ウィンドウ関数
分析関数は、ウィンドウ関数とも呼ばれ、データセット内の行に対して複雑な計算を実行するSQLクエリの関数です。ウィンドウ関数の特徴は、クエリ結果の行数を減らすのではなく、各行に新しい計算結果を追加することです。ウィンドウ関数は、累計の計算、ランキング、移動平均など、さまざまな分析シナリオに適用できます。
以下は、ウィンドウ関数を使用して、指定された日付の前後で各店舗の売上の3日移動平均を計算する例です:
CREATE TABLE daily_sales
(store_id INT, sales_date DATE, sales_amount DECIMAL(10, 2))
PROPERTIES (
"replication_num" = "1"
);
INSERT INTO daily_sales (store_id, sales_date, sales_amount) VALUES (1, '2023-01-01', 100.00), (1, '2023-01-02', 150.00), (1, '2023-01-03', 200.00), (1, '2023-01-04', 250.00), (1, '2023-01-05', 300.00), (1, '2023-01-06', 350.00), (1, '2023-01-07', 400.00), (1, '2023-01-08', 450.00), (1, '2023-01-09', 500.00), (2, '2023-01-01', 110.00), (2, '2023-01-02', 160.00), (2, '2023-01-03', 210.00), (2, '2023-01-04', 260.00), (2, '2023-01-05', 310.00), (2, '2023-01-06', 360.00), (2, '2023-01-07', 410.00), (2, '2023-01-08', 460.00), (2, '2023-01-09', 510.00);
SELECT
store_id,
sales_date,
sales_amount,
AVG(sales_amount) OVER ( PARTITION BY store_id ORDER BY sales_date
ROWS BETWEEN 3 PRECEDING AND 3 FOLLOWING ) AS moving_avg_sales
FROM
daily_sales;
クエリ結果は以下の通りです:
+----------+------------+--------------+------------------+
| store_id | sales_date | sales_amount | moving_avg_sales |
+----------+------------+--------------+------------------+
| 1 | 2023-01-01 | 100.00 | 175.0000 |
| 1 | 2023-01-02 | 150.00 | 200.0000 |
| 1 | 2023-01-03 | 200.00 | 225.0000 |
| 1 | 2023-01-04 | 250.00 | 250.0000 |
| 1 | 2023-01-05 | 300.00 | 300.0000 |
| 1 | 2023-01-06 | 350.00 | 350.0000 |
| 1 | 2023-01-07 | 400.00 | 375.0000 |
| 1 | 2023-01-08 | 450.00 | 400.0000 |
| 1 | 2023-01-09 | 500.00 | 425.0000 |
| 2 | 2023-01-01 | 110.00 | 185.0000 |
| 2 | 2023-01-02 | 160.00 | 210.0000 |
| 2 | 2023-01-03 | 210.00 | 235.0000 |
| 2 | 2023-01-04 | 260.00 | 260.0000 |
| 2 | 2023-01-05 | 310.00 | 310.0000 |
| 2 | 2023-01-06 | 360.00 | 360.0000 |
| 2 | 2023-01-07 | 410.00 | 385.0000 |
| 2 | 2023-01-08 | 460.00 | 410.0000 |
| 2 | 2023-01-09 | 510.00 | 435.0000 |
+----------+------------+--------------+------------------+
18 rows in set (0.09 sec)
基本概念の紹介
処理順序
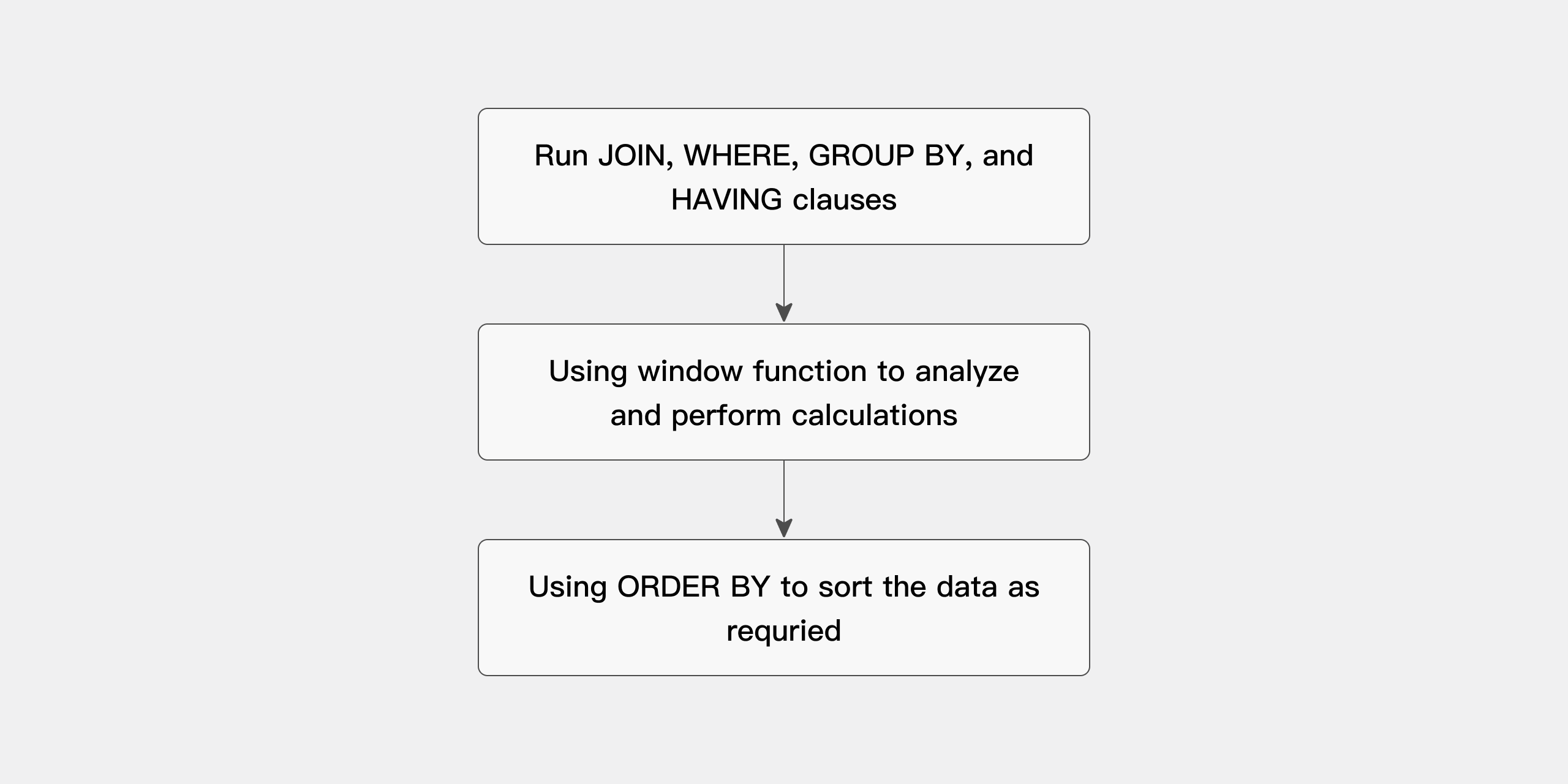
解析関数を使用したクエリの処理は、3つの段階に分けることができます。
-
すべての結合、WHERE、GROUP BY、およびHAVING句を実行する。
-
結果セットを解析関数に提供し、必要なすべての計算を実行する。
-
クエリがORDER BY句で終わる場合、正確な出力ソートを実現するためにこの句を処理する。
クエリの処理順序は以下のように図示されます:
結果セットのパーティション化
パーティションは、PARTITION BY句を使用してグループを定義した後に作成されます。解析関数では、ユーザーはクエリ結果セットをパーティションと呼ばれる行のグループに分割できます。
解析関数で使用される「パーティション」という用語は、Tableパーティション機能とは無関係です。この章では、「パーティション」という用語は解析関数に関連する意味のみを指します。
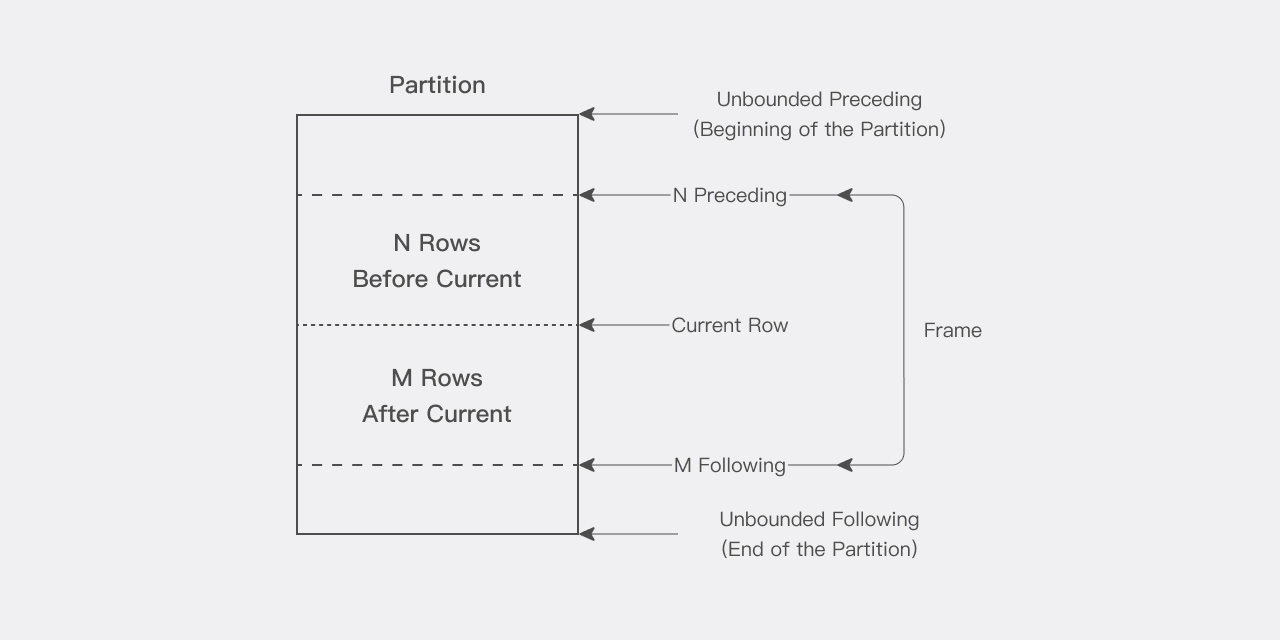
Window
