ロード時のデータ変換
Dorisは、データ読み込み時に強力なデータ変換機能を提供しており、これによりデータ処理ワークフローを簡素化し、追加のETLツールへの依存を減らすことができます。主に4種類の変換をサポートしています:
-
Column Mapping: ソースデータの列をターゲットTableの異なる列にマッピングします。
-
Column Transformation: 関数と式を使用してソースデータをリアルタイムで変換します。
-
Pre-filtering: 列のマッピングと変換の前に、不要な生データをフィルタリングします。
-
Post-filtering: 列のマッピングと変換後に、最終結果をフィルタリングします。
これらの組み込みデータ変換機能により、読み込み効率を向上させ、データ処理ロジックの一貫性を確保することができます。
読み込み構文
Stream Load
HTTPヘッダーで以下のパラメータを設定してデータ変換を構成します:
| パラメータ | 説明 |
|---|---|
columns | 列のマッピングと変換を指定 |
where | Post-filteringを指定 |
注意: Stream LoadはPre-filteringをサポートしていません。
例:
curl --location-trusted -u user:passwd \
-H "columns: k1, k2, tmp_k3, k3 = tmp_k3 + 1" \
-H "where: k1 > 1" \
-T data.csv \
http://<fe_ip>:<fe_http_port>/api/example_db/example_table/_stream_load
Broker Load
以下の句を使用してSQL文でデータ変換を実装します:
| 句 | 説明 |
|---|---|
column list | カラムマッピングを指定、形式:(k1, k2, tmp_k3) |
SET | カラム変換を指定 |
PRECEDING FILTER | 事前フィルタリングを指定 |
WHERE | 事後フィルタリングを指定 |
例:
LOAD LABEL test_db.label1
(
DATA INFILE("s3://bucket_name/data.csv")
INTO TABLE `test_tbl`
(k1, k2, tmp_k3)
PRECEDING FILTER k1 = 1
SET (
k3 = tmp_k3 + 1
)
WHERE k1 > 1
)
WITH S3 (...);
Routine Load
以下の句を使用してSQL文でデータ変換を実装します:
| 句 | 説明 |
|---|---|
COLUMNS | 列マッピングと変換を指定 |
PRECEDING FILTER | 事前フィルタリングを指定 |
WHERE | 事後フィルタリングを指定 |
例:
CREATE ROUTINE LOAD test_db.label1 ON test_tbl
COLUMNS(k1, k2, tmp_k3, k3 = tmp_k3 + 1),
PRECEDING FILTER k1 = 1,
WHERE k1 > 1
...
Insert Into
Insert IntoはSELECT文で直接データ変換を実行でき、データフィルタリングにWHERE句を使用します。
Column Mapping
Column mappingは、ソースデータの列とターゲットTableの列との対応関係を定義するために使用されます。以下のシナリオに対応できます:
- ソースデータの列とターゲットTableの列の順序が一致しない
- ソースデータの列とターゲットTableの列の数が一致しない
実装原理
Column mappingの実装は2つのステップに分けることができます:
- ステップ1:データソース解析 - データ形式に基づいて生データを中間変数に解析
- ステップ2:Column Mappingと割り当て - 列名によって中間変数をターゲットTableフィールドにマッピング
以下は3つの異なるデータ形式の処理フローです:
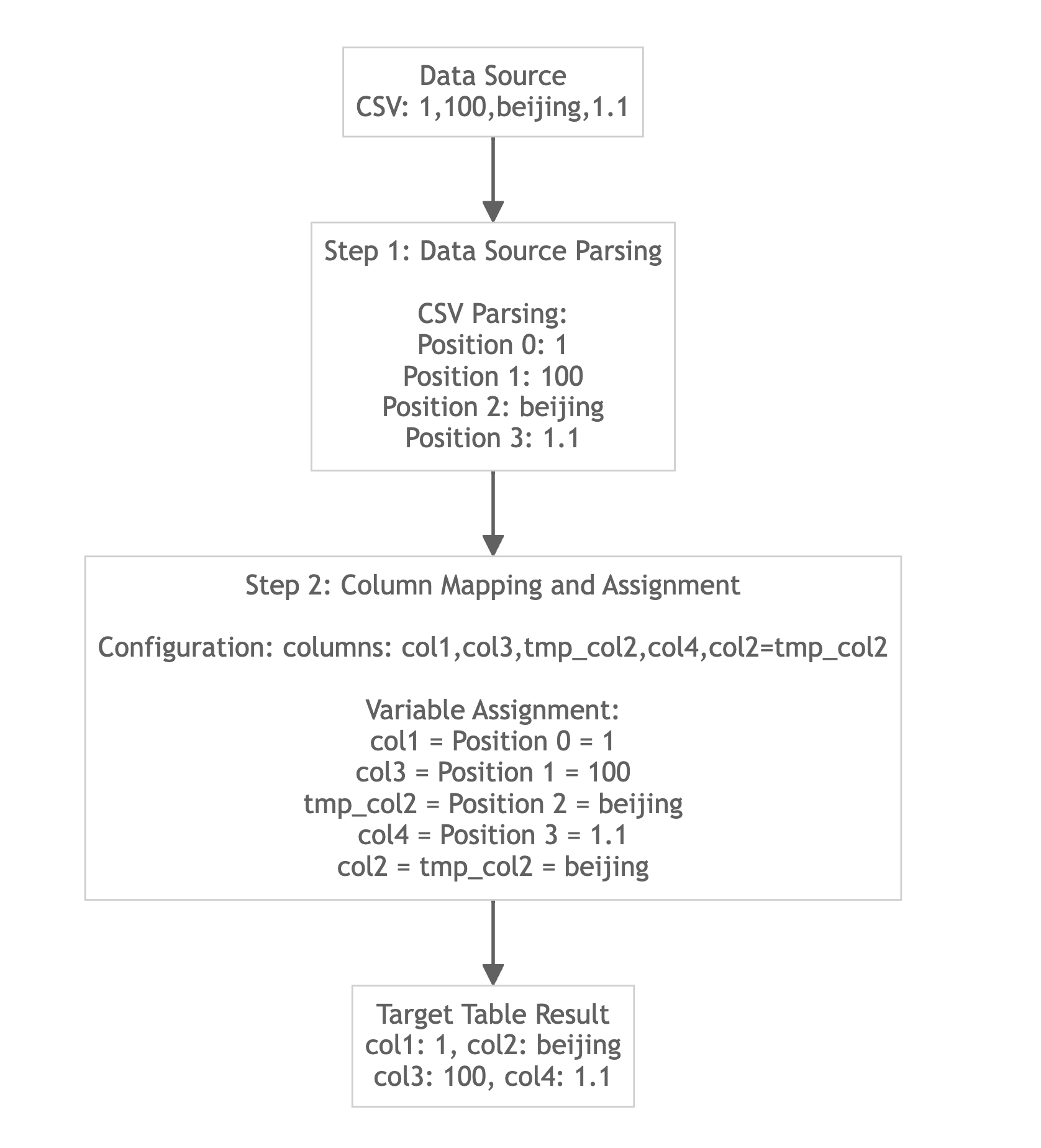
CSV形式データのロード
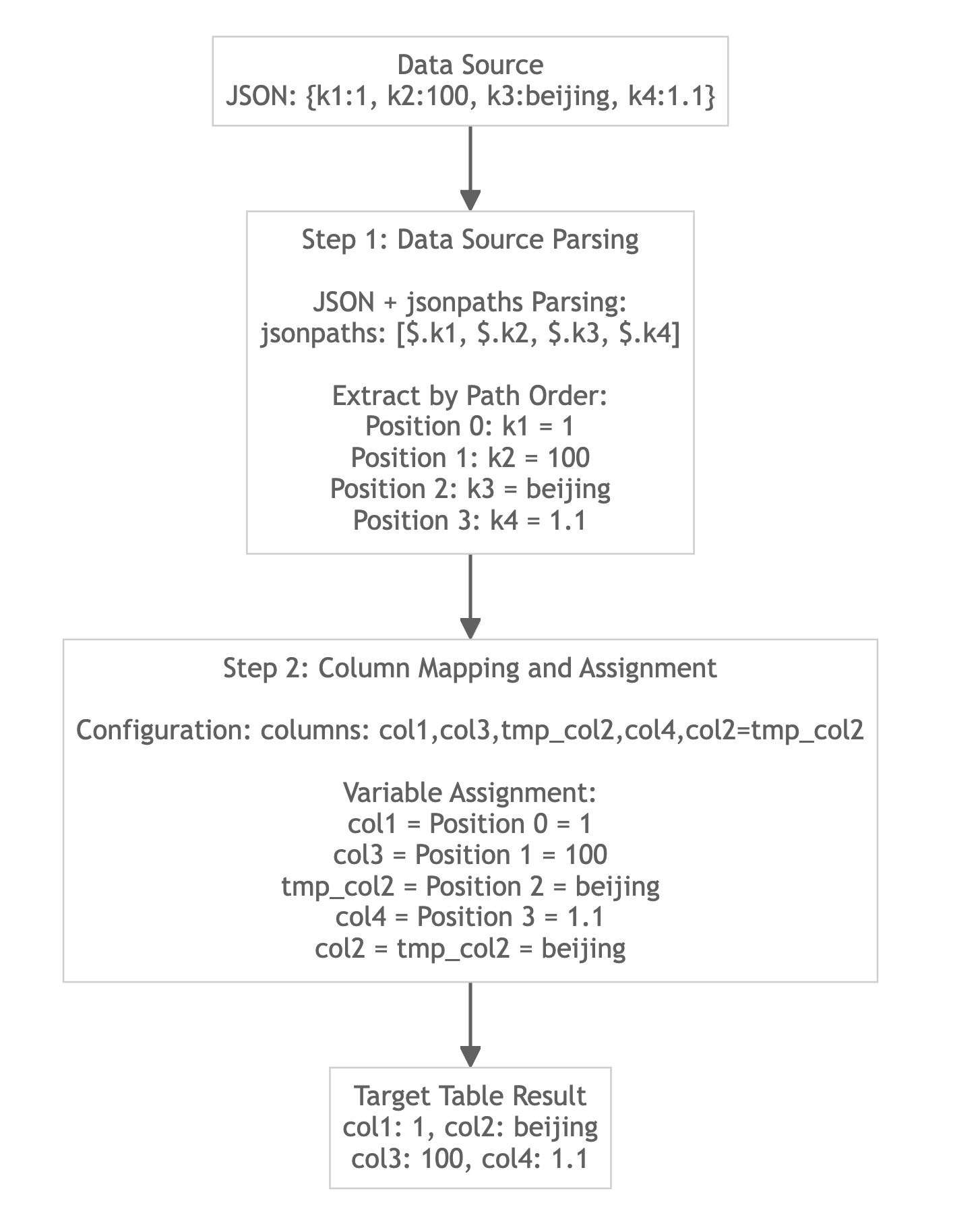
指定されたjsonpathsを使用したJSON形式データのロード
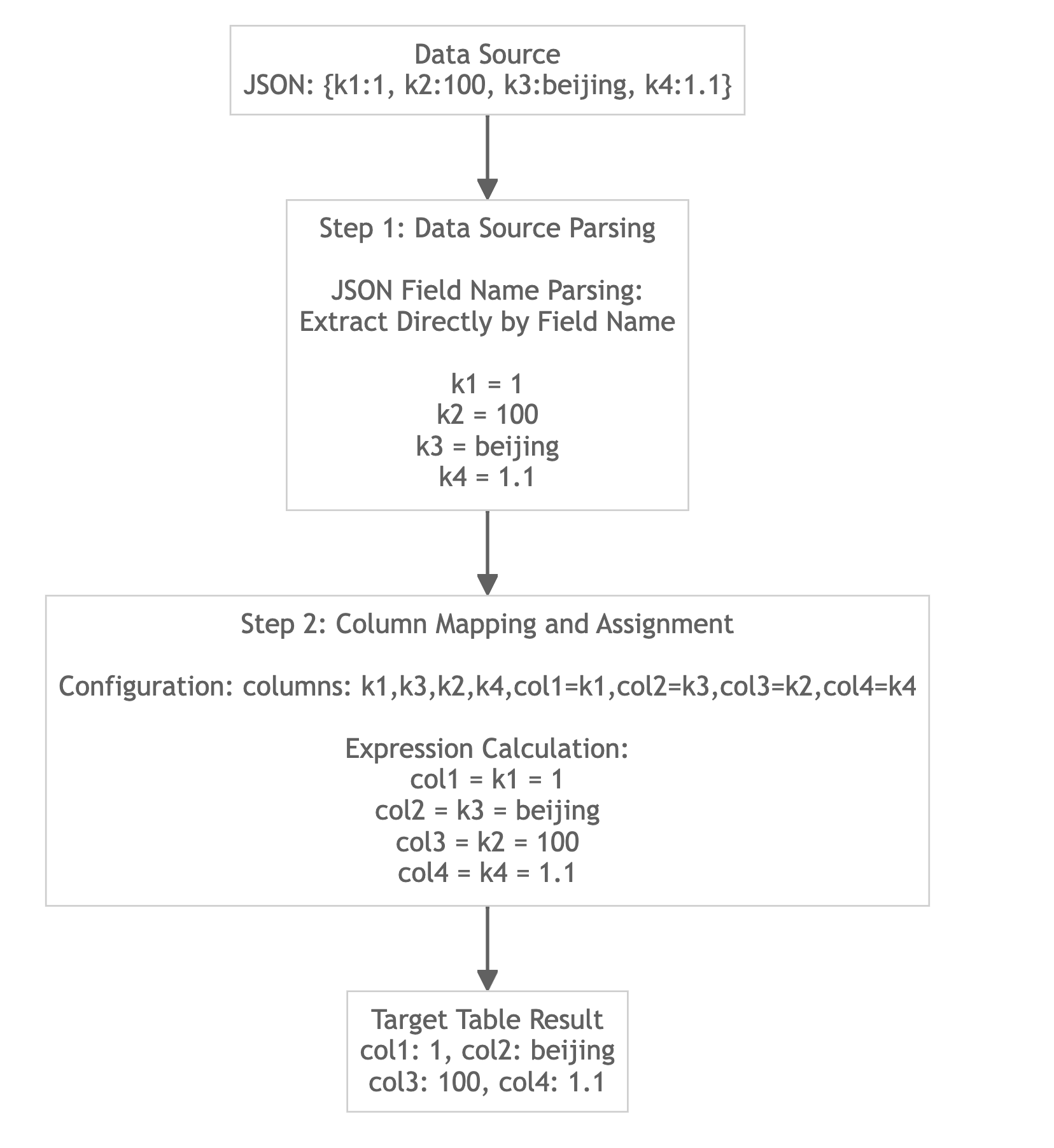
指定されたjsonpathsを使用しないJSON形式データのロード
指定されたjsonpathsを使用したJSONデータのロード
以下のソースデータを仮定します(列ヘッダーは説明のためのもので、実際のヘッダーは存在しません):
{"k1":1,"k2":"100","k3":"beijing","k4":1.1}
{"k1":2,"k2":"200","k3":"shanghai","k4":1.2}
{"k1":3,"k2":"300","k3":"guangzhou","k4":1.3}
{"k1":4,"k2":"\\N","k3":"chongqing","k4":1.4}
ターゲットTableを作成する
CREATE TABLE example_table
(
col1 INT,
col2 STRING,
col3 INT,
col4 DOUBLE
) ENGINE = OLAP
DUPLICATE KEY(col1)
DISTRIBUTED BY HASH(col1) BUCKETS 1;
データの読み込み
- Stream Load
curl --location-trusted -u user:passwd \
-H "columns:col1, col3, col2, col4" \
