ダッシュボード
概要
この文書では、GrafanaでDOG Stackの可観測性データを使用する方法について説明します。
DOG StackはDorisを統一ストレージバックエンドとして使用します。DorisはMySQLプロトコル互換であるため、Grafanaの単一のMySQLデータソースですべてのログ、トレース、メトリクスをクエリできます。データパスは次のとおりです:
Apps / Infrastructure → OpenTelemetry Collector → Doris Exporter → Doris → Grafana (MySQL DataSource)
このドキュメントは以下の内容をカバーします:
- 事前構築されたダッシュボードのインポート: 提供されているすぐに使えるダッシュボードを使用します。
- データモデルの理解: OTelデータがDorisにどのように保存されているか。
- カスタムダッシュボードの作成: パネル、クエリ、変数をゼロから構築します。
- リファレンス: スキーマと構文のチートシート。
前提条件
開始する前に、以下を確認してください:
- DOG Stackがデプロイされ、GrafanaとDorisの両方が実行中である。
- DorisへのMySQL形式のデータソースがGrafanaで設定されている(DOG Stackに同梱されているGrafanaには、事前設定されたDorisデータソースがすでに含まれている)。
まだデータソースを設定していない場合は、以下の手順に従ってください:
-
Grafanaの左側メニューで、Connections > Data sources > Add data sourceをクリックします。
-
MySQLを選択します。
-
接続情報を入力します:
- Host:
<Doris-fe-host>:9030- Database:
otel- User:
root(または設定したユーザー)- Password: 空白のまま(パスワードが設定されていない場合)
-
Save & testをクリックして接続が動作することを確認します。
事前構築されたダッシュボードのインポート
一般的な監視シナリオをカバーする4つの事前構築されたダッシュボードを提供しています:
| Dashboard | File | What it monitors |
|---|---|---|
| Host Metrics | host_metrics_dashboard.json | CPU、メモリ、ディスク、ネットワーク、システム負荷 |
| JVM Monitoring | jvm_metrics_dashboard.json | ヒープメモリ、GC、スレッド、CPU使用率 |
| K8s Observability | k8s_kubelet_dashboard.json | Pod / Node / Namespaceのリソース使用量 |
| Nginx Logs | nginx_logs_dashboard.json | リクエスト、ステータスコード、上位URL、エラーログ |
| PostgreSQL Metrics | postgresql-metrics-dashboard.json | 接続、トランザクション、DBサイズ、Checkpoint、BGWriter |
事前構築されたダッシュボードをインポートするには:
-
Grafanaの左側メニューで、Dashboards > New > Importをクリックします。
-
Upload dashboard JSON fileをクリックし、
grafana-dashboard/以下のJSONファイルを選択します。 -
インポートページで、データソースを設定済みのDoris(MySQL)データソースに設定します。
-
Importをクリックします。
-
残りのJSONファイルについて上記の手順を繰り返します。
インポート後、ダッシュボード上部の変数セレクタ(Service、Namespaceなど)は自動的にDorisから候補値をクエリします。
ダッシュボード別パネル詳細
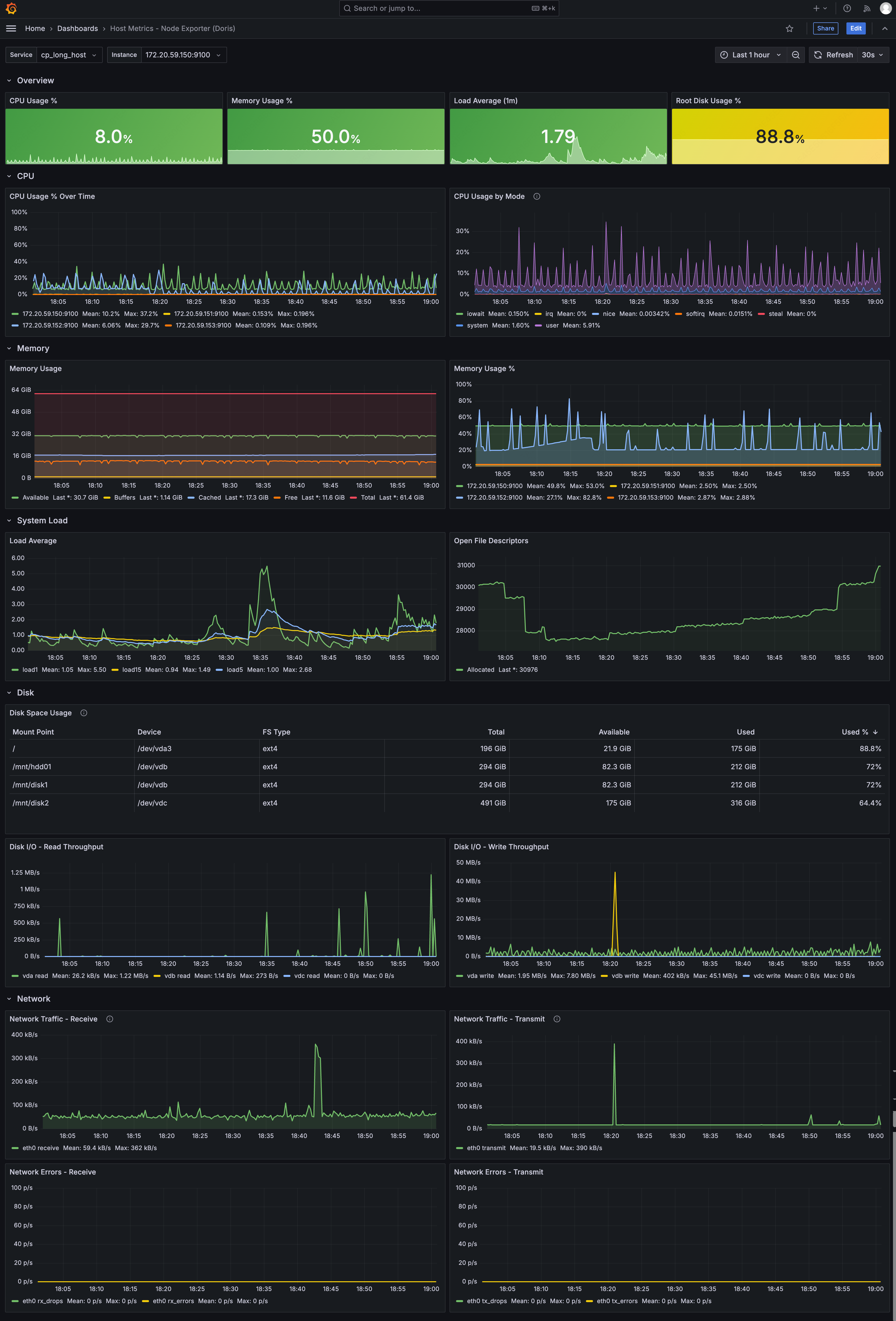
Host Metricsダッシュボード
- 概要: CPU使用率、メモリ使用率、1分負荷、rootディスク使用率
- CPU: 使用率傾向、モード別使用率
- メモリ: メモリ詳細(Total / Available / Free / Cached / Buffers)、使用率傾向
- システム負荷: 1 / 5 / 15分負荷、オープンファイルディスクリプタ
- ディスク: ディスク容量使用率テーブル、読み取り/書き込みスループット
- ネットワーク: ingress/egressトラフィック、エラーとパケットドロップ