パーティション内の各行に対して、スライディングデータウィンドウを定義できます。このウィンドウは、現在の行に対して計算を実行する際に関与する行の範囲を決定します。ウィンドウには開始行と終了行があり、その定義に応じて、ウィンドウは一方または両方の端でスライドできます。例えば、累積和関数では、開始行はそのパーティションの最初の行に固定され、終了行は開始からパーティションの最後の行までスライドします。逆に、移動平均では、開始点と終了点の両方がスライドします。
ウィンドウのサイズは、パーティション内のすべての行と同じ大きさに設定することも、パーティション内で1行のみを含むスライディングウィンドウと同じ小ささに設定することもできます。ウィンドウがパーティションの境界付近にある場合、境界制限により計算範囲が縮小され、関数は利用可能な行の計算結果のみを返すことに注意してください。
ウィンドウ関数を使用する場合、現在の行は計算に含まれます。したがって、n項目を処理する場合は、(n-1)として指定する必要があります。例えば、5日間の平均を計算する必要がある場合、ウィンドウは「rows between 4 preceding and current row」として指定する必要があり、これは「rows 4 preceding」と省略することもできます。
Current Row
解析関数を使用して実行される各計算は、パーティション内のcurrent rowに基づいています。current rowは、以下に示すように、ウィンドウの開始と終了を決定するための基準点として機能します。
例えば、ウィンドウを使用して、current row、current rowより前の6行、およびcurrent rowより後の6行を含む中央移動平均計算を定義できます。これにより、13行を含むスライディングウィンドウが作成されます。
ソート関数
ソート関数では、指定されたソート列が一意である場合にのみクエリ結果が決定的になります。ソート列に重複値が含まれている場合、クエリ結果は実行ごとに異なる可能性があります。
NTILE関数
NTILEは、クエリ結果セットを指定された数のバケット(グループ)に分割し、各行にバケット番号を割り当てるために使用されるSQLのウィンドウ関数です。これは、特にデータをグループ化およびソートする必要がある場合に、データ分析およびレポートで特に有用です。
1. 関数構文
NTILE(num_buckets) OVER ([PARTITION BY partition_expression] ORDER BY order_expression)
-
num_buckets: 行を分割するバケット数。 -
PARTITION BY partition_expression(オプション): データをパーティション分割する方法を定義します。 -
ORDER BY order_expression: データをソートする方法を定義します。
2. NTILE関数の使用
学生の試験スコアを含むclass_student_scoresTableがあり、スコアに基づいて学生を4つのグループに分割し、各グループの学生数をできるだけ均等にしたいとします。
まず、class_student_scoresTableを作成してデータを挿入します:
CREATE TABLE class_student_scores (
class_id INT,
student_id INT,
student_name VARCHAR(50),
score INT
)distributed by hash(student_id) properties('replication_num'=1);
INSERT INTO class_student_scores VALUES
(1, 1, 'Alice', 85),
(1, 2, 'Bob', 92),
(1, 3, 'Charlie', 87),
(2, 4, 'David', 78),
(2, 5, 'Eve', 95),
(2, 6, 'Frank', 80),
(2, 7, 'Grace', 90),
(2, 8, 'Hannah', 84);
その後、NTILE関数を使用して、スコアに基づいて学生を4つのグループに分割します:
SELECT
student_id,
student_name,
score,
NTILE(4) OVER (ORDER BY score DESC) AS bucket
FROM
class_student_scores;
結果は以下の通りです:
+------------+--------------+-------+--------+
| student_id | student_name | score | bucket |
+------------+--------------+-------+--------+
| 5 | Eve | 95 | 1 |
| 2 | Bob | 92 | 1 |
| 7 | Grace | 90 | 2 |
| 3 | Charlie | 87 | 2 |
| 1 | Alice | 85 | 3 |
| 8 | Hannah | 84 | 3 |
| 6 | Frank | 80 | 4 |
| 4 | David | 78 | 4 |
+------------+--------------+-------+--------+
8 rows in set (0.12 sec)
この例では、NTILE(4)関数が学生のスコアに基づいて学生を4つのグループ(バケット)に分割し、各グループの学生数ができる限り均等になるようにします。
-
行をバケットに均等に分散できない場合、一部のバケットには1つの追加行が含まれる場合があります。
-
NTILE関数は各パーティション内で動作します。PARTITION BY句を使用する場合、各パーティション内のデータが個別にバケットに割り当てられます。
