WebUI Guide
VeloDB Enterprise WebUI ("WebUI") is a data development platform for data development scenarios, which can assist you in managing and exploring data, and can replace Navicat.
Main Function
- Login : Use different database users to log in to the cluster in the WebUI.
- Data : View and manage data in the database, currently supports viewing.
- Query :
- SQL Editor : An easy-to-use SQL query editor that supports query execution, viewing query history and saving queries.
- Log analysis : A user-friendly analysis tool designed for log scenarios, supporting features like SQL filtering, searching, and more.
- Session Management : Manages running SQL queries, allowing users to view and kill SQL queries;
- Query Audit : A one-stop query history auditing tool, capable of filtering slow queries and viewing their profiles.
- Workload Management : Supports quick creation, editing, and viewing of Workload Groups.
- Privilege : Manage users and roles in the database, and grant and revoke permissions to them.
- Import : Support the view of import tasks and operate on import tasks.
Register and Login
Using the WebUI service
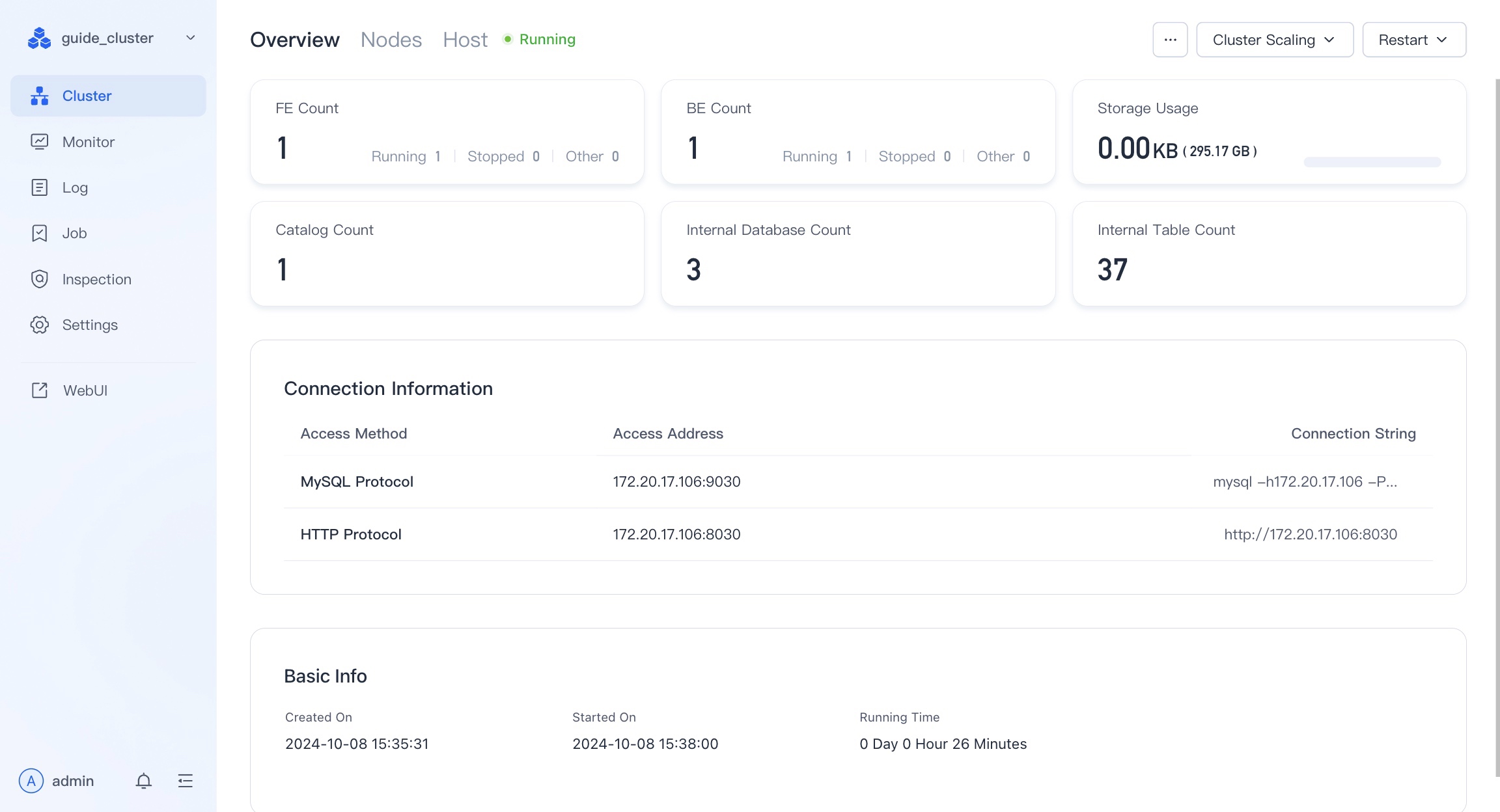
In VeloDB Manager, if you have deployed VeloDB-Doris, you can find the entrance to the WebUI in the left sidebar menu.
Sign in to WebUI
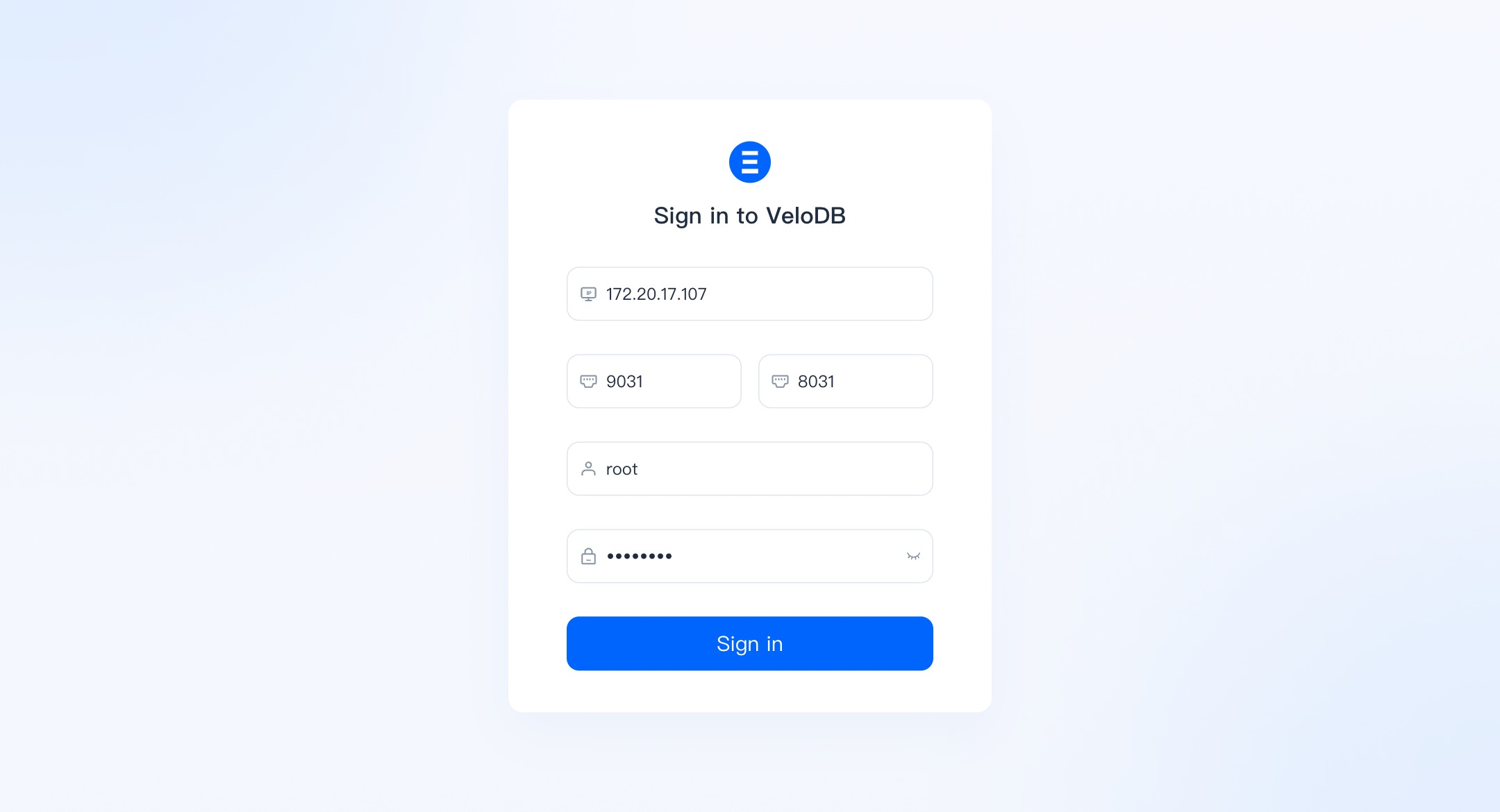
You need to enter the FE IP,FE JDBC Port,FE HTTP Port,Username and Password .
If you click the link to sign in from Manager, the FE IP, FE JDBC Port, FE HTTP Port should be pre-filled.
The username and password for logging into the WebUI are the same as those for the database. If you forget the root or admin password for the cluster, you can modify it in the settings module of the cluster.
We will not record your login account and password, but you can use the recording function that comes with your browser.
Data
The "data" module is the basic function of WebUI to manage the database, and it mainly has two functions:
1、 Check the data and its organizational form, such as database table structure, data size, table creation statement, table field information, data preview, etc.
2、 Add, delete and modify data, including creating and deleting database objects, modifying storage strategies, etc. This part of the functionality is still being implemented and is temporarily unavailable.
The data module is displayed according to the organizational form of the data in the database, and is divided into Catalog -Database -Table /View .
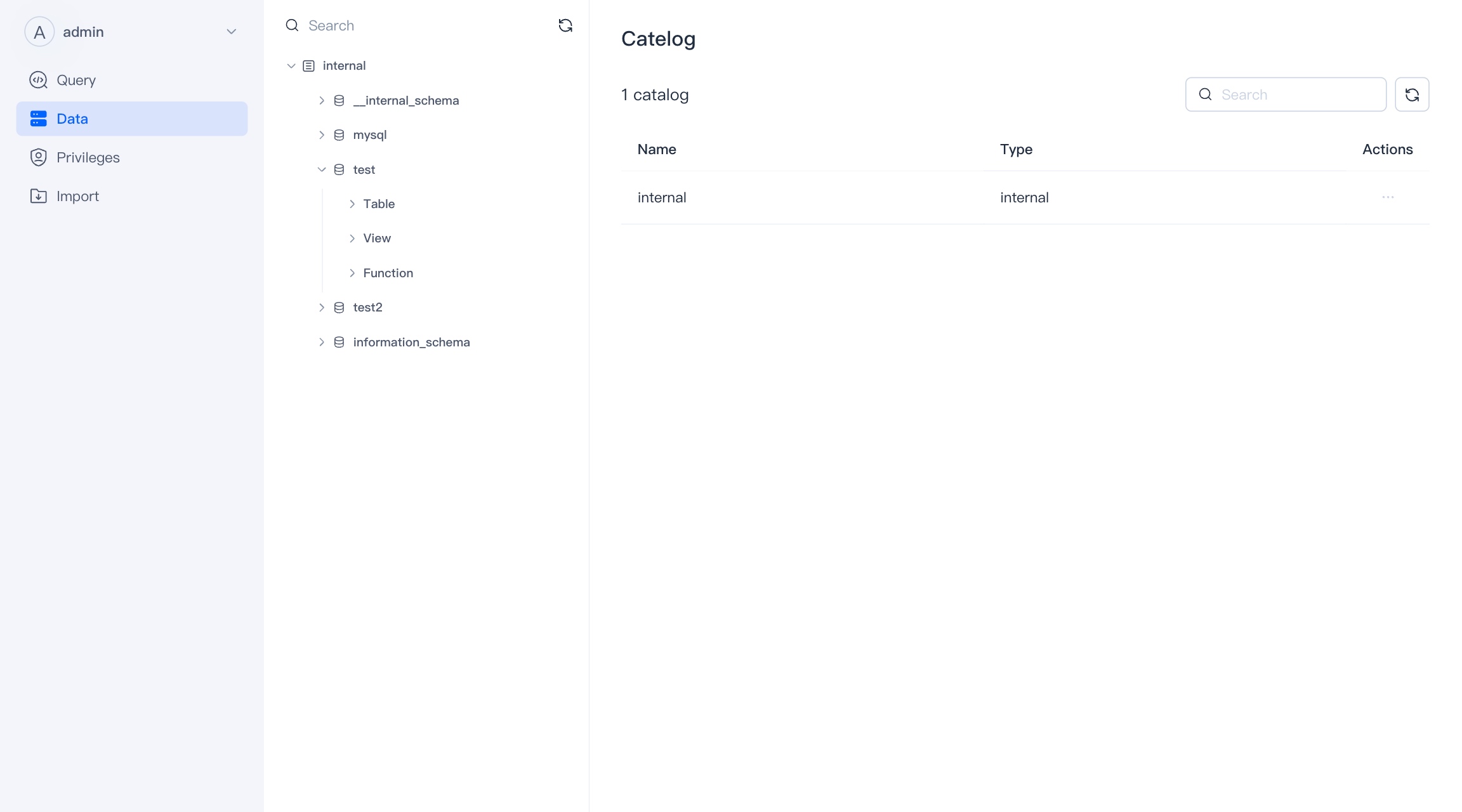
Catalog
Catalog is a collection of databases.