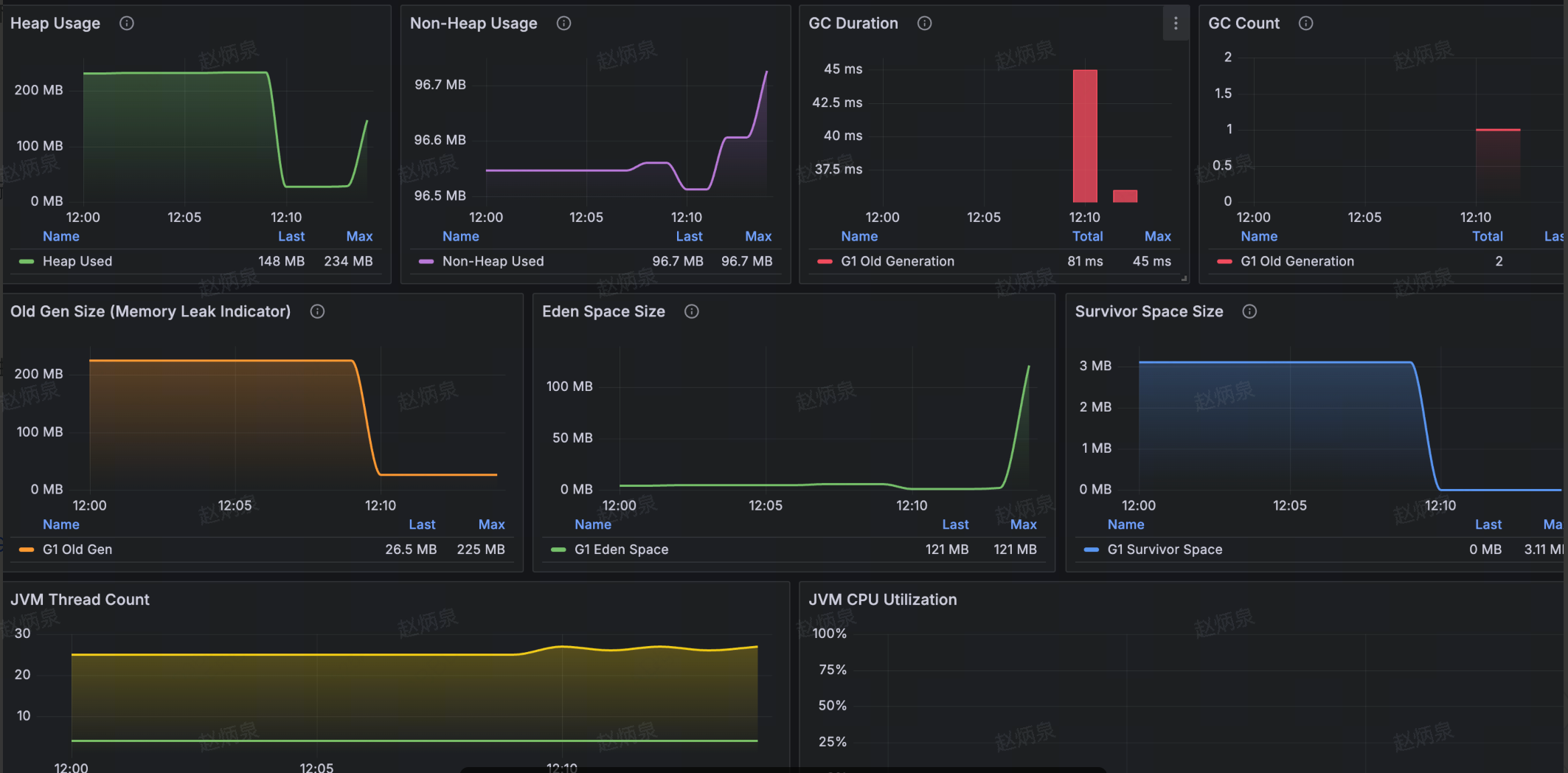
JVM Monitoringダッシュボード
- 概要: ヒープ使用量、Full GC回数、CPU使用率、スレッド数
- メモリ: ヒープ/非ヒープ傾向; Old Gen / Eden / Survivorプールの詳細
- GC: 時間(Young / Old)と回数
- スレッドとCPU: スレッド数傾向、CPU使用率
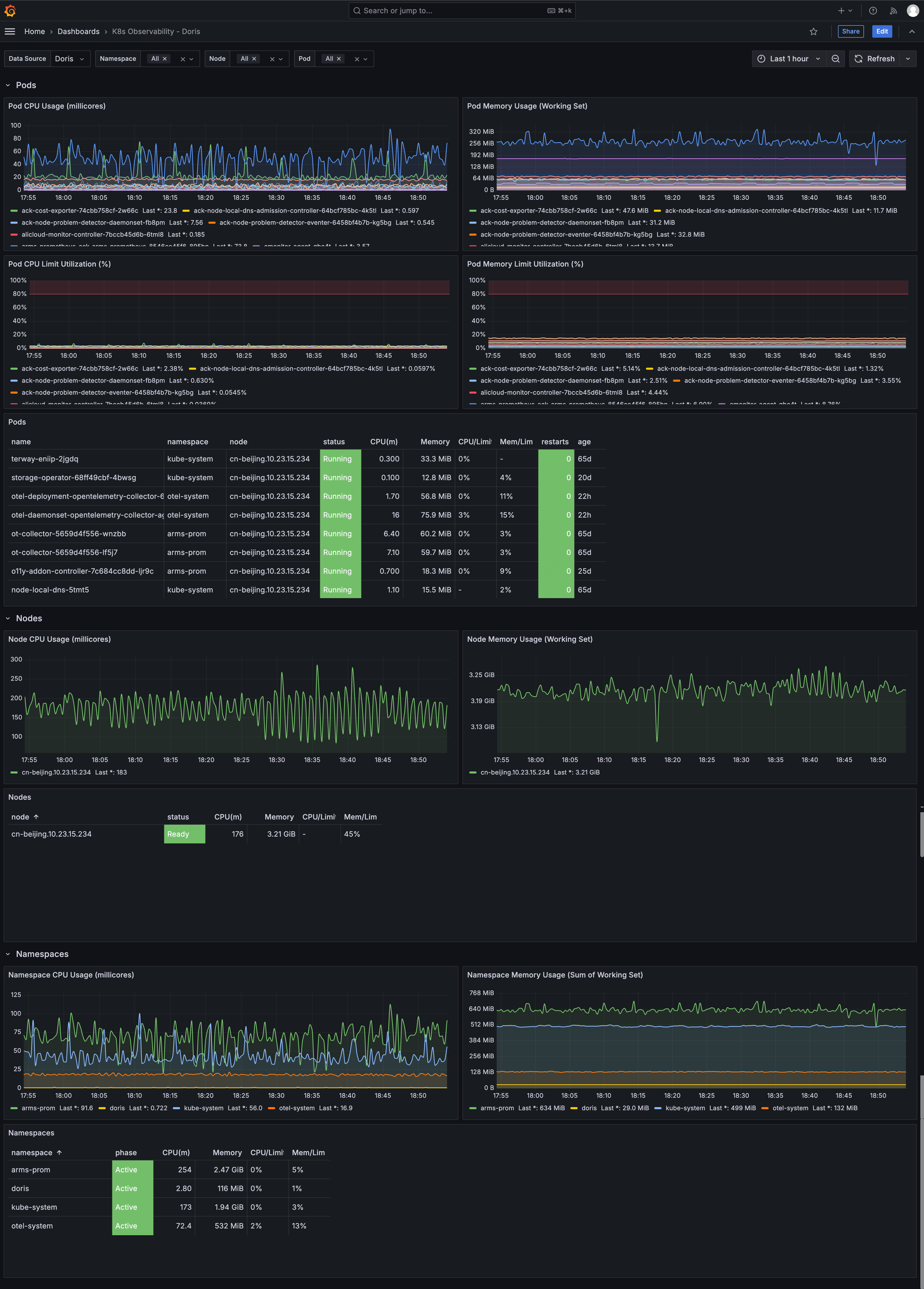
K8s Observabilityダッシュボード
- Pods: CPU(ミリコア)、メモリ、制限使用率、ステータステーブル(再起動回数とアップタイム含む)
- Nodes: CPU / メモリ傾向、ステータステーブル
- Namespaces: CPU / メモリ集計、ステータステーブル
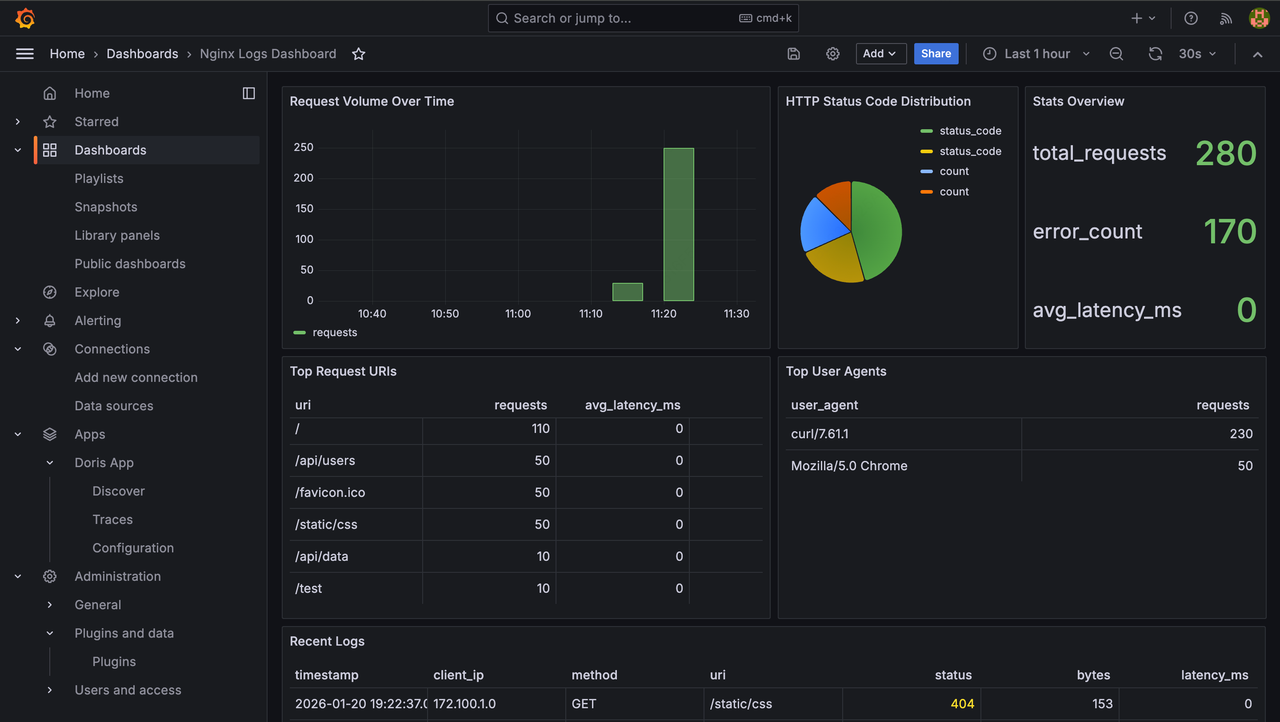
Nginx Logsダッシュボード
- 概要: リクエスト、エラー、5xx / 4xx統計、ステータスコード円グラフ
- 傾向: リクエスト量 / エラーログ傾向
- 分析: 上位URL、上位IP、HTTPメソッド分布、上位エラーメッセージ
- 最近のログ: アクセス / エラーログ詳細
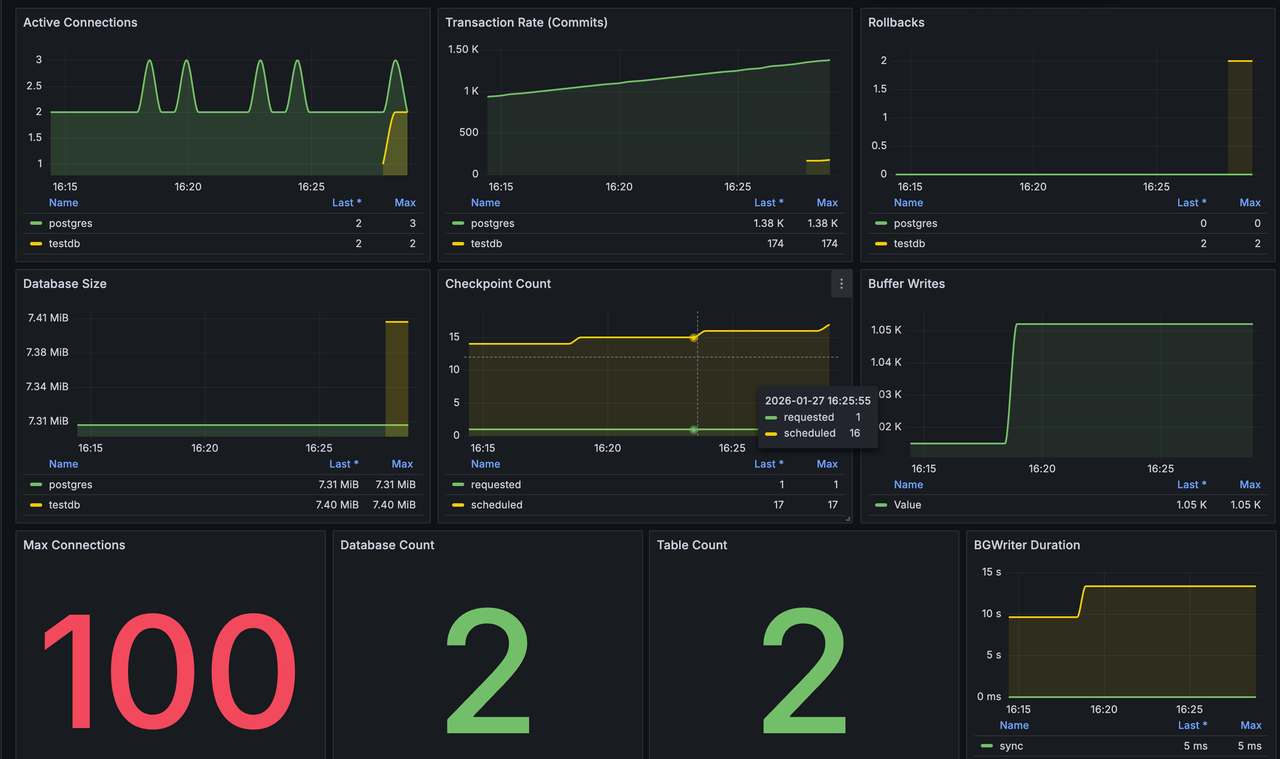
PostgreSQL Metricsダッシュボード
- 接続: アクティブ接続(データベース別)、最大接続数
- トランザクション: コミット率、ロールバック数
- ストレージ: データベースサイズ(データベース別)、データベース数、テーブル数
- BGWriter: チェックポイント数(スケジュール済み / 要求済み)、バッファ書き込み、BGWriter時間
データモデルの理解
カスタムダッシュボードを作成する前に、OTelデータがDorisにどのように保存されているかを知る必要があります。
テーブル
Prometheusとは異なり、Dorisではメトリック名だけではクエリできません — どのテーブルをクエリするかも知る必要があります。OTelデータはシグナルタイプとメトリックタイプによって複数のテーブルに保存されます:
| Table | Content | Value field | Query approach |
|---|---|---|---|
otel_metrics_gauge | 瞬時メトリック | value | 直接集計、例:AVG(value) |
otel_metrics_sum | 累積カウンタ | value(単調増加) | LAG()でレートを計算 |
otel_metrics_histogram | ヒストグラム | count、sum、bucket_counts | LAG()で差分を計算 |
otel_logs | ログ | body、severity_text | COUNT集計または詳細クエリ |
otel_traces | トレース | duration、span_name | durationでソートまたは集計 |
特定のメトリックがどのテーブルに保持されているかを確認するには、以下を実行します:
SELECT 'gauge' AS type, metric_name FROM otel.otel_metrics_gauge WHERE metric_name = 'your_metric_name' LIMIT 1
UNION ALL
SELECT 'sum', metric_name FROM otel.otel_metrics_sum WHERE metric_name = 'your_metric_name' LIMIT 1
UNION ALL
SELECT 'histogram', metric_name FROM otel.otel_metrics_histogram WHERE metric_name = 'your_metric_name' LIMIT 1;
利用可能なすべてのメトリクスを参照するには、各テーブルで以下を実行してください:
SELECT DISTINCT metric_name FROM otel.otel_metrics_gauge ORDER BY metric_name;
属性フィールド
Prometheusでは、すべてのラベルは{key="value"}として統一的にアクセスされます。Dorisでは、属性は複数のvariant(JSON)カラムに分散されており、ブラケット構文でアクセスします:
| テーブル | フィールド | 内容 | 例 |
|---|---|---|---|