3. PARTITION BYでのNTILEの使用
クラス別に学生をグループ化し、各クラス内でスコアに基づいて3つのグループに分割したい場合を想定します。PARTITION BYとNTILE関数を使用できます:
SELECT
class_id,
student_id,
student_name,
score,
NTILE(3) OVER (PARTITION BY class_id ORDER BY score DESC) AS bucket
FROM
class_student_scores;
結果は以下の通りです:
+----------+------------+--------------+-------+--------+
| class_id | student_id | student_name | score | bucket |
+----------+------------+--------------+-------+--------+
| 1 | 2 | Bob | 92 | 1 |
| 1 | 3 | Charlie | 87 | 2 |
| 1 | 1 | Alice | 85 | 3 |
| 2 | 5 | Eve | 95 | 1 |
| 2 | 7 | Grace | 90 | 1 |
| 2 | 8 | Hannah | 84 | 2 |
| 2 | 6 | Frank | 80 | 2 |
| 2 | 4 | David | 78 | 3 |
+----------+------------+--------------+-------+--------+
8 rows in set (0.05 sec)
この例では、学生をクラスで分割し、その後各クラス内で、スコアに基づいて3つのグループに分けています。各グループの学生数はできるだけ均等になるようにしています。
Analytic Functions
Analytic ファンクション SUMを使用して累積値を計算する
以下は例です:
SELECT
i_category,
year(d_date),
month(d_date),
sum(ss_net_paid) as total_sales,
sum(sum(ss_net_paid)) over(partition by i_category order by year(d_date),month(d_date) ROWS UNBOUNDED PRECEDING) cum_sales
FROM
store_sales,
date_dim d1,
item
WHERE
d1.d_date_sk = ss_sold_date_sk
and i_item_sk = ss_item_sk
and year(d_date) =2000
and i_category in ('Books','Electronics')
GROUP BY
i_category,
year(d_date),
month(d_date)
クエリ結果は以下の通りです:
+-------------+--------------+---------------+-------------+-------------+
| i_category | year(d_date) | month(d_date) | total_sales | cum_sales |
+-------------+--------------+---------------+-------------+-------------+
| Books | 2000 | 1 | 5348482.88 | 5348482.88 |
| Books | 2000 | 2 | 4353162.03 | 9701644.91 |
| Books | 2000 | 3 | 4466958.01 | 14168602.92 |
| Books | 2000 | 4 | 4495802.19 | 18664405.11 |
| Books | 2000 | 5 | 4589913.47 | 23254318.58 |
| Books | 2000 | 6 | 4384384.00 | 27638702.58 |
| Books | 2000 | 7 | 4488018.76 | 32126721.34 |
| Books | 2000 | 8 | 9909227.94 | 42035949.28 |
| Books | 2000 | 9 | 10366110.30 | 52402059.58 |
| Books | 2000 | 10 | 10445320.76 | 62847380.34 |
| Books | 2000 | 11 | 15246901.52 | 78094281.86 |
| Books | 2000 | 12 | 15526630.11 | 93620911.97 |
| Electronics | 2000 | 1 | 5534568.17 | 5534568.17 |
| Electronics | 2000 | 2 | 4472655.10 | 10007223.27 |
| Electronics | 2000 | 3 | 4316942.60 | 14324165.87 |
| Electronics | 2000 | 4 | 4211523.06 | 18535688.93 |
| Electronics | 2000 | 5 | 4723661.00 | 23259349.93 |
| Electronics | 2000 | 6 | 4127773.06 | 27387122.99 |
| Electronics | 2000 | 7 | 4286523.05 | 31673646.04 |
