集約キーTable
DorisのAggregate Key Tableは、大規模データクエリにおける集約操作を効率的に処理するように設計されています。データに対して事前集約を実行することで、計算の冗長性を削減し、クエリ性能を向上させます。このTableは集約されたデータのみを格納し、生データを省略することで、ストレージ容量を節約し、クエリ性能を向上させます。
使用例
-
詳細データの要約: Aggregate Key Tableは、月次売上を評価するeコマースプラットフォーム、顧客取引合計を計算する金融リスク管理、または広告クリック合計を分析する広告キャンペーンなど、詳細データの多次元要約のシナリオで使用されます。
-
生の詳細データをクエリする必要がない場合: ダッシュボードレポートやユーザー取引行動分析などの使用例では、生データはデータレイクに保存されており、データベースに保持する必要がない場合、集約されたデータのみが格納されます。
原理
各データインポートはAggregate Key Tableにバージョンを作成し、コンパクション段階でバージョンがマージされます。クエリ時には、データは主キーによって集約されます:
-
データインポート段階
-
データはバッチでaggregate key tableにインポートされ、各バッチが新しいバージョンを作成します。
-
各バージョン内で、同じ集約キーを持つデータが事前集約されます(例:sum、countなど)。
-
-
バックグラウンドファイルマージ段階(コンパクション)
-
複数のバッチが複数のバージョンファイルを生成し、これらは定期的により大きなバージョンファイルにマージされます。
-
マージプロセス中、同じ集約キーを持つデータが再集約され、冗長性を削減し、ストレージを最適化します。
-
-
クエリ段階
-
クエリ時、システムはすべてのバージョンから同じ集約キーを持つデータを集約し、正確な結果を保証します。
-
このプロセスにより、大量のデータボリュームでも集約操作が効率的に実行されることが保証されます。集約された結果は高速クエリ用に最適化され、生データクエリと比較して大幅な性能向上を提供します。
-
Table作成手順
Table作成時、AGGREGATE KEYキーワードを使用してAggregate Key Tableを指定できます。Aggregate Key Tableは、格納時にValue列を集約するために使用されるKey列を指定する必要があります。
CREATE TABLE IF NOT EXISTS example_tbl_agg
(
user_id LARGEINT NOT NULL,
load_date DATE NOT NULL,
city VARCHAR(20),
last_visit_dt DATETIME REPLACE DEFAULT "1970-01-01 00:00:00",
cost BIGINT SUM DEFAULT "0",
max_dwell INT MAX DEFAULT "0",
)
AGGREGATE KEY(user_id, load_date, city)
DISTRIBUTED BY HASH(user_id) BUCKETS 10;
上記の例では、ユーザー情報とアクセス行動のファクトTableが定義されており、user_id、load_date、cityが集約用のKeyカラムとして使用されています。データインポート時に、KeyカラムはひとつのRowに集約され、ValueカラムはPARAMETER指定された集約タイプに従って集約されます。
Aggregate Key Tableでは、以下のタイプのディメンション集約がサポートされています:
| 集約メソッド | 説明 |
|---|---|
| SUM | 合計、複数のValueRows을 累積します。 |
| REPLACE | 置換、次のバッチのValueが以前に挿入されたValueを置き換えます。 |
| MAX | 最大値を保持します。 |
