結合
JOINとは
リレーショナルデータベースでは、データは複数のTableに分散され、特定の関係を通じて相互接続されています。SQL JOIN操作により、ユーザーはこれらの関係に基づいて異なるTableをより完全な結果セットに結合することができます。
DorisでサポートされているJOINタイプ
-
INNER JOIN: JOIN条件に基づいて左Tableの各行を右Tableのすべての行と比較し、両Tableから一致する行を返します。詳細については、SELECTでのJOINクエリの構文定義を参照してください。
-
LEFT JOIN: INNER JOINの結果セットに基づき、左Tableの行が右Tableに一致するものがない場合、左Tableのすべての行が返され、右Tableの対応する列はNULLとして表示されます。
-
RIGHT JOIN: LEFT JOINの反対です。右Tableの行が左Tableに一致するものがない場合、右Tableのすべての行が返され、左Tableの対応する列はNULLとして表示されます。
-
FULL JOIN: INNER JOINの結果セットに基づき、両Tableのすべての行を返し、一致しない箇所にはNULLを補填します。
-
CROSS JOIN: JOIN条件がなく、2つのTableのデカルト積を返します。左Tableの各行が右Tableの各行と結合されます。
-
LEFT SEMI JOIN: JOIN条件に基づいて左Tableの各行を右Tableのすべての行と比較します。一致が存在する場合、左Tableから対応する行が返されます。
-
RIGHT SEMI JOIN: LEFT SEMI JOINの反対です。右Tableの各行を左Tableのすべての行と比較し、一致が存在する場合は右Tableから対応する行を返します。
-
LEFT ANTI JOIN: JOIN条件に基づいて左Tableの各行を右Tableのすべての行と比較します。一致しない場合、左Tableから対応する行が返されます。
-