| Electronics | 2000 | 8 | 10004890.96 | 41678537.00 |
| Electronics | 2000 | 9 | 10143665.77 | 51822202.77 |
| Electronics | 2000 | 10 | 10312020.35 | 62134223.12 |
| Electronics | 2000 | 11 | 14696000.54 | 76830223.66 |
| Electronics | 2000 | 12 | 15344441.52 | 92174665.18 |
+-------------+--------------+---------------+-------------+-------------+
24 rows in set (0.13 sec)
この例では、分析関数SUMが各行に対してウィンドウを定義し、パーティションの開始(UNBOUNDED PRECEDING)から始まり、デフォルトで現在の行で終了します。この場合、SUMの結果自体に対してSUMを実行する必要があるため、SUMのネストした使用が必要になります。ネストした集約は、分析集約関数でよく使用されます。
分析関数AVGを使用した移動平均の計算
例を示します:
SELECT
i_category,
year(d_date),
month(d_date),
sum(ss_net_paid) as total_sales,
avg(sum(ss_net_paid)) over(order by year(d_date),month(d_date) ROWS 2 PRECEDING) avg
FROM
store_sales,
date_dim d1,
item
WHERE
d1.d_date_sk = ss_sold_date_sk
and i_item_sk = ss_item_sk
and year(d_date) =2000
and i_category='Books'
GROUP BY
i_category,
year(d_date),
month(d_date)
クエリ結果は以下の通りです:
+------------+--------------+---------------+-------------+---------------+
| i_category | year(d_date) | month(d_date) | total_sales | avg |
+------------+--------------+---------------+-------------+---------------+
| Books | 2000 | 1 | 5348482.88 | 5348482.8800 |
| Books | 2000 | 2 | 4353162.03 | 4850822.4550 |
| Books | 2000 | 3 | 4466958.01 | 4722867.6400 |
| Books | 2000 | 4 | 4495802.19 | 4438640.7433 |
| Books | 2000 | 5 | 4589913.47 | 4517557.8900 |
| Books | 2000 | 6 | 4384384.00 | 4490033.2200 |
| Books | 2000 | 7 | 4488018.76 | 4487438.7433 |
| Books | 2000 | 8 | 9909227.94 | 6260543.5666 |
| Books | 2000 | 9 | 10366110.30 | 8254452.3333 |
| Books | 2000 | 10 | 10445320.76 | 10240219.6666 |
| Books | 2000 | 11 | 15246901.52 | 12019444.1933 |
| Books | 2000 | 12 | 15526630.11 | 13739617.4633 |
+------------+--------------+---------------+-------------+---------------+
12 rows in set (0.13 sec)
出力データにおいて、最初の2行のAVG列は3日移動平均を計算していません。これは、境界データに対して十分な先行行がないためです(SQLで指定された行数は3です)。
さらに、現在の行を中心としたウィンドウ集約関数を計算することも可能です。たとえば、この例では2000年の"Books"カテゴリの製品について月次売上の中央移動平均を計算しており、具体的には現在の行の前月、現在の行、および現在の行の翌月の売上合計を平均化しています。
SELECT
i_category,
YEAR(d_date) AS year,
MONTH(d_date) AS month,
SUM(ss_net_paid) AS total_sales,
AVG(SUM(ss_net_paid)) OVER (ORDER BY YEAR(d_date), MONTH(d_date) ROWS BETWEEN 1 PRECEDING AND 1 FOLLOWING) AS avg_sales
FROM
store_sales,
date_dim d1,
item
WHERE
d1.d_date_sk = ss_sold_date_sk
AND i_item_sk = ss_item_sk
AND YEAR(d_date) = 2000
AND i_category = 'Books'
GROUP BY
i_category,
YEAR(d_date),
MONTH(d_date)
出力データの開始行と終了行の中心移動平均は、境界データの前後に十分な行がないため、2日分のデータのみに基づいて計算されます。
Reporting ファンクション