-H "jsonpaths:[\"$.k1\", \"$.k2\", \"$.k3\", \"$.k4\"]" \
-H "format:json" \
-H "read_json_by_line:true" \
-T data.json \
-X PUT \
http://<fe_ip>:<fe_http_port>/api/example_db/example_table/_stream_load
- Broker Load
LOAD LABEL example_db.label_broker
(
DATA INFILE("s3://bucket_name/data.json")
INTO TABLE example_table
FORMAT AS "json"
(col1, col3, col2, col4)
PROPERTIES
(
"jsonpaths" = "[\"$.k1\", \"$.k2\", \"$.k3\", \"$.k4\"]"
)
)
WITH s3 (...);
- Routine Load
CREATE ROUTINE LOAD example_db.example_routine_load ON example_table
COLUMNS(col1, col3, col2, col4)
PROPERTIES
(
"format" = "json",
"jsonpaths" = "[\"$.k1\", \"$.k2\", \"$.k3\", \"$.k4\"]",
"read_json_by_line" = "true"
)
FROM KAFKA (...);
クエリ結果
mysql> SELECT * FROM example_table;
+------+-----------+------+------+
| col1 | col2 | col3 | col4 |
+------+-----------+------+------+
| 1 | beijing | 100 | 1.1 |
| 2 | shanghai | 200 | 1.2 |
| 3 | guangzhou | 300 | 1.3 |
| 4 | chongqing | NULL | 1.4 |
+------+-----------+------+------+
指定されたjsonpathsなしでJSONデータを読み込む
以下のソースデータを想定します(列ヘッダーは説明のためのものであり、実際のヘッダーは存在しません):
{"k1":1,"k2":"100","k3":"beijing","k4":1.1}
{"k1":2,"k2":"200","k3":"shanghai","k4":1.2}
{"k1":3,"k2":"300","k3":"guangzhou","k4":1.3}
{"k1":4,"k2":"\\N","k3":"chongqing","k4":1.4}
ターゲットTableの作成
CREATE TABLE example_table
(
col1 INT,
col2 STRING,
col3 INT,
col4 DOUBLE
) ENGINE = OLAP
DUPLICATE KEY(col1)
DISTRIBUTED BY HASH(col1) BUCKETS 1;
データの読み込み
- Stream Load
curl --location-trusted -u user:passwd \
-H "columns:k1, k3, k2, k4,col1 = k1, col2 = k3, col3 = k2, col4 = k4" \
-H "format:json" \
-H "read_json_by_line:true" \
-T data.json \
-X PUT \
http://<fe_ip>:<fe_http_port>/api/example_db/example_table/_stream_load
- Brokerの負荷
LOAD LABEL example_db.label_broker
(
DATA INFILE("s3://bucket_name/data.json")
INTO TABLE example_table
FORMAT AS "json"
(k1, k3, k2, k4)
SET (
col1 = k1,
col2 = k3,
col3 = k2,
col4 = k4
)
)
WITH s3 (...);
- Routine Load
CREATE ROUTINE LOAD example_db.example_routine_load ON example_table
COLUMNS(k1, k3, k2, k4, col1 = k1, col2 = k3, col3 = k2, col4 = k4),
PROPERTIES
(
"format" = "json",
"read_json_by_line" = "true"
)
FROM KAFKA (...);
クエリ結果
mysql> SELECT * FROM example_table;
+------+-----------+------+------+
| col1 | col2 | col3 | col4 |
+------+-----------+------+------+
| 1 | beijing | 100 | 1.1 |
| 2 | shanghai | 200 | 1.2 |
| 3 | guangzhou | 300 | 1.3 |
| 4 | chongqing | NULL | 1.4 |
+------+-----------+------+------+
列の順序の調整
以下のソースデータがあるとします(列名は説明のためのものであり、実際のヘッダーは存在しません):
column1,column2,column3,column4
1,100,beijing,1.1
2,200,shanghai,1.2
