Installation and Deployment
Introduction
X2Doris is a tool developed by VeloDB for migrating all kinds of off-line data to Apache Doris/VeloDB. The tool integrates automatically create Doris tables and data migration. At present, it supports Apache Doris, Hive, Kudu and StarRocks database migration to Doris or VeloDB Cloud, the whole process of visual platform operation, very easy to use. Reduce the difficulty of synchronizing data into Doris or VeloDB Cloud.
Installation and Deployment
1 Installation requirement
A machine that is ready to deploy X2Doris must ensure a valid network policy: the source to be migrated and the destination written Doris/VeloDB Cloud have to ensure network connectivity.
2 Choose packages
The implementation of X2Doris is based on Spark, and it is recommended to deploy to Hadoop, Yarn big data environment, this can make full use of the cluster capacity of big data, which can greatly improve the efficiency and speed of data migration . If you don't have a big data environment, you can also choose to deploy a version with Spark on your own machine.(Don't install a pseudo-distributed Hadoop cluster if you don't already have one.)
2.1 With a Spark environment
Go to the jars directory of your spark installation and see the Scala version of the package, as follows: spark-yarn_2.12-3.2.4.jar, where 2.12 is the Scala version.
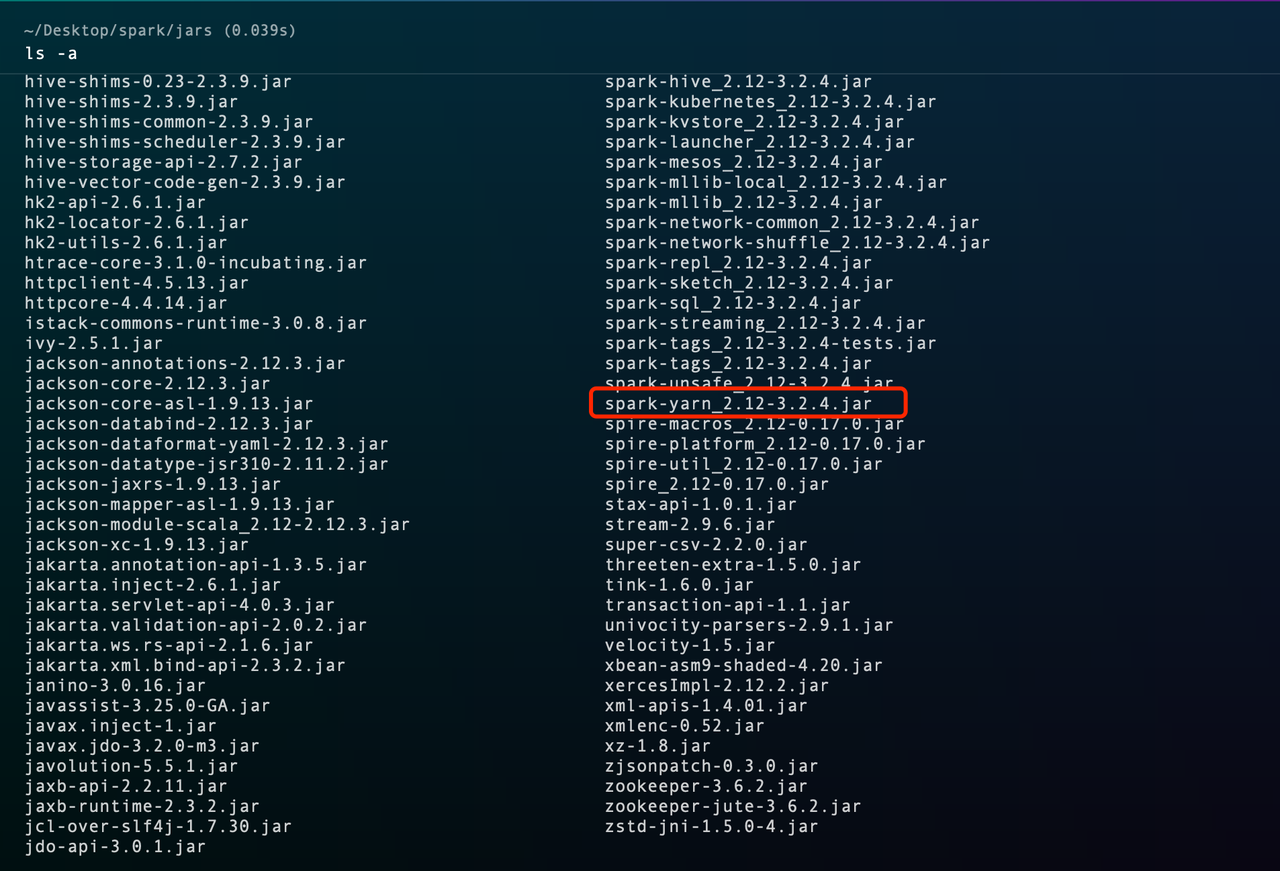
You can download the X2Doris package corresponding to the Scala version, with the filename of the X2Doris package containing the Scala version, as follows: velodb-x2doris_ 2.12-1.0.0-bin.tar.gz is the Scala 2.12 equivalent.