RIGHT ANTI JOIN: LEFT ANTI JOINの反対です。右Tableの各行を左Tableのすべての行と比較し、一致しない右Tableの行を返します。
-
NULL AWARE LEFT ANTI JOIN: LEFT ANTI JOINと似ていますが、一致する列がNULLである左Tableの行を無視します。
DorisでのJOINの実装
DorisはHash JoinとNested Loop Joinという2つのJOIN実装方法をサポートしています。
- Hash Join: 等価JOIN列に基づいて右TableにハッシュTableを構築し、左TableのデータをこのハッシュTableにストリーミングしてJOIN計算を行います。この方法は等価JOIN条件が適用可能な場合に限定されます。
- Nested Loop Join: この方法は2つのネストしたループを使用し、左Tableを駆動として、左Tableの各行を反復処理し、JOIN条件に基づいて右Tableのすべての行と比較します。Hash Joinが処理できないGREATER THANやLESS THAN比較を含むクエリ、またはデカルト積を必要とする場合など、すべてのJOINシナリオに適用可能です。ただし、Hash Joinと比較して、Nested Loop Joinのパフォーマンスは劣る場合があります。
DorisでのHash Joinの実装
分散MPPデータベースとして、Apache DorisはJOIN結果の正確性を確保するため、Hash Joinプロセス中にデータシャッフリングが必要です。以下に複数のデータシャッフリング方法を示します。
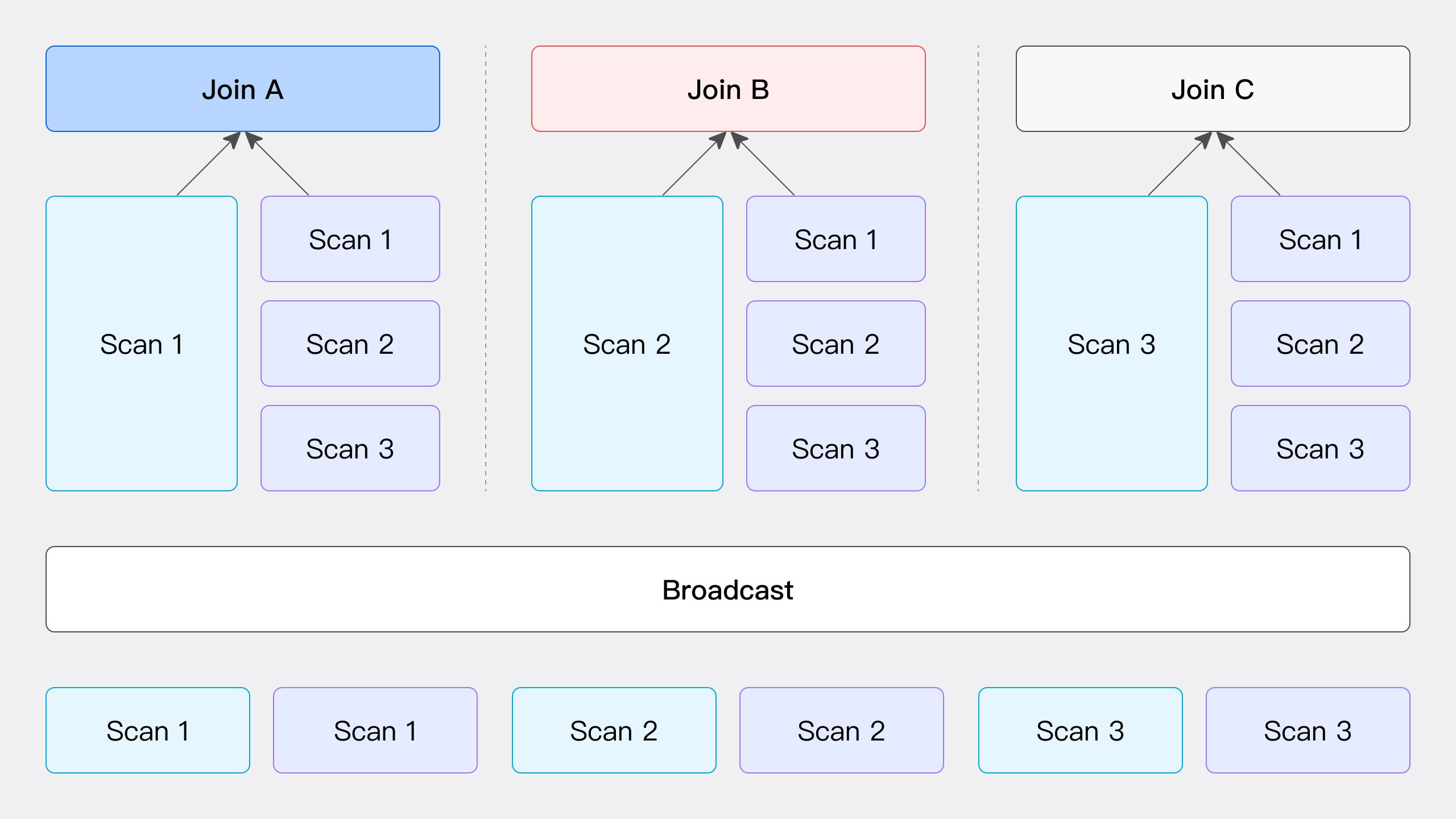
Broadcast Join 図に示すように、Broadcast Joinプロセスでは、右Tableのすべてのデータを、左Tableのデータをスキャンするノードを含む、JOIN計算に参加するすべてのノードに送信する一方で、左Tableのデータは静止したままです。このプロセスでは、各ノードが右Tableのデータの完全なコピー(総量T(R))を受信し、すべてのノードがJOIN操作を実行するために必要なデータを確実に持てるようにします。