| metrics | attributes | メトリクスディメンション(Prometheusラベル) | attributes['mode'] |
| metrics | resource_attributes | リソース情報(K8s pod/nodeなど) | resource_attributes['k8s.pod.name'] |
| logs | log_attributes | ログフィールド | log_attributes['status'] |
| traces | span_attributes | スパンフィールド | span_attributes['http.method'] |
注意:service_nameとservice_instance_idはトップレベルカラムであり、attributesの一部ではありません。これらは直接使用してください。例:WHERE service_name = '...'。
SELECT、GROUP BY、PARTITION BY、またはLIKEを使用する場合は、型変換のためにCASTを使用する必要があります:
-- Extract a value in SELECT
CAST(attributes['device'] AS VARCHAR) AS device
-- Pattern match in WHERE
CAST(attributes['device'] AS VARCHAR) NOT LIKE 'veth%'
-- Numeric comparison in WHERE
CAST(log_attributes['status'] AS INT) >= 500
-- Use in GROUP BY
GROUP BY CAST(resource_attributes['k8s.pod.name'] AS VARCHAR)
WHEREでの単純な等価比較では、通常CASTは不要です:
WHERE attributes['mode'] = 'idle'
注意: 間違った属性フィールド名を使用した場合(例:メトリクステーブルでlog_attributesを使用)、エラーは発生しません。代わりに静かにNULLが返され、空のクエリ結果が生成されます。
Counterメトリクスとレート計算
Gaugeメトリクスの場合、valueは直接現在の値を表し、AVGやMAXで集計できます。
Counter / Sumメトリクスの場合、valueは単調に増加する累積値です(総CPU秒数や総ネットワークバイト数など)。レートを取得するには、隣接するデータポイント間のデルタが必要です。PrometheusのPrometheus のrate()は、DorisではLAG()ウィンドウ関数で実装されています。
以下は汎用的なレートテンプレートです:
SELECT
t.timestamp AS time,
t.<dimension_field> AS metric,
CASE
WHEN UNIX_TIMESTAMP(t.timestamp) > UNIX_TIMESTAMP(t.prev_ts)
AND t.value >= t.prev_value
THEN (t.value - t.prev_value) / (UNIX_TIMESTAMP(t.timestamp) - UNIX_TIMESTAMP(t.prev_ts))
ELSE NULL
END AS value
FROM (
SELECT timestamp, value, <dimension_field>,
LAG(value) OVER (PARTITION BY <dimension_field> ORDER BY timestamp) AS prev_value,
LAG(timestamp) OVER (PARTITION BY <dimension_field> ORDER BY timestamp) AS prev_ts
FROM otel.otel_metrics_sum
WHERE metric_name = '<metric_name>'
AND $__timeFilter(timestamp)
) t
WHERE t.prev_ts IS NOT NULL
ORDER BY time
このテンプレートを使用するには、以下のプレースホルダーを置き換えてください:
<dimension_field>: シリーズを分割するフィールド。例:CAST(attributes['device'] AS VARCHAR)<metric_name>: メトリック名。例:node_network_receive_bytes_total
このテンプレートには3つの安全性レイヤーが含まれています:
| 条件 | 目的 |
|---|---|
WHERE t.prev_ts IS NOT NULL | 各パーティションの最初の行をスキップ(LAGがNULLを返すため) |