2.2 Without a Spark environment
You can choose the X2Doris package for Scala 2.12.
3 Untar the package
tar -xzvf velodb-x2doris_2.12-1.0.0-bin.tar.gz
4 Initialize the metadata
4.1 Change the system's database type tomysql
To enter the conf directory and modify the application.yml file, change spring.profiles.action from h2 to mysql. Please note that the default h2 database is an in-memory database, which may result in data loss after system restart.
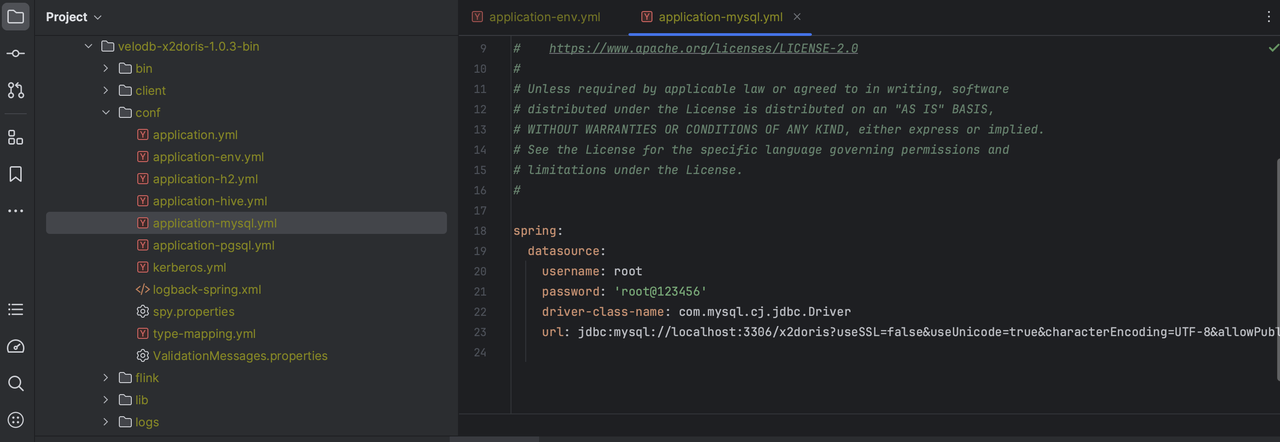
4.2 Modify conf/application-mysql.yml file, specifies MySQL connection information
4.3 Run Script
Go to the script directory: there are two directories called schema and data
-
Initialize the table structure by running
mysql-schema.sqlunderschema -
Then run
mysql-data.sqlunderdatato initialize the metadata
PostgreSQL operations are similar to MySQL, so we won't repeat it here.
