数のPipelineに分割し、その後複数のPipelineTaskを開始して並列実行を実現し、クエリ効率を向上させます。
Pipeline
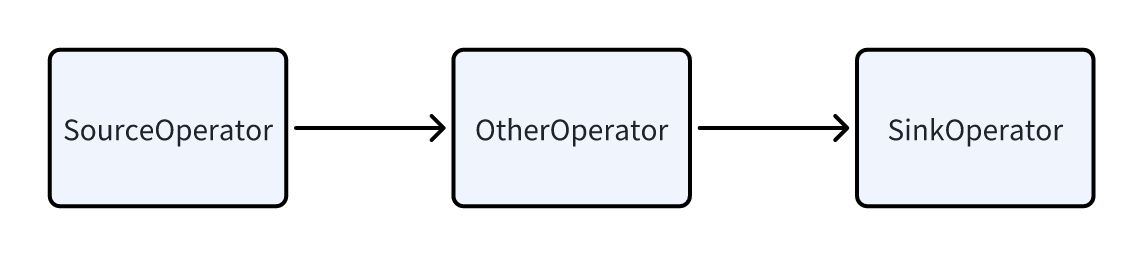
PipelineはSourceOperator、SinkOperator、および複数の中間オペレーターで構成されます。SourceOperatorは外部ソースからのデータ読み取りを表し、Table(例:OlapTable)またはバッファ(例:Exchange)にできます。SinkOperatorはデータ出力を表し、ネットワーク経由で他のノードにシャッフルされる(例:DataStreamSinkOperator)か、ハッシュTableに出力される(例:集約オペレーター、結合ビルドハッシュTableなど)ことができます。
複数のPipelineは実際に相互依存しています。JoinNodeを例に取ると、それは2つのPipelineに分割されます。Pipeline-0はExchangeからデータを読み取ってハッシュTableを構築し、Pipeline-1はTableからデータを読み取ってプローブ操作を実行します。これら2つのPipelineは依存関係で結ばれており、Pipeline-1はPipeline-0が完了した後にのみ実行できることを意味します。この依存関係はDependencyと呼ばれます。Pipeline-0が実行を終了すると、Dependencyのset_readyメソッドを呼び出して、Pipeline-1に実行準備ができたことを通知します。