Catalog is divided into internal catalog and external catalog. Internal catalog contains Doris's own database, external catalog can connect to Hive, Iceberg, Hudi, etc. and perform queries.
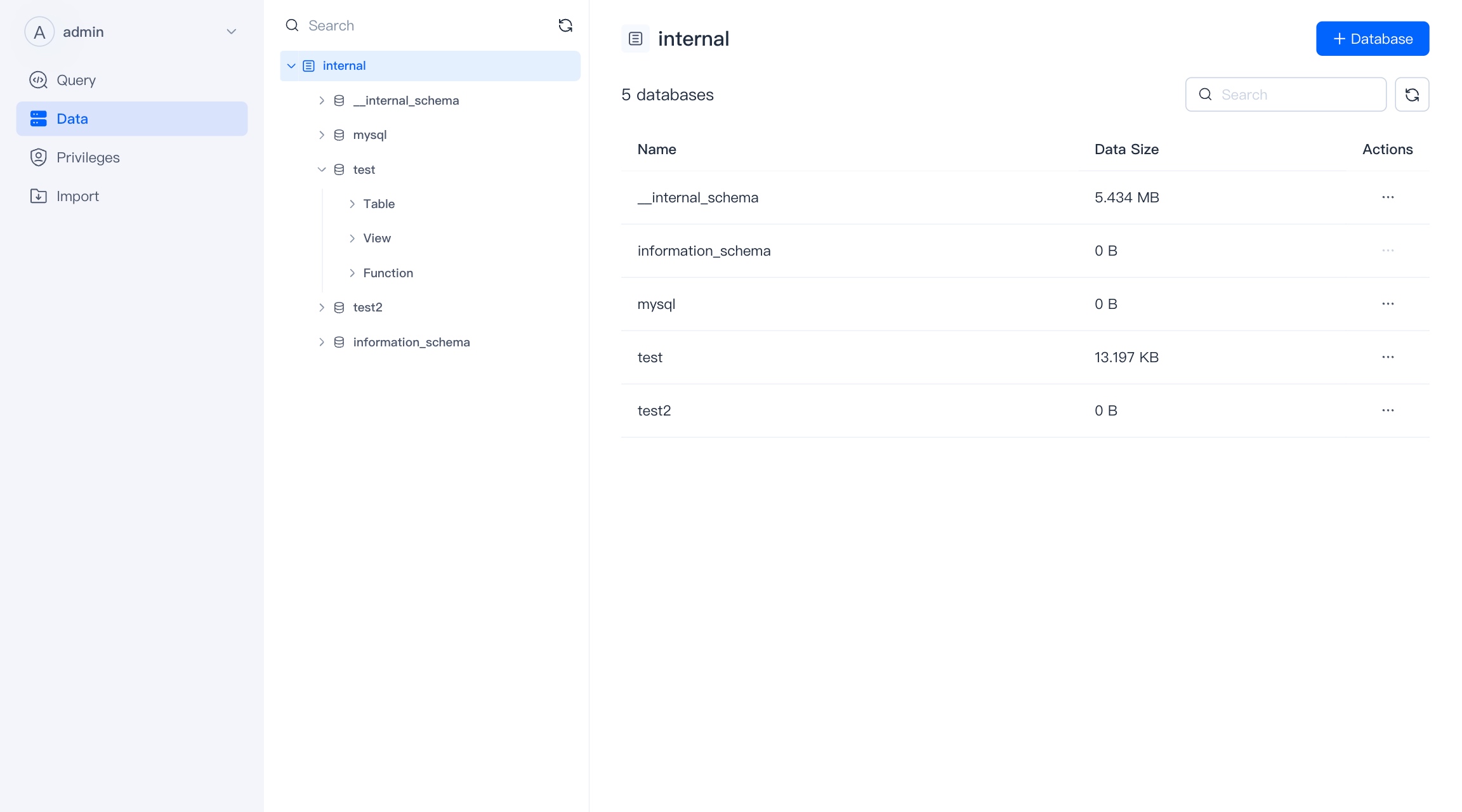
Database
Database is a collection of tables and views. Database belongs to catalog.
When you select a directory, you can view the database under the directory, as well as the size of the database and the modification time. At the same time, you can delete and create new databases.
Table
Table is the basic unit of VeloDB data warehouse, and table belongs to database.
When a database is selected, you can see the tables under the database, as well as the size of the table, creation and modification time.
In the current version, you can delete the table, and in the future version, you can create the table and manage the life cycle of the table in the WebUI.
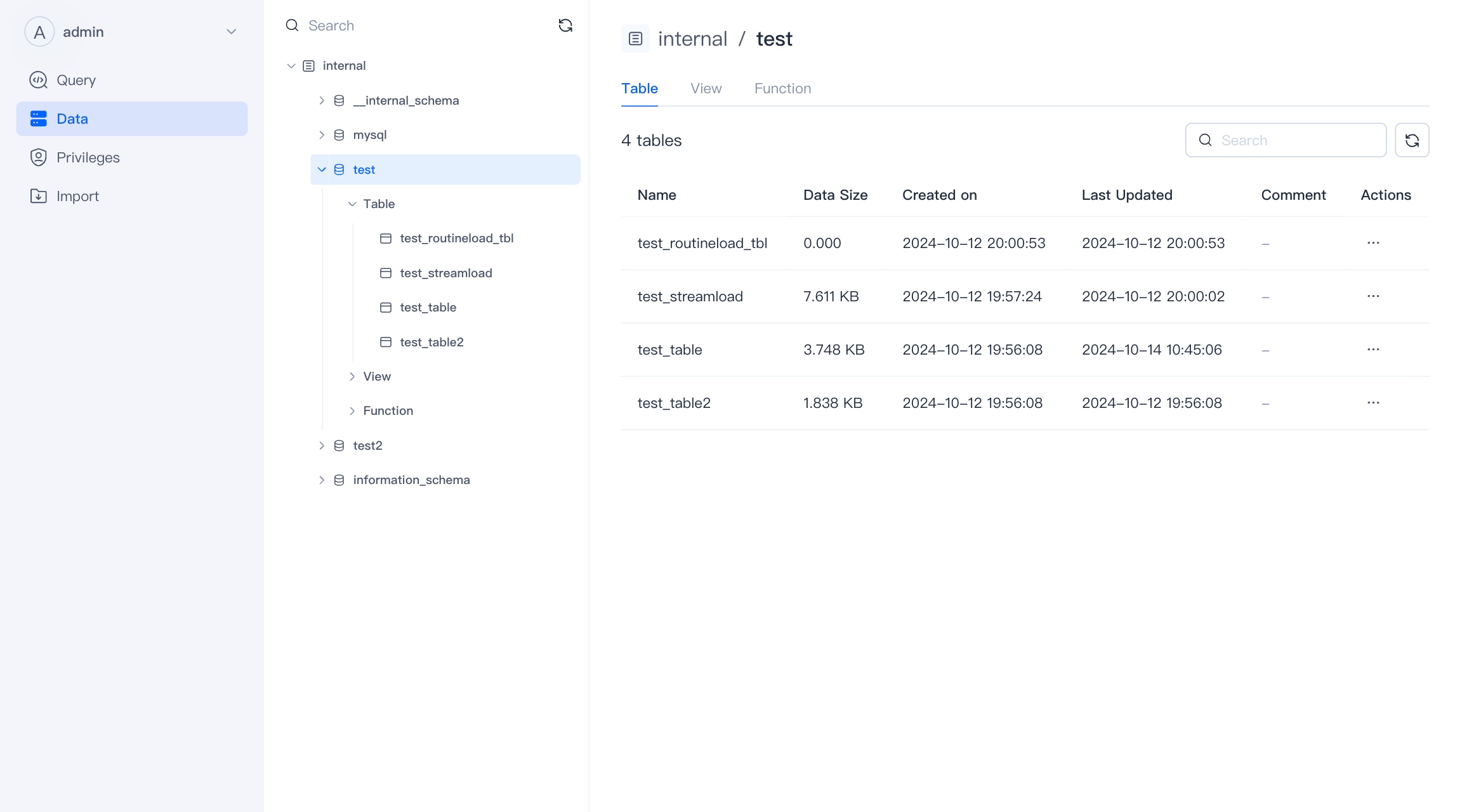
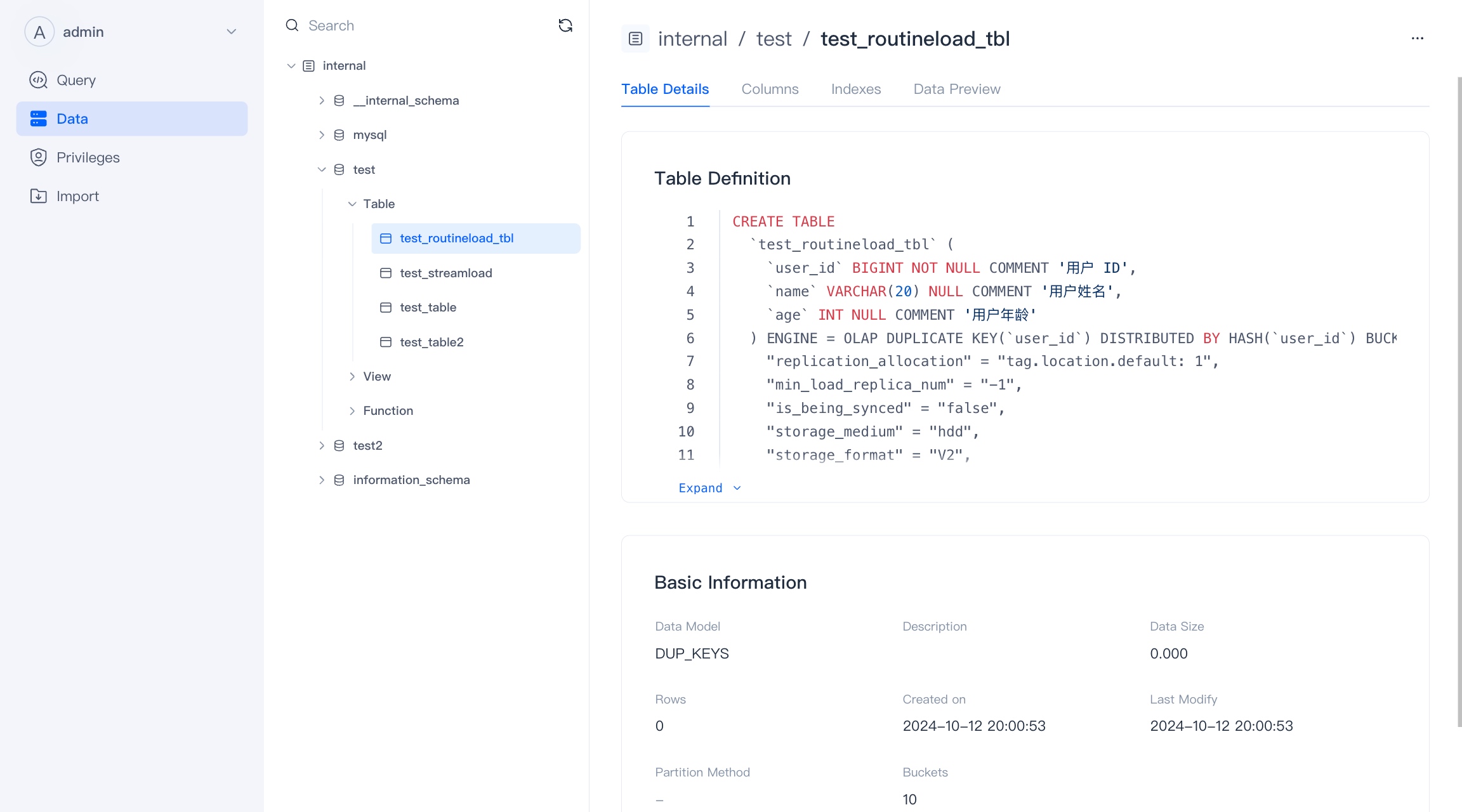
Table Details
On the table details page, you can view the table definition and some basic attributes.
In the future, we will support the viewing and management of the life cycle of the table here, and provide more abundant storage-related statistical information.