UNIX_TIMESTAMP(t.timestamp) > UNIX_TIMESTAMP(t.prev_ts) | 重複するタイムスタンプによるゼロ除算を防止 |
t.value >= t.prev_value | カウンタリセットによる負のデルタを防止 |
PARTITION BYの選択は、レートが正しいかどうかを直接決定します。間違った選択により、異なる次元のデータが混在します。プリビルトダッシュボードで使用されている選択は以下の通りです:
| シナリオ | PARTITION BY |
|---|---|
| CPU使用率(マルチコア集計) | service_instance_id, CAST(attributes['cpu'] AS VARCHAR) |
| ディスクI/O | CAST(attributes['device'] AS VARCHAR) |
| ネットワークトラフィック | CAST(attributes['device'] AS VARCHAR) |
| GC時間 | CAST(attributes['jvm.gc.name'] AS VARCHAR) |
カスタムダッシュボードの作成
このセクションでは、複数のパネルと変数を持つダッシュボードを一から作成する実践的な手順を説明します。
ダッシュボードとTime Seriesパネルの作成
K8sポッドのCPU使用率トレンドを表示するTime Seriesパネルを作成します。この例では、Gaugeメトリックを使用し、SQLを記述する完全な思考プロセスを示します。
-
Grafanaの左側メニューで、Dashboards > New > New dashboardをクリックします。
-
Add visualizationをクリックします。
-
データソースドロップダウンから、設定済みのMySQL(Doris)データソースを選択します。
-
クエリエディタの右上で、Codeモードに切り替えます。
次に、SQLクエリを記述します。以下では、段階的に構築していきます。
ベースクエリを記述します。 目標はポッドCPUの監視です。メトリック名はk8s.pod.cpu.usageです。これはotel_metrics_gaugeに格納されるGaugeメトリックで、valueを直接集計できます:
SELECT timestamp, value
FROM otel.otel_metrics_gauge
WHERE metric_name = 'k8s.pod.cpu.usage'
時間フィルタリングを追加する。 GrafanaのMySQLデータソースは、時間でフィルタリングする2つの方法を提供します:
-- Option A: use the $__timeFilter macro (recommended)
WHERE metric_name = 'k8s.pod.cpu.usage'
AND $__timeFilter(timestamp)
-- Option B: use $__from and $__to (more flexible inside subqueries or JOINs)
WHERE metric_name = 'k8s.pod.cpu.usage'
AND timestamp >= FROM_UNIXTIME($__from/1000)
AND timestamp < FROM_UNIXTIME($__to/1000)
注意: $__fromと$__toはミリ秒のタイムスタンプです — FROM_UNIXTIME()で使用する前に1000で割ってください。
時間バケッティングを追加します。 生データポイントは密度が高すぎるため、固定間隔で集約してください。時間をN秒のバケットに丸めるにはFLOOR(UNIX_TIMESTAMP(timestamp) / N) * Nを使用します:
SELECT
FLOOR(UNIX_TIMESTAMP(timestamp) / 20) * 20 AS time,
AVG(value) AS value
FROM otel.otel_metrics_gauge
WHERE metric_name = 'k8s.pod.cpu.usage'
AND timestamp >= FROM_UNIXTIME($__from/1000)
AND timestamp < FROM_UNIXTIME($__to/1000)
GROUP BY time
ORDER BY time
ディメンションによって複数の系列に分割します。 Time Series形式では、GrafanaのMySQLデータソースに3つの列が必要です:
| 列 | 目的 |
|---|---|
