ログとトレース検索
Discoverページは、高性能ログ解析に最適化されたKibana Discover風の検索・分析体験を提供します。
主要機能:
- SQLとLuceneの両方のクエリ構文をサポート
- ログからトレースへのワンクリックナビゲーション
- 時間範囲、フィルターなどのインタラクティブ選択
- テーブル形式とJSON形式の結果表示を提供
- 文脈分析のための特定レコード周辺データの表示
- フィールド値分布統計(パーセンテージ付きトップ5値)
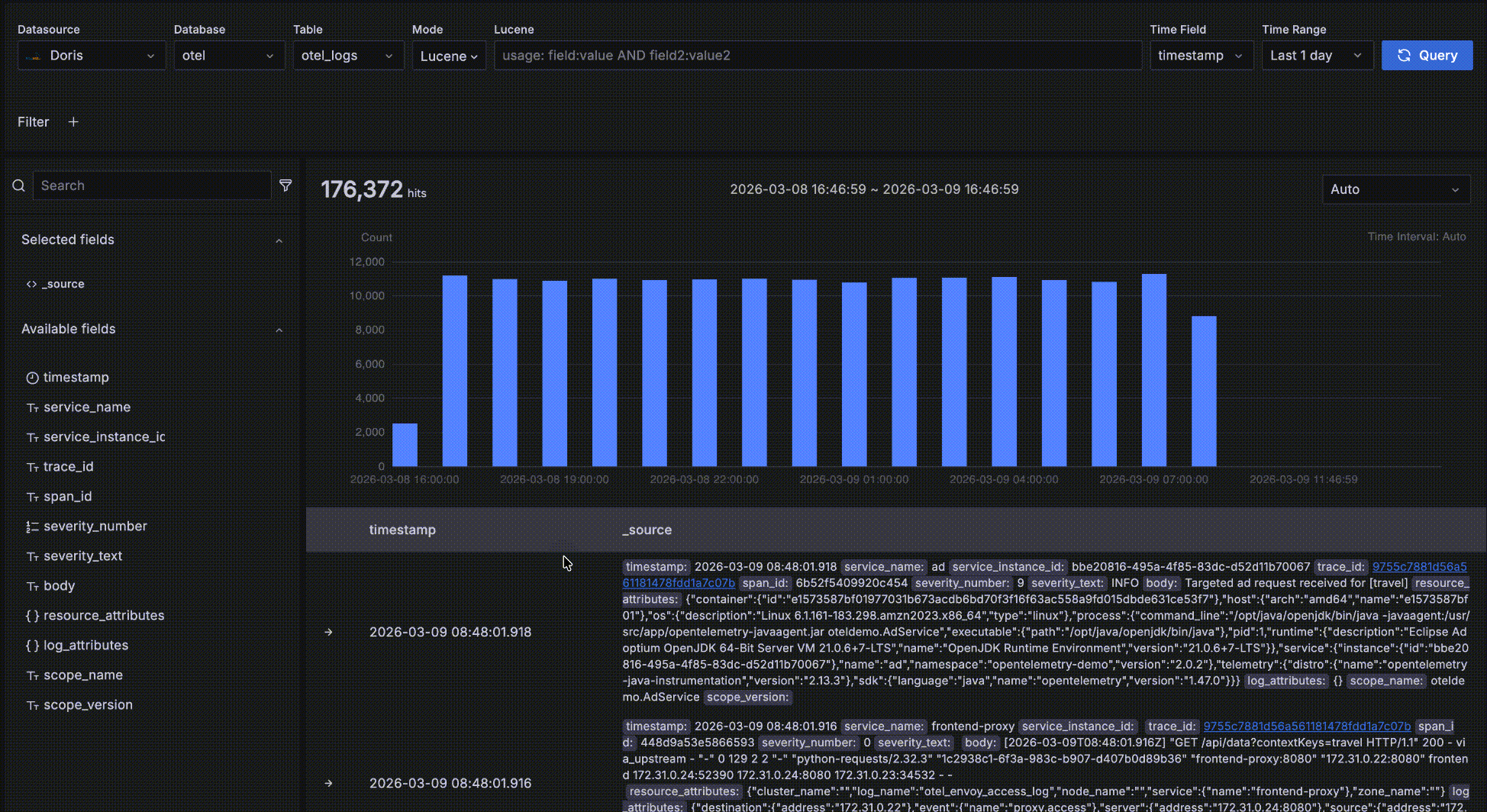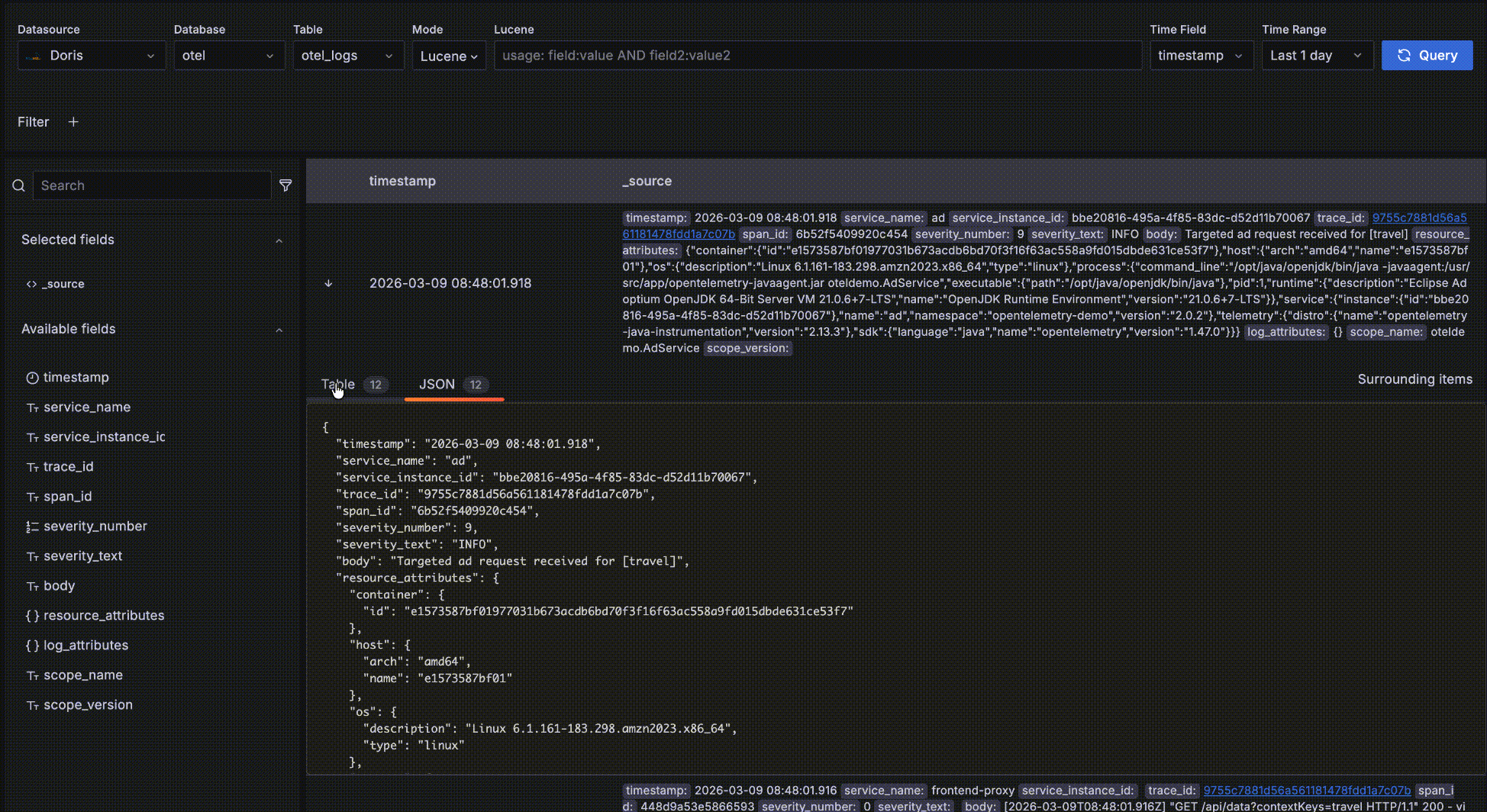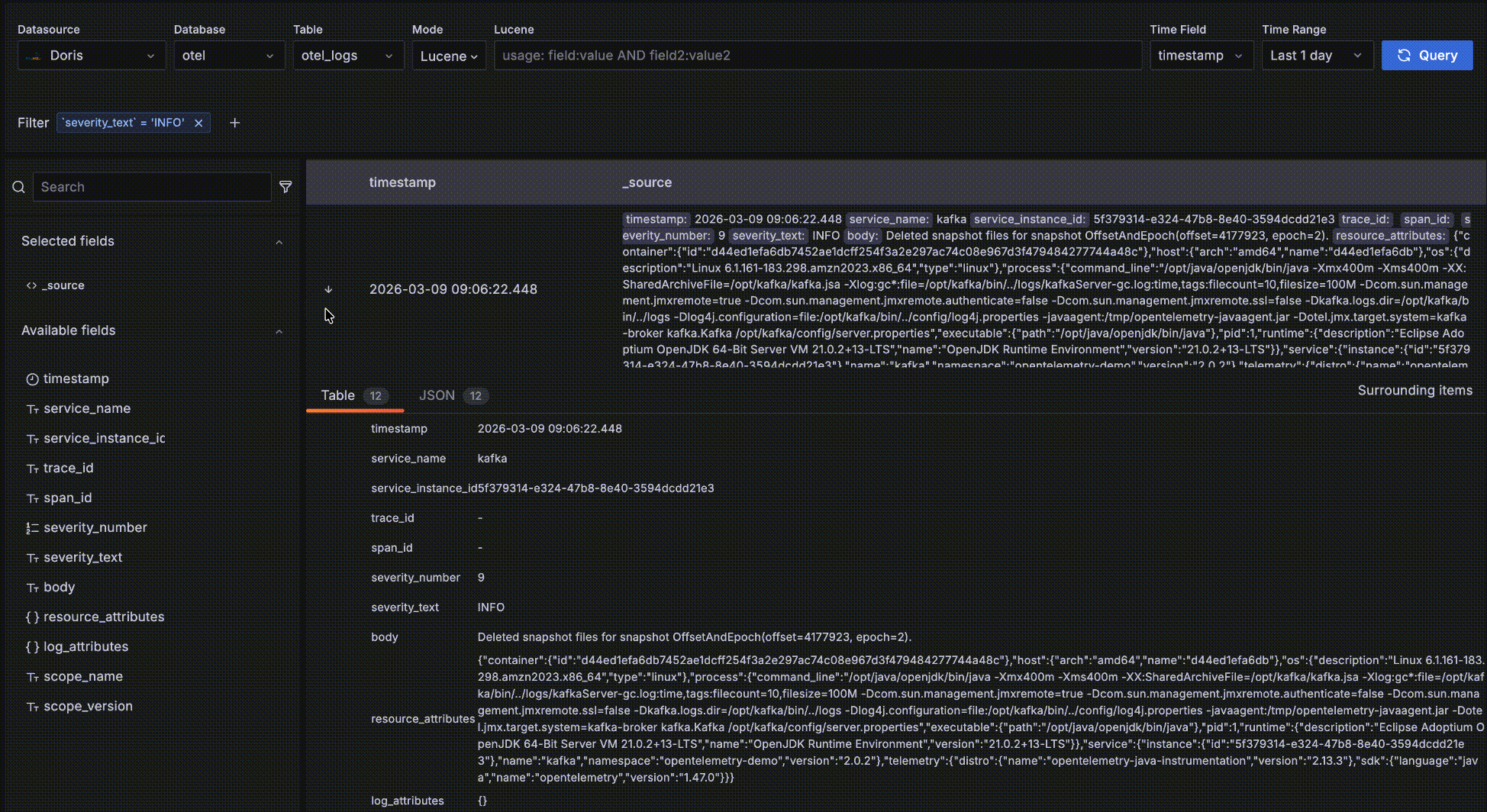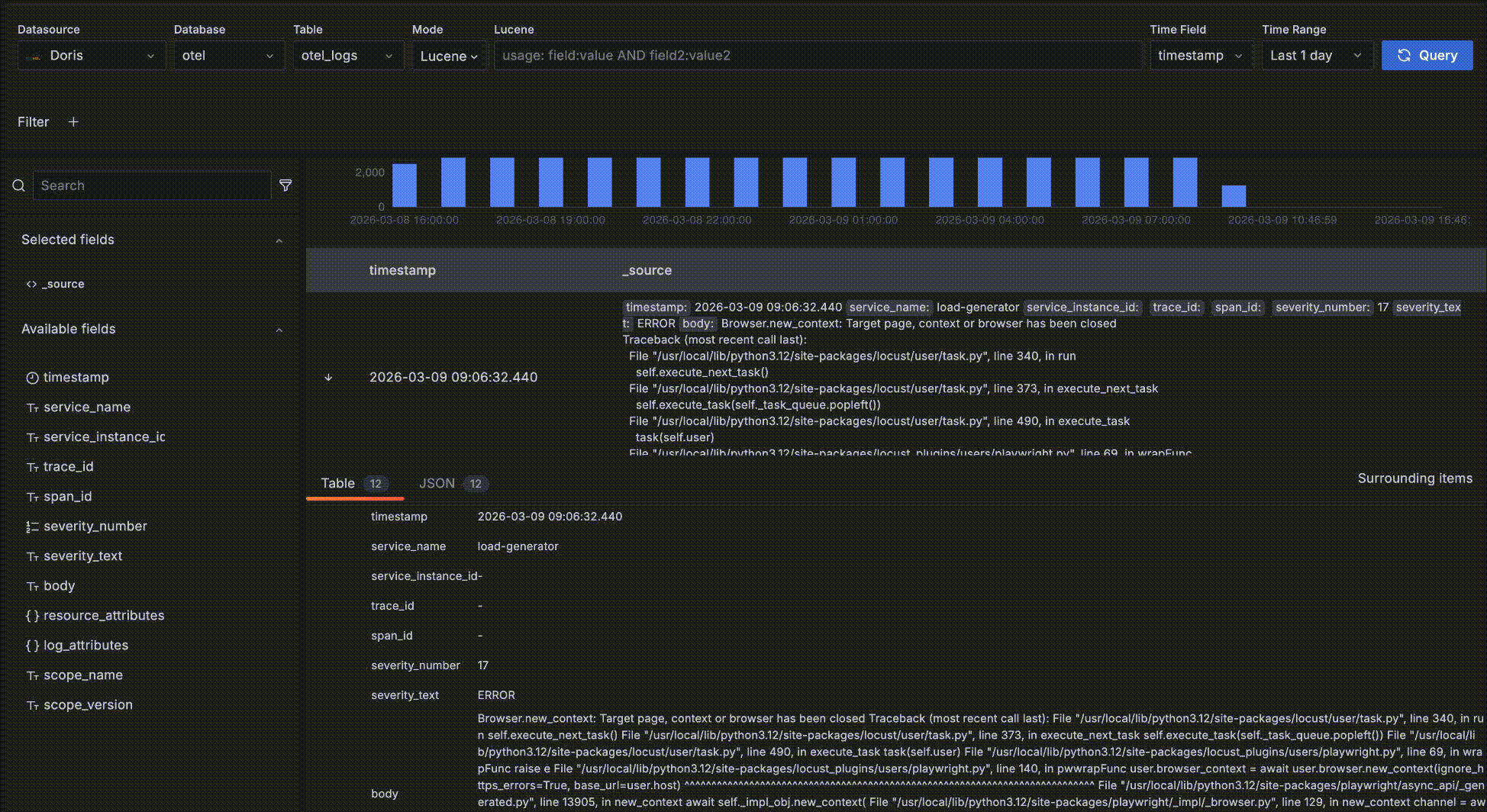
Discoverページ概要
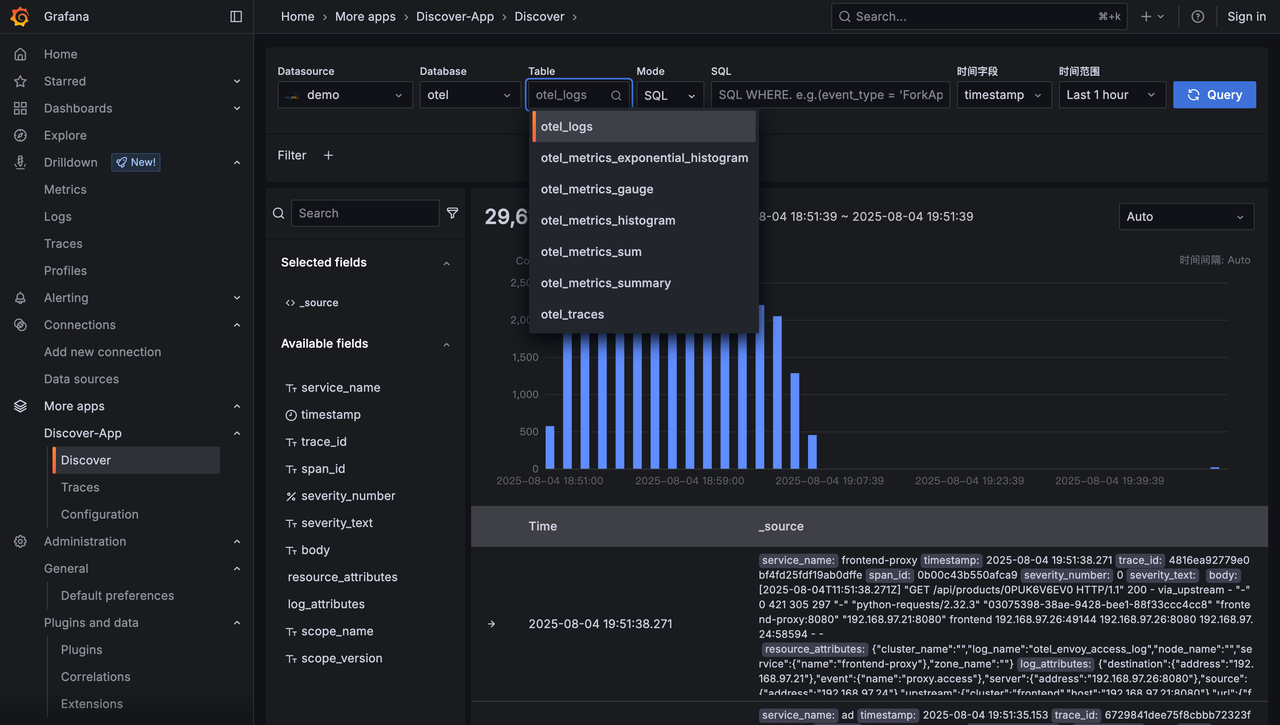
Discoverページは4つの主要エリアで構成されています:
1. クエリ入力エリア(上部)
クエリスコープと検索文を設定します。機能には以下が含まれます:
- データソースの選択
- 時間フィールドと時間範囲の選択
- SQLまたはLucene構文での検索条件入力