3,300,guangzhou,1.3
4,\N,chongqing,1.4
ターゲットTableには4つのカラムがあります:k1、k2、k3、k4です。以下のようにカラムをマッピングしたいと思います:
column1 -> k1
column2 -> k3
column3 -> k2
column4 -> k4
ターゲットTableの作成
CREATE TABLE example_table
(
k1 INT,
k2 STRING,
k3 INT,
k4 DOUBLE
) ENGINE = OLAP
DUPLICATE KEY(k1)
DISTRIBUTED BY HASH(k1) BUCKETS 1;
データの読み込み
- Stream Load
curl --location-trusted -u user:passwd \
-H "column_separator:," \
-H "columns: k1,k3,k2,k4" \
-T data.csv \
-X PUT \
http://<fe_ip>:<fe_http_port>/api/example_db/example_table/_stream_load
- Broker負荷
LOAD LABEL example_db.label_broker
(
DATA INFILE("s3://bucket_name/data.csv")
INTO TABLE example_table
COLUMNS TERMINATED BY ","
(k1, k3, k2, k4)
)
WITH s3 (...);
- Routine Load
CREATE ROUTINE LOAD example_db.example_routine_load ON example_table
COLUMNS(k1, k3, k2, k4),
COLUMNS TERMINATED BY ","
FROM KAFKA (...);
クエリ結果
mysql> select * from example_table;
+------+-----------+------+------+
| k1 | k2 | k3 | k4 |
+------+-----------+------+------+
| 2 | shanghai | 200 | 1.2 |
| 4 | chongqing | NULL | 1.4 |
| 3 | guangzhou | 300 | 1.3 |
| 1 | beijing | 100 | 1.1 |
+------+-----------+------+------+
Source File Columns Exceed Table Columns
以下のソースデータがあるとします(列名は説明のためのものであり、実際のヘッダーは存在しません):
column1,column2,column3,column4
1,100,beijing,1.1
2,200,shanghai,1.2
3,300,guangzhou,1.3
4,\N,chongqing,1.4
対象のTableには3つの列があります:k1、k2、k3。ソースファイルから必要なのは1番目、2番目、4番目の列のみで、以下のマッピング関係になります:
column1 -> k1
column2 -> k2
column4 -> k3
ソースファイルの特定の列をスキップするには、列マッピング時にターゲットTableに存在しない任意の列名を使用できます。これらの列名はカスタマイズ可能で、制限はありません。これらの列のデータは、ロード中に自動的に無視されます。
ターゲットTableの作成
CREATE TABLE example_table
(
k1 INT,
k2 STRING,
k3 DOUBLE
) ENGINE = OLAP
DUPLICATE KEY(k1)
DISTRIBUTED BY HASH(k1) BUCKETS 1;
データの読み込み
- Stream Load
curl --location-trusted -u usr:passwd \
-H "column_separator:," \
-H "columns: k1,k2,tmp_skip,k3" \
-T data.csv \
http://<fe_ip>:<fe_http_port>/api/example_db/example_table/_stream_load
- Broker Load
LOAD LABEL example_db.label_broker
(
DATA INFILE("s3://bucket_name/data.csv")
INTO TABLE example_table
COLUMNS TERMINATED BY ","
(tmp_k1, tmp_k2, tmp_skip, tmp_k3)
SET (
k1 = tmp_k1,
k2 = tmp_k2,
k3 = tmp_k3
)
)
WITH s3 (...);
- Routine Load
CREATE ROUTINE LOAD example_db.example_routine_load ON example_table
COLUMNS(k1, k2, tmp_skip, k3),
PROPERTIES
(
"format" = "csv",
"column_separator" = ","
)
FROM KAFKA (...);
注意: 例の中の
tmp_skipは、対象Tableのカラム定義に含まれていない限り、任意の名前に置き換えることができます。
クエリ結果
mysql> select * from example_table;
+------+------+------+
| k1 | k2 | k3 |
+------+------+------+
| 1 | 100 | 1.1 |
| 2 | 200 | 1.2 |