time または time_sec | X軸の時間。datetime値または秒単位のUNIXタイムスタンプのいずれか。 |
metric | 系列名。Grafanaはこの列の異なる値によって複数の線に分割します。 |
value | Y軸の値。 |
完全なクエリのために、pod名をmetric列として追加します:
SELECT
FLOOR(UNIX_TIMESTAMP(timestamp) / 20) * 20 AS time,
CAST(resource_attributes['k8s.pod.name'] AS VARCHAR) AS metric,
AVG(value) AS value
FROM otel.otel_metrics_gauge
WHERE metric_name = 'k8s.pod.cpu.usage'
AND timestamp >= FROM_UNIXTIME($__from/1000)
AND timestamp < FROM_UNIXTIME($__to/1000)
GROUP BY time, metric
ORDER BY time
別のGaugeメトリックを監視するには、以下を変更してください:
metric_name: 対象のメトリック名。metric列:attributesまたはresource_attributesから選択される、シリーズを分割するために使用されるディメンション。
-
完全なSQLをクエリエディターに貼り付けます。
-
エディターの下で、FormatをTime seriesに設定します。
-
パネルのタイトルをクリックして名前を設定します。
-
右側のパネル設定で、Standard options > Unitを見つけて、適切な単位を選択します。
-
右上のApplyをクリックします。
Counterメトリックパネルの追加
このセクションでは、Counterメトリックのレートを表示するTime Seriesパネルを作成します。Counterのvalueは単調に増加する累積値です — レートを計算するには汎用レートテンプレートを使用してください。
- ダッシュボードで、Add > Visualizationをクリックします。
- データソースを選択してCodeモードに切り替えます。
レートテンプレート内のプレースホルダーを具体的な値に置き換えます。以下の例では、ネットワークデバイス別に分割したネットワーク受信バイトレートを計算しています:
SELECT
t.timestamp AS time,
t.device AS metric,
CASE
WHEN UNIX_TIMESTAMP(t.timestamp) > UNIX_TIMESTAMP(t.prev_ts)
AND t.value >= t.prev_value
THEN (t.value - t.prev_value) / (UNIX_TIMESTAMP(t.timestamp) - UNIX_TIMESTAMP(t.prev_ts))
ELSE NULL
END AS value
FROM (
SELECT timestamp, CAST(attributes['device'] AS VARCHAR) AS device, value,
LAG(value) OVER (PARTITION BY CAST(attributes['device'] AS VARCHAR) ORDER BY timestamp) AS prev_value,
LAG(timestamp) OVER (PARTITION BY CAST(attributes['device'] AS VARCHAR) ORDER BY timestamp) AS prev_ts
FROM otel.otel_metrics_sum
WHERE metric_name = 'node_network_receive_bytes_total'
AND $__timeFilter(timestamp)
) t
WHERE t.prev_ts IS NOT NULL
ORDER BY time
異なるCounterメトリックを使用するには、2つの項目を変更します:
metric_name:対象のメトリック名。PARTITION BYとSELECT内のディメンションフィールド:そのメトリックを分割するために使用されるディメンション(attributes['cpu']、attributes['gc_name']など)。- SQLを貼り付けて、FormatをTime seriesに設定します。
- Standard options > Unitで、適切な単位を選択します。
- Applyをクリックします。
Statパネルを追加する
Statパネルは、現在の使用率や最新のカウントなどの単一の値を表示します。SQLは1つの値を返すだけで済みます。
