Unique Keyモデル
データの更新が必要な場合は、Unique Key Modelを使用してください。このモデルはKeyカラムの一意性を保証し、一致するキーを持つ既存のレコードを新しいデータで上書きすることで、最新のレコードのみが維持されることを保証します。このモデルは更新シナリオに最適で、データ挿入時にunique-keyレベルでの更新を可能にします。 Unique Key Modelには以下の特徴があります:
-
Unique Key UPSERT: 挿入時に、重複するキーを持つレコードは更新され、新しいキーは挿入されます。
-
自動重複排除: モデルはキーの一意性を保証し、unique keyに基づいてデータの重複を自動的に排除します。
-
高頻度更新の最適化: 更新とクエリのパフォーマンスのバランスを取りながら、高頻度の更新を効率的に処理します。
使用例
-
高頻度データ更新: 上流のOLTPデータベースで、ディメンションTableが頻繁に更新される場合、Unique Key Modelは上流の更新されたレコードを効率的に同期し、効率的なUPSERT操作を実行できます。
-
効率的なデータ重複排除: 広告キャンペーンや顧客関係管理システムなど、ユーザーIDに基づいて重複排除が必要なシナリオでは、Unique Key Modelが効率的な重複排除を保証します。
-
部分カラム更新: ユーザープロファイリングで動的タグが頻繁に変更される場合や、注文消費シナリオで取引ステータスを更新する必要がある場合などのシナリオでは、Unique Key Modelの部分カラム更新機能により、特定のカラムの変更が可能になります。
実装方法
Dorisでは、Unique Key Modelに2つの実装方法があります:
-
Merge-on-write: バージョン1.2以降、DorisのUnique Key Modelのデフォルト実装はmerge-on-writeモードです。このモードでは、書き込み時に同じKeyに対してデータが即座にマージされ、各書き込み後のデータストレージ状態がunique keyの最終マージ結果となることを保証し、最新の結果のみが保存されます。Merge-on-writeは、クエリと書き込みパフォーマンスの良いバランスを提供し、クエリ時に複数バージョンのデータをマージする必要がなく、ストレージ層への述語プッシュダウンを保証します。ほとんどのシナリオではmerge-on-writeモデルが推奨されます。
-
Merge-on-read: バージョン1.2より前では、DorisのUnique Key Modelはデフォルトでmerge-on-readモードでした。このモードでは、書き込み時にデータはマージされず、増分的に追加され、Doris内で複数のバージョンが保持されます。クエリやCompaction時に、同じKeyバージョンでデータがマージされます。Merge-on-readは書き込み重視で読み取り軽量のシナリオに適していますが、クエリ時に複数のバージョンをマージする必要があり、述語をプッシュダウンできないため、クエリ速度に影響を与える可能性があります。
Dorisでは、Unique Key Modelに2種類の更新セマンティクスがあります:
-
Full Row Upsert: Unique Key Modelのデフォルトの更新セマンティクスはfull row UPSERT、すなわちUPDATE OR INSERTです。行のKeyが存在する場合は更新され、存在しない場合は新しいデータが挿入されます。full row UPSERTセマンティクスでは、ユーザーが
INSERT INTOを使用して特定のカラムにデータを挿入した場合でも、Dorisはプランナー段階で不足しているカラムにNULL値またはデフォルト値を入力します。 -
Partial Column Upsert: ユーザーが特定のフィールドを更新したい場合は、merge-on-write実装を使用し、特定のパラメータを通じて部分カラム更新サポートを有効にする必要があります。部分カラム更新のドキュメントを参照してください。
Merge-on-write
Merge-on-writeTableの作成
Unique KeyTableを作成するには、UNIQUE KEYキーワードを使用します。enable_unique_key_merge_on_write属性を設定してmerge-on-writeモードを有効にします(Doris 2.1以降はデフォルト):