Reporting Functionとは、各行のウィンドウ範囲が パーティション 全体をカバーするシナリオを指します。Reporting Functionの主な利点は、単一のクエリブロック内でデータを複数回渡すことができるため、クエリパフォーマンスが向上することです。例えば、「各年において、売上が最も高い商品カテゴリを見つける」といったクエリでは、Reporting Functionを使用することで JOIN 操作が不要になります。以下に例を示します:
SELECT year, category, total_sum FROM (
SELECT
YEAR(d_date) AS year,
i_category AS category,
SUM(ss_net_paid) AS total_sum,
MAX(SUM(ss_net_paid)) OVER (PARTITION BY YEAR(d_date)) AS max_sales
FROM
store_sales,
date_dim d1,
item
WHERE
d1.d_date_sk = ss_sold_date_sk
AND i_item_sk = ss_item_sk
AND YEAR(d_date) IN (1998, 1999)
GROUP BY
YEAR(d_date), i_category
) t
WHERE total_sum = max_sales;
reportingのMAX(SUM(ss_net_paid))に対する内部クエリの結果は以下の通りです:
SELECT year, category, total_sum FROM (
SELECT
YEAR(d_date) AS year,
i_category AS category,
SUM(ss_net_paid) AS total_sum,
MAX(SUM(ss_net_paid)) OVER (PARTITION BY YEAR(d_date)) AS max_sales
FROM
store_sales,
date_dim d1,
item
WHERE
d1.d_date_sk = ss_sold_date_sk
AND i_item_sk = ss_item_sk
AND YEAR(d_date) IN (1998, 1999)
GROUP BY
YEAR(d_date), i_category
) t
WHERE total_sum = max_sales;
完全なクエリ結果は以下の通りです:
+------+-------------+-------------+
| year | category | total_sum |
+------+-------------+-------------+
| 1998 | Electronics | 91723676.27 |
| 1999 | Electronics | 90310850.54 |
+------+-------------+-------------+
2 rows in set (0.12 sec)
レポート集計をネストクエリと組み合わせることで、重要な商品サブカテゴリ内でのベストセラー商品の検索など、複雑な問題を解決できます。例えば、「商品売上がその商品カテゴリの総売上の20%以上を占めるサブカテゴリを見つけて、これらのサブカテゴリから上位5つの商品を選択する」場合、クエリ文は以下の通りです:
SELECT i_category AS categ, i_class AS sub_categ, i_item_id
FROM
(
SELECT
i_item_id, i_class, i_category, SUM(ss_net_paid) AS sales,
SUM(SUM(ss_net_paid)) OVER (PARTITION BY i_category) AS cat_sales,
SUM(SUM(ss_net_paid)) OVER (PARTITION BY i_class) AS sub_cat_sales,
RANK() OVER (PARTITION BY i_class ORDER BY SUM(ss_net_paid)) AS rank_in_line
FROM
store_sales,
item
WHERE
i_item_sk = ss_item_sk
GROUP BY i_class, i_category, i_item_id
) t
WHERE sub_cat_sales > 0.2 * cat_sales AND rank_in_line <= 5;
LAG / LEAD
LAG関数とLEAD関数は値間の比較に適しています。両方の関数は、自己結合を必要とせずにTable内の複数の行に同時にアクセスできるため、クエリ処理の速度を向上させます。具体的には、LAG関数は現在の行より指定されたオフセット分前の行へのアクセスを提供し、LEAD関数は現在の行より指定されたオフセット分後の行へのアクセスを提供します。
以下はLAG関数を使用したSQLクエリの例です。このクエリは、特定の年(1999、2000、2001、2002)における各製品カテゴリの総売上、前年の総売上、およびそれらの差を選択することを目的としています:
select year, category, total_sales, before_year_sales, total_sales - before_year_sales from
(
select
sum(ss_net_paid) as total_sales,
year(d_date) year,
i_category category,
lag(sum(ss_net_paid), 1,0) over(PARTITION BY i_category ORDER BY YEAR(d_date)) AS before_year_sales