- Add > Visualizationをクリックして、Codeモードに切り替えます。
次のクエリは、時間範囲内の最新のメトリック値を取得します:
SELECT value
FROM otel.otel_metrics_gauge
WHERE metric_name = 'node_memory_MemAvailable_bytes'
AND $__timeFilter(timestamp)
ORDER BY timestamp DESC
LIMIT 1
複数のメトリック(比率など)で計算を行う必要がある場合は、最適化のヒントの「1つのSQLで複数のメトリックをクエリする」を参照してください。
- SQLを貼り付けて、FormatをTableに設定します(StatパネルはTable形式を使用します)。
- 右側のパネル設定で、パネルタイプをStatに変更します。
- Standard options > Unitで、適切な単位を選択します。
- Applyをクリックします。
Tableパネルの追加
Tableパネルは複数行、複数列のデータに適しています。SQLの各列エイリアスが列ヘッダーになります。
- Add > Visualizationをクリックして、Codeモードに切り替えます。
以下のクエリは最近のログの詳細を表示します:
SELECT
timestamp,
service_name,
severity_text,
body,
CAST(log_attributes['your_key'] AS VARCHAR) AS your_key
FROM otel.otel_logs
WHERE $__timeFilter(timestamp)
ORDER BY timestamp DESC
LIMIT 100
your_key を実際のログ属性フィールド名に置き換えてください。利用可能な属性を確認するには、以下を実行してください:
SELECT log_attributes FROM otel.otel_logs LIMIT 1;
- SQLを貼り付け、FormatをTableに設定します。
- Applyをクリックします。
テンプレート変数の追加
テンプレート変数は、ダッシュボードにインタラクティブなドロップダウンフィルターを追加し、SQLを変更することなくユーザーがデータをフィルタリングできるようにします。
単一選択変数:
-
ダッシュボードの右上にある歯車アイコンをクリックし、Settings > Variables > New variableに移動します。
-
設定を入力します:
- Name:
service_name- Type: Query
- Data source: Dorisデータソースを選択
- Query:
sql SELECT DISTINCT service_name FROM otel.otel_metrics_gauge WHERE service_name != '' AND service_name IS NOT NULL AND $__timeFilter(timestamp) ORDER BY service_name
- Applyをクリックします。
パネルのSQLで単一選択変数を参照するには、$variable構文を使用します:
AND service_name = '$service_name'
マルチセレクト変数:
-
次の設定で新しい変数を作成します:
- Name:
namespace- Type: Query
- Multi-value: チェック
- Include All option: チェック
- Query:
sql SELECT DISTINCT CAST(resource_attributes['k8s.namespace.name'] AS VARCHAR) AS __text FROM otel.otel_metrics_gauge WHERE metric_name = 'k8s.pod.phase' AND timestamp >= NOW() - INTERVAL 1 HOUR ORDER BY 1
- Applyをクリックします。
注記:列エイリアス__textは、ドロップダウンの表示テキストを制御するために使用されるGrafanaの規約です。
パネルのSQLでは、マルチセレクト変数を${variable:sqlstring}構文とIN()を組み合わせて参照します:
AND CAST(resource_attributes['k8s.namespace.name'] AS VARCHAR) IN (${namespace:sqlstring})
注意: マルチ選択変数で:sqlstringが省略されると、SQL構文エラーが発生します。
カスケード変数:
ある変数の候補値は、別の変数に依存することができます。例えば、以下のPod変数は、現在選択されているNamespaceによって候補をフィルタリングします:
SELECT DISTINCT CAST(resource_attributes['k8s.pod.name'] AS VARCHAR) AS __text
FROM otel.otel_metrics_gauge
WHERE metric_name = 'k8s.pod.phase'
AND timestamp >= NOW() - INTERVAL 1 HOUR
AND CAST(resource_attributes['k8s.namespace.name'] AS VARCHAR) IN (${namespace:sqlstring})
ORDER BY 1
最適化のヒント
以下は、事前構築されたダッシュボードで使用される一般的な最適化テクニックです。
時間バケット間隔を調整する。 時間範囲に合ったバケットサイズを選択してください。FLOOR(UNIX_TIMESTAMP(timestamp) / N) * NのNを変更します:
- 20秒:短時間ウィンドウのリアルタイム監視に適している。
- 60秒:時間レベルの概要に適している。
- 300秒:日レベルのトレンドに適している。
意味のあるシリーズ名を設定する。 CONCAT()を使用して複数のフィールドを結合します:
CONCAT(device, ' read') AS metric
CASE WHENを使用して数値を読みやすいテキストにマッピングする:
CASE WHEN value = 2 THEN 'Running'
WHEN value = 1 THEN 'Pending'
WHEN value = 3 THEN 'Succeeded'
WHEN value = 4 THEN 'Failed'
ELSE 'Unknown'
END AS status
ゼロ除算とNULLを処理する。 ゼロ除算を防ぐためにNULLIFを使用し、デフォルト値を提供するためにCOALESCEを使用する:
/ NULLIF(SUM(...), 0)
COALESCE(restarts, 0)
1つのSQLで複数のメトリクスをクエリする。 JOINの代わりにCASE WHEN metric_nameを使用する:
SELECT timestamp AS time,
SUM(CASE WHEN metric_name = 'node_memory_MemAvailable_bytes' THEN value END) AS available,
SUM(CASE WHEN metric_name = 'node_memory_MemTotal_bytes' THEN value END) AS total
FROM otel.otel_metrics_gauge
WHERE metric_name IN ('node_memory_MemTotal_bytes', 'node_memory_MemAvailable_bytes')
GROUP BY timestamp
ノイズデータをフィルタリングする。 仮想ネットワークインターフェースを除外する:
AND CAST(attributes['device'] AS VARCHAR) NOT LIKE 'veth%'
AND CAST(attributes['device'] AS VARCHAR) NOT LIKE 'br-%'
AND CAST(attributes['device'] AS VARCHAR) != 'lo'
実際のファイルシステムのみを保持:
AND CAST(attributes['fstype'] AS VARCHAR) IN ('ext4', 'xfs', 'btrfs')
リファレンス
OTelテーブルスキーマ
Metricsテーブル(gauge / sum / histogram — 共通フィールド)
| フィールド | タイプ | 説明 |
|---|---|---|
service_name | varchar(200) | サービス名 |
timestamp | datetime(6) | データタイムスタンプ |
service_instance_id | varchar(200) | サービスインスタンスID |
metric_name | varchar(200) | メトリック名 |
metric_description | text | メトリック説明 |
metric_unit | text | メトリック単位 |
attributes | variant (JSON) | メトリック次元 |
resource_attributes | variant (JSON) | リソース属性 |