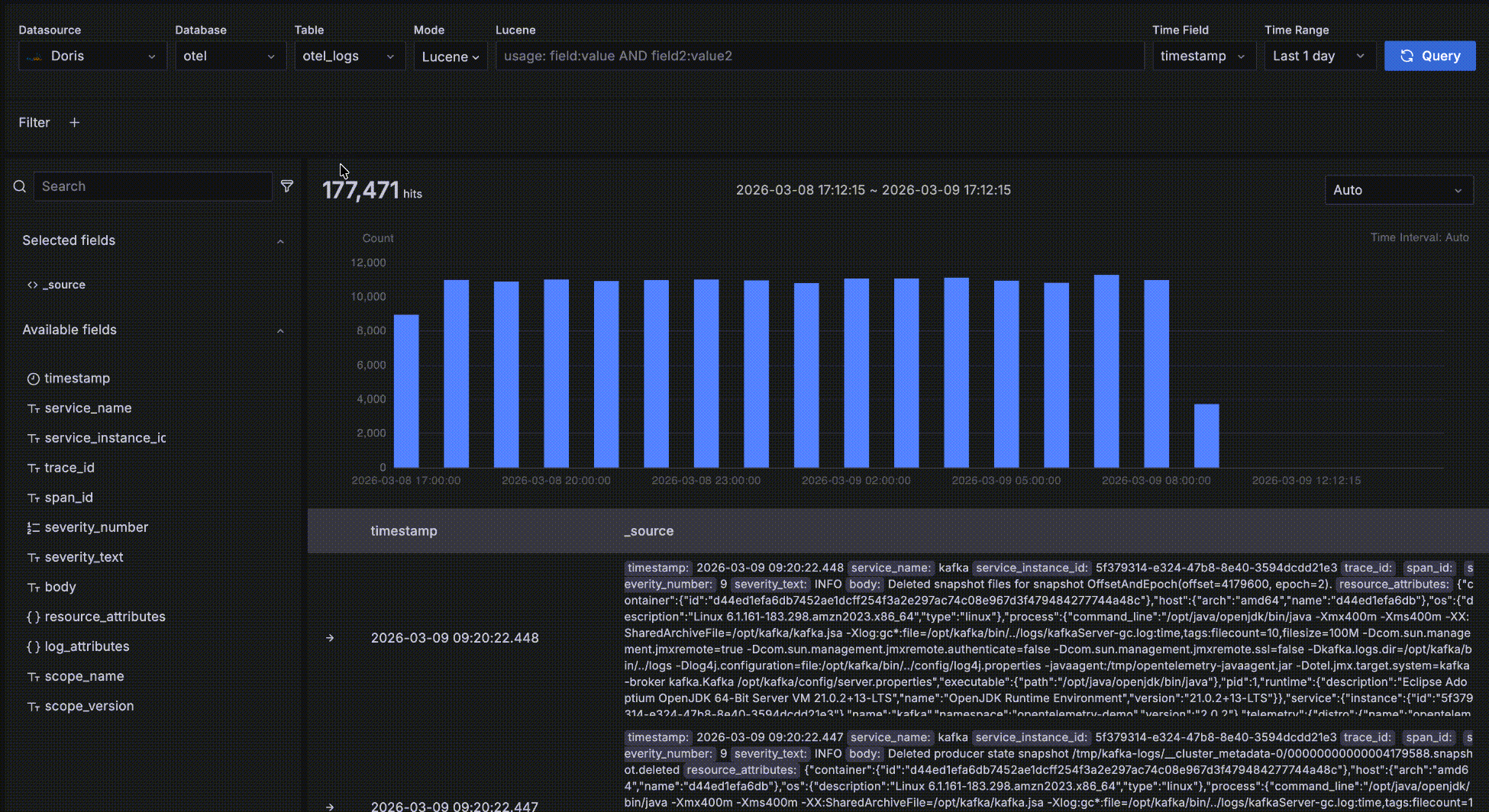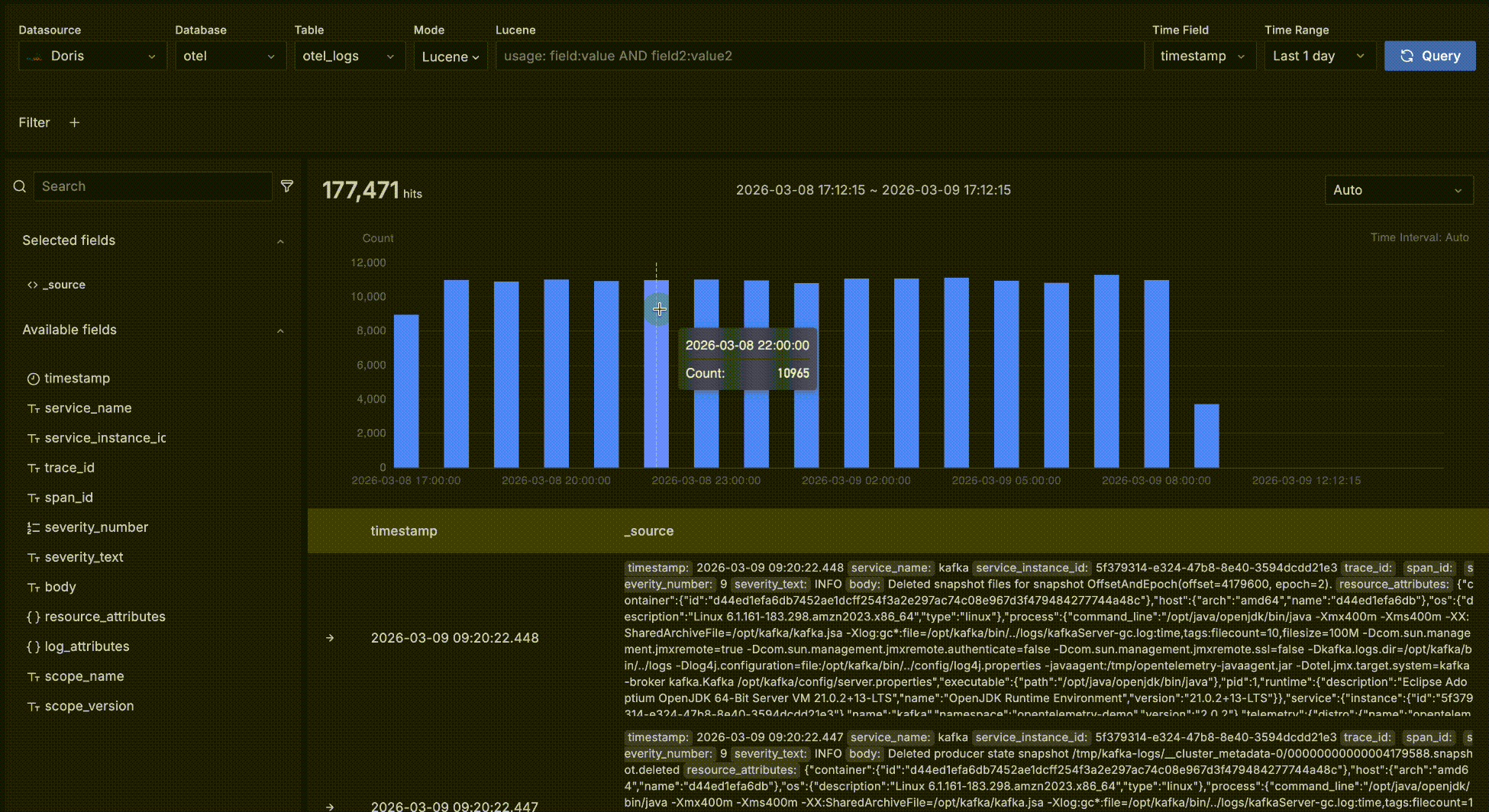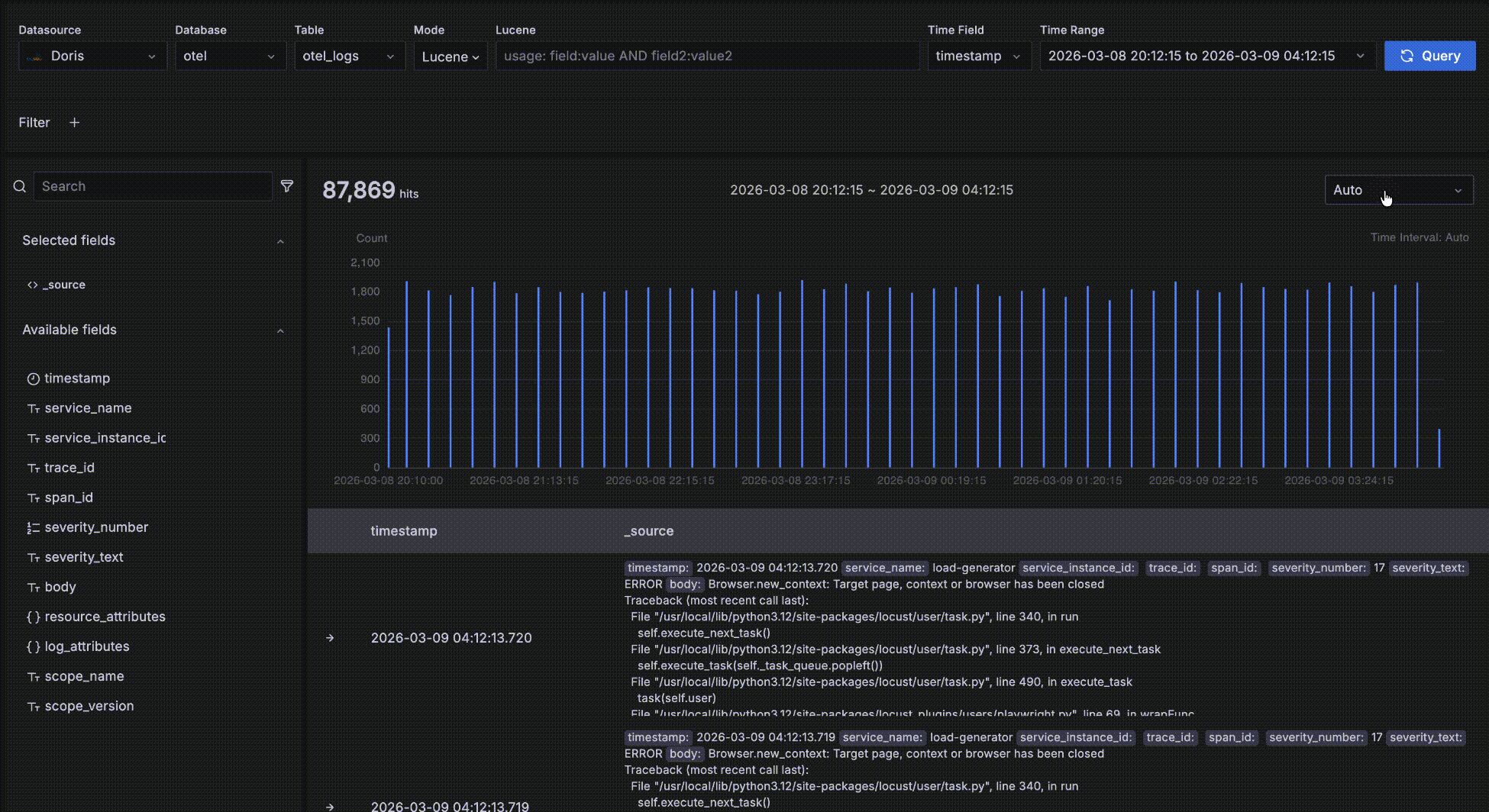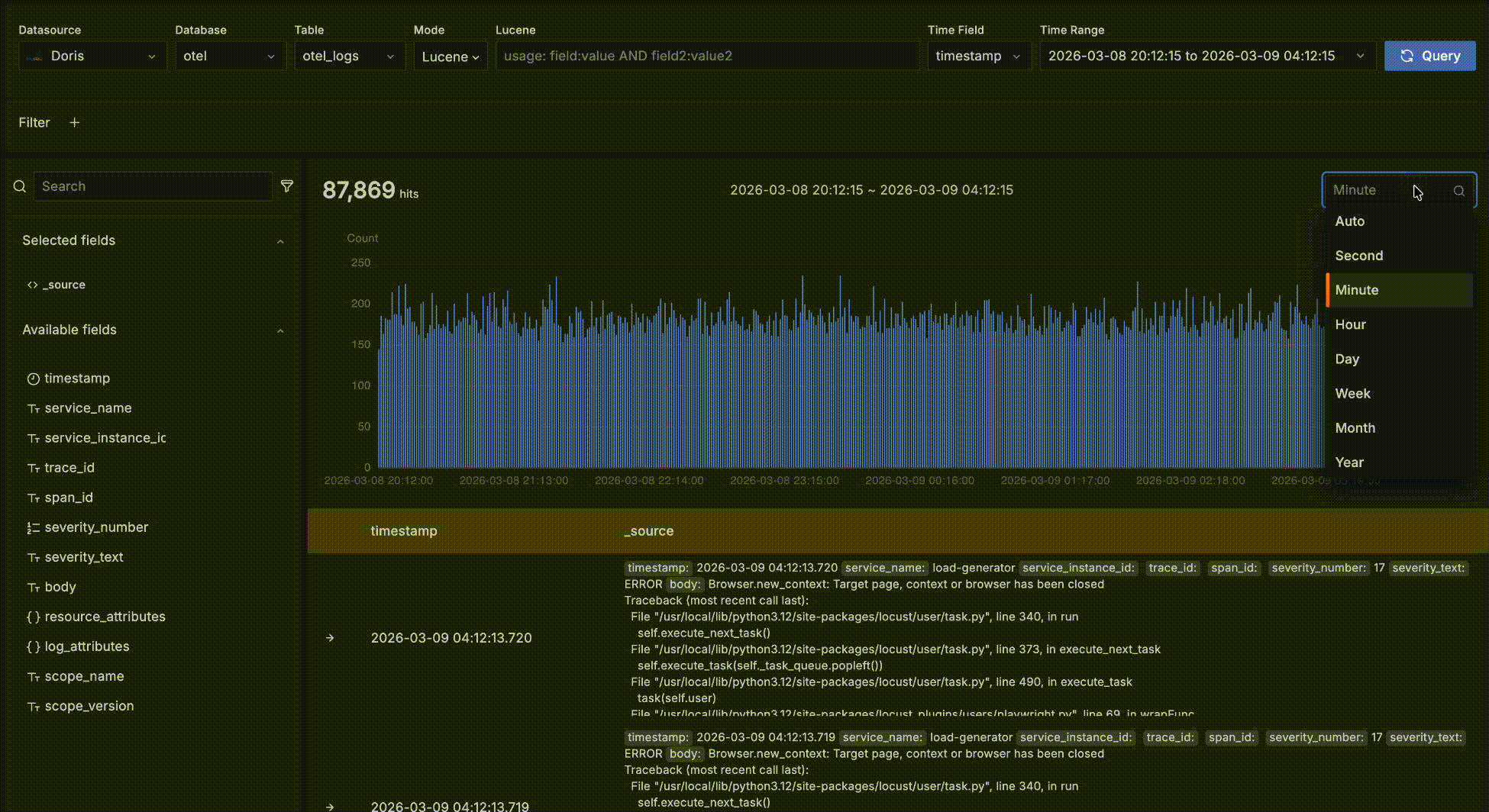
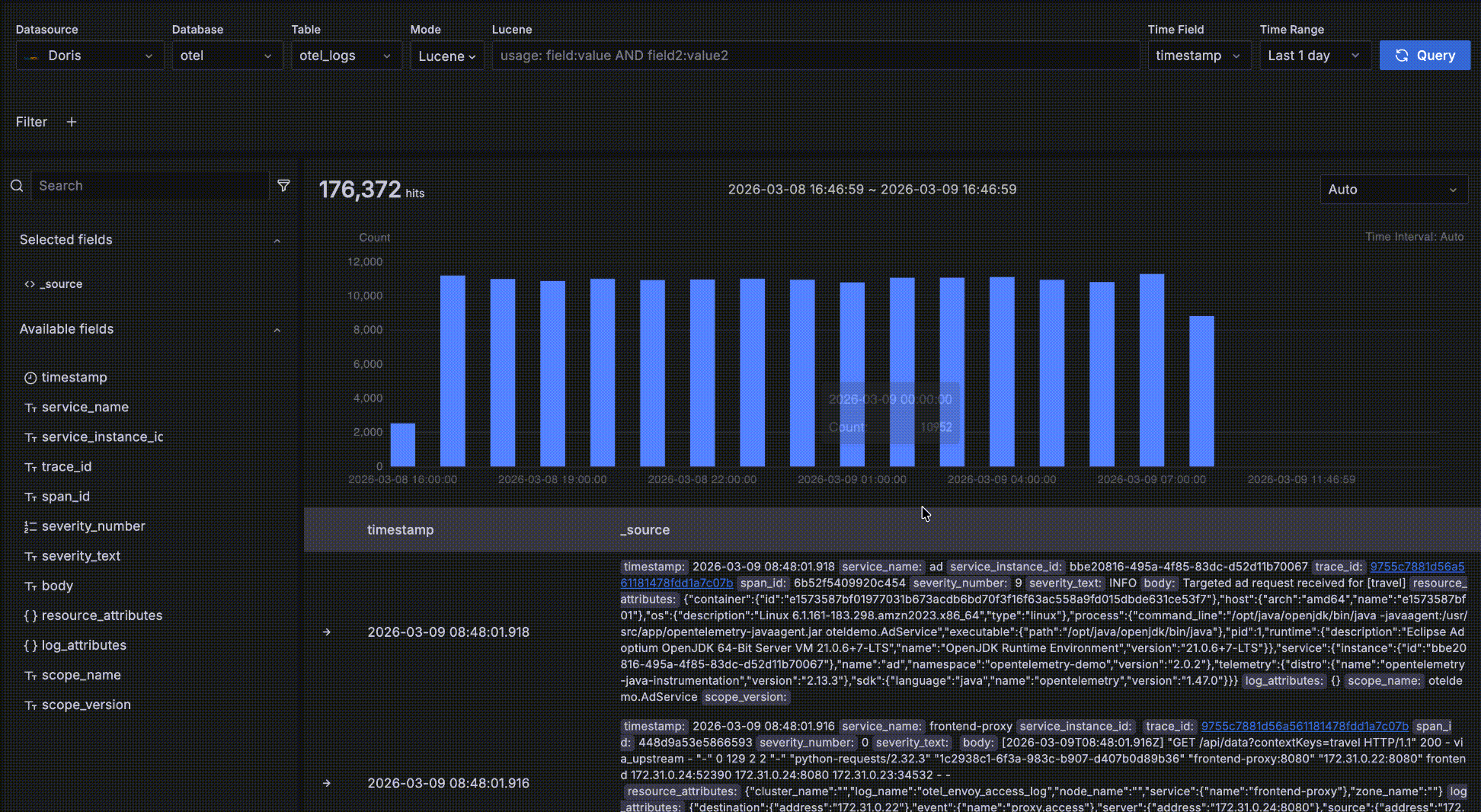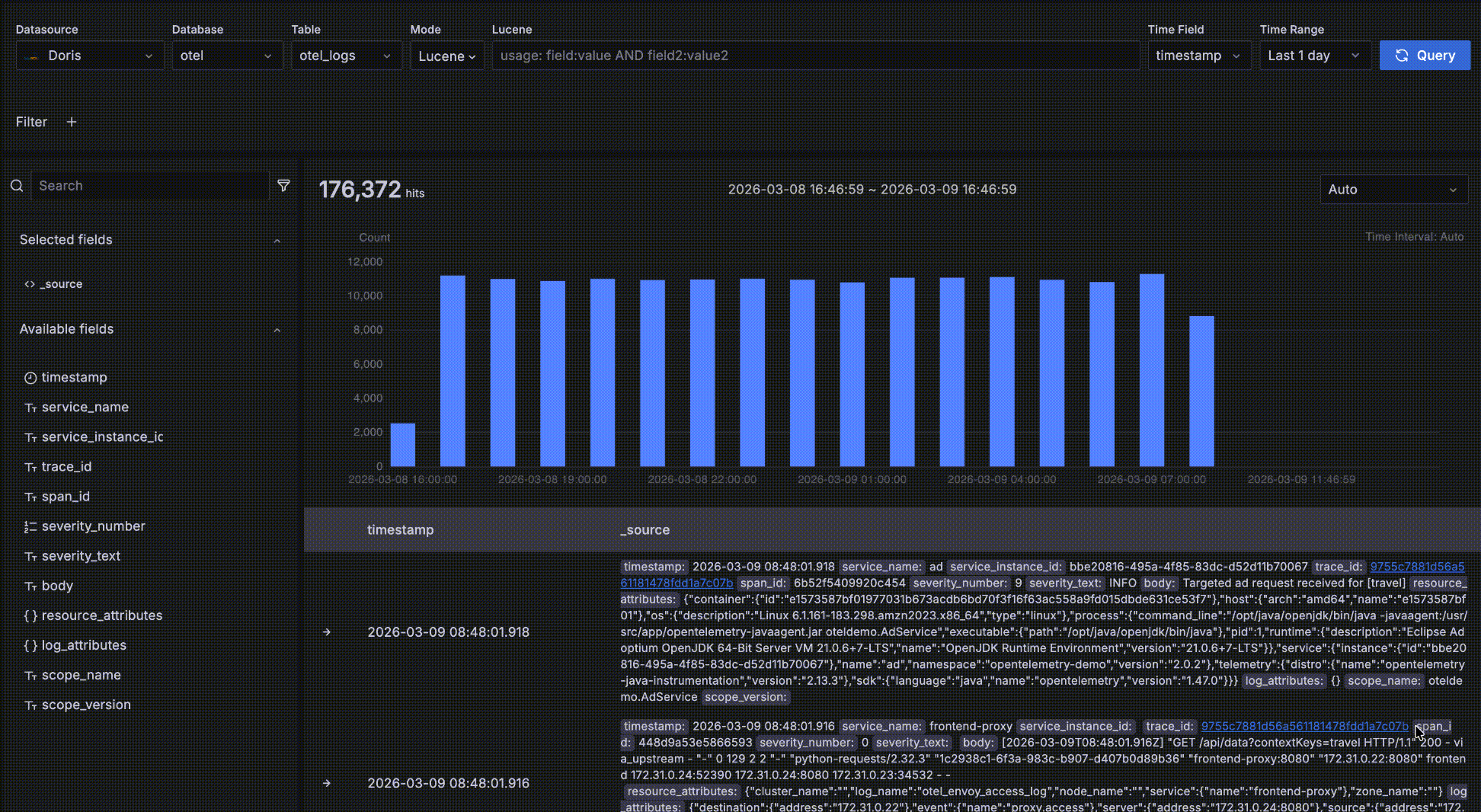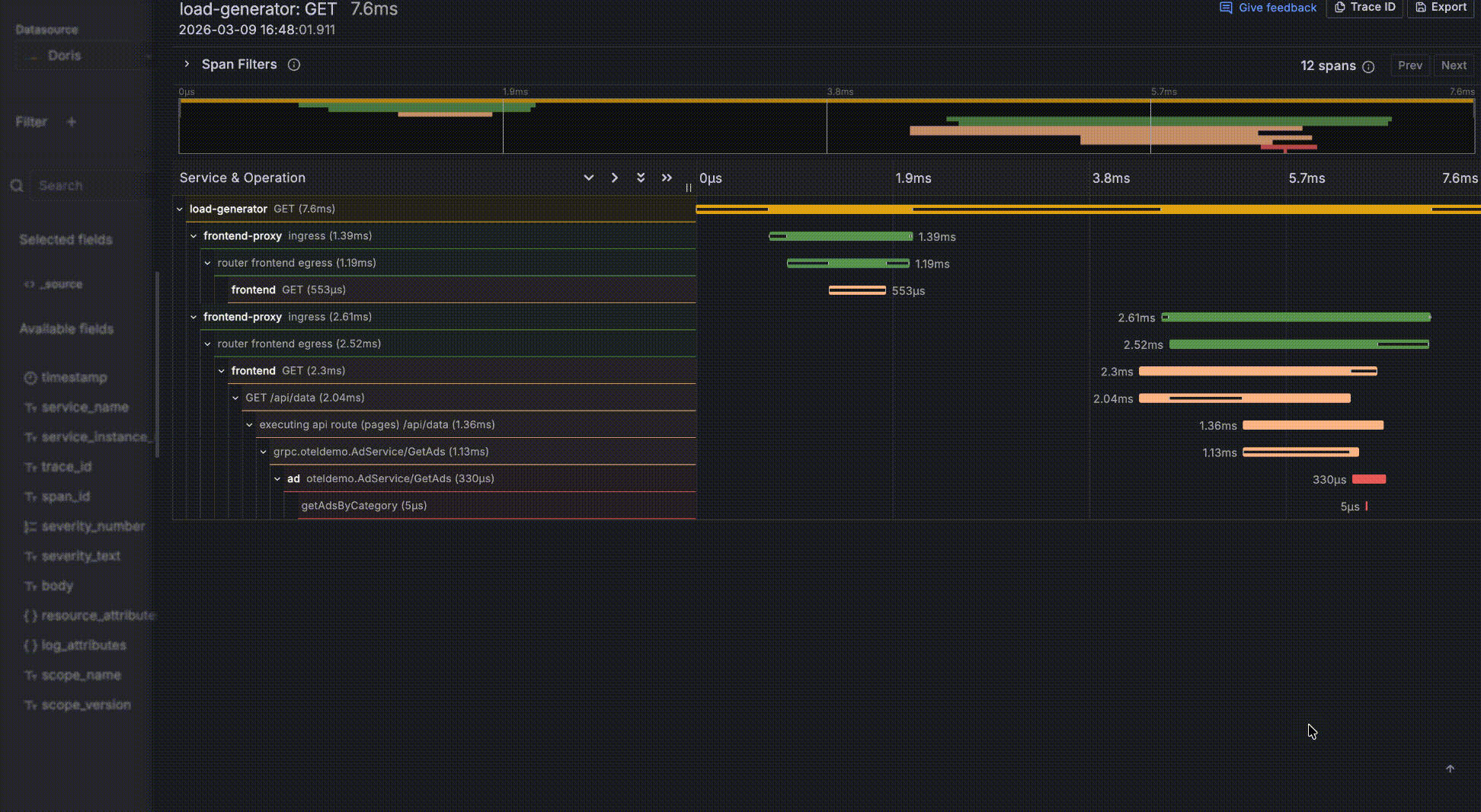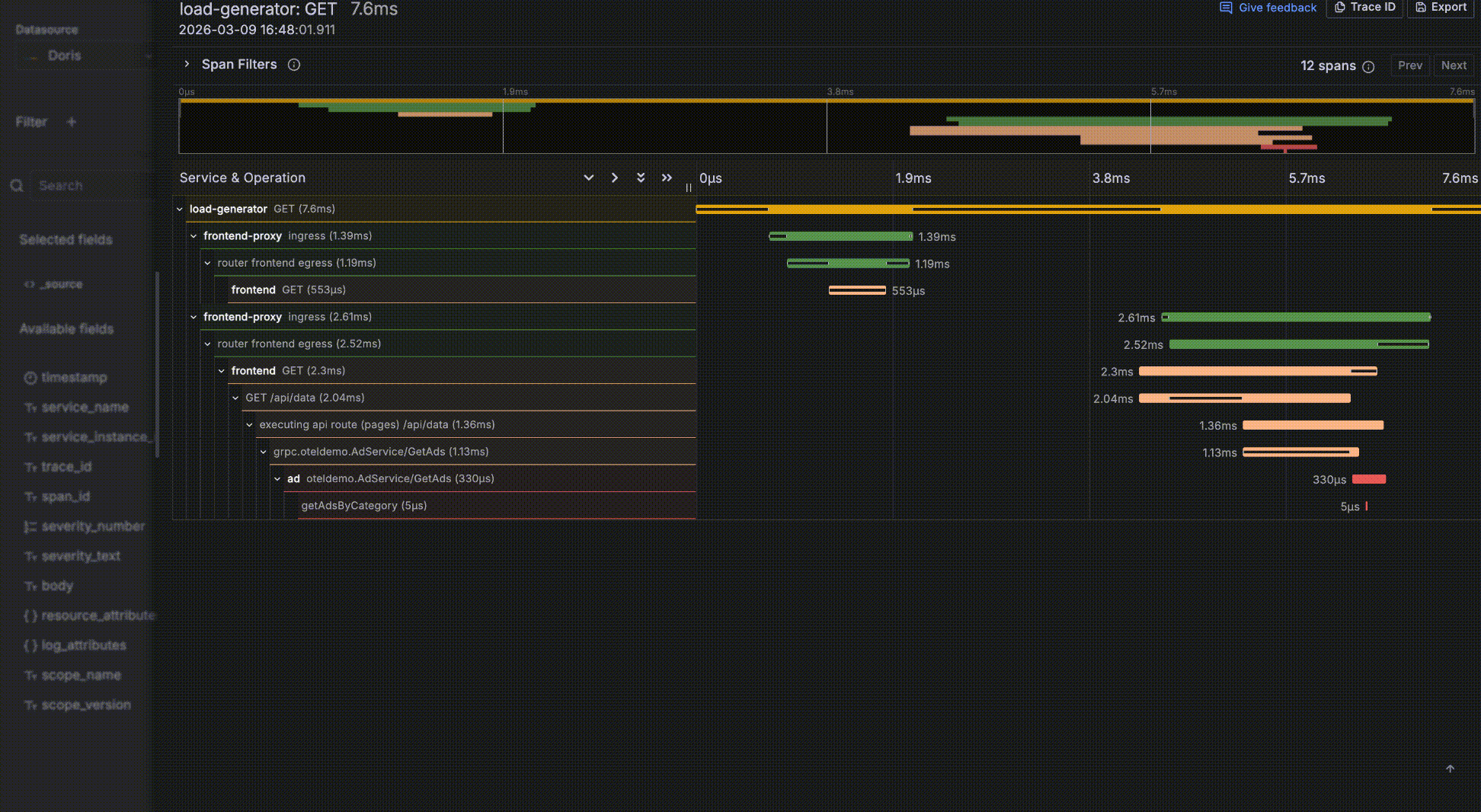
2. 時間トレンドエリア(中央)
クエリ結果の時間ベース分布を示すヒストグラム。機能には以下が含まれます:
- 一致するデータが時間経過でどのようにトレンドしているかを素早く観察
- 時間ウィンドウをドラッグ選択してクエリの時間範囲を変更
3. 詳細データエリア(下部)
文脈探索機能付きでクエリ結果の詳細レコードを表示。機能には以下が含まれます:
- 最新の一致レコードを表示;
trace_idが存在する場合、クリックでトレース詳細を表示 - 単一ログを展開してテーブル形式またはJSON形式ですべてのフィールドを表示
- テーブル形式からインタラクティブにフィルター条件を構築
- レコードの周辺データを表示
4. フィールドブラウザエリア(左側)
現在のテーブルのすべてのフィールドを表示し、フィールドレベルの探索を提供。
機能には以下が含まれます:
- 右側に表示するフィールドを選択;デフォルトでは