この方法は様々なシナリオに適していますが、RIGHT OUTER、RIGHT ANTI、RIGHT SEMIタイプのHash Joinには適用できません。ネットワークオーバーヘッドは、JOINノード数Nに右Tableのデータ量T(R)を乗じて計算されます。
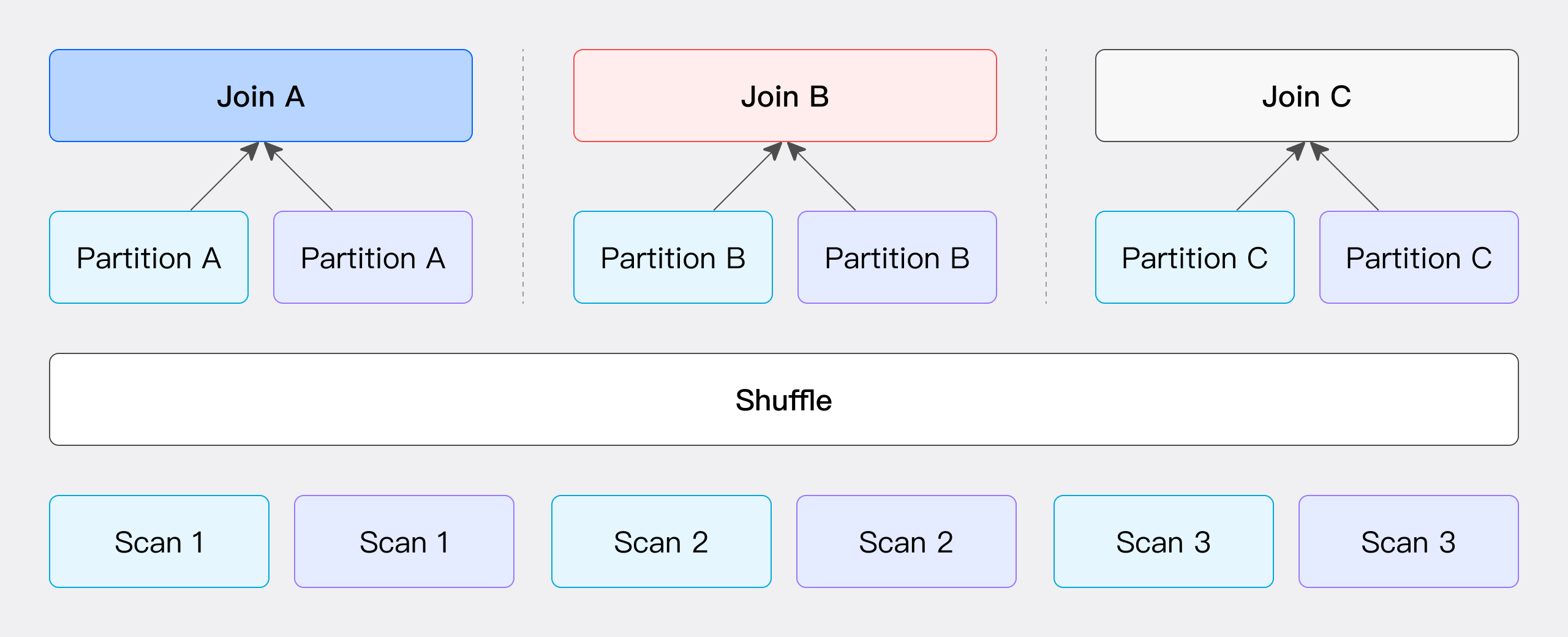
パーティション Shuffle Join
この方法は、JOIN条件に基づいてハッシュ値を計算し、バケッティングを実行します。具体的には、左Tableと右Tableの両方のデータが、JOIN条件から計算されたハッシュ値に従ってパーティション分割され、これらのパーティション分割されたデータセットが対応するパーティションノードに送信されます(図に示すように)。
この方法のネットワークオーバーヘッドは主に2つの部分から構成されます。左Tableのデータ転送コストT(S)と右Tableのデータ転送コストT(R)です。この方法は、データバケッティングを実行するためにJOIN条件に依存するため、Hash JOIN操作のみをサポートします。
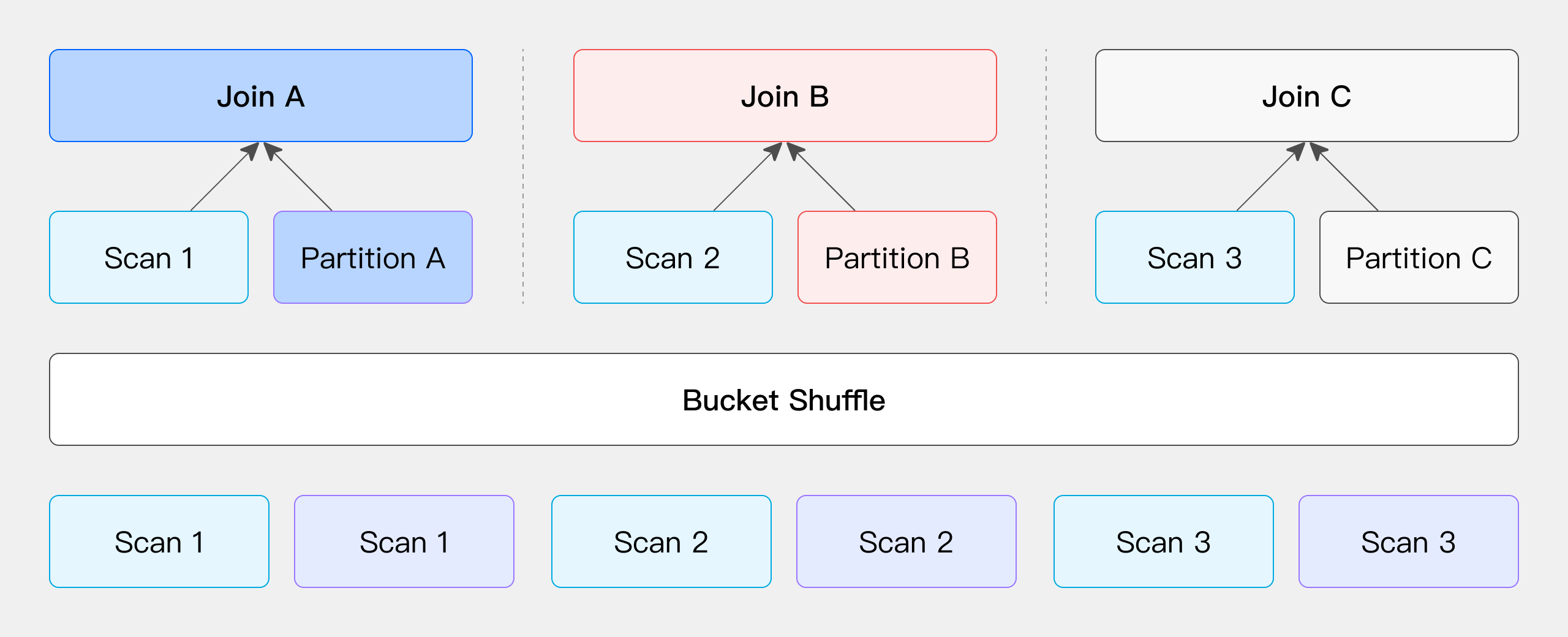
バケット Shuffle Join
JOIN条件に左Tableのバケット列が含まれる場合、左Tableのデータ位置は変更されず、右Tableのデータが左Tableのノードに配布されてJOINが実行され、ネットワークオーバーヘッドが削減されます。
JOIN操作に関わるTableの一方が、JOIN条件列に従ってすでにハッシュ分散されている場合、ユーザーはこの側のデータ位置を変更せず、同じJOIN条件列とハッシュ分散に基づいて他方のデータを分散させることを選択できます。(ここでの「Table」は物理的に格納されたTableだけでなく、SQLクエリ内の任意の演算子の出力結果も指します。ユーザーは柔軟に左Tableまたは右Tableのデータ位置を変更せず、他方のTableのみを移動・分散させることを選択できます。)