PipelineTask
Pipelineは実際には論理的な概念であり、実行可能なエンティティではありません。Pipelineが定義されると、さらに複数のPipelineTaskにインスタンス化される必要があります。読み取る必要があるデータは異なるPipelineTaskに分散され、最終的に並列処理を実現します。同じPipelineの複数のPipelineTask内のオペレーターは同一ですが、それらの状態は異なります。例えば、異なるデータを読み取ったり、異なるハッシュTableを構築したりする場合があります。これらの異なる状態はLocalStateと呼ばれます。
各PipelineTaskは最終的にスレッドプールに独立したタスクとして実行するために送信されます。Dependencyトリガーメカニズムにより、このアプローチはマルチコアCPUの活用を向上させ、完全な並列化を実現します。
Operator
ほとんどの場合、Pipeline内の各オペレーターはPlanNodeに対応しますが、例外的な特殊なオペレーターもあります:
- JoinNodeはJoinBuildOperatorとJoinProbeOperatorに分割されます。
- AggNodeはAggSinkOperatorとAggSourceOperatorに分割されます。
- SortNodeはSortSinkOperatorとSortSourceOperatorに分割されます。 基本原則は、特定の「ブレーキング」オペレーター(計算を実行する前にすべてのデータを収集する必要があるオペレーター)について、データ取り込み部分をSinkに分割し、オペレーターからデータを取得する部分をSourceと呼ぶことです。