_source(すべてのフィールドの連結)を表示 - フィールドにホバーして頻出トップ5値とパーセンテージを表示
- 値の「+」または「-」をクリックしてインタラクティブにフィルター条件を構築し、上部のクエリバーと同期
クエリ入力
クエリ入力エリアで、ドロップダウンメニューを使用してデータソース、データベース、テーブル、時間フィールド、時間範囲を選択します。データソース、データベース、テーブルのデフォルトは設定ページで変更可能です;デフォルトの時間フィールドはテーブルの最初のDATETIMEまたはDATEカラムです。
検索入力ボックスはSQLとLuceneの両方の構文をサポートします — LuceneはSQL WHERE条件に内部的に変換されます。サポートされているLucene構文、Kibana、SQLの対応関係は以下の通りです。
| 機能 | Doris App Lucene構文 | Kibana | SQL WHERE | 注記 |
|---|---|---|---|---|
| 単一フィールドキーワードマッチ | service_name:kafka | 同一 | service_name MATCH 'kafka' | 完全フィールドマッチ、service_name MATCH_ANY 'kafka'に書き換え |
| 横断フィールドキーワードマッチ | error | 同一 | (service_name MATCH 'error') OR (scope_name MATCH 'error') | すべての転置インデックスフィールドでの全文マッチ、複数フィールドMATCH_ANYとして自動書き換え |