例えば、Dorisの物理Tableの場合、Tableデータはハッシュ計算によってバケット方式で格納されているため、ユーザーはこの機能を直接活用してJOIN操作のデータシャッフルプロセスを最適化できます。JOINが必要な2つのTableがあり、JOIN列が左Tableのバケット列である場合を想定します。この場合、左Tableのデータを移動する必要はなく、左Tableのバケット情報に基づいて右Tableのデータを適切な場所に分散させるだけでJOIN計算が完了します。
このプロセスの主要なネットワークオーバーヘッドは、右Tableのデータの移動から生じ、T(R)として表されます。
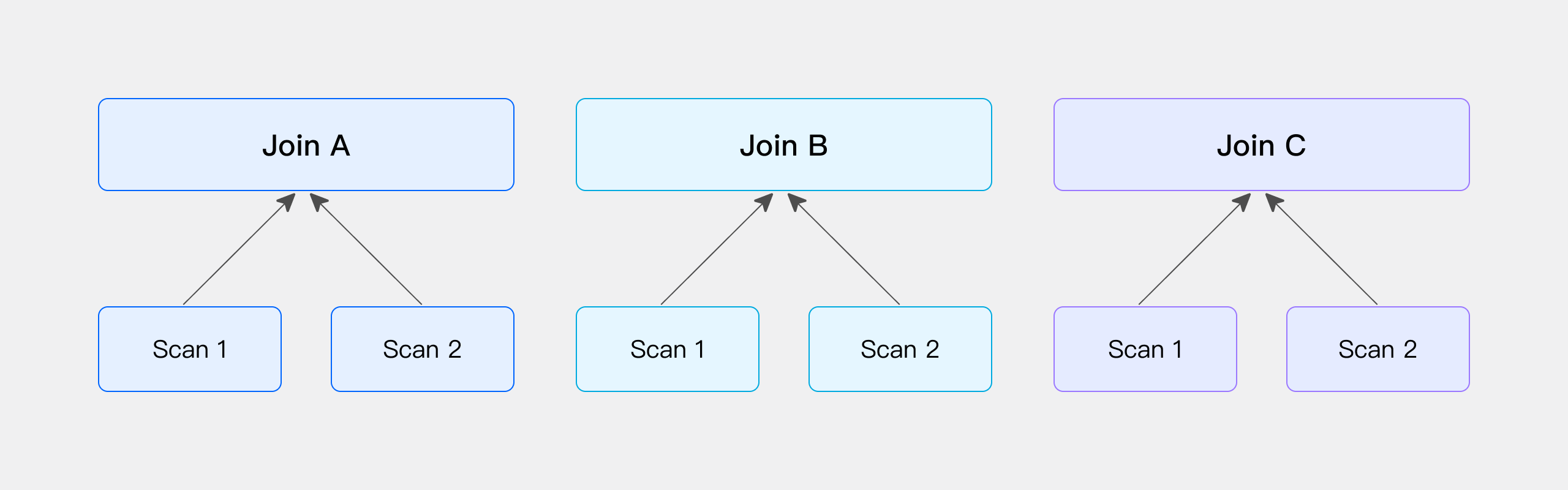
Colocate Join
バケット Shuffle Joinと同様に、Joinに関わる両方のTableがJoin条件列に従ってすでにHashで分散されている場合、Shuffleプロセスをスキップして、ローカルデータで直接Join計算を実行できます。これは物理Tableで説明できます。
DorisでDISTRIBUTED BY HASHの指定でTableを作成する場合、システムはデータインポート時にHash分散キーに基づいてデータを分散させます。両方のTableのHash分散キーがJoin条件列と一致する場合、これらの2つのTableのデータはJoin要件に従ってすでに事前分散されていると言え、追加のShuffle操作が不要になります。そのため、実際のクエリ時には、これらの2つのTableでJoin計算を直接実行できます。
データを直接スキャンした後にJoinが実行されるシナリオでは、Table作成時に特定の条件を満たす必要があります。2つの物理Table間のColocate Joinに関する後続の制限を参照してください。
バケット Shuffle Join VS Colocate Join
前述のとおり、バケット Shuffle JoinとColocate Joinの両方において、参加Tableの分散が特定の条件を満たす限り、join操作を実行できます(ここでの「Table」は、SQLクエリ演算子からの任意の出力を指します)。