| 3 | 300 | 1.3 |
| 4 | NULL | 1.4 |
+------+------+------+
Source File Columns Less Than Table Columns
ソースデータが以下のようになっているとします(カラム名は説明のみを目的としており、実際のヘッダーは存在しません):
column1,column2,column3,column4
1,100,beijing,1.1
2,200,shanghai,1.2
3,300,guangzhou,1.3
4,\N,chongqing,1.4
ターゲットTableには5つの列があります:k1、k2、k3、k4、k5。ソースファイルからは最初、2番目、3番目、4番目の列のみが必要で、以下のマッピング関係があります:
column1 -> k1
column2 -> k3
column3 -> k2
column4 -> k4
k5 uses the default value
ターゲットTableの作成
CREATE TABLE example_table
(
k1 INT,
k2 STRING,
k3 INT,
k4 DOUBLE,
k5 INT DEFAULT 2
) ENGINE = OLAP
DUPLICATE KEY(k1)
DISTRIBUTED BY HASH(k1) BUCKETS 1;
データの読み込み
- Stream Load
curl --location-trusted -u user:passwd \
-H "column_separator:," \
-H "columns: k1,k3,k2,k4" \
-T data.csv \
http://<fe_ip>:<fe_http_port>/api/example_db/example_table/_stream_load
- Broker負荷
LOAD LABEL example_db.label_broker
(
DATA INFILE("s3://bucket_name/data.csv")
INTO TABLE example_table
COLUMNS TERMINATED BY ","
(tmp_k1, tmp_k3, tmp_k2, tmp_k4)
SET (
k1 = tmp_k1,
k3 = tmp_k3,
k2 = tmp_k2,
k4 = tmp_k4
)
)
WITH s3 (...);
- Routine Load
CREATE ROUTINE LOAD example_db.example_routine_load ON example_table
COLUMNS(k1, k3, k2, k4),
COLUMNS TERMINATED BY ","
FROM KAFKA (...);
注意:
- k5にデフォルト値がある場合、デフォルト値で埋められます
- k5がnullable列でデフォルト値がない場合、NULLで埋められます
- k5がnon-nullable列でデフォルト値がない場合、読み込みは失敗します
Query Results
mysql> select * from example_table;
+------+-----------+------+------+------+
| k1 | k2 | k3 | k4 | k5 |
+------+-----------+------+------+------+
| 1 | beijing | 100 | 1.1 | 2 |
| 2 | shanghai | 200 | 1.2 | 2 |
| 3 | guangzhou | 300 | 1.3 | 2 |
| 4 | chongqing | NULL | 1.4 | 2 |
+------+-----------+------+------+------+
Column Transformation
Column transformationは、ユーザーがソースファイルの列値を変換することを可能にし、ほとんどのbuilt-in functionの使用をサポートします。Column transformationは通常、column mappingと一緒に定義されます。つまり、まず列をmapしてから変換します。
ロード前にソースファイルの列値を変換する
以下のソースデータがあるとします(列名は説明目的のみで、実際のheaderはありません):
column1,column2,column3,column4
1,100,beijing,1.1
2,200,shanghai,1.2
3,300,guangzhou,1.3
4,\N,chongqing,1.4
ターゲットTableには4つのカラムがあります:k1、k2、k3、k4。これらのカラムの値を以下のように変換したいと思います:
column1 -> k1
column2 * 100 -> k3
column3 -> k2
column4 -> k4
ターゲットTableの作成
CREATE TABLE example_table
(
k1 INT,
k2 STRING,
k3 INT,
k4 DOUBLE
)
ENGINE = OLAP
DUPLICATE KEY(k1)
DISTRIBUTED BY HASH(k1) BUCKETS 1;
データの読み込み
- Stream Load
curl --location-trusted -u user:passwd \
-H "column_separator:," \
-H "columns: k1, tmp_k3, k2, k4, k3 = tmp_k3 * 100" \
-T data.csv \
http://host:port/api/example_db/example_table/_stream_load
- Broker負荷
LOAD LABEL example_db.label1
(
