Colocate Groupを使用したJoinの最適化
colocate groupの定義はJoinの効率的な方法です。これにより、実行エンジンはJoin操作に通常伴うデータ転送のオーバーヘッドを効果的に回避できます(Colocate Groupの概要については、Colocation Joinを参照してください)。
しかし、一部のユースケースでは、Colocate Groupが正常に確立されている場合でも、実行プランがShuffle JoinまたはBucket Shuffle Joinとして表示されることがあります。この状況は通常、Dorisがデータを整理している際に発生します。例えば、複数のBE間でより均衡の取れたデータ分散を確保するために、BE間でtabletを移行している場合があります。
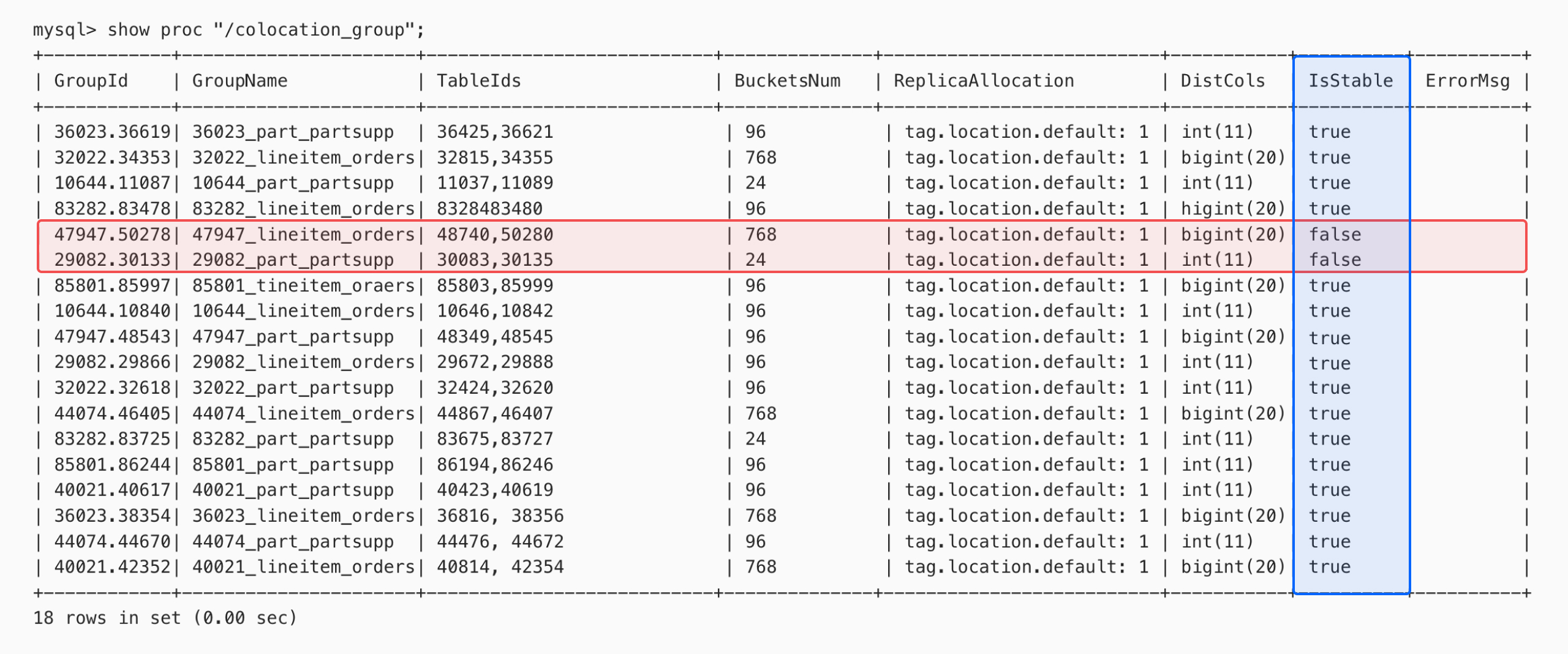
SHOW PROC "/colocation_group";コマンドを使用してColocate Groupのステータスを確認できます。下図に示すように、IsStableがfalseの場合、利用できないColocate Groupインスタンスがあることを示しています。