次に、2つのTablet1とt2、および関連するSQLサンプルを使用して、一般化されたBucket Shuffle JoinとColocate Joinについてより詳しく説明します。まず、両TableのTable作成ステートメントは以下のとおりです。
create table t1
(
c1 bigint,
c2 bigint
)
DISTRIBUTED BY HASH(c1) BUCKETS 3
PROPERTIES ("replication_num" = "1");
create table t2
(
c1 bigint,
c2 bigint
)
DISTRIBUTED BY HASH(c1) BUCKETS 3
PROPERTIES ("replication_num" = "1");
バケット Shuffle Joinの例
以下の例では、Tablet1とt2の両方がGROUP BY演算子によって処理され、新しいTableが生成されています(この時点で、txTableはc1によってハッシュ分散され、tyTableはc2によってハッシュ分散されています)。後続のJOIN条件はtx.c1 = ty.c2であり、これはBucket Shuffle Joinの条件を完全に満たしています。
explain select *
from
(
-- The t1 table is hash-distributed by c1, and after the GROUP BY operator, it still maintains the hash distribution by c1.
select c1 as c1, sum(c2) as c2
from t1
group by c1
) tx
join
(
-- The t2 table is hash-distributed by c1, but after the GROUP BY operator, the data is redistributed to be hash-distributed by c2.