DATA INFILE("s3://bucket_name/data.csv")
INTO TABLE example_table
COLUMNS TERMINATED BY ","
(k1, tmp_k3, k2, k4)
SET (
k3 = tmp_k3 * 100
)
)
WITH s3 (...);
- Routine Load
CREATE ROUTINE LOAD example_db.example_routine_load ON example_table
COLUMNS(k1, tmp_k3, k2, k4, k3 = tmp_k3 * 100),
COLUMNS TERMINATED BY ","
FROM KAFKA (...);
クエリ結果
mysql> select * from example_table;
+------+------+-------+------+
| k1 | k2 | k3 | k4 |
+------+------+-------+------+
| 1 | beijing | 10000 | 1.1 |
| 2 | shanghai | 20000 | 1.2 |
| 3 | guangzhou | 30000 | 1.3 |
| 4 | chongqing | NULL | 1.4 |
+------+------+-------+------+
条件付き列変換でのCase When関数の使用
次のソースデータがあると仮定します(列名は説明目的のみで、実際のヘッダーはありません):
column1,column2,column3,column4
1,100,beijing,1.1
2,200,shanghai,1.2
3,300,guangzhou,1.3
4,\N,chongqing,1.4
ターゲットTableは4つのカラムを持ちます:k1、k2、k3、k4。これらのカラムの値を以下のように変換します:
column1 -> k1
column2 -> k2
column3 -> k3 (transformed to area id)
column4 -> k4
ターゲットTableの作成
CREATE TABLE example_table
(
k1 INT,
k2 INT,
k3 INT,
k4 DOUBLE
)
ENGINE = OLAP
DUPLICATE KEY(k1)
DISTRIBUTED BY HASH(k1) BUCKETS 1;
データの読み込み
- Stream Load
curl --location-trusted -u user:passwd \
-H "column_separator:," \
-H "columns: k1, k2, tmp_k3, k4, k3 = CASE tmp_k3 WHEN 'beijing' THEN 1 WHEN 'shanghai' THEN 2 WHEN 'guangzhou' THEN 3 WHEN 'chongqing' THEN 4 ELSE NULL END" \
-T data.csv \
http://host:port/api/example_db/example_table/_stream_load
- Broker Load
LOAD LABEL example_db.label1
(
DATA INFILE("s3://bucket_name/data.csv")
INTO TABLE example_table
COLUMNS TERMINATED BY ","
(k1, k2, tmp_k3, k4)
SET (
k3 = CASE tmp_k3 WHEN 'beijing' THEN 1 WHEN 'shanghai' THEN 2 WHEN 'guangzhou' THEN 3 WHEN 'chongqing' THEN 4 ELSE NULL END
)
)
WITH s3 (...);
- Routine Load
CREATE ROUTINE LOAD example_db.example_routine_load ON example_table
COLUMNS(k1, k2, tmp_k3, k4, k3 = CASE tmp_k3 WHEN 'beijing' THEN 1 WHEN 'shanghai' THEN 2 WHEN 'guangzhou' THEN 3 WHEN 'chongqing' THEN 4 ELSE NULL END),
COLUMNS TERMINATED BY ","
FROM KAFKA (...);
クエリ結果
mysql> select * from example_table;
+------+------+------+------+
| k1 | k2 | k3 | k4 |
+------+------+------+------+
| 1 | 100 | 1 | 1.1 |
| 2 | 200 | 2 | 1.2 |
| 3 | 300 | 3 | 1.3 |
| 4 | NULL | 4 | 1.4 |
+------+------+------+------+
ソースファイルでのNULL値の処理
以下のソースデータがあるとします(列名は説明のためのものであり、実際のヘッダーは存在しません):
column1,column2,column3,column4
1,100,beijing,1.1
2,200,shanghai,1.2
3,300,guangzhou,1.3
4,\N,chongqing,1.4
ターゲットTableには4つの列があります:k1、k2、k3、k4。以下のように列の値を変換したいと思います:
column1 -> k1 (transform NULL to 0)
column2 -> k2
column3 -> k3
column4 -> k4
ターゲットTableの作成