| MIN | 最小値を保持します。 |
| REPLACE_IF_NOT_NULL | 非null値を置換します。REPLACEと異なり、null値は置換されません。 |
| HLL_UNION | HLL型カラムの集約メソッドで、HyperLogLogアルゴリズムを使用します。 |
| BITMAP_UNION | BITMAP型カラムの集約メソッドで、ビットマップユニオン集約を実行します。 |
上記の集約メソッドがビジネス要件を満たさない場合は、agg_stateタイプの使用を検討してください。
データ挿入とストレージ
Aggregate Key Tableでは、データはプライマリキーに基づいて集約されます。データ挿入後、集約オペレーションが完了します。
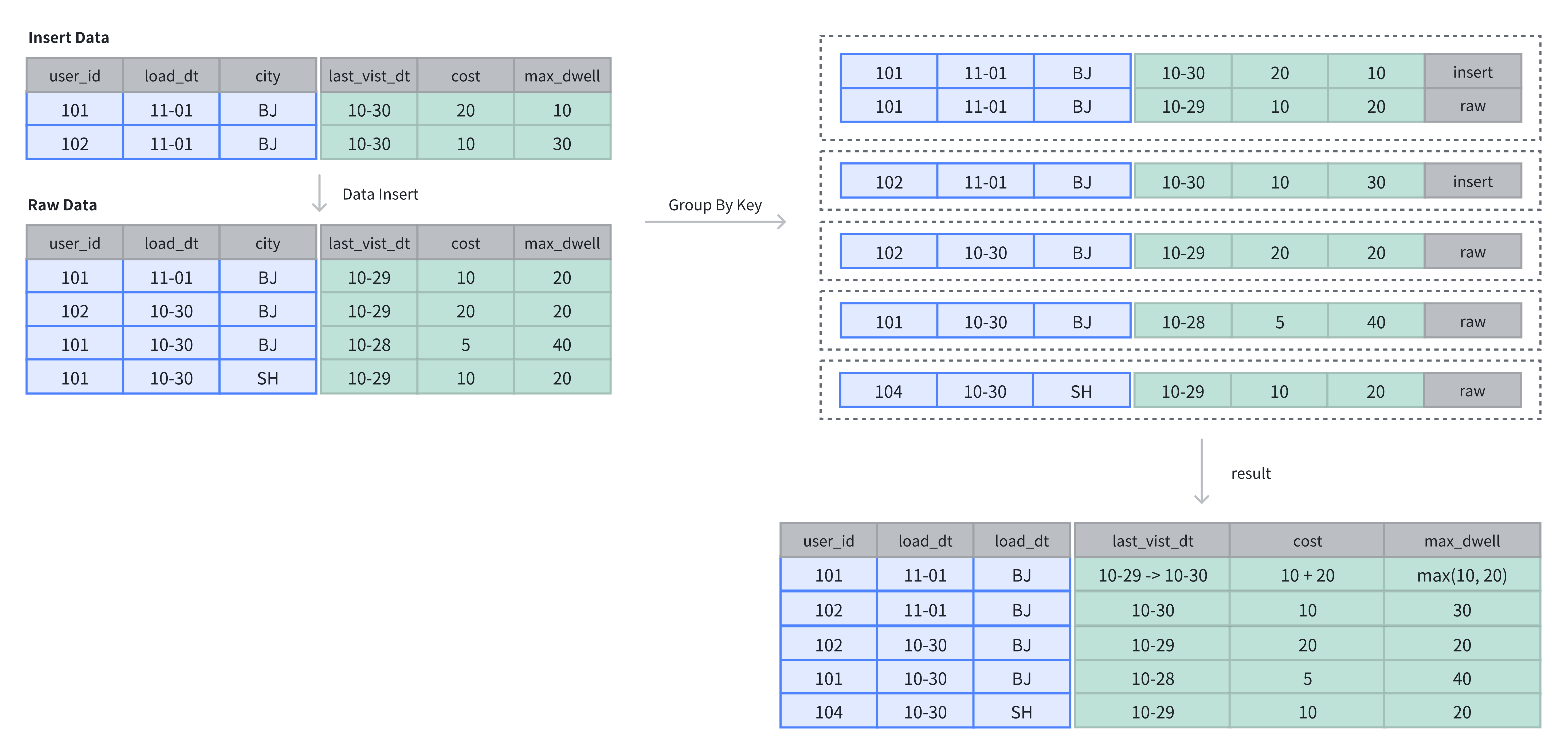
上記の例では、Tableに元々4行のデータがありました。2行を挿入した後、Keyカラムに基づいてディメンションカラムの集約オペレーションが実行されます:
-- 4 rows raw data
INSERT INTO example_tbl_agg VALUES
(101, '2024-11-01', 'BJ', '2024-10-29', 10, 20),
(102, '2024-10-30', 'BJ', '2024-10-29', 20, 20),
(101, '2024-10-30', 'BJ', '2024-10-28', 5, 40),
(101, '2024-10-30', 'SH', '2024-10-29', 10, 20);
-- insert into 2 rows
INSERT INTO example_tbl_agg VALUES
(101, '2024-11-01', 'BJ', '2024-10-30', 20, 10),
(102, '2024-11-01', 'BJ', '2024-10-30', 10, 30);
-- check the rows of table
SELECT * FROM example_tbl_agg;
+---------+------------+------+---------------------+------+----------------+
| user_id | load_date | city | last_visit_date | cost | max_dwell_time |
+---------+------------+------+---------------------+------+----------------+
| 102 | 2024-10-30 | BJ | 2024-10-29 00:00:00 | 20 | 20 |
| 102 | 2024-11-01 | BJ | 2024-10-30 00:00:00 | 10 | 30 |
| 101 | 2024-10-30 | BJ | 2024-10-28 00:00:00 | 5 | 40 |
| 101 | 2024-10-30 | SH | 2024-10-29 00:00:00 | 10 | 20 |
| 101 | 2024-11-01 | BJ | 2024-10-30 00:00:00 | 30 | 20 |
+---------+------------+------+---------------------+------+----------------+
AGG_STATE
::: Info Tips: AGG_STATEは実験的な機能であり、開発およびテスト環境での使用が推奨されます。 :::
AGG_STATEはKeyカラムとして使用することはできません。Table作成時に集約関数のシグネチャを宣言する必要があります。ユーザーは長さやデフォルト値を指定する必要はありません。データストレージサイズは関数の実装に依存します。
set enable_agg_state = true;
CREATE TABLE aggstate(