select c2 as c2, sum(c1) as c1
from t2
group by c2
) ty
on tx.c1 = ty.c2;
以下のExplain execution planから、Hash Joinノード7の左子ノードが集約ノード6であり、右子ノードがExchangeノード4であることが確認できます。これは、左子ノードのデータが集約後も同じ場所に留まる一方で、右子ノードのデータは後続のHash Join操作を実行するためにBucket Shuffle方式を使用して左子ノードが存在するノードに分散されることを示しています。
+------------------------------------------------------------+
| Explain String(Nereids Planner) |
+------------------------------------------------------------+
| PLAN FRAGMENT 0 |
| OUTPUT EXPRS: |
| c1[#18] |
| c2[#19] |
| c2[#20] |
| c1[#21] |
| PARTITION: HASH_PARTITIONED: c1[#8] |
| |
| HAS_COLO_PLAN_NODE: true |
| |
| VRESULT SINK |
| MYSQL_PROTOCAL |
| |
| 7:VHASH JOIN(364) |
| | join op: INNER JOIN(BUCKET_SHUFFLE)[] |
| | equal join conjunct: (c1[#12] = c2[#6]) |
| | cardinality=10 |
| | vec output tuple id: 8 |
| | output tuple id: 8 |
| | vIntermediate tuple ids: 7 |
| | hash output slot ids: 6 7 12 13 |
| | final projections: c1[#14], c2[#15], c2[#16], c1[#17] |
| | final project output tuple id: 8 |
| | distribute expr lists: c1[#12] |
| | distribute expr lists: c2[#6] |
| | |
| |----4:VEXCHANGE |
| | offset: 0 |
| | distribute expr lists: c2[#6] |
| | |
| 6:VAGGREGATE (update finalize)(342) |
| | output: sum(c2[#9])[#11] |
| | group by: c1[#8] |
| | sortByGroupKey:false |
| | cardinality=10 |
| | final projections: c1[#10], c2[#11] |
| | final project output tuple id: 6 |
| | distribute expr lists: c1[#8] |
| | |
| 5:VOlapScanNode(339) |
| TABLE: tt.t1(t1), PREAGGREGATION: ON |
| partitions=1/1 (t1) |
| tablets=1/1, tabletList=491188 |
| cardinality=21, avgRowSize=0.0, numNodes=1 |
| pushAggOp=NONE |
| |
| PLAN FRAGMENT 1 |
| |
| PARTITION: HASH_PARTITIONED: c2[#2] |
| |
| HAS_COLO_PLAN_NODE: true |
| |
| STREAM DATA SINK |
| EXCHANGE ID: 04 |
| BUCKET_SHFFULE_HASH_PARTITIONED: c2[#6] |
| |
| 3:VAGGREGATE (merge finalize)(355) |
| | output: sum(partial_sum(c1)[#3])[#5] |
| | group by: c2[#2] |
| | sortByGroupKey:false |
| | cardinality=5 |
| | final projections: c2[#4], c1[#5] |
| | final project output tuple id: 3 |
| | distribute expr lists: c2[#2] |
| | |
| 2:VEXCHANGE |
| offset: 0 |
| distribute expr lists: |
| |
| PLAN FRAGMENT 2 |
| |
| PARTITION: HASH_PARTITIONED: c1[#0] |
| |
| HAS_COLO_PLAN_NODE: false |
| |
| STREAM DATA SINK |
| EXCHANGE ID: 02 |
| HASH_PARTITIONED: c2[#2] |
| |
| 1:VAGGREGATE (update serialize)(349) |
| | STREAMING |
| | output: partial_sum(c1[#0])[#3] |
| | group by: c2[#1] |
| | sortByGroupKey:false |
| | cardinality=5 |
| | distribute expr lists: c1[#0] |
| | |
| 0:VOlapScanNode(346) |
| TABLE: tt.t2(t2), PREAGGREGATION: ON |
| partitions=1/1 (t2) |
| tablets=1/1, tabletList=491198 |
| cardinality=10, avgRowSize=0.0, numNodes=1 |
| pushAggOp=NONE |
| |
| |
| Statistics |
| planed with unknown column statistics |
+------------------------------------------------------------+
97 rows in set (0.01 sec)
Colocate Joinの例
以下の例では、Tablet1とt2の両方がGROUP BY演算子によって処理され、新しいTableが生成されています(この時点で、txとtyはどちらもc2によってハッシュ分散されています)。その後のJOIN条件はtx.c2 = ty.c2であり、これはColocate Joinの条件を完全に満たしています。
explain select *
from
(
-- The t1 table is initially hash-distributed by c1, but after the GROUP BY operator, the data distribution changes to be hash-distributed by c2.