| 単一フィールドフレーズマッチ | service_name:"kafka logs" | 同一 | service_name MATCH_PHRASE 'kafka logs' | フィールドレベルのフレーズマッチ |
| 横断フィールドフレーズマッチ | "kafka logs" | 同一 | service_name MATCH_PHRASE 'kafka logs') | 完全フレーズマッチ、MATCH_PHRASEに書き換え |
| ワイルドカード | kaf* | 同一 | ((service_name MATCH_PHRASE_PREFIX 'kaf') OR (scope_name MATCH_PHRASE_PREFIX 'kaf')) | プレフィックス/サフィックスワイルドカード、MATCH_PHRASE_PREFIXに書き換え |
| 数値/時間範囲 | duration:[100 TO 500] | 同一 | duration BETWEEN 100 AND 500 | SQL BETWEENに変換 |
| 無境界範囲 | duration:>500 | 同一 | duration > '500' | SQL比較に変換 |
| 開/閉区間 | {100 TO 200} | 同一 | 中括弧は開区間を表す | |
| AND組み合わせ | service_name:kafka AND status:failed | 同一 | (service_name MATCH 'kafka') AND (status MATCH 'failed') | 論理AND |
| OR組み合わせ | error OR warning | 同一 | 論理OR | |
| NOT組み合わせ | NOT kafka or -kafka | 同一 | NOT (service_name MATCH 'kafka') | 論理NOT |
| グループ化 | (service_name:kafka OR service_name:zookeeper) AND status:failed | 同一 | ((service_name MATCH 'kafka') OR (service_name MATCH 'zookeeper')) AND (status MATCH 'failed') | 複雑な論理組み合わせをサポート |
Lucene構文の重要なポイント:
- 基本形は
field_name:match_conditionです。 field_name:は単一フィールドをmatch_conditionに対してマッチさせます。field_name:なしでは、単純なmatch_conditionはいずれかのフィールドがマッチすればマッチします(フィールド間のOR)。- テキスト値の場合、