from
store_sales,
date_dim d1,
item
where
d1.d_date_sk = ss_sold_date_sk
and i_item_sk = ss_item_sk
GROUP BY
YEAR(d_date), i_category
) t
where year in (1999, 2000, 2001, 2002)
クエリ結果は以下の通りです:
+------+-------------+-------------+-------------------+-----------------------------------+
| year | category | total_sales | before_year_sales | (total_sales - before_year_sales) |
+------+-------------+-------------+-------------------+-----------------------------------+
| 1999 | Books | 88993351.11 | 91307909.84 | -2314558.73 |
| 2000 | Books | 93620911.97 | 88993351.11 | 4627560.86 |
| 2001 | Books | 90640097.99 | 93620911.97 | -2980813.98 |
| 2002 | Books | 89585515.90 | 90640097.99 | -1054582.09 |
| 1999 | Electronics | 90310850.54 | 91723676.27 | -1412825.73 |
| 2000 | Electronics | 92174665.18 | 90310850.54 | 1863814.64 |
| 2001 | Electronics | 92598527.85 | 92174665.18 | 423862.67 |
| 2002 | Electronics | 94303831.84 | 92598527.85 | 1705303.99 |
+------+-------------+-------------+-------------------+-----------------------------------+
8 rows in set (0.16 sec)
分析関数データの一意な順序付け
1. 一貫性のない戻り結果の問題
ウィンドウ関数のORDER BY句がデータの一意な順序付けを生成できない場合、例えばORDER BY式が重複する値を結果として生じる場合、行の順序は不確定になります。これは、これらの行の戻り順序が複数のクエリ実行で変動する可能性があることを意味し、ウィンドウ関数から一貫性のない結果が生じることになります。
以下の例では、連続する実行でクエリが異なる結果を返す様子を示しています。この一貫性の欠如は主に、ORDER BY dateidがSUMウィンドウ関数に対して一意な順序付けを提供しないことに起因します。
CREATE TABLE test_window_order
(item_id int,
date_time date,
sales double)
distributed BY hash(item_id)
properties("replication_num" = 1);
INSERT INTO test_window_order VALUES
(1, '2024-07-01', 100),
(2, '2024-07-01', 100),
(3, '2024-07-01', 140);
SELECT
item_id, date_time, sales,
sum(sales) OVER (ORDER BY date_time ROWS BETWEEN
UNBOUNDED PRECEDING AND CURRENT ROW) sum
FROM
test_window_order;
sorting列date_timeに重複する値があるため、以下の2つのクエリ結果が観測される可能性があります:
+---------+------------+-------+------+
| item_id | date_time | sales | sum |
+---------+------------+-------+------+
| 1 | 2024-07-01 | 100 | 100 |
| 3 | 2024-07-01 | 140 | 240 |
| 2 | 2024-07-01 | 100 | 340 |
+---------+------------+-------+------+
3 rows in set (0.03 sec)
2. Solution
この問題に対処するため、item_idなどの一意な値の列をORDER BY句に追加して、順序の一意性を保証することができます。
SELECT
item_id,
date_time,
sales,
sum(sales) OVER (
ORDER BY item_id,
date_time ROWS BETWEEN UNBOUNDED PRECEDING AND CURRENT ROW) sum
FROM
test_window_order;
これにより、一貫したクエリ出力が得られます:
+---------+------------+-------+------+
| item_id | date_time | sales | sum |
+---------+------------+-------+------+
| 1 | 2024-07-01 | 100 | 100 |
| 2 | 2024-07-01 | 100 | 200 |