In the future, VeloDB WebUI will also support uploading local files to tables to complete the lightweight table import function.
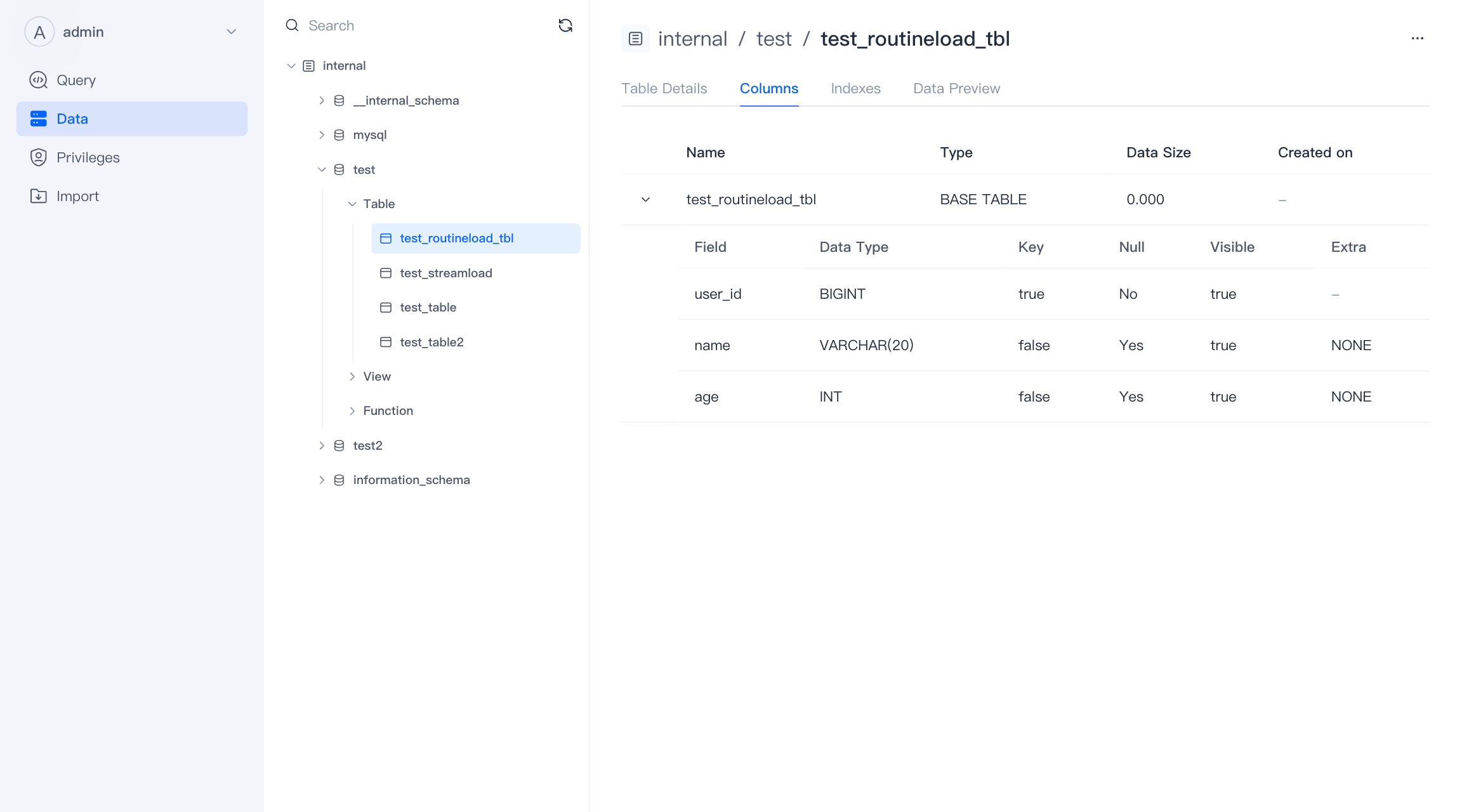
Field Information
Here you can see the field information of the Base Table and its Rollup or materialized view.
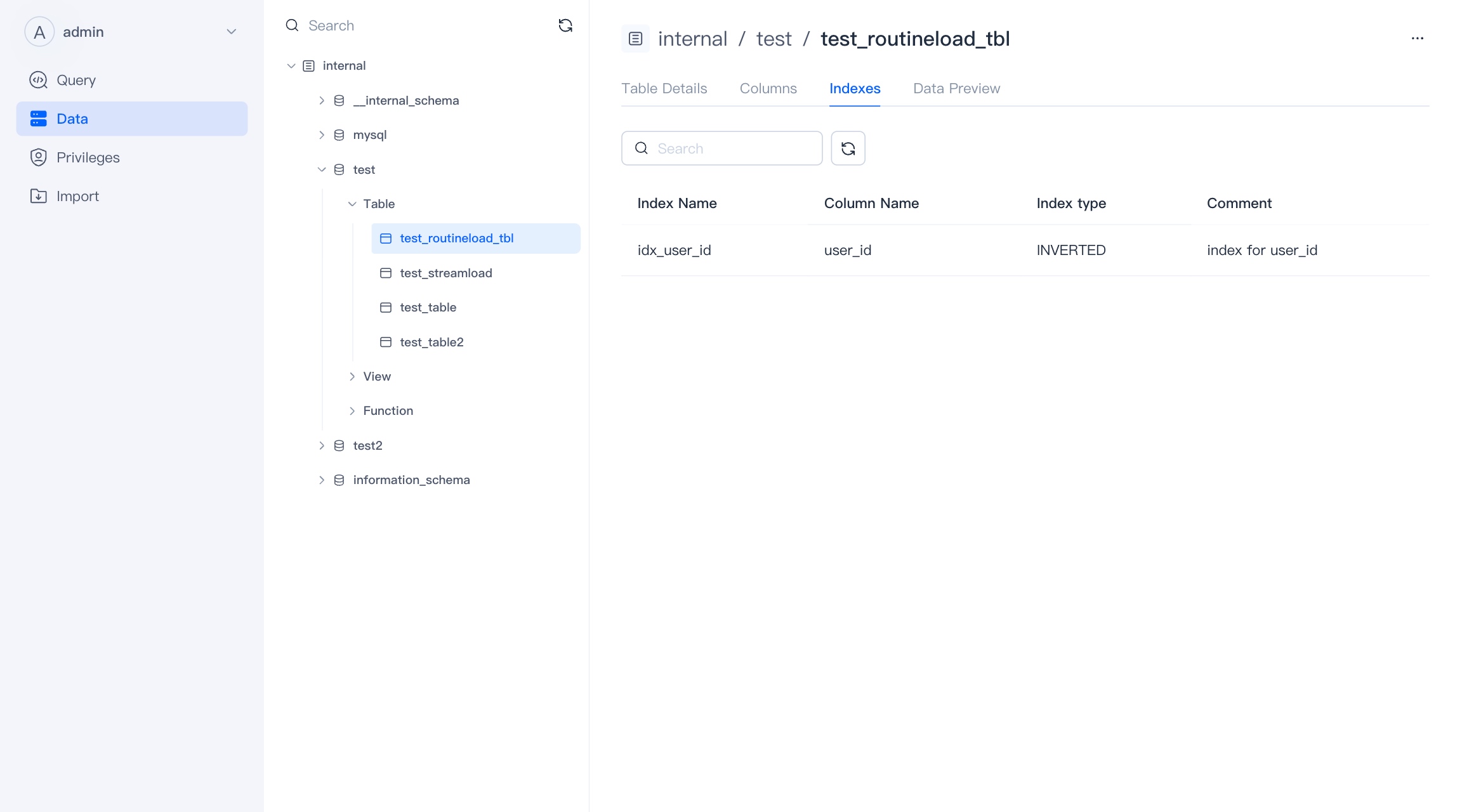
Index
Here is the index information in the table. There are many index-like acceleration methods in VeloDB. Here, partitions, primary keys, and rollups are not treated as indexes for the time being, and only Zonemap, Bloomfilter, Bitmap/Inverted Index are displayed.
Data Overview
Viewing the overview will consume cluster resources, and you must have an available cluster to view the data overview.
"Total x data" is fetched from the metadata service, so there may be a delay and does not reflect the actual number of table rows.
View
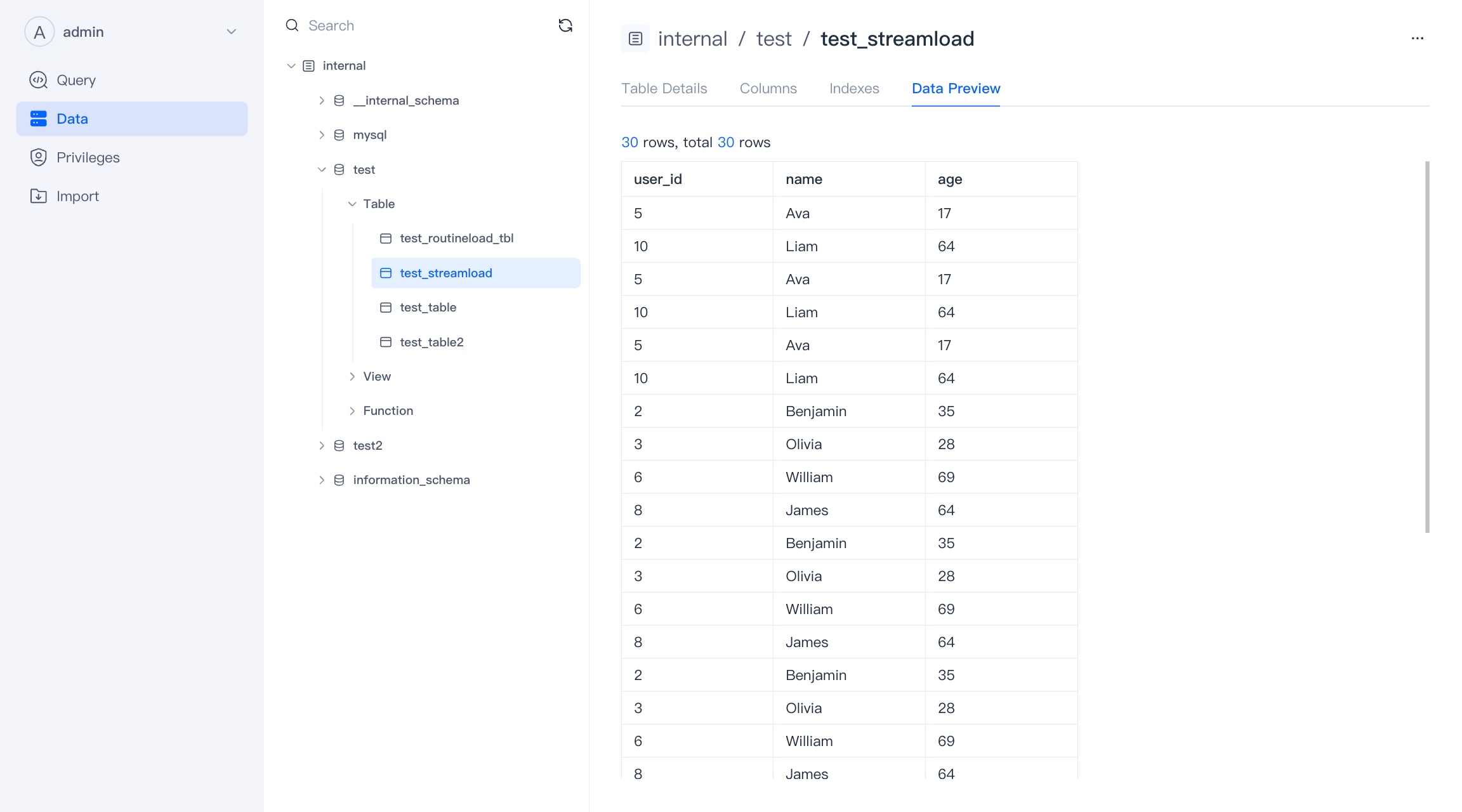
A view is a table based visualization of the result set of an SQL statement. In WebUI, we treat views separately from tables, and materialized views are not within the scope of views.
The view page is roughly similar to the table page, and the attributes that the view does not have (such as index and details) will not be displayed.
You can preview the data, but the preview view data will initiate queries and consume cluster resources.