match_conditionは3つの形式があります:- ダブルクォートで囲まれた条件はフレーズマッチを表します — すべての単語がクォート内と同じ順序で出現する必要があります。
- クォートなしの条件はキーワードマッチを表します — いずれかの単語がマッチできます。
*はワイルドカードを表します。
- 数値と日付値の場合、
match_conditionは3つの形式があります:- 単一値は等価を表します。
>、<はSQLと同様に範囲を表します。- 括弧は区間を表します — 角括弧は閉区間、中括弧は開区間です。
- 複数の条件はSQL同様にAND / OR / NOTで組み合わせできます。括弧はグループ化の優先順位を調整します。
SQL構文の重要なポイント:
MATCHとMATCH_ANYはLuceneキーワードマッチに対応します — いずれかのキーワードがマッチします(OR関係)。MATCH_ALLもキーワードマッチですが、すべてのキーワードがマッチする必要があります(AND関係)。MATCH_PHRASEはLuceneフレーズマッチに対応します — 同じ順序のすべての単語。- 等価と範囲クエリは標準の
=、>、<、BETWEENを使用します。 - 複数の条件はAND / OR / NOTで組み合わせでき、括弧で優先順位を調整できます。
時間トレンドデータ
以下に示すように、赤いボックス内のエリアは時間トレンドデータエリアです。これは一致するデータの数と時間経過のトレンドを素早く確認するためのものです。いくつかのインタラクションが利用可能です:
- バーにホバーして、時間バケットの開始時刻とその中の一致データ数を表示。
- トレンドチャート上でドラッグ選択してクエリの時間範囲を変更。
- バケット長はデフォルトで
Autoで、全体の時間範囲にスケールされます。ドロップダウンから秒、分、時間などの異なる粒度を選択することも可能です。
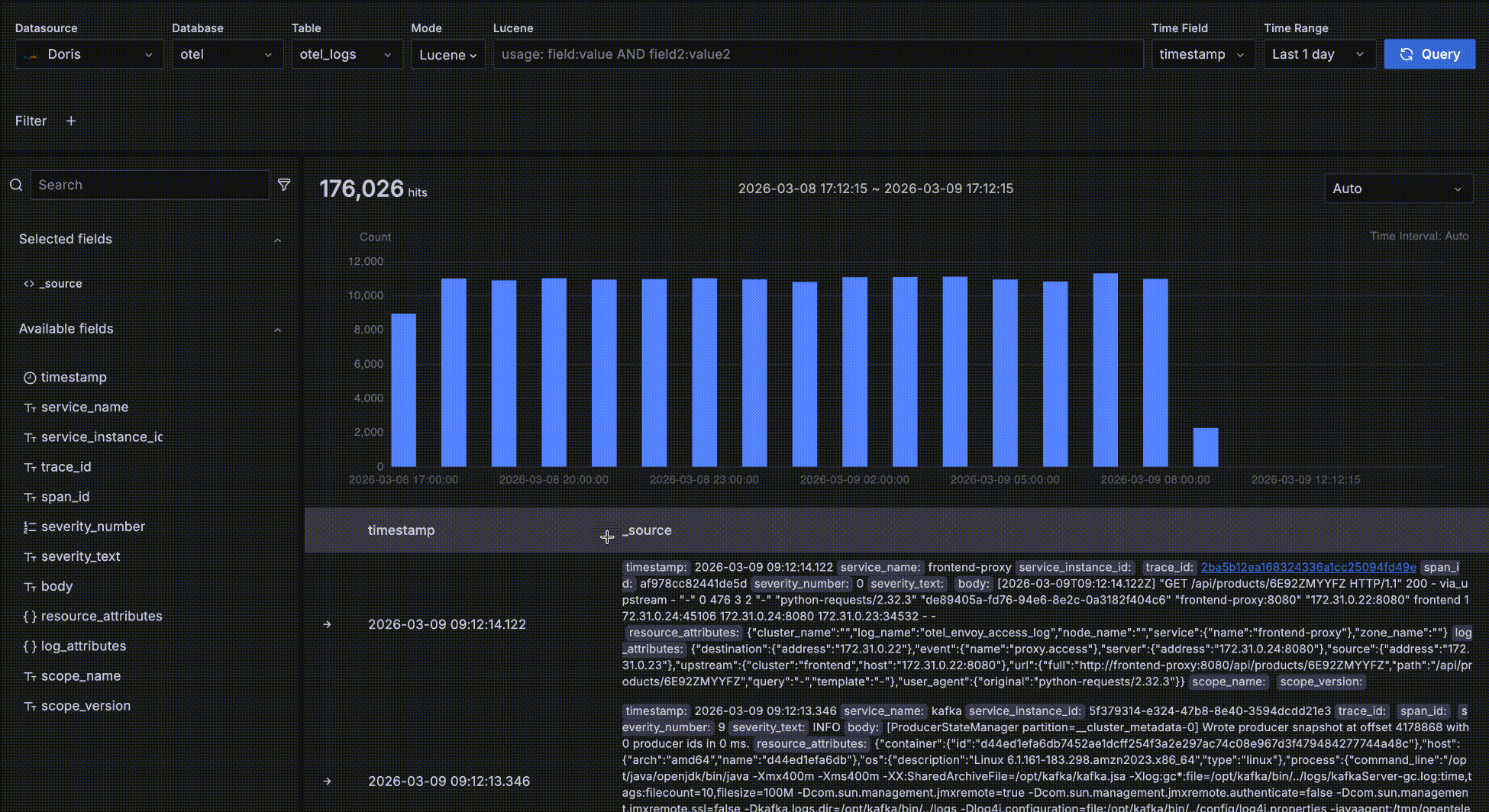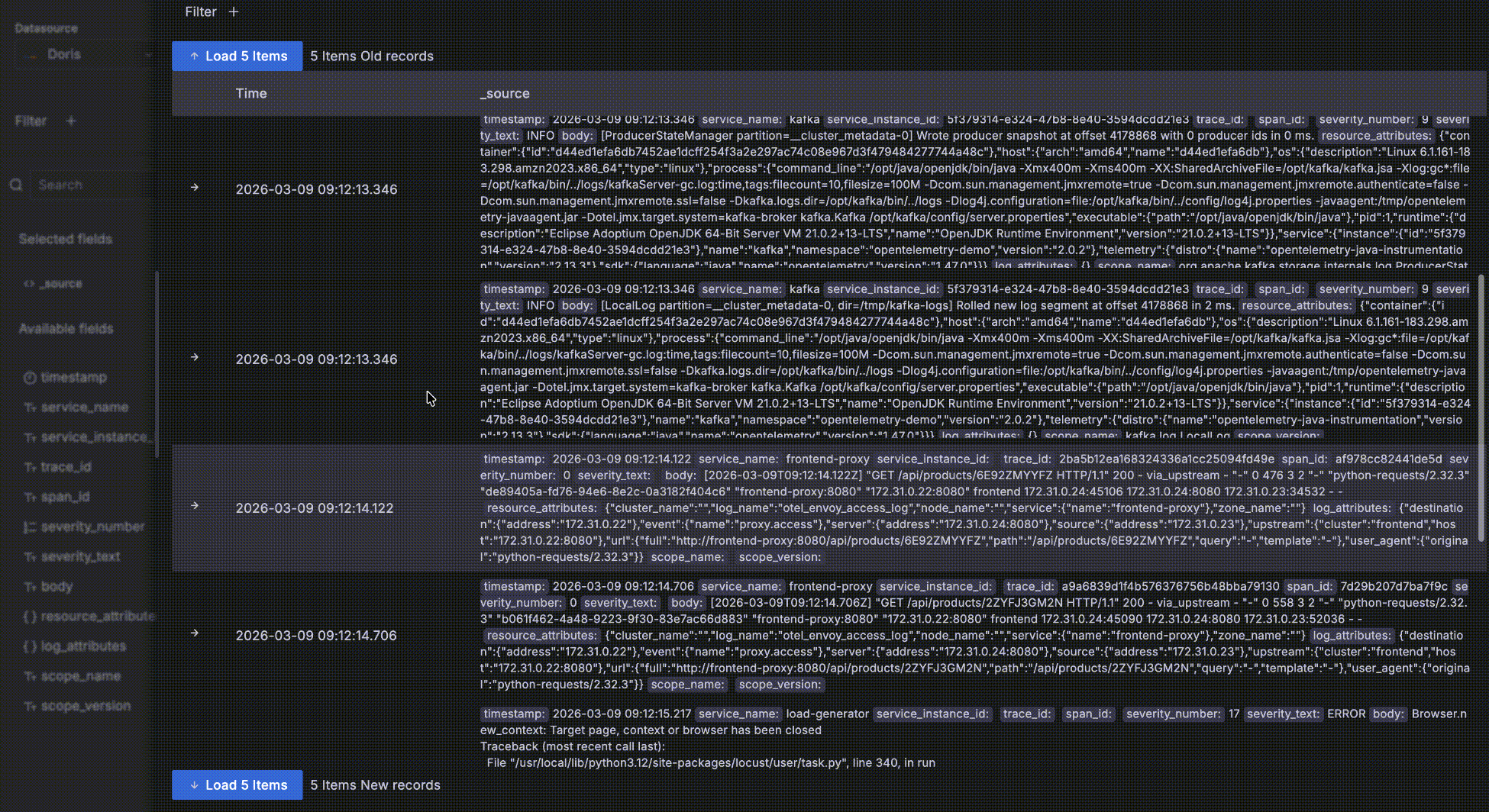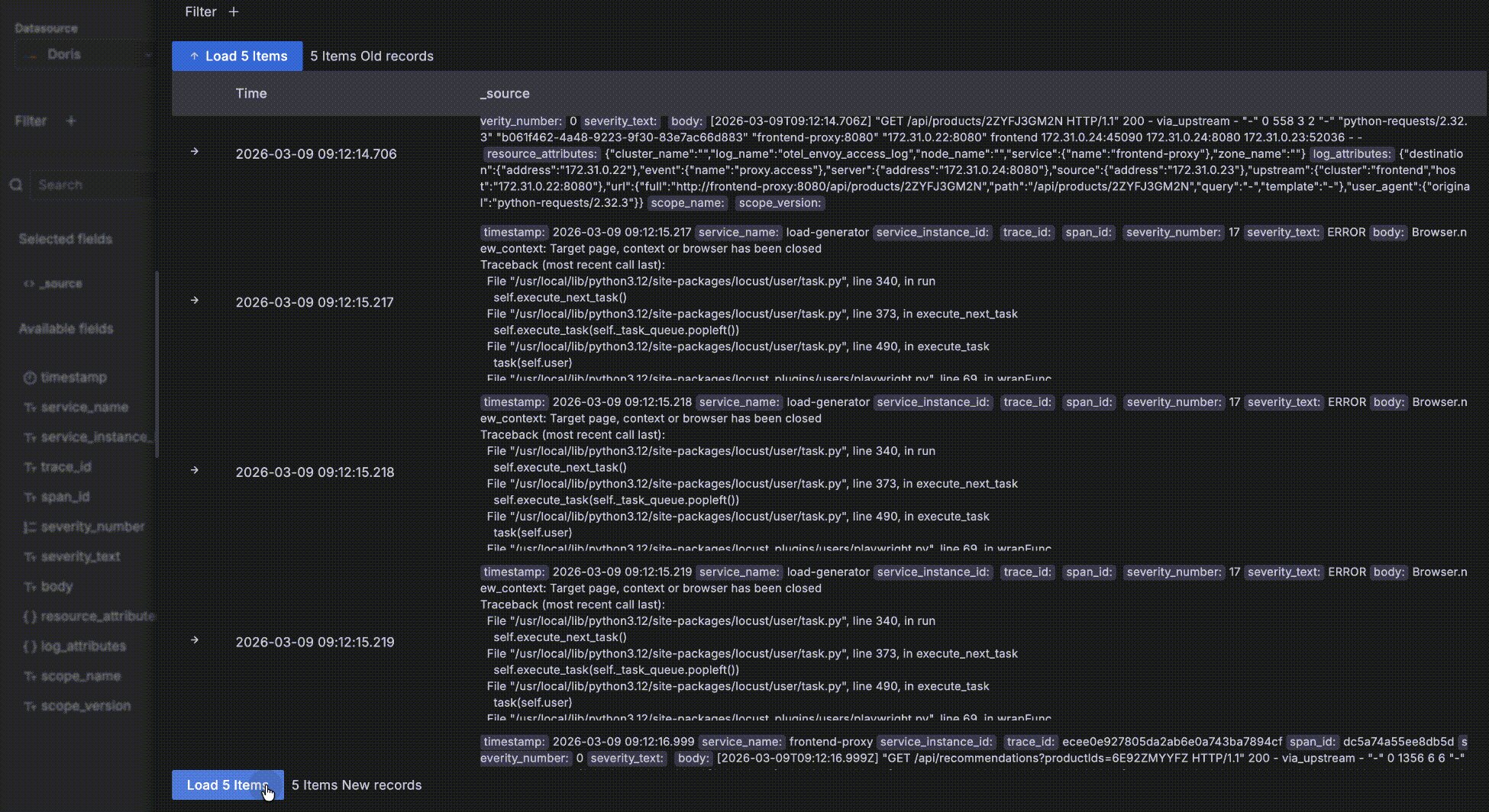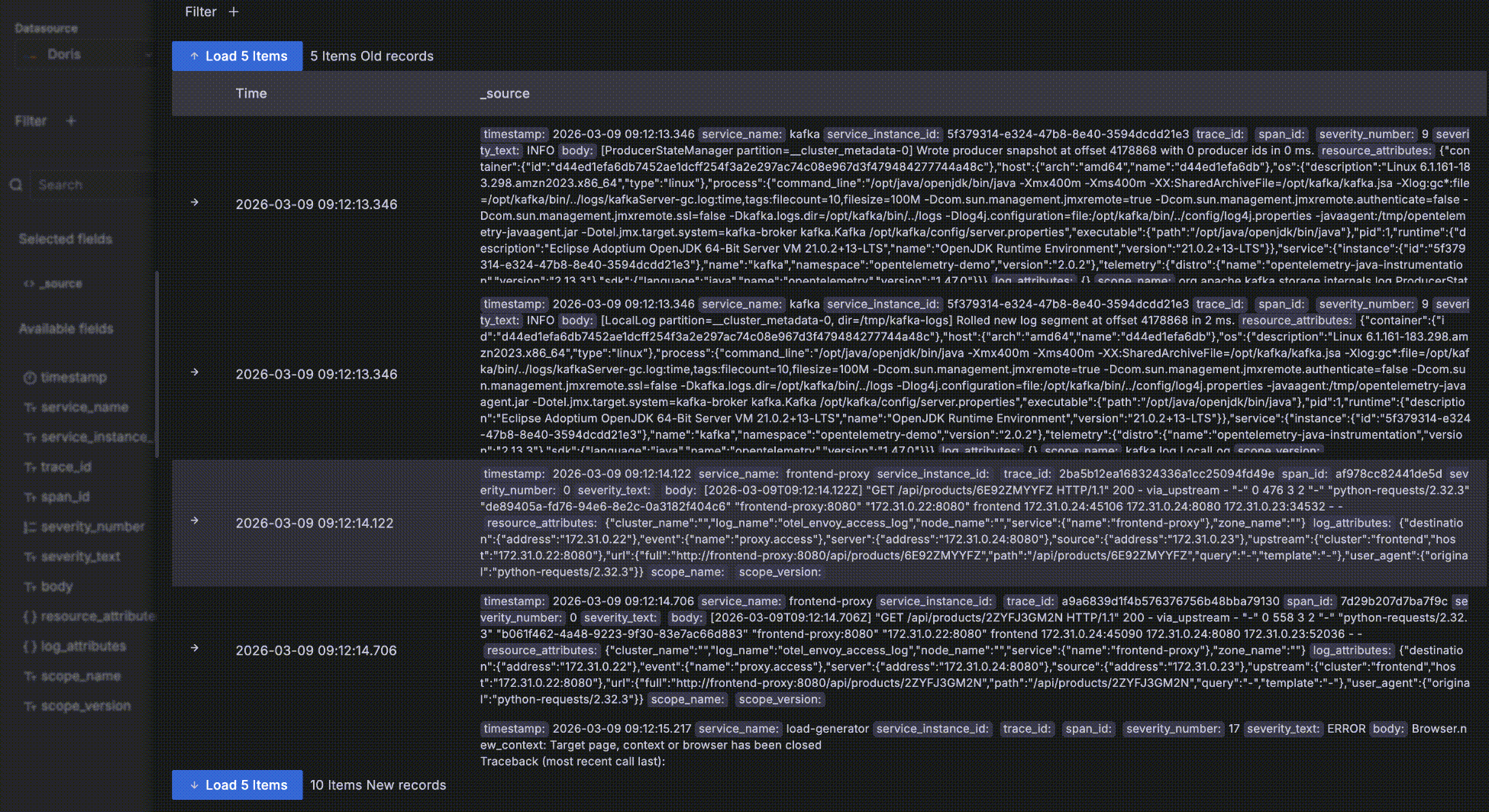
詳細データ
以下に示すように、赤いボックス内のエリアは詳細データエリアで、クエリ条件に一致するレコードを表示します。
- レコードは時間フィールドで降順にソートされ、最新のデータが最初に表示されます。各ページは50レコードを表示し、さらに多くを表示するためにページネーションできます。デフォルトで2つのフィールドが表示されます:時間フィールドと
_sourceです。_sourceはすべてのフィールドの仮想的な連結で、可読性のためにキーがハイライトされたkey: valueペアとして表示されます。左側のフィールドブラウザでフィールド名の隣の「+」をクリックして、右側に表示するフィールドをカスタマイズできます。複数のフィールドを追加でき、右側の「x」をクリックして削除できます;すべてのフィールドが削除されるとデフォルトの_sourceにフォールバックします。
- 最左端位置の「->」矢印をクリックしてレコードの詳細を展開します。TableとJSONの2つの形式があります。Table形式では、フィールドの隣の「+」または「-」をクリックして
severity_text=INFOなどのフィルター条件をインタラクティブに追加できます。
- レコードを展開後、Surrounding itemsをクリックしてそのレコードの「コンテキスト」— 時間的にその前後5レコードを表示します。この機能は問題分析中に特定のログ周辺のログを調査するために一般的に使用されるため、時間以外の他のクエリフィルター条件は無視されます — そうでなければ詳細データテーブルと同じ動作になります。もちろん5レコード以上の周辺レコードを表示し、特定のホストに制限するなどの独自フィルターを追加できます。
- レコードに
trace_idフィールドがある場合、関連トレースとして認識されます。値はクリック可能なリンクになり、クリックするとログからトレースへの相関のためにトレースウォーターフォールドロワーが開きます。
フィールドブラウザ
左側のフィールドブラウザは現在のテーブルのフィールドを調査し、その値分布を分析できます。
- フィールドの右側の「+」をクリックして詳細データテーブルに追加します。
- フィールド名をクリックして頻出トップ5値を表示し、値の隣の「+」/「-」をクリックして動的にフィルター条件を追加します。