| 3 | 2024-07-01 | 140 | 340 |
+---------+------------+-------+------+
3 rows in set (0.03 sec)
分析関数の詳細については、Oracle公式ドキュメントのSQL for Analysis and Reportingを参照してください。
リファレンス
例で使用されるTable作成文は以下の通りです:
CREATE DATABASE IF NOT EXISTS doc_tpcds;
USE doc_tpcds;
CREATE TABLE IF NOT EXISTS item (
i_item_sk bigint not null,
i_item_id char(16) not null,
i_rec_start_date date,
i_rec_end_date date,
i_item_desc varchar(200),
i_current_price decimal(7,2),
i_wholesale_cost decimal(7,2),
i_brand_id integer,
i_brand char(50),
i_class_id integer,
i_class char(50),
i_category_id integer,
i_category char(50),
i_manufact_id integer,
i_manufact char(50),
i_size char(20),
i_formulation char(20),
i_color char(20),
i_units char(10),
i_container char(10),
i_manager_id integer,
i_product_name char(50)
)
DUPLICATE KEY(i_item_sk)
DISTRIBUTED BY HASH(i_item_sk) BUCKETS 12
PROPERTIES (
"replication_num" = "1"
);
CREATE TABLE IF NOT EXISTS store_sales (
ss_item_sk bigint not null,
ss_ticket_number bigint not null,
ss_sold_date_sk bigint,
ss_sold_time_sk bigint,
ss_customer_sk bigint,
ss_cdemo_sk bigint,
ss_hdemo_sk bigint,
ss_addr_sk bigint,
ss_store_sk bigint,
ss_promo_sk bigint,
ss_quantity integer,
ss_wholesale_cost decimal(7,2),
ss_list_price decimal(7,2),
ss_sales_price decimal(7,2),
ss_ext_discount_amt decimal(7,2),
ss_ext_sales_price decimal(7,2),
ss_ext_wholesale_cost decimal(7,2),
ss_ext_list_price decimal(7,2),
ss_ext_tax decimal(7,2),
ss_coupon_amt decimal(7,2),
ss_net_paid decimal(7,2),
ss_net_paid_inc_tax decimal(7,2),
ss_net_profit decimal(7,2)
)
DUPLICATE KEY(ss_item_sk, ss_ticket_number)
DISTRIBUTED BY HASH(ss_item_sk, ss_ticket_number) BUCKETS 32
PROPERTIES (
"replication_num" = "1"
);
CREATE TABLE IF NOT EXISTS date_dim (
d_date_sk bigint not null,
d_date_id char(16) not null,
d_date date,
d_month_seq integer,
d_week_seq integer,
d_quarter_seq integer,
d_year integer,
d_dow integer,
d_moy integer,
d_dom integer,
d_qoy integer,
d_fy_year integer,
d_fy_quarter_seq integer,
d_fy_week_seq integer,
d_day_name char(9),
d_quarter_name char(6),
d_holiday char(1),
d_weekend char(1),
d_following_holiday char(1),
d_first_dom integer,
d_last_dom integer,
d_same_day_ly integer,
d_same_day_lq integer,
d_current_day char(1),
d_current_week char(1),
d_current_month char(1),
d_current_quarter char(1),
d_current_year char(1)
)
DUPLICATE KEY(d_date_sk)
DISTRIBUTED BY HASH(d_date_sk) BUCKETS 12
PROPERTIES (
"replication_num" = "1"
);
CREATE TABLE IF NOT EXISTS customer_address (
ca_address_sk bigint not null,
ca_address_id char(16) not null,