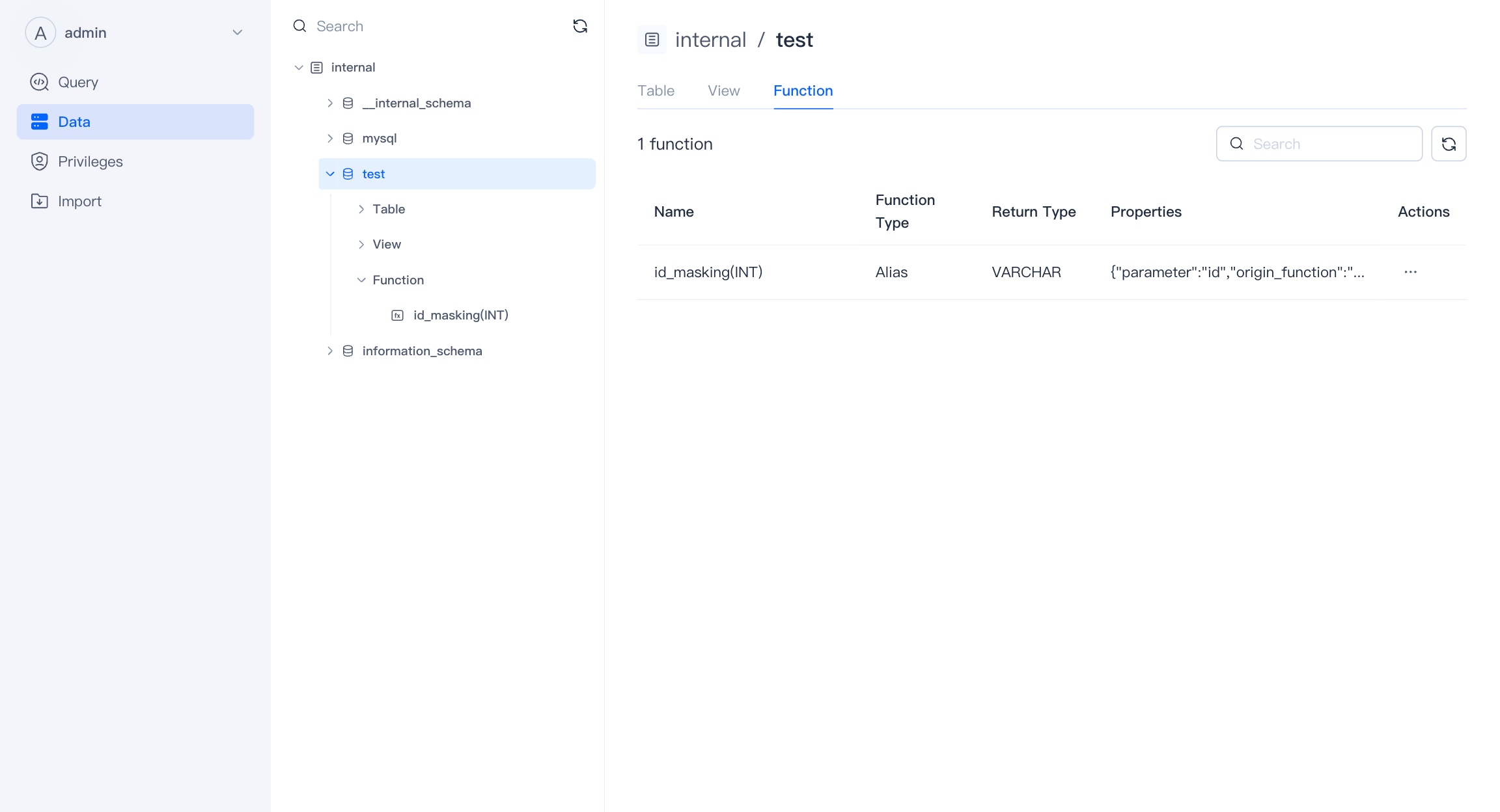
Function
Function is a type of Code Block that can be reused during queries, data operations, or stored procedures. Functions receive input parameters and return calculation results. They can simplify complex query logic, improve code readability and maintainability.
Query
SQL Editor
The query result will be returned below the edit box, and the error or success status and information returned by the query will also be displayed at the query result.
At the same time, you can click the drop-down button Run (LIMIT 1000) and switch to Run and Download to download your query results.
Reminder Currently, if multiple queries are executed at one time, the result of the first Query will be returned, and we will add the function of viewing other returns in later versions.
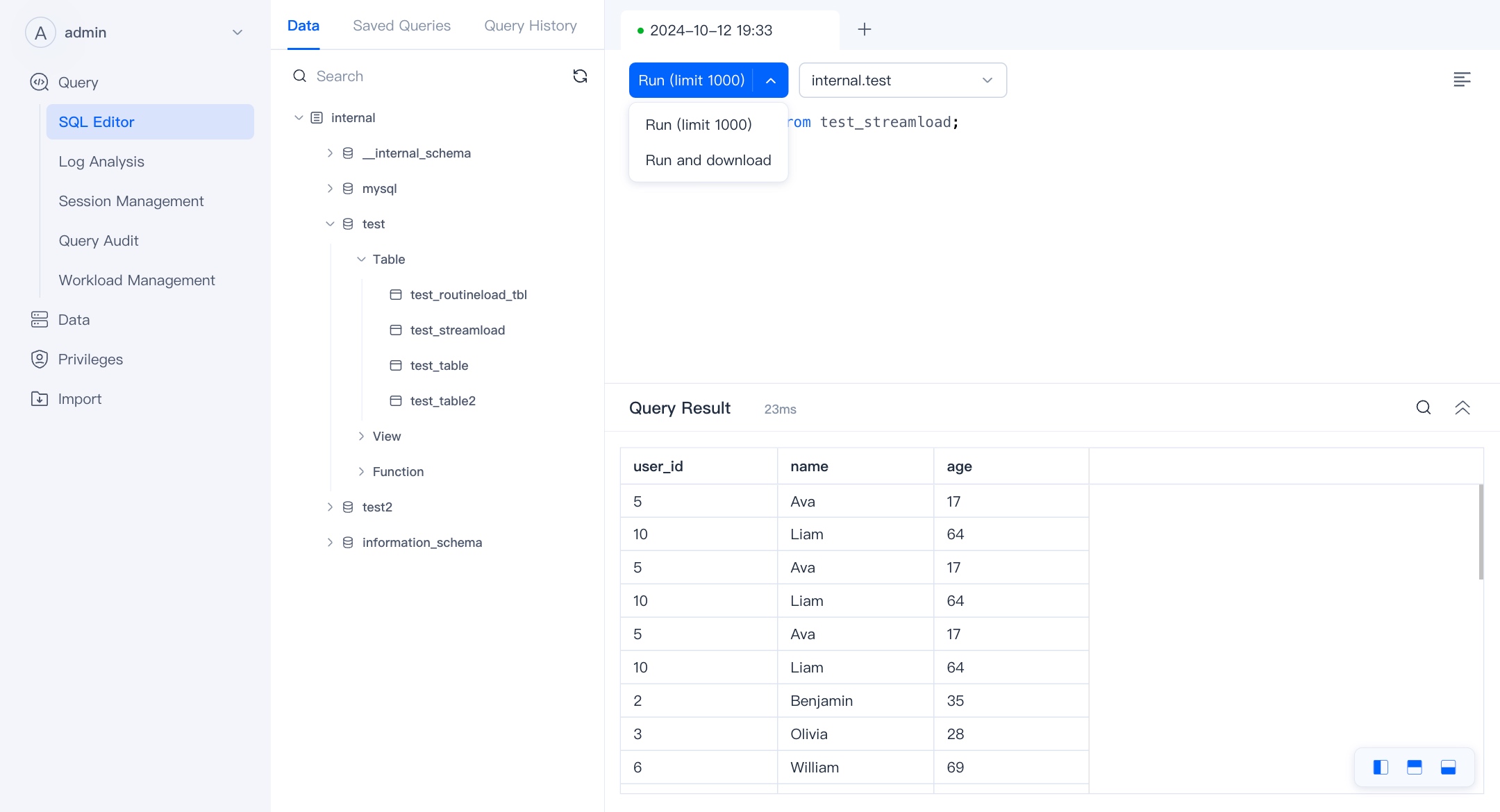
You can click the Query ID of the query history to view the query details.
NOTE There is no Query ID for non-query statements, nor for failed statements.
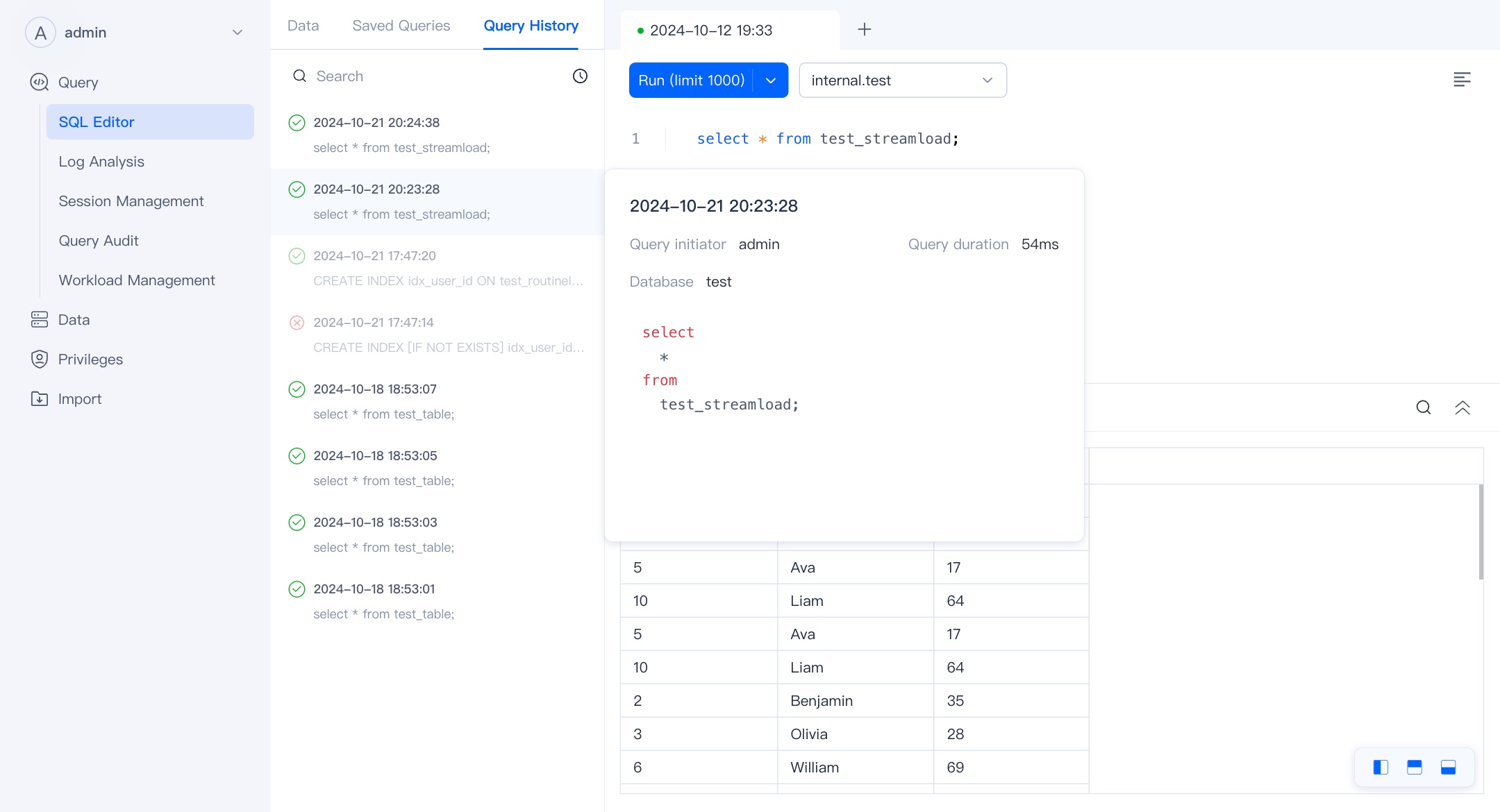
By default, query plans are enabled for queries initiated in the WebUI, which will not affect the performance of a single query. Click "Query Statement" to enter the execution plan page.