The default database used is h2, and the data will be cleared after restarting!
5 Authentication related configuration
5.1 Kerberos
If your Hadoop cluster has kerberos authentication enabled (you can skip this step if you don't have it), you need to configure the Kerberos information by editing conf/kerberos.yml :
enable: true #Enable the Kerberos switch
principal, krb5, keytab need to be filled in with the actual paths.
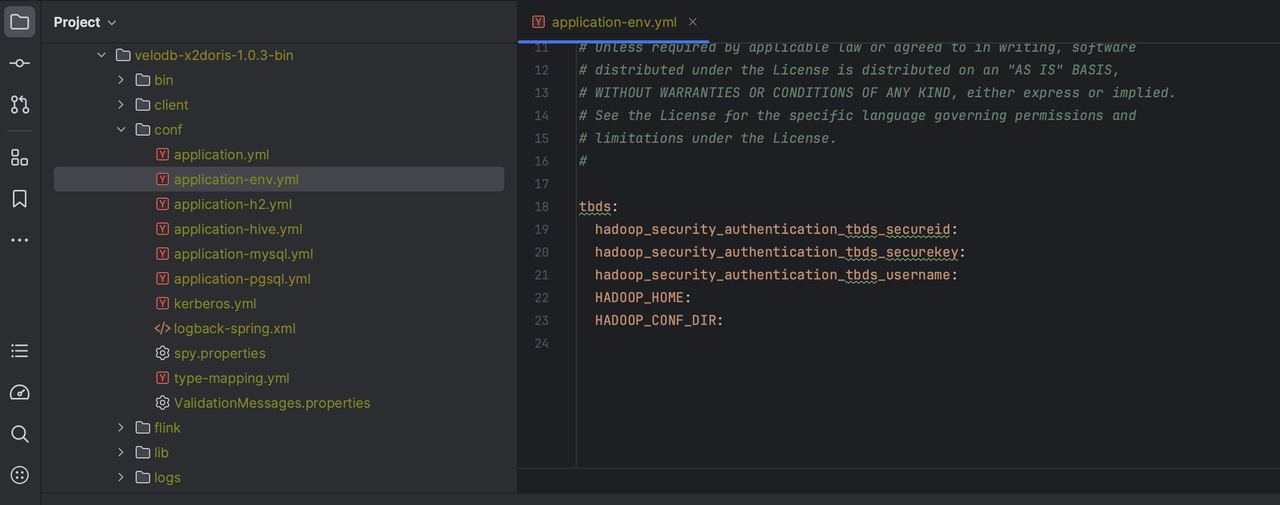
5.2 tbds
tbds is Tencent cloud big data cluster. If it is not tbds, just skip it. Edit conf/application-env.yml and fill in the following information:
Get Started
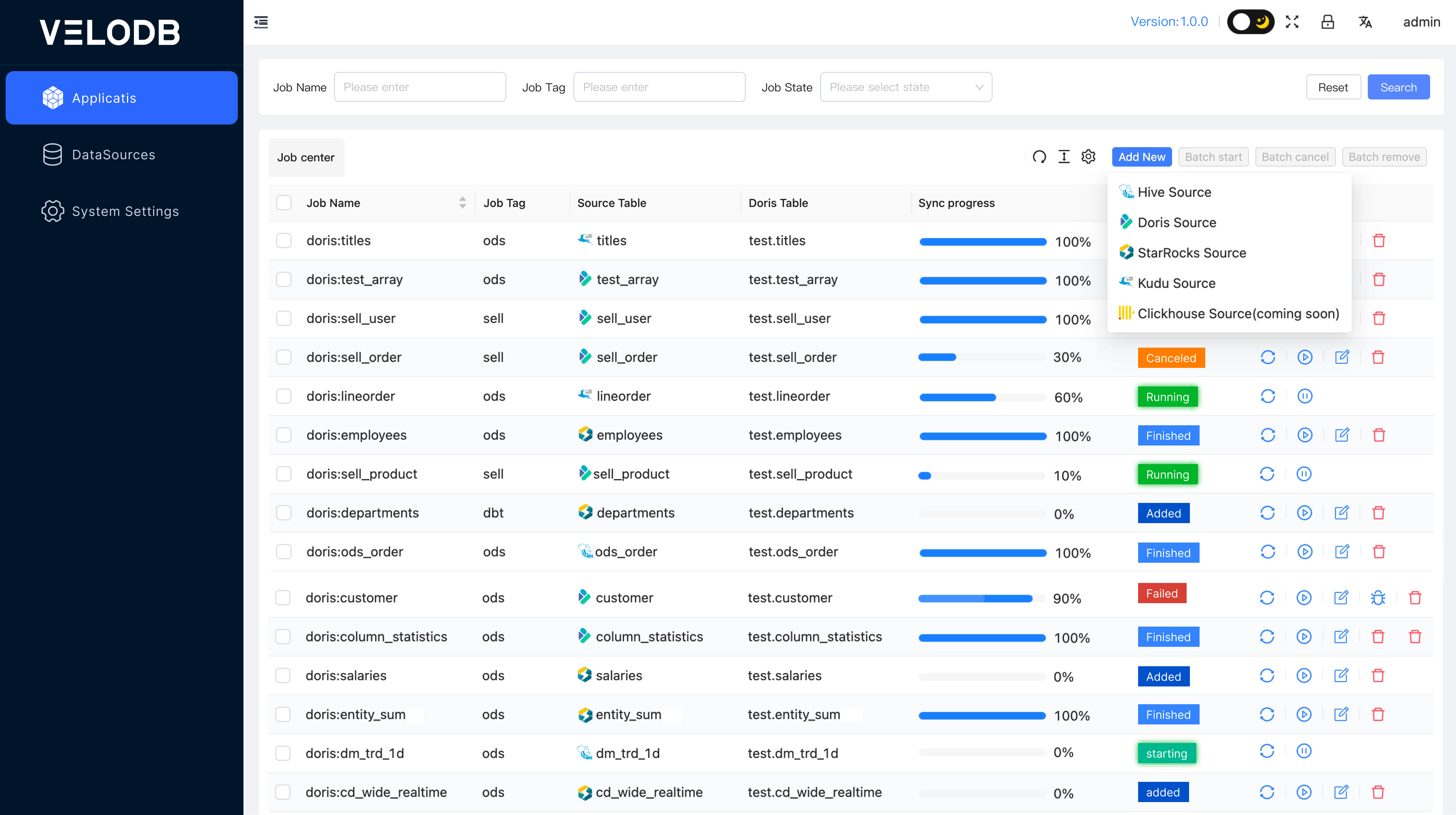
Startup
With everything in place, go to the bin directory and run startup.sh
Login platform

The default URL is http://$host:9091. This can be changed in application.yml. The default username and password are: admin/admin, you can modify them in the main interface after logging in.