並列スキャン
データのスキャンは非常に重いI/O操作であり、ローカルディスクから大量のデータを読み取る必要があり(データレイクシナリオの場合はHDFSやS3から読み取り、さらに長いレイテンシが発生する)、かなりの時間を消費します。そのため、ScanOperatorに並列スキャン技術を導入しました。ScanOperatorは複数のScannerを動的に生成し、各Scannerは約100万から200万行のデータをスキャンします。スキャンを実行している間、各Scannerはデータの解凍、フィルタリング、その他の計算などのタスクを処理し、その後ScanOperatorが読み取るためにDataQueueにデータを送信します。
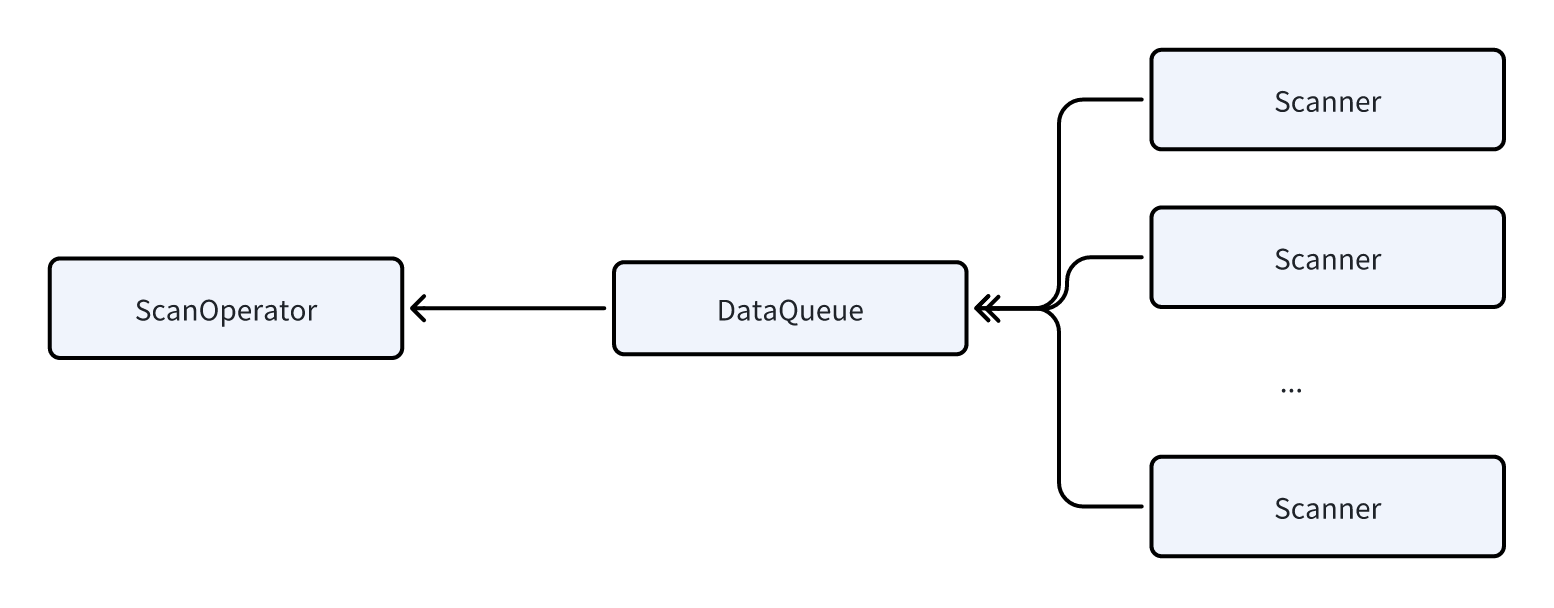
並列スキャン技術を使用することで、不適切なバケット化やデータスキューにより特定のScanOperatorが過度に長い時間を要し、クエリ全体のレイテンシを遅くする問題を効果的に回避できます。
Local Shuffle
Pipeline実行モデルにおいて、Local ShuffleはPipeline Breakerとして機能し、異なる実行タスク間でローカルにデータを再分散する技術です。HASHやRound Robinなどの方法を使用して、上流Pipelineが出力するすべてのデータを下流Pipelineのすべてのタスクに均等に分散します。