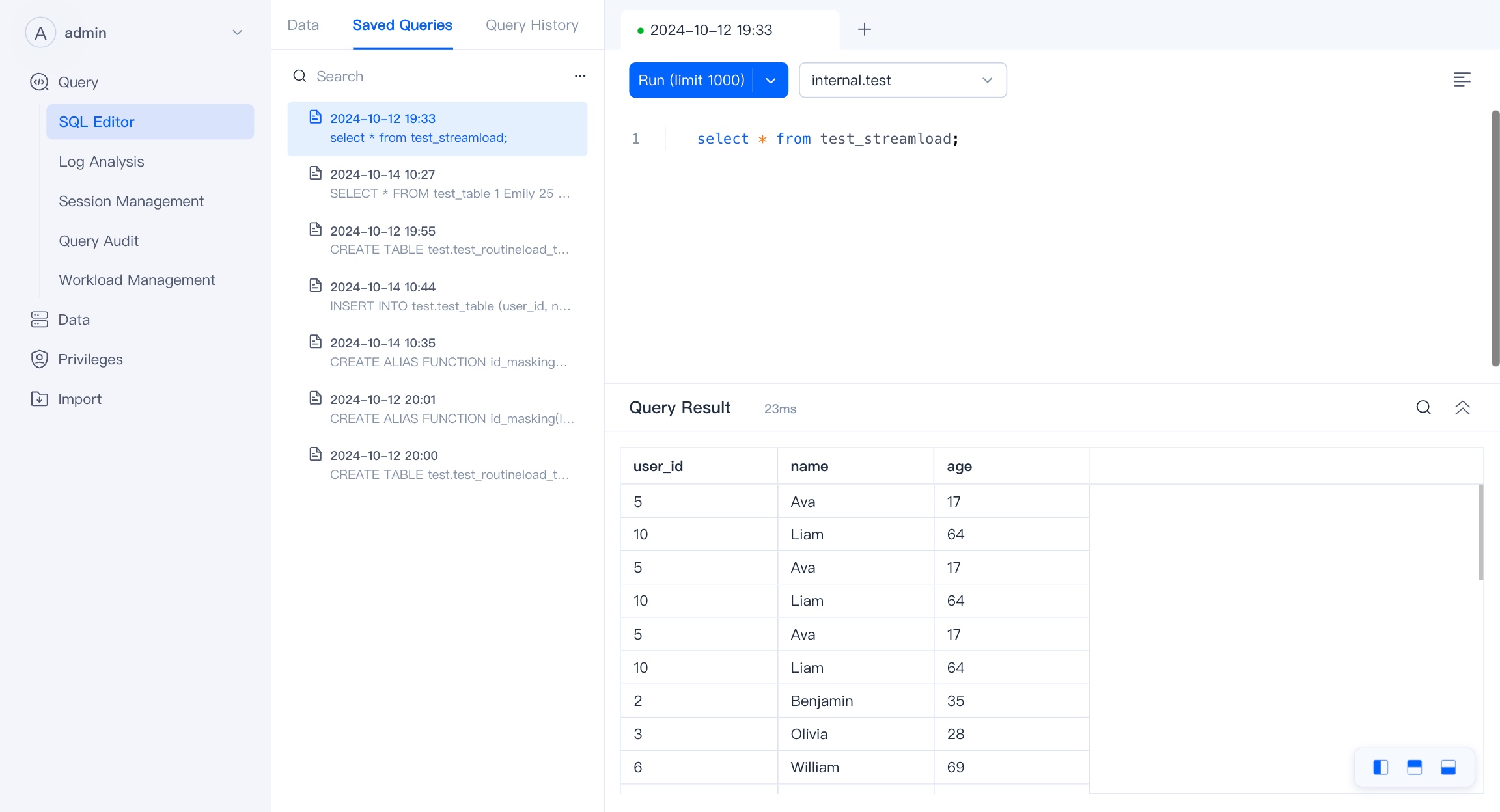
The tabs you create in the SQL Editor and the queries you initiate will be automatically saved. You can double-click on the tab to modify the title of the saved SQL. In Saved Queries, you can view the saved queries and reopen them.
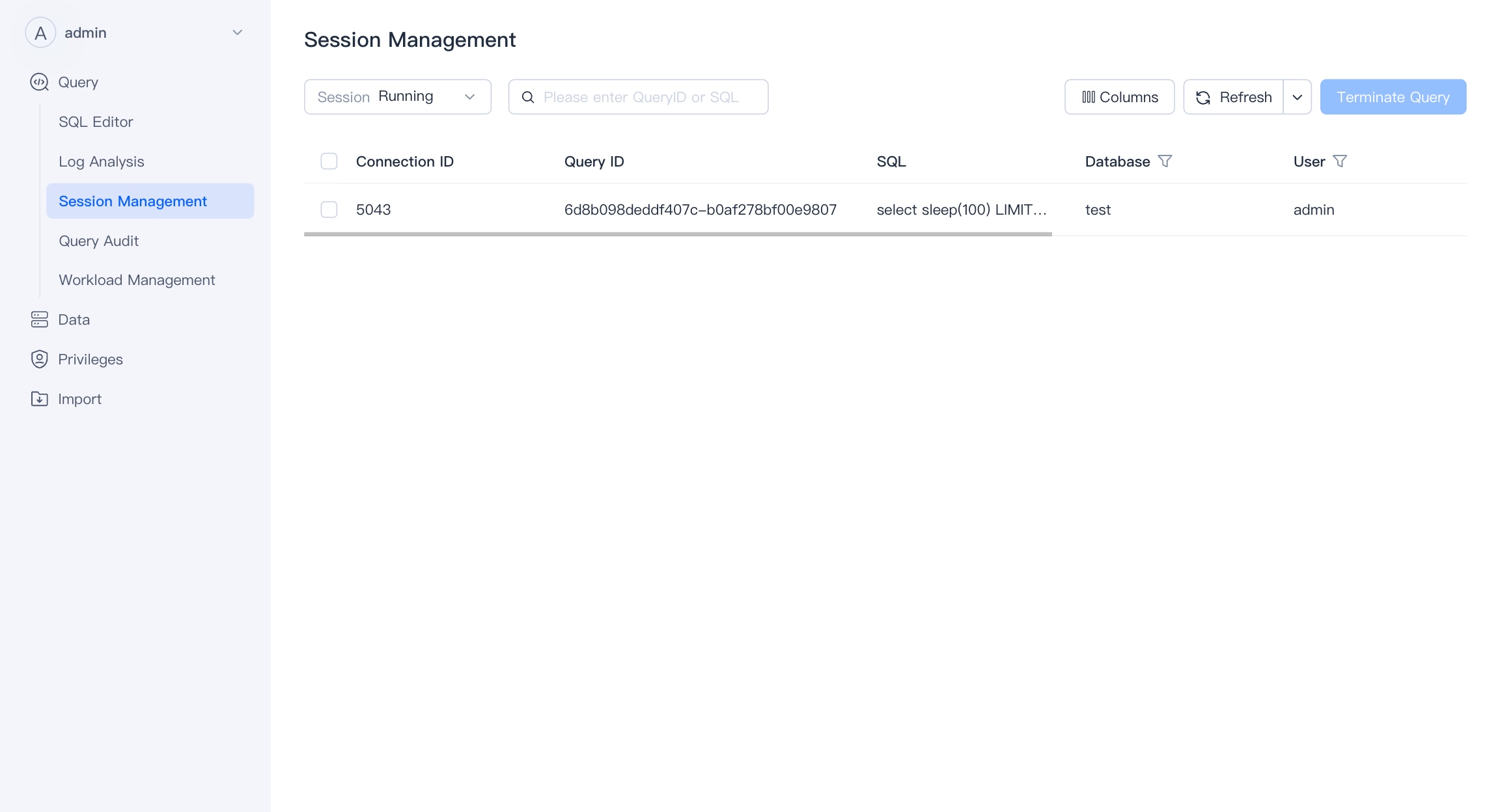
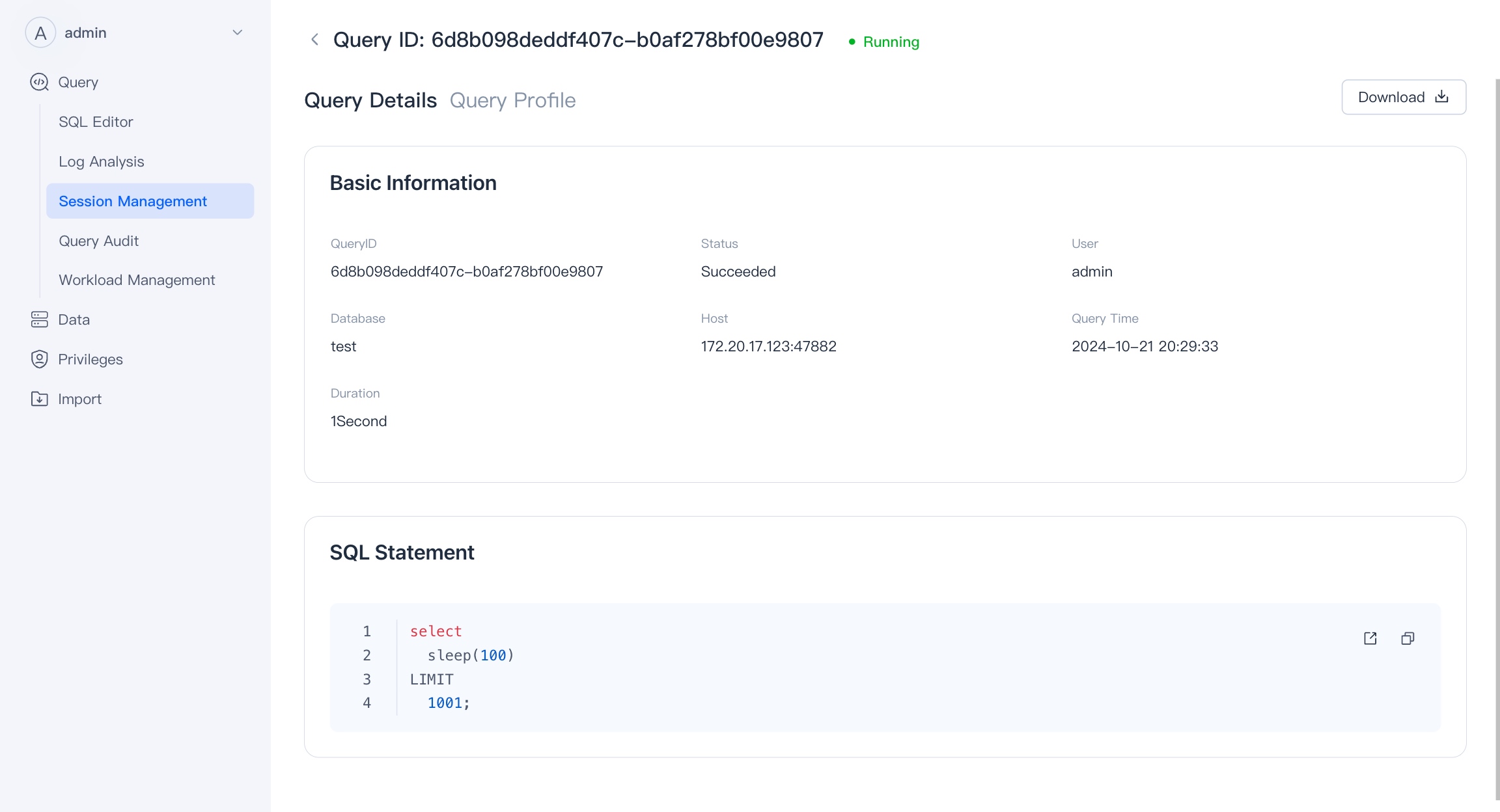
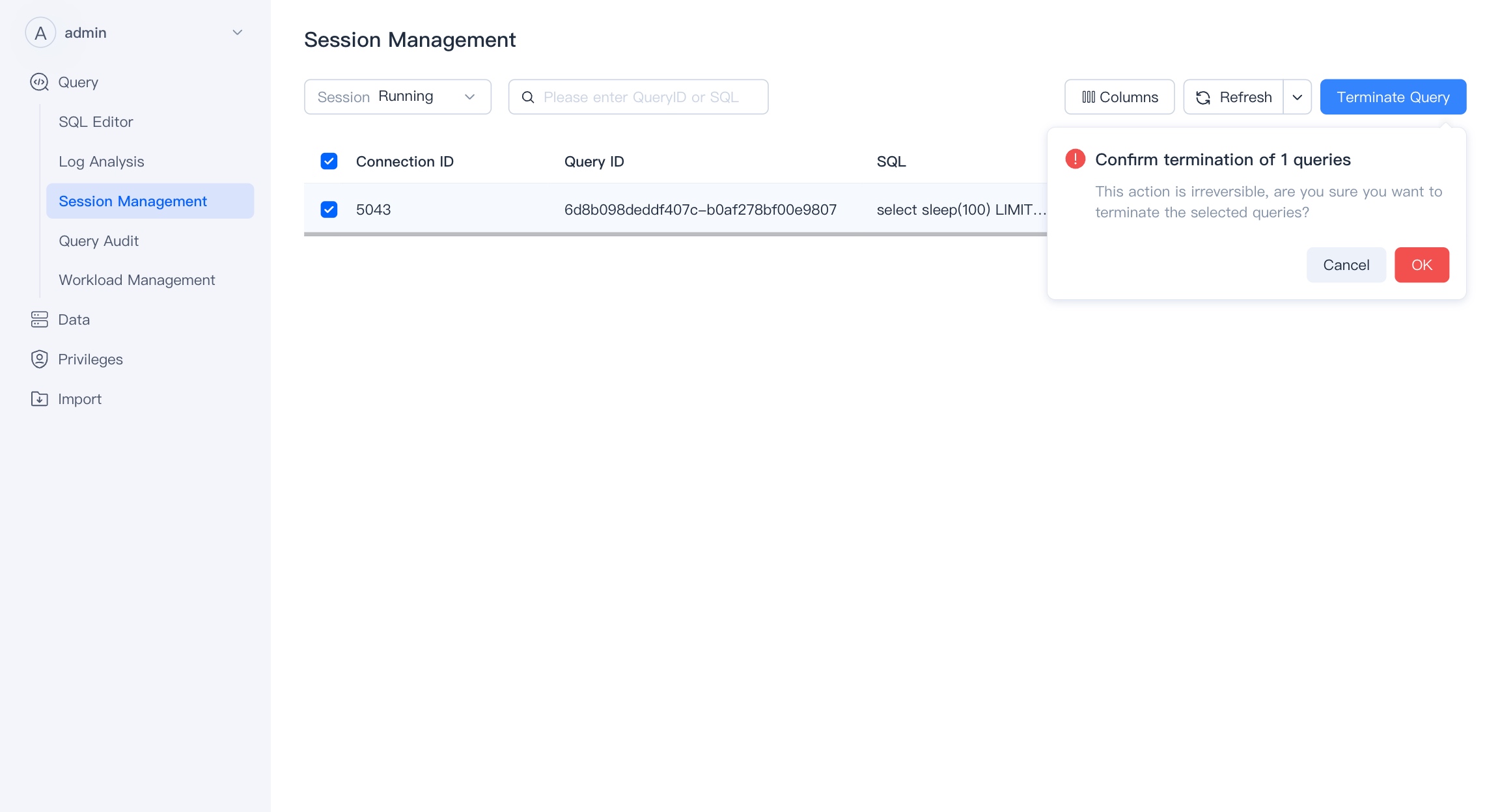
Session Management
Session Management deals with the management of active SQL sessions in a database or data analysis environment. You can view all currently running SQL queries and have the option to terminate (kill) any query that is causing issues or running longer than expected.
