BloomFilter インデックス
インデックスの原理
BloomFilterインデックスは、BloomFilterに基づくスキップインデックスの一種です。その原理は、BloomFilterを使用して等価クエリの指定された条件を満たさないデータブロックをスキップし、それによってIOを削減してクエリを高速化することです。
BloomFilterは、1970年にBloomによって提案された高速検索アルゴリズムで、複数のハッシュ関数を使用します。これは、100%の精度を必要とせずに、要素がセットに属するかどうかを迅速に判定する必要があるシナリオで一般的に使用されます。BloomFilterには以下の特徴があります:
- 要素がセットに含まれているかどうかをチェックするために使用される、空間効率的な確率的データ構造
- メンバーシップチェックにおいて、BloomFilterは2つの結果のうちの1つを返す:セットに含まれている可能性がある、またはセットに含まれていないことが確実
BloomFilterは、非常に長いバイナリビット配列と一連のハッシュ関数で構成されます。ビット配列は最初すべて0に設定されます。要素をチェックする際、一連のハッシュ関数によってハッシュ化され、一連の値を生成し、配列のこれらの位置のビットが1に設定されます。
下図は、m=18とk=3のBloomFilterの例を示しています(mはビット配列のサイズ、kはハッシュ関数の数)。セット内の要素x、y、zが3つの異なるハッシュ関数によってビット配列にハッシュされます。要素wをクエリする際、ハッシュ関数によって計算されたビットのいずれかが0の場合、wはセットに含まれていません。逆に、すべてのビットが1の場合、ハッシュ衝突の可能性があるため、wがセットに含まれている可能性があることのみを示し、確実ではありません。
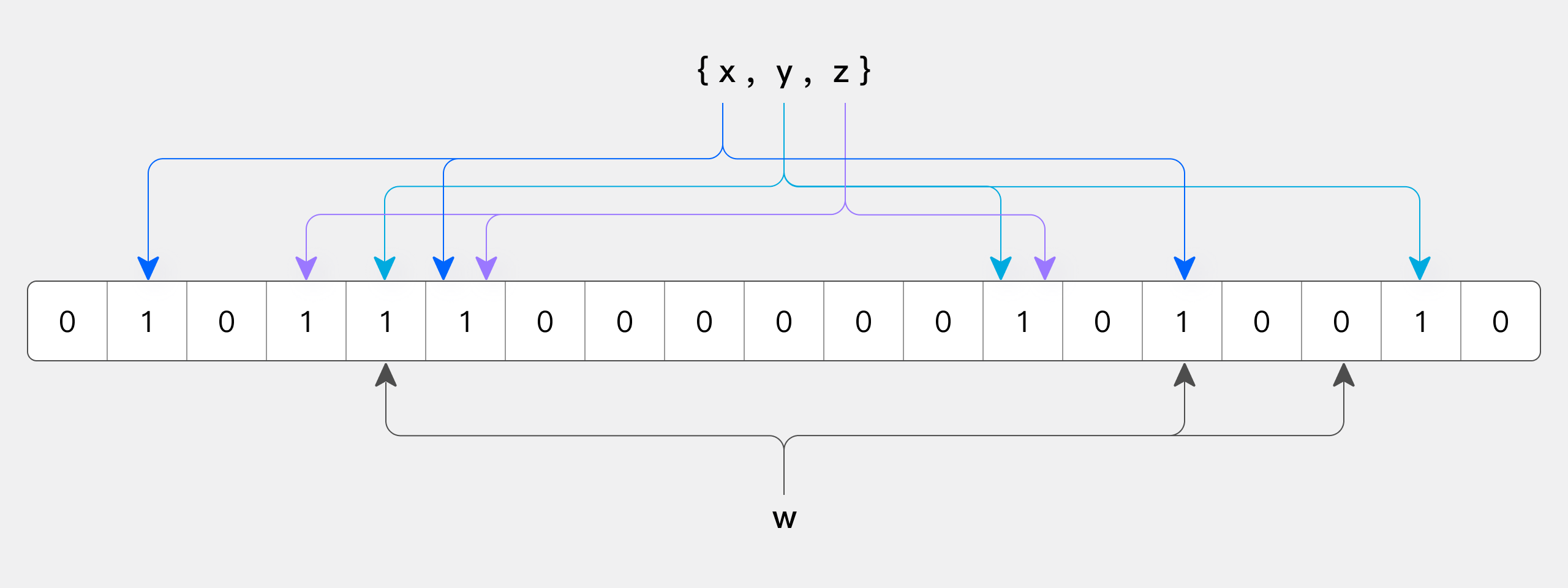
したがって、計算された位置のすべてのビットが1の場合、ハッシュ衝突の可能性があるため、要素がセットに含まれている可能性があることのみを示し、確実ではありません。これがBloomFilterの「偽陽性」の性質です。そのため、BloomFilterベースのインデックスは条件を満たさないデータをスキップできますが、条件を満たすデータを正確に特定することはできません。
DorisのBloomFilterインデックスはページ単位で構築され、各データブロックがBloomFilterを保存します。書き込み時には、データブロック内の各値が対応するBloomFilterにハッシュされます。クエリ時には、等価条件に対して、各データブロックのBloomFilterが値を含んでいるかどうかをチェックします。含まれていない場合、データブロックはスキップされ、IOが削減されクエリが高速化されます。
使用ケース
BloomFilterインデックスは等価クエリ(=とINを含む)を高速化でき、useridのような一意のidフィールドなど、高カーディナリティフィールドに対して効果的です。
BloomFilterには以下の制限があります:
- inと=以外のクエリ(!=、NOT IN、>、<など)には効果がありません。
- Tinyint、Float、Double型の列でのBloomFilterインデックスをサポートしていません。
- 低カーディナリティフィールドに対する高速化効果は限定的です。例えば、2つの値のみを持つ「性別」フィールドは、ほぼすべてのデータブロックに含まれる可能性が高く、BloomFilterインデックスが無意味になります。
クエリに対するBloomFilterインデックスの効果を確認するには、Query Profileの関連メトリクスを分析できます。
- BlockConditionsFilteredBloomFilterTimeは、BloomFilterインデックスによって消費された時間です。
- RowsBloomFilterFilteredは、BloomFilterによってフィルタリングされた行数です。他のRows値と比較して、BloomFilterインデックスのフィルタリング効果を分析できます。
インデックスの管理