CREATE TABLE example_table
(
k1 INT,
k2 INT,
k3 INT,
k4 DOUBLE
)
ENGINE = OLAP
DUPLICATE KEY(k1)
DISTRIBUTED BY HASH(k1) BUCKETS 1;
データの読み込み
- Stream Load
curl --location-trusted -u user:passwd \
-H "column_separator:," \
-H "columns: k1, tmp_k2, tmp_k3, k4, k2 = ifnull(tmp_k2, 0), k3 = CASE tmp_k3 WHEN 'beijing' THEN 1 WHEN 'shanghai' THEN 2 WHEN 'guangzhou' THEN 3 WHEN 'chongqing' THEN 4 ELSE NULL END" \
-T data.csv \
http://host:port/api/example_db/example_table/_stream_load
- Broker Load
LOAD LABEL example_db.label1
(
DATA INFILE("s3://bucket_name/data.csv")
INTO TABLE example_table
COLUMNS TERMINATED BY ","
(k1, tmp_k2, tmp_k3, k4)
SET (
k2 = ifnull(tmp_k2, 0),
k3 = CASE tmp_k3 WHEN 'beijing' THEN 1 WHEN 'shanghai' THEN 2 WHEN 'guangzhou' THEN 3 WHEN 'chongqing' THEN 4 ELSE NULL END
)
)
WITH s3 (...);
- Routine Load
CREATE ROUTINE LOAD example_db.example_routine_load ON example_table
COLUMNS(k1, tmp_k2, tmp_k3, k4, k2 = ifnull(tmp_k2, 0), k3 = CASE tmp_k3 WHEN 'beijing' THEN 1 WHEN 'shanghai' THEN 2 WHEN 'guangzhou' THEN 3 WHEN 'chongqing' THEN 4 ELSE NULL END),
COLUMNS TERMINATED BY ","
FROM KAFKA (...);
クエリ結果
mysql> select * from example_table;
+------+------+------+------+
| k1 | k2 | k3 | k4 |
+------+------+------+------+
| 1 | 100 | 1 | 1.1 |
| 2 | 200 | 2 | 1.2 |
| 3 | 300 | 3 | 1.3 |
| 4 | 0 | 4 | 1.4 |
+------+------+------+------+
Pre-filtering
Pre-filteringは、カラムマッピングと変換前に不要な生データをフィルタリングするプロセスです。この機能はBroker LoadとRoutine Loadでのみサポートされています。
Pre-filteringには以下の適用シナリオがあります:
- 変換前のフィルタリング
カラムマッピングと変換前にフィルタリングが必要なシナリオで、処理前に不要なデータの除去を可能にします。
- Tableに存在しないカラムのフィルタリング(フィルタリング指標としてのみ使用)
例えば、ソースデータに複数のTableのデータが含まれている場合(または複数のTableのデータが同一のKafkaメッセージキューに書き込まれている場合)。各データ行には、そのデータがどのTableに属するかを示すカラムがあります。ユーザーはpre-filtering条件を使用して、ロード用の対応するTableデータをフィルタリングできます。
Pre-filteringには以下の制限があります:
- カラムフィルタリングの制限
Pre-filteringはカラムリスト内の独立した単純なカラムのみをフィルタリングでき、式を含むカラムはフィルタリングできません。例:カラムマッピングが(a, tmp, b = tmp + 1)の場合、カラムbはフィルター条件として使用できません。
- データ処理の制限
Pre-filteringはデータ変換前に発生し、比較には生データ値を使用し、生データは文字列型として扱われます。例:\Nのようなデータの場合、NULLに変換してから比較するのではなく、\N文字列として直接比較されます。
例1:数値条件を使用したPre-filtering
この例では、単純な数値比較条件を使用してソースデータをフィルタリングする方法を示します。フィルター条件k1 > 1を設定することで、データ変換前に不要なレコードを除外できます。
以下のソースデータがあるとします(カラム名は説明目的のみで、実際のヘッダーは存在しません):
column1,column2,column3,column4
1,100,beijing,1.1
2,200,shanghai,1.2
3,300,guangzhou,1.3
4,\N,chongqing,1.4
プリフィルタリング条件:
column1 > 1, i.e., only load data where column1 > 1, and filter out other data.
ターゲットTableの作成
CREATE TABLE example_table
(
k1 INT,
k2 INT,
k3 STRING,
k4 DOUBLE
)
ENGINE = OLAP
DUPLICATE KEY(k1)