It enhances system performance by allowing administrators to manage resource usage and prioritize critical queries and it provide detailed information about each session, like execution time, the user who initiated the query, and the resources being utilized.
Query Audit
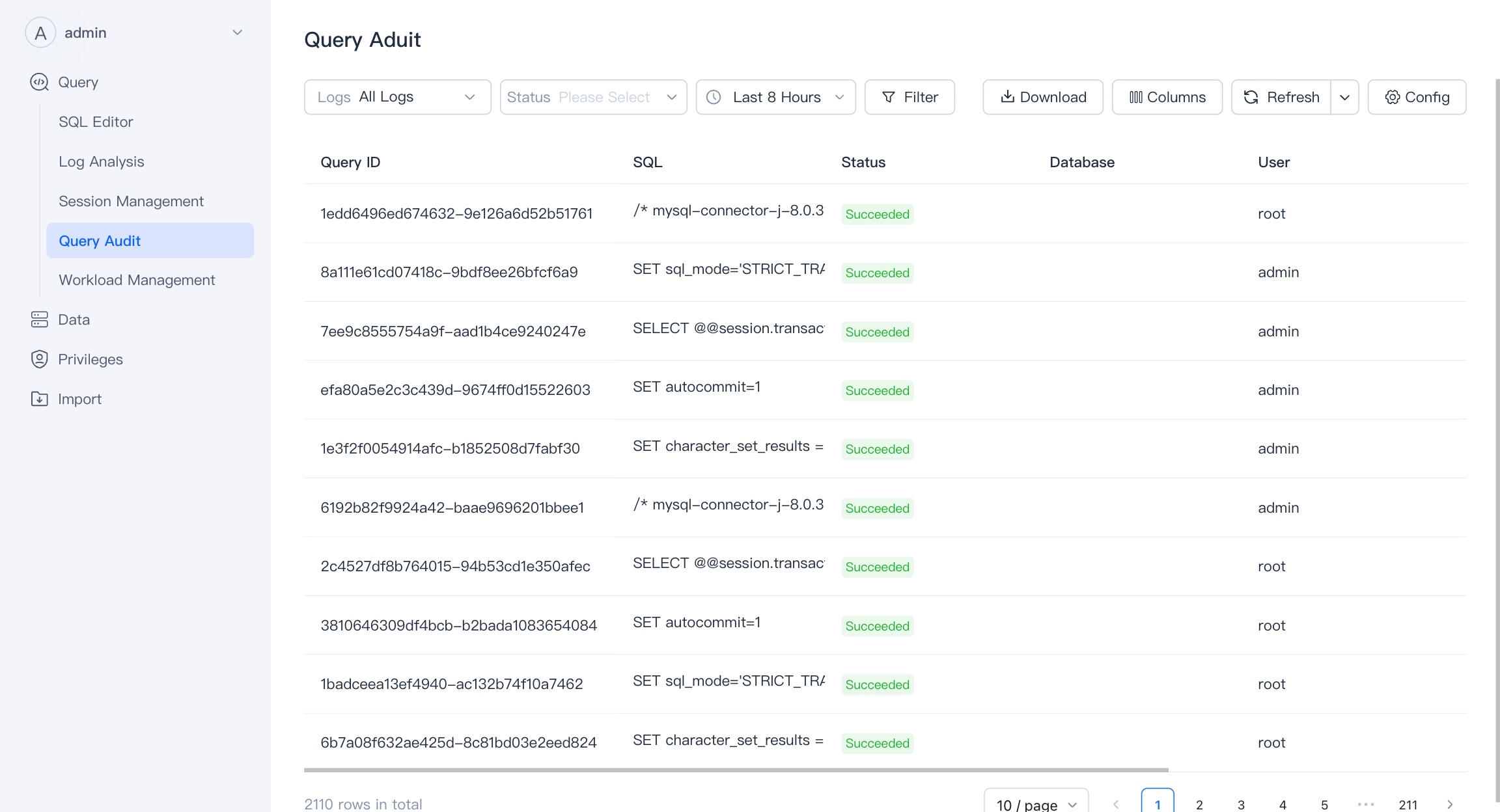
Query Audit is a comprehensive tool for auditing and analyzing the history of queries executed in the system.It allows users to filter and identify slow-performing queries, which is essential for optimizing database performance.
The tool include profiling features that provide deep insights into each query's execution plan and resource usage.It serves as a one-stop solution for tracking query performance, spotting trends, and diagnosing issues over time.
Workload management
Workload management supports quick creation, editing, and viewing of Workload Groups. Workload Groups can be used to manage the CPU/memory/IO resource usage for querying and importing loads in the cluster, and control the maximum concurrency of queries in the cluster.
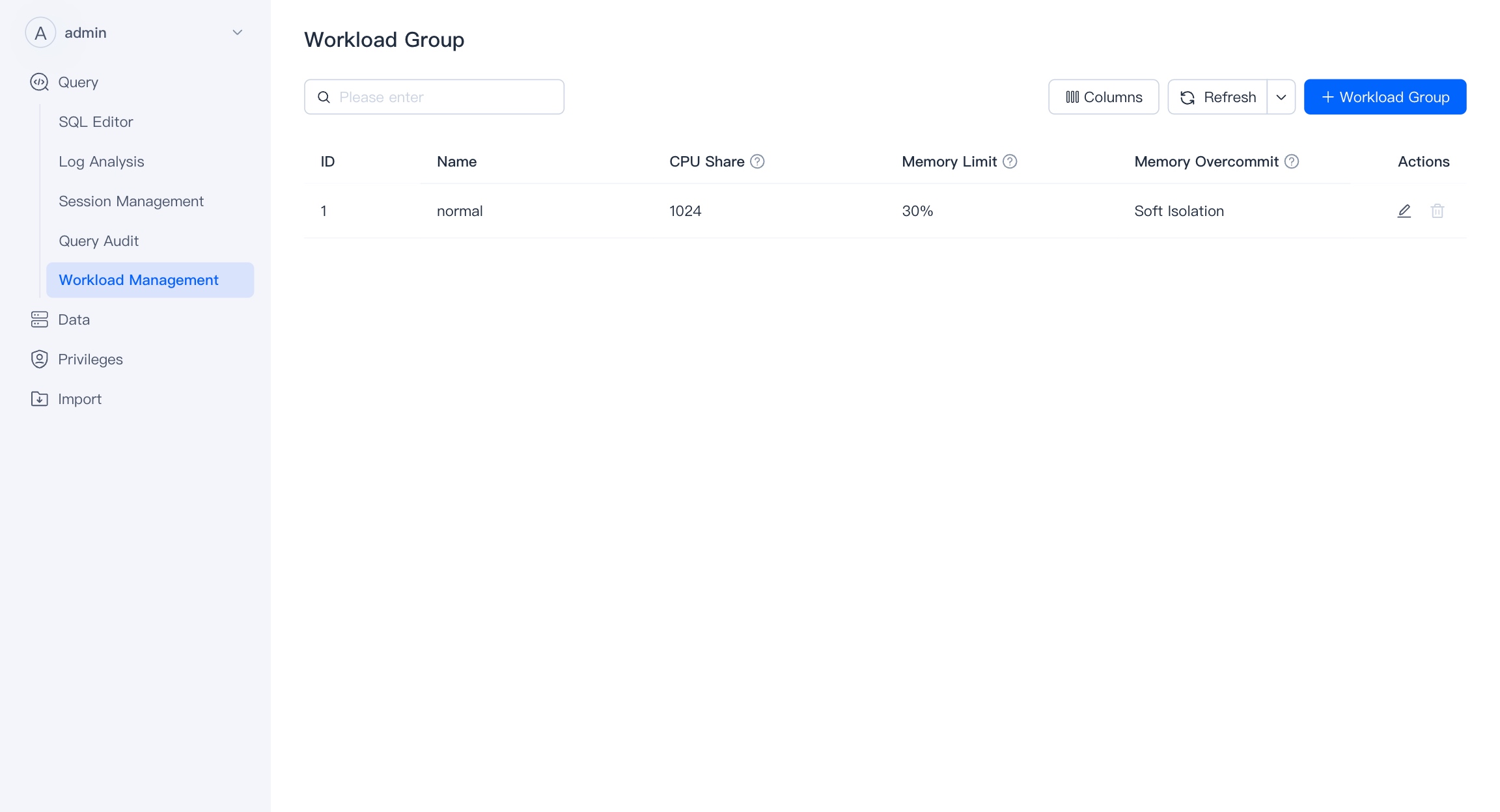
Users with admin privileges can create, modify, and delete workload groups.