select c2 as c2, sum(c1) as c1
from t1
group by c2
) tx
join
(
-- The t2 table is initially hash-distributed by c1, but after the GROUP BY operator, the data distribution changes to be hash-distributed by c2.
select c2 as c2, sum(c1) as c1
from t2
group by c2
) ty
on tx.c2 = ty.c2;
以下のExplain実行計画の結果から、Hash Joinノード8の左の子ノードが集約ノード7であり、右の子ノードが集約ノード3であることがわかり、Exchangeノードは存在していません。これは、左右の子ノードからの集約データが元の場所に残っていることを示しており、データ移動の必要性を排除し、後続のHash Join操作を直接ローカルで実行できることを意味します。
+------------------------------------------------------------+
| Explain String(Nereids Planner) |
+------------------------------------------------------------+
| PLAN FRAGMENT 0 |
| OUTPUT EXPRS: |
| c2[#20] |
| c1[#21] |
| c2[#22] |
| c1[#23] |
| PARTITION: HASH_PARTITIONED: c2[#10] |
| |
| HAS_COLO_PLAN_NODE: true |
| |
| VRESULT SINK |
| MYSQL_PROTOCAL |
| |
| 8:VHASH JOIN(373) |
| | join op: INNER JOIN(PARTITIONED)[] |
| | equal join conjunct: (c2[#14] = c2[#6]) |
| | cardinality=10 |
| | vec output tuple id: 9 |
| | output tuple id: 9 |
| | vIntermediate tuple ids: 8 |
| | hash output slot ids: 6 7 14 15 |
| | final projections: c2[#16], c1[#17], c2[#18], c1[#19] |
| | final project output tuple id: 9 |
| | distribute expr lists: c2[#14] |
| | distribute expr lists: c2[#6] |
| | |
| |----3:VAGGREGATE (merge finalize)(367) |
| | | output: sum(partial_sum(c1)[#3])[#5] |
| | | group by: c2[#2] |
| | | sortByGroupKey:false |
| | | cardinality=5 |
| | | final projections: c2[#4], c1[#5] |
| | | final project output tuple id: 3 |
| | | distribute expr lists: c2[#2] |
| | | |
| | 2:VEXCHANGE |
| | offset: 0 |
| | distribute expr lists: |
| | |
| 7:VAGGREGATE (merge finalize)(354) |
| | output: sum(partial_sum(c1)[#11])[#13] |
| | group by: c2[#10] |
| | sortByGroupKey:false |
| | cardinality=10 |
| | final projections: c2[#12], c1[#13] |
| | final project output tuple id: 7 |
| | distribute expr lists: c2[#10] |
| | |
| 6:VEXCHANGE |
| offset: 0 |
| distribute expr lists: |
| |
| PLAN FRAGMENT 1 |
| |
| PARTITION: HASH_PARTITIONED: c1[#8] |
| |
| HAS_COLO_PLAN_NODE: false |
| |
| STREAM DATA SINK |
| EXCHANGE ID: 06 |
| HASH_PARTITIONED: c2[#10] |
| |
| 5:VAGGREGATE (update serialize)(348) |
| | STREAMING |
| | output: partial_sum(c1[#8])[#11] |
| | group by: c2[#9] |
| | sortByGroupKey:false |
| | cardinality=10 |
| | distribute expr lists: c1[#8] |
| | |
| 4:VOlapScanNode(345) |
| TABLE: tt.t1(t1), PREAGGREGATION: ON |
| partitions=1/1 (t1) |
| tablets=1/1, tabletList=491188 |
| cardinality=21, avgRowSize=0.0, numNodes=1 |
| pushAggOp=NONE |
| |
| PLAN FRAGMENT 2 |
| |
| PARTITION: HASH_PARTITIONED: c1[#0] |
| |