DISTRIBUTED BY HASH(k1) BUCKETS 1;
データの読み込み
- Broker Load
LOAD LABEL example_db.label1
(
DATA INFILE("s3://bucket_name/data.csv")
INTO TABLE example_table
COLUMNS TERMINATED BY ","
(k1, k2, k3, k4)
PRECEDING FILTER k1 > 1
)
WITH s3 (...);
- Routine Load
CREATE ROUTINE LOAD example_db.example_routine_load ON example_table
COLUMNS(k1, k2, k3, k4),
COLUMNS TERMINATED BY ","
PRECEDING FILTER k1 > 1
FROM KAFKA (...)
クエリ結果
mysql> select * from example_table;
+------+------+-----------+------+
| k1 | k2 | k3 | k4 |
+------+------+-----------+------+
| 2 | 200 | shanghai | 1.2 |
| 3 | 300 | guangzhou | 1.3 |
| 4 | NULL | chongqing | 1.4 |
+------+------+-----------+------+
例2: 中間列を使用した無効データのフィルタリング
この例では、無効なデータを含むデータインポートシナリオの処理方法を示します。
ソースデータ:
1,1
2,abc
3,3
Table作成
CREATE TABLE example_table
(
k1 INT,
k2 INT NOT NULL
)
ENGINE = OLAP
DUPLICATE KEY(k1)
DISTRIBUTED BY HASH(k1) BUCKETS 1;
カラムk2はINT型ですが、abcは無効な不正データです。このデータをフィルタリングするために、フィルタリング用の中間カラムを導入することができます。
Load Statements
- Broker Load
LOAD LABEL example_db.label1
(
DATA INFILE("s3://bucket_name/data.csv")
INTO TABLE example_table
COLUMNS TERMINATED BY ","
(k1, tmp, k2 = tmp)
PRECEDING FILTER tmp != "abc"
)
WITH s3 (...);
- Routine Load
CREATE ROUTINE LOAD example_db.example_routine_load ON example_table
COLUMNS(k1, tmp, k2 = tmp),
COLUMNS TERMINATED BY ","
PRECEDING FILTER tmp != "abc"
FROM KAFKA (...);
読み込み結果
mysql> select * from example_table;
+------+----+
| k1 | k2 |
+------+----+
| 1 | 1 |
| 3 | 3 |
+------+----+
Post-filtering
Post-filteringは、カラムマッピングと変換後の最終結果をフィルタリングするプロセスです。
Column MappingとTransformationを使用しないフィルタリング
以下のソースデータがあると仮定します(カラム名は説明目的のみで、実際のヘッダーは存在しません):
column1,column2,column3,column4
1,100,beijing,1.1
2,200,shanghai,1.2
3,300,guangzhou,1.3
4,\N,chongqing,1.4
ターゲットTableには4つの列があります:k1、k2、k3、およびk4。4番目の列が1.2より大きいデータのみをロードしたいと思います。
ターゲットTableの作成
CREATE TABLE example_table
(
k1 INT,
k2 INT,
k3 STRING,
k4 DOUBLE
)
ENGINE = OLAP
DUPLICATE KEY(k1)
DISTRIBUTED BY HASH(k1) BUCKETS 1;
データの読み込み
- Stream Load
curl --location-trusted -u user:passwd \
-H "column_separator:," \
-H "columns: k1, k2, k3, k4" \
-H "where: k4 > 1.2" \
-T data.csv \
http://host:port/api/example_db/example_table/_stream_load
- Broker負荷
LOAD LABEL example_db.label1
(
DATA INFILE("s3://bucket_name/data.csv")
INTO TABLE example_table
COLUMNS TERMINATED BY ","
(k1, k2, k3, k4)
where k4 > 1.2
)
WITH s3 (...);
- Routine Load
CREATE ROUTINE LOAD example_db.example_routine_load ON example_table
COLUMNS(k1, k2, k3, k4),
COLUMNS TERMINATED BY ","
WHERE k4 > 1.2;
FROM KAFKA (...)