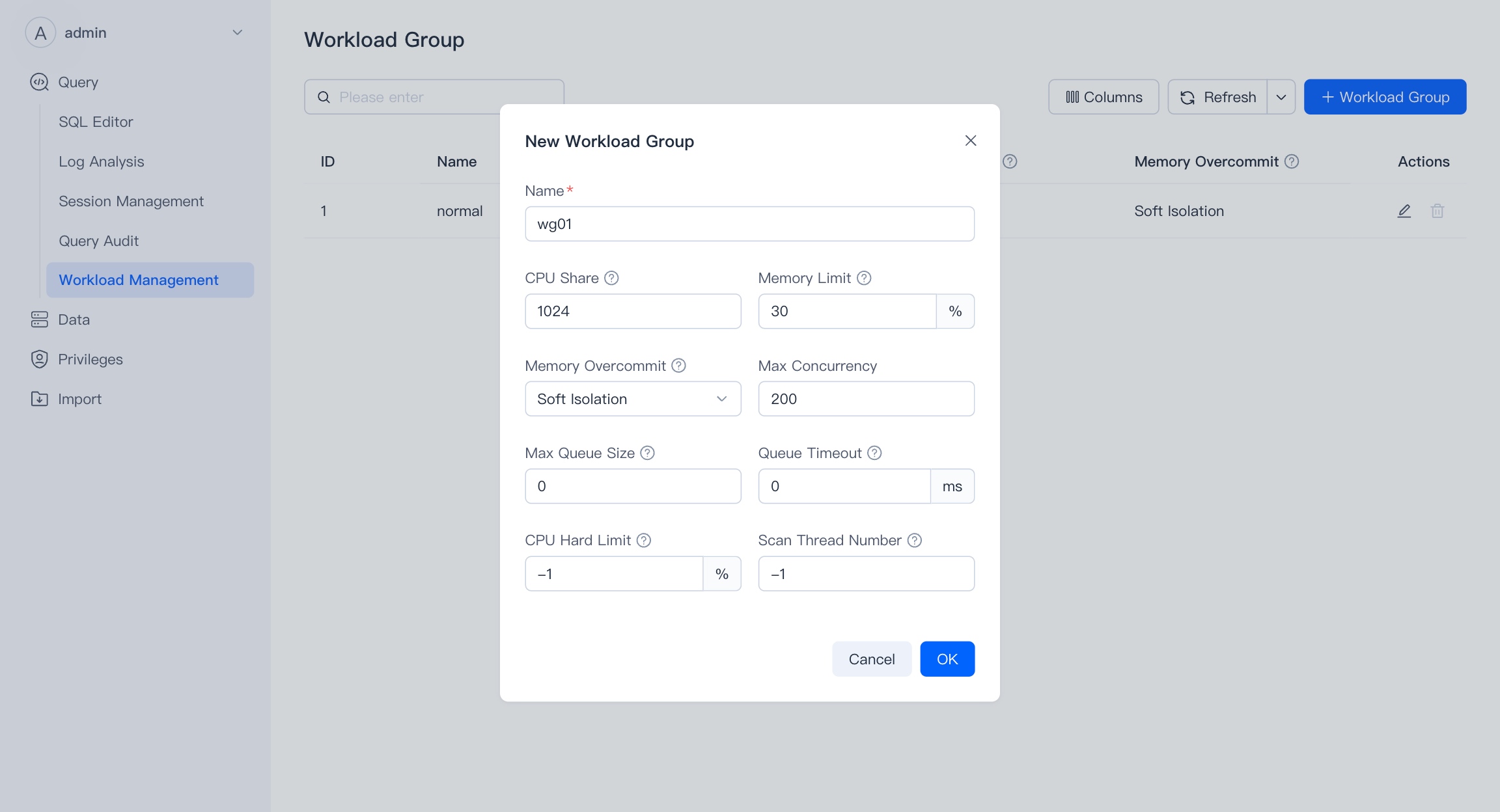
Permissions
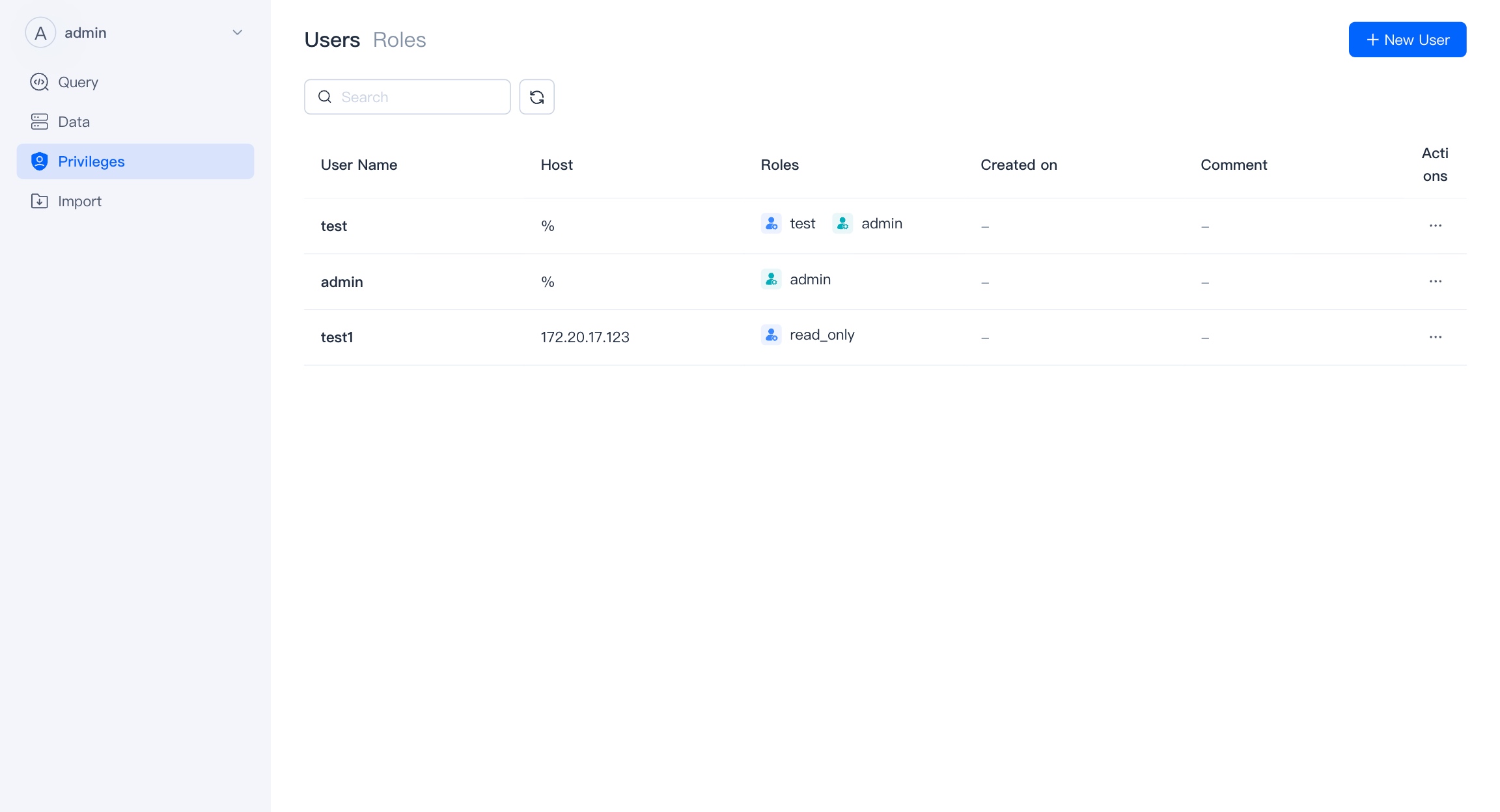
User
Display the users in the VeloDB cluster.
Only users with Admin authority can add and modify other users.
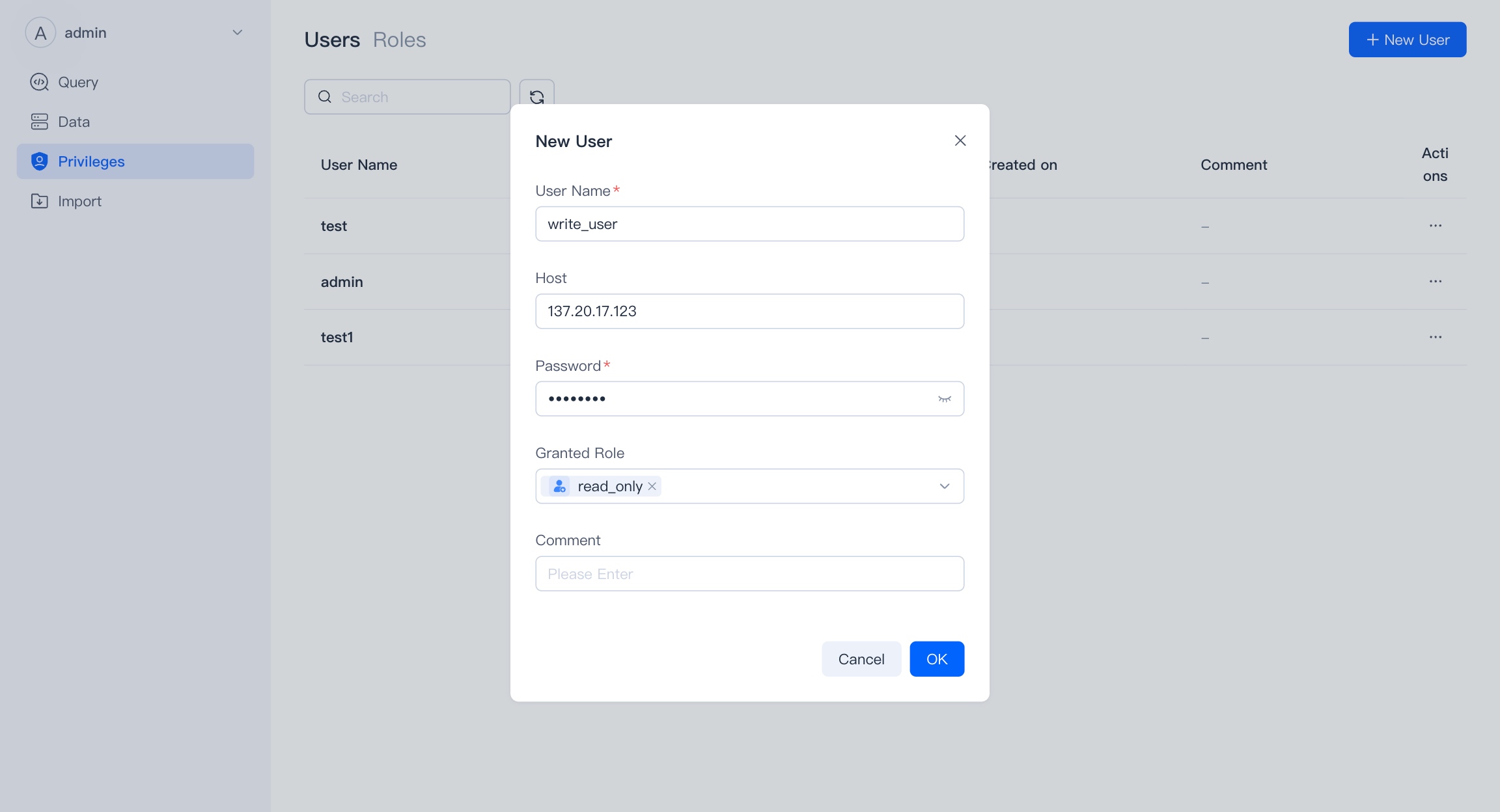
You can create a new user on this page, except for the username, other content is optional. However, we strongly recommend that you add passwords for users and restrict access to hosts for enhanced security.
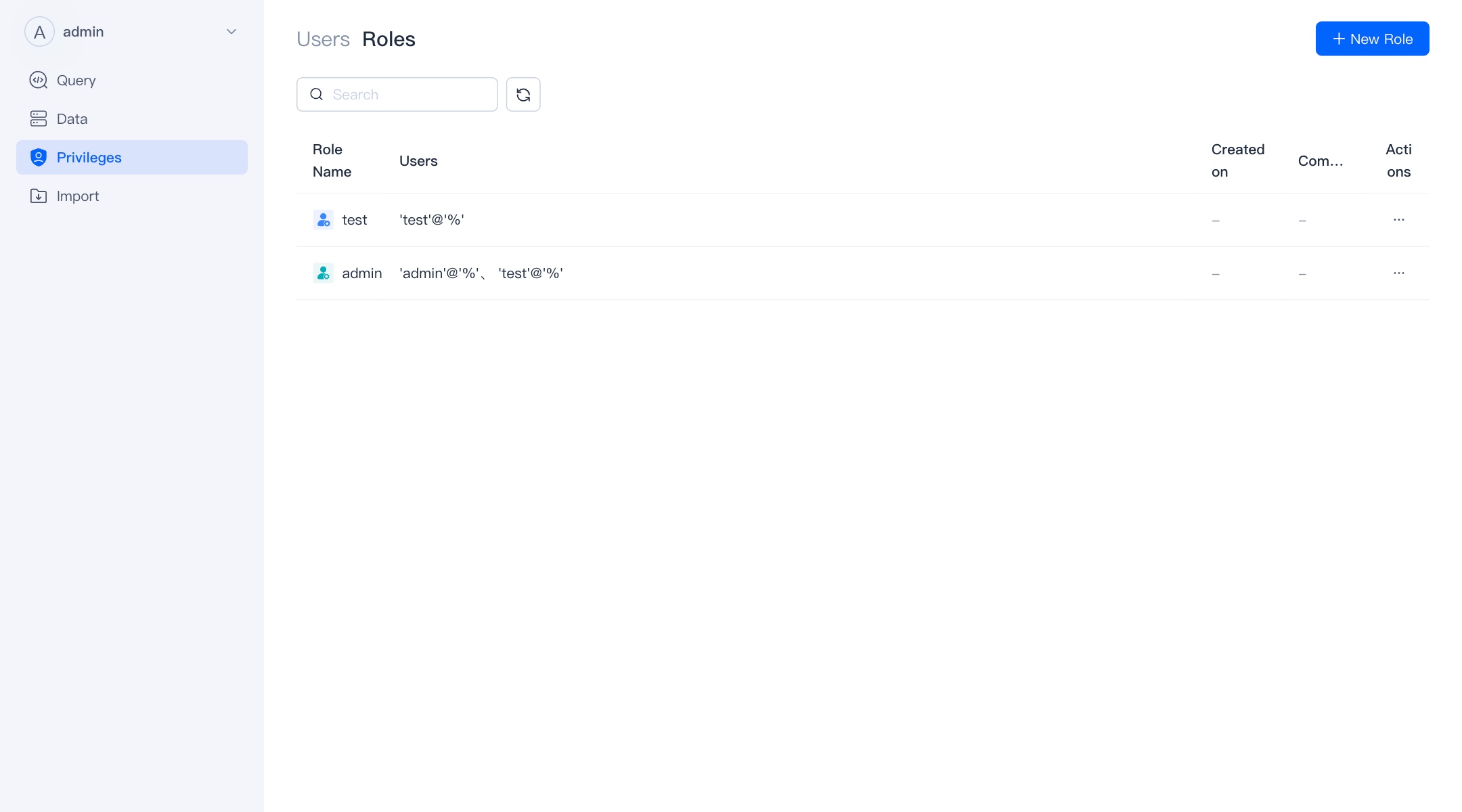
Role
Here you can manage the roles in VeloDB, and also perform authorized operations on the roles.