| HAS_COLO_PLAN_NODE: false |
| |
| STREAM DATA SINK |
| EXCHANGE ID: 02 |
| HASH_PARTITIONED: c2[#2] |
| |
| 1:VAGGREGATE (update serialize)(361) |
| | STREAMING |
| | output: partial_sum(c1[#0])[#3] |
| | group by: c2[#1] |
| | sortByGroupKey:false |
| | cardinality=5 |
| | distribute expr lists: c1[#0] |
| | |
| 0:VOlapScanNode(358) |
| TABLE: tt.t2(t2), PREAGGREGATION: ON |
| partitions=1/1 (t2) |
| tablets=1/1, tabletList=491198 |
| cardinality=10, avgRowSize=0.0, numNodes=1 |
| pushAggOp=NONE |
| |
| |
| Statistics |
| planed with unknown column statistics |
+------------------------------------------------------------+
105 rows in set (0.06 sec)
4つのshuffleメソッドの比較
| Shuffle Methods | Network Overhead | Physical Operator | Applicable Scenarios |
|---|---|---|---|
| Broadcast | N * T(R) | Hash Join /Nest Loop Join | General |
| Shuffle | T(S) + T(R) | Hash Join | General |
| バケット Shuffle | T(R) | Hash Join | JOIN条件が左Tableのbucketed columnを含み、左Tableが単一パーティションである場合。 |
| Colocate | 0 | Hash Join | JOIN条件が左Tableのbucketed columnを含み、両方のTableが同じColocate Groupに属している場合。 |
N: Join計算に参加するインスタンス数
T(Relation): リレーション内のタプル数
4つのShuffleメソッドの柔軟性は順次低下し、データ分散に対する要件はますます厳しくなります。多くの場合、データ分散への要件が高くなるにつれて、Join計算のパフォーマンスは徐々に向上する傾向があります。注意すべき点は、Tableのバケット数が少ない場合、バケット ShuffleやColocate Joinは並列性の低下によりパフォーマンスが低下し、Shuffle Joinよりも遅くなる可能性があることです。これは、Shuffle操作がデータ分散をより効果的にバランス化し、それによって後続の処理でより高い並列性を提供できるためです。
FAQ
バケット Shuffle JoinとColocate Joinは、適用時にデータ分散とJOIN条件に関して特定の制限があります。以下では、これらのJOINメソッドそれぞれの具体的な制限について詳しく説明します。
バケット Shuffle Joinの制限
2つの物理Tableを直接スキャンしてBucket Shuffle Joinを実行する場合、以下の条件を満たす必要があります:
-
等価Join条件: バケット Shuffle Joinは、JOIN条件が等価性に基づくシナリオにのみ適用できます。これは、データ分散を決定するためにハッシュ計算に依存するためです。
-
等価条件にbucketed columnsを含む: 等価JOIN条件は、両方のTableのbucketed columnsを含む必要があります。左Tableのbucketed columnが等価JOIN条件として使用される場合、バケット Shuffle Joinとして計画される可能性が高くなります。
-
Tableタイプの制限: バケット Shuffle JoinはDorisのネイティブOLAPTableにのみ適用できます。ODBC、MySQL、ESなどの外部Tableの場合、それらが左Tableとして使用される際、バケット Shuffle Joinは効果的に機能しません。
-
単一パーティション要件: パーティションTableでは、データ分散がパーティション間で異なる可能性があるため、バケット Shuffle Joinは左Tableが単一パーティションの場合にのみ効果的であることが保証されます。したがって、SQLを実行する際は、可能な限り
WHERE条件を使用してパーティションプルーニング戦略を有効にすることが推奨されます。
Colocate Joinの制限
2つの物理Tableを直接スキャンする場合、Colocate JoinはBucket Shuffle Joinと比較してより厳しい制限があります。バケット Shuffle Joinのすべての条件を満たすことに加えて、以下の要件も満たす必要があります:
-
bucket columnのタイプと数が同じ: bucketed columnsのタイプが一致するだけでなく、バケット数も同じでなければ、データ分散の一貫性を保証できません。
-
Colocation Groupの明示的な指定: Colocation Groupを明示的に指定する必要があります。同じColocation Group内のTableのみがColocate Joinに参加できます。
-
レプリカ修復またはバランシング中の不安定な状態: レプリカ修復やバランシングなどの操作中、Colocation Groupは不安定な状態になる可能性があります。この場合、Colocate Joinは通常のJoin操作に格下げされます。