Table作成時のBloomFilterインデックスの作成
歴史的な理由により、BloomFilterインデックスを定義する構文は、転置インデックスに使用される一般的なINDEX構文とは異なります。BloomFilterインデックスは、TableのPROPERTIESで"bloom_filter_columns"を使用して指定され、1つ以上のフィールドを指定できます。
PROPERTIES (
"bloom_filter_columns" = "column_name1,column_name2"
);
BloomFilter Indexesの表示
SHOW CREATE TABLE table_name;
既存TableでのBloomFilterインデックスの追加または削除
ALTER TABLEを使用してTableのbloom_filter_columnsプロパティを変更し、BloomFilterインデックスを追加または削除します。
column_name3にBloomFilterインデックスを追加
ALTER TABLE table_name SET ("bloom_filter_columns" = "column_name1,column_name2,column_name3");
column_name1のBloomFilterインデックスを削除する
ALTER TABLE table_name SET ("bloom_filter_columns" = "column_name2,column_name3");
インデックスの使用
BloomFilterインデックスは、WHERE句の等価クエリを高速化するために使用されます。適用可能な場合に自動的に有効になり、特別な構文は必要ありません。
BloomFilterインデックスの高速化効果は、Query Profileの以下のメトリクスを使用して分析できます:
- RowsBloomFilterFiltered: BloomFilterインデックスによってフィルタされた行数。他のRows値と比較してインデックスのフィルタ効果を分析できます。
- BlockConditionsFilteredBloomFilterTime: BloomFilter転置インデックスで消費された時間。
使用例
以下は、DorisでBloomFilterインデックスを作成する方法の例です。
DorisのBloomFilterインデックスは、CREATE TABLE文で"bloom_filter_columns"プロパティを追加することで作成され、k1、k2、k3がBloomFilterインデックスのキー列になります。例えば、以下はsaler_idとcategory_idにBloomFilterインデックスを作成します。
CREATE TABLE IF NOT EXISTS sale_detail_bloom (
sale_date date NOT NULL COMMENT "Sale date",
customer_id int NOT NULL COMMENT "Customer ID",
saler_id int NOT NULL COMMENT "Salesperson",
sku_id int NOT NULL COMMENT "Product ID",
category_id int NOT NULL COMMENT "Product category",
sale_count int NOT NULL COMMENT "Sales quantity",
sale_price DECIMAL(12,2) NOT NULL COMMENT "Unit price",
sale_amt DECIMAL(20,2) COMMENT "Total sales amount"
)
DUPLICATE KEY(sale_date, customer_id, saler_id, sku_id, category_id)
DISTRIBUTED BY HASH(saler_id) BUCKETS 10
PROPERTIES (
"replication_num" = "1",
"bloom_filter_columns"="saler_id,category_id"
);