これは実行中のデータスキューの問題を解決するのに役立ち、実行モデルがデータストレージやクエリプランによって制限されないことを保証します。次に、Local Exchangeがどのように動作するかを説明する例を提供します。
前の例のPipeline-1を使用して、Local Exchangeがデータスキューをどのように防ぐかをさらに説明します。
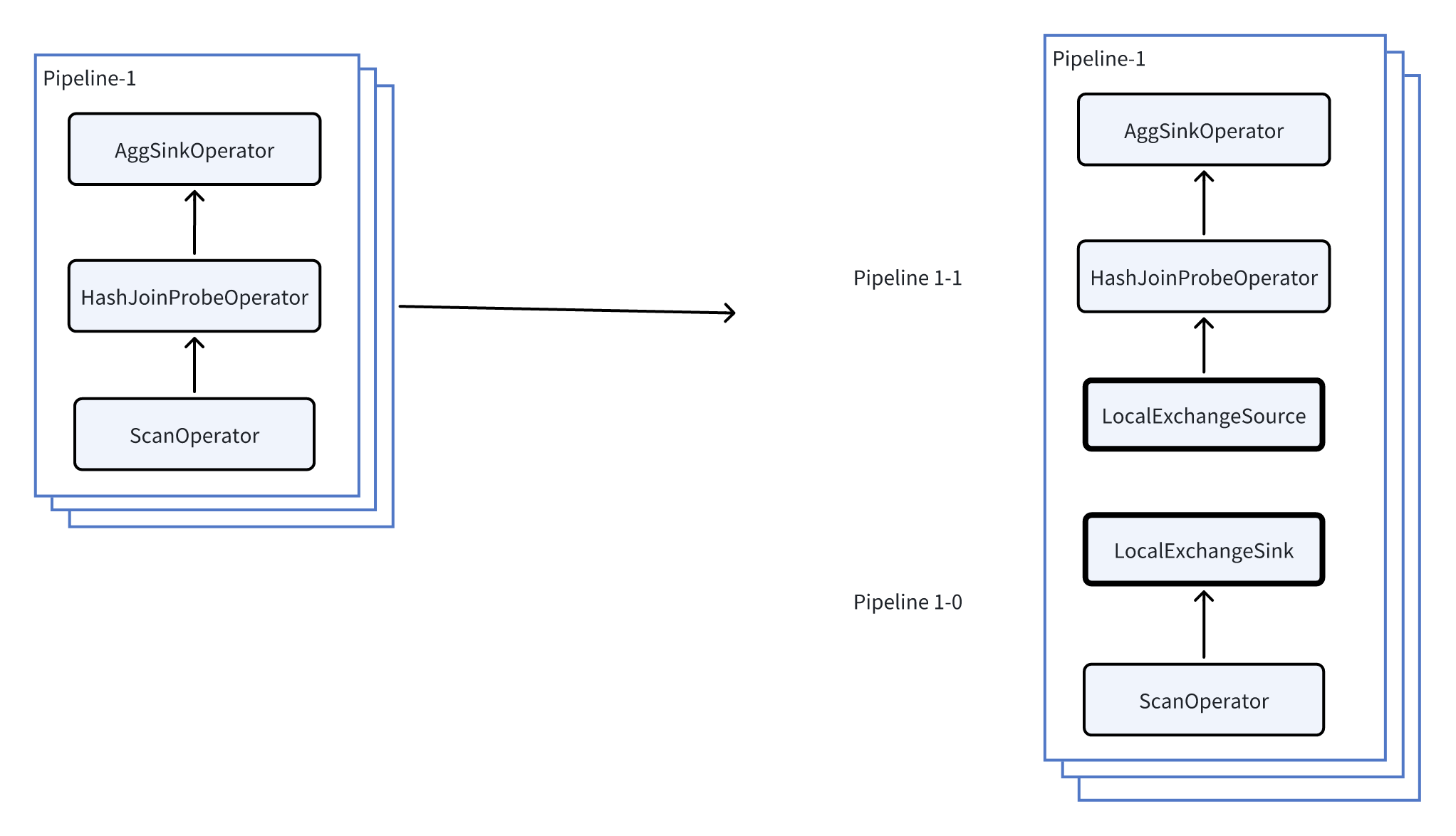
上図に示すように、Pipeline-1にLocal Exchangeを挿入することで、Pipeline-1をPipeline-1-0とPipeline-1-1にさらに分割します。
現在の並行度が3(各Pipelineに3つのタスク)であり、各タスクがストレージ層から1つのバケットを読み取ると仮定します。3つのバケットの行数はそれぞれ1、1、7です。Local Exchangeの挿入前後の実行は次のように変化します:
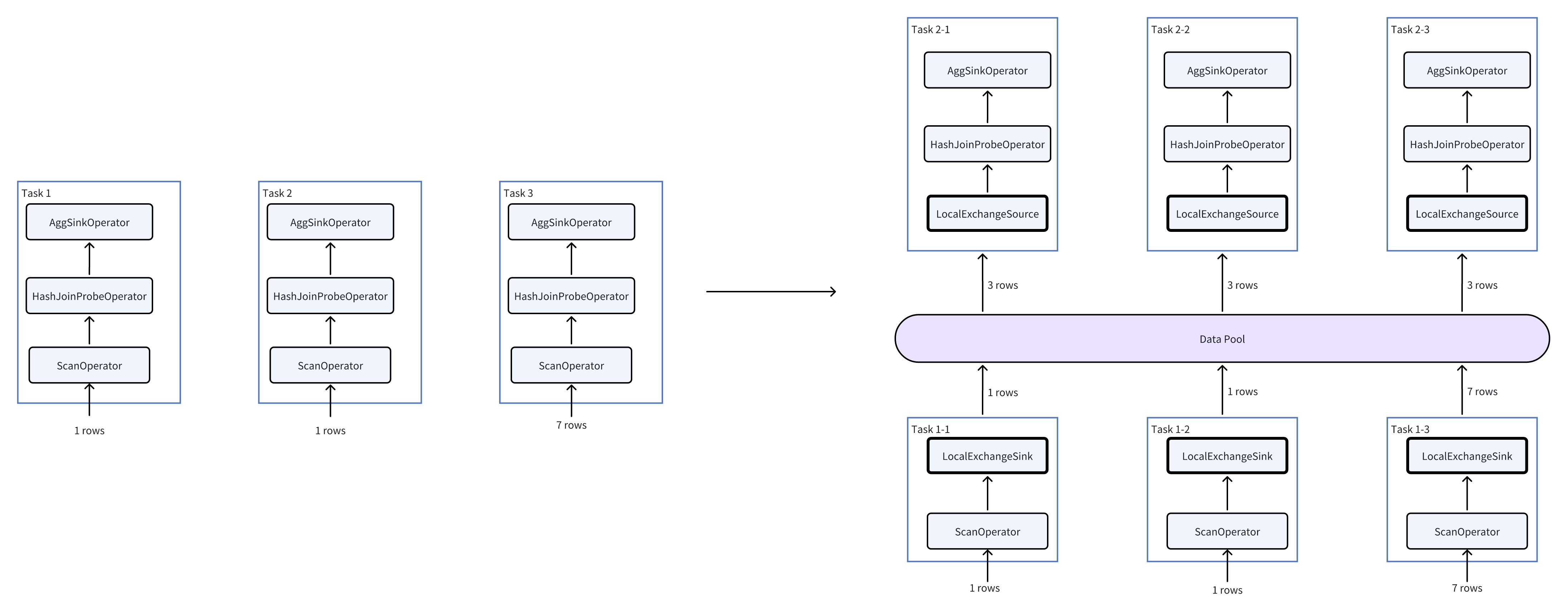
右図からわかるように、HashJoinとAggオペレーターが処理する必要があるデータ量が(1、1、7)から(3、3、3)に変化し、データスキューを回避します。
Local Shuffleは一連のルールに基づいて計画されます。例えば、クエリにJoin、Aggregation、Window Functionsなどの時間のかかるオペレーターが含まれる場合、データスキューを可能な限り最小化するためにLocal Shuffleが使用されます。