k1 int NULL,
v1 int SUM,
v2 agg_state<group_concat(string)> generic
)
AGGREGATE KEY(k1)
DISTRIBUTED BY HASH(k1) BUCKETS 3;
この場合、agg_stateはデータ型をagg_stateとして宣言するために使用され、sum/group_concatは集約関数のシグネチャです。agg_stateはint、array、stringと同様にデータ型であることに注意してください。agg_stateはstate、merge、unionなどのコンビネータとのみ使用できます。agg_stateは集約関数の中間結果を表します。例えば、集約関数group_concatの場合、agg_stateは最終結果ではなく、group_concat('a', 'b', 'c')の中間状態を表すことができます。
agg_state型はstate関数を使用して生成する必要があります。このTableでは、group_concat_stateを使用する必要があります:
insert into aggstate values(1, 1, group_concat_state('a'));
insert into aggstate values(1, 2, group_concat_state('b'));
insert into aggstate values(1, 3, group_concat_state('c'));
insert into aggstate values(2, 4, group_concat_state('d'));
Tableでの計算方法は以下の図に示されています:

Tableにクエリを実行する際、merge操作を使用して複数のstate値をマージし、最終的な集約結果を返すことができます。group_concatは順序付けが必要なため、結果が不安定になる可能性があります。
select group_concat_merge(v2) from aggstate;
+------------------------+
| group_concat_merge(v2) |
+------------------------+
| d,c,b,a |
+------------------------+
最終的な集計結果が不要な場合は、unionを使用して複数の中間集計結果を結合し、新しい中間結果を生成することができます。
insert into aggstate select 3,sum_union(k2),group_concat_union(k3) from aggstate;
Table内の計算は以下の通りです:

クエリ結果は以下の通りです:
mysql> select sum_merge(k2) , group_concat_merge(k3)from aggstate;
+---------------+------------------------+
| sum_merge(k2) | group_concat_merge(k3) |
+---------------+------------------------+
| 20 | c,b,a,d,c,b,a,d |
+---------------+------------------------+
mysql> select sum_merge(k2) , group_concat_merge(k3)from aggstate where k1 != 2;
+---------------+------------------------+
| sum_merge(k2) | group_concat_merge(k3) |
+---------------+------------------------+
| 16 | c,b,a,d,c,b,a |
+---------------+------------------------+