クエリ結果
mysql> select * from example_table;
+------+------+-----------+------+
| k1 | k2 | k3 | k4 |
+------+------+-----------+------+
| 3 | 300 | guangzhou | 1.3 |
| 4 | NULL | chongqing | 1.4 |
+------+------+-----------+------+
フィルタリング変換されたデータ
以下のソースデータがあるとします(列名は説明目的のみであり、実際のヘッダーは存在しません):
column1,column2,column3,column4
1,100,beijing,1.1
2,200,shanghai,1.2
3,300,guangzhou,1.3
4,\N,chongqing,1.4
ターゲットTableには4つのカラムがあります:k1、k2、k3、k4。以下のようにカラム値を変換したいと考えています:
column1 -> k1
column2 -> k2
column3 -> k3 (transformed to area id)
column4 -> k4
変換された k3 値が 3 であるデータを除外したいと思います。
ターゲットTableの作成
CREATE TABLE example_table
(
k1 INT,
k2 INT,
k3 INT,
k4 DOUBLE
)
ENGINE = OLAP
DUPLICATE KEY(k1)
DISTRIBUTED BY HASH(k1) BUCKETS 1;
データ読み込み
- Stream Load
curl --location-trusted -u user:passwd \
-H "column_separator:," \
-H "columns: k1, k2, tmp_k3, k4, k3 = case tmp_k3 when 'beijing' then 1 when 'shanghai' then 2 when 'guangzhou' then 3 when 'chongqing' then 4 else null end" \
-H "where: k3 != 3" \
-T data.csv \
http://host:port/api/example_db/example_table/_stream_load
- Broker負荷
LOAD LABEL example_db.label1
(
DATA INFILE("s3://bucket_name/data.csv")
INTO TABLE example_table
COLUMNS TERMINATED BY ","
(k1, k2, tmp_k3, k4)
SET (
k3 = CASE tmp_k3 WHEN 'beijing' THEN 1 WHEN 'shanghai' THEN 2 WHEN 'guangzhou' THEN 3 WHEN 'chongqing' THEN 4 ELSE NULL END
)
WHERE k3 != 3
)
WITH s3 (...);
- Routine Load
CREATE ROUTINE LOAD example_db.example_routine_load ON example_table
COLUMNS(k1, k2, tmp_k3, k4),
COLUMNS TERMINATED BY ","
SET (
k3 = CASE tmp_k3 WHEN 'beijing' THEN 1 WHEN 'shanghai' THEN 2 WHEN 'guangzhou' THEN 3 WHEN 'chongqing' THEN 4 ELSE NULL END
)
WHERE k3 != 3;
FROM KAFKA (...)
クエリ結果
mysql> select * from example_table;
+------+------+------+------+
| k1 | k2 | k3 | k4 |
+------+------+------+------+
| 1 | 100 | 1 | 1.1 |
| 2 | 200 | 2 | 1.2 |
| 4 | NULL | 4 | 1.4 |
+------+------+------+------+
複数条件によるフィルタリング
以下のようなソースデータがあるとします(列名は説明のためのものであり、実際のヘッダーは存在しません):
column1,column2,column3,column4
1,100,beijing,1.1
2,200,shanghai,1.2
3,300,guangzhou,1.3
4,\N,chongqing,1.4
ターゲットTableには4つの列があります:k1、k2、k3、k4。k1がNULLで、k4が1.2未満のデータをフィルタリングしたいと思います。
ターゲットTableの作成
CREATE TABLE example_table
(
k1 INT,
k2 INT,
k3 STRING,
k4 DOUBLE
)
ENGINE = OLAP
DUPLICATE KEY(k1)
DISTRIBUTED BY HASH(k1) BUCKETS 1;
データの読み込み
- Stream Load
curl --location-trusted -u user:passwd \
-H "column_separator:," \
-H "columns: k1, k2, k3, k4" \
-H "where: k1 is not null and k4 > 1.2" \
-T data.csv \
http://host:port/api/example_db/example_table/_stream_load
- Broker Load
LOAD LABEL example_db.label1
(
DATA INFILE("s3://bucket_name/data.csv")
INTO TABLE example_table
COLUMNS TERMINATED BY ","
(k1, k2, k3, k4)
where k1 is not null and k4 > 1.2
)
WITH s3 (...);
- Routine Load
CREATE ROUTINE LOAD example_db.example_routine_load ON example_table
COLUMNS(k1, k2, k3, k4),
COLUMNS TERMINATED BY ","
WHERE k1 is not null and k4 > 1.2
FROM KAFKA (...);
クエリ結果
mysql> select * from example_table;
+------+------+-----------+------+
| k1 | k2 | k3 | k4 |
+------+------+-----------+------+
| 3 | 300 | guangzhou | 1.3 |
| 4 | NULL | chongqing | 1.4 |
+------+------+-----------+------+