scope_name | text | コレクター名 |
gauge専用フィールド: value (double)
sum追加フィールド: value (double), aggregation_temporality (text), is_monotonic (boolean)
histogram追加フィールド: count (bigint), sum (double), bucket_counts (array<bigint>), explicit_bounds (array<double>), min (double), max (double)
Logsテーブル
| フィールド | タイプ | 説明 |
|---|---|---|
timestamp | datetime(6) | ログタイムスタンプ |
service_name | varchar(200) | サービス名 |
service_instance_id | varchar(200) | サービスインスタンスID |
trace_id | varchar(200) | 関連するトレースID |
span_id | text | 関連するスパンID |
severity_number | int | 重要度番号 |
severity_text | text | 重要度テキスト(INFO / WARN / ERROR) |
body | text | ログ本文 |
resource_attributes | variant (JSON) | リソース属性 |
log_attributes | variant (JSON) | ログ属性 |
Tracesテーブル
| フィールド | タイプ | 説明 |
|---|---|---|
timestamp | datetime(6) | スパン開始時刻 |
service_name | varchar(200) | サービス名 |
trace_id | varchar(200) | トレースID |
span_id | text | スパンID |
parent_span_id | text | 親スパンID |
span_name | text | スパン名 |
span_kind | text | スパン種別(CLIENT / SERVER / INTERNAL) |
end_time | datetime(6) | スパン終了時刻 |
duration | bigint | 継続時間(ナノ秒) |
span_attributes | variant (JSON) | スパン属性 |
events | array | スパンイベント |
links | array | スパンリンク |
status_code | text | ステータスコード(OK / ERROR / UNSET) |
status_message | text | ステータスメッセージ |
resource_attributes | variant (JSON) | リソース属性 |
構文チートシート
| 目的 | 構文 |
|---|---|
| 時間フィルター(マクロ) | $__timeFilter(timestamp) |
| 時間フィルター(手動) | timestamp >= FROM_UNIXTIME($__from/1000) |
| 時間バケット(20秒) | FLOOR(UNIX_TIMESTAMP(timestamp) / 20) * 20 AS time |
| 時間バケット(1分) | UNIX_TIMESTAMP(DATE_FORMAT(timestamp, '%Y-%m-%d %H:%i:00')) * 1000 AS time |
| 属性アクセス | attributes['key'] |
| 属性CAST | CAST(attributes['key'] AS VARCHAR) |
| 単一選択変数 | service_name = '$service_name' |
| 複数選択変数 | IN (${namespace:sqlstring}) |
| ゼロ除算ガード | / NULLIF(..., 0) |
| デフォルト値 | COALESCE(..., 0) |
| シリーズ命名 | CONCAT(device, ' read') AS metric |
| ステータスマッピング | CASE WHEN value = 2 THEN 'Running' ... END |
| URLクエリ文字列削除 | SUBSTRING_INDEX(url, '?', 1) |
| 仮想ネットワークカードフィルター除外 | NOT LIKE 'veth%' + NOT LIKE 'br-%' + != 'lo' |