ca_street_number char(10),
ca_street_name varchar(60),
ca_street_type char(15),
ca_suite_number char(10),
ca_city varchar(60),
ca_county varchar(30),
ca_state char(2),
ca_zip char(10),
ca_country varchar(20),
ca_gmt_offset decimal(5,2),
ca_location_type char(20)
)
DUPLICATE KEY(ca_address_sk)
DISTRIBUTED BY HASH(ca_address_sk) BUCKETS 12
PROPERTIES (
"replication_num" = "1"
);
ターミナルで以下のコマンドを実行して、データをローカルコンピュータにダウンロードし、Stream Load方式を使用してTableにデータを読み込みます:
curl -L https://cdn.selectdb.com/static/doc_ddl_dir_d27a752a7b.tar -o - | tar -Jxf -
curl --location-trusted \
-u "root:" \
-H "column_separator:|" \
-H "columns: i_item_sk, i_item_id, i_rec_start_date, i_rec_end_date, i_item_desc, i_current_price, i_wholesale_cost, i_brand_id, i_brand, i_class_id, i_class, i_category_id, i_category, i_manufact_id, i_manufact, i_size, i_formulation, i_color, i_units, i_container, i_manager_id, i_product_name" \
-T "doc_ddl_dir/item_1_10.dat" \
http://127.0.0.1:8030/api/doc_tpcds/item/_stream_load
curl --location-trusted \
-u "root:" \
-H "column_separator:|" \
-H "columns: d_date_sk, d_date_id, d_date, d_month_seq, d_week_seq, d_quarter_seq, d_year, d_dow, d_moy, d_dom, d_qoy, d_fy_year, d_fy_quarter_seq, d_fy_week_seq, d_day_name, d_quarter_name, d_holiday, d_weekend, d_following_holiday, d_first_dom, d_last_dom, d_same_day_ly, d_same_day_lq, d_current_day, d_current_week, d_current_month, d_current_quarter, d_current_year" \
-T "doc_ddl_dir/date_dim_1_10.dat" \
http://127.0.0.1:8030/api/doc_tpcds/date_dim/_stream_load
curl --location-trusted \
-u "root:" \
-H "column_separator:|" \
-H "columns: ss_sold_date_sk, ss_sold_time_sk, ss_item_sk, ss_customer_sk, ss_cdemo_sk, ss_hdemo_sk, ss_addr_sk, ss_store_sk, ss_promo_sk, ss_ticket_number, ss_quantity, ss_wholesale_cost, ss_list_price, ss_sales_price, ss_ext_discount_amt, ss_ext_sales_price, ss_ext_wholesale_cost, ss_ext_list_price, ss_ext_tax, ss_coupon_amt, ss_net_paid, ss_net_paid_inc_tax, ss_net_profit" \
-T "doc_ddl_dir/store_sales.csv" \
http://127.0.0.1:8030/api/doc_tpcds/store_sales/_stream_load
curl --location-trusted \
-u "root:" \
-H "column_separator:|" \
-H "ca_address_sk, ca_address_id, ca_street_number, ca_street_name, ca_street_type, ca_suite_number, ca_city, ca_county, ca_state, ca_zip, ca_country, ca_gmt_offset, ca_location_type" \
-T "doc_ddl_dir/customer_address_1_10.dat" \
http://127.0.0.1:8030/api/doc_tpcds/customer_address/_stream_load
データファイルitem_1_10.dat、date-dim_1_10.dat、store_stales.csv、およびcustomer-address_1_10.datは、linkをクリックしてダウンロードできます。