CREATE TABLE IF NOT EXISTS example_tbl_unique
(
user_id LARGEINT NOT NULL,
user_name VARCHAR(50) NOT NULL,
city VARCHAR(20),
age SMALLINT,
sex TINYINT
)
UNIQUE KEY(user_id, user_name)
DISTRIBUTED BY HASH(user_id) BUCKETS 10
PROPERTIES (
"enable_unique_key_merge_on_write" = "true"
);
Merge-on-read
Merge-on-readTableの作成
Table作成時に、UNIQUE KEYキーワードを使用してUnique KeyTableを指定できます。merge-on-readモードは、enable_unique_key_merge_on_write属性を明示的に無効にすることで有効にできます。Dorisバージョン2.1以前では、merge-on-readモードがデフォルトで有効でした:
CREATE TABLE IF NOT EXISTS example_tbl_unique
(
user_id LARGEINT NOT NULL,
username VARCHAR(50) NOT NULL,
city VARCHAR(20),
age SMALLINT,
sex TINYINT
)
UNIQUE KEY(user_id, username)
DISTRIBUTED BY HASH(user_id) BUCKETS 10
PROPERTIES (
"enable_unique_key_merge_on_write" = "false"
);
データの挿入と保存
Unique KeyTableでは、Keyカラムがソートと重複排除の両方の役割を果たします。新しい挿入は、一致するキーを持つ既存のレコードを上書きします。
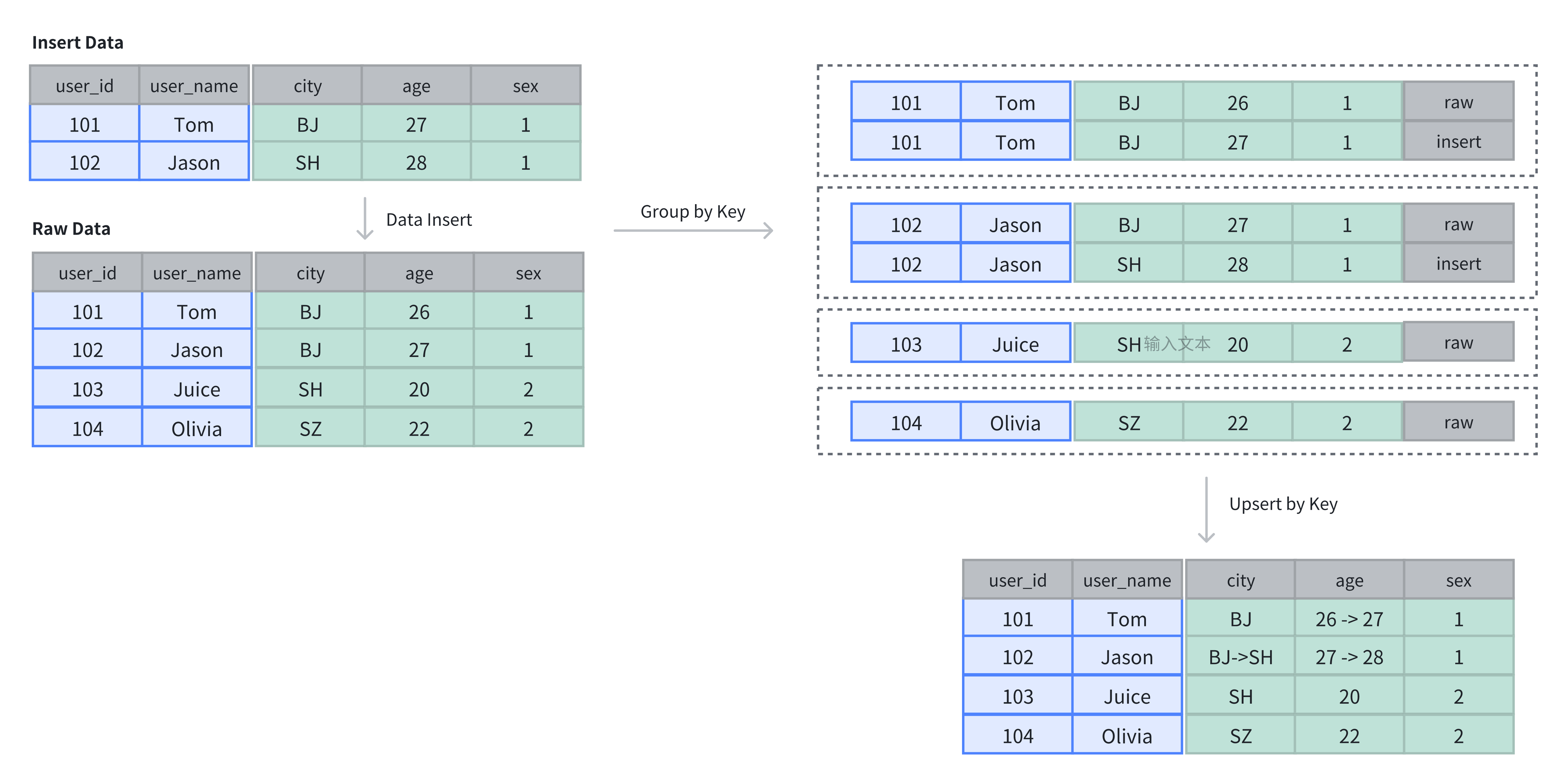
例に示されているように、元のTableには4行のデータがありました。2つの新しい行を挿入した後、新しく挿入された行はunique keyに基づいて更新されます:
-- insert into raw data
INSERT INTO example_tbl_unique VALUES
(101, 'Tom', 'BJ', 26, 1),
(102, 'Jason', 'BJ', 27, 1),
(103, 'Juice', 'SH', 20, 2),
(104, 'Olivia', 'SZ', 22, 2);
-- insert into data to update by key
INSERT INTO example_tbl_unique VALUES
(101, 'Tom', 'BJ', 27, 1),
(102, 'Jason', 'SH', 28, 1);
-- check updated data
SELECT * FROM example_tbl_unique;
+---------+----------+------+------+------+
| user_id | username | city | age | sex |
+---------+----------+------+------+------+
| 101 | Tom | BJ | 27 | 1 |
| 102 | Jason | SH | 28 | 1 |
| 104 | Olivia | SZ | 22 | 2 |
| 103 | Juice | SH | 20 | 2 |
+---------+----------+------+------+------+
注釈
-
Unique Key Tableの実装モードは作成時に固定され、スキーマ変更によって変更することはできません。
-
完全行 UPSERT セマンティクスでは、挿入時に特定のカラムが省略された場合、Doris は計画時にそれらを NULL またはデフォルト値で埋めます。
-
部分カラム upsert の場合は、適切なパラメータで merge-on-write モードを有効にしてください。ガイダンスについては Partial Column Updates を参照してください。
-
Unique Tableを使用する場合、データの一意性を保証するために、パーティションキーを Key カラムに含める必要があります。