Only users with Admin permissions can add and modify other roles.
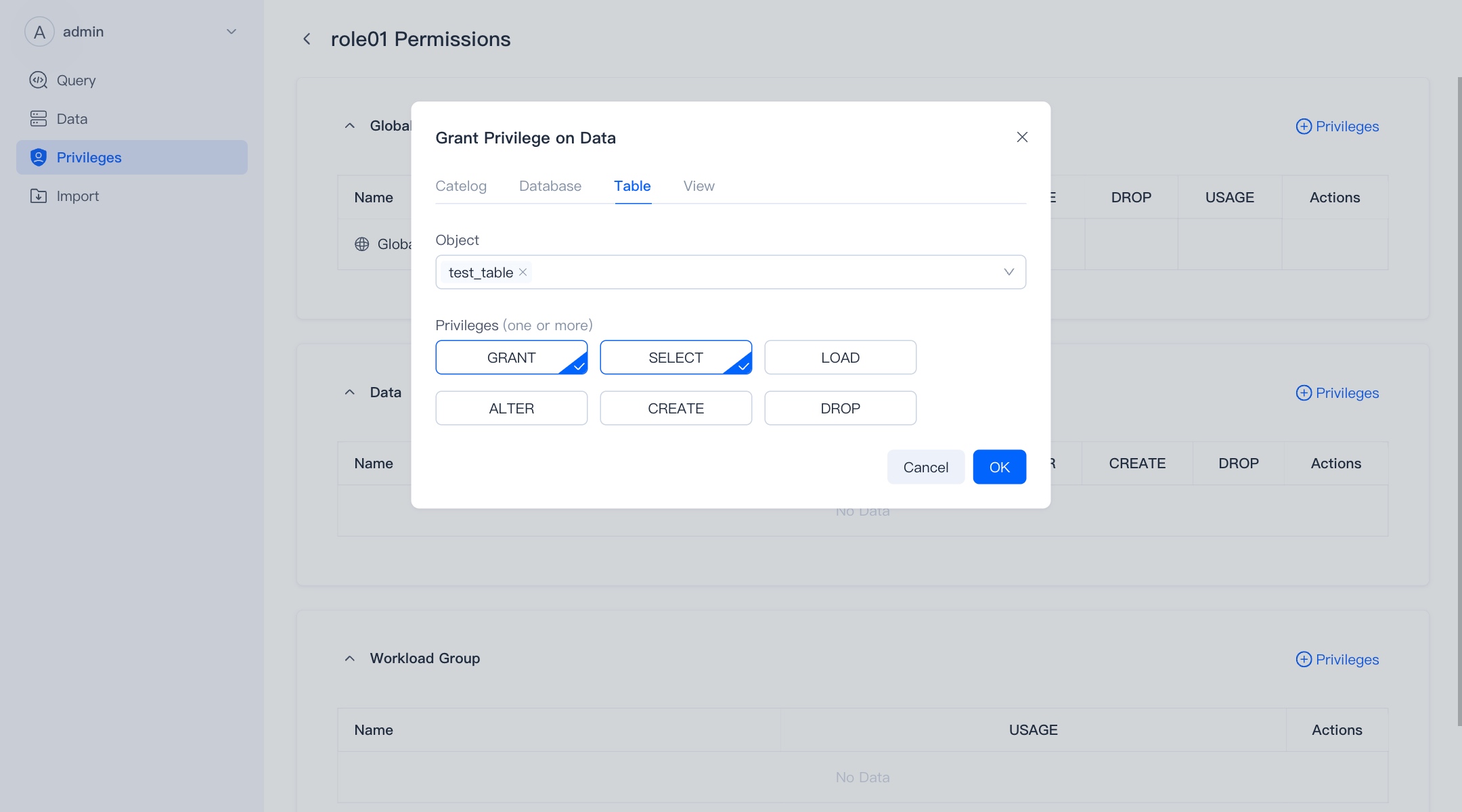
Authorize
On the details page of a user or role, you can perform authorization/revocation operations.
You need to have Admin or the Grant permission at the corresponding level to perform authorization/revocation work.
In WebUI, we divide permissions into three categories, namely:
- Global: Global permissions are permissions at the Global level. With global permissions, you automatically have the corresponding permissions for all corresponding objects in the database.
- Data: Refers to the authority of data resources. You can authorize it according to the level. With the authority of the parent level, you automatically have the corresponding authority of its child content.
- Resource: Only root or admin users can create resources. Currently supported external resources include Spark, ODBC, S3, JDBC, HDFS, HMS, and ES.
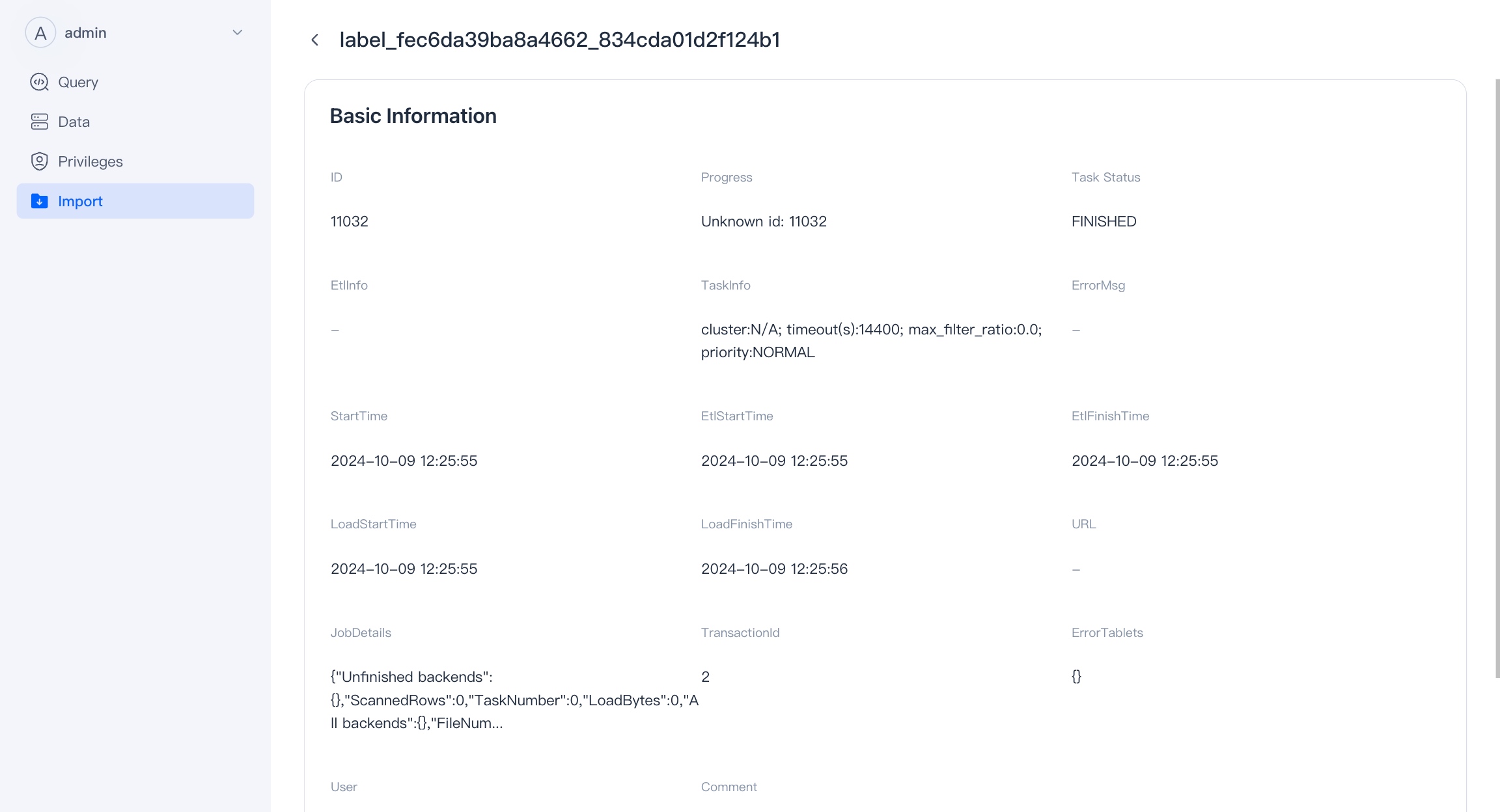
Import
You can view the list of import tasks for the corresponding database in the import module, and perform related operations on these import tasks.
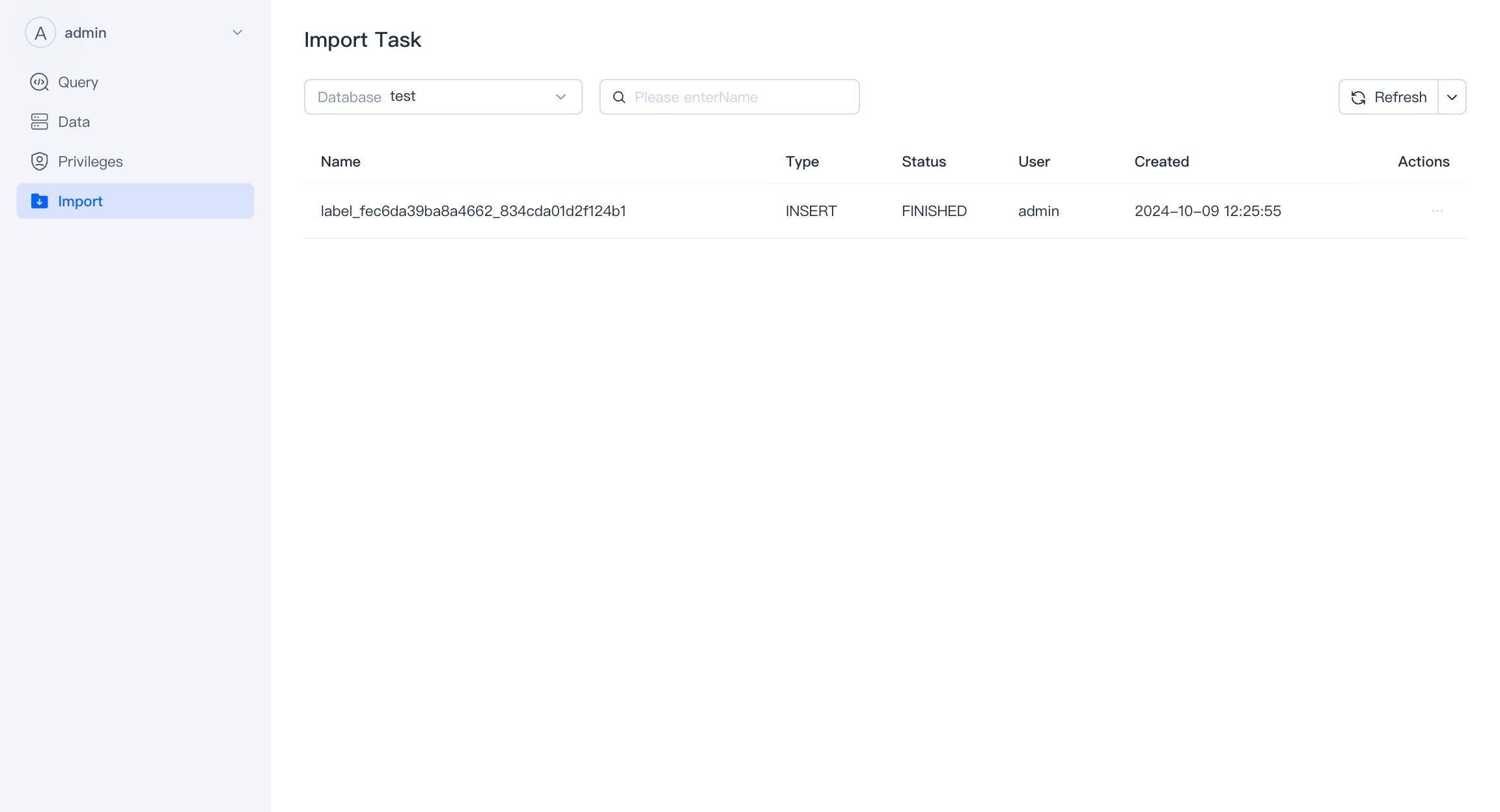
Click the name of